ORAP Forum October 10, 2013
|
|
|
- Melanie McDaniel
- 5 years ago
- Views:
Transcription


1 Towards Petaflop simulations of core collapse supernovae ORAP Forum October 10, 2013 Andreas Marek 1 together with Markus Rampp 1, Florian Hanke 2, and Thomas Janka 2 1 Rechenzentrum der Max-Planck-Gesellschaft 2 Max-Planck Institut für Astrophysik
2 Content Supernova modelling: the challenges The VERTEX code Scaling Performance Conclusions

3 How to understand them

4 Supernova modeling
5 The challenges: The curse of dimensions - Boltzmann equation determines the neutrino distribution function f(r,,,,,,t) - Integration in momentum space: source terms for hydrodynamics Q(r,,,t), dy e (r,,,t)/dt r Solution approach 3D hydro + 6D direct discretization of Boltzmann Eq. (code development by Sumiyoshi & Yamada 2012) 3D hydro + two-moment closure of Boltzmann Eq. (next feasible step to full 3D; cf. Kuroda et al. 2012) 2D or 3D hydro + ray-by-ray-plus variable Eddington factor method (MPA, RZG) Required resources >= PFlop/s (sustained!) >= 1 10 PFlop/s >= 0.1 TFlop/s 1 TFlop/s (2D) >= 0.1 Pflop/s 1 PFlop/s (3D)
6 Computing requirements for current simulations ORAP Forum, October D and 3D supernova modeling Time dependent simulations: t ~ 1 second, ~ 10 6 timesteps CPU-time requirements for one model run In 2D with 600 radial zones, 1 degree lateral resolution ~ 3 *10 18 Flops, about 10 6 processor-core hours In 3D with 600 radial zones, 1.5 degree angular resolution ~ 3 *10 20 Flops, about 10 8 processor-core hours and in the near future with increased resultion this will be at least 3 times more

7 The VERTEX code : Setup Hybrid MPI/OpenMP parallelized version of VERTEX VERTEX works on a spherical grid Hydro module fully MPI parallelized Transport module MPI + OpenMP coarse grain parallelization along ``angular rays MPI couples rays

8 Mapping onto the processor grid Example: BG/P Node 1 1 MPI-Task 4 Threads in the node: 1 angular ray per Core
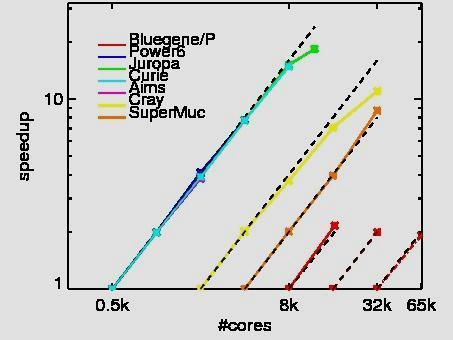

9 Scaling

10 Performance Estimate: Roofline model memory BW peak performance optimization of memory references Measurement: Intel Nehalem node, GHz, SSE4.2 done with the ``likwid,``perflib, and ``PAPI => VERTEX is ``memory bound runs ~ 12.5% of peak performance
11 Performance: SandyBridge cores Performance on 131k cores of SuperMuc: 8192 nodes => ~ PFlop/s on LRZ`s SuperMUC ~ 9 % of peak performance
12 Scaling: development Ken Batcher: A supercomputer is a device for turning compute-bound problems into I/O-bound data-transfer-bound problems problems Each factor of 2 higher core counts, produced memory issues to solve => rewrite memory layout that it scales => hybrid OpenMP/MPI reduced memory of MPI buffers MPI communication times do not necessarily scale => again: hybrid was helpful IO is always an issue! VERTEX uses parallel HDF-5, which does not always work optimal on a new machine => cooperation between computer center, machine vendor etc. necessary
13 Challenges of for the future Ken Batcher: A supercomputer is a device for turning compute-bound problems into I/O-bound problems data-transfer-bound problems in the future data movement will be the problem for good scaling - problem of MPI at large scales? - memory per cores will still decrease - data transfer within a node (scaling within a traditional node ) - OpenMP scaling (e.g. Xeon PHI) - data transfer to accelerator cards (Xeon PHI, GPU) => think of (and rewrite) memory layout that it scales on many core nodes as well as s of nodes Other issue: robustness of machines
14 ParCo2013, September 2013 Further Code development Even stronger scaling capability needed: The next or next-next supernova models will need even more computing power! ``Traditional development: usage of more cores at the moment another third parallelization level is implemented => within one ``ray a nested OpenMP workload is possible => use 10 to 20 times more cores Accelerator cards development: the usage of GPUs and Xeon Phi is tested => GPU implementation already shows promising results => factor 2 achieved, 3 seems possible
