OpenCAPI Technology. Myron Slota Speaker name, Title OpenCAPI Consortium Company/Organization Name. Join the Conversation #OpenPOWERSummit
|
|
|
- Marshall Webb
- 6 years ago
- Views:
Transcription

1 OpenCAPI Technology Myron Slota Speaker name, Title OpenCAPI Consortium Company/Organization Name Join the Conversation #OpenPOWERSummit

2 Industry Collaboration and Innovation
3 OpenCAPI Topics Computation Data Access Industry Background Where/How OpenCAPI Technology is used Technology Overview and Advantages Demonstrations OpenCAPI Consortium Where it all Happens Key Messages Throughout Open IO Standard High Performance No OS/Hypervisor/FW Overhead with Low Latency and High Bandwidth Not tied to Power Architecture Agnostic Very Low Accelerator Design Overhead Programing Ease Ideal for Accelerated Computing and SCM Supports heterogeneous environment Use Cases Optimized for within a single system node Products exist today!
4 Industry Background that Defined OpenCAPI Growing computational demand due to emerging workloads (e.g., AI, cognitive, etc.) Moore s Law not being supported by traditional silicon scaling Computation Driving increased dependence on Hardware Acceleration for performance Hyperscale Datacenters and HPC need much higher network bandwidth 100 Gb/s -> 200 Gb/s -> 400Gb/s are emerging Deep learning and HPC require more bandwidth between accelerators and memory Emerging memory/storage technologies are driving need for bandwidth with low latency Data Access Hardware accelerators are defining the attributes of a high performance bus Growing demand for network performance and network offload Introduction of device coherency requirements (IBM s introduction in 2013) Emergence of complex storage and memory solutions Various form factors with no one able to address everything (e.g., GPUs, FPGAs, ASICs, etc.) 4 all Relevant to Modern Data Centers
5 Use Cases - A True Heterogeneous Architecture Built Upon OpenCAPI OpenCAPI 3.0 OpenCAPI specifications are downloadable from the website at - Register - Download OpenCAPI 3.1


6 Buffered System Memory OpenCAPI Memory Buffers OpenCAPI Key Attributes Standard System Memory Advanced SCM Solutions Storage/Compute/Network etc ASIC/FPGA/FFSA FPGA, SOC, GPU Accelerator Load/Store or Block Access Caches Accelerated OpenCAPI Device Device Memory TLx/DLx U Accelerated Function TL/DL 25Gb I/O Application Any OpenCAPI Enabled Processor 1. Architecture agnostic bus Applicable with any system/microprocessor architecture 2. Optimized for High Bandwidth and Low Latency 3. High performance 25Gbps PHY design with zero overhead 4. Coherency - Attached devices operate natively within application s user space and coherently with host microprocessor 5. Virtual addressing enables low overhead with no Kernel, hypervisor or firmware involvement 6. Wide range of Use Cases and access semantics 7. CPU coherent device memory (Home Agent Memory) 8. Architected for both Classic Memory and emerging Advanced Storage Class Memory 9. Minimal OpenCAPI design overhead (FPGA less than 5%) 6
7 POWER9 IO Features POWER9 IO Leading the Industry PCIe Gen4 CAPI 2.0 (Power) NVLink 2.0 OpenCAPI 3.0 POWER9 Silicon Die Various packages (scale-out, scale-up) 8 and 16Gbps PHY Protocols Supported PCIe Gen3 x16 and PCIe Gen4 x8 CAPI 2.0 on PCIe Gen4 PCIe Gen4 P9 25Gbs 25Gbps PHY Protocols Supported OpenCAPI 3.0 NVLink 2.0
8 Virtual Addressing and Benefits An OpenCAPI device operates in the virtual address spaces of the applications that it supports Eliminates kernel and device driver software overhead Allows device to operate on application memory without kernel-level data copies/pinned pages Simplifies programming effort to integrate accelerators into applications Improves accelerator performance The Virtual-to-Physical Address Translation occurs in the host CPU Reduces design complexity of OpenCAPI-attached devices Makes it easier to ensure interoperability between OpenCAPI devices and different CPU architectures Security - Since the OpenCAPI device never has access to a physical address, this eliminates the possibility of a defective or malicious device accessing memory locations belonging to the kernel or other applications that it is not authorized to access
9 Acc Acceleration Paradigms with Great Performance Memory Transform Processor Chip Example: Basic work offload DLx/TLx Data Acc OpenCAPI is ideal for acceleration due to Bandwidth to/from accelerators, best of breed latency, and flexibility of an Open architecture Examples: Machine or Deep Learning such as Natural Language processing, sentiment analysis or other Actionable Intelligence using OpenCAPI attached memory Egress Transform Ingress Transform Acc Acc Processor Chip DLx/TLx Data Processor Chip DLx/TLx Data Examples: Encryption, Compression, Erasure prior to delivering data to the network or storage Needle-in-a-haystack Needle-In-A-Haystack Engine Engine Processor Chip DLx/TLx Needles Examples: Database searches, joins, intersections, merges Only the Needles are sent to the processor Large Haystack Of Data Examples: Video Analytics, Network Security, Deep Packet Inspection, Data Plane Accelerator, Video Encoding (H.265), High Frequency Trading etc Bi-Directional Transform Processor Chip DLx/TLx Data Acc Acc Examples: NoSQL such as Neo4J with Graph Node Traversals, etc 9
