Vertex Shader Design I
|
|
|
- Julianna Chapman
- 6 years ago
- Views:
Transcription
1 The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact I will correct the error asap. This course used only and please do NOT broadcast. Thank you. Vertex Shader Design I Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Hsinchu, Taiwan Fall,


2 Source from: A 155-mW 50-Mvertices/s Graphics Processor With Fixed-Point Programmable Vertex Shader for Mobile Applications J. H. Shon, J. H. Woo, M. W. Lee, H. J. Kim, R. Woo, H. J. Yoo A 155-mW 50-Mvertices/s graphics processor with fixed-point programmable vertex shader for mobile applications, IEEE J. Solid-State Circuits, vol. 41, no. 5, pp , May
3 Outline Introduction System Architecture System Operations Data Transfer Flow Dual Operations Programmable SIMD Vertex Shader Internal Architecture Pipeline Structure Fixed-Point Graphics Processing SIMD Multiply Engine 3
4 Introduction (1/2) For wireless applications, the low power consumption is the most important issue because of limited battery lifetime. The reduced instruction set computer (RISC) architecture are widely used as the main platforms for wireless applications because of their high MIPS/watt. However, these low-power RISC platforms have very limited system resources in terms of computation power and memory bandwidth. 4
5 Introduction (2/2) Moreover, since users are watching 3-D graphics images on a small screen very closely to their eyes, the graphics processor must generate high quality of graphics images with advanced graphics algorithms. These increase image quality and/or lower memory bandwidth usage, and thus also power consumption. In the previous works, the graphics processors did not integrate vertex shader and showed lack of processing parallelism for streaming graphics data. In this work, we designed and implemented a graphics processor with programmable fixed-point singleinstruction-multiple-data (SIMD) vertex shader for mobile applications. 5
6 System Architecture (1/2) Block diagram of the graphics processor 6
7 System Architecture (2/2) The vertex shader is implemented as an ARM-10 coprocessor and processes all per-vertex operations such as geometry transformation and lighting calculation. The primitive assembly such as clipping and culling is also performed by the vertex shader in collaboration with the RISC processor. The rendering engine is responsible for the rasterization and the per-pixel operations such as pixel blending and texture mapping. The rendering engine instruction is composed of transformed vertex coordinates, texture coordinates and lit vertex color. The PFS (Programmable Frequency Synthesizer) reduces the dynamic power consumption of the chip by clock gating and frequency scaling. 7
8 System Operations (1/8) A. Data Transfer Flow The whole system performance of graphics hardware depends not only on the performance of the individual hardware acceleration blocks but also on the communication cycles for transferring the graphics data between external memory and the graphics hardware. 8
9 System Operations (2/8) In this data flow, hardware-instruction path and graphics-data path are separated from each other to improve the streaming processing within allowed memory bandwidth. 9
10 System Operations (3/8) The vertex data stored in the data cache of the ARM- 10 processor are transferred by vertex-attribute-move instruction of the vertex shader, which is mapped into the co-processor register transfer instruction of the ARM-10 processor. The separation of instruction and data paths increases processing parallelism of the hardware blocks and reduces the required bus bandwidth. 10
11 System Operations (4/8) B. Dual Operations (a) Tightly Coupled Co-processor (TCC) state (b) Parallel Processor (PP) state 11
12 System Operations (5/8) (a) Tightly Coupled Co-processor (TCC) state They do not affect the memory and registers unless the arithmetic flags (negative, zero, carry out and overflow) of the ARM-10 processor satisfy a condition specified in the instructions. In the vertex shader, SIMD control flags such as arithmetic flags, saturation, overflow and underflow are updated after execution of every SIMD data processing instructions and can be moved to program status register (PSR) of the ARM-10 processor. The general SIMD instructions such as arithmetic and movement operations are implemented in the TCC state, performing clipping and back-face culling operations in 3-D graphics pipeline. 12
13 System Operations (6/8) (b) Parallel Processor (PP) state In this state, the vertex shader behaves like an independent processor and it does not need any control from the ARM-10 processor. The PP state has a separate graphics instruction set different from the general SIMD instructions of the TCC state. 13
14 System Operations (7/8) Processor for synchronization. The vertex shader executes the independent vertex program codes while the ARM-10 processor performs its main application program or enters even into cache miss. Various user-defined vertex processing operations such as geometry transformation and lighting calculations can be performed for the current vertex input while next vertex data is fetched from the ARM- 10 processor. To maintain the communication protocol of the ARM- 10 co-processor interface, the vertex shader drives co-processor busy (CPbusy) signal to the ARM-10 processor in the PP state, blocking next co-processor instruction from the ARM-10 14
