READEX: A Tool Suite for Dynamic Energy Tuning. Michael Gerndt Technische Universität München
|
|
|
- Louisa Cooper
- 5 years ago
- Views:
Transcription
1 READEX: A Tool Suite for Dynamic Energy Tuning Michael Gerndt Technische Universität München

2 Campus Garching 2

3 SuperMUC: 3 Petaflops, 3 MW 3

4 READEX Runtime Exploitation of Application Dynamism for Energy-efficient exascale Computing 09/2015 to 08/
5 Objectives Tuning for energy efficiency Beyond static tuning: exploit dynamism in application characteristics Leverage system scenario based tuning HPC Automatic Tuning Embedded System Scenarios 5

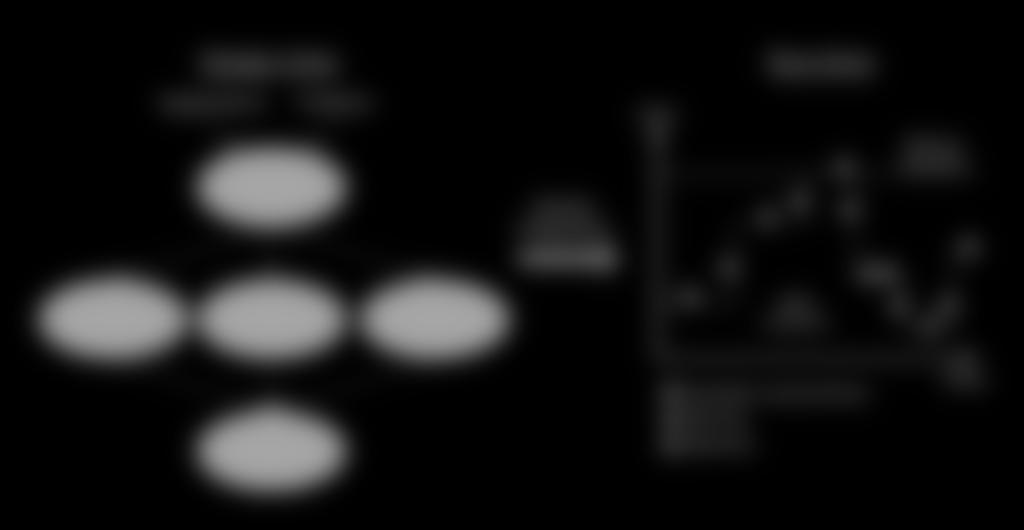

6 Systems Scenario based Methodology 6



7 Periscope Tuning Framework (PTF) Automatic application analysis & tuning Tune performance and energy (statically) Plug-in-based architecture Evaluate alternatives online Scalable and distributed framework Support variety of parallel paradigms MPI, OpenMP, OpenCL, Parallel pattern AutoTune EU-FP7 project 7



8 Score-P Scalable Performance Measurement Infrastructure for Parallel Codes Common instrumentationand measurement infrastructure 8
9 Tuning Plugin Interface Plugin Periscope Frontend Application with Monitor Search Space Exploration inside of Tuning Steps Scenario execution Tuning actions Measurement requests
10 Tuning Plugins MPI parameters Eager Limit, Buffer space, collective algorithms Application restart or MPIT Tools Interface DVFS Frequency tuning for energy delay product Model-based prediction of frequency Region level tuning Parallelism capping Thread number tuning for energy delay product Exhaustive and curve fitting based prediction
11 Dynamic Tuning with the READEX Tool Suite READEX extendsthe concept of tuning in Periscope Dynamic tuning Instead of one optimal configuration, SWITCH between different best configurations. Dynamic adaptation to changing program characteristics.
