A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models
|
|
|
- Juniper Mitchell
- 6 years ago
- Views:
Transcription
1 A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge, MA 1of 31


")



2 Diversification of speech interfaces Today Personal assistant (smartphone) Search (smartphone, PC) Future Wearables Appliances Robots Goal: Complement or replace touchscreen interfaces 2of 31


3 Computational demands of ASR (ASR = Automatic speech recognition) Real-time ASR is now feasible on x86 PCs ARM SoCs can run with minor performance degradation But what about everyone else? Today s model: offload to cloud servers Tomorrow: offload to cloud OR hardware accelerator System power concerns: Memory I/O signaling If processor efficiency is optimized in isolation, these can exceed core power Today s non-volatile memory: MLC NAND flash At 100 pj/bit: 100 MB/s -> 80 mw 3of 31


4 Hardware accelerated speech interface Primary use cases: 1. Low power 2. Low system complexity 3. Low latency 4of 31
5 1. Introduction a) Motivation and scope b) ASR formulation Outline 2. Acoustic modeling with deep neural networks (DNN) a) Performance with limited memory bandwidth b) Parallel architecture c) Details of execution unit design 3. Search (Viterbi) architecture 4. Voice activity detection (VAD) a) System power model b) Modulation frequency (MF) algorithm and architecture 5. Test chip a) Circuit features b) Measured performance 5of 31


6 ASR formulation HMM Inference: search using Viterbi algorithm 6of 31
 where i is the tied state index and y is the feature vector (typ. 10 50 dims.")

7 ASR formulation Acoustic model Training clusters WFST states into tied states (senones) Acoustic model approximates p(y i) where i is the tied state index and y is the feature vector (typ dims.) Example PDFs (MFCC features projected to 2-D) Models have many parameters large memory requirement Size: Typical ASR model is ~50 MB must be stored off-chip Bandwidth: Naïve evaluation would require 5 GB/s (Target for low-power ASR: ~10 MB/s) 7of 31
8 Bandwidth-limited acoustic models Comparison of frameworks considers: Quantization Parallelization Accuracy GMM = Gaussian mixture model SGMM = Subspace GMM DNN = Deep neural network 8of 31


")

9 Feed-forward neural network (DNN) Sequence of simple nonlinear transformations Used in ASR to evaluate all acoustic likelihoods jointly This work: feed-forward networks only (no time dependence) Top image is from: Michael A. Nielsen, Neural Networks and Deep Learning, Determination Press, of 31

10 DNN evaluator architecture 10 of 31
11 Execution unit assignment International Solid-State Circuits Conference and Voice-Activated Power Gating 11 of 31


12 Execution unit design Complexity has been minimized: Executes arithmetic commands from sequencer Writes results back to local SRAM 12 of 31
 polynomial fit Less")


13 Sigmoid approximation Piecewise (low-order) polynomial fit Less area than plain LUT Simpler to evaluate than high-order fit Chebyshev approximation Better accuracy than Taylor series 13 of 31

14 Sigmoid approximation Polynomial evaluated using Horner s method Use unpipelined version to save area 7-cycle latency; 5.7k gates (mostly the multiplier) 14 of 31




15 Search Viterbi algorithm Baseline architecture From: M. Price et al., A 6mW 5kword Speech Recognizer using WFST Models, ISSCC of 31





16 Search Viterbi algorithm Improved architecture Compression and caching: memory bandwidth reduction Word lattice: memory bandwidth reduction Merged state lists: 11% area savings 16 of 31




17 Search Word lattice From state lattice to word lattice Discard intermediate states between words 17 of 31
18 Search Word lattice (cont.) Light workloads: no external memory writes (pruning keeps word lattice within internal memory) Heavy workloads: 8x reduction (writing only word arcs) 18 of 31
19 ASR accuracy and speed Similar accuracy to software (Kaldi) with 145k word vocab. At 80 MHz, same search speed as software on 3.7 GHz Xeon 19 of 31
")


20 Voice activity detection (VAD) Use VAD to control power gate for ASR (Automatic wake-up) 20 of 31
21 VAD power impacts Consider typical values: p VAD < 100 μw p downstream > 1 mw D < 0.05 Downstream system contribution If p FA is significant, averaged downstream power exceeds VAD power Optimize for p M and p FA (VAD accuracy) rather than VAD power 21 of 31



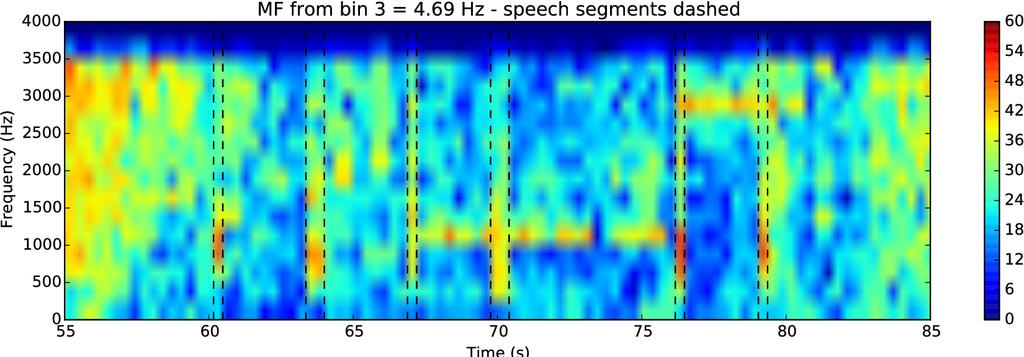
22 Modulation frequency VAD International Solid-State Circuits Conference and Voice-Activated Power Gating 22 of 31
 MF features fed to NN classifier")
 is sufficient Fewer parameters")