15 Current Code improvements
16 Load-Balancing (Host only) thread 1 thread 2 thread 3 thread 4 rate Rate 11 Rate rate 1 Rate rate 1 Rate rate 1 rate Rate 22 Rate rate 2 Rate rate 2 Rate rate 2 rate Rate 33 Rate rate 3 Rate rate 3 Rate rate 3 rate Rate KJT 4 Rate rate KJT 4 Rate rate KJT 4 Rate rate KJT 4 = running
17 Load-Balancing (HOST + GPU) thread 1 thread 2 thread 3 thread 4 rate Rate 1 rate Rate 1 rate 1 Rate rate 1 rate Rate 2 rate 2 Rate rate 2 Rate rate 2 rate 3 rate Rate 3 rate Rate 3 Rate rate 3 Rate rate KJT 4 (GPU) Rate rate KJT 4 (GPU) Rate rate KJT 4 (GPU) rate KJT (GPU)
18 Summary We have demonstrated the need of supernova research for high end HPC computing at the moment production runs are done on 16k -32k cores, the next generation of models will need about 65k 100k cores However, we have demonstrated that VERTEX scales already now on 131k cores of LRZ`s SuperMuc (and on Bluegene/P) VERTEX operates with ~ 10% of the peak performance on Intel Sandybridge nodes The next generation of VERTEX is already under development - nested OpenMP level: about 1 to 2 Mcores might be used - usage of accelerator cards: * GPU acceleration: speedup of 2 achieved 3 possible * Xeon PHI: still under investigation
19 Questions?
20
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
GPU computing at RZG overview & some early performance results. Markus Rampp
 GPU computing at RZG overview & some early performance results Markus Rampp Introduction Outline Hydra configuration overview GPU software environment Benchmarking and porting activities Team Renate Dohmen
GPU computing at RZG overview & some early performance results Markus Rampp Introduction Outline Hydra configuration overview GPU software environment Benchmarking and porting activities Team Renate Dohmen
ICON for HD(CP) 2. High Definition Clouds and Precipitation for Advancing Climate Prediction
 2. High Definition Clouds and Precipitation for Advancing Climate Prediction") ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
RAMSES on the GPU: An OpenACC-Based Approach
 RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
Knights Landing Scalability and the Role of Hybrid Parallelism
 Knights Landing Scalability and the Role of Hybrid Parallelism Sergi Siso 1, Aidan Chalk 1, Alin Elena 2, James Clark 1, Luke Mason 1 1 Hartree Centre @ STFC - Daresbury Labs 2 Scientific Computing Department
Knights Landing Scalability and the Role of Hybrid Parallelism Sergi Siso 1, Aidan Chalk 1, Alin Elena 2, James Clark 1, Luke Mason 1 1 Hartree Centre @ STFC - Daresbury Labs 2 Scientific Computing Department
Massively Parallel Phase Field Simulations using HPC Framework walberla
 Massively Parallel Phase Field Simulations using HPC Framework walberla SIAM CSE 2015, March 15 th 2015 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer, Harald Köstler and Ulrich
Massively Parallel Phase Field Simulations using HPC Framework walberla SIAM CSE 2015, March 15 th 2015 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer, Harald Köstler and Ulrich
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Visualization Support at RZG
 Visualization Support at RZG Markus Rampp (RZG) mjr@rzg.mpg.de MPA Computer Seminar, Jan 14, 2009 Outline Topics Overview Existing services Some example projects Software overview & demo Remote visualization
Visualization Support at RZG Markus Rampp (RZG) mjr@rzg.mpg.de MPA Computer Seminar, Jan 14, 2009 Outline Topics Overview Existing services Some example projects Software overview & demo Remote visualization
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Programming Techniques for Supercomputers
 Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b) Dr. G. Hager (a) Dr.-Ing. M. Wittmann (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University
Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b) Dr. G. Hager (a) Dr.-Ing. M. Wittmann (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
simulation framework for piecewise regular grids
 WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Parallel 3D Sweep Kernel with PaRSEC