15 System Operations (8/8) The graphics instruction set is the subset of the general SIMD instructions with graphics extensions such as source swizzling and write-masks. In the PP state, there are more register file sets that can be used as input operands of instructions in programmer s model. The general SIMD instructions in the TCC state can also accelerate various multimedia functions beyond 3-D graphics such as MPEG-4 video. 15
")
16 Programmable SIMD Vertex Shader (1/4) 16
17 Programmable SIMD Vertex Shader (2/4) In the control part, there is a 2 kb code memory that stores vertex program codes of graphics instructions. Vertex program control unit (VPCTRL) issues the graphics instructions without control of the ARM-10 processor. The contents of control register determine its operating state. The two operating states the TCC state and the PP state share all of the hardware blocks except instruction fetch units. 17
18 Programmable SIMD Vertex Shader (3/4) Fixed-point vector unit is responsible for all SIMD arithmetic operations such as addition and multiplication. Special function unit (SFU) is responsible for reciprocal (RCP) and reciprocal square root (RSQ) operations. Display buffer, implemented as a 32 kb synchronous SRAM, stores graphics constants such as transformation matrix, lighting parameters and lookup table entries. Ex. of lighting parameters : normal vectors, view vectors, light vectors 18
 There are three output vertex register files for caching of vertex data in the primitive assembly and only one")
19 Programmable SIMD Vertex Shader (4/4) For streaming graphics processing, the vertex shader contains multiple register files : Vertex Input Registers (VIR) Hold the vertex attributes such as position and normal vector Feed into the fixed-point SIMD datapath Vertex Output Registers (VOR) There are three output vertex register files for caching of vertex data in the primitive assembly and only one of them is accessible in the vertex program Vertex General SIMD Registers (VGR) Store temporary results during vertex program execution 19

20 Pipeline Structure (1/2) 20
21 Pipeline Structure (2/2) For programmable shading, operands of the SRAM display buffer and the SIMD register files are accessed at the same time in the decode stage. In the execution stage, there are three separated pipelines : SIMD arithmetic-and-logic (ALU) pipeline SIMD multiply pipeline SFU pipeline To reduce the design complexity, register forwarding logic between pipeline stages is used only in the general SIMD register file. 21

22 Fixed-Point Graphics Processing (1/3) Qm.n represents the format of a fixed point number, where m represents the number of bits used for integer part and n represents for that of fraction part. 22
23 Fixed-Point Graphics Processing (2/3) In this work, fixed-point number representation is used instead of floating-point number format. Simple integer datapath of fixed-point unit can achieve higher clock frequency while consuming less power than floating-point unit, yielding total energy reduction. To improve the usefulness of the fixed-point arithmetic operations, it is designed such that hardware status registers automatically indicate the overflows and the underflows occurred in the multiplications of two fixedpoint numbers. These status registers can be used to check errors in the fixed-point arithmetic without extra cycle penalties and degradation of SIMD parallelism. 23
 Block diagram of SIMD ALU")
24 Fixed-Point Graphics Processing (3/3) Block diagram of SIMD ALU 24
25 SIMD Multiply Engine (1/4) Since multiplication-equivalent instructions spend most of time in graphics operations, the throughput of fixed-point MAC operations is designed as a single cycle. In addition, fast 4- cycle matrix transformation (TRFM) is implemented. 25

26 SIMD Multiply Engine (2/4) However, fixed-point MUL and MAC operations require two cycle integer multiplications and two cycle integer additions, leading to 4-cycle latency. To resolve data dependency between theses MUL and MAC operations, it is allowed that intermediate value of the integer multipliers can be bypassed to accumulator input of the integer adders in the SIMD multiply engine. 26

27 SIMD Multiply Engine (3/4) By this scheme, the graphics processor shows 50 Mvertices/s peak graphics performance for parallel projection at 200 MHz operating frequency. 27
28 SIMD Multiply Engine (4/4) Hardware architecture of single fixed-point multiplier unit in the SIMD multiply engine 28



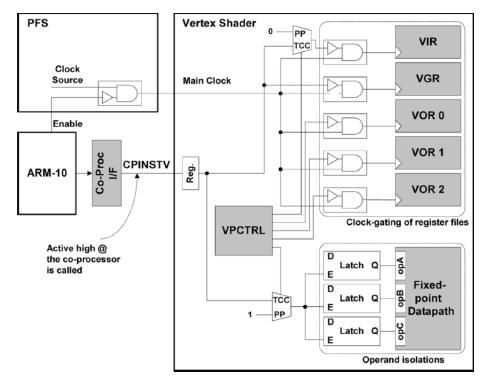
29 Instruction-level Power Management 29


30 Rendering Engine and Clock Gating 30
31 Programmable Frequency Synthesizer (PFS) 31

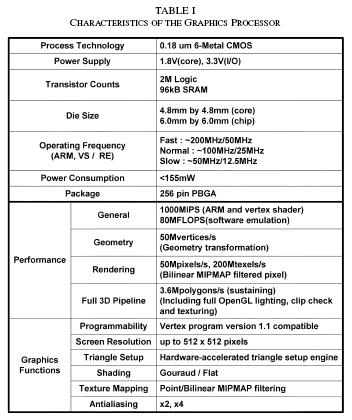
32 Performance Results (1/3) 32
")
33 Performance Results (2/3) 33
")
34 Performance Results (3/3) 34


35 Conclusion A low-power graphics processor is designed and implemented co-processor architecture with dual operations. Fixed-point graphics processing Instruction-level power management of the vertex shader Pixel-level clock gating of the rendering engine Programmable clocking of the PFS. 35
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications
 A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
Vertex Shader Design II
 The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This course used only
The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This course used only
Design and Optimization of Geometry Acceleration for Portable 3D Graphics
 M.S. Thesis Design and Optimization of Geometry Acceleration for Portable 3D Graphics Ju-ho Sohn 2002.12.20 oratory Department of Electrical Engineering and Computer Science Korea Advanced Institute of
M.S. Thesis Design and Optimization of Geometry Acceleration for Portable 3D Graphics Ju-ho Sohn 2002.12.20 oratory Department of Electrical Engineering and Computer Science Korea Advanced Institute of