23 Modulation frequency VAD (cont.) MF features fed to NN classifier Small network (e.g. 3x32) is sufficient Fewer parameters than SVM NN architecture stripped down from ASR No sparse matrix support No parallel evaluation Still quantized No external memory Parameters supplied at startup over SPI bus 23 of 31
24 VAD performance comparison Two tasks: Aurora2 (left), Forklift/Switchboard (right more difficult) MF algorithm outperforms energy-based (EB) and harmonicity (HM) Performance improves with more training data 24 of 31






25 ASR/VAD interfaces VAD runs continuously Supervisory logic places ASR in reset during non-speech input ASR requests audio samples buffered by VAD after wake-up 25 of 31



26 Test chip specifications 26 of 31

 cannot handle low logic level Intermediate")

27 Multivoltage design Memory tends to require higher voltage than logic Separate memory supplies I/O level shifters ( V) cannot handle low logic level Intermediate supply for top level (with supervisory logic) Relationship between supply voltages is constrained Level shifters operate in one direction 27 of 31




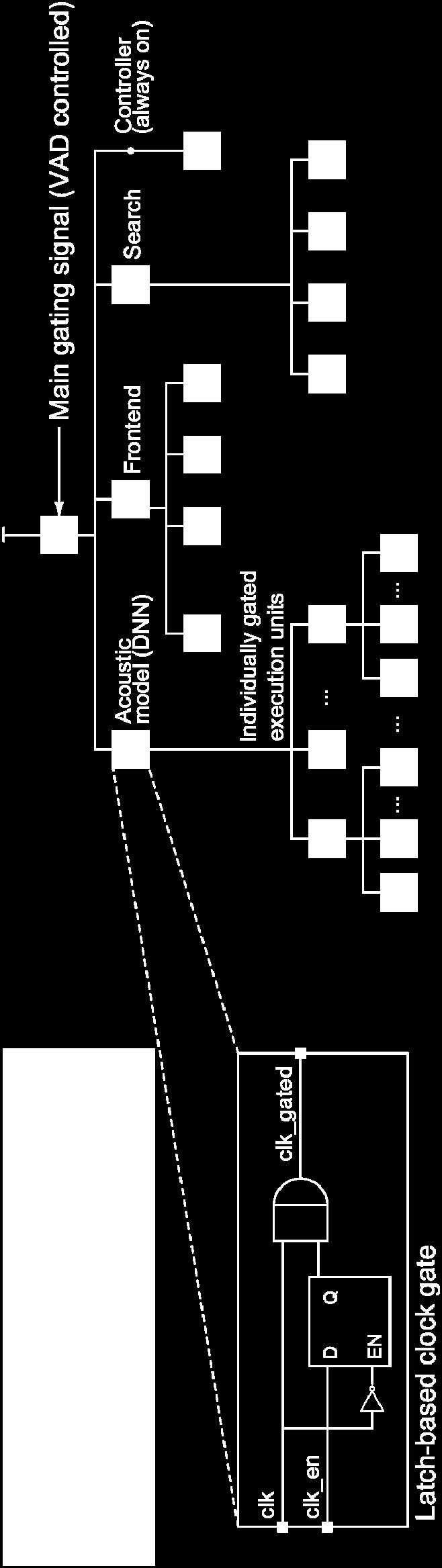
28 Clock gating Explicit clock gating complements automatic clock gating 28 of 31

29 Test setup On-board control of clocks and power supplies FPGA provides host and memory interfaces Tested live audio, real-time streaming, batch processing 29 of 31




