Lustre Parallel Filesystem Best Practices
|
|
|
- Rodney Riley
- 5 years ago
- Views:
Transcription
1 Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory 7 November 2017
2 Outline Introduction to Parallel I/O Understanding the I/O performance on Lustre Accelerating the performance
3 There is no magic solution I/O Performance I/O performance depends on the pattern Of course a bottleneck can occur from any part of an application Increasing computation and decreasing I/O is a good solution but not always possible
4 Lustre best practices I Do not use ls l The information on ownership and permission metadata is stores on MDTs, however, the file size metadata is available from OSTs Use ls instead Avoid having large number of files in a single directory Split a large number of files into multiple subdirectories to minimize the contention.
5 Lustre best practices II Avoid accessing large number of small files on Lustre On Lustre, create a small file 64KB: dd if=/dev/urandom of=my_big_file count= records in records out bytes (66 kb) copied, s, 4.7 MB/s On /tmp/ of the node /tmp> dd if=/dev/urandom of=my_big_file count= records in records out bytes (66 kb) copied, s, 9.7 MB/s

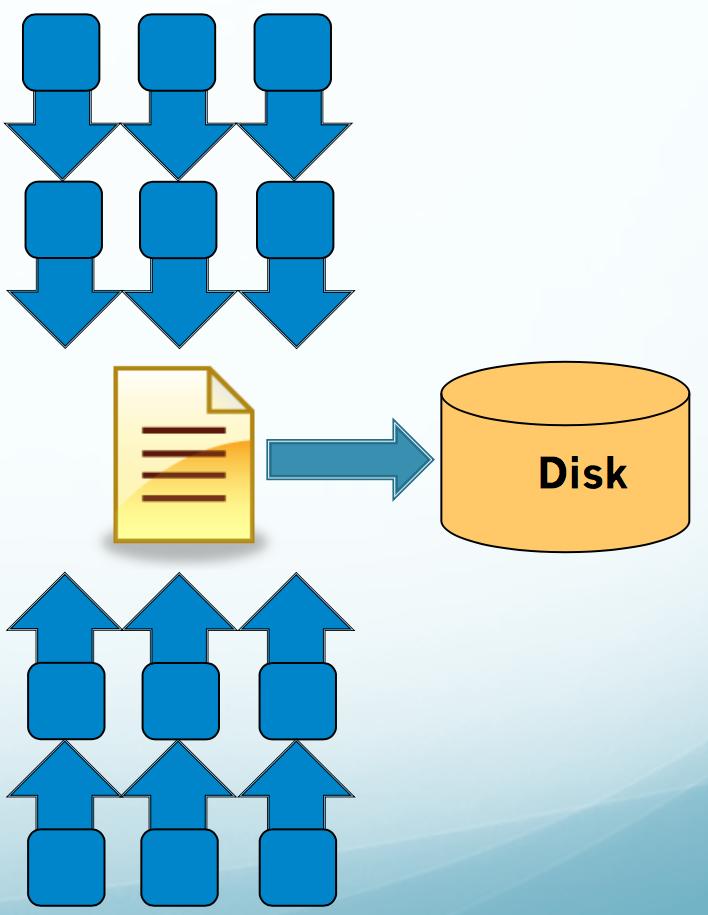
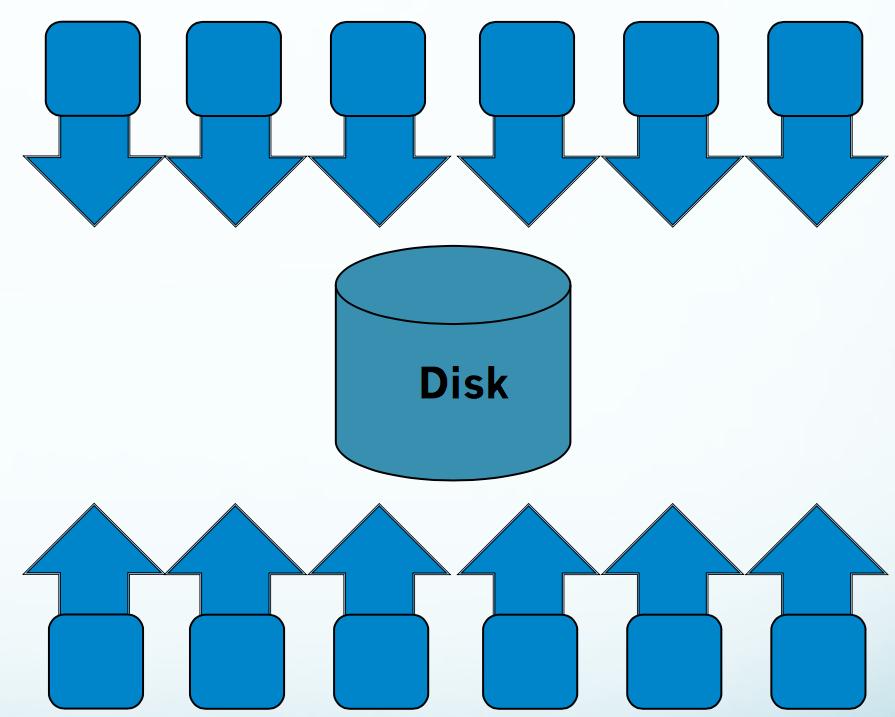
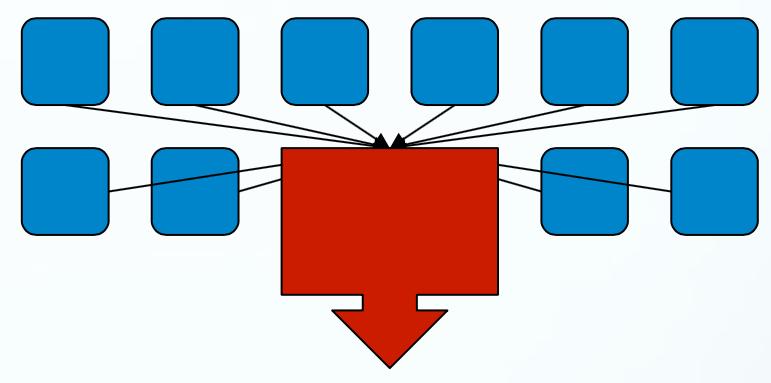
6 Various I/O modes
.")