12 Scenario-Based Tuning Design Time Analysis Periscope Tuning Framework (PTF) Tuning Model Runtime Tuning READEX Runtime Library (RRL) 12
13 Intra-phase Dynamism Phase region Phase FREQ=2 GHz Intra-phase dynamism FREQ=1.5 GHz Significant region Runtime situation 13
14 READEX Intra-phase Tuning Plugin Tuning plugin supporting Core and uncore frequencies, numthreads parameters, application tuningparameters Configurable search space via READEX Configuration File Several objective functions: energy, CPUenergy, EDP, EDP2, time Several search strategies: exhaustive, individual, random, genetic Approach 1. Experiment with default configuration 2. Experiments for selected configurations Configuration set for phase region Energy and time measured for all runtime situations 3. Identification of static best for phase and rts specific best configurations 14
15 Pre-Computation of Tuning Model Search Algorithms Analysis Periscope Tuning Framework Plugin Control Performance Database Experiments Engine Score-P Online Access Interface READEX Runtime Library RTS Management DTA Management DTA Process Management READEX Tuning Plugin Substrate Plugin Interface Instrumentation RTS Database Scenario Identification Metric Plugin Interface Energy Measurements (HDEEM) Application Tuning Model 15
16 READEX Runtime Library (RRL) Runtime Application Tuning performed by the READEX Runtime Library. Tuning requests during Design Time Analysis are sent to RRL. A lightweight library Dynamic switching between different configurations at runtime. Implemented as a substrate plugin of Score-P. Developed by TUD and NTNU 16
17 Runtime Scenario Detection and Switching Decision during Production Run During Runtime Application Tuning Scenario classification Switching decision component Manipulation of tuning parameters 17

18 BEM4I Dynamic switching Energy blade summary, energy assemble_k [J] assemble_v [J] gmres_solve [J] print_vtu [J] main [J] default settings static tuning only dynamic tuning only static + dynamic tuning static savings [%] -27.9% -29.8% 52.2% 64.8% +19.4% dynamic savings [%] 8.4% 10.9% 57.5% 76.8% +40.0% static + dynamic savings [%] 8.1% 10.0% 57.9% 76.5% +39.8% static": { }, "FREQUENCY": 25", "NUM_THREADS": 12", "UNCORE_FREQUENCY": 22 < GHz < OpenMP threads < GHz "assemble_k": { "FREQUENCY": "23", "NUM_THREADS": "24", "UNCORE_FREQUENCY": 16 }, "assemble_v": { "FREQUENCY": 25", "NUM_THREADS": "24", "UNCORE_FREQUENCY": 14 }, "gmres_solve": { "FREQUENCY": 17", "NUM_THREADS": 8", "UNCORE_FREQUENCY": 22 }, "print_vtu": { "FREQUENCY": "25", "NUM_THREADS": 6", "UNCORE_FREQUENCY": 24 } 18
19 Scalability Tests OpenFOAM Analysis simplefoam strong scaling test Motorbike example optimum detected for every run Static: 11.7% Dynamic: 4.4% Total: 15.5% Dynamic savings increases with higher number of nodes Does not scale anymore

20 Inter-phase Dynamism All-to-all Performance 2048 phases PEPC Benchmark of the DEISA Benchmark Suite 20
21 Inter-Phase Analysis Variation of behavior among phases Group/cluster phases Select a best configuration for each cluster of phases What do we need? Identifiers of phase characteristics (Phase Identifiers) Provided by application expert (??) 21
22 Inter-Phase Analysis Approach Developed the interphase_tuning plugin 3 tuning steps: Analysis step: Random search strategy is used to create the search space Don t want to explore the whole tuning space Cluster phases and find best configuration for each cluster Default step: Run the application for the default setting Verification step: Select the best configuration for each phase, as determined for its cluster. Aggregate the savings over the phases 22
23 INDEED 3 clusters identified Noise points marked in red 23
24 Cluster Prediction in RRL How to handle phase identifiers to predict clusters? Call path of an rts nowincludes the cluster number Solution: Add the cluster number as a user parameter Add PAPI events to measure L3_TCM, Total_Instr and conditional branch instructions SCOREP_OA_PHASE_BEGIN() SCOREP_USER_PARAMETER_INT64(cluster, predict_cluster()) SCOREP_OA_PHASE_END() Predict the cluster of the upcomingphase If the cluster was mispredicted for the phase, correct it at the end of the phase 24
