AutoTune Workshop. Michael Gerndt Technische Universität München
|
|
|
- Roland Green
- 6 years ago
- Views:
Transcription
1 AutoTune Workshop Michael Gerndt Technische Universität München
2 AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy Efficiency Partners Coordinator: Technische Universität München Universität Wien Universitat Autonoma de Barcelona Leibniz Rechenzentrum University of Galway, ICHEC October 2011-April 2015



3 Project Participants Today Michael Gerndt, TUM Coordinator Michael Lysaght, ICHEC WP5: Evaluation Yury Oleynik, TUM ECS-Group
4 Goals of Meeting Present the Periscope Tuning Framework Present post-project exploitation plans AutoTune Demonstration Center ECS-Group spin-off Collect feedback on post-project exploitation
5 Agenda for Today 11:00 12:30 Introduction to the project Lunch 14:00 14:30 AutoTune Demonstration Center 14:30 15:00 ECS-Group 15:00 15:45 Discussion, Questionnaire Coffee
6 Todays Parallel Architectures Zoo of architectures Multicore processors NUMA multiprocessors Accelerators Clusters Supercomputers and programming models OpenMP, PGAS, TBB MPI CUDA, OpenCL, OpenACC

7 Multicore Processors Ingredients Superscalar cores SIMD units Multithreading Multiple cores Memory hierarchy Challenges Intel Sandy Bridge processor Long latency, low-bandwith memory access Multiple levels of parallelism: ILP, SIMD, thread Compilation, vectorization, parallelization (OpenMP)

8 NUMA Multiprocessors Ingredients Multiple multicore processors Shared address space Challenges SuperMUC Board Different latencies to memory, local vs remote access Contention for memory and synchronization OS support for thread affinity


9 Accelerators Ingredients Many cores Wide SIMD Specialized Hardware Challenges Special programming model CUDA, OpenCL, OpenACC Computation and data offload Application tuning Nvidia Keppler Intel Xeon Phi

10 Clusters Ingredients Many nodes Scalable high performance network Distributed memory Challenges Explicit data transfers Global parallelization with MPI Scalability Energy consumption LRZ
11 Development Cycle Coding Measurement Performance Analysis Refinement Analysis Program Tuning Ranking Production
12 Performance Analysis Goal: Identify inefficient regions and root cause Analysis techniques: Time profile Single core: counter profiles Multiple cores: overhead profiles Accelerators: counter and overhead profiles Clusters: Communication profiles and traces Measurement techniques Sampling Instrumentation


13 Performance Analysis Tools Profiling tools Single core, accelerators Multiple cores, clusters IDE integration Tracing tools Multiple cores, clusters: visualization of dynamic behavior. Automatic Beyond measurements
14 Knowledge Involved Refinement Current Hypotheses Detected Problems Instrumentation Analysis Requirements Performance Data Experiment
15 Runtime Tuning Design Time Tuning Application Tuning Objectives Performance Cost Energy Coding Performance Analysis Tuning When Installation Design time Runtime Production Runs Performance Analysis Tuning








16 VI-HPS Virtual Institute for High Productivity Supercomputing Aiming at development of tools and training of users to enable higher productivity in using supercomputers Partners FZJ GRS RWTH Aachen UNI Stuttgart ZIH Dresden TUM UNI Oregon UNI Tennessee

17 Periscope Performance Analysis On-line no need to store trace files Distributed reduced network utilization Scales to s of CPUs Analyzes: Single-node Performance MPI Communication OpenMP Supports: Fortran, C Intel Itanium based systems IBM Power BlueGene P x86 based systems periscope.in.tum.de
18 Performance Properties APART specification language Performance property Condition Severity Confidence Agent analysis strategies Determine hypothesis refinement Region nesting Property hierarchy-based refinement Experiment for a phase execution
19 Agent Search Strategies Application phase is a period of program s execution Phase region Full program Single user region assumed to be repetitive Phase boundaries have to be global (SPMD programs) Search strategies Determine hypothesis refinement Region nesting Property hierarchy-based refinement
20 Periscope Tuning Framework Periscope Pathway Tuning Plugins
21 AutoTune Project Automatic tuning based on expert knowledge Expert knowledge When is it necessary to tune? Where to tune? What are the tuning parameters? How to shrink the search space? Beyond auto-tuning like Active Harmony Tuning plugins for Periscope Dynamically loaded < few hundred lines of code

