ME964 High Performance Computing for Engineering Applications
|
|
|
- Lindsay Moody
- 6 years ago
- Views:
Transcription
1 ME964 High Performance Computing for Engineering Applications Outlining Midterm Projects Topic 3: GPU-based FEA Topic 4: GPU Direct Solver for Sparse Linear Algebra March 01, 2011 Dan Negrut, 2011 ME964 UW-Madison The real problem is not whether machines think but whether men do. B. F. Skinner
2 Before We Get Started Last time Midterm Project topics 1 and 2 Today Discrete Element Method on the GPU. Area coordinator: Toby Heyn Collision Detection on the GPU. Area coordinator: Arman Pazouki Midterm Project topics 3 and 4 Finite Element Method on the GPU. Area coordinators: Prof. Suresh and Naresh Khude Sparse direct solver on the GPU (Cholesky). Area coordinator: Dan Negrut Midterm Project Related Issues Midterm Project is due on 04/13 at 11:59 PM (use Learn@UW drop-box) Intermediate report due on 03/22 at 11:59 PM (use the same Learn@UW drop-box) Each area coordinator Will provide a test problem for you to test your GPU implementation Will also assist you with questions related to the non-programming aspects (the theory ) behind the topic you chose You can continue your Midterm Project (MP) and have it become your Final Project (FP) In this case you will be expected to show how the FP implementation is superior to your MP implementation Other issues HW5 due tonight at 11:59 PM Use Learn@UW drop-box to submit homework 2

3 Finite Element Analysis on the GPU? Krishnan Suresh Associate Professor
4 Finite Element Analysis Computer simulation of engineering models Physics: Structural, thermal, fluid, Mode: Static, modal, transient Linear, non-linear, multi-physics

![JPL]](/docs-images/74/69956663/images/5-2.jpg "Hours or")


5 Why GPU? [Gordon; JPL] Hours or even days of CPU time.

 to speedup Finite")
6 Question Can one exploit graphics programmable units (GPU) to speedup Finite Element analysis? +
7 Structural Static FEA K f e e K f = = K f e e Ku = f Model Discretize Element Stiffness Assemble/ Solve Postprocess
8 FEA: Variations K f e e K f = = Ku = K f e f e Tet/Hex/ Order/Hybrid Direct/Iterative Model Discretize Element Stiffness Assemble/ Solve Postprocess Nonlinear Optimization
9 FEA: Challenges K f e e K f = = Ku = K f e f e Tet/Hex/ Order/Hybrid Direct/Iterative Model Discretize Element Stiffness Assemble/ Solve Postprocess Optimization Nonlinear 1. Accuracy 2. Automation 3. Speed
10 Typical Bottleneck K f e e K f = = K f e e Ku = f Model Discretize Element Stiffness Assemble/ Solve Postprocess
11 GPU & Engineering Analysis Model CPU Discretize GPU? Discretization Data: Small b-rep (+) Logic: Complex (-) Threads: Few (-) Not a good candidate for GPU!?

")
12 Element Stiffness K e f e Model Discretize Element Stiffness Hex 2 nd Order CPU CPU GPU? Hex Hybrid Element Stiffness Data: O(N) (+/-) Logic: Simple (+) Threads: N (+)
13 Stiffness: Hex 2 nd Order K = e [ ] ( M, M ) (8 Corners) (27 Nodes) 8 Corners~100 Bytes Data (x y z) 27 Nodes~ M = 81 DOF (u v w) k ij ~ Gaussian integration 30 flops 2 Flops N(15 M ) N T = , M= 81 CPU 4sec
14 Typical Bottleneck K f e e K f = = K f e e Ku = f Model Discretize Element Stiffness Assemble/ Solve
15 Direct vs. Iterative Ku = f K = K is sparse & usually symmetric P.D Direct Iterative LDL T 1 1 T u = L D L f i 1 i i u + = u + B( f Ku ) B : Preconditioner of K (GPU Variation: Assembly-free) Note: Nvidia offers CuBLAS-3 dense matrix library

")
16 Direct Sparse on GPU (1) (2006)