25 Evaluation of the readex_interphase plugin Performed on two applications: minimd, INDEED Experiments conducted on the Taurus HPC system at the ZIH in Dresden Each node contains two 12-core Intel Xeon CPUs E v3 (Intel Haswell family) Runs with a default CPU frequency of 2.5 GHz, uncore frequency of 3 GHz Energy measurements provided on Taurus via HDEEM measurement hardware Provides processor and blade energy measurements 25
26 minimd Lightweight, parallel molecular dynamics simulation code Performs molecular dynamics simulation of a Lennard-Jones Embedded Atom Model (EAM) system Written in C++ Provides input file to specify problem size, temperature, timesteps Evaluation of DTA: Hybrid (MPI+OpenMP) AVX vectorized version Problem size of 50 for the Lennard-Jones system. 26
27 minimd (2) 6 clusters identified Noise points marked in red ParCo'17, September 13, 27
28 INDEED INDEED performs sheet metal forming simulations of tools with different geometries moving towards a stationary workpiece Contact between tool and workpiece causes: Adaptive mesh refinement Increase in number of finite element nodes Increasing computational cost Time loop computes the solution to a system of equations until equilibrium is reached. OpenMP version evaluated ParCo'17, September 13, 28
29 INDEED (2) 3 clusters identified Noise points marked in red ParCo'17, September 13, 29
30 Energy Savings Application Phase best for the rts s (%) rts best for the rts s (%) minimd INDEED minimd records lower dynamic savings minimd has only two significant regions One region is called only once during the entire application run Better static and dynamic savings for the rts s of INDEED INDEED has nine significant regions Provides more potential for dynamism 30
31 Application Tuning Parameters (ATP) Exploit the dynamism in characteristics through the use of different code paths (e.g. preconditioners) Identify the control variables responsible for control flow switching. provides APIs to annotate the source code
32 Evaluation of ATP: Espreso l Finite Element (FEM) tools and domain decomposition based Finite Element Tearing and Interconnect (FETI) solver l Contains a projected conjugate gradient (PCG) solver. l Convergence can be improved by several preconditioners. l Evaluated preconditioners on a structural mechanics problem with 23 million unknowns l On a single compute node with 24 MPI processes s j Preconditioner # iterations 1 iteration Solution None ms 31.6 J s J Weight function ms J s J Lumped ms J 6.32 s J Light dirichlet ms J 5.46 s J Dirichlet ms J 6.34 s J
33 Configuration Variable Tuning Recently added readex_configuration tuning plugin Application Configuration Parameters with search space Replace selected value in input files and rerun the application 33
34 Input Identifiers What about different inputs? Annotation with Input Identifiers like problemsize Apply Design Time Analysis and merge generated tuning models Selection at runtime based on the input identifiers 34
35 Summary Energy-efficiency tuning Design Time Analysis Tuning Model Runtime Tuning Support for Intra-phase dynamism Inter-phase dynamism Application Tuning Parameters Application Configuration Parameters Different input configurations Based on Periscope Tuning Framework Score-P Monitoring 35


36 Thank you! Questions? 36
Energy Efficiency Tuning: READEX. Madhura Kumaraswamy Technische Universität München
 Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
READEX Runtime Exploitation of Application Dynamism for Energyefficient
 READEX Runtime Exploitation of Application Dynamism for Energyefficient exascale computing EnA-HPC @ ISC 17 Robert Schöne TUD Project Motivation Applications exhibit dynamic behaviour Changing resource
