ECE Exam II - Solutions November 8 th, 2017
|
|
|
- Judith Armstrong
- 6 years ago
- Views:
Transcription
1 ECE 3056 Exam II - Solutions November 8 th, 2017
2 1. (15 pts) To the base pipeline we add data forwarding to EX, data hazard detection and stall generation, and branches implemented in MEM and predicted not taken with flushing. For a load-to-use hazard a check will generate a stall = 1 signal when this hazard is detected. a. (5 pts) Write the Boolean expression to generate this stall signal. Use the signal notation from the figures, defining any other variables if you feel you need them. If (ID/EX.MemRead = 1) & ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) Stall =1 An equivalent solution is possible by checking between EX and MEM and inserting the stall in the MEM stage b. (15 pts) How should the data path be modified to use this stall signal to ensure correct implementation of stalls for the load-to-use dependency? The following specific actions are necessary when performing the check between ID and EX. Stall the IF/ID register and the PC. This can be done by performing the logical AND of the stall signal and the clock at the PC and IF/ID register The control signals generated in ID should be zero to create a stall cycle in EX at the next clock. If the check is being performed between EX and MEM equivalent actions have to performed including stalling the EX stage.
3 2. (20 pts) To the base pipeline we add data forwarding to EX with data hazard detection (load-to-use) with stall generation. Now imagine that the implementation of the branch has been moved to ID and predicted not taken with flushing but there is no forwarding to ID. Consider the following code sequence at the stages indicated in cycle i. sub $8, $12, $11 -- WB add $4, $8, $9 add $4, $4, $7 beq $4, $6, loop -- MEM -- EX -- ID subi $2, $2, 4 -- IF This code will not execute correctly on this pipeline a) (5 pts) Show what the correct state of the pipeline should be at cycle i+1, i.e. what should be in each stage. IF ID EX MEM WB subi $2, $2, 4 beq $4, $6, loop <stall> add $4, $4, $7 add $4, $8, $9 b) (15 pts) Describe a general hardware solution to ensure correct execution when there are data hazards on branches. Clearly define i) the checks to be made, and ii) how they are implemented, i.e., what are the main functional blocks. It is probably easier to show additions to one of the figures. Check for hazards and insert the correct number of stalls. Hazards can occur when beq is in ID and rformat or lw instructions are in EX or MEM. Stalls ensure the producer instruction gets to WB since reads and writes can happen in the same cycle. Check dependencies between EX and ID and insert stall in EX if necessary: for both rformat and lw dependencies. Checks compare source and destination registers and check for instruction types, i.e., beq in ID and rformat or lw in EX. If ((ID/EX.ALUOp = 10) & (IF/ID.Opcode = beq)) & ((ID/EX.RegisterRd = IF/ID.RegisterRs) or (ID/EX.RegisterRd = IF/ID.RegisterRt)) Stall = 1; If (ID/EX.MemRead = 1) & ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) Stall =1; (The question notes that this check is already present).
4 Similar checks are performed between MEM and ID and may insert a stall in EX. Both EX and MEM checks could be concurrently positive - generate the logical OR of the outcome of the checks in each stage. There are also alternative combinations of variables for these checks but they look very similar. These checks will insert 1 or 2 stalls. Alternatively, one could add forwarding to ID from MEM and add checks between EX and ID. However, you still need a check between MEM and ID for lw.