A Low Power Multimedia SoC with Fully Programmable 3D Graphics and MPEG4/H.264/JPEG for Mobile Devices
 A Low Power Multimedia SoC with Fully Programmable 3D Graphics and MPEG4/H.264/JPEG for Mobile Devices Jeong-Ho Woo, Ju-Ho Sohn, Hyejung Kim, Jongcheol Jeong 1, Euljoo Jeong 1, Suk Joong Lee 1 and Hoi-Jun
A Low Power Multimedia SoC with Fully Programmable 3D Graphics and MPEG4/H.264/JPEG for Mobile Devices Jeong-Ho Woo, Ju-Ho Sohn, Hyejung Kim, Jongcheol Jeong 1, Euljoo Jeong 1, Suk Joong Lee 1 and Hoi-Jun
2D/3D Graphics Accelerator for Mobile Multimedia Applications. Ramchan Woo, Sohn, Seong-Jun Song, Young-Don
 RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
ISSCC 2001 / SESSION 9 / INTEGRATED MULTIMEDIA PROCESSORS / 9.2
 ISSCC 2001 / SESSION 9 / INTEGRATED MULTIMEDIA PROCESSORS / 9.2 9.2 A 80/20MHz 160mW Multimedia Processor integrated with Embedded DRAM MPEG-4 Accelerator and 3D Rendering Engine for Mobile Applications
ISSCC 2001 / SESSION 9 / INTEGRATED MULTIMEDIA PROCESSORS / 9.2 9.2 A 80/20MHz 160mW Multimedia Processor integrated with Embedded DRAM MPEG-4 Accelerator and 3D Rendering Engine for Mobile Applications
Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seung Jin Lee, and Hoi-Jun Yoo
 A Low-Power Handheld GPU using Logarithmic Arithmetic and Triple DVFS Power Domains Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seung Jin Lee, and Hoi-Jun Yoo Outline Backgrounds Proposed Handheld GPU Low-Power
A Low-Power Handheld GPU using Logarithmic Arithmetic and Triple DVFS Power Domains Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seung Jin Lee, and Hoi-Jun Yoo Outline Backgrounds Proposed Handheld GPU Low-Power
A Programmable Vertex Shader with Fixed-Point SIMD Datapath for Low Power Wireless Applications
 Graphics Hardware (004) T. Akenine-Möller, M. McCool (Editors) A Programmable Shader with ixed-point SIMD Datapath for Low Power Wireless Applications Ju-Ho Sohn Ramchan Woo Hoi-Jun Yoo Semiconductor System
Graphics Hardware (004) T. Akenine-Möller, M. McCool (Editors) A Programmable Shader with ixed-point SIMD Datapath for Low Power Wireless Applications Ju-Ho Sohn Ramchan Woo Hoi-Jun Yoo Semiconductor System
Implementation of DSP Algorithms
 Implementation of DSP Algorithms Main frame computers Dedicated (application specific) architectures Programmable digital signal processors voice band data modem speech codec 1 PDSP and General-Purpose
Implementation of DSP Algorithms Main frame computers Dedicated (application specific) architectures Programmable digital signal processors voice band data modem speech codec 1 PDSP and General-Purpose
Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan
 Processors Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan chanhl@maili.cgu.edu.twcgu General-purpose p processor Control unit Controllerr Control/ status Datapath ALU
Processors Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan chanhl@maili.cgu.edu.twcgu General-purpose p processor Control unit Controllerr Control/ status Datapath ALU
NOWADAYS, 3-D graphics functions are integrated into
 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS I: REGULAR PAPERS, VOL. 58, NO. 9, SEPTEMBER 2011 2211 A Power-Area Efficient Geometry Engine With Low-Complexity Subdivision Algorithm for 3-D Graphics System
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS I: REGULAR PAPERS, VOL. 58, NO. 9, SEPTEMBER 2011 2211 A Power-Area Efficient Geometry Engine With Low-Complexity Subdivision Algorithm for 3-D Graphics System
Spring 2010 Prof. Hyesoon Kim. AMD presentations from Richard Huddy and Michael Doggett
 Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Introduction to Modern GPU Hardware
 The following content are extracted from the material in the references on last page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This
The following content are extracted from the material in the references on last page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This
EMBEDDED VERTEX SHADER IN FPGA
 EMBEDDED VERTEX SHADER IN FPGA Lars Middendorf, Felix Mühlbauer 1, Georg Umlauf 2, Christophe Bobda 1 1 Self-Organizing Embedded Systems Group, Department of Computer Science University of Kaiserslautern
EMBEDDED VERTEX SHADER IN FPGA Lars Middendorf, Felix Mühlbauer 1, Georg Umlauf 2, Christophe Bobda 1 1 Self-Organizing Embedded Systems Group, Department of Computer Science University of Kaiserslautern
EMBEDDED VERTEX SHADER IN FPGA
 EMBEDDED VERTEX SHADER IN FPGA Lars Middendorf, Felix Mühlbauer 1, Georg Umlauf 2, Christophe Bobda 1 1 Self-Organizing Embedded Systems Group, Department of Computer Science University of Kaiserslautern
EMBEDDED VERTEX SHADER IN FPGA Lars Middendorf, Felix Mühlbauer 1, Georg Umlauf 2, Christophe Bobda 1 1 Self-Organizing Embedded Systems Group, Department of Computer Science University of Kaiserslautern
Tutorial on GPU Programming #2. Joong-Youn Lee Supercomputing Center, KISTI
 Tutorial on GPU Programming #2 Joong-Youn Lee Supercomputing Center, KISTI Contents Graphics Pipeline Vertex Programming Fragment Programming Introduction to Cg Language Graphics Pipeline The process to
Tutorial on GPU Programming #2 Joong-Youn Lee Supercomputing Center, KISTI Contents Graphics Pipeline Vertex Programming Fragment Programming Introduction to Cg Language Graphics Pipeline The process to
Windowing System on a 3D Pipeline. February 2005
 Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Case 1:17-cv SLR Document 1-3 Filed 01/23/17 Page 1 of 33 PageID #: 60 EXHIBIT C