READEX Runtime Exploitation of Application Dynamism for Energyefficient exascale computing EnA-HPC @ ISC 17 Robert Schöne TUD Project Motivation Applications exhibit dynamic behaviour Changing resource
AutoTune Workshop. Michael Gerndt Technische Universität München
 AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
Automatic Tuning of HPC Applications with Periscope. Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München
 Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
READEX: Linking Two Ends of the Computing Continuum to Improve Energy-efficiency in Dynamic Applications
 READEX: Linking Two Ends of the Computing Continuum to Improve Energy-efficiency in Dynamic Applications Per Gunnar Kjeldsberg, Andreas Gocht, Michael Gerndt, Lubomir Riha, Joseph Schuchart, and Umbreen
READEX: Linking Two Ends of the Computing Continuum to Improve Energy-efficiency in Dynamic Applications Per Gunnar Kjeldsberg, Andreas Gocht, Michael Gerndt, Lubomir Riha, Joseph Schuchart, and Umbreen
Tuning Alya with READEX for Energy-Efficiency
 Tuning Alya with READEX for Energy-Efficiency Venkatesh Kannan 1, Ricard Borrell 2, Myles Doyle 1, Guillaume Houzeaux 2 1 Irish Centre for High-End Computing (ICHEC) 2 Barcelona Supercomputing Centre (BSC)
Tuning Alya with READEX for Energy-Efficiency Venkatesh Kannan 1, Ricard Borrell 2, Myles Doyle 1, Guillaume Houzeaux 2 1 Irish Centre for High-End Computing (ICHEC) 2 Barcelona Supercomputing Centre (BSC)
Code Auto-Tuning with the Periscope Tuning Framework
 Code Auto-Tuning with the Periscope Tuning Framework Renato Miceli, SENAI CIMATEC renato.miceli@fieb.org.br Isaías A. Comprés, TUM compresu@in.tum.de Project Participants Michael Gerndt, TUM Coordinator
Code Auto-Tuning with the Periscope Tuning Framework Renato Miceli, SENAI CIMATEC renato.miceli@fieb.org.br Isaías A. Comprés, TUM compresu@in.tum.de Project Participants Michael Gerndt, TUM Coordinator
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
ESPRESO ExaScale PaRallel FETI Solver. Hybrid FETI Solver Report
 ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
The READEX formalism for automatic tuning for energy efficiency
 Computing DOI 10.1007/s00607-016-0532-7 The READEX formalism for automatic tuning for energy efficiency Joseph Schuchart 1 Michael Gerndt 2 Per Gunnar Kjeldsberg 3 Michael Lysaght 4 David Horák 5 Lubomír
Computing DOI 10.1007/s00607-016-0532-7 The READEX formalism for automatic tuning for energy efficiency Joseph Schuchart 1 Michael Gerndt 2 Per Gunnar Kjeldsberg 3 Michael Lysaght 4 David Horák 5 Lubomír
Analyzing I/O Performance on a NEXTGenIO Class System
 Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Performance analysis with Periscope
 Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität petkovve@in.tum.de March 2010 Outline Motivation Periscope (PSC) Periscope performance analysis
Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität petkovve@in.tum.de March 2010 Outline Motivation Periscope (PSC) Periscope performance analysis
A Simple Framework for Energy Efficiency Evaluation and Hardware Parameter. Tuning with Modular Support for Different HPC Platforms
 A Simple Framework for Energy Efficiency Evaluation and Hardware Parameter Tuning with Modular Support for Different HPC Platforms Ondrej Vysocky, Jan Zapletal and Lubomir Riha IT4Innovations, VSB Technical
A Simple Framework for Energy Efficiency Evaluation and Hardware Parameter Tuning with Modular Support for Different HPC Platforms Ondrej Vysocky, Jan Zapletal and Lubomir Riha IT4Innovations, VSB Technical
ICON for HD(CP) 2. High Definition Clouds and Precipitation for Advancing Climate Prediction
 2. High Definition Clouds and Precipitation for Advancing Climate Prediction") ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
On the Path towards Exascale Computing in the Czech Republic and in Europe
 MARTIN PALKOVIČ Martin Palkovič is the managing director of IT4Innovations, the national supercomputing center in the Czech Republic. Before joining IT4Innovations, he was working for 12 years at imec