5 3. (15 pts) To the base pipeline we add data forwarding to EX, data hazard detection with stall generation, and branches are implemented in MEM and predicted not taken with flushing. Consider the following code sequence in the pipeline at cycle 10. In the attached forwarding figure, ForwardA is the top mux and ForwardB is the bottom mux in the collateral. The inputs are numbered 00, 01, 10 from top to bottom. add $1, $2, $3 add $1, $1, $4 add $1, $1, $5 add $1, $1, $6 add $1, $1, $7 -- WB -- MEM -- EX -- ID -- IF a) (5 pts) What should be the value of ForwardA and ForwardB during cycles 10 and 11? cycle cycle cycle 11 _10 cycle The MEM stage will always have the latest value for $1. Hence rs will be forwarded from MEM. The mux value from the figure is 10. The rt value is unique, has not been updated, and therefore will be whatever was read form the register file hence the mux value (from the figure) will be 00. b) (10 pts) Now consider that we pipeline some stages in the interest of increasing the clock rate. For each approach separately, what are the number of clock cycles for the branch and load-to-use penalties? IF ID EX MEM WB Branch Penalty Load-to-Use Penalty i. MEM is pipelined to 3 stages 3 3_ ii. IF is pipelined to two stages 4 1_ iii. EX is pipelined to two stages 4 2 Pipelining MEM to 3 stages will not add to the penalty since the since a branch instruction will not need the result from MEM. The and gate will operate on the equality test result from EX in
6 the first cycle of MEM. However, the load-to-use penalty will need the result from MEM and hence will increase by 2 cycles. When IF is pipelined to 2 stages the branch penalty will increase by 1 cycle but the load-to-use does not increase since this test is between ID and EX. If EX is pipelined to 2 stages the branch penalty will increase by 1 cycle since the branch test has to complete and all a preceding stages flushed when taken. The load-to use will increase by 1 cycle. The hazard test can be performed in the first cycle of EX. However, there has to be a 2 cycle gap between the lw and the dependent instruction. When lw is in WB, the dependent instruction should be in the first cycle of EX.
7 4. (20 pts) To the base pipeline we add data forwarding to EX, data hazard detection with stall generation, and branches are implemented in MEM and predicted not taken with flushing. Consider the execution of the code below. First instruction is at 0x add $7, $0, $0 2 addi $5, $0, 72 3 addi $3, $0, x loop: lw $4, 0($3) 5 lw $9, -8($3) 6 lw $6, -4($3) 7 add $7, $6, $7 8 add $7, $9, $7 9 add $7, $4, $7 10 addi $3, $3, addi $5, $5, bne $5, $0, loop a. (10 pts) Identify all data and control hazards, i.e., I à J where I and J are instruction numbers Data hazard from 6à7 Control hazard on the bne The question is asking for hazards not dependencies. b. (10 pts) Fill in the values below for cycle 9 (start counting at 0!). Use the notation in the base pipeline in the collateral. Pipeline Signal Instruction in the stage Value IF/ID.PC4 add $7, $9, $7 0x ID/EX.ALUSrc add $7, $6, $7 0 ID/EX.RegDst add $7, $6, $7 1 EX/MEM.MEM.Address <stall> 0x1024 MEM/WB.MemToReg lw $6, -4($3) 1
8 5. (20 pts) Consider a 32 Kbyte direct mapped cache with 64 byte lines operating with 32-bit addresses. i. (5 pts) How many lines are there in the cache (2 15 / 6 ) = 2 9 = 512 lines ii. (5 pts) Show the breakdown of the address bits into fields used to address the cache iii. (10 pts) Consider a read to address 0x004000F8 that misses in the cache and is processed to bring the corresponding line into the cache. For each of the following addresses, if it is the next reference to the cache, identify whether it will be a reference to a word in the same line (Y/N). i. 0x N ii. 0x N iii. 0x004000C4 Y