22 Periscope Tuning Framework PTF User Interface Extension of Periscope Online tuning process Application phase-based Extensible via tuning plugins Single tuning aspect Combining multiple tuning aspects Rich framework for plugin implementation Automatic and parallel experiment execution Search Algorithms PTF Frontend Tuning Plugins Static Program Info Experiment Execution Agent Network Monitor Monitor Monitor Application Performance Analysis
23 Tuning Plugins MPI parameters (UAB, TUM) Eager Limit, Buffer space, collective algorithms Application restart or MPIT Tools Interface DVFS (LRZ) Frequency tuning for energy delay product Model-based prediction of frequency, pre-analysis Region level tuning Parallelism capping (TUM) Thread number tuning for energy delay product Exhaustive and curve fitting based prediction
24 Tuning Plugins Master/worker (UAB) Partition factor and number of workers Prediction through performance model based on data measured in pre-analysis Parallel Pattern (UNI Vienna) Tuning replication and buffer between pipeline stages Based on component distribution via StarPU OpenHMPP/OpenACC (CAPS) Tuning parameters based on CAPS tune directives Optimizing data transfer and kernel execution time
25 Tuning Plugins MPI IO (TUM) Tuning data sieving and number of aggregators Exhaustive and model based Compiler Flag Selection (TUM) Automatic recompilation and execution Selective recompilation based on pre-analysis Exhaustive and individual search Scenario analysis for significant routines Combination with Pathway Machine learning support

26 Pathway Goals Formalize performance engineering workflows. Automate usage of analysis and tuning tools. Remove Monkey Work from code developers. Support overall tuning effort by bookkeeping.
27 Pathway Features Formal, graphical view on workflows Pre-defined workflows available Transparently serve different HPC systems Define connection parameters for each system Pathway automatically generates batch scripts for different schedulers Automatic tool invocation Experiment browser Notebook
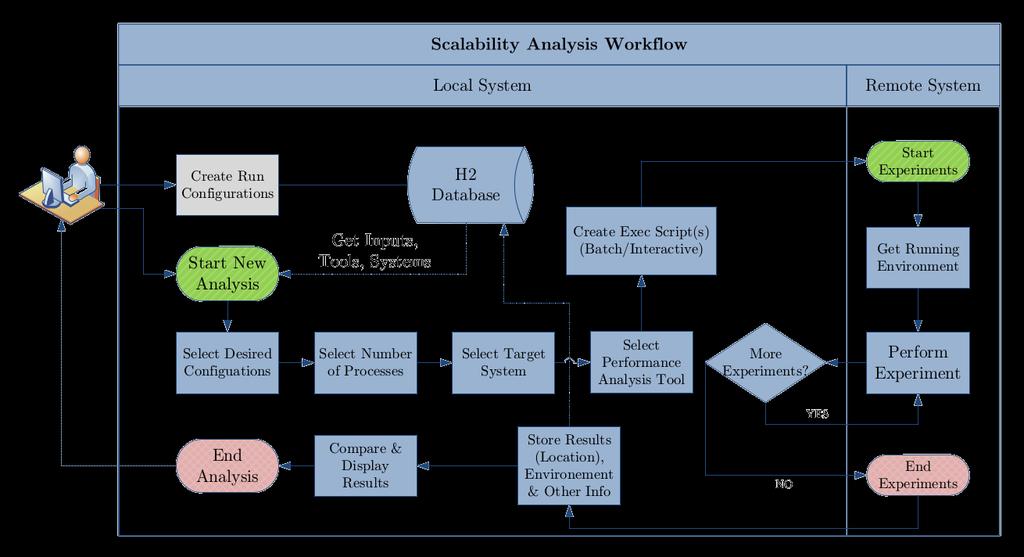
28 Scalability Workflow