10 Comparison of Memory Paradigms Common physical interface between non-memory and memory devices OpenCAPI protocol was architected to minimize latency; excellent for classic DRAM memory Extreme bandwidth beyond classical DDR memory interface Agnostic interface will handle evolving memory technologies in the future (e.g., compute-in-mem) Ability to handle a memory buffer to decouple raw memory and host interface to optimize power, cost, perf Main Memory Example: Basic DDR attach Processor Chip DLx/TLx Data DDR4/5 OpenCAPI 3.1 Architecture Ultra Low Latency ASIC buffer chip adding +5ns on top of native DDR direct connect!! Emerging Storage Class Memory Processor Chip DLx/TLx Data SCM Storage Class Memories have the potential to be the next disruptive technology.. Examples include ReRAM, MRAM, Z-NAND All are racing to become the defacto Tiered Memory Processor Chip DLx/TLx Data DDR4/5 DLx/TLx Data SCM Storage Class Memory tiered with traditional DDR Memory all built upon OpenCAPI 3.1 & 3.0 architecture. Still have the ability to use Load/Store Semantics

11 CAPI and OpenCAPI Performance 128B DMA Read 128B DMA Write 256B DMA Read 256B DMA Write CAPI 1.0 PCIE Gen3 x8 Measured CAPI 2.0 PCIE Gen4 x8 Measured OpenCAPI Gb/s x8 Measured 3.81 GB/s GB/s 22.1 GB/s 4.16 GB/s GB/s 21.6 GB/s N/A GB/s 22.1 GB/s N/A GB/s 22.0 GB/s POWER8 CAPI 1.0 POWER9 CAPI 2.0 and OpenCAPI 3.0 Xilinx KU60/VU3P FPGA POWER8 Introduced in POWER9 Second Generation POWER9 Open Architecture with a Clean Slate Focused on Bandwidth and Latency





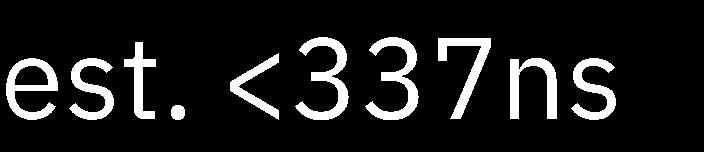










12 Latency Test Results
13 Latency Test Simple workload created to simulate communication between system and attached FPGA 1. Copy 512B from host send buffer to FPGA 2. Host waits for 128 Byte cache injection from FPGA and polls for last 8 bytes 3. Reset last 8 bytes 4. Repeat Go TO 1.



14 OpenCAPI Enabled FPGA Cards Mellanox Innova2 Accelerator Card Alpha Data 9v3 Accelerator Card Typical eye diagram at 25Gb/s using these cards 14


15 Barrel Eye G2 System Demo Actual Barrel Eye G2 demo system Packet Classifier Demonstration using Alpha Data 9v3 Accelerator Card (early classifier bringup at 20 Gb/s)


16 Barrel Eye G2 System Demo Actual Barrel Eye G2 demo system Packet Classifier Demonstration using Mellanox Innova2 Accelerator Card (early classifier bringup at 20 Gb/s)
17 OpenCAPI Consortium Incorporated September 13, 2016 Announced October 14, Open forum founded by AMD, Google, IBM, Mellanox, and Micron Manage the OpenCAPI specification, Establish enablement, Grow the ecosystem Currently over 35 members Consortium now established Established Board of Directors (AMD, Google, IBM, Mellanox Technologies, Micron, NVIDIA, Western Digital, Xilinx) Governing Documents (Bylaws, IPR Policy, Membership) with established Membership Levels Website Technical Steering Committee with Work Group Process established Marketing/Communications Committee Work Groups TL Specification, DL Specification, PHY Signaling, PHY Mechanical, Compliance, and Enablement Creation of additional work groups include: Memory, Software, Accelerator, and more OpenCAPI Specification available on web site, was contributed to consortium as starting point for the Work Groups Design enablement available today (reference designs, documentation, SIM environment, exercisers, etc.)
18 OpenCAPI Design Enablement Item Availability OpenCAPI 3.0 TLx and DLx Reference Xilinx FPGA Designs (RTL and Specifications) Xilinx Vivado Project Build with Memcopy Exerciser Device Discovery and Configuration Specification and RTL AFU Interface Specification Reference Card Design Enablement Specification 25Gbps PHY Signal Specification 25Gbps PHY Mechanical Specification OpenCAPI Simulation Environment (OCSE) Tech Preview Memcopy and Memory Home Agent Exercisers Reference Driver Available Today Today Today Today 2Q18 Today Today Today Today 2Q18 18
19 Membership Entitlement Details Strategic level - $25K Draft and Final Specifications and enablement License for Product development Workgroup participation and voting TSC participation Vote on new Board Members Nominate and/or run for officer election Prominent listing in appropriate materials Contributor level - $15K Draft and Final Specifications and enablement License for Product development Workgroup participation and voting TSC participation Submit proposals Observing level - $5K Final Specifications and enablement License for Product development Academic and Non-Profit level - Free Final Specifications and enablement Workgroup participation and voting





20 Current Members Strategic Membership level Contributor Membership level Observing Membership Level Academic Membership Level 20




21 Cross Industry Collaboration and Innovation Research & Academic SW Deployment Systems and Software Accelerator Solutions SOC OpenCAPI Protocol Products and Services Welcoming new members in all areas of the ecosystem 21
22 OpenCAPI Consortium Next Steps JOIN TODAY! Come see us in the Exhibit Hall OpenCApI BOOth. 5
OpenCAPI and its Roadmap
 OpenCAPI and its Roadmap Myron Slota, President OpenCAPI Speaker name, Consortium Title Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration and Innovation OpenCAPI and
OpenCAPI and its Roadmap Myron Slota, President OpenCAPI Speaker name, Consortium Title Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration and Innovation OpenCAPI and
Industry Collaboration and Innovation
 Industry Collaboration and Innovation Industry Landscape Key changes occurring in our industry Historical microprocessor technology continues to deliver far less than the historical rate of cost/performance