9 6. (10 pts) To the base pipeline we add data forwarding to EX, branches are implemented in MEM, and support for jumps are implemented in ID. There is no hardware support for hazard detection or associated flushing/stall generation. Compiler support maintains correctness via the insertion of nops for any possible data or control hazards. Executing programs result in the following statistics. 40% of branches are taken and 20% of all load operations produce a hazard. The compiler can reorganize the code to fill 60% of branch delay slots, 30% of the jump delay slots, and 50% of load delay slots. What is the improvement in execution time achieved by such instruction scheduling? Assume a base CPI of 1.0. You may leave answers in expression form. Instruction Frequency Loads 22% Stores 13% ALU 42% Operations Branches 18% Jumps 5% EX 1 = #I * CPI 1 * clock_cycle CPI 1 = CPI base * 0.2 * * * 1 = = Note that the branch taken probability does not matter. There is no hazard detection so every branch will incur a 3-cycle penalty. The load-to-use and jump penalties are 1 cycle. CPI 2 = CPI base * 0.2 * 0.5 * * 0.4 * * 0.7 * 1 = = Without flushing every branch will incur a penalty, but this penalty has been reduced by 60% with instruction scheduling. Similarly the load-to-use and jump-penalties have been reduced. EX 2 = #I * CPI 2 * clock_cycle Improvement in execution time = EX 1 - EX 2
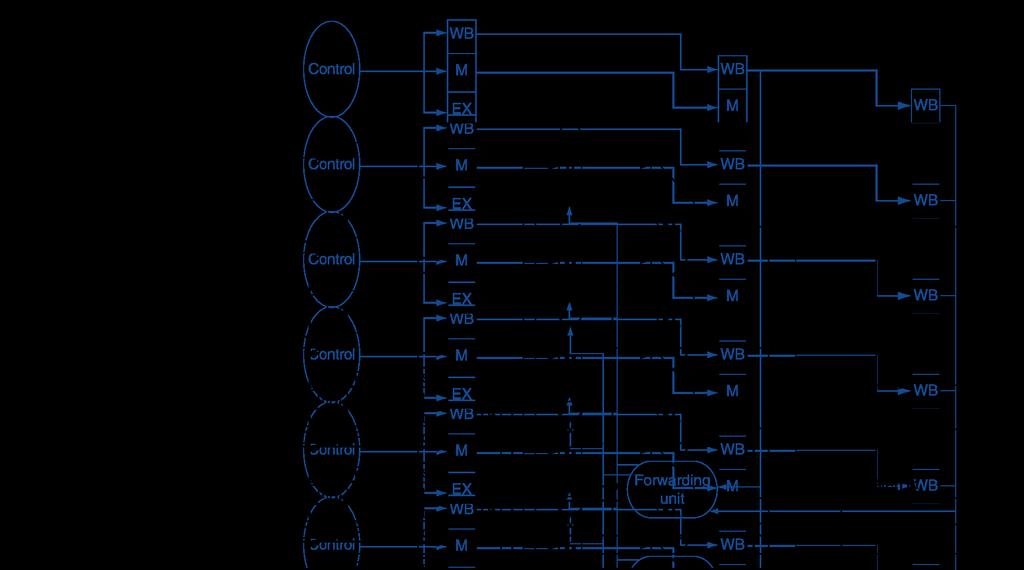

10 Forwarding Paths
ECE Exam II - Solutions October 30 th, :35 pm 5:55pm
 ECE 3056 Exam II - Solutions October 30 th, 2013 4:35 pm 5:55pm 1. (20 pts) Consider the pipelined SPIM datapath with forwarding and branches are predicted as not taken. Assume branch instructions occur
ECE 3056 Exam II - Solutions October 30 th, 2013 4:35 pm 5:55pm 1. (20 pts) Consider the pipelined SPIM datapath with forwarding and branches are predicted as not taken. Assume branch instructions occur
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
ECE260: Fundamentals of Computer Engineering
 Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Question 1: (20 points) For this question, refer to the following pipeline architecture.
 For this question, refer to the following pipeline architecture.") This is the Mid Term exam given in Fall 2018. Note that Question 2(a) was a homework problem this term (was not a homework problem in Fall 2018). Also, Questions 6, 7 and half of 5 are from Chapter 5,
This is the Mid Term exam given in Fall 2018. Note that Question 2(a) was a homework problem this term (was not a homework problem in Fall 2018). Also, Questions 6, 7 and half of 5 are from Chapter 5,
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
LECTURE 9. Pipeline Hazards
 LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
ECE 3056: Architecture, Concurrency, and Energy of Computation. Sample Problem Sets: Pipelining
 ECE 3056: Architecture, Concurrency, and Energy of Computation Sample Problem Sets: Pipelining 1. Consider the following code sequence used often in block copies. This produces a special form of the load
ECE 3056: Architecture, Concurrency, and Energy of Computation Sample Problem Sets: Pipelining 1. Consider the following code sequence used often in block copies. This produces a special form of the load
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
EE557--FALL 1999 MIDTERM 1. Closed books, closed notes
 NAME: SOLUTIONS STUDENT NUMBER: EE557--FALL 1999 MIDTERM 1 Closed books, closed notes GRADING POLICY: The front page of your exam shows your total numerical score out of 75. The highest numerical score
NAME: SOLUTIONS STUDENT NUMBER: EE557--FALL 1999 MIDTERM 1 Closed books, closed notes GRADING POLICY: The front page of your exam shows your total numerical score out of 75. The highest numerical score
OPEN BOOK, OPEN NOTES. NO COMPUTERS, OR SOLVING PROBLEMS DIRECTLY USING CALCULATORS.