30 Measured performance and scalability Note: ASR model sizes and search parameters vary between tasks; ASR and VAD tested independently 45x range 30 of 31
31 Conclusions DNNs can improve performance of HW ASR Even with restricted memory bandwidth: < 10 MB/s DNN based VAD can be robust and compact Model stored on-chip (< 12 kb) Low power (22.3 μw) ASR is not only about neural networks Significant effort required for feature extraction and search NN architecture developed with knowledge of application Combination of algorithm, architecture, and circuit techniques delivers: Improved accuracy fewer word errors Improved programmability train using standard tools Improved scalability lower power consumption 31 of 31
Automatic Speech Recognition (ASR)
") Automatic Speech Recognition (ASR) February 2018 Reza Yazdani Aminabadi Universitat Politecnica de Catalunya (UPC) State-of-the-art State-of-the-art ASR system: DNN+HMM Speech (words) Sound Signal Graph
Automatic Speech Recognition (ASR) February 2018 Reza Yazdani Aminabadi Universitat Politecnica de Catalunya (UPC) State-of-the-art State-of-the-art ASR system: DNN+HMM Speech (words) Sound Signal Graph
DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses
 DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses Paul N. Whatmough 1,2 S. K. Lee 2, N. Mulholland 2, P. Hansen 2, S. Kodali 3, D. Brooks 2, G.-Y. Wei 2 1 ARM Research, Boston,
DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses Paul N. Whatmough 1,2 S. K. Lee 2, N. Mulholland 2, P. Hansen 2, S. Kodali 3, D. Brooks 2, G.-Y. Wei 2 1 ARM Research, Boston,
TINY System Ultra-Low Power Sensor Hub for Always-on Context Features
 TINY System Ultra-Low Power Sensor Hub for Always-on Context Features MediaTek White Paper June 2015 MediaTek s sensor hub solution, powered by the TINY Stem low power architecture, supports always-on
TINY System Ultra-Low Power Sensor Hub for Always-on Context Features MediaTek White Paper June 2015 MediaTek s sensor hub solution, powered by the TINY Stem low power architecture, supports always-on
The Power of Speech: Supporting Voice- Driven Commands in Small, Low-Power. Microcontrollers
 Borrowing from an approach used for computer vision, we created a compact keyword spotting algorithm that supports voice-driven commands in edge devices that use a very small, low-power microcontroller.
Borrowing from an approach used for computer vision, we created a compact keyword spotting algorithm that supports voice-driven commands in edge devices that use a very small, low-power microcontroller.
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
Sophon SC1 White Paper
 Sophon SC1 White Paper V10 Copyright 2017 BITMAIN TECHNOLOGIES LIMITED All rights reserved Version Update Content Release Date V10-2017/10/25 Copyright 2017 BITMAIN TECHNOLOGIES LIMITED All rights reserved
Sophon SC1 White Paper V10 Copyright 2017 BITMAIN TECHNOLOGIES LIMITED All rights reserved Version Update Content Release Date V10-2017/10/25 Copyright 2017 BITMAIN TECHNOLOGIES LIMITED All rights reserved
An Ultra Low-Power Hardware Accelerator for Automatic Speech Recognition
 An Ultra Low-Power Hardware Accelerator for Automatic Speech Recognition Reza Yazdani, Albert Segura, Jose-Maria Arnau, Antonio Gonzalez Computer Architecture Department, Universitat Politecnica de Catalunya
An Ultra Low-Power Hardware Accelerator for Automatic Speech Recognition Reza Yazdani, Albert Segura, Jose-Maria Arnau, Antonio Gonzalez Computer Architecture Department, Universitat Politecnica de Catalunya
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
Hello Edge: Keyword Spotting on Microcontrollers
 Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Low-Power Processor Solutions for Always-on Devices
 Low-Power Processor Solutions for Always-on Devices Pieter van der Wolf MPSoC 2014 July 7 11, 2014 2014 Synopsys, Inc. All rights reserved. 1 Always-on Mobile Devices Mobile devices on the move Mobile
Low-Power Processor Solutions for Always-on Devices Pieter van der Wolf MPSoC 2014 July 7 11, 2014 2014 Synopsys, Inc. All rights reserved. 1 Always-on Mobile Devices Mobile devices on the move Mobile
Sirius: An Open End-to-End Voice and Vision Personal Assistant and Its Implications for Future Warehouse Scale Computers
 Sirius: An Open End-to-End Voice and Vision Personal Assistant and Its Implications for Future Warehouse Scale Computers Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Cheng Li, Austin Rovinski,
Sirius: An Open End-to-End Voice and Vision Personal Assistant and Its Implications for Future Warehouse Scale Computers Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Cheng Li, Austin Rovinski,
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on
 A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
Deep Learning on Arm Cortex-M Microcontrollers. Rod Crawford Director Software Technologies, Arm
 Deep Learning on Arm Cortex-M Microcontrollers Rod Crawford Director Software Technologies, Arm What is Machine Learning (ML)? Artificial Intelligence Machine Learning Deep Learning Neural Networks Additional
Deep Learning on Arm Cortex-M Microcontrollers Rod Crawford Director Software Technologies, Arm What is Machine Learning (ML)? Artificial Intelligence Machine Learning Deep Learning Neural Networks Additional
Vertex Shader Design I
 The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This course used only
The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This course used only
Toward a Memory-centric Architecture
 Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Bringing Intelligence to Enterprise Storage Drives
 Bringing Intelligence to Enterprise Storage Drives Neil Werdmuller Director Storage Solutions Arm Santa Clara, CA 1 Who am I? 28 years experience in embedded Lead the storage solutions team Work closely
Bringing Intelligence to Enterprise Storage Drives Neil Werdmuller Director Storage Solutions Arm Santa Clara, CA 1 Who am I? 28 years experience in embedded Lead the storage solutions team Work closely
TEXAS INSTRUMENTS DEEP LEARNING (TIDL) GOES HERE FOR SITARA PROCESSORS GOES HERE
 GOES HERE FOR SITARA PROCESSORS GOES HERE") YOUR TEXAS INSTRUMENTS VIDEO TITLE DEEP LEARNING (TIDL) GOES HERE FOR SITARA PROCESSORS OVERVIEW THE SUBTITLE GOES HERE Texas Instruments Deep Learning (TIDL) for Sitara Processors Overview Texas Instruments
YOUR TEXAS INSTRUMENTS VIDEO TITLE DEEP LEARNING (TIDL) GOES HERE FOR SITARA PROCESSORS OVERVIEW THE SUBTITLE GOES HERE Texas Instruments Deep Learning (TIDL) for Sitara Processors Overview Texas Instruments
May Wu, Ravi Iyer, Yatin Hoskote, Steven Zhang, Julio Zamora, German Fabila, Ilya Klotchkov, Mukesh Bhartiya. August, 2015
 May Wu, Ravi Iyer, Yatin Hoskote, Steven Zhang, Julio Zamora, German Fabila, Ilya Klotchkov, Mukesh Bhartiya August, 2015 Legal Notices and Disclaimers Intel technologies may require enabled hardware,
May Wu, Ravi Iyer, Yatin Hoskote, Steven Zhang, Julio Zamora, German Fabila, Ilya Klotchkov, Mukesh Bhartiya August, 2015 Legal Notices and Disclaimers Intel technologies may require enabled hardware,
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
Hidden Markov Models. Gabriela Tavares and Juri Minxha Mentor: Taehwan Kim CS159 04/25/2017
 Hidden Markov Models Gabriela Tavares and Juri Minxha Mentor: Taehwan Kim CS159 04/25/2017 1 Outline 1. 2. 3. 4. Brief review of HMMs Hidden Markov Support Vector Machines Large Margin Hidden Markov Models
Hidden Markov Models Gabriela Tavares and Juri Minxha Mentor: Taehwan Kim CS159 04/25/2017 1 Outline 1. 2. 3. 4. Brief review of HMMs Hidden Markov Support Vector Machines Large Margin Hidden Markov Models
Characterization of Speech Recognition Systems on GPU Architectures
 Facultat d Informàtica de Barcelona Master in Innovation and Research in Informatics High Performance Computing Master Thesis Characterization of Speech Recognition Systems on GPU Architectures Author:
Facultat d Informàtica de Barcelona Master in Innovation and Research in Informatics High Performance Computing Master Thesis Characterization of Speech Recognition Systems on GPU Architectures Author:
BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques
 BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques Jingyang Zhu 1, Zhiliang Qian 2*, and Chi-Ying Tsui 1 1 The Hong Kong University of Science and
BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques Jingyang Zhu 1, Zhiliang Qian 2*, and Chi-Ying Tsui 1 1 The Hong Kong University of Science and
GPU Accelerated Model Combination for Robust Speech Recognition and Keyword Search
 GPU Accelerated Model Combination for Robust Speech Recognition and Keyword Search Wonkyum Lee Jungsuk Kim Ian Lane Electrical and Computer Engineering Carnegie Mellon University March 26, 2014 @GTC2014
GPU Accelerated Model Combination for Robust Speech Recognition and Keyword Search Wonkyum Lee Jungsuk Kim Ian Lane Electrical and Computer Engineering Carnegie Mellon University March 26, 2014 @GTC2014
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory
 TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
Index. Springer Nature Switzerland AG 2019 B. Moons et al., Embedded Deep Learning,
 Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Why DNN Works for Speech and How to Make it More Efficient?
 Why DNN Works for Speech and How to Make it More Efficient? Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering, York University, CANADA Joint work with Y.
Why DNN Works for Speech and How to Make it More Efficient? Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering, York University, CANADA Joint work with Y.
An introduction to Machine Learning silicon
 An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
SVD-based Universal DNN Modeling for Multiple Scenarios
 SVD-based Universal DNN Modeling for Multiple Scenarios Changliang Liu 1, Jinyu Li 2, Yifan Gong 2 1 Microsoft Search echnology Center Asia, Beijing, China 2 Microsoft Corporation, One Microsoft Way, Redmond,
SVD-based Universal DNN Modeling for Multiple Scenarios Changliang Liu 1, Jinyu Li 2, Yifan Gong 2 1 Microsoft Search echnology Center Asia, Beijing, China 2 Microsoft Corporation, One Microsoft Way, Redmond,
Variable-Component Deep Neural Network for Robust Speech Recognition
 Variable-Component Deep Neural Network for Robust Speech Recognition Rui Zhao 1, Jinyu Li 2, and Yifan Gong 2 1 Microsoft Search Technology Center Asia, Beijing, China 2 Microsoft Corporation, One Microsoft
Variable-Component Deep Neural Network for Robust Speech Recognition Rui Zhao 1, Jinyu Li 2, and Yifan Gong 2 1 Microsoft Search Technology Center Asia, Beijing, China 2 Microsoft Corporation, One Microsoft
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System
 Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Digital system (SoC) design for lowcomplexity. Hyun Kim
 design for lowcomplexity. Hyun Kim") Digital system (SoC) design for lowcomplexity multimedia processing Hyun Kim SoC Design for Multimedia Systems Goal : Reducing computational complexity & power consumption of state-ofthe-art technologies