Industry Collaboration and Innovation Industry Landscape Key changes occurring in our industry Historical microprocessor technology continues to deliver far less than the historical rate of cost/performance
Industry Collaboration and Innovation
 Industry Collaboration and Innovation OpenCAPI Topics Industry Background Technology Overview Design Enablement OpenCAPI Consortium Industry Landscape Key changes occurring in our industry Historical microprocessor
Industry Collaboration and Innovation OpenCAPI Topics Industry Background Technology Overview Design Enablement OpenCAPI Consortium Industry Landscape Key changes occurring in our industry Historical microprocessor
Industry Collaboration and Innovation
 Industry Collaboration and Innovation Open Coherent Accelerator Processor Interface OpenCAPI TM - A New Standard for High Performance Memory, Acceleration and Networks Jeff Stuecheli April 10, 2017 What
Industry Collaboration and Innovation Open Coherent Accelerator Processor Interface OpenCAPI TM - A New Standard for High Performance Memory, Acceleration and Networks Jeff Stuecheli April 10, 2017 What
Accelerating Flash Memory with the High Performance, Low Latency, OpenCAPI Interface
 Accelerating Flash Memory with the High Performance, Low Latency, OpenCAPI Interface Allan Cantle, CTO & Founder, Nallatech/Molex Marcy Byers, Processor Development, IBM Nallatech at a Glance Server qualified
Accelerating Flash Memory with the High Performance, Low Latency, OpenCAPI Interface Allan Cantle, CTO & Founder, Nallatech/Molex Marcy Byers, Processor Development, IBM Nallatech at a Glance Server qualified
Introduction to the OpenCAPI Interface
 Introduction to the OpenCAPI Interface Brian Allison, STSM OpenCAPI Technology and Enablement Speaker name, Title Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration
Introduction to the OpenCAPI Interface Brian Allison, STSM OpenCAPI Technology and Enablement Speaker name, Title Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration
New Interconnnects. Moderator: Andy Rudoff, SNIA NVM Programming Technical Work Group and Persistent Memory SW Architect, Intel
 New Interconnnects Moderator: Andy Rudoff, SNIA NVM Programming Technical Work Group and Persistent Memory SW Architect, Intel CCIX: Seamless Data Movement for Accelerated Applications TM Millind Mittal
New Interconnnects Moderator: Andy Rudoff, SNIA NVM Programming Technical Work Group and Persistent Memory SW Architect, Intel CCIX: Seamless Data Movement for Accelerated Applications TM Millind Mittal
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC
 How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
Facilitating IP Development for the OpenCAPI Memory Interface Kevin McIlvain, Memory Development Engineer IBM. Join the Conversation #OpenPOWERSummit
 Facilitating IP Development for the OpenCAPI Memory Interface Kevin McIlvain, Memory Development Engineer IBM Join the Conversation #OpenPOWERSummit Moral of the Story OpenPOWER is the best platform to
Facilitating IP Development for the OpenCAPI Memory Interface Kevin McIlvain, Memory Development Engineer IBM Join the Conversation #OpenPOWERSummit Moral of the Story OpenPOWER is the best platform to
CAPI SNAP framework, the tool for C/C++ programmers to accelerate by a 2 digit factor using FPGA technology
 CAPI SNAP framework, the tool for C/C++ programmers to accelerate by a 2 digit factor using FPGA technology Bruno MESNET, Power CAPI Enablement IBM Power Systems Join the Conversation #OpenPOWERSummit
CAPI SNAP framework, the tool for C/C++ programmers to accelerate by a 2 digit factor using FPGA technology Bruno MESNET, Power CAPI Enablement IBM Power Systems Join the Conversation #OpenPOWERSummit
genzconsortium.org Gen-Z Technology: Enabling Memory Centric Architecture
 Gen-Z Technology: Enabling Memory Centric Architecture Why Gen-Z? Gen-Z Consortium 2017 2 Why Gen-Z? Gen-Z Consortium 2017 3 Why Gen-Z? Businesses Need to Monetize Data Big Data AI Machine Learning Deep
Gen-Z Technology: Enabling Memory Centric Architecture Why Gen-Z? Gen-Z Consortium 2017 2 Why Gen-Z? Gen-Z Consortium 2017 3 Why Gen-Z? Businesses Need to Monetize Data Big Data AI Machine Learning Deep
Maximizing heterogeneous system performance with ARM interconnect and CCIX
 Maximizing heterogeneous system performance with ARM interconnect and CCIX Neil Parris, Director of product marketing Systems and software group, ARM Teratec June 2017 Intelligent flexible cloud to enable
Maximizing heterogeneous system performance with ARM interconnect and CCIX Neil Parris, Director of product marketing Systems and software group, ARM Teratec June 2017 Intelligent flexible cloud to enable
Gen-Z Overview. 1. Introduction. 2. Background. 3. A better way to access data. 4. Why a memory-semantic fabric
 Gen-Z Overview 1. Introduction Gen-Z is a new data access technology that will allow business and technology leaders, to overcome current challenges with the existing computer architecture and provide
Gen-Z Overview 1. Introduction Gen-Z is a new data access technology that will allow business and technology leaders, to overcome current challenges with the existing computer architecture and provide
Hybrid Memory Platform
 Hybrid Memory Platform Kenneth Wright, Sr. Driector Rambus / Emerging Solutions Division Join the Conversation #OpenPOWERSummit 1 Outline The problem / The opportunity Project goals Roadmap - Sub-projects/Tracks