 CS/ECE472 Midterm #2 Fall 2008 NAME: Student ID#: OPEN BOOK, OPEN NOTES. NO COMPUTERS, OR SOLVING PROBLEMS DIRECTLY USING CALCULATORS. Your signature is your promise that you have not cheated and will
CS/ECE472 Midterm #2 Fall 2008 NAME: Student ID#: OPEN BOOK, OPEN NOTES. NO COMPUTERS, OR SOLVING PROBLEMS DIRECTLY USING CALCULATORS. Your signature is your promise that you have not cheated and will
CS 251, Winter 2018, Assignment % of course mark
 CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture.
 zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
Computer Architecture CS372 Exam 3
 Name: Computer Architecture CS372 Exam 3 This exam has 7 pages. Please make sure you have all of them. Write your name on this page and initials on every other page now. You may only use the green card
Name: Computer Architecture CS372 Exam 3 This exam has 7 pages. Please make sure you have all of them. Write your name on this page and initials on every other page now. You may only use the green card
ECE Sample Final Examination
 ECE 3056 Sample Final Examination 1 Overview The following applies to all problems unless otherwise explicitly stated. Consider a 2 GHz MIPS processor with a canonical 5-stage pipeline and 32 general-purpose
ECE 3056 Sample Final Examination 1 Overview The following applies to all problems unless otherwise explicitly stated. Consider a 2 GHz MIPS processor with a canonical 5-stage pipeline and 32 general-purpose
CS/CoE 1541 Mid Term Exam (Fall 2018).
.") CS/CoE 1541 Mid Term Exam (Fall 2018). Name: Question 1: (6+3+3+4+4=20 points) For this question, refer to the following pipeline architecture. a) Consider the execution of the following code (5 instructions)
CS/CoE 1541 Mid Term Exam (Fall 2018). Name: Question 1: (6+3+3+4+4=20 points) For this question, refer to the following pipeline architecture. a) Consider the execution of the following code (5 instructions)
CENG 3531 Computer Architecture Spring a. T / F A processor can have different CPIs for different programs.
 Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
高雄大學資訊工程系計算機組織期末考. and (MEM/WB.RegRd=ID/EX.RegRt))
)") 高雄大學資訊工程系計算機組織期末考 學號 : 姓名 : 1. (12%) Please explain the three types of hazards in pipelining: (a) Structural hazards (b) Data hazards (c) Control hazards Structural hazards: Hardware cannot support this
高雄大學資訊工程系計算機組織期末考 學號 : 姓名 : 1. (12%) Please explain the three types of hazards in pipelining: (a) Structural hazards (b) Data hazards (c) Control hazards Structural hazards: Hardware cannot support this
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12
 Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Computer Organization and Structure
 Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12 (2) Lecture notes from MKP, H. H. Lee and S.
 Lecture notes from MKP, H. H. Lee and S.") Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Final Exam Fall 2007
 ICS 233 - Computer Architecture & Assembly Language Final Exam Fall 2007 Wednesday, January 23, 2007 7:30 am 10:00 am Computer Engineering Department College of Computer Sciences & Engineering King Fahd
ICS 233 - Computer Architecture & Assembly Language Final Exam Fall 2007 Wednesday, January 23, 2007 7:30 am 10:00 am Computer Engineering Department College of Computer Sciences & Engineering King Fahd
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
CS 251, Winter 2019, Assignment % of course mark
 CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Unresolved data hazards. CS2504, Spring'2007 Dimitris Nikolopoulos
 Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions
 CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions Tutorial Questions 2. [AY2014/5 Semester 2 Exam] Refer to the following MIPS program: # register $s0 contains a 32-bit
CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions Tutorial Questions 2. [AY2014/5 Semester 2 Exam] Refer to the following MIPS program: # register $s0 contains a 32-bit
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
ECE473 Computer Architecture and Organization. Pipeline: Data Hazards
 Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
Final Exam Spring 2017
 COE 3 / ICS 233 Computer Organization Final Exam Spring 27 Friday, May 9, 27 7:3 AM Computer Engineering Department College of Computer Sciences & Engineering King Fahd University of Petroleum & Minerals
COE 3 / ICS 233 Computer Organization Final Exam Spring 27 Friday, May 9, 27 7:3 AM Computer Engineering Department College of Computer Sciences & Engineering King Fahd University of Petroleum & Minerals