17 Direct Sparse on GPU (1) Ku = f
 Ku =")
18 Direct Sparse on GPU (1) Ku = f
19 Direct Sparse on GPU (2) Ku = f (2008)


20 Direct Sparse on GPU (2) Ku = f
21 Iterative Sparse on GPU (1) (2008) Jacobi preconditioned conjugate gradient ATI GPU Speed-up 3.5.
22 Iterative Sparse on GPU (2) Double precision real world SpMv CPU (2.3 GHz Dual Xeon): 1 GFLOPS GPU (GTX 280): 16 GFLOPS Speedup ~ 16
23 FEA/GPU Class Projects? 1. Complete < 6 weeks 2. Important (publishable) 3. Pilot code
24 FEA/GPU Class Projects? 1. GPU Friendly Preconditioners for Thin Structures Research papers OpenCL and ViennaCL Pilot Code 2. Topology Optimization Research papers CUDA code 3. Others Can discuss



25 Thin Structure?



26 Thin Structure? Large K
27 Preconditioners? Ku = f i 1 i i u + = u + B( f Ku ) B : Preconditioner of K Iterative Methods: GPU methods available for K*u Typical preconditioners: simple Jacobi, Poor preconditioner slow convergence Objective: GPU friendly preconditioner for thin structures
28 Research Publication

29 Basic Idea
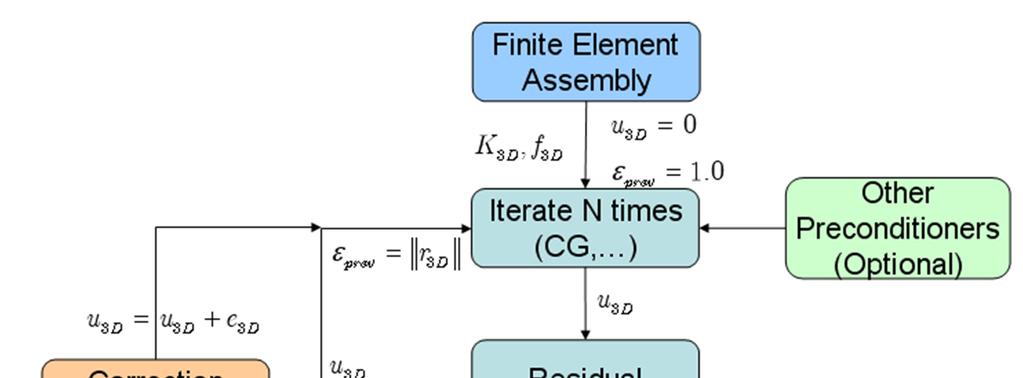

30 Algorithm
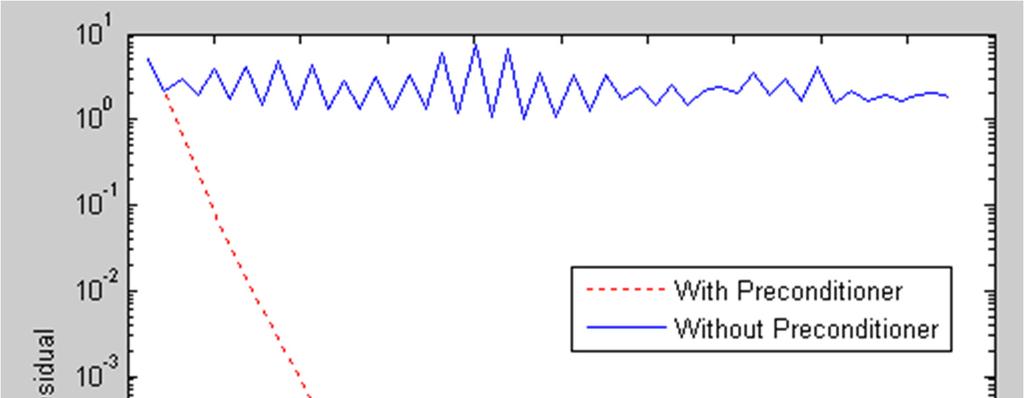
31 Why Preconditioner?

32 Why Double Precision?

33 How Expensive is Preconditioner?

34 GPU Friendly Speed-up without Preconditioner Speed-up with Preconditioner
35 FEA/GPU Class Projects? 1. GPU Friendly Preconditioners for Thin Structures Research papers OpenCL and ViennaCL Pilot Code 2. Topology Optimization Research papers CUDA code 3. Others Can discuss

36 Topology Optimization D Stiffest topology for a given volume? Where to remove material? Min Ω D J Ω= V 0 V = 50% [Sigmund 2001] Multi Objective + Topology Optimization = MOTO Min {J, V } Ω D 0