7 Lustre Lustre file system is made up of an underlying: Set of I/O servers called Object Storage Servers (OSSs) Disks called Object Storage Targets (OSTs), stores file data (chunk of files). We have 144 OSTs on Shaheen The file metadata is controlled by a Metadata Server (MDS) and stored on a Metadata Target (MDT)

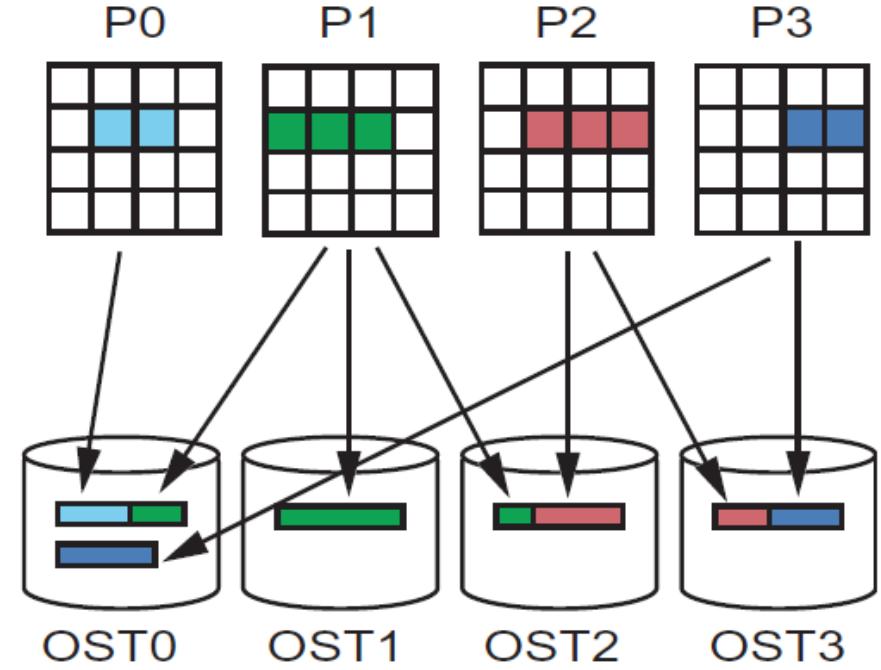
8 Lustre Operation
9 Lustre best practices III Use stripe count 1 for directories with many small files (default on our system) mkdir experiments lfs setstripe -c 1 experiments cd experiments tar -zxvf code.tgz Copy larger files to another directory with higher striping mkdir large_files lfs setstripe -c 16 large_files cp file large_files/
10 Lustre best practices IV Increase striping count for parallel access, especially on large files. The striping factor should be a factor of a number of processes performing the parallel I/O. To identify the minimum number of striping, use the square root of the file size. If the file is 90GB. The square root is 9.5, so use at least 9 OSTs lfs setstripe c 9 file If you use 64 MPI processes for parallel I/O, the number of used OSTs should be less than 64, you could try 8, 16, 32, 64, depending on file size
11 Important factors: Striping Aligned data Software/techiniques to optimize I/O IOBUF for serial I/O module load iobuf Compile and link your application export IOBUF_PARAMS= *.out:verbose:count=12:size=32m Hugepage for MPI applications module load craype-hugepages4m compile and link Multiple options for Huge pages size Huge pages increase the maximum size of data and text in a program accessible by the high speed network Use parallel I/O libraries suchs as PHDF5, PNetCDF, ADIOS But how parallel is your I/O?
12 Collective Buffering MPI I/O aggregators During a collective write, the buffers on the aggregated nodes are buffered through MPI, then these nodes write the data to the I/O servers. Example 8 MPI processes, 2 MPI I/O aggregators
13 How many MPI processes are writing a shared file? With CRAY-MPICH, we execute one application with 1216 MPI processes and it supports parallel I/O with Parallel NetCDF and the file s size is 361GB: First case (no stripping): mkdir execution_folder copy necessary files in the folder cd execution_folder run the application Timing for Writing restart for domain seconds Answer: 1 MPI process 1: elapsed
14 How many MPI processes are writing a shared file? With CRAY-MPICH, we execute one application with 1216 MPI processes and it supports parallel I/O with Parallel NetCDF and the file s size is 361GB: Second case: mkdir execution_folder lfs seststripe c 144 execution_folder copy necessary files in the folder cd execution_folder Run the application Timing for Writing restart for domain 1: elapsed seconds Answer: 144 MPI processes
15 I/O performance on Lustre while increasing OSTs WRF 361GB restart file Lustre Time (in seconds) Lustre # OST If the file is not big enough, increasing OSTs can cause performance issues
16 How to declare the number of MPI I/O aggregators By default with the current version of Lustre, the number of MPI I/O aggregators is the number of OSTs. There are two ways to declare the striping (number of OSTs). Execute the following command on an empty folder lfs setstripe -c X empty_folder where X is between 2 and 144, depending on the size of the used files. Use the environment variable MPICH_MPIIO_HINTS to declare striping per files export MPICH_MPIIO_HINTS= "wrfinput*:striping_factor=64,wrfrst*:striping_factor=144,\ wrfout*:striping_factor=144

17 Handling Darshan Data: Using Darshan tool to visualize I/O performance
18 Lustre best practices V Experiment with different stripe count/sizes for MPI collective writes Stripe align, make sure that the I/O requests do not access multiple OSTs Avoid repetitive stat operations Loop: Check if file exists Execute a command Delete a file
19 Lustre best practices VI Avoid multiple processes opening the same file at same time. When opening a read-only file in Fortran use ACTION='read and not the default ACTION='readwrite to reduce contention by not locking the file Avoid repetitive Open/Close operations, if you read only a file use Action= read, read the file once, read all the information and save the results.
20 Test case 4 MPI processes n=1000 do i=1,n open(11, file=ffile,position="append") write (11, *) 5 close(11) end do

21 Test case - Darshan
22 Test case Darshan II
23 Test case II 4 MPI processes n=1000 open(11, file=ffile,position="append") do i=1,n write (11, *) 5 end do close(11)

24 Test case II - Darshan
25 Test case II Darshan II
26 It was explained how Lustre operates Conclusions Some parameters need be investigated for the optimum performance Be patient, probably you will not achieve the best performance immediately