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Final Exam Fall 2008
 COE 308 Computer Architecture Final Exam Fall 2008 page 1 of 8 Saturday, February 7, 2009 7:30 10:00 AM Computer Engineering Department College of Computer Sciences & Engineering King Fahd University of
COE 308 Computer Architecture Final Exam Fall 2008 page 1 of 8 Saturday, February 7, 2009 7:30 10:00 AM Computer Engineering Department College of Computer Sciences & Engineering King Fahd University of
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
Processor Design Pipelined Processor (II) Hung-Wei Tseng
 Hung-Wei Tseng") Processor Design Pipelined Processor (II) Hung-Wei Tseng Recap: Pipelining Break up the logic with pipeline registers into pipeline stages Each pipeline registers is clocked Each pipeline stage takes one
Processor Design Pipelined Processor (II) Hung-Wei Tseng Recap: Pipelining Break up the logic with pipeline registers into pipeline stages Each pipeline registers is clocked Each pipeline stage takes one
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
The University of Alabama in Huntsville Electrical & Computer Engineering Department CPE Test II November 14, 2000
 The University of Alabama in Huntsville Electrical & Computer Engineering Department CPE 513 01 Test II November 14, 2000 Name: 1. (5 points) For an eight-stage pipeline, how many cycles does it take to
The University of Alabama in Huntsville Electrical & Computer Engineering Department CPE 513 01 Test II November 14, 2000 Name: 1. (5 points) For an eight-stage pipeline, how many cycles does it take to
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
5008: Computer Architecture HW#2
 5008: Computer Architecture HW#2 1. We will now support for register-memory ALU operations to the classic five-stage RISC pipeline. To offset this increase in complexity, all memory addressing will be
5008: Computer Architecture HW#2 1. We will now support for register-memory ALU operations to the classic five-stage RISC pipeline. To offset this increase in complexity, all memory addressing will be
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
EE557--FALL 1999 MAKE-UP MIDTERM 1. Closed books, closed notes
 NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
14:332:331 Pipelined Datapath
 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
CSE Lecture 13/14 In Class Handout For all of these problems: HAS NOT CANNOT Add Add Add must wait until $5 written by previous add;
 CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
CIS 662: Midterm. 16 cycles, 6 stalls
 CIS 662: Midterm Name: Points: /100 First read all the questions carefully and note how many points each question carries and how difficult it is. You have 1 hour 15 minutes. Plan your time accordingly.
CIS 662: Midterm Name: Points: /100 First read all the questions carefully and note how many points each question carries and how difficult it is. You have 1 hour 15 minutes. Plan your time accordingly.
CS/CoE 1541 Exam 1 (Spring 2019).
.") CS/CoE 1541 Exam 1 (Spring 2019). Name: Question 1 (8+2+2+3=15 points): In this problem, consider the execution of the following code segment on a 5-stage pipeline with forwarding/stalling hardware and
CS/CoE 1541 Exam 1 (Spring 2019). Name: Question 1 (8+2+2+3=15 points): In this problem, consider the execution of the following code segment on a 5-stage pipeline with forwarding/stalling hardware and
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
CPE 335 Computer Organization. Basic MIPS Pipelining Part I
 CPE 335 Computer Organization Basic MIPS Pipelining Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Pipelining
CPE 335 Computer Organization Basic MIPS Pipelining Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Pipelining
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 6 Exercises with solutions
 Islamic University Gaza Engineering Faculty Department of Computer Engineering ECOM 3010: Computer Architecture Discussion Chapter 6 Exercises with solutions Eng. Eman R. Habib December, 2013 2 Computer
Islamic University Gaza Engineering Faculty Department of Computer Engineering ECOM 3010: Computer Architecture Discussion Chapter 6 Exercises with solutions Eng. Eman R. Habib December, 2013 2 Computer
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
c. What are the machine cycle times (in nanoseconds) of the non-pipelined and the pipelined implementations?