Hybrid Memory Platform Kenneth Wright, Sr. Driector Rambus / Emerging Solutions Division Join the Conversation #OpenPOWERSummit 1 Outline The problem / The opportunity Project goals Roadmap - Sub-projects/Tracks
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
Revolutionizing Open. Cecilia Carniel IBM Power Systems Scale Out sales
 Revolutionizing Open Cecilia Carniel IBM Power Systems Scale Out sales cecilia_carniel@it.ibm.com Copyright IBM Corporation 2015 Technical University/Symposia materials may not be reproduced in whole or
Revolutionizing Open Cecilia Carniel IBM Power Systems Scale Out sales cecilia_carniel@it.ibm.com Copyright IBM Corporation 2015 Technical University/Symposia materials may not be reproduced in whole or
OCP Engineering Workshop - Telco
 OCP Engineering Workshop - Telco Low Latency Mobile Edge Computing Trevor Hiatt Product Management, IDT IDT Company Overview Founded 1980 Workforce Approximately 1,800 employees Headquarters San Jose,
OCP Engineering Workshop - Telco Low Latency Mobile Edge Computing Trevor Hiatt Product Management, IDT IDT Company Overview Founded 1980 Workforce Approximately 1,800 employees Headquarters San Jose,
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Toward a Memory-centric Architecture
 Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
GEN-Z AN OVERVIEW AND USE CASES
 13 th ANNUAL WORKSHOP 2017 GEN-Z AN OVERVIEW AND USE CASES Greg Casey, Senior Architect and Strategist Server CTO Team DellEMC March, 2017 WHY PROPOSE A NEW BUS? System memory is flat or shrinking Memory
13 th ANNUAL WORKSHOP 2017 GEN-Z AN OVERVIEW AND USE CASES Greg Casey, Senior Architect and Strategist Server CTO Team DellEMC March, 2017 WHY PROPOSE A NEW BUS? System memory is flat or shrinking Memory
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
POWER CAPI+SNAP+FPGA,
 POWER CAPI+SNAP+FPGA, the powerful combination to accelerate routines explained through use cases Bruno MESNET, CAPI / OpenCAPI enablement IBM Systems Join the Conversation #OpenPOWERSummit Offload?...CAPI
POWER CAPI+SNAP+FPGA, the powerful combination to accelerate routines explained through use cases Bruno MESNET, CAPI / OpenCAPI enablement IBM Systems Join the Conversation #OpenPOWERSummit Offload?...CAPI
CCIX: a new coherent multichip interconnect for accelerated use cases
 : a new coherent multichip interconnect for accelerated use cases Akira Shimizu Senior Manager, Operator relations Arm 2017 Arm Limited Arm 2017 Interconnects for different scale SoC interconnect. Connectivity
: a new coherent multichip interconnect for accelerated use cases Akira Shimizu Senior Manager, Operator relations Arm 2017 Arm Limited Arm 2017 Interconnects for different scale SoC interconnect. Connectivity
Power Technology For a Smarter Future
 2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Power Technology For a Smarter Future Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation
2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Power Technology For a Smarter Future Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation
Open Innovation with Power8
 2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Open Innovation with Power8 Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation 2013
2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Open Innovation with Power8 Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation 2013
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Gen-Z Memory-Driven Computing
 Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
OpenPOWER Innovations for HPC. IBM Research. IWOPH workshop, ISC, Germany June 21, Christoph Hagleitner,
 IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
Extending RDMA for Persistent Memory over Fabrics. Live Webcast October 25, 2018
 Extending RDMA for Persistent Memory over Fabrics Live Webcast October 25, 2018 Today s Presenters John Kim SNIA NSF Chair Mellanox Tony Hurson Intel Rob Davis Mellanox SNIA-At-A-Glance 3 SNIA Legal Notice
Extending RDMA for Persistent Memory over Fabrics Live Webcast October 25, 2018 Today s Presenters John Kim SNIA NSF Chair Mellanox Tony Hurson Intel Rob Davis Mellanox SNIA-At-A-Glance 3 SNIA Legal Notice
Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation
 Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation Dr. Li Li Distinguished Engineer June 28, 2016 Outline Evolution of Internet The Promise of Internet
Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation Dr. Li Li Distinguished Engineer June 28, 2016 Outline Evolution of Internet The Promise of Internet
Efficient Data Movement in Modern SoC Designs Why It Matters
 WHITE PAPER Efficient Data Movement in Modern SoC Designs Why It Matters COPROCESSORS OFFLOAD AND ACCELERATE SPECIFIC WORKLOADS, HOWEVER DATA MOVEMENT EFFICIENCY ACROSS THE PROCESSING CORES AND MEMORY
WHITE PAPER Efficient Data Movement in Modern SoC Designs Why It Matters COPROCESSORS OFFLOAD AND ACCELERATE SPECIFIC WORKLOADS, HOWEVER DATA MOVEMENT EFFICIENCY ACROSS THE PROCESSING CORES AND MEMORY
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud
 Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud Doug Burger Director, Hardware, Devices, & Experiences MSR NExT November 15, 2015 The Cloud is a Growing Disruptor for HPC Moore s
Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud Doug Burger Director, Hardware, Devices, & Experiences MSR NExT November 15, 2015 The Cloud is a Growing Disruptor for HPC Moore s
Persistent Memory over Fabrics