29 Individual Tuning NPB (C)
30 k-nn training error
31 DVFS Tuning Plugin SeisSol application code-region optimization Percentage of energy savings on the outer most region (Region ID 1) Region ID 1.6 GHz 1.7 GHz 1.8 GHz Table showing energy consumption in Joules.
32 MPI Parameters Tuning (fish school simulation-64k fishes) Parameter Min Max Best Value Execution Time (Distribution) eager_limit 4196 B B use_bulk_xfer Yes No Yes bulk_min_msg_size 4096 B B task_affinity CORE MCM CORE pe_affinity Yes No Yes cc_scratch_buf Yes No No (with default values )
33 Periscope Tuning Framework periscope.in.tum.de Version: 1.0 (1.1 coming in April) Supported systems: x86-based clusters Bluegene IBM Power License: New BSD
34 Summary Manual and automatic performance engineering are important. Periscope supports automatic online analysis Periscope Tuning Framework adds automatic tuning plugins Pathway formalizes and supports the overall performance engineering process Future work: Integration with Score-P
Code Auto-Tuning with the Periscope Tuning Framework
 Code Auto-Tuning with the Periscope Tuning Framework Renato Miceli, SENAI CIMATEC renato.miceli@fieb.org.br Isaías A. Comprés, TUM compresu@in.tum.de Project Participants Michael Gerndt, TUM Coordinator
Code Auto-Tuning with the Periscope Tuning Framework Renato Miceli, SENAI CIMATEC renato.miceli@fieb.org.br Isaías A. Comprés, TUM compresu@in.tum.de Project Participants Michael Gerndt, TUM Coordinator
Automatic Tuning of HPC Applications with Periscope. Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München
 Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
Energy Efficiency Tuning: READEX. Madhura Kumaraswamy Technische Universität München
 Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
READEX: A Tool Suite for Dynamic Energy Tuning. Michael Gerndt Technische Universität München
 READEX: A Tool Suite for Dynamic Energy Tuning Michael Gerndt Technische Universität München Campus Garching 2 SuperMUC: 3 Petaflops, 3 MW 3 READEX Runtime Exploitation of Application Dynamism for Energy-efficient
READEX: A Tool Suite for Dynamic Energy Tuning Michael Gerndt Technische Universität München Campus Garching 2 SuperMUC: 3 Petaflops, 3 MW 3 READEX Runtime Exploitation of Application Dynamism for Energy-efficient
Performance Analysis with Periscope
 Performance Analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 Outline Motivation Periscope overview Periscope performance
Performance Analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 Outline Motivation Periscope overview Periscope performance
The AutoTune Project
 The AutoTune Project Siegfried Benkner (on behalf of the Autotune consortium) Research Group Scientific Computing University of Vienna AutoTune: Interna-onal Workshop on Code Auto- Tuning, CGO 2015, San
The AutoTune Project Siegfried Benkner (on behalf of the Autotune consortium) Research Group Scientific Computing University of Vienna AutoTune: Interna-onal Workshop on Code Auto- Tuning, CGO 2015, San
Performance analysis with Periscope
 Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität petkovve@in.tum.de March 2010 Outline Motivation Periscope (PSC) Periscope performance analysis
Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität petkovve@in.tum.de March 2010 Outline Motivation Periscope (PSC) Periscope performance analysis
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Performance Analysis for Large Scale Simulation Codes with Periscope
 Performance Analysis for Large Scale Simulation Codes with Periscope M. Gerndt, Y. Oleynik, C. Pospiech, D. Gudu Technische Universität München IBM Deutschland GmbH May 2011 Outline Motivation Periscope
Performance Analysis for Large Scale Simulation Codes with Periscope M. Gerndt, Y. Oleynik, C. Pospiech, D. Gudu Technische Universität München IBM Deutschland GmbH May 2011 Outline Motivation Periscope
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
[Scalasca] Tool Integrations
![[Scalasca] Tool Integrations](/thumbs/95/125562042.jpg "[Scalasca] Tool Integrations") Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
Integrating Parallel Application Development with Performance Analysis in Periscope