Digital system (SoC) design for lowcomplexity multimedia processing Hyun Kim SoC Design for Multimedia Systems Goal : Reducing computational complexity & power consumption of state-ofthe-art technologies
PicoServer : Using 3D Stacking Technology To Enable A Compact Energy Efficient Chip Multiprocessor
 PicoServer : Using 3D Stacking Technology To Enable A Compact Energy Efficient Chip Multiprocessor Taeho Kgil, Shaun D Souza, Ali Saidi, Nathan Binkert, Ronald Dreslinski, Steve Reinhardt, Krisztian Flautner,
PicoServer : Using 3D Stacking Technology To Enable A Compact Energy Efficient Chip Multiprocessor Taeho Kgil, Shaun D Souza, Ali Saidi, Nathan Binkert, Ronald Dreslinski, Steve Reinhardt, Krisztian Flautner,
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
COL862 - Low Power Computing
 COL862 - Low Power Computing Power Measurements using performance counters and studying the low power computing techniques in IoT development board (PSoC 4 BLE Pioneer Kit) and Arduino Mega 2560 Submitted
COL862 - Low Power Computing Power Measurements using performance counters and studying the low power computing techniques in IoT development board (PSoC 4 BLE Pioneer Kit) and Arduino Mega 2560 Submitted
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design
 Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Memory technology and optimizations ( 2.3) Main Memory
 Main Memory") Memory technology and optimizations ( 2.3) 47 Main Memory Performance of Main Memory: Latency: affects Cache Miss Penalty» Access Time: time between request and word arrival» Cycle Time: minimum time between
Memory technology and optimizations ( 2.3) 47 Main Memory Performance of Main Memory: Latency: affects Cache Miss Penalty» Access Time: time between request and word arrival» Cycle Time: minimum time between
Last Time. Making correct concurrent programs. Maintaining invariants Avoiding deadlocks
 Last Time Making correct concurrent programs Maintaining invariants Avoiding deadlocks Today Power management Hardware capabilities Software management strategies Power and Energy Review Energy is power
Last Time Making correct concurrent programs Maintaining invariants Avoiding deadlocks Today Power management Hardware capabilities Software management strategies Power and Energy Review Energy is power
The Long-Term Future of Solid State Storage Jim Handy Objective Analysis
 The Long-Term Future of Solid State Storage Jim Handy Objective Analysis Agenda How did we get here? Why it s suboptimal How we move ahead Why now? DRAM speed scaling Changing role of NVM in computing
The Long-Term Future of Solid State Storage Jim Handy Objective Analysis Agenda How did we get here? Why it s suboptimal How we move ahead Why now? DRAM speed scaling Changing role of NVM in computing
Computer Architectures for Deep Learning. Ethan Dell and Daniyal Iqbal
 Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Lucida Sirius and DjiNN Tutorial
 Lucida Sirius and DjiNN Tutorial Speakers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang Organizers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Lingjia Tang, Jason Mars Before We Begin
Lucida Sirius and DjiNN Tutorial Speakers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang Organizers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Lingjia Tang, Jason Mars Before We Begin
Smart Ultra-Low Power Visual Sensing
 Smart Ultra-Low Power Visual Sensing Manuele Rusci*, Francesco Conti * manuele.rusci@unibo.it f.conti@unibo.it Energy-Efficient Embedded Systems Laboratory Dipartimento di Ingegneria dell Energia Elettrica
Smart Ultra-Low Power Visual Sensing Manuele Rusci*, Francesco Conti * manuele.rusci@unibo.it f.conti@unibo.it Energy-Efficient Embedded Systems Laboratory Dipartimento di Ingegneria dell Energia Elettrica
Bringing Intelligence to Enterprise Storage Drives
 Bringing Intelligence to Enterprise Storage Drives Neil Werdmuller Director Storage Solutions Arm Santa Clara, CA 1 Who am I? 28 years experience in embedded Lead the storage solutions team Work closely
Bringing Intelligence to Enterprise Storage Drives Neil Werdmuller Director Storage Solutions Arm Santa Clara, CA 1 Who am I? 28 years experience in embedded Lead the storage solutions team Work closely
Mohsen Imani. University of California San Diego. System Energy Efficiency Lab seelab.ucsd.edu
 Mohsen Imani University of California San Diego Winter 2016 Technology Trend for IoT http://www.flashmemorysummit.com/english/collaterals/proceedi ngs/2014/20140807_304c_hill.pdf 2 Motivation IoT significantly
Mohsen Imani University of California San Diego Winter 2016 Technology Trend for IoT http://www.flashmemorysummit.com/english/collaterals/proceedi ngs/2014/20140807_304c_hill.pdf 2 Motivation IoT significantly
Data Organization and Processing
 Data Organization and Processing Indexing Techniques for Solid State Drives (NDBI007) David Hoksza http://siret.ms.mff.cuni.cz/hoksza Outline SSD technology overview Motivation for standard algorithms
Data Organization and Processing Indexing Techniques for Solid State Drives (NDBI007) David Hoksza http://siret.ms.mff.cuni.cz/hoksza Outline SSD technology overview Motivation for standard algorithms
In Silico Vox: Towards Speech Recognition in Silicon
 In Silico Vox: Towards Speech Recognition in Silicon Edward C Lin, Kai Yu, Rob A Rutenbar, Tsuhan Chen Electrical & Computer Engineering {eclin, kaiy, rutenbar, tsuhan}@ececmuedu RA Rutenbar 2006 Speech