 Case 1:17-cv-00064-SLR Document 1-3 Filed 01/23/17 Page 1 of 33 PageID #: 60 EXHIBIT C Case 1:17-cv-00064-SLR Document 1-3 Filed 01/23/17 Page 2 of 33 PageID #: 61 U.S. Patent No. 7,633,506 VIZIO / Sigma
Case 1:17-cv-00064-SLR Document 1-3 Filed 01/23/17 Page 1 of 33 PageID #: 60 EXHIBIT C Case 1:17-cv-00064-SLR Document 1-3 Filed 01/23/17 Page 2 of 33 PageID #: 61 U.S. Patent No. 7,633,506 VIZIO / Sigma
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Register Transfer Level in Verilog: Part I
 Source: M. Morris Mano and Michael D. Ciletti, Digital Design, 4rd Edition, 2007, Prentice Hall. Register Transfer Level in Verilog: Part I Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National
Source: M. Morris Mano and Michael D. Ciletti, Digital Design, 4rd Edition, 2007, Prentice Hall. Register Transfer Level in Verilog: Part I Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National
Media Instructions, Coprocessors, and Hardware Accelerators. Overview
 Media Instructions, Coprocessors, and Hardware Accelerators Steven P. Smith SoC Design EE382V Fall 2009 EE382 System-on-Chip Design Coprocessors, etc. SPS-1 University of Texas at Austin Overview SoCs
Media Instructions, Coprocessors, and Hardware Accelerators Steven P. Smith SoC Design EE382V Fall 2009 EE382 System-on-Chip Design Coprocessors, etc. SPS-1 University of Texas at Austin Overview SoCs
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Graphics Processing Unit Architecture (GPU Arch)
") Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
VLSI Signal Processing
 VLSI Signal Processing Programmable DSP Architectures Chih-Wei Liu VLSI Signal Processing Lab Department of Electronics Engineering National Chiao Tung University Outline DSP Arithmetic Stream Interface
VLSI Signal Processing Programmable DSP Architectures Chih-Wei Liu VLSI Signal Processing Lab Department of Electronics Engineering National Chiao Tung University Outline DSP Arithmetic Stream Interface
Storage I/O Summary. Lecture 16: Multimedia and DSP Architectures
 Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Cost-Effective Low-Power Graphics Processing Unit for Handheld Devices
 INTEGRATED CIRCUITS FOR COMMUNICATIONS Cost-Effective Low-Power Graphics Processing Unit for Handheld Devices Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seungjin Lee, and Hoi-Jun Yoo, Korea Advanced Institute
INTEGRATED CIRCUITS FOR COMMUNICATIONS Cost-Effective Low-Power Graphics Processing Unit for Handheld Devices Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seungjin Lee, and Hoi-Jun Yoo, Korea Advanced Institute
ASSEMBLY LANGUAGE MACHINE ORGANIZATION
 ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
A SXGA 3D Display Processor with Reduced Rendering Data and Enhanced Precision
 A SXGA 3D Display Processor with Reduced Rendering Data and Enhanced Precision Seok-Hoon Kim KAIST, Daejeon, Republic of Korea I. INTRODUCTION Recently, there has been tremendous progress in 3D graphics
A SXGA 3D Display Processor with Reduced Rendering Data and Enhanced Precision Seok-Hoon Kim KAIST, Daejeon, Republic of Korea I. INTRODUCTION Recently, there has been tremendous progress in 3D graphics
Verilog for Combinational Circuits
 Verilog for Combinational Circuits Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Fall, 2014 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/
Verilog for Combinational Circuits Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Fall, 2014 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/
Mali-400 MP: A Scalable GPU for Mobile Devices Tom Olson
 Mali-400 MP: A Scalable GPU for Mobile Devices Tom Olson Director, Graphics Research, ARM Outline ARM and Mobile Graphics Design Constraints for Mobile GPUs Mali Architecture Overview Multicore Scaling
Mali-400 MP: A Scalable GPU for Mobile Devices Tom Olson Director, Graphics Research, ARM Outline ARM and Mobile Graphics Design Constraints for Mobile GPUs Mali Architecture Overview Multicore Scaling
General Purpose Signal Processors
 General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
A SXGA 3D Display Processor with Reduced Rendering Data and Enhanced Precision. Seok-Hoon Kim MVLSI Lab., KAIST
 A SXGA 3D Display Processor with Reduced Rendering Data and Enhanced Precision Seok-Hoon Kim MVLSI Lab., KAIST Contents Background Motivation 3D Graphics + 3D Display Previous Works Conventional 3D Image
A SXGA 3D Display Processor with Reduced Rendering Data and Enhanced Precision Seok-Hoon Kim MVLSI Lab., KAIST Contents Background Motivation 3D Graphics + 3D Display Previous Works Conventional 3D Image
Hardware-driven visibility culling
 Hardware-driven visibility culling I. Introduction 20073114 김정현 The goal of the 3D graphics is to generate a realistic and accurate 3D image. To achieve this, it needs to process not only large amount
Hardware-driven visibility culling I. Introduction 20073114 김정현 The goal of the 3D graphics is to generate a realistic and accurate 3D image. To achieve this, it needs to process not only large amount
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Design of a Programmable Vertex Processing Unit for Mobile Platforms
 Design of a Programmable Vertex Processing Unit for Mobile Platforms Tae-Young Kim 1, Kyoung-Su Oh 2 1 Dept. of Computer Engineering, Seokyeong University 136704 Seoul, Korea tykim@skuniv.ac.kr 2 Dept.
Design of a Programmable Vertex Processing Unit for Mobile Platforms Tae-Young Kim 1, Kyoung-Su Oh 2 1 Dept. of Computer Engineering, Seokyeong University 136704 Seoul, Korea tykim@skuniv.ac.kr 2 Dept.
Multicore SoC is coming. Scalable and Reconfigurable Stream Processor for Mobile Multimedia Systems. Source: 2007 ISSCC and IDF.