37 Demo Matlab code




38 Pareto Optimal Designs Purely pareto optimal



39 Comparison D
40 3-D Pareto-Method SIMP
")
41 3-D GPU Implementation Multi-grid Topology Optimization on the GPU (IDETC conf. 2011)
42 Motivation for Topic 4: Sparse Direct Solver 42
43 Nomenclature & Simplifying Assumptions 43


44 The Schur Complement Problem in Multi-Body Dynamics Applications 44
45 Formulation Framework Position: r = [ x, y, z ] T i i i i Orientation: Euler parameters, p [,,, ] T i = ei ei ei ei Translational Velocity: rɺ = [ xɺ, yɺ, zɺ ] T i i i i Angular velocities ω = [ω, ω, ω ] x y y T i i i i 45
46 Constrained Equations of Motion Φ ( r, p, t) = 0 Φ ( r, p, t) rɺ + Φ ( r, p, t) ω = Φ ( r, p, t) η ρ Φ ( r, p, t) ɺɺ r + Φ ( r, p, t) ω ɺ = τ ( rɺ, ω, r, p, t) η ρ t T M 0 ɺɺ r Φη( r, p, t) F( rɺ, ω, r, p, t) λ T ω + = Φ (,, t) ˆ ρ (, ω,,, t) 0 J ɺ r p n rɺ r p 46
47 Numerical Solution of the Newton-Euler Constrained Equations of Motion One has to solve a set of Differential Algebraic Equations (DAEs) to find the time evolution of a mechanical system Most often the numerical solution of the DAEs requires the solution of a linear system of the form: T M 0 Φη ɺɺ r F T Φ ˆ ρ ω 0 J ɺ = n Φ η Φ ρ 0 λ τ 47
48 Approach Followed First solve the Reduced System for : λ 1 T M 0 Φ η η ρ 1 T 0 J Φρ Φ Φ λ = b Then recover accelerations 1 T ɺɺ r = M ( F Φ λ ) ω ɺ 1 = J n η T ( ˆ Φ λ ) ρ 48
49 Iterative Solution of the Reduced System Define positive definite Reduced Matrix E 1 T M 0 Φ η = Φ η Φ ρ 1 T 0 J Φρ E Preconditioned Conjugate Gradient requires computation at time of ( k ) t n E n λ requires preconditioning: Eold λ = b 49
50 Computing E ( k) n λ Time step n, iteration (k): e 1 e e J e 2 ( k ) ( k ) m n = Enλ n = R A thread is associated with each body We ll look at how thread 9 does its share of work to compute e 3 50
51 How Thread-9 Does its Work S1. Compute reaction forces acting on me: F = ( Φ ) λ + ( Φ ) λ + ( Φ ) λ C 3 T 5 T 6 T S2. Compute my constraint acceleration a = M F C 1 C S3. Project my constraint acceleration Π = Φ a Π = Φ a Π = Φ a 3 3 C 5 5 C 6 6 C Finally, e = Π + Π
52 Iteration Operation Count for Body 9 (Thread-9) Step Multiplications Additions S1 S2 6 C ( C 1) 9 5 S3 6 C 9 5 C 9 52
53 Computing [Concluding Remarks] E n λ ( k) The algorithm scales very well: one thread for each body Each thread only interacts with adjacent joints Load balance is obtained when the bodies have similar topology index 53
54 Direct Solution of the Reduced System 54
55 The Sparse Direct Solver 55
56 The Direct Solver: How Things Get Done In the reduced linear system Eλ = b each constraint induces an equation Example: constraint 3 induced equation: E λ + E λ + E λ + E λ = b Since E is positive definite, E33 is also positive definite Fundamental Idea: Solve for λ 3 and substitute it in all the equations where it shows up 56
57 First Example: Seven-Body Mechanism 57
58 58

59 The Elimination Sequence The fundamental question is this: what should be the sequence in which the unknowns (the edges of the graph) are eliminated? Different elimination sequences result in different levels of effort The question becomes more complicated since you are interested in a parallel elimination sequence You would like to limit the amount of synchronization barriers that you impose in the implementation In the end, although it s formulated like solving a system, the problem becomes that starting with a graph and eliminating its edges in parallel Similar to a Mikado, or pick-up sticks, game that you want to play in parallel 59