 Persistent Memory over Fabrics Rob Davis, Mellanox Technologies Chet Douglas, Intel Paul Grun, Cray, Inc Tom Talpey, Microsoft Santa Clara, CA 1 Agenda The Promise of Persistent Memory over Fabrics Driving
Persistent Memory over Fabrics Rob Davis, Mellanox Technologies Chet Douglas, Intel Paul Grun, Cray, Inc Tom Talpey, Microsoft Santa Clara, CA 1 Agenda The Promise of Persistent Memory over Fabrics Driving
Adrian Proctor Vice President, Marketing Viking Technology
 Storage PRESENTATION in the TITLE DIMM GOES HERE Socket Adrian Proctor Vice President, Marketing Viking Technology SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
Storage PRESENTATION in the TITLE DIMM GOES HERE Socket Adrian Proctor Vice President, Marketing Viking Technology SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
CPU Project in Western Digital: From Embedded Cores for Flash Controllers to Vision of Datacenter Processors with Open Interfaces
 CPU Project in Western Digital: From Embedded Cores for Flash Controllers to Vision of Datacenter Processors with Open Interfaces Zvonimir Z. Bandic, Sr. Director Robert Golla, Sr. Fellow Dejan Vucinic,
CPU Project in Western Digital: From Embedded Cores for Flash Controllers to Vision of Datacenter Processors with Open Interfaces Zvonimir Z. Bandic, Sr. Director Robert Golla, Sr. Fellow Dejan Vucinic,
Realizing the Next Generation of Exabyte-scale Persistent Memory-Centric Architectures and Memory Fabrics
 Realizing the Next Generation of Exabyte-scale Persistent Memory-Centric Architectures and Memory Fabrics Zvonimir Z. Bandic, Sr. Director, Next Generation Platform Technologies Western Digital Corporation
Realizing the Next Generation of Exabyte-scale Persistent Memory-Centric Architectures and Memory Fabrics Zvonimir Z. Bandic, Sr. Director, Next Generation Platform Technologies Western Digital Corporation
Université IBM i 2017
 Université IBM i 2017 17 et 18 mai IBM Client Center de Bois-Colombes S24 Architecture IBM POWER: tendances et stratégies Jeudi 18 mai 11h00-12h30 Jean-Luc Bonhommet IBM AGENDA IBM Power Systems - IBM
Université IBM i 2017 17 et 18 mai IBM Client Center de Bois-Colombes S24 Architecture IBM POWER: tendances et stratégies Jeudi 18 mai 11h00-12h30 Jean-Luc Bonhommet IBM AGENDA IBM Power Systems - IBM
A 101 Guide to Heterogeneous, Accelerated, Data Centric Computing Architectures
 A 101 Guide to Heterogeneous, Accelerated, Centric Computing Architectures Allan Cantle President & Founder, Nallatech Join the Conversation #OpenPOWERSummit 2016 OpenPOWER Foundation Buzzword & Acronym
A 101 Guide to Heterogeneous, Accelerated, Centric Computing Architectures Allan Cantle President & Founder, Nallatech Join the Conversation #OpenPOWERSummit 2016 OpenPOWER Foundation Buzzword & Acronym
POWER9 Announcement. Martin Bušek IBM Server Solution Sales Specialist
 POWER9 Announcement Martin Bušek IBM Server Solution Sales Specialist Announce Performance Launch GA 2/13 2/27 3/19 3/20 POWER9 is here!!! The new POWER9 processor ~1TB/s 1 st chip with PCIe4 4GHZ 2x Core
POWER9 Announcement Martin Bušek IBM Server Solution Sales Specialist Announce Performance Launch GA 2/13 2/27 3/19 3/20 POWER9 is here!!! The new POWER9 processor ~1TB/s 1 st chip with PCIe4 4GHZ 2x Core
LinuxCon Japan 2014 OpenPOWER Technical Overview. Jeff Scheel Chief Engineer Linux on Power May 21, IBM Corporation
 LinuxCon Japan 2014 OpenPOWER Technical Overview Jeff Scheel Chief Engineer Linux on Power scheel@us.ibm.com May 21, 2014 Agenda 1. OpenPOWER Foundation Overview 2. OpenPOWER Hardware Technologies 3. OpenPOWER
LinuxCon Japan 2014 OpenPOWER Technical Overview Jeff Scheel Chief Engineer Linux on Power scheel@us.ibm.com May 21, 2014 Agenda 1. OpenPOWER Foundation Overview 2. OpenPOWER Hardware Technologies 3. OpenPOWER
Revolutionizing the Datacenter
 Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
LegUp: Accelerating Memcached on Cloud FPGAs
 0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
Altera SDK for OpenCL
 Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Transprecision Computing
 Transprecision Computing Dionysios Speaker Diamantopoulos name, Title Company/Organization Name IBM Research - Zurich Join the Conversation #OpenPOWERSummit A look into the next 15 years -8x Source: The
Transprecision Computing Dionysios Speaker Diamantopoulos name, Title Company/Organization Name IBM Research - Zurich Join the Conversation #OpenPOWERSummit A look into the next 15 years -8x Source: The
NVM Express Awakening a New Storage and Networking Titan Shaun Walsh G2M Research
 NVM Express Awakening a New Storage and Networking Titan Shaun Walsh G2M Research Acronyms and Definition Check Point Term Definition NVMe Non-Volatile Memory Express NVMe-oF Non-Volatile Memory Express
NVM Express Awakening a New Storage and Networking Titan Shaun Walsh G2M Research Acronyms and Definition Check Point Term Definition NVMe Non-Volatile Memory Express NVMe-oF Non-Volatile Memory Express
This presentation covers Gen Z coherency operations and semantics.
 This presentation covers Gen Z coherency operations and semantics. 1 2 The traditional I/O work queue model is well understood, highly optimized, and pervasive. It will continue to serve the industry for
This presentation covers Gen Z coherency operations and semantics. 1 2 The traditional I/O work queue model is well understood, highly optimized, and pervasive. It will continue to serve the industry for
This presentation provides an overview of Gen Z architecture and its application in multiple use cases.