MARTIN PALKOVIČ Martin Palkovič is the managing director of IT4Innovations, the national supercomputing center in the Czech Republic. Before joining IT4Innovations, he was working for 12 years at imec
Application of GPU technology to OpenFOAM simulations
 Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
Powernightmares: The Challenge of Efficiently Using Sleep States on Multi-Core Systems
 Powernightmares: The Challenge of Efficiently Using Sleep States on Multi-Core Systems Thomas Ilsche, Marcus Hähnel, Robert Schöne, Mario Bielert, and Daniel Hackenberg Technische Universität Dresden Observation
Powernightmares: The Challenge of Efficiently Using Sleep States on Multi-Core Systems Thomas Ilsche, Marcus Hähnel, Robert Schöne, Mario Bielert, and Daniel Hackenberg Technische Universität Dresden Observation
ORAP Forum October 10, 2013
 Towards Petaflop simulations of core collapse supernovae ORAP Forum October 10, 2013 Andreas Marek 1 together with Markus Rampp 1, Florian Hanke 2, and Thomas Janka 2 1 Rechenzentrum der Max-Planck-Gesellschaft
Towards Petaflop simulations of core collapse supernovae ORAP Forum October 10, 2013 Andreas Marek 1 together with Markus Rampp 1, Florian Hanke 2, and Thomas Janka 2 1 Rechenzentrum der Max-Planck-Gesellschaft
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation
 Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
Performance Analysis with Periscope
 Performance Analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 Outline Motivation Periscope overview Periscope performance
Performance Analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 Outline Motivation Periscope overview Periscope performance
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures
 Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Design Space Exploration and Application Autotuning for Runtime Adaptivity in Multicore Architectures
 Design Space Exploration and Application Autotuning for Runtime Adaptivity in Multicore Architectures Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Outline Research challenges in multicore
Design Space Exploration and Application Autotuning for Runtime Adaptivity in Multicore Architectures Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Outline Research challenges in multicore
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
update: HPC, Data Center Infrastructure and Machine Learning HPC User Forum, February 28, 2017 Stuttgart
 GCS@LRZ update: HPC, Data Center Infrastructure and Machine Learning HPC User Forum, February 28, 2017 Stuttgart Arndt Bode Chairman of the Board, Leibniz-Rechenzentrum of the Bavarian Academy of Sciences
GCS@LRZ update: HPC, Data Center Infrastructure and Machine Learning HPC User Forum, February 28, 2017 Stuttgart Arndt Bode Chairman of the Board, Leibniz-Rechenzentrum of the Bavarian Academy of Sciences
Performance Analysis for Large Scale Simulation Codes with Periscope
 Performance Analysis for Large Scale Simulation Codes with Periscope M. Gerndt, Y. Oleynik, C. Pospiech, D. Gudu Technische Universität München IBM Deutschland GmbH May 2011 Outline Motivation Periscope
Performance Analysis for Large Scale Simulation Codes with Periscope M. Gerndt, Y. Oleynik, C. Pospiech, D. Gudu Technische Universität München IBM Deutschland GmbH May 2011 Outline Motivation Periscope
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
I/O Profiling Towards the Exascale
 I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
AUTOMATIC SMT THREADING
 AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
SCALASCA parallel performance analyses of SPEC MPI2007 applications
 Mitglied der Helmholtz-Gemeinschaft SCALASCA parallel performance analyses of SPEC MPI2007 applications 2008-05-22 Zoltán Szebenyi Jülich Supercomputing Centre, Forschungszentrum Jülich Aachen Institute
Mitglied der Helmholtz-Gemeinschaft SCALASCA parallel performance analyses of SPEC MPI2007 applications 2008-05-22 Zoltán Szebenyi Jülich Supercomputing Centre, Forschungszentrum Jülich Aachen Institute
Managing Hardware Power Saving Modes for High Performance Computing
 Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr timo.minartz@informatik.uni-hamburg.de
Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr timo.minartz@informatik.uni-hamburg.de
Lecture 7: Introduction to HFSS-IE
 Lecture 7: Introduction to HFSS-IE 2015.0 Release ANSYS HFSS for Antenna Design 1 2015 ANSYS, Inc. HFSS-IE: Integral Equation Solver Introduction HFSS-IE: Technology An Integral Equation solver technology
Lecture 7: Introduction to HFSS-IE 2015.0 Release ANSYS HFSS for Antenna Design 1 2015 ANSYS, Inc. HFSS-IE: Integral Equation Solver Introduction HFSS-IE: Technology An Integral Equation solver technology
[Scalasca] Tool Integrations
![[Scalasca] Tool Integrations](/thumbs/95/125562042.jpg "[Scalasca] Tool Integrations") Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
The AutoTune Project
 The AutoTune Project Siegfried Benkner (on behalf of the Autotune consortium) Research Group Scientific Computing University of Vienna AutoTune: Interna-onal Workshop on Code Auto- Tuning, CGO 2015, San
The AutoTune Project Siegfried Benkner (on behalf of the Autotune consortium) Research Group Scientific Computing University of Vienna AutoTune: Interna-onal Workshop on Code Auto- Tuning, CGO 2015, San
IBM High Performance Computing Toolkit
 IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
MPI Performance Engineering through the Integration of MVAPICH and TAU
 MPI Performance Engineering through the Integration of MVAPICH and TAU Allen D. Malony Department of Computer and Information Science University of Oregon Acknowledgement Research work presented in this
MPI Performance Engineering through the Integration of MVAPICH and TAU Allen D. Malony Department of Computer and Information Science University of Oregon Acknowledgement Research work presented in this
Open Compute Stack (OpenCS) Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,
 Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,") Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir
 Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir Andreas Knüpfer, Christian Rössel andreas.knuepfer@tu-dresden.de, c.roessel@fz-juelich.de 2011-09-26
Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir Andreas Knüpfer, Christian Rössel andreas.knuepfer@tu-dresden.de, c.roessel@fz-juelich.de 2011-09-26
simulation framework for piecewise regular grids
 WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW
 VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität
VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität
Outline 1 Motivation 2 Theory of a non-blocking benchmark 3 The benchmark and results 4 Future work
 Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Exploring Hardware Overprovisioning in Power-Constrained, High Performance Computing
 Exploring Hardware Overprovisioning in Power-Constrained, High Performance Computing Tapasya Patki 1 David Lowenthal 1 Barry Rountree 2 Martin Schulz 2 Bronis de Supinski 2 1 The University of Arizona
Exploring Hardware Overprovisioning in Power-Constrained, High Performance Computing Tapasya Patki 1 David Lowenthal 1 Barry Rountree 2 Martin Schulz 2 Bronis de Supinski 2 1 The University of Arizona
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Molecular Modelling and the Cray XC30 Performance Counters. Michael Bareford, ARCHER CSE Team
 Molecular Modelling and the Cray XC30 Performance Counters Michael Bareford, ARCHER CSE Team michael.bareford@epcc.ed.ac.uk Reusing this material This work is licensed under a Creative Commons Attribution-
Molecular Modelling and the Cray XC30 Performance Counters Michael Bareford, ARCHER CSE Team michael.bareford@epcc.ed.ac.uk Reusing this material This work is licensed under a Creative Commons Attribution-
Performance of deal.ii on a node
 Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
NEXTGenIO Performance Tools for In-Memory I/O
 NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
Multi-GPU simulations in OpenFOAM with SpeedIT technology.
 Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms
 The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Efficient AMG on Hybrid GPU Clusters. ScicomP Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann. Fraunhofer SCAI
 Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Score-P. SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1
 Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017
 OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Predicting GPU Performance from CPU Runs Using Machine Learning
 Predicting GPU Performance from CPU Runs Using Machine Learning Ioana Baldini Stephen Fink Erik Altman IBM T. J. Watson Research Center Yorktown Heights, NY USA 1 To exploit GPGPU acceleration need to
Predicting GPU Performance from CPU Runs Using Machine Learning Ioana Baldini Stephen Fink Erik Altman IBM T. J. Watson Research Center Yorktown Heights, NY USA 1 To exploit GPGPU acceleration need to
Adaptive Power Profiling for Many-Core HPC Architectures
 Adaptive Power Profiling for Many-Core HPC Architectures Jaimie Kelley, Christopher Stewart The Ohio State University Devesh Tiwari, Saurabh Gupta Oak Ridge National Laboratory State-of-the-Art Schedulers
Adaptive Power Profiling for Many-Core HPC Architectures Jaimie Kelley, Christopher Stewart The Ohio State University Devesh Tiwari, Saurabh Gupta Oak Ridge National Laboratory State-of-the-Art Schedulers
Solving Large Complex Problems. Efficient and Smart Solutions for Large Models
 Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Presenting: Comparing the Power and Performance of Intel's SCC to State-of-the-Art CPUs and GPUs
 Presenting: Comparing the Power and Performance of Intel's SCC to State-of-the-Art CPUs and GPUs A paper comparing modern architectures Joakim Skarding Christian Chavez Motivation Continue scaling of performance
Presenting: Comparing the Power and Performance of Intel's SCC to State-of-the-Art CPUs and GPUs A paper comparing modern architectures Joakim Skarding Christian Chavez Motivation Continue scaling of performance
Team 194: Aerodynamic Study of Airflow around an Airfoil in the EGI Cloud
 Team 194: Aerodynamic Study of Airflow around an Airfoil in the EGI Cloud CFD Support s OpenFOAM and UberCloud Containers enable efficient, effective, and easy access and use of MEET THE TEAM End-User/CFD
Team 194: Aerodynamic Study of Airflow around an Airfoil in the EGI Cloud CFD Support s OpenFOAM and UberCloud Containers enable efficient, effective, and easy access and use of MEET THE TEAM End-User/CFD
HFSS Hybrid Finite Element and Integral Equation Solver for Large Scale Electromagnetic Design and Simulation
 HFSS Hybrid Finite Element and Integral Equation Solver for Large Scale Electromagnetic Design and Simulation Laila Salman, PhD Technical Services Specialist laila.salman@ansys.com 1 Agenda Overview of
HFSS Hybrid Finite Element and Integral Equation Solver for Large Scale Electromagnetic Design and Simulation Laila Salman, PhD Technical Services Specialist laila.salman@ansys.com 1 Agenda Overview of
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Computational Interdisciplinary Modelling High Performance Parallel & Distributed Computing Our Research
 Insieme Insieme-an Optimization System for OpenMP, MPI and OpenCLPrograms Institute of Computer Science University of Innsbruck Thomas Fahringer, Ivan Grasso, Klaus Kofler, Herbert Jordan, Hans Moritsch,
Insieme Insieme-an Optimization System for OpenMP, MPI and OpenCLPrograms Institute of Computer Science University of Innsbruck Thomas Fahringer, Ivan Grasso, Klaus Kofler, Herbert Jordan, Hans Moritsch,
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
Parallel solution for finite element linear systems of. equations on workstation cluster *
 Aug. 2009, Volume 6, No.8 (Serial No.57) Journal of Communication and Computer, ISSN 1548-7709, USA Parallel solution for finite element linear systems of equations on workstation cluster * FU Chao-jiang
Aug. 2009, Volume 6, No.8 (Serial No.57) Journal of Communication and Computer, ISSN 1548-7709, USA Parallel solution for finite element linear systems of equations on workstation cluster * FU Chao-jiang
Performance of Implicit Solver Strategies on GPUs
 9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks
 Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster
 First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
I/O at JSC. I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O. Wolfgang Frings
 Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Detecting Memory-Boundedness with Hardware Performance Counters