 Parallel 3D Sweep Kernel with PaRSEC Salli Moustafa Mathieu Faverge Laurent Plagne Pierre Ramet 1 st International Workshop on HPC-CFD in Energy/Transport Domains August 22, 2014 Overview 1. Cartesian
Parallel 3D Sweep Kernel with PaRSEC Salli Moustafa Mathieu Faverge Laurent Plagne Pierre Ramet 1 st International Workshop on HPC-CFD in Energy/Transport Domains August 22, 2014 Overview 1. Cartesian
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms
 The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
PSE Molekulardynamik
 OpenMP, Multicore Architectures, PAPI 21.12.2012 Outline Schedule Presentations: Worksheet 4 OpenMP Multicore Architectures PAPI Membrane, Crystallization Preparation: Worksheet 5 2 Schedule (big meetings)
OpenMP, Multicore Architectures, PAPI 21.12.2012 Outline Schedule Presentations: Worksheet 4 OpenMP Multicore Architectures PAPI Membrane, Crystallization Preparation: Worksheet 5 2 Schedule (big meetings)
Scientific Visualization Services at RZG
 Scientific Visualization Services at RZG Klaus Reuter, Markus Rampp klaus.reuter@rzg.mpg.de Garching Computing Centre (RZG) 7th GOTiT High Level Course, Garching, 2010 Outline 1 Introduction 2 Details
Scientific Visualization Services at RZG Klaus Reuter, Markus Rampp klaus.reuter@rzg.mpg.de Garching Computing Centre (RZG) 7th GOTiT High Level Course, Garching, 2010 Outline 1 Introduction 2 Details
Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ)
") Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ) Overview Modernising P-Gadget3 for the Intel Xeon Phi : code features, challenges and strategy for
Towards modernisation of the Gadget code on many-core architectures Fabio Baruffa, Luigi Iapichino (LRZ) Overview Modernising P-Gadget3 for the Intel Xeon Phi : code features, challenges and strategy for
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla
 Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
HPC Architectures past,present and emerging trends
 HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Performance of the hybrid MPI/OpenMP version of the HERACLES code on the Curie «Fat nodes» system
 Performance of the hybrid MPI/OpenMP version of the HERACLES code on the Curie «Fat nodes» system Edouard Audit, Matthias Gonzalez, Pierre Kestener and Pierre-François Lavallé The HERACLES code Fixed grid
Performance of the hybrid MPI/OpenMP version of the HERACLES code on the Curie «Fat nodes» system Edouard Audit, Matthias Gonzalez, Pierre Kestener and Pierre-François Lavallé The HERACLES code Fixed grid
Compilation for Heterogeneous Platforms
 Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model
 www.bsc.es Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model HPC Knowledge Meeting'15 George S. Markomanolis, Jesus Labarta, Oriol Jorba University of Barcelona, Barcelona,
www.bsc.es Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model HPC Knowledge Meeting'15 George S. Markomanolis, Jesus Labarta, Oriol Jorba University of Barcelona, Barcelona,
READEX: A Tool Suite for Dynamic Energy Tuning. Michael Gerndt Technische Universität München
 READEX: A Tool Suite for Dynamic Energy Tuning Michael Gerndt Technische Universität München Campus Garching 2 SuperMUC: 3 Petaflops, 3 MW 3 READEX Runtime Exploitation of Application Dynamism for Energy-efficient
READEX: A Tool Suite for Dynamic Energy Tuning Michael Gerndt Technische Universität München Campus Garching 2 SuperMUC: 3 Petaflops, 3 MW 3 READEX Runtime Exploitation of Application Dynamism for Energy-efficient
HPC Resources & Training
 www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
AACE: Applications. Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn-
 AACE: Applications R. Glenn Brook Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn- brook@tennessee.edu Ryan C. Hulguin Computational Science
AACE: Applications R. Glenn Brook Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn- brook@tennessee.edu Ryan C. Hulguin Computational Science
John Hengeveld Director of Marketing, HPC Evangelist
 MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Improved Event Generation at NLO and NNLO. or Extending MCFM to include NNLO processes
 Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Splotch: High Performance Visualization using MPI, OpenMP and CUDA
 Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Mixed MPI-OpenMP EUROBEN kernels
 Mixed MPI-OpenMP EUROBEN kernels Filippo Spiga ( on behalf of CINECA ) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany Outline Short kernel description MPI and OpenMP
Mixed MPI-OpenMP EUROBEN kernels Filippo Spiga ( on behalf of CINECA ) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany Outline Short kernel description MPI and OpenMP
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
High Performance Ocean Modeling using CUDA
 using CUDA Chris Lupo Computer Science Cal Poly Slide 1 Acknowledgements Dr. Paul Choboter Jason Mak Ian Panzer Spencer Lines Sagiv Sheelo Jake Gardner Slide 2 Background Joint research with Dr. Paul Choboter
using CUDA Chris Lupo Computer Science Cal Poly Slide 1 Acknowledgements Dr. Paul Choboter Jason Mak Ian Panzer Spencer Lines Sagiv Sheelo Jake Gardner Slide 2 Background Joint research with Dr. Paul Choboter
Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture. Alexander Berreth. Markus Bühler, Benedikt Anlauf
 PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland
PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Transport Simulations beyond Petascale. Jing Fu (ANL)
") Transport Simulations beyond Petascale Jing Fu (ANL) A) Project Overview The project: Peta- and exascale algorithms and software development (petascalable codes: Nek5000, NekCEM, NekLBM) Science goals:
Transport Simulations beyond Petascale Jing Fu (ANL) A) Project Overview The project: Peta- and exascale algorithms and software development (petascalable codes: Nek5000, NekCEM, NekLBM) Science goals:
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Optimization of finite-difference kernels on multi-core architectures for seismic applications
 Optimization of finite-difference kernels on multi-core architectures for seismic applications V. Etienne 1, T. Tonellot 1, K. Akbudak 2, H. Ltaief 2, S. Kortas 3, T. Malas 4, P. Thierry 4, D. Keyes 2
Optimization of finite-difference kernels on multi-core architectures for seismic applications V. Etienne 1, T. Tonellot 1, K. Akbudak 2, H. Ltaief 2, S. Kortas 3, T. Malas 4, P. Thierry 4, D. Keyes 2
International Conference Russian Supercomputing Days. September 25-26, 2017, Moscow
 International Conference Russian Supercomputing Days September 25-26, 2017, Moscow International Conference Russian Supercomputing Days Supported by the Russian Foundation for Basic Research Platinum Sponsor
International Conference Russian Supercomputing Days September 25-26, 2017, Moscow International Conference Russian Supercomputing Days Supported by the Russian Foundation for Basic Research Platinum Sponsor
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
The determination of the correct
 SPECIAL High-performance SECTION: H i gh-performance computing computing MARK NOBLE, Mines ParisTech PHILIPPE THIERRY, Intel CEDRIC TAILLANDIER, CGGVeritas (formerly Mines ParisTech) HENRI CALANDRA, Total
SPECIAL High-performance SECTION: H i gh-performance computing computing MARK NOBLE, Mines ParisTech PHILIPPE THIERRY, Intel CEDRIC TAILLANDIER, CGGVeritas (formerly Mines ParisTech) HENRI CALANDRA, Total
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
High-performance computing technological trends and programming challenges
 High-performance computing technological trends and programming challenges Markus Rampp Max Planck Computing and Data Facility (MPCDF) HPC applications group Topics where we are technologically - in scientific
High-performance computing technological trends and programming challenges Markus Rampp Max Planck Computing and Data Facility (MPCDF) HPC applications group Topics where we are technologically - in scientific
walberla: Developing a Massively Parallel HPC Framework