 Technische Universität München Integrating Parallel Application Development with Performance Analysis in Periscope V. Petkov, M. Gerndt Technische Universität München 19 April 2010 Atlanta, GA, USA Motivation
Technische Universität München Integrating Parallel Application Development with Performance Analysis in Periscope V. Petkov, M. Gerndt Technische Universität München 19 April 2010 Atlanta, GA, USA Motivation
HPC code modernization with Intel development tools
 HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Introduction to VI-HPS
 Introduction to VI-HPS José Gracia HLRS Virtual Institute High Productivity Supercomputing Goal: Improve the quality and accelerate the development process of complex simulation codes running on highly-parallel
Introduction to VI-HPS José Gracia HLRS Virtual Institute High Productivity Supercomputing Goal: Improve the quality and accelerate the development process of complex simulation codes running on highly-parallel
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir
 Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir VI-HPS Team Score-P: Specialized Measurements and Analyses Mastering build systems Hooking up the
Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir VI-HPS Team Score-P: Specialized Measurements and Analyses Mastering build systems Hooking up the
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Tuning Alya with READEX for Energy-Efficiency
 Tuning Alya with READEX for Energy-Efficiency Venkatesh Kannan 1, Ricard Borrell 2, Myles Doyle 1, Guillaume Houzeaux 2 1 Irish Centre for High-End Computing (ICHEC) 2 Barcelona Supercomputing Centre (BSC)
Tuning Alya with READEX for Energy-Efficiency Venkatesh Kannan 1, Ricard Borrell 2, Myles Doyle 1, Guillaume Houzeaux 2 1 Irish Centre for High-End Computing (ICHEC) 2 Barcelona Supercomputing Centre (BSC)
StarPU: a runtime system for multigpu multicore machines
 StarPU: a runtime system for multigpu multicore machines Raymond Namyst RUNTIME group, INRIA Bordeaux Journées du Groupe Calcul Lyon, November 2010 The RUNTIME Team High Performance Runtime Systems for
StarPU: a runtime system for multigpu multicore machines Raymond Namyst RUNTIME group, INRIA Bordeaux Journées du Groupe Calcul Lyon, November 2010 The RUNTIME Team High Performance Runtime Systems for
Performance analysis tools: Intel VTuneTM Amplifier and Advisor. Dr. Luigi Iapichino
 Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
The Heterogeneous Programming Jungle. Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest
 The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Periscope Tutorial Exercise NPB-MPI/BT
 Periscope Tutorial Exercise NPB-MPI/BT M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 NPB-BT Exercise Intermediate-level tutorial example
Periscope Tutorial Exercise NPB-MPI/BT M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 NPB-BT Exercise Intermediate-level tutorial example
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW
 VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität
VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
READEX Runtime Exploitation of Application Dynamism for Energyefficient
 READEX Runtime Exploitation of Application Dynamism for Energyefficient exascale computing EnA-HPC @ ISC 17 Robert Schöne TUD Project Motivation Applications exhibit dynamic behaviour Changing resource
READEX Runtime Exploitation of Application Dynamism for Energyefficient exascale computing EnA-HPC @ ISC 17 Robert Schöne TUD Project Motivation Applications exhibit dynamic behaviour Changing resource
Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir
 Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir Andreas Knüpfer, Christian Rössel andreas.knuepfer@tu-dresden.de, c.roessel@fz-juelich.de 2011-09-26
Score-P A Joint Performance Measurement Run-Time Infrastructure for Periscope, Scalasca, TAU, and Vampir Andreas Knüpfer, Christian Rössel andreas.knuepfer@tu-dresden.de, c.roessel@fz-juelich.de 2011-09-26
Distribution of Periscope Analysis Agents on ALTIX 4700
 John von Neumann Institute for Computing Distribution of Periscope Analysis Agents on ALTIX 4700 Michael Gerndt, Sebastian Strohhäcker published in Parallel Computing: Architectures, Algorithms and Applications,
John von Neumann Institute for Computing Distribution of Periscope Analysis Agents on ALTIX 4700 Michael Gerndt, Sebastian Strohhäcker published in Parallel Computing: Architectures, Algorithms and Applications,