 This presentation provides an overview of Gen Z architecture and its application in multiple use cases. 1 2 Despite numerous advances in data storage and computation, data access complexity continues to
This presentation provides an overview of Gen Z architecture and its application in multiple use cases. 1 2 Despite numerous advances in data storage and computation, data access complexity continues to
Introducing NVDIMM-X: Designed to be the World s Fastest NAND-Based SSD Architecture and a Platform for the Next Generation of New Media SSDs
 , Inc. Introducing NVDIMM-X: Designed to be the World s Fastest NAND-Based SSD Architecture and a Platform for the Next Generation of New Media SSDs Doug Finke Director of Product Marketing September 2016
, Inc. Introducing NVDIMM-X: Designed to be the World s Fastest NAND-Based SSD Architecture and a Platform for the Next Generation of New Media SSDs Doug Finke Director of Product Marketing September 2016
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Accelerating Data Centers Using NVMe and CUDA
 Accelerating Data Centers Using NVMe and CUDA Stephen Bates, PhD Technical Director, CSTO, PMC-Sierra Santa Clara, CA 1 Project Donard @ PMC-Sierra Donard is a PMC CTO project that leverages NVM Express
Accelerating Data Centers Using NVMe and CUDA Stephen Bates, PhD Technical Director, CSTO, PMC-Sierra Santa Clara, CA 1 Project Donard @ PMC-Sierra Donard is a PMC CTO project that leverages NVM Express
POWER9. Jeff Stuecheli POWER Systems, IBM Systems IBM Corporation
 POWER9 Jeff Stuecheli POWER Systems, IM Systems 2018 IM Corporation Recent and Future POWER Processor Roadmap POWER7 45 nm 2010 POWER7+ 32 nm 2012 POWER8 Family 22nm 2014 2016 POWER9 Family 14nm 2H17 2H18+
POWER9 Jeff Stuecheli POWER Systems, IM Systems 2018 IM Corporation Recent and Future POWER Processor Roadmap POWER7 45 nm 2010 POWER7+ 32 nm 2012 POWER8 Family 22nm 2014 2016 POWER9 Family 14nm 2H17 2H18+
Capturing value from an open ecosystem
 Capturing value from an open ecosystem Tom Rosamilia Senior Vice President IBM Systems Forward-Looking Statement Certain comments made during this event and in the presentation materials may be characterized
Capturing value from an open ecosystem Tom Rosamilia Senior Vice President IBM Systems Forward-Looking Statement Certain comments made during this event and in the presentation materials may be characterized
RapidIO.org Update. Mar RapidIO.org 1
 RapidIO.org Update rickoco@rapidio.org Mar 2015 2015 RapidIO.org 1 Outline RapidIO Overview & Markets Data Center & HPC Communications Infrastructure Industrial Automation Military & Aerospace RapidIO.org
RapidIO.org Update rickoco@rapidio.org Mar 2015 2015 RapidIO.org 1 Outline RapidIO Overview & Markets Data Center & HPC Communications Infrastructure Industrial Automation Military & Aerospace RapidIO.org
PCIe Storage Beyond SSDs
 PCIe Storage Beyond SSDs Fabian Trumper NVM Solutions Group PMC-Sierra Santa Clara, CA 1 Classic Memory / Storage Hierarchy FAST, VOLATILE CPU Cache DRAM Performance Gap Performance Tier (SSDs) SLOW, NON-VOLATILE
PCIe Storage Beyond SSDs Fabian Trumper NVM Solutions Group PMC-Sierra Santa Clara, CA 1 Classic Memory / Storage Hierarchy FAST, VOLATILE CPU Cache DRAM Performance Gap Performance Tier (SSDs) SLOW, NON-VOLATILE
Zhang Tianfei. Rosen Xu
 Zhang Tianfei Rosen Xu Agenda Part 1: FPGA and OPAE - Intel FPGAs and the Modern Datacenter - Platform Options and the Acceleration Stack - FPGA Hardware overview - Open Programmable Acceleration Engine
Zhang Tianfei Rosen Xu Agenda Part 1: FPGA and OPAE - Intel FPGAs and the Modern Datacenter - Platform Options and the Acceleration Stack - FPGA Hardware overview - Open Programmable Acceleration Engine
DRAM and Storage-Class Memory (SCM) Overview
 Overview") Page 1 of 7 DRAM and Storage-Class Memory (SCM) Overview Introduction/Motivation Looking forward, volatile and non-volatile memory will play a much greater role in future infrastructure solutions. Figure
Page 1 of 7 DRAM and Storage-Class Memory (SCM) Overview Introduction/Motivation Looking forward, volatile and non-volatile memory will play a much greater role in future infrastructure solutions. Figure
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
Netronome NFP: Theory of Operation
 WHITE PAPER Netronome NFP: Theory of Operation TO ACHIEVE PERFORMANCE GOALS, A MULTI-CORE PROCESSOR NEEDS AN EFFICIENT DATA MOVEMENT ARCHITECTURE. CONTENTS 1. INTRODUCTION...1 2. ARCHITECTURE OVERVIEW...2
WHITE PAPER Netronome NFP: Theory of Operation TO ACHIEVE PERFORMANCE GOALS, A MULTI-CORE PROCESSOR NEEDS AN EFFICIENT DATA MOVEMENT ARCHITECTURE. CONTENTS 1. INTRODUCTION...1 2. ARCHITECTURE OVERVIEW...2
Hardware NVMe implementation on cache and storage systems
 Hardware NVMe implementation on cache and storage systems Jerome Gaysse, IP-Maker Santa Clara, CA 1 Agenda Hardware architecture NVMe for storage NVMe for cache/application accelerator NVMe for new NVM
Hardware NVMe implementation on cache and storage systems Jerome Gaysse, IP-Maker Santa Clara, CA 1 Agenda Hardware architecture NVMe for storage NVMe for cache/application accelerator NVMe for new NVM
IBM Power Systems Update. David Spurway IBM Power Systems Product Manager STG, UK and Ireland
 IBM Power Systems Update David Spurway IBM Power Systems Product Manager STG, UK and Ireland Would you like to go fast? Go faster - win your race Doing More LESS With Power 8 POWER8 is the fastest around
IBM Power Systems Update David Spurway IBM Power Systems Product Manager STG, UK and Ireland Would you like to go fast? Go faster - win your race Doing More LESS With Power 8 POWER8 is the fastest around
Modeling Performance Use Cases with Traffic Profiles Over ARM AMBA Interfaces