27 Thank you! Questions?
Using file systems at HC3
 Using file systems at HC3 Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association www.kit.edu Basic Lustre
Using file systems at HC3 Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association www.kit.edu Basic Lustre
HPC Input/Output. I/O and Darshan. Cristian Simarro User Support Section
 HPC Input/Output I/O and Darshan Cristian Simarro Cristian.Simarro@ecmwf.int User Support Section Index Lustre summary HPC I/O Different I/O methods Darshan Introduction Goals Considerations How to use
HPC Input/Output I/O and Darshan Cristian Simarro Cristian.Simarro@ecmwf.int User Support Section Index Lustre summary HPC I/O Different I/O methods Darshan Introduction Goals Considerations How to use
Introduction to Parallel I/O
 Introduction to Parallel I/O Bilel Hadri bhadri@utk.edu NICS Scientific Computing Group OLCF/NICS Fall Training October 19 th, 2011 Outline Introduction to I/O Path from Application to File System Common
Introduction to Parallel I/O Bilel Hadri bhadri@utk.edu NICS Scientific Computing Group OLCF/NICS Fall Training October 19 th, 2011 Outline Introduction to I/O Path from Application to File System Common
Welcome! Virtual tutorial starts at 15:00 BST
 Welcome! Virtual tutorial starts at 15:00 BST Parallel IO and the ARCHER Filesystem ARCHER Virtual Tutorial, Wed 8 th Oct 2014 David Henty Reusing this material This work is licensed
Welcome! Virtual tutorial starts at 15:00 BST Parallel IO and the ARCHER Filesystem ARCHER Virtual Tutorial, Wed 8 th Oct 2014 David Henty Reusing this material This work is licensed
Parallel I/O on Theta with Best Practices
 Parallel I/O on Theta with Best Practices Paul Coffman pcoffman@anl.gov Francois Tessier, Preeti Malakar, George Brown ALCF 1 Parallel IO Performance on Theta dependent on optimal Lustre File System utilization
Parallel I/O on Theta with Best Practices Paul Coffman pcoffman@anl.gov Francois Tessier, Preeti Malakar, George Brown ALCF 1 Parallel IO Performance on Theta dependent on optimal Lustre File System utilization
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Triton file systems - an introduction. slide 1 of 28
 Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Data storage on Triton: an introduction
 Motivation Data storage on Triton: an introduction How storage is organized in Triton How to optimize IO Do's and Don'ts Exercises slide 1 of 33 Data storage: Motivation Program speed isn t just about
Motivation Data storage on Triton: an introduction How storage is organized in Triton How to optimize IO Do's and Don'ts Exercises slide 1 of 33 Data storage: Motivation Program speed isn t just about
Overview of High Performance Input/Output on LRZ HPC systems. Christoph Biardzki Richard Patra Reinhold Bader
 Overview of High Performance Input/Output on LRZ HPC systems Christoph Biardzki Richard Patra Reinhold Bader Agenda Choosing the right file system Storage subsystems at LRZ Introduction to parallel file
Overview of High Performance Input/Output on LRZ HPC systems Christoph Biardzki Richard Patra Reinhold Bader Agenda Choosing the right file system Storage subsystems at LRZ Introduction to parallel file
Application I/O on Blue Waters. Rob Sisneros Kalyana Chadalavada
 Application I/O on Blue Waters Rob Sisneros Kalyana Chadalavada I/O For Science! HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware U'li'es Parallel File System Darshan Blue Waters
Application I/O on Blue Waters Rob Sisneros Kalyana Chadalavada I/O For Science! HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware U'li'es Parallel File System Darshan Blue Waters
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Parallel File Systems for HPC
 Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
How To write(101)data on a large system like a Cray XT called HECToR
data on a large system like a Cray XT called HECToR") How To write(101)data on a large system like a Cray XT called HECToR Martyn Foster mfoster@cray.com Topics Why does this matter? IO architecture on the Cray XT Hardware Architecture Language layers OS
How To write(101)data on a large system like a Cray XT called HECToR Martyn Foster mfoster@cray.com Topics Why does this matter? IO architecture on the Cray XT Hardware Architecture Language layers OS
Computer Science Section. Computational and Information Systems Laboratory National Center for Atmospheric Research
 Computer Science Section Computational and Information Systems Laboratory National Center for Atmospheric Research My work in the context of TDD/CSS/ReSET Polynya new research computing environment Polynya
Computer Science Section Computational and Information Systems Laboratory National Center for Atmospheric Research My work in the context of TDD/CSS/ReSET Polynya new research computing environment Polynya
Parallel I/O. Steve Lantz Senior Research Associate Cornell CAC. Workshop: Data Analysis on Ranger, January 19, 2012
 Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Data Analysis on Ranger, January 19, 2012 Based on materials developed by Bill Barth at TACC 1. Lustre 2 Lustre Components All Ranger
Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Data Analysis on Ranger, January 19, 2012 Based on materials developed by Bill Barth at TACC 1. Lustre 2 Lustre Components All Ranger
Guidelines for Efficient Parallel I/O on the Cray XT3/XT4
 Guidelines for Efficient Parallel I/O on the Cray XT3/XT4 Jeff Larkin, Cray Inc. and Mark Fahey, Oak Ridge National Laboratory ABSTRACT: This paper will present an overview of I/O methods on Cray XT3/XT4
Guidelines for Efficient Parallel I/O on the Cray XT3/XT4 Jeff Larkin, Cray Inc. and Mark Fahey, Oak Ridge National Laboratory ABSTRACT: This paper will present an overview of I/O methods on Cray XT3/XT4
 George Markomanolis IO500 Committee: John Bent, Julian M. Kunkel, Jay Lofstead 2017-11-12 http://www.io500.org IBM Spectrum Scale User Group, Denver, Colorado, USA Why? The increase of the studied domains,
George Markomanolis IO500 Committee: John Bent, Julian M. Kunkel, Jay Lofstead 2017-11-12 http://www.io500.org IBM Spectrum Scale User Group, Denver, Colorado, USA Why? The increase of the studied domains,
File Systems for HPC Machines. Parallel I/O
 File Systems for HPC Machines Parallel I/O Course Outline Background Knowledge Why I/O and data storage are important Introduction to I/O hardware File systems Lustre specifics Data formats and data provenance
File Systems for HPC Machines Parallel I/O Course Outline Background Knowledge Why I/O and data storage are important Introduction to I/O hardware File systems Lustre specifics Data formats and data provenance
Lustre overview and roadmap to Exascale computing
 HPC Advisory Council China Workshop Jinan China, October 26th 2011 Lustre overview and roadmap to Exascale computing Liang Zhen Whamcloud, Inc liang@whamcloud.com Agenda Lustre technology overview Lustre
HPC Advisory Council China Workshop Jinan China, October 26th 2011 Lustre overview and roadmap to Exascale computing Liang Zhen Whamcloud, Inc liang@whamcloud.com Agenda Lustre technology overview Lustre
Blue Waters Local Software To Be Released: Module Improvements and Parfu Parallel Archive Tool
 November 15, 16 2016 Blue Waters Local Software To Be Released: Module Improvements and Parfu Parallel Archive Tool Craig P Steffen csteffen@ncsa.illinois.edu Blue Waters Science and Engineering Applications
November 15, 16 2016 Blue Waters Local Software To Be Released: Module Improvements and Parfu Parallel Archive Tool Craig P Steffen csteffen@ncsa.illinois.edu Blue Waters Science and Engineering Applications
The cluster system. Introduction 22th February Jan Saalbach Scientific Computing Group
 The cluster system Introduction 22th February 2018 Jan Saalbach Scientific Computing Group cluster-help@luis.uni-hannover.de Contents 1 General information about the compute cluster 2 Available computing
The cluster system Introduction 22th February 2018 Jan Saalbach Scientific Computing Group cluster-help@luis.uni-hannover.de Contents 1 General information about the compute cluster 2 Available computing
The JANUS Computing Environment
 Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
I/O Performance on Cray XC30
 I/O Performance on Cray XC30 Zhengji Zhao 1), Doug Petesch 2), David Knaak 2), and Tina Declerck 1) 1) National Energy Research Scientific Center, Berkeley, CA 2) Cray, Inc., St. Paul, MN Email: {zzhao,
I/O Performance on Cray XC30 Zhengji Zhao 1), Doug Petesch 2), David Knaak 2), and Tina Declerck 1) 1) National Energy Research Scientific Center, Berkeley, CA 2) Cray, Inc., St. Paul, MN Email: {zzhao,
Extreme I/O Scaling with HDF5
 Extreme I/O Scaling with HDF5 Quincey Koziol Director of Core Software Development and HPC The HDF Group koziol@hdfgroup.org July 15, 2012 XSEDE 12 - Extreme Scaling Workshop 1 Outline Brief overview of
Extreme I/O Scaling with HDF5 Quincey Koziol Director of Core Software Development and HPC The HDF Group koziol@hdfgroup.org July 15, 2012 XSEDE 12 - Extreme Scaling Workshop 1 Outline Brief overview of
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Lecture 33: More on MPI I/O. William Gropp
 Lecture 33: More on MPI I/O William Gropp www.cs.illinois.edu/~wgropp Today s Topics High level parallel I/O libraries Options for efficient I/O Example of I/O for a distributed array Understanding why
Lecture 33: More on MPI I/O William Gropp www.cs.illinois.edu/~wgropp Today s Topics High level parallel I/O libraries Options for efficient I/O Example of I/O for a distributed array Understanding why
Mark Pagel
 Mark Pagel pags@cray.com New features in XT MPT 3.1 and MPT 3.2 Features as a result of scaling to 150K MPI ranks MPI-IO Improvements(MPT 3.1 and MPT 3.2) SMP aware collective improvements(mpt 3.2) Misc
Mark Pagel pags@cray.com New features in XT MPT 3.1 and MPT 3.2 Features as a result of scaling to 150K MPI ranks MPI-IO Improvements(MPT 3.1 and MPT 3.2) SMP aware collective improvements(mpt 3.2) Misc
Lustre Lockahead: Early Experience and Performance using Optimized Locking. Michael Moore
 Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Disruptive Storage Workshop Hands-On Lustre
 Disruptive Storage Workshop Hands-On Lustre Mark Miller http://www.pinedalab.org/disruptive-storage-workshop/ Schedule - Setting up our VMs (5 minutes 15 minutes to percolate) - Installing Lustre (30 minutes
Disruptive Storage Workshop Hands-On Lustre Mark Miller http://www.pinedalab.org/disruptive-storage-workshop/ Schedule - Setting up our VMs (5 minutes 15 minutes to percolate) - Installing Lustre (30 minutes
PERFORMANCE OF PARALLEL IO ON LUSTRE AND GPFS
 PERFORMANCE OF PARALLEL IO ON LUSTRE AND GPFS David Henty and Adrian Jackson (EPCC, The University of Edinburgh) Charles Moulinec and Vendel Szeremi (STFC, Daresbury Laboratory Outline Parallel IO problem
PERFORMANCE OF PARALLEL IO ON LUSTRE AND GPFS David Henty and Adrian Jackson (EPCC, The University of Edinburgh) Charles Moulinec and Vendel Szeremi (STFC, Daresbury Laboratory Outline Parallel IO problem
An Evolutionary Path to Object Storage Access
 An Evolutionary Path to Object Storage Access David Goodell +, Seong Jo (Shawn) Kim*, Robert Latham +, Mahmut Kandemir*, and Robert Ross + *Pennsylvania State University + Argonne National Laboratory Outline
An Evolutionary Path to Object Storage Access David Goodell +, Seong Jo (Shawn) Kim*, Robert Latham +, Mahmut Kandemir*, and Robert Ross + *Pennsylvania State University + Argonne National Laboratory Outline
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Lustre Clustered Meta-Data (CMD) Huang Hua Andreas Dilger Lustre Group, Sun Microsystems
 Huang Hua Andreas Dilger Lustre Group, Sun Microsystems") Lustre Clustered Meta-Data (CMD) Huang Hua H.Huang@Sun.Com Andreas Dilger adilger@sun.com Lustre Group, Sun Microsystems 1 Agenda What is CMD? How does it work? What are FIDs? CMD features CMD tricks Upcoming
Lustre Clustered Meta-Data (CMD) Huang Hua H.Huang@Sun.Com Andreas Dilger adilger@sun.com Lustre Group, Sun Microsystems 1 Agenda What is CMD? How does it work? What are FIDs? CMD features CMD tricks Upcoming
Scalable I/O. Ed Karrels,
 Scalable I/O Ed Karrels, edk@illinois.edu I/O performance overview Main factors in performance Know your I/O Striping Data layout Collective I/O 2 of 32 I/O performance Length of each basic operation High
Scalable I/O Ed Karrels, edk@illinois.edu I/O performance overview Main factors in performance Know your I/O Striping Data layout Collective I/O 2 of 32 I/O performance Length of each basic operation High
libhio: Optimizing IO on Cray XC Systems With DataWarp
 libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
Parallel IO Benchmarking
 Parallel IO Benchmarking Jia-Ying Wu August 17, 2016 MSc in High Performance Computing with Data Science The University of Edinburgh Year of Presentation: 2016 Abstract The project is aimed to investigate
Parallel IO Benchmarking Jia-Ying Wu August 17, 2016 MSc in High Performance Computing with Data Science The University of Edinburgh Year of Presentation: 2016 Abstract The project is aimed to investigate
ECSS Project: Prof. Bodony: CFD, Aeroacoustics
 ECSS Project: Prof. Bodony: CFD, Aeroacoustics Robert McLay The Texas Advanced Computing Center June 19, 2012 ECSS Project: Bodony Aeroacoustics Program Program s name is RocfloCM It is mixture of Fortran
ECSS Project: Prof. Bodony: CFD, Aeroacoustics Robert McLay The Texas Advanced Computing Center June 19, 2012 ECSS Project: Bodony Aeroacoustics Program Program s name is RocfloCM It is mixture of Fortran
Parallel I/O Techniques and Performance Optimization
 Parallel I/O Techniques and Performance Optimization Lonnie Crosby lcrosby1@utk.edu NICS Scientific Computing Group NICS/RDAV Spring Training 2012 March 22, 2012 2 Outline Introduction to I/O Path from
Parallel I/O Techniques and Performance Optimization Lonnie Crosby lcrosby1@utk.edu NICS Scientific Computing Group NICS/RDAV Spring Training 2012 March 22, 2012 2 Outline Introduction to I/O Path from
HDF5 I/O Performance. HDF and HDF-EOS Workshop VI December 5, 2002
 HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
Taming Parallel I/O Complexity with Auto-Tuning
 Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Welcome to getting started with Ubuntu Server. This System Administrator Manual. guide to be simple to follow, with step by step instructions
 Welcome to getting started with Ubuntu 12.04 Server. This System Administrator Manual guide to be simple to follow, with step by step instructions with screenshots INDEX 1.Installation of Ubuntu 12.04
Welcome to getting started with Ubuntu 12.04 Server. This System Administrator Manual guide to be simple to follow, with step by step instructions with screenshots INDEX 1.Installation of Ubuntu 12.04
HDFS Access Options, Applications
 Hadoop Distributed File System (HDFS) access, APIs, applications HDFS Access Options, Applications Able to access/use HDFS via command line Know about available application programming interfaces Example
Hadoop Distributed File System (HDFS) access, APIs, applications HDFS Access Options, Applications Able to access/use HDFS via command line Know about available application programming interfaces Example
CMD Code Walk through Wang Di
 CMD Code Walk through Wang Di Lustre Group Sun Microsystems 1 Current status and plan CMD status 2.0 MDT stack is rebuilt for CMD, but there are still some problems in current implementation. No recovery
CMD Code Walk through Wang Di Lustre Group Sun Microsystems 1 Current status and plan CMD status 2.0 MDT stack is rebuilt for CMD, but there are still some problems in current implementation. No recovery
Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage
![Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage](/thumbs/92/109196544.jpg "Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage") Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage Evaluation of Lustre File System software enhancements for improved Metadata performance Wojciech Turek, Paul Calleja,John
Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage Evaluation of Lustre File System software enhancements for improved Metadata performance Wojciech Turek, Paul Calleja,John
A More Realistic Way of Stressing the End-to-end I/O System
 A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
Parallel I/O Libraries and Techniques
 Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Improved Solutions for I/O Provisioning and Application Acceleration
 1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
CNAG Advanced User Training
 www.bsc.es CNAG Advanced User Training Aníbal Moreno, CNAG System Administrator Pablo Ródenas, BSC HPC Support Rubén Ramos Horta, CNAG HPC Support Barcelona,May the 5th Aim Understand CNAG s cluster design
www.bsc.es CNAG Advanced User Training Aníbal Moreno, CNAG System Administrator Pablo Ródenas, BSC HPC Support Rubén Ramos Horta, CNAG HPC Support Barcelona,May the 5th Aim Understand CNAG s cluster design
Parallel I/O. Steve Lantz Senior Research Associate Cornell CAC. Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012
 Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012 Based on materials developed by Bill Barth at TACC Introduction: The Parallel
Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012 Based on materials developed by Bill Barth at TACC Introduction: The Parallel
PLFS and Lustre Performance Comparison
 PLFS and Lustre Performance Comparison Lustre User Group 2014 Miami, FL April 8-10, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider, Brett Kettering,
PLFS and Lustre Performance Comparison Lustre User Group 2014 Miami, FL April 8-10, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider, Brett Kettering,
Filesystems on SSCK's HP XC6000
 Filesystems on SSCK's HP XC6000 Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Overview» Overview of HP SFS at SSCK HP StorageWorks Scalable File Share (SFS) based on
Filesystems on SSCK's HP XC6000 Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Overview» Overview of HP SFS at SSCK HP StorageWorks Scalable File Share (SFS) based on
Introduction The Project Lustre Architecture Performance Conclusion References. Lustre. Paul Bienkowski
 Lustre Paul Bienkowski 2bienkow@informatik.uni-hamburg.de Proseminar Ein-/Ausgabe - Stand der Wissenschaft 2013-06-03 1 / 34 Outline 1 Introduction 2 The Project Goals and Priorities History Who is involved?
Lustre Paul Bienkowski 2bienkow@informatik.uni-hamburg.de Proseminar Ein-/Ausgabe - Stand der Wissenschaft 2013-06-03 1 / 34 Outline 1 Introduction 2 The Project Goals and Priorities History Who is involved?
An Overview of Fujitsu s Lustre Based File System
 An Overview of Fujitsu s Lustre Based File System Shinji Sumimoto Fujitsu Limited Apr.12 2011 For Maximizing CPU Utilization by Minimizing File IO Overhead Outline Target System Overview Goals of Fujitsu
An Overview of Fujitsu s Lustre Based File System Shinji Sumimoto Fujitsu Limited Apr.12 2011 For Maximizing CPU Utilization by Minimizing File IO Overhead Outline Target System Overview Goals of Fujitsu
Deep Learning on SHARCNET:
 Deep Learning on SHARCNET: Best Practices Fei Mao Outlines What does SHARCNET have? - Hardware/software resources now and future How to run a job? - A torch7 example How to train in parallel: - A Theano-based
Deep Learning on SHARCNET: Best Practices Fei Mao Outlines What does SHARCNET have? - Hardware/software resources now and future How to run a job? - A torch7 example How to train in parallel: - A Theano-based
INTEGRATING HPFS IN A CLOUD COMPUTING ENVIRONMENT
 INTEGRATING HPFS IN A CLOUD COMPUTING ENVIRONMENT Abhisek Pan 2, J.P. Walters 1, Vijay S. Pai 1,2, David Kang 1, Stephen P. Crago 1 1 University of Southern California/Information Sciences Institute 2
INTEGRATING HPFS IN A CLOUD COMPUTING ENVIRONMENT Abhisek Pan 2, J.P. Walters 1, Vijay S. Pai 1,2, David Kang 1, Stephen P. Crago 1 1 University of Southern California/Information Sciences Institute 2
A Comparative Experimental Study of Parallel File Systems for Large-Scale Data Processing
 A Comparative Experimental Study of Parallel File Systems for Large-Scale Data Processing Z. Sebepou, K. Magoutis, M. Marazakis, A. Bilas Institute of Computer Science (ICS) Foundation for Research and
A Comparative Experimental Study of Parallel File Systems for Large-Scale Data Processing Z. Sebepou, K. Magoutis, M. Marazakis, A. Bilas Institute of Computer Science (ICS) Foundation for Research and
Chapter Two. Lesson A. Objectives. Exploring the UNIX File System and File Security. Understanding Files and Directories
 Chapter Two Exploring the UNIX File System and File Security Lesson A Understanding Files and Directories 2 Objectives Discuss and explain the UNIX file system Define a UNIX file system partition Use the
Chapter Two Exploring the UNIX File System and File Security Lesson A Understanding Files and Directories 2 Objectives Discuss and explain the UNIX file system Define a UNIX file system partition Use the
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
I/O: State of the art and Future developments
 I/O: State of the art and Future developments Giorgio Amati SCAI Dept. Rome, 18/19 May 2016 Some questions Just to know each other: Why are you here? Which is the typical I/O size you work with? GB? TB?
I/O: State of the art and Future developments Giorgio Amati SCAI Dept. Rome, 18/19 May 2016 Some questions Just to know each other: Why are you here? Which is the typical I/O size you work with? GB? TB?
File Open, Close, and Flush Performance Issues in HDF5 Scot Breitenfeld John Mainzer Richard Warren 02/19/18
 File Open, Close, and Flush Performance Issues in HDF5 Scot Breitenfeld John Mainzer Richard Warren 02/19/18 1 Introduction Historically, the parallel version of the HDF5 library has suffered from performance
File Open, Close, and Flush Performance Issues in HDF5 Scot Breitenfeld John Mainzer Richard Warren 02/19/18 1 Introduction Historically, the parallel version of the HDF5 library has suffered from performance
Outline. File Systems. File System Structure. CSCI 4061 Introduction to Operating Systems
 Outline CSCI 4061 Introduction to Operating Systems Instructor: Abhishek Chandra File Systems Directories File and directory operations Inodes and metadata Links 2 File Systems An organized collection
Outline CSCI 4061 Introduction to Operating Systems Instructor: Abhishek Chandra File Systems Directories File and directory operations Inodes and metadata Links 2 File Systems An organized collection
Introduction to HPC Parallel I/O
 Introduction to HPC Parallel I/O Feiyi Wang (Ph.D.) and Sarp Oral (Ph.D.) Technology Integration Group Oak Ridge Leadership Computing ORNL is managed by UT-Battelle for the US Department of Energy Outline
Introduction to HPC Parallel I/O Feiyi Wang (Ph.D.) and Sarp Oral (Ph.D.) Technology Integration Group Oak Ridge Leadership Computing ORNL is managed by UT-Battelle for the US Department of Energy Outline
Remote Directories High Level Design
 Remote Directories High Level Design Introduction Distributed Namespace (DNE) allows the Lustre namespace to be divided across multiple metadata servers. This enables the size of the namespace and metadata
Remote Directories High Level Design Introduction Distributed Namespace (DNE) allows the Lustre namespace to be divided across multiple metadata servers. This enables the size of the namespace and metadata
Performance Monitoring in an HP SFS Environment
 Performance Monitoring in an HP SFS Environment Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Outline» Motivation» Performance monitoring on different layers» Examples
Performance Monitoring in an HP SFS Environment Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Outline» Motivation» Performance monitoring on different layers» Examples
Blue Waters I/O Performance
 Blue Waters I/O Performance Mark Swan Performance Group Cray Inc. Saint Paul, Minnesota, USA mswan@cray.com Doug Petesch Performance Group Cray Inc. Saint Paul, Minnesota, USA dpetesch@cray.com Abstract
Blue Waters I/O Performance Mark Swan Performance Group Cray Inc. Saint Paul, Minnesota, USA mswan@cray.com Doug Petesch Performance Group Cray Inc. Saint Paul, Minnesota, USA dpetesch@cray.com Abstract
5.4 - DAOS Demonstration and Benchmark Report
 5.4 - DAOS Demonstration and Benchmark Report Johann LOMBARDI on behalf of the DAOS team September 25 th, 2013 Livermore (CA) NOTICE: THIS MANUSCRIPT HAS BEEN AUTHORED BY INTEL UNDER ITS SUBCONTRACT WITH
5.4 - DAOS Demonstration and Benchmark Report Johann LOMBARDI on behalf of the DAOS team September 25 th, 2013 Livermore (CA) NOTICE: THIS MANUSCRIPT HAS BEEN AUTHORED BY INTEL UNDER ITS SUBCONTRACT WITH
Lustre File System. Proseminar 2013 Ein-/Ausgabe - Stand der Wissenschaft Universität Hamburg. Paul Bienkowski Author. Michael Kuhn Supervisor
 Proseminar 2013 Ein-/Ausgabe - Stand der Wissenschaft Universität Hamburg September 30, 2013 Paul Bienkowski Author 2bienkow@informatik.uni-hamburg.de Michael Kuhn Supervisor michael.kuhn@informatik.uni-hamburg.de
Proseminar 2013 Ein-/Ausgabe - Stand der Wissenschaft Universität Hamburg September 30, 2013 Paul Bienkowski Author 2bienkow@informatik.uni-hamburg.de Michael Kuhn Supervisor michael.kuhn@informatik.uni-hamburg.de
Best Practice Guide - Parallel I/O
 Sandra Mendez, LRZ, Germany Sebastian Lührs, FZJ, Germany Dominic Sloan-Murphy (Editor), EPCC, United Kingdom Andrew Turner (Editor), EPCC, United Kingdom Volker Weinberg (Editor), LRZ, Germany Version
Sandra Mendez, LRZ, Germany Sebastian Lührs, FZJ, Germany Dominic Sloan-Murphy (Editor), EPCC, United Kingdom Andrew Turner (Editor), EPCC, United Kingdom Volker Weinberg (Editor), LRZ, Germany Version
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Diagnosing Performance Issues in Cray ClusterStor Systems
 Diagnosing Performance Issues in Cray ClusterStor Systems Comprehensive Performance Analysis with Cray View for ClusterStor Patricia Langer Cray, Inc. Bloomington, MN USA planger@cray.com I. INTRODUCTION
Diagnosing Performance Issues in Cray ClusterStor Systems Comprehensive Performance Analysis with Cray View for ClusterStor Patricia Langer Cray, Inc. Bloomington, MN USA planger@cray.com I. INTRODUCTION
Managing Lustre TM Data Striping
 Managing Lustre TM Data Striping Metadata Server Extended Attributes and Lustre Striping APIs in a Lustre File System Sun Microsystems, Inc. February 4, 2008 Table of Contents Overview...3 Data Striping
Managing Lustre TM Data Striping Metadata Server Extended Attributes and Lustre Striping APIs in a Lustre File System Sun Microsystems, Inc. February 4, 2008 Table of Contents Overview...3 Data Striping