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Introduction to Parallel Performance Engineering
 Introduction to Parallel Performance Engineering Markus Geimer, Brian Wylie Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray) Performance:
Introduction to Parallel Performance Engineering Markus Geimer, Brian Wylie Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray) Performance:
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Score-P. SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1
 Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
ELASTIC: Dynamic Tuning for Large-Scale Parallel Applications
 Workshop on Extreme-Scale Programming Tools 18th November 2013 Supercomputing 2013 ELASTIC: Dynamic Tuning for Large-Scale Parallel Applications Toni Espinosa Andrea Martínez, Anna Sikora, Eduardo César
Workshop on Extreme-Scale Programming Tools 18th November 2013 Supercomputing 2013 ELASTIC: Dynamic Tuning for Large-Scale Parallel Applications Toni Espinosa Andrea Martínez, Anna Sikora, Eduardo César
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
A Characterization of Shared Data Access Patterns in UPC Programs
 IBM T.J. Watson Research Center A Characterization of Shared Data Access Patterns in UPC Programs Christopher Barton, Calin Cascaval, Jose Nelson Amaral LCPC `06 November 2, 2006 Outline Motivation Overview
IBM T.J. Watson Research Center A Characterization of Shared Data Access Patterns in UPC Programs Christopher Barton, Calin Cascaval, Jose Nelson Amaral LCPC `06 November 2, 2006 Outline Motivation Overview
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Agenda
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
Introduction to Runtime Systems
 Introduction to Runtime Systems Towards Portability of Performance ST RM Static Optimizations Runtime Methods Team Storm Olivier Aumage Inria LaBRI, in cooperation with La Maison de la Simulation Contents
Introduction to Runtime Systems Towards Portability of Performance ST RM Static Optimizations Runtime Methods Team Storm Olivier Aumage Inria LaBRI, in cooperation with La Maison de la Simulation Contents
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
Performance Profiler. Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava,
 Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Profile analysis with CUBE. David Böhme, Markus Geimer German Research School for Simulation Sciences Jülich Supercomputing Centre
 Profile analysis with CUBE David Böhme, Markus Geimer German Research School for Simulation Sciences Jülich Supercomputing Centre CUBE Parallel program analysis report exploration tools Libraries for XML
Profile analysis with CUBE David Böhme, Markus Geimer German Research School for Simulation Sciences Jülich Supercomputing Centre CUBE Parallel program analysis report exploration tools Libraries for XML
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Recent Developments in Score-P and Scalasca V2
 Mitglied der Helmholtz-Gemeinschaft Recent Developments in Score-P and Scalasca V2 Aug 2015 Bernd Mohr 9 th Scalable Tools Workshop Lake Tahoe YOU KNOW YOU MADE IT IF LARGE COMPANIES STEAL YOUR STUFF August
Mitglied der Helmholtz-Gemeinschaft Recent Developments in Score-P and Scalasca V2 Aug 2015 Bernd Mohr 9 th Scalable Tools Workshop Lake Tahoe YOU KNOW YOU MADE IT IF LARGE COMPANIES STEAL YOUR STUFF August
Programming for Fujitsu Supercomputers
 Programming for Fujitsu Supercomputers Koh Hotta The Next Generation Technical Computing Fujitsu Limited To Programmers who are busy on their own research, Fujitsu provides environments for Parallel Programming
Programming for Fujitsu Supercomputers Koh Hotta The Next Generation Technical Computing Fujitsu Limited To Programmers who are busy on their own research, Fujitsu provides environments for Parallel Programming
Parallel Programming. Michael Gerndt Technische Universität München
 Parallel Programming Michael Gerndt Technische Universität München gerndt@in.tum.de Contents 1. Introduction 2. Parallel architectures 3. Parallel applications 4. Parallelization approach 5. OpenMP 6.