 Modeling Performance Use Cases with Traffic Profiles Over ARM AMBA Interfaces Li Chen, Staff AE Cadence China Agenda Performance Challenges Current Approaches Traffic Profiles Intro Traffic Profiles Implementation
Modeling Performance Use Cases with Traffic Profiles Over ARM AMBA Interfaces Li Chen, Staff AE Cadence China Agenda Performance Challenges Current Approaches Traffic Profiles Intro Traffic Profiles Implementation
Why Composable Infrastructure? Live Webcast February 13, :00 am PT
 Why Composable Infrastructure? Live Webcast February 13, 2019 10:00 am PT Today s Presenters Philip Kufeldt University of California Santa Cruz Mike Jochimsen Kaminario Alex McDonald NetApp 2 SNIA Legal
Why Composable Infrastructure? Live Webcast February 13, 2019 10:00 am PT Today s Presenters Philip Kufeldt University of California Santa Cruz Mike Jochimsen Kaminario Alex McDonald NetApp 2 SNIA Legal
Messaging Overview. Introduction. Gen-Z Messaging
 Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Technical Steering Committee Update
 Technical Steering Committee Update Jeff Brown, TSC Chair IBM, Emerging Product Development, IBM Academy of Technology member Revolutionizing the Datacenter Topics TSC and Workgroup Accomplishments OpenPOWER
Technical Steering Committee Update Jeff Brown, TSC Chair IBM, Emerging Product Development, IBM Academy of Technology member Revolutionizing the Datacenter Topics TSC and Workgroup Accomplishments OpenPOWER
SmartNICs: Giving Rise To Smarter Offload at The Edge and In The Data Center
 SmartNICs: Giving Rise To Smarter Offload at The Edge and In The Data Center Jeff Defilippi Senior Product Manager Arm #Arm Tech Symposia The Cloud to Edge Infrastructure Foundation for a World of 1T Intelligent
SmartNICs: Giving Rise To Smarter Offload at The Edge and In The Data Center Jeff Defilippi Senior Product Manager Arm #Arm Tech Symposia The Cloud to Edge Infrastructure Foundation for a World of 1T Intelligent
P51: High Performance Networking
 P51: High Performance Networking Lecture 6: Programmable network devices Dr Noa Zilberman noa.zilberman@cl.cam.ac.uk Lent 2017/18 High Throughput Interfaces Performance Limitations So far we discussed
P51: High Performance Networking Lecture 6: Programmable network devices Dr Noa Zilberman noa.zilberman@cl.cam.ac.uk Lent 2017/18 High Throughput Interfaces Performance Limitations So far we discussed
Building Open Source IoT Ecosystems. November 2017
 Building Open Source IoT Ecosystems November 2017 Jim White, Dell Distinguished Engineer & Senior Software Architect james_white2@dell.com Dell Project Fuse Architect EdgeX Foundry Technical Steering Committee
Building Open Source IoT Ecosystems November 2017 Jim White, Dell Distinguished Engineer & Senior Software Architect james_white2@dell.com Dell Project Fuse Architect EdgeX Foundry Technical Steering Committee
40Gbps+ Full Line Rate, Programmable Network Accelerators for Low Latency Applications SAAHPC 19 th July 2011
 40Gbps+ Full Line Rate, Programmable Network Accelerators for Low Latency Applications SAAHPC 19 th July 2011 Allan Cantle President & Founder www.nallatech.com Company Overview ISI + Nallatech + Innovative
40Gbps+ Full Line Rate, Programmable Network Accelerators for Low Latency Applications SAAHPC 19 th July 2011 Allan Cantle President & Founder www.nallatech.com Company Overview ISI + Nallatech + Innovative
An Open Accelerator Infrastructure Project for OCP Accelerator Module (OAM)
") An Open Accelerator Infrastructure Project for OCP Accelerator Module (OAM) SERVER Whitney Zhao, Hardware Engineer, Facebook Siamak Tavallaei, Principal Architect, Microsoft Richard Ding, AI System Architect,
An Open Accelerator Infrastructure Project for OCP Accelerator Module (OAM) SERVER Whitney Zhao, Hardware Engineer, Facebook Siamak Tavallaei, Principal Architect, Microsoft Richard Ding, AI System Architect,
Fast Hardware For AI
 Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Adaptable Intelligence The Next Computing Era
 Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Emergence of the Memory Centric Architectures
 Emergence of the Memory Centric Architectures Balint Fleischer Chief Scientist AI is Everywhere Business Consumer Advising the CEO External Sensing: Market trends, Competitive environment, Customer sentiment,
Emergence of the Memory Centric Architectures Balint Fleischer Chief Scientist AI is Everywhere Business Consumer Advising the CEO External Sensing: Market trends, Competitive environment, Customer sentiment,
Toward a unified architecture for LAN/WAN/WLAN/SAN switches and routers
 Toward a unified architecture for LAN/WAN/WLAN/SAN switches and routers Silvano Gai 1 The sellable HPSR Seamless LAN/WLAN/SAN/WAN Network as a platform System-wide network intelligence as platform for
Toward a unified architecture for LAN/WAN/WLAN/SAN switches and routers Silvano Gai 1 The sellable HPSR Seamless LAN/WLAN/SAN/WAN Network as a platform System-wide network intelligence as platform for
THE NVIDIA DEEP LEARNING ACCELERATOR
 THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
Pactron FPGA Accelerated Computing Solutions
 Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
6.9. Communicating to the Outside World: Cluster Networking
 6.9 Communicating to the Outside World: Cluster Networking This online section describes the networking hardware and software used to connect the nodes of cluster together. As there are whole books and
6.9 Communicating to the Outside World: Cluster Networking This online section describes the networking hardware and software used to connect the nodes of cluster together. As there are whole books and
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
HETEROGENEOUS COMPUTE INFRASTRUCTURE FOR SINGAPORE