 walberla: Developing a Massively Parallel HPC Framework SIAM CS&E 2013, Boston February 26, 2013 Florian Schornbaum*, Christian Godenschwager*, Martin Bauer*, Matthias Markl, Ulrich Rüde* *Chair for System
walberla: Developing a Massively Parallel HPC Framework SIAM CS&E 2013, Boston February 26, 2013 Florian Schornbaum*, Christian Godenschwager*, Martin Bauer*, Matthias Markl, Ulrich Rüde* *Chair for System
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
FUSION PROCESSORS AND HPC
 FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters
 PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters IEEE CLUSTER 2015 Chicago, IL, USA Luis Sant Ana 1, Daniel Cordeiro 2, Raphael Camargo 1 1 Federal University of ABC,
PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters IEEE CLUSTER 2015 Chicago, IL, USA Luis Sant Ana 1, Daniel Cordeiro 2, Raphael Camargo 1 1 Federal University of ABC,
AutoTune Workshop. Michael Gerndt Technische Universität München
 AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Numerical Algorithm Co-Design multi-scale simulation at extreme scale
 Co-Design 2014, Guangzhou, Nov. 6-8 Numerical Algorithm Co-Design multi-scale simulation at extreme scale Wei Ge Institute of Process Engineering (IPE), CAS Co-Design 2014, Guangzhou, Nov. 6-8 Co-Design
Co-Design 2014, Guangzhou, Nov. 6-8 Numerical Algorithm Co-Design multi-scale simulation at extreme scale Wei Ge Institute of Process Engineering (IPE), CAS Co-Design 2014, Guangzhou, Nov. 6-8 Co-Design
Accelerating Insights In the Technical Computing Transformation
 Accelerating Insights In the Technical Computing Transformation Dr. Rajeeb Hazra Vice President, Data Center Group General Manager, Technical Computing Group June 2014 TOP500 Highlights Intel Xeon Phi
Accelerating Insights In the Technical Computing Transformation Dr. Rajeeb Hazra Vice President, Data Center Group General Manager, Technical Computing Group June 2014 TOP500 Highlights Intel Xeon Phi
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
Outline 1 Motivation 2 Theory of a non-blocking benchmark 3 The benchmark and results 4 Future work
 Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Experiences with GPGPUs at HLRS
 ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: Experiences with GPGPUs at HLRS Stefan Wesner, Managing Director High
::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: ::::: Experiences with GPGPUs at HLRS Stefan Wesner, Managing Director High
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu
 Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
Accelerating Octo-Tiger: Stellar Mergers on Intel Knights Landing with HPX
 Accelerating Octo-Tiger: Stellar Mergers on Intel Knights Landing with HPX David Pfander*, Gregor Daiß*, Dominic Marcello**, Hartmut Kaiser**, Dirk Pflüger* * University of Stuttgart ** Louisiana State
Accelerating Octo-Tiger: Stellar Mergers on Intel Knights Landing with HPX David Pfander*, Gregor Daiß*, Dominic Marcello**, Hartmut Kaiser**, Dirk Pflüger* * University of Stuttgart ** Louisiana State
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Profile analysis with CUBE. David Böhme, Markus Geimer German Research School for Simulation Sciences Jülich Supercomputing Centre
 Profile analysis with CUBE David Böhme, Markus Geimer German Research School for Simulation Sciences Jülich Supercomputing Centre CUBE Parallel program analysis report exploration tools Libraries for XML
Profile analysis with CUBE David Böhme, Markus Geimer German Research School for Simulation Sciences Jülich Supercomputing Centre CUBE Parallel program analysis report exploration tools Libraries for XML
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace
 Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace James Southern, Jim Tuccillo SGI 25 October 2016 0 Motivation Trend in HPC continues to be towards more
Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace James Southern, Jim Tuccillo SGI 25 October 2016 0 Motivation Trend in HPC continues to be towards more
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
What Could Deskside Supercomputers Do For The Power Grid?