60 Second Example: HMMWV Model Elim. Sequence A M I F NNZ Bad Good Index Reduction
Krishnan Suresh Associate Professor Mechanical Engineering
 Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Performance of Implicit Solver Strategies on GPUs
 9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
Very fast simulation of nonlinear water waves in very large numerical wave tanks on affordable graphics cards
 Very fast simulation of nonlinear water waves in very large numerical wave tanks on affordable graphics cards By Allan P. Engsig-Karup, Morten Gorm Madsen and Stefan L. Glimberg DTU Informatics Workshop
Very fast simulation of nonlinear water waves in very large numerical wave tanks on affordable graphics cards By Allan P. Engsig-Karup, Morten Gorm Madsen and Stefan L. Glimberg DTU Informatics Workshop
Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC
 Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI
 EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI 1 Akshay N. Panajwar, 2 Prof.M.A.Shah Department of Computer Science and Engineering, Walchand College of Engineering,
EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI 1 Akshay N. Panajwar, 2 Prof.M.A.Shah Department of Computer Science and Engineering, Walchand College of Engineering,
Efficient Use of Iterative Solvers in Nested Topology Optimization
 Efficient Use of Iterative Solvers in Nested Topology Optimization Oded Amir, Mathias Stolpe and Ole Sigmund Technical University of Denmark Department of Mathematics Department of Mechanical Engineering
Efficient Use of Iterative Solvers in Nested Topology Optimization Oded Amir, Mathias Stolpe and Ole Sigmund Technical University of Denmark Department of Mathematics Department of Mechanical Engineering
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Contents. I The Basic Framework for Stationary Problems 1
 page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
A GPU Sparse Direct Solver for AX=B
 1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
The 3D DSC in Fluid Simulation
 The 3D DSC in Fluid Simulation Marek K. Misztal Informatics and Mathematical Modelling, Technical University of Denmark mkm@imm.dtu.dk DSC 2011 Workshop Kgs. Lyngby, 26th August 2011 Governing Equations
The 3D DSC in Fluid Simulation Marek K. Misztal Informatics and Mathematical Modelling, Technical University of Denmark mkm@imm.dtu.dk DSC 2011 Workshop Kgs. Lyngby, 26th August 2011 Governing Equations
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
T6: Position-Based Simulation Methods in Computer Graphics. Jan Bender Miles Macklin Matthias Müller
 T6: Position-Based Simulation Methods in Computer Graphics Jan Bender Miles Macklin Matthias Müller Jan Bender Organizer Professor at the Visual Computing Institute at Aachen University Research topics
T6: Position-Based Simulation Methods in Computer Graphics Jan Bender Miles Macklin Matthias Müller Jan Bender Organizer Professor at the Visual Computing Institute at Aachen University Research topics
Parallel resolution of sparse linear systems by mixing direct and iterative methods
 Parallel resolution of sparse linear systems by mixing direct and iterative methods Phyleas Meeting, Bordeaux J. Gaidamour, P. Hénon, J. Roman, Y. Saad LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix
Parallel resolution of sparse linear systems by mixing direct and iterative methods Phyleas Meeting, Bordeaux J. Gaidamour, P. Hénon, J. Roman, Y. Saad LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Fast Tridiagonal Solvers on GPU
 Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
A parallel direct/iterative solver based on a Schur complement approach
 A parallel direct/iterative solver based on a Schur complement approach Gene around the world at CERFACS Jérémie Gaidamour LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix project) February 29th, 2008
A parallel direct/iterative solver based on a Schur complement approach Gene around the world at CERFACS Jérémie Gaidamour LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix project) February 29th, 2008
A Parallel Implementation of the BDDC Method for Linear Elasticity
 A Parallel Implementation of the BDDC Method for Linear Elasticity Jakub Šístek joint work with P. Burda, M. Čertíková, J. Mandel, J. Novotný, B. Sousedík Institute of Mathematics of the AS CR, Prague
A Parallel Implementation of the BDDC Method for Linear Elasticity Jakub Šístek joint work with P. Burda, M. Čertíková, J. Mandel, J. Novotný, B. Sousedík Institute of Mathematics of the AS CR, Prague