 HETEROGENEOUS COMPUTE INFRASTRUCTURE FOR SINGAPORE PHILIP HEAH ASSISTANT CHIEF EXECUTIVE TECHNOLOGY & INFRASTRUCTURE GROUP LAUNCH OF SERVICES AND DIGITAL ECONOMY (SDE) TECHNOLOGY ROADMAP (NOV 2018) Source
HETEROGENEOUS COMPUTE INFRASTRUCTURE FOR SINGAPORE PHILIP HEAH ASSISTANT CHIEF EXECUTIVE TECHNOLOGY & INFRASTRUCTURE GROUP LAUNCH OF SERVICES AND DIGITAL ECONOMY (SDE) TECHNOLOGY ROADMAP (NOV 2018) Source
Next Generation Enterprise Solutions from ARM
 Next Generation Enterprise Solutions from ARM Ian Forsyth Director Product Marketing Enterprise and Infrastructure Applications Processor Product Line Ian.forsyth@arm.com 1 Enterprise Trends IT is the
Next Generation Enterprise Solutions from ARM Ian Forsyth Director Product Marketing Enterprise and Infrastructure Applications Processor Product Line Ian.forsyth@arm.com 1 Enterprise Trends IT is the
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Capabilities and System Benefits Enabled by NVDIMM-N
 Capabilities and System Benefits Enabled by NVDIMM-N Bob Frey Arthur Sainio SMART Modular Technologies August 7, 2018 Santa Clara, CA 1 NVDIMM-N Maturity and Evolution If there's one takeaway you should
Capabilities and System Benefits Enabled by NVDIMM-N Bob Frey Arthur Sainio SMART Modular Technologies August 7, 2018 Santa Clara, CA 1 NVDIMM-N Maturity and Evolution If there's one takeaway you should
Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no commitme
 FUT3040BU Storage at Memory Speed: Finally, Nonvolatile Memory Is Here Rajesh Venkatasubramanian, VMware, Inc Richard A Brunner, VMware, Inc #VMworld #FUT3040BU Disclaimer This presentation may contain
FUT3040BU Storage at Memory Speed: Finally, Nonvolatile Memory Is Here Rajesh Venkatasubramanian, VMware, Inc Richard A Brunner, VMware, Inc #VMworld #FUT3040BU Disclaimer This presentation may contain
Cloud Acceleration with FPGA s. Mike Strickland, Director, Computer & Storage BU, Altera
 Cloud Acceleration with FPGA s Mike Strickland, Director, Computer & Storage BU, Altera Agenda Mission Alignment & Data Center Trends OpenCL and Algorithm Acceleration Networking Acceleration Data Access
Cloud Acceleration with FPGA s Mike Strickland, Director, Computer & Storage BU, Altera Agenda Mission Alignment & Data Center Trends OpenCL and Algorithm Acceleration Networking Acceleration Data Access
Welcome. Altera Technology Roadshow 2013
 Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
System-on-Chip Architecture for Mobile Applications. Sabyasachi Dey
 System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
What You can Do with NVDIMMs. Rob Peglar President, Advanced Computation and Storage LLC
 What You can Do with NVDIMMs Rob Peglar President, Advanced Computation and Storage LLC A Fundamental Change Requires An Ecosystem Windows Server 2016 Windows 10 Pro for Workstations Linux Kernel 4.2 and
What You can Do with NVDIMMs Rob Peglar President, Advanced Computation and Storage LLC A Fundamental Change Requires An Ecosystem Windows Server 2016 Windows 10 Pro for Workstations Linux Kernel 4.2 and
NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM. Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive)
 & Yunsup Lee (SiFive)") NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive) NVDLA NVIDIA DEEP LEARNING ACCELERATOR IP Core for deep learning part of NVIDIA s Xavier
NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive) NVDLA NVIDIA DEEP LEARNING ACCELERATOR IP Core for deep learning part of NVIDIA s Xavier
Building blocks for custom HyperTransport solutions
 Building blocks for custom HyperTransport solutions Holger Fröning 2 nd Symposium of the HyperTransport Center of Excellence Feb. 11-12 th 2009, Mannheim, Germany Motivation Back in 2005: Quite some experience
Building blocks for custom HyperTransport solutions Holger Fröning 2 nd Symposium of the HyperTransport Center of Excellence Feb. 11-12 th 2009, Mannheim, Germany Motivation Back in 2005: Quite some experience
Moneta: A High-performance Storage Array Architecture for Nextgeneration, Micro 2010
 Moneta: A High-performance Storage Array Architecture for Nextgeneration, Non-volatile Memories Micro 2010 NVM-based SSD NVMs are replacing spinning-disks Performance of disks has lagged NAND flash showed
Moneta: A High-performance Storage Array Architecture for Nextgeneration, Non-volatile Memories Micro 2010 NVM-based SSD NVMs are replacing spinning-disks Performance of disks has lagged NAND flash showed
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
3D Xpoint Status and Forecast 2017
 3D Xpoint Status and Forecast 2017 Mark Webb MKW 1 Ventures Consulting, LLC Memory Technologies Latency Density Cost HVM ready DRAM ***** *** *** ***** NAND * ***** ***** ***** MRAM ***** * * *** 3DXP
3D Xpoint Status and Forecast 2017 Mark Webb MKW 1 Ventures Consulting, LLC Memory Technologies Latency Density Cost HVM ready DRAM ***** *** *** ***** NAND * ***** ***** ***** MRAM ***** * * *** 3DXP
Revolutionizing Data-Centric Transformation
 2016 OpenPOWER Foundation Revolutionizing Data-Centric Transformation April 2016 Sumit Gupta Vice President, High Performance Computing and Analytics IBM Power Systems OpenPOWER: Catalyst for Open Innovation
2016 OpenPOWER Foundation Revolutionizing Data-Centric Transformation April 2016 Sumit Gupta Vice President, High Performance Computing and Analytics IBM Power Systems OpenPOWER: Catalyst for Open Innovation
IBM POWER SYSTEMS: YOUR UNFAIR ADVANTAGE
 IBM POWER SYSTEMS: YOUR UNFAIR ADVANTAGE Choosing IT infrastructure is a crucial decision, and the right choice will position your organization for success. IBM Power Systems provides an innovative platform
IBM POWER SYSTEMS: YOUR UNFAIR ADVANTAGE Choosing IT infrastructure is a crucial decision, and the right choice will position your organization for success. IBM Power Systems provides an innovative platform