In Silico Vox: Towards Speech Recognition in Silicon Edward C Lin, Kai Yu, Rob A Rutenbar, Tsuhan Chen Electrical & Computer Engineering {eclin, kaiy, rutenbar, tsuhan}@ececmuedu RA Rutenbar 2006 Speech
How to Estimate the Energy Consumption of Deep Neural Networks
 How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
Recurrent Neural Networks. Deep neural networks have enabled major advances in machine learning and AI. Convolutional Neural Networks
 Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep Learning Performance and Cost Evaluation
 Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Rene Meyer, Ph.D. AMAX Corporation Publish date: October 25, 2018 Abstract Introduction
Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Rene Meyer, Ph.D. AMAX Corporation Publish date: October 25, 2018 Abstract Introduction
Speech Technology Using in Wechat
 Speech Technology Using in Wechat FENG RAO Powered by WeChat Outline Introduce Algorithm of Speech Recognition Acoustic Model Language Model Decoder Speech Technology Open Platform Framework of Speech
Speech Technology Using in Wechat FENG RAO Powered by WeChat Outline Introduce Algorithm of Speech Recognition Acoustic Model Language Model Decoder Speech Technology Open Platform Framework of Speech
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
How to Build Optimized ML Applications with Arm Software
 How to Build Optimized ML Applications with Arm Software Arm Technical Symposia 2018 ML Group Overview Today we will talk about applied machine learning (ML) on Arm. My aim for today is to show you just
How to Build Optimized ML Applications with Arm Software Arm Technical Symposia 2018 ML Group Overview Today we will talk about applied machine learning (ML) on Arm. My aim for today is to show you just
FABRICATION TECHNOLOGIES
 FABRICATION TECHNOLOGIES DSP Processor Design Approaches Full custom Standard cell** higher performance lower energy (power) lower per-part cost Gate array* FPGA* Programmable DSP Programmable general
FABRICATION TECHNOLOGIES DSP Processor Design Approaches Full custom Standard cell** higher performance lower energy (power) lower per-part cost Gate array* FPGA* Programmable DSP Programmable general
S2C K7 Prodigy Logic Module Series
 S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
High-Speed NAND Flash
 High-Speed NAND Flash Design Considerations to Maximize Performance Presented by: Robert Pierce Sr. Director, NAND Flash Denali Software, Inc. History of NAND Bandwidth Trend MB/s 20 60 80 100 200 The
High-Speed NAND Flash Design Considerations to Maximize Performance Presented by: Robert Pierce Sr. Director, NAND Flash Denali Software, Inc. History of NAND Bandwidth Trend MB/s 20 60 80 100 200 The
1. NoCs: What s the point?
 1. Nos: What s the point? What is the role of networks-on-chip in future many-core systems? What topologies are most promising for performance? What about for energy scaling? How heavily utilized are Nos
1. Nos: What s the point? What is the role of networks-on-chip in future many-core systems? What topologies are most promising for performance? What about for energy scaling? How heavily utilized are Nos
PBLN52832 DataSheet V Copyright c 2017 Prochild.
 PBLN52832 DataSheet V1.2.3 Copyright c 2017 Prochild. No part of this publication and modification may be reproduced without the prior written permission of the author. Revision History No Version Date
PBLN52832 DataSheet V1.2.3 Copyright c 2017 Prochild. No part of this publication and modification may be reproduced without the prior written permission of the author. Revision History No Version Date
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
A Lightweight YOLOv2:
 FPGA2018 @Monterey A Lightweight YOLOv2: A Binarized CNN with a Parallel Support Vector Regression for an FPGA Hiroki Nakahara, Haruyoshi Yonekawa, Tomoya Fujii, Shimpei Sato Tokyo Institute of Technology,
FPGA2018 @Monterey A Lightweight YOLOv2: A Binarized CNN with a Parallel Support Vector Regression for an FPGA Hiroki Nakahara, Haruyoshi Yonekawa, Tomoya Fujii, Shimpei Sato Tokyo Institute of Technology,
Monolithic 3D IC Design for Deep Neural Networks
 Monolithic 3D IC Design for Deep Neural Networks 1 with Application on Low-power Speech Recognition Kyungwook Chang 1, Deepak Kadetotad 2, Yu (Kevin) Cao 2, Jae-sun Seo 2, and Sung Kyu Lim 1 1 School of
Monolithic 3D IC Design for Deep Neural Networks 1 with Application on Low-power Speech Recognition Kyungwook Chang 1, Deepak Kadetotad 2, Yu (Kevin) Cao 2, Jae-sun Seo 2, and Sung Kyu Lim 1 1 School of
Overview. Memory Classification Read-Only Memory (ROM) Random Access Memory (RAM) Functional Behavior of RAM. Implementing Static RAM
 Random Access Memory (RAM) Functional Behavior of RAM. Implementing Static RAM") Memories Overview Memory Classification Read-Only Memory (ROM) Types of ROM PROM, EPROM, E 2 PROM Flash ROMs (Compact Flash, Secure Digital, Memory Stick) Random Access Memory (RAM) Types of RAM Static
Memories Overview Memory Classification Read-Only Memory (ROM) Types of ROM PROM, EPROM, E 2 PROM Flash ROMs (Compact Flash, Secure Digital, Memory Stick) Random Access Memory (RAM) Types of RAM Static
TECHNOLOGY BRIEF. Compaq 8-Way Multiprocessing Architecture EXECUTIVE OVERVIEW CONTENTS
 TECHNOLOGY BRIEF March 1999 Compaq Computer Corporation ISSD Technology Communications CONTENTS Executive Overview1 Notice2 Introduction 3 8-Way Architecture Overview 3 Processor and I/O Bus Design 4 Processor
TECHNOLOGY BRIEF March 1999 Compaq Computer Corporation ISSD Technology Communications CONTENTS Executive Overview1 Notice2 Introduction 3 8-Way Architecture Overview 3 Processor and I/O Bus Design 4 Processor