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Parallel Interpolation in FSI Problems Using Radial Basis Functions and Problem Size Reduction
 Parallel Interpolation in FSI Problems Using Radial Basis Functions and Problem Size Reduction Sergey Kopysov, Igor Kuzmin, Alexander Novikov, Nikita Nedozhogin, and Leonid Tonkov Institute of Mechanics,
Parallel Interpolation in FSI Problems Using Radial Basis Functions and Problem Size Reduction Sergey Kopysov, Igor Kuzmin, Alexander Novikov, Nikita Nedozhogin, and Leonid Tonkov Institute of Mechanics,
Report of Linear Solver Implementation on GPU
 Report of Linear Solver Implementation on GPU XIANG LI Abstract As the development of technology and the linear equation solver is used in many aspects such as smart grid, aviation and chemical engineering,
Report of Linear Solver Implementation on GPU XIANG LI Abstract As the development of technology and the linear equation solver is used in many aspects such as smart grid, aviation and chemical engineering,
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
ME451 Kinematics and Dynamics of Machine Systems
 ME451 Kinematics and Dynamics of Machine Systems Elements of 2D Kinematics September 23, 2014 Dan Negrut ME451, Fall 2014 University of Wisconsin-Madison Quote of the day: "Success is stumbling from failure
ME451 Kinematics and Dynamics of Machine Systems Elements of 2D Kinematics September 23, 2014 Dan Negrut ME451, Fall 2014 University of Wisconsin-Madison Quote of the day: "Success is stumbling from failure
Lecture 15: More Iterative Ideas
 Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
OpenFOAM + GPGPU. İbrahim Özküçük
 OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
Introduction to Multigrid and its Parallelization
 Introduction to Multigrid and its Parallelization! Thomas D. Economon Lecture 14a May 28, 2014 Announcements 2 HW 1 & 2 have been returned. Any questions? Final projects are due June 11, 5 pm. If you are
Introduction to Multigrid and its Parallelization! Thomas D. Economon Lecture 14a May 28, 2014 Announcements 2 HW 1 & 2 have been returned. Any questions? Final projects are due June 11, 5 pm. If you are
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Available online at ScienceDirect. Parallel Computational Fluid Dynamics Conference (ParCFD2013)
") Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
Iterative Sparse Triangular Solves for Preconditioning
 Euro-Par 2015, Vienna Aug 24-28, 2015 Iterative Sparse Triangular Solves for Preconditioning Hartwig Anzt, Edmond Chow and Jack Dongarra Incomplete Factorization Preconditioning Incomplete LU factorizations
Euro-Par 2015, Vienna Aug 24-28, 2015 Iterative Sparse Triangular Solves for Preconditioning Hartwig Anzt, Edmond Chow and Jack Dongarra Incomplete Factorization Preconditioning Incomplete LU factorizations
Unstructured Mesh Generation for Implicit Moving Geometries and Level Set Applications
 Unstructured Mesh Generation for Implicit Moving Geometries and Level Set Applications Per-Olof Persson (persson@mit.edu) Department of Mathematics Massachusetts Institute of Technology http://www.mit.edu/
Unstructured Mesh Generation for Implicit Moving Geometries and Level Set Applications Per-Olof Persson (persson@mit.edu) Department of Mathematics Massachusetts Institute of Technology http://www.mit.edu/
Contents. I Basics 1. Copyright by SIAM. Unauthorized reproduction of this article is prohibited.
 page v Preface xiii I Basics 1 1 Optimization Models 3 1.1 Introduction... 3 1.2 Optimization: An Informal Introduction... 4 1.3 Linear Equations... 7 1.4 Linear Optimization... 10 Exercises... 12 1.5
page v Preface xiii I Basics 1 1 Optimization Models 3 1.1 Introduction... 3 1.2 Optimization: An Informal Introduction... 4 1.3 Linear Equations... 7 1.4 Linear Optimization... 10 Exercises... 12 1.5
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs
 Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs M. J. McNenly and R. A. Whitesides GPU Technology Conference March 27, 2014 San Jose, CA LLNL-PRES-652254! This work performed under
Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs M. J. McNenly and R. A. Whitesides GPU Technology Conference March 27, 2014 San Jose, CA LLNL-PRES-652254! This work performed under
Accelerating a Simulation of Type I X ray Bursts from Accreting Neutron Stars Mark Mackey Professor Alexander Heger
 Accelerating a Simulation of Type I X ray Bursts from Accreting Neutron Stars Mark Mackey Professor Alexander Heger The goal of my project was to develop an optimized linear system solver to shorten the