 Scalable and Reconfigurable Stream Processor for Mobile Multimedia Systems Liang-Gee Chen Distinguished Professor General Director, SOC Center National Taiwan University DSP/IC Design Lab, GIEE, NTU 1
Scalable and Reconfigurable Stream Processor for Mobile Multimedia Systems Liang-Gee Chen Distinguished Professor General Director, SOC Center National Taiwan University DSP/IC Design Lab, GIEE, NTU 1
0;L$+LJK3HUIRUPDQFH ;3URFHVVRU:LWK,QWHJUDWHG'*UDSKLFV
 0;L$+LJK3HUIRUPDQFH ;3URFHVVRU:LWK,QWHJUDWHG'*UDSKLFV Rajeev Jayavant Cyrix Corporation A National Semiconductor Company 8/18/98 1 0;L$UFKLWHFWXUDO)HDWXUHV ¾ Next-generation Cayenne Core Dual-issue pipelined
0;L$+LJK3HUIRUPDQFH ;3URFHVVRU:LWK,QWHJUDWHG'*UDSKLFV Rajeev Jayavant Cyrix Corporation A National Semiconductor Company 8/18/98 1 0;L$UFKLWHFWXUDO)HDWXUHV ¾ Next-generation Cayenne Core Dual-issue pipelined
Computer organization by G. Naveen kumar, Asst Prof, C.S.E Department 1
 Pipelining and Vector Processing Parallel Processing: The term parallel processing indicates that the system is able to perform several operations in a single time. Now we will elaborate the scenario,
Pipelining and Vector Processing Parallel Processing: The term parallel processing indicates that the system is able to perform several operations in a single time. Now we will elaborate the scenario,
Review for Ray-tracing Algorithm and Hardware
 Review for Ray-tracing Algorithm and Hardware Reporter: 邱敬捷博士候選人 Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Summer, 2017 1 2017/7/26 Outline
Review for Ray-tracing Algorithm and Hardware Reporter: 邱敬捷博士候選人 Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Summer, 2017 1 2017/7/26 Outline
Architectures. Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1
 Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Architectures Michael Doggett Department of Computer Science Lund University 2009 Tomas Akenine-Möller and Michael Doggett 1 Overview of today s lecture The idea is to cover some of the existing graphics
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Folding. Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Fall,
, Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Fall,") Folding ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Fall, 2010 ldvan@cs.nctu.edu.tw http://www.cs.nctu.tw/~ldvan/ Outline Introduction Folding Transformation
Folding ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Fall, 2010 ldvan@cs.nctu.edu.tw http://www.cs.nctu.tw/~ldvan/ Outline Introduction Folding Transformation
1.2.3 The Graphics Hardware Pipeline
 Figure 1-3. The Graphics Hardware Pipeline 1.2.3 The Graphics Hardware Pipeline A pipeline is a sequence of stages operating in parallel and in a fixed order. Each stage receives its input from the prior
Figure 1-3. The Graphics Hardware Pipeline 1.2.3 The Graphics Hardware Pipeline A pipeline is a sequence of stages operating in parallel and in a fixed order. Each stage receives its input from the prior
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 14 Instruction Level Parallelism and Superscalar Processors
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? Common instructions (arithmetic, load/store,
William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? Common instructions (arithmetic, load/store,
ARM ARCHITECTURE. Contents at a glance:
 UNIT-III ARM ARCHITECTURE Contents at a glance: RISC Design Philosophy ARM Design Philosophy Registers Current Program Status Register(CPSR) Instruction Pipeline Interrupts and Vector Table Architecture
UNIT-III ARM ARCHITECTURE Contents at a glance: RISC Design Philosophy ARM Design Philosophy Registers Current Program Status Register(CPSR) Instruction Pipeline Interrupts and Vector Table Architecture
COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design
![COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design](/thumbs/80/81947289.jpg "COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design") COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design Lecture Objectives Background Need for Accelerator Accelerators and different type of parallelizm
COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design Lecture Objectives Background Need for Accelerator Accelerators and different type of parallelizm
Monday Morning. Graphics Hardware
 Monday Morning Department of Computer Engineering Graphics Hardware Ulf Assarsson Skärmen består av massa pixlar 3D-Rendering Objects are often made of triangles x,y,z- coordinate for each vertex Y X Z
Monday Morning Department of Computer Engineering Graphics Hardware Ulf Assarsson Skärmen består av massa pixlar 3D-Rendering Objects are often made of triangles x,y,z- coordinate for each vertex Y X Z
A fixed-point 3D graphics library with energy-efficient efficient cache architecture for mobile multimedia system
 MS Thesis A fixed-point 3D graphics library with energy-efficient efficient cache architecture for mobile multimedia system Min-wuk Lee 2004.12.14 Semiconductor System Laboratory Department Electrical
MS Thesis A fixed-point 3D graphics library with energy-efficient efficient cache architecture for mobile multimedia system Min-wuk Lee 2004.12.14 Semiconductor System Laboratory Department Electrical
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Design of a Programmable Vertex Processing Unit for Mobile Platforms
 Design of a Programmable Vertex Processing Unit for Mobile Platforms Tae-Young Kim 1 and Kyoung-Su Oh 2 1 Dept of Computer Engineering, Seokyeong University 136704 Seoul, Korea tykim@skunivackr 2 Dept
Design of a Programmable Vertex Processing Unit for Mobile Platforms Tae-Young Kim 1 and Kyoung-Su Oh 2 1 Dept of Computer Engineering, Seokyeong University 136704 Seoul, Korea tykim@skunivackr 2 Dept
PowerPC 740 and 750
 368 floating-point registers. A reorder buffer with 16 elements is used as well to support speculative execution. The register file has 12 ports. Although instructions can be executed out-of-order, in-order
368 floating-point registers. A reorder buffer with 16 elements is used as well to support speculative execution. The register file has 12 ports. Although instructions can be executed out-of-order, in-order
Hardware-driven Visibility Culling Jeong Hyun Kim
 Hardware-driven Visibility Culling Jeong Hyun Kim KAIST (Korea Advanced Institute of Science and Technology) Contents Introduction Background Clipping Culling Z-max (Z-min) Filter Programmable culling
Hardware-driven Visibility Culling Jeong Hyun Kim KAIST (Korea Advanced Institute of Science and Technology) Contents Introduction Background Clipping Culling Z-max (Z-min) Filter Programmable culling
PIPELINE AND VECTOR PROCESSING
 PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
Iteration Bound. Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C.
, Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C.") Iteration Bound ( 范倫達 ) Ph. D. Department of Computer Science National Chiao Tung University Taiwan R.O.C. Fall 2 ldvan@cs.nctu.edu.tw http://www.cs.nctu.tw/~ldvan/ Outline Introduction Data Flow Graph
Iteration Bound ( 范倫達 ) Ph. D. Department of Computer Science National Chiao Tung University Taiwan R.O.C. Fall 2 ldvan@cs.nctu.edu.tw http://www.cs.nctu.tw/~ldvan/ Outline Introduction Data Flow Graph
CIS 665 GPU Programming and Architecture
 CIS 665 GPU Programming and Architecture Homework #3 Due: June 6/09/09 : 23:59:59PM EST 1) Benchmarking your GPU (25 points) Background: GPUBench is a benchmark suite designed to analyze the performance
CIS 665 GPU Programming and Architecture Homework #3 Due: June 6/09/09 : 23:59:59PM EST 1) Benchmarking your GPU (25 points) Background: GPUBench is a benchmark suite designed to analyze the performance
Jim Keller. Digital Equipment Corp. Hudson MA
 Jim Keller Digital Equipment Corp. Hudson MA ! Performance - SPECint95 100 50 21264 30 21164 10 1995 1996 1997 1998 1999 2000 2001 CMOS 5 0.5um CMOS 6 0.35um CMOS 7 0.25um "## Continued Performance Leadership
Jim Keller Digital Equipment Corp. Hudson MA ! Performance - SPECint95 100 50 21264 30 21164 10 1995 1996 1997 1998 1999 2000 2001 CMOS 5 0.5um CMOS 6 0.35um CMOS 7 0.25um "## Continued Performance Leadership
High Speed Special Function Unit for Graphics Processing Unit
 High Speed Special Function Unit for Graphics Processing Unit Abd-Elrahman G. Qoutb 1, Abdullah M. El-Gunidy 1, Mohammed F. Tolba 1, and Magdy A. El-Moursy 2 1 Electrical Engineering Department, Fayoum
High Speed Special Function Unit for Graphics Processing Unit Abd-Elrahman G. Qoutb 1, Abdullah M. El-Gunidy 1, Mohammed F. Tolba 1, and Magdy A. El-Moursy 2 1 Electrical Engineering Department, Fayoum
E.Order of Operations
 Appendix E E.Order of Operations This book describes all the performed between initial specification of vertices and final writing of fragments into the framebuffer. The chapters of this book are arranged
Appendix E E.Order of Operations This book describes all the performed between initial specification of vertices and final writing of fragments into the framebuffer. The chapters of this book are arranged
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Arithmetic Unit 10032011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Chapter 3 Number Systems Fixed Point
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Arithmetic Unit 10032011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Chapter 3 Number Systems Fixed Point
Processing Unit CS206T
 Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
A 120mW Embedded 3D Graphics Rendering Engine with 6Mb Logically Local Frame-Buffer and 3.2GByte/s Run-time Reconfigurable Bus for PDA-Chip
 A 120mW Embedded 3D Graphics Rendering Engine with 6Mb Logically Local Frame-Buffer and 3.2GByte/s Run-time Reconfigurable Bus for PDA-Chip Ramchan Woo*, Chi-Weon Yoon, Jeonghoon Kook, Se-Joong Lee, Kangmin
A 120mW Embedded 3D Graphics Rendering Engine with 6Mb Logically Local Frame-Buffer and 3.2GByte/s Run-time Reconfigurable Bus for PDA-Chip Ramchan Woo*, Chi-Weon Yoon, Jeonghoon Kook, Se-Joong Lee, Kangmin
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Embedded Systems Ch 15 ARM Organization and Implementation
 Embedded Systems Ch 15 ARM Organization and Implementation Byung Kook Kim Dept of EECS Korea Advanced Institute of Science and Technology Summary ARM architecture Very little change From the first 3-micron
Embedded Systems Ch 15 ARM Organization and Implementation Byung Kook Kim Dept of EECS Korea Advanced Institute of Science and Technology Summary ARM architecture Very little change From the first 3-micron
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
17. Instruction Sets: Characteristics and Functions
 17. Instruction Sets: Characteristics and Functions Chapter 12 Spring 2016 CS430 - Computer Architecture 1 Introduction Section 12.1, 12.2, and 12.3 pp. 406-418 Computer Designer: Machine instruction set
17. Instruction Sets: Characteristics and Functions Chapter 12 Spring 2016 CS430 - Computer Architecture 1 Introduction Section 12.1, 12.2, and 12.3 pp. 406-418 Computer Designer: Machine instruction set
TEAPOT: A Toolset for Evaluating Performance, Power and Image Quality on Mobile Graphics Systems
 International Conference on Supercomputing June 2013 TEAPOT: A Toolset for Evaluating Performance, Power and Image Quality on Mobile Graphics Systems Joan-Manuel Parcerisa Polychronis Xekalakis Computer