Parallel Programming Michael Gerndt Technische Universität München gerndt@in.tum.de Contents 1. Introduction 2. Parallel architectures 3. Parallel applications 4. Parallelization approach 5. OpenMP 6.
IBM High Performance Computing Toolkit
 IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Accelerators in Technical Computing: Is it Worth the Pain?
 Accelerators in Technical Computing: Is it Worth the Pain? A TCO Perspective Sandra Wienke, Dieter an Mey, Matthias S. Müller Center for Computing and Communication JARA High-Performance Computing RWTH
Accelerators in Technical Computing: Is it Worth the Pain? A TCO Perspective Sandra Wienke, Dieter an Mey, Matthias S. Müller Center for Computing and Communication JARA High-Performance Computing RWTH
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Agenda. Optimization Notice Copyright 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Master Program (Laurea Magistrale) in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.
 in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.") Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
ICON for HD(CP) 2. High Definition Clouds and Precipitation for Advancing Climate Prediction
 2. High Definition Clouds and Precipitation for Advancing Climate Prediction") ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
MPI Performance Engineering through the Integration of MVAPICH and TAU
 MPI Performance Engineering through the Integration of MVAPICH and TAU Allen D. Malony Department of Computer and Information Science University of Oregon Acknowledgement Research work presented in this
MPI Performance Engineering through the Integration of MVAPICH and TAU Allen D. Malony Department of Computer and Information Science University of Oregon Acknowledgement Research work presented in this
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
AUTOMATIC SMT THREADING
 AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
ELP. Effektive Laufzeitunterstützung für zukünftige Programmierstandards. Speaker: Tim Cramer, RWTH Aachen University
 ELP Effektive Laufzeitunterstützung für zukünftige Programmierstandards Agenda ELP Project Goals ELP Achievements Remaining Steps ELP Project Goals Goals of ELP: Improve programmer productivity By influencing
ELP Effektive Laufzeitunterstützung für zukünftige Programmierstandards Agenda ELP Project Goals ELP Achievements Remaining Steps ELP Project Goals Goals of ELP: Improve programmer productivity By influencing
A General Discussion on! Parallelism!
 Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing
 Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Intel VTune Amplifier XE. Dr. Michael Klemm Software and Services Group Developer Relations Division
 Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Parallel Hybrid Computing Stéphane Bihan, CAPS
 Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010
 Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Why you should care about hardware locality and how.
 Why you should care about hardware locality and how. Brice Goglin TADaaM team Inria Bordeaux Sud-Ouest Agenda Quick example as an introduction Bind your processes What's the actual problem? Convenient
Why you should care about hardware locality and how. Brice Goglin TADaaM team Inria Bordeaux Sud-Ouest Agenda Quick example as an introduction Bind your processes What's the actual problem? Convenient
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Advanced Threading and Optimization
 Mikko Byckling, CSC Michael Klemm, Intel Advanced Threading and Optimization February 24-26, 2015 PRACE Advanced Training Centre CSC IT Center for Science Ltd, Finland!$omp parallel do collapse(3) do p4=1,p4d
Mikko Byckling, CSC Michael Klemm, Intel Advanced Threading and Optimization February 24-26, 2015 PRACE Advanced Training Centre CSC IT Center for Science Ltd, Finland!$omp parallel do collapse(3) do p4=1,p4d
Masterpraktikum Scientific Computing
 Masterpraktikum Scientific Computing High-Performance Computing Michael Bader Alexander Heinecke Technische Universität München, Germany Outline Logins Levels of Parallelism Single Processor Systems Von-Neumann-Principle
Masterpraktikum Scientific Computing High-Performance Computing Michael Bader Alexander Heinecke Technische Universität München, Germany Outline Logins Levels of Parallelism Single Processor Systems Von-Neumann-Principle