Accelerating a Simulation of Type I X ray Bursts from Accreting Neutron Stars Mark Mackey Professor Alexander Heger The goal of my project was to develop an optimized linear system solver to shorten the
Figure 6.1: Truss topology optimization diagram.
 6 Implementation 6.1 Outline This chapter shows the implementation details to optimize the truss, obtained in the ground structure approach, according to the formulation presented in previous chapters.
6 Implementation 6.1 Outline This chapter shows the implementation details to optimize the truss, obtained in the ground structure approach, according to the formulation presented in previous chapters.
Approaches to Parallel Implementation of the BDDC Method
 Approaches to Parallel Implementation of the BDDC Method Jakub Šístek Includes joint work with P. Burda, M. Čertíková, J. Mandel, J. Novotný, B. Sousedík. Institute of Mathematics of the AS CR, Prague
Approaches to Parallel Implementation of the BDDC Method Jakub Šístek Includes joint work with P. Burda, M. Čertíková, J. Mandel, J. Novotný, B. Sousedík. Institute of Mathematics of the AS CR, Prague
Center for Computational Science
 Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
FOR P3: A monolithic multigrid FEM solver for fluid structure interaction
 FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
PhD Student. Associate Professor, Co-Director, Center for Computational Earth and Environmental Science. Abdulrahman Manea.
 Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
GPU Cluster Computing for FEM
 GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
HYBRID DIRECT AND ITERATIVE SOLVER FOR H ADAPTIVE MESHES WITH POINT SINGULARITIES
 HYBRID DIRECT AND ITERATIVE SOLVER FOR H ADAPTIVE MESHES WITH POINT SINGULARITIES Maciej Paszyński Department of Computer Science, AGH University of Science and Technology, Kraków, Poland email: paszynsk@agh.edu.pl
HYBRID DIRECT AND ITERATIVE SOLVER FOR H ADAPTIVE MESHES WITH POINT SINGULARITIES Maciej Paszyński Department of Computer Science, AGH University of Science and Technology, Kraków, Poland email: paszynsk@agh.edu.pl
Efficient Imaging Algorithms on Many-Core Platforms
 Efficient Imaging Algorithms on Many-Core Platforms H. Köstler Dagstuhl, 22.11.2011 Contents Imaging Applications HDR Compression performance of PDE-based models Image Denoising performance of patch-based
Efficient Imaging Algorithms on Many-Core Platforms H. Köstler Dagstuhl, 22.11.2011 Contents Imaging Applications HDR Compression performance of PDE-based models Image Denoising performance of patch-based
Matrix-free IPM with GPU acceleration
 Matrix-free IPM with GPU acceleration Julian Hall, Edmund Smith and Jacek Gondzio School of Mathematics University of Edinburgh jajhall@ed.ac.uk 29th June 2011 Linear programming theory Primal-dual pair
Matrix-free IPM with GPU acceleration Julian Hall, Edmund Smith and Jacek Gondzio School of Mathematics University of Edinburgh jajhall@ed.ac.uk 29th June 2011 Linear programming theory Primal-dual pair
Large Displacement Optical Flow & Applications
 Large Displacement Optical Flow & Applications Narayanan Sundaram, Kurt Keutzer (Parlab) In collaboration with Thomas Brox (University of Freiburg) Michael Tao (University of California Berkeley) Parlab
Large Displacement Optical Flow & Applications Narayanan Sundaram, Kurt Keutzer (Parlab) In collaboration with Thomas Brox (University of Freiburg) Michael Tao (University of California Berkeley) Parlab
Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009
 Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009 Dan l Pierce, PhD, MBA, CEO & President AAI Joint with: Yukai Hung, Chia-Chi Liu, Yao-Hung Tsai, Weichung Wang, and David Yu Access
Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009 Dan l Pierce, PhD, MBA, CEO & President AAI Joint with: Yukai Hung, Chia-Chi Liu, Yao-Hung Tsai, Weichung Wang, and David Yu Access
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
Generating 3D Topologies with Multiple Constraints on the GPU
 1 th World Congress on Structural and Multidisciplinary Optimization May 19-4, 13, Orlando, Florida, USA Generating 3D Topologies with Multiple Constraints on the GPU Krishnan Suresh University of Wisconsin,
1 th World Congress on Structural and Multidisciplinary Optimization May 19-4, 13, Orlando, Florida, USA Generating 3D Topologies with Multiple Constraints on the GPU Krishnan Suresh University of Wisconsin,
MULTIPHYSICS SIMULATION USING GPU