International Conference on Supercomputing June 2013 TEAPOT: A Toolset for Evaluating Performance, Power and Image Quality on Mobile Graphics Systems Joan-Manuel Parcerisa Polychronis Xekalakis Computer
Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary
![Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary](/thumbs/95/124913402.jpg "Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary") Cornell University CS 569: Interactive Computer Graphics Introduction Lecture 1 [John C. Stone, UIUC] 2008 Steve Marschner 1 2008 Steve Marschner 2 NASA University of Calgary 2008 Steve Marschner 3 2008
Cornell University CS 569: Interactive Computer Graphics Introduction Lecture 1 [John C. Stone, UIUC] 2008 Steve Marschner 1 2008 Steve Marschner 2 NASA University of Calgary 2008 Steve Marschner 3 2008
Optimizing Games for ATI s IMAGEON Aaftab Munshi. 3D Architect ATI Research
 Optimizing Games for ATI s IMAGEON 2300 Aaftab Munshi 3D Architect ATI Research A A 3D hardware solution enables publishers to extend brands to mobile devices while remaining close to original vision of
Optimizing Games for ATI s IMAGEON 2300 Aaftab Munshi 3D Architect ATI Research A A 3D hardware solution enables publishers to extend brands to mobile devices while remaining close to original vision of
EECS150 - Digital Design Lecture 09 - Parallelism
 EECS150 - Digital Design Lecture 09 - Parallelism Feb 19, 2013 John Wawrzynek Spring 2013 EECS150 - Lec09-parallel Page 1 Parallelism Parallelism is the act of doing more than one thing at a time. Optimization
EECS150 - Digital Design Lecture 09 - Parallelism Feb 19, 2013 John Wawrzynek Spring 2013 EECS150 - Lec09-parallel Page 1 Parallelism Parallelism is the act of doing more than one thing at a time. Optimization
RISC Processors and Parallel Processing. Section and 3.3.6
 RISC Processors and Parallel Processing Section 3.3.5 and 3.3.6 The Control Unit When a program is being executed it is actually the CPU receiving and executing a sequence of machine code instructions.
RISC Processors and Parallel Processing Section 3.3.5 and 3.3.6 The Control Unit When a program is being executed it is actually the CPU receiving and executing a sequence of machine code instructions.
Optimizing DirectX Graphics. Richard Huddy European Developer Relations Manager
 Optimizing DirectX Graphics Richard Huddy European Developer Relations Manager Some early observations Bear in mind that graphics performance problems are both commoner and rarer than you d think The most
Optimizing DirectX Graphics Richard Huddy European Developer Relations Manager Some early observations Bear in mind that graphics performance problems are both commoner and rarer than you d think The most
Verilog Behavioral Modeling
 Verilog Behavioral Modeling Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Spring, 2017 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/ Source:
Verilog Behavioral Modeling Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Spring, 2017 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/ Source:
Assembly Language for Intel-Based Computers, 4 th Edition. Chapter 2: IA-32 Processor Architecture. Chapter Overview.
 Assembly Language for Intel-Based Computers, 4 th Edition Kip R. Irvine Chapter 2: IA-32 Processor Architecture Slides prepared by Kip R. Irvine Revision date: 09/25/2002 Chapter corrections (Web) Printing
Assembly Language for Intel-Based Computers, 4 th Edition Kip R. Irvine Chapter 2: IA-32 Processor Architecture Slides prepared by Kip R. Irvine Revision date: 09/25/2002 Chapter corrections (Web) Printing
ISSCC 2006 / SESSION 22 / LOW POWER MULTIMEDIA / 22.1
 ISSCC 26 / SESSION 22 / LOW POWER MULTIMEDIA / 22.1 22.1 A 125µW, Fully Scalable MPEG-2 and H.264/AVC Video Decoder for Mobile Applications Tsu-Ming Liu 1, Ting-An Lin 2, Sheng-Zen Wang 2, Wen-Ping Lee
ISSCC 26 / SESSION 22 / LOW POWER MULTIMEDIA / 22.1 22.1 A 125µW, Fully Scalable MPEG-2 and H.264/AVC Video Decoder for Mobile Applications Tsu-Ming Liu 1, Ting-An Lin 2, Sheng-Zen Wang 2, Wen-Ping Lee
ARM Processors for Embedded Applications
 ARM Processors for Embedded Applications Roadmap for ARM Processors ARM Architecture Basics ARM Families AMBA Architecture 1 Current ARM Core Families ARM7: Hard cores and Soft cores Cache with MPU or
ARM Processors for Embedded Applications Roadmap for ARM Processors ARM Architecture Basics ARM Families AMBA Architecture 1 Current ARM Core Families ARM7: Hard cores and Soft cores Cache with MPU or
Rendering approaches. 1.image-oriented. 2.object-oriented. foreach pixel... 3D rendering pipeline. foreach object...