New User Seminar: Part 2 (best practices)
") New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
Progress on Efficient Integration of Lustre* and Hadoop/YARN
 Progress on Efficient Integration of Lustre* and Hadoop/YARN Weikuan Yu Robin Goldstone Omkar Kulkarni Bryon Neitzel * Some name and brands may be claimed as the property of others. MapReduce l l l l A
Progress on Efficient Integration of Lustre* and Hadoop/YARN Weikuan Yu Robin Goldstone Omkar Kulkarni Bryon Neitzel * Some name and brands may be claimed as the property of others. MapReduce l l l l A
Lustre * Features In Development Fan Yong High Performance Data Division, Intel CLUG
 Lustre * Features In Development Fan Yong High Performance Data Division, Intel CLUG 2017 @Beijing Outline LNet reliability DNE improvements Small file performance File Level Redundancy Miscellaneous improvements
Lustre * Features In Development Fan Yong High Performance Data Division, Intel CLUG 2017 @Beijing Outline LNet reliability DNE improvements Small file performance File Level Redundancy Miscellaneous improvements
Unix Filesystem. January 26 th, 2004 Class Meeting 2
 Unix Filesystem January 26 th, 2004 Class Meeting 2 * Notes adapted by Christian Allgood from previous work by other members of the CS faculty at Virginia Tech Unix Filesystem! The filesystem is your interface
Unix Filesystem January 26 th, 2004 Class Meeting 2 * Notes adapted by Christian Allgood from previous work by other members of the CS faculty at Virginia Tech Unix Filesystem! The filesystem is your interface
An Exploration of New Hardware Features for Lustre. Nathan Rutman
 An Exploration of New Hardware Features for Lustre Nathan Rutman Motivation Open-source Hardware-agnostic Linux Least-common-denominator hardware 2 Contents Hardware CRC MDRAID T10 DIF End-to-end data
An Exploration of New Hardware Features for Lustre Nathan Rutman Motivation Open-source Hardware-agnostic Linux Least-common-denominator hardware 2 Contents Hardware CRC MDRAID T10 DIF End-to-end data
Experiences with Porting CESM to ARCHER
 Experiences with Porting CESM to ARCHER ARCHER Technical Forum Webinar, 25th February, 2015 Gavin J. Pringle 25 February 2015 ARCHER Technical Forum Webinar Overview of talk Overview of the associated
Experiences with Porting CESM to ARCHER ARCHER Technical Forum Webinar, 25th February, 2015 Gavin J. Pringle 25 February 2015 ARCHER Technical Forum Webinar Overview of talk Overview of the associated
Evaluation of Parallel I/O Performance and Energy with Frequency Scaling on Cray XC30 Suren Byna and Brian Austin
 Evaluation of Parallel I/O Performance and Energy with Frequency Scaling on Cray XC30 Suren Byna and Brian Austin Lawrence Berkeley National Laboratory Energy efficiency at Exascale A design goal for future
Evaluation of Parallel I/O Performance and Energy with Frequency Scaling on Cray XC30 Suren Byna and Brian Austin Lawrence Berkeley National Laboratory Energy efficiency at Exascale A design goal for future
Lustre Metadata Fundamental Benchmark and Performance
 09/22/2014 Lustre Metadata Fundamental Benchmark and Performance DataDirect Networks Japan, Inc. Shuichi Ihara 2014 DataDirect Networks. All Rights Reserved. 1 Lustre Metadata Performance Lustre metadata
09/22/2014 Lustre Metadata Fundamental Benchmark and Performance DataDirect Networks Japan, Inc. Shuichi Ihara 2014 DataDirect Networks. All Rights Reserved. 1 Lustre Metadata Performance Lustre metadata
Experiences with the Parallel Virtual File System (PVFS) in Linux Clusters
 in Linux Clusters") Experiences with the Parallel Virtual File System (PVFS) in Linux Clusters Kent Milfeld, Avijit Purkayastha, Chona Guiang Texas Advanced Computing Center The University of Texas Austin, Texas USA Abstract
Experiences with the Parallel Virtual File System (PVFS) in Linux Clusters Kent Milfeld, Avijit Purkayastha, Chona Guiang Texas Advanced Computing Center The University of Texas Austin, Texas USA Abstract
The BioHPC Nucleus Cluster & Future Developments
 1 The BioHPC Nucleus Cluster & Future Developments Overview Today we ll talk about the BioHPC Nucleus HPC cluster with some technical details for those interested! How is it designed? What hardware does
1 The BioHPC Nucleus Cluster & Future Developments Overview Today we ll talk about the BioHPC Nucleus HPC cluster with some technical details for those interested! How is it designed? What hardware does
Lustre/HSM Binding. Aurélien Degrémont Aurélien Degrémont LUG April
 Lustre/HSM Binding Aurélien Degrémont aurelien.degremont@cea.fr Aurélien Degrémont LUG 2011 12-14 April 2011 1 Agenda Project history Presentation Architecture Components Performances Code Integration
Lustre/HSM Binding Aurélien Degrémont aurelien.degremont@cea.fr Aurélien Degrémont LUG 2011 12-14 April 2011 1 Agenda Project history Presentation Architecture Components Performances Code Integration
Operating Systems 2015 Assignment 4: File Systems
 Operating Systems 2015 Assignment 4: File Systems Deadline: Tuesday, May 26 before 23:59 hours. 1 Introduction A disk can be accessed as an array of disk blocks, often each block is 512 bytes in length.
Operating Systems 2015 Assignment 4: File Systems Deadline: Tuesday, May 26 before 23:59 hours. 1 Introduction A disk can be accessed as an array of disk blocks, often each block is 512 bytes in length.