 of the non-pipelined and the pipelined implementations?") Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
ECE/CS 552: Pipeline Hazards
 ECE/CS 552: Pipeline Hazards Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Pipeline Hazards Forecast Program Dependences
ECE/CS 552: Pipeline Hazards Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Pipeline Hazards Forecast Program Dependences
CS232 Final Exam May 5, 2001
 CS232 Final Exam May 5, 2 Name: This exam has 4 pages, including this cover. There are six questions, worth a total of 5 points. You have 3 hours. Budget your time! Write clearly and show your work. State
CS232 Final Exam May 5, 2 Name: This exam has 4 pages, including this cover. There are six questions, worth a total of 5 points. You have 3 hours. Budget your time! Write clearly and show your work. State
CS 230 Practice Final Exam & Actual Take-home Question. Part I: Assembly and Machine Languages (22 pts)
") Part I: Assembly and Machine Languages (22 pts) 1. Assume that assembly code for the following variable definitions has already been generated (and initialization of A and length). int powerof2; /* powerof2
Part I: Assembly and Machine Languages (22 pts) 1. Assume that assembly code for the following variable definitions has already been generated (and initialization of A and length). int powerof2; /* powerof2
Pipeline Data Hazards. Dealing With Data Hazards
 Pipeline Data Hazards Warning, warning, warning! Dealing With Data Hazards In Software inserting independent instructions In Hardware inserting bubbles (stalling the pipeline) data forwarding Data Data
Pipeline Data Hazards Warning, warning, warning! Dealing With Data Hazards In Software inserting independent instructions In Hardware inserting bubbles (stalling the pipeline) data forwarding Data Data
ECE260: Fundamentals of Computer Engineering
 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
ECE 2300 Digital Logic & Computer Organization. Caches
 ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COSC121: Computer Systems. ISA and Performance
 COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
Pipelined datapath Staging data. CS2504, Spring'2007 Dimitris Nikolopoulos
 Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Processor Design Pipelined Processor. Hung-Wei Tseng
 Processor Design Pipelined Processor Hung-Wei Tseng Pipelining 7 Pipelining Break up the logic with isters into pipeline stages Each stage can act on different instruction/data States/Control signals of
Processor Design Pipelined Processor Hung-Wei Tseng Pipelining 7 Pipelining Break up the logic with isters into pipeline stages Each stage can act on different instruction/data States/Control signals of
The University of Michigan - Department of EECS EECS 370 Introduction to Computer Architecture Midterm Exam 2 solutions April 5, 2011
 1. Performance Principles [5 pts] The University of Michigan - Department of EECS EECS 370 Introduction to Computer Architecture Midterm Exam 2 solutions April 5, 2011 For each of the following comparisons,
1. Performance Principles [5 pts] The University of Michigan - Department of EECS EECS 370 Introduction to Computer Architecture Midterm Exam 2 solutions April 5, 2011 For each of the following comparisons,
Lecture 9 Pipeline and Cache
 Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
CS3350B Computer Architecture Quiz 3 March 15, 2018
 CS3350B Computer Architecture Quiz 3 March 15, 2018 Student ID number: Student Last Name: Question 1.1 1.2 1.3 2.1 2.2 2.3 Total Marks The quiz consists of two exercises. The expected duration is 30 minutes.
CS3350B Computer Architecture Quiz 3 March 15, 2018 Student ID number: Student Last Name: Question 1.1 1.2 1.3 2.1 2.2 2.3 Total Marks The quiz consists of two exercises. The expected duration is 30 minutes.
CMSC411 Fall 2013 Midterm 1
 CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
Lecture 8: Data Hazard and Resolution. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 8: Data Hazard and Resolution James C. Hoe Department of ECE Carnegie ellon University 18 447 S18 L08 S1, James C. Hoe, CU/ECE/CALC, 2018 Your goal today Housekeeping detect and resolve
18 447 Lecture 8: Data Hazard and Resolution James C. Hoe Department of ECE Carnegie ellon University 18 447 S18 L08 S1, James C. Hoe, CU/ECE/CALC, 2018 Your goal today Housekeeping detect and resolve
cs470 - Computer Architecture 1 Spring 2002 Final Exam open books, open notes
 1 of 7 ay 13, 2002 v2 Spring 2002 Final Exam open books, open notes Starts: 7:30 pm Ends: 9:30 pm Name: (please print) ID: Problem ax points Your mark Comments 1 10 5+5 2 40 10+5+5+10+10 3 15 5+10 4 10
1 of 7 ay 13, 2002 v2 Spring 2002 Final Exam open books, open notes Starts: 7:30 pm Ends: 9:30 pm Name: (please print) ID: Problem ax points Your mark Comments 1 10 5+5 2 40 10+5+5+10+10 3 15 5+10 4 10