 Center for Information Services and High Performance Computing (ZIH) Detecting ory-boundedness with Hardware Performance Counters ICPE, Apr 24th 2017 (daniel.molka@tu-dresden.de) Robert Schöne (robert.schoene@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Detecting ory-boundedness with Hardware Performance Counters ICPE, Apr 24th 2017 (daniel.molka@tu-dresden.de) Robert Schöne (robert.schoene@tu-dresden.de)
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Lecture 2: Introduction
 Lecture 2: Introduction v2015.0 Release ANSYS HFSS for Antenna Design 1 2015 ANSYS, Inc. Multiple Advanced Techniques Allow HFSS to Excel at a Wide Variety of Applications Platform Integration and RCS
Lecture 2: Introduction v2015.0 Release ANSYS HFSS for Antenna Design 1 2015 ANSYS, Inc. Multiple Advanced Techniques Allow HFSS to Excel at a Wide Variety of Applications Platform Integration and RCS
Hybrid programming with MPI and OpenMP On the way to exascale
 Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Optimization of parameter settings for GAMG solver in simple solver
 Optimization of parameter settings for GAMG solver in simple solver Masashi Imano (OCAEL Co.Ltd.) Aug. 26th 2012 OpenFOAM Study Meeting for beginner @ Kanto Test cluster condition Hardware: SGI Altix ICE8200
Optimization of parameter settings for GAMG solver in simple solver Masashi Imano (OCAEL Co.Ltd.) Aug. 26th 2012 OpenFOAM Study Meeting for beginner @ Kanto Test cluster condition Hardware: SGI Altix ICE8200
Method-Level Phase Behavior in Java Workloads
 Method-Level Phase Behavior in Java Workloads Andy Georges, Dries Buytaert, Lieven Eeckhout and Koen De Bosschere Ghent University Presented by Bruno Dufour dufour@cs.rutgers.edu Rutgers University DCS
Method-Level Phase Behavior in Java Workloads Andy Georges, Dries Buytaert, Lieven Eeckhout and Koen De Bosschere Ghent University Presented by Bruno Dufour dufour@cs.rutgers.edu Rutgers University DCS
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
High-performance Randomized Matrix Computations for Big Data Analytics and Applications
 jh160025-dahi High-performance Randomized Matrix Computations for Big Data Analytics and Applications akahiro Katagiri (Nagoya University) Abstract In this project, we evaluate performance of randomized
jh160025-dahi High-performance Randomized Matrix Computations for Big Data Analytics and Applications akahiro Katagiri (Nagoya University) Abstract In this project, we evaluate performance of randomized
Overcoming Distributed Debugging Challenges in the MPI+OpenMP Programming Model
 Overcoming Distributed Debugging Challenges in the MPI+OpenMP Programming Model Lai Wei, Ignacio Laguna, Dong H. Ahn Matthew P. LeGendre, Gregory L. Lee This work was performed under the auspices of the
Overcoming Distributed Debugging Challenges in the MPI+OpenMP Programming Model Lai Wei, Ignacio Laguna, Dong H. Ahn Matthew P. LeGendre, Gregory L. Lee This work was performed under the auspices of the
Detection and Analysis of Iterative Behavior in Parallel Applications
 Detection and Analysis of Iterative Behavior in Parallel Applications Karl Fürlinger and Shirley Moore Innovative Computing Laboratory, Department of Electrical Engineering and Computer Science, University
Detection and Analysis of Iterative Behavior in Parallel Applications Karl Fürlinger and Shirley Moore Innovative Computing Laboratory, Department of Electrical Engineering and Computer Science, University
Early Experiences with Trinity - The First Advanced Technology Platform for the ASC Program
 Early Experiences with Trinity - The First Advanced Technology Platform for the ASC Program C.T. Vaughan, D.C. Dinge, P.T. Lin, S.D. Hammond, J. Cook, C. R. Trott, A.M. Agelastos, D.M. Pase, R.E. Benner,
Early Experiences with Trinity - The First Advanced Technology Platform for the ASC Program C.T. Vaughan, D.C. Dinge, P.T. Lin, S.D. Hammond, J. Cook, C. R. Trott, A.M. Agelastos, D.M. Pase, R.E. Benner,
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
The HiCFD Project A joint initiative from DLR, T-Systems SfR and TU Dresden with Airbus, MTU and IBM as associated partners
 The HiCFD Project A joint initiative from DLR, T-Systems SfR and TU Dresden with Airbus, MTU and IBM as associated partners Thomas Alrutz, Christian Simmendinger T-Systems Solutions for Research GmbH 02.06.2009
The HiCFD Project A joint initiative from DLR, T-Systems SfR and TU Dresden with Airbus, MTU and IBM as associated partners Thomas Alrutz, Christian Simmendinger T-Systems Solutions for Research GmbH 02.06.2009
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,