ROBINHOOD POLICY ENGINE
 ROBINHOOD POLICY ENGINE Aurélien DEGREMONT Thomas LEIBOVICI CEA/DAM LUSTRE USER GROUP 2013 PAGE 1 ROBINHOOD: BIG PICTURE Admin rules & policies find and du clones Parallel scan (nighly, weekly, ) Lustre
ROBINHOOD POLICY ENGINE Aurélien DEGREMONT Thomas LEIBOVICI CEA/DAM LUSTRE USER GROUP 2013 PAGE 1 ROBINHOOD: BIG PICTURE Admin rules & policies find and du clones Parallel scan (nighly, weekly, ) Lustre
1 / 23. CS 137: File Systems. General Filesystem Design
 1 / 23 CS 137: File Systems General Filesystem Design 2 / 23 Promises Made by Disks (etc.) Promises 1. I am a linear array of fixed-size blocks 1 2. You can access any block fairly quickly, regardless
1 / 23 CS 137: File Systems General Filesystem Design 2 / 23 Promises Made by Disks (etc.) Promises 1. I am a linear array of fixed-size blocks 1 2. You can access any block fairly quickly, regardless
AWP ODC QUICK START GUIDE
 AWP ODC QUICK START GUIDE 1. CPU 1.1. Prepare the code Obtain and compile the code, possibly at a path which does not purge. Use the appropriate makefile. For Bluewaters (/u/sciteam/poyraz/scratch/quick_start/cpu/src
AWP ODC QUICK START GUIDE 1. CPU 1.1. Prepare the code Obtain and compile the code, possibly at a path which does not purge. Use the appropriate makefile. For Bluewaters (/u/sciteam/poyraz/scratch/quick_start/cpu/src
Ceph: A Scalable, High-Performance Distributed File System
 Ceph: A Scalable, High-Performance Distributed File System S. A. Weil, S. A. Brandt, E. L. Miller, D. D. E. Long Presented by Philip Snowberger Department of Computer Science and Engineering University
Ceph: A Scalable, High-Performance Distributed File System S. A. Weil, S. A. Brandt, E. L. Miller, D. D. E. Long Presented by Philip Snowberger Department of Computer Science and Engineering University
Lustre and PLFS Parallel I/O Performance on a Cray XE6
 Lustre and PLFS Parallel I/O Performance on a Cray XE6 Cray User Group 2014 Lugano, Switzerland May 4-8, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider,
Lustre and PLFS Parallel I/O Performance on a Cray XE6 Cray User Group 2014 Lugano, Switzerland May 4-8, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider,
Understanding MPI on Cray XC30
 Understanding MPI on Cray XC30 MPICH3 and Cray MPT Cray MPI uses MPICH3 distribution from Argonne Provides a good, robust and feature rich MPI Cray provides enhancements on top of this: low level communication
Understanding MPI on Cray XC30 MPICH3 and Cray MPT Cray MPI uses MPICH3 distribution from Argonne Provides a good, robust and feature rich MPI Cray provides enhancements on top of this: low level communication
File Management 1/34
 1/34 Learning Objectives system organization and recursive traversal buffering and memory mapping for performance Low-level data structures for implementing filesystems Disk space management for sample
1/34 Learning Objectives system organization and recursive traversal buffering and memory mapping for performance Low-level data structures for implementing filesystems Disk space management for sample
Chapter 11: File System Implementation. Objectives
 Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
API and Usage of libhio on XC-40 Systems
 API and Usage of libhio on XC-40 Systems May 24, 2018 Nathan Hjelm Cray Users Group May 24, 2018 Los Alamos National Laboratory LA-UR-18-24513 5/24/2018 1 Outline Background HIO Design HIO API HIO Configuration
API and Usage of libhio on XC-40 Systems May 24, 2018 Nathan Hjelm Cray Users Group May 24, 2018 Los Alamos National Laboratory LA-UR-18-24513 5/24/2018 1 Outline Background HIO Design HIO API HIO Configuration
NetApp High-Performance Storage Solution for Lustre
 Technical Report NetApp High-Performance Storage Solution for Lustre Solution Design Narjit Chadha, NetApp October 2014 TR-4345-DESIGN Abstract The NetApp High-Performance Storage Solution (HPSS) for Lustre,
Technical Report NetApp High-Performance Storage Solution for Lustre Solution Design Narjit Chadha, NetApp October 2014 TR-4345-DESIGN Abstract The NetApp High-Performance Storage Solution (HPSS) for Lustre,
Virtual Memory. User memory model so far:! In reality they share the same memory space! Separate Instruction and Data memory!!
 Virtual Memory User memory model so far:! Separate Instruction and Data memory!! In reality they share the same memory space!!! 0x00000000 User space Instruction memory 0x7fffffff Data memory MicroComuter
Virtual Memory User memory model so far:! Separate Instruction and Data memory!! In reality they share the same memory space!!! 0x00000000 User space Instruction memory 0x7fffffff Data memory MicroComuter
Pintos Project 4 File Systems. November 14, 2016
 Pintos Project 4 File Systems November 14, 2016 Overview Requirements Implementation Project 4 will be done in src/filesys/ This means you will run make in src/filesys This means you will run tests in
Pintos Project 4 File Systems November 14, 2016 Overview Requirements Implementation Project 4 will be done in src/filesys/ This means you will run make in src/filesys This means you will run tests in
Reminder. COP4600 Discussion 9 Assignment4. Discussion 8 Recap. Question-1(Segmentation) Question-2(I-node) Question-1(Segmentation) 10/24/2010
 Question-2(I-node) Question-1(Segmentation) 10/24/2010") COP4600 Discussion 9 Assignment4 TA: Huafeng Jin hj0@cise.ufl.edu Reminder Homework3 is due today at midnight will be posted soon, please prepare for it Discussion 8 Recap Segmentation Segmentation vs.
COP4600 Discussion 9 Assignment4 TA: Huafeng Jin hj0@cise.ufl.edu Reminder Homework3 is due today at midnight will be posted soon, please prepare for it Discussion 8 Recap Segmentation Segmentation vs.
LustreFS and its ongoing Evolution for High Performance Computing and Data Analysis Solutions
 LustreFS and its ongoing Evolution for High Performance Computing and Data Analysis Solutions Roger Goff Senior Product Manager DataDirect Networks, Inc. What is Lustre? Parallel/shared file system for
LustreFS and its ongoing Evolution for High Performance Computing and Data Analysis Solutions Roger Goff Senior Product Manager DataDirect Networks, Inc. What is Lustre? Parallel/shared file system for
HIGH PERFORMANCE COMPUTING: MODELS, METHODS, & MEANS PARALLEL FILE I/O 1
 Prof. Thomas Sterling Chirag Dekate Department of Computer Science Louisiana State University March 29 th, 2011 HIGH PERFORMANCE COMPUTING: MODELS, METHODS, & MEANS PARALLEL FILE I/O 1 Topics Introduction
Prof. Thomas Sterling Chirag Dekate Department of Computer Science Louisiana State University March 29 th, 2011 HIGH PERFORMANCE COMPUTING: MODELS, METHODS, & MEANS PARALLEL FILE I/O 1 Topics Introduction
Hotfix 913CDD03 Visual Data Explorer and SAS Web OLAP Viewer for Java
 Hotfix 913CDD03 Visual Data Explorer and SAS Web OLAP Viewer for Java BEFORE DOWNLOADING: The hot fix 913CDD03 addresses issue(s) in 9.1.3 of Component Design and Development Components on Windows as documented
Hotfix 913CDD03 Visual Data Explorer and SAS Web OLAP Viewer for Java BEFORE DOWNLOADING: The hot fix 913CDD03 addresses issue(s) in 9.1.3 of Component Design and Development Components on Windows as documented