 What Could Deskside Supercomputers Do For The Power Grid? Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com Joint work with Tao Cui and Cory Thoma
What Could Deskside Supercomputers Do For The Power Grid? Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com Joint work with Tao Cui and Cory Thoma
RZG Visualisation Infrastructure
 Visualisation of Large Data Sets on Supercomputers RZG Visualisation Infrastructure Markus Rampp Computing Centre (RZG) of the Max-Planck-Society and IPP markus.rampp@rzg.mpg.de LRZ/RZG Course on Visualisation
Visualisation of Large Data Sets on Supercomputers RZG Visualisation Infrastructure Markus Rampp Computing Centre (RZG) of the Max-Planck-Society and IPP markus.rampp@rzg.mpg.de LRZ/RZG Course on Visualisation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Simulation using MIC co-processor on Helios
 Simulation using MIC co-processor on Helios Serhiy Mochalskyy, Roman Hatzky PRACE PATC Course: Intel MIC Programming Workshop High Level Support Team Max-Planck-Institut für Plasmaphysik Boltzmannstr.
Simulation using MIC co-processor on Helios Serhiy Mochalskyy, Roman Hatzky PRACE PATC Course: Intel MIC Programming Workshop High Level Support Team Max-Planck-Institut für Plasmaphysik Boltzmannstr.
SIMD Exploitation in (JIT) Compilers
 Compilers") SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
DEVITO AUTOMATED HIGH-PERFORMANCE FINITE DIFFERENCES FOR GEOPHYSICAL EXPLORATION
 DEVITO AUTOMATED HIGH-PERFORMANCE FINITE DIFFERENCES FOR GEOPHYSICAL EXPLORATION F. Luporini 1, C. Yount 4, M. Louboutin 3, N. Kukreja 1, P. Witte 2, M. Lange 5, P. Kelly 1, F. Herrmann 3, G.Gorman 1 1Imperial
DEVITO AUTOMATED HIGH-PERFORMANCE FINITE DIFFERENCES FOR GEOPHYSICAL EXPLORATION F. Luporini 1, C. Yount 4, M. Louboutin 3, N. Kukreja 1, P. Witte 2, M. Lange 5, P. Kelly 1, F. Herrmann 3, G.Gorman 1 1Imperial
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Accelerated Earthquake Simulations
 Accelerated Earthquake Simulations Alex Breuer Technische Universität München Germany 1 Acknowledgements Volkswagen Stiftung Project ASCETE: Advanced Simulation of Coupled Earthquake-Tsunami Events Bavarian
Accelerated Earthquake Simulations Alex Breuer Technische Universität München Germany 1 Acknowledgements Volkswagen Stiftung Project ASCETE: Advanced Simulation of Coupled Earthquake-Tsunami Events Bavarian
Optimizing High-Dimensional Dynamic Stochastic Economic Models for MPI+GPU Clusters. Simon Scheidegger
 Optimizing High-Dimensional Dynamic Stochastic Economic Models for MPI+GPU Clusters Simon Scheidegger GTC San Jose, March 17-20th, 2015 Johannes Brumm (UZH) Dmitry Mikushin (USI LUGANO & https://parallel-computing.pro/)
Optimizing High-Dimensional Dynamic Stochastic Economic Models for MPI+GPU Clusters Simon Scheidegger GTC San Jose, March 17-20th, 2015 Johannes Brumm (UZH) Dmitry Mikushin (USI LUGANO & https://parallel-computing.pro/)
Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling
 Iterative Solvers Numerical Results Conclusion and outlook 1/22 Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling Part II: GPU Implementation and Scaling on Titan Eike
Iterative Solvers Numerical Results Conclusion and outlook 1/22 Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling Part II: GPU Implementation and Scaling on Titan Eike