Open-Source Speech Recognition for Hand-held and Embedded Devices
 PocketSphinx: Open-Source Speech Recognition for Hand-held and Embedded Devices David Huggins Daines (dhuggins@cs.cmu.edu) Mohit Kumar (mohitkum@cs.cmu.edu) Arthur Chan (archan@cs.cmu.edu) Alan W Black
PocketSphinx: Open-Source Speech Recognition for Hand-held and Embedded Devices David Huggins Daines (dhuggins@cs.cmu.edu) Mohit Kumar (mohitkum@cs.cmu.edu) Arthur Chan (archan@cs.cmu.edu) Alan W Black
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks
 Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Data Parallel Architectures
 EE392C: Advanced Topics in Computer Architecture Lecture #2 Chip Multiprocessors and Polymorphic Processors Thursday, April 3 rd, 2003 Data Parallel Architectures Lecture #2: Thursday, April 3 rd, 2003
EE392C: Advanced Topics in Computer Architecture Lecture #2 Chip Multiprocessors and Polymorphic Processors Thursday, April 3 rd, 2003 Data Parallel Architectures Lecture #2: Thursday, April 3 rd, 2003
DEEP LEARNING ACCELERATOR UNIT WITH HIGH EFFICIENCY ON FPGA
 DEEP LEARNING ACCELERATOR UNIT WITH HIGH EFFICIENCY ON FPGA J.Jayalakshmi 1, S.Ali Asgar 2, V.Thrimurthulu 3 1 M.tech Student, Department of ECE, Chadalawada Ramanamma Engineering College, Tirupati Email
DEEP LEARNING ACCELERATOR UNIT WITH HIGH EFFICIENCY ON FPGA J.Jayalakshmi 1, S.Ali Asgar 2, V.Thrimurthulu 3 1 M.tech Student, Department of ECE, Chadalawada Ramanamma Engineering College, Tirupati Email
New STM32 F7 Series. World s 1 st to market, ARM Cortex -M7 based 32-bit MCU
 New STM32 F7 Series World s 1 st to market, ARM Cortex -M7 based 32-bit MCU 7 Keys of STM32 F7 series 2 1 2 3 4 5 6 7 First. ST is first to sample a fully functional Cortex-M7 based 32-bit MCU : STM32
New STM32 F7 Series World s 1 st to market, ARM Cortex -M7 based 32-bit MCU 7 Keys of STM32 F7 series 2 1 2 3 4 5 6 7 First. ST is first to sample a fully functional Cortex-M7 based 32-bit MCU : STM32
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications
 A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
M.Tech Student, Department of ECE, S.V. College of Engineering, Tirupati, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 5 ISSN : 2456-3307 High Performance Scalable Deep Learning Accelerator
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 5 ISSN : 2456-3307 High Performance Scalable Deep Learning Accelerator
AI Requires Many Approaches
 By Linley Gwennap Principal Analyst July 2018 www.linleygroup.com By Linley Gwennap, Principal Analyst, The Linley Group Artificial intelligence (AI) is being applied to a wide range of problems, so no
By Linley Gwennap Principal Analyst July 2018 www.linleygroup.com By Linley Gwennap, Principal Analyst, The Linley Group Artificial intelligence (AI) is being applied to a wide range of problems, so no
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
 Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Simplify System Complexity
 Simplify System Complexity With the new high-performance CompactRIO controller Fanie Coetzer Field Sales Engineer Northern South Africa 2 3 New control system CompactPCI MMI/Sequencing/Logging FieldPoint
Simplify System Complexity With the new high-performance CompactRIO controller Fanie Coetzer Field Sales Engineer Northern South Africa 2 3 New control system CompactPCI MMI/Sequencing/Logging FieldPoint
PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in ReRAM-based Main Memory
 Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM. Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive)
 & Yunsup Lee (SiFive)") NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive) NVDLA NVIDIA DEEP LEARNING ACCELERATOR IP Core for deep learning part of NVIDIA s Xavier
NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive) NVDLA NVIDIA DEEP LEARNING ACCELERATOR IP Core for deep learning part of NVIDIA s Xavier
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
How to Build Optimized ML Applications with Arm Software
 How to Build Optimized ML Applications with Arm Software Arm Technical Symposia 2018 Arm K.K. Senior FAE Ryuji Tanaka Overview Today we will talk about applied machine learning (ML) on Arm. My aim for
How to Build Optimized ML Applications with Arm Software Arm Technical Symposia 2018 Arm K.K. Senior FAE Ryuji Tanaka Overview Today we will talk about applied machine learning (ML) on Arm. My aim for
ARDUINO MEGA INTRODUCTION
 ARDUINO MEGA INTRODUCTION The Arduino MEGA 2560 is designed for projects that require more I/O llines, more sketch memory and more RAM. With 54 digital I/O pins, 16 analog inputs so it is suitable for
ARDUINO MEGA INTRODUCTION The Arduino MEGA 2560 is designed for projects that require more I/O llines, more sketch memory and more RAM. With 54 digital I/O pins, 16 analog inputs so it is suitable for
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Simplify System Complexity
 1 2 Simplify System Complexity With the new high-performance CompactRIO controller Arun Veeramani Senior Program Manager National Instruments NI CompactRIO The Worlds Only Software Designed Controller
1 2 Simplify System Complexity With the new high-performance CompactRIO controller Arun Veeramani Senior Program Manager National Instruments NI CompactRIO The Worlds Only Software Designed Controller
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery
 Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery Achuth Rao MV, Prasanta Kumar Ghosh SPIRE LAB Electrical Engineering, Indian Institute of Science (IISc), Bangalore,
Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery Achuth Rao MV, Prasanta Kumar Ghosh SPIRE LAB Electrical Engineering, Indian Institute of Science (IISc), Bangalore,
AT-501 Cortex-A5 System On Module Product Brief
 AT-501 Cortex-A5 System On Module Product Brief 1. Scope The following document provides a brief description of the AT-501 System on Module (SOM) its features and ordering options. For more details please
AT-501 Cortex-A5 System On Module Product Brief 1. Scope The following document provides a brief description of the AT-501 System on Module (SOM) its features and ordering options. For more details please
Towards Energy-Proportional Datacenter Memory with Mobile DRAM
 Towards Energy-Proportional Datacenter Memory with Mobile DRAM Krishna Malladi 1 Frank Nothaft 1 Karthika Periyathambi Benjamin Lee 2 Christos Kozyrakis 1 Mark Horowitz 1 Stanford University 1 Duke University
Towards Energy-Proportional Datacenter Memory with Mobile DRAM Krishna Malladi 1 Frank Nothaft 1 Karthika Periyathambi Benjamin Lee 2 Christos Kozyrakis 1 Mark Horowitz 1 Stanford University 1 Duke University
Computer Systems Colloquium (EE380) Wednesday, 4:15-5:30PM 5:30PM in Gates B01
 Wednesday, 4:15-5:30PM 5:30PM in Gates B01") Adapting Systems by Evolving Hardware Computer Systems Colloquium (EE380) Wednesday, 4:15-5:30PM 5:30PM in Gates B01 Jim Torresen Group Department of Informatics University of Oslo, Norway E-mail: jimtoer@ifi.uio.no
Adapting Systems by Evolving Hardware Computer Systems Colloquium (EE380) Wednesday, 4:15-5:30PM 5:30PM in Gates B01 Jim Torresen Group Department of Informatics University of Oslo, Norway E-mail: jimtoer@ifi.uio.no
SOUND EVENT DETECTION AND CONTEXT RECOGNITION 1 INTRODUCTION. Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2
 Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
Maximizing Server Efficiency from μarch to ML accelerators. Michael Ferdman
 Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Developing a Data Driven System for Computational Neuroscience
 Developing a Data Driven System for Computational Neuroscience Ross Snider and Yongming Zhu Montana State University, Bozeman MT 59717, USA Abstract. A data driven system implies the need to integrate
Developing a Data Driven System for Computational Neuroscience Ross Snider and Yongming Zhu Montana State University, Bozeman MT 59717, USA Abstract. A data driven system implies the need to integrate
REAL TIME DIGITAL SIGNAL PROCESSING
 REAL TIME DIGITAL SIGNAL PROCESSING UTN-FRBA 2010 Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable. Reproducibility. Don t depend on components
REAL TIME DIGITAL SIGNAL PROCESSING UTN-FRBA 2010 Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable. Reproducibility. Don t depend on components
Near-Data Processing for Differentiable Machine Learning Models
 Near-Data Processing for Differentiable Machine Learning Models Hyeokjun Choe 1, Seil Lee 1, Hyunha Nam 1, Seongsik Park 1, Seijoon Kim 1, Eui-Young Chung 2 and Sungroh Yoon 1,3 1 Electrical and Computer
Near-Data Processing for Differentiable Machine Learning Models Hyeokjun Choe 1, Seil Lee 1, Hyunha Nam 1, Seongsik Park 1, Seijoon Kim 1, Eui-Young Chung 2 and Sungroh Yoon 1,3 1 Electrical and Computer
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
In Silico Vox: Towards Speech Recognition in Silicon
 In Silico Vox: Towards Speech Recognition in Silicon Edward C Lin, Kai Yu, Rob A Rutenbar, Tsuhan Chen Electrical & Computer Engineering {eclin, kaiy, rutenbar, tsuhan}@ececmuedu RA Rutenbar 006 Speech
In Silico Vox: Towards Speech Recognition in Silicon Edward C Lin, Kai Yu, Rob A Rutenbar, Tsuhan Chen Electrical & Computer Engineering {eclin, kaiy, rutenbar, tsuhan}@ececmuedu RA Rutenbar 006 Speech
Pharmacy college.. Assist.Prof. Dr. Abdullah A. Abdullah
 The kinds of memory:- 1. RAM(Random Access Memory):- The main memory in the computer, it s the location where data and programs are stored (temporally). RAM is volatile means that the data is only there
The kinds of memory:- 1. RAM(Random Access Memory):- The main memory in the computer, it s the location where data and programs are stored (temporally). RAM is volatile means that the data is only there
Zynq-7000 All Programmable SoC Product Overview
 Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
2D/3D Graphics Accelerator for Mobile Multimedia Applications. Ramchan Woo, Sohn, Seong-Jun Song, Young-Don
 RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection
 An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
Chapter 2 Designing Crossbar Based Systems
 Chapter 2 Designing Crossbar Based Systems Over the last decade, the communication architecture of SoCs has evolved from single shared bus systems to multi-bus systems. Today, state-of-the-art bus based
Chapter 2 Designing Crossbar Based Systems Over the last decade, the communication architecture of SoCs has evolved from single shared bus systems to multi-bus systems. Today, state-of-the-art bus based
Implementation of DSP Algorithms
 Implementation of DSP Algorithms Main frame computers Dedicated (application specific) architectures Programmable digital signal processors voice band data modem speech codec 1 PDSP and General-Purpose
Implementation of DSP Algorithms Main frame computers Dedicated (application specific) architectures Programmable digital signal processors voice band data modem speech codec 1 PDSP and General-Purpose