 Rendering approaches 1.image-oriented foreach pixel... 2.object-oriented foreach object... geometry 3D rendering pipeline image 3D graphics pipeline Vertices Vertex processor Clipper and primitive assembler
Rendering approaches 1.image-oriented foreach pixel... 2.object-oriented foreach object... geometry 3D rendering pipeline image 3D graphics pipeline Vertices Vertex processor Clipper and primitive assembler
Topics in computer architecture
 Topics in computer architecture Sun Microsystems SPARC P.J. Drongowski SandSoftwareSound.net Copyright 1990-2013 Paul J. Drongowski Sun Microsystems SPARC Scalable Processor Architecture Computer family
Topics in computer architecture Sun Microsystems SPARC P.J. Drongowski SandSoftwareSound.net Copyright 1990-2013 Paul J. Drongowski Sun Microsystems SPARC Scalable Processor Architecture Computer family
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Improving Application Performance with Instruction Set Architecture Extensions to Embedded Processors
 DesignCon 2004 Improving Application Performance with Instruction Set Architecture Extensions to Embedded Processors Jonah Probell, Ultra Data Corp. jonah@ultradatacorp.com Abstract The addition of key
DesignCon 2004 Improving Application Performance with Instruction Set Architecture Extensions to Embedded Processors Jonah Probell, Ultra Data Corp. jonah@ultradatacorp.com Abstract The addition of key
EECS 151/251A Fall 2017 Digital Design and Integrated Circuits. Instructor: John Wawrzynek and Nicholas Weaver. Lecture 14 EE141
 EECS 151/251A Fall 2017 Digital Design and Integrated Circuits Instructor: John Wawrzynek and Nicholas Weaver Lecture 14 EE141 Outline Parallelism EE141 2 Parallelism Parallelism is the act of doing more
EECS 151/251A Fall 2017 Digital Design and Integrated Circuits Instructor: John Wawrzynek and Nicholas Weaver Lecture 14 EE141 Outline Parallelism EE141 2 Parallelism Parallelism is the act of doing more
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
ELE 375 Final Exam Fall, 2000 Prof. Martonosi
 ELE 375 Final Exam Fall, 2000 Prof. Martonosi Question Score 1 /10 2 /20 3 /15 4 /15 5 /10 6 /20 7 /20 8 /25 9 /30 10 /30 11 /30 12 /15 13 /10 Total / 250 Please write your answers clearly in the space
ELE 375 Final Exam Fall, 2000 Prof. Martonosi Question Score 1 /10 2 /20 3 /15 4 /15 5 /10 6 /20 7 /20 8 /25 9 /30 10 /30 11 /30 12 /15 13 /10 Total / 250 Please write your answers clearly in the space
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Structure of Computer Systems
 288 between this new matrix and the initial collision matrix M A, because the original forbidden latencies for functional unit A still have to be considered in later initiations. Figure 5.37. State diagram
288 between this new matrix and the initial collision matrix M A, because the original forbidden latencies for functional unit A still have to be considered in later initiations. Figure 5.37. State diagram
Processor Applications. The Processor Design Space. World s Cellular Subscribers. Nov. 12, 1997 Bob Brodersen (http://infopad.eecs.berkeley.
 Processor Applications CS 152 Computer Architecture and Engineering Introduction to Architectures for Digital Signal Processing Nov. 12, 1997 Bob Brodersen (http://infopad.eecs.berkeley.edu) 1 General
Processor Applications CS 152 Computer Architecture and Engineering Introduction to Architectures for Digital Signal Processing Nov. 12, 1997 Bob Brodersen (http://infopad.eecs.berkeley.edu) 1 General
UNIT 2 PROCESSORS ORGANIZATION CONT.
 UNIT 2 PROCESSORS ORGANIZATION CONT. Types of Operand Addresses Numbers Integer/floating point Characters ASCII etc. Logical Data Bits or flags x86 Data Types Operands in 8 bit -Byte 16 bit- word 32 bit-
UNIT 2 PROCESSORS ORGANIZATION CONT. Types of Operand Addresses Numbers Integer/floating point Characters ASCII etc. Logical Data Bits or flags x86 Data Types Operands in 8 bit -Byte 16 bit- word 32 bit-
The NVIDIA GeForce 8800 GPU
 The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
3-D Accelerator on Chip
 3-D Accelerator on Chip Third Prize 3-D Accelerator on Chip Institution: Participants: Instructor: Donga & Pusan University Young-Hee Won, Jin-Sung Park, Woo-Sung Moon Sam-Hak Jin Design Introduction Recently,
3-D Accelerator on Chip Third Prize 3-D Accelerator on Chip Institution: Participants: Instructor: Donga & Pusan University Young-Hee Won, Jin-Sung Park, Woo-Sung Moon Sam-Hak Jin Design Introduction Recently,
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on
 A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
Pipeline and Vector Processing 1. Parallel Processing SISD SIMD MISD & MIMD
 Pipeline and Vector Processing 1. Parallel Processing Parallel processing is a term used to denote a large class of techniques that are used to provide simultaneous data-processing tasks for the purpose
Pipeline and Vector Processing 1. Parallel Processing Parallel processing is a term used to denote a large class of techniques that are used to provide simultaneous data-processing tasks for the purpose
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
15CS44: MICROPROCESSORS AND MICROCONTROLLERS. QUESTION BANK with SOLUTIONS MODULE-4
 15CS44: MICROPROCESSORS AND MICROCONTROLLERS QUESTION BANK with SOLUTIONS MODULE-4 1) Differentiate CISC and RISC architectures. 2) Explain the important design rules of RISC philosophy. The RISC philosophy
15CS44: MICROPROCESSORS AND MICROCONTROLLERS QUESTION BANK with SOLUTIONS MODULE-4 1) Differentiate CISC and RISC architectures. 2) Explain the important design rules of RISC philosophy. The RISC philosophy
DSP Platforms Lab (AD-SHARC) Session 05
 Session 05") University of Miami - Frost School of Music DSP Platforms Lab (AD-SHARC) Session 05 Description This session will be dedicated to give an introduction to the hardware architecture and assembly programming
University of Miami - Frost School of Music DSP Platforms Lab (AD-SHARC) Session 05 Description This session will be dedicated to give an introduction to the hardware architecture and assembly programming
Age nda. Intel PXA27x Processor Family: An Applications Processor for Phone and PDA applications
 Intel PXA27x Processor Family: An Applications Processor for Phone and PDA applications N.C. Paver PhD Architect Intel Corporation Hot Chips 16 August 2004 Age nda Overview of the Intel PXA27X processor
Intel PXA27x Processor Family: An Applications Processor for Phone and PDA applications N.C. Paver PhD Architect Intel Corporation Hot Chips 16 August 2004 Age nda Overview of the Intel PXA27X processor
CS433 Homework 2 (Chapter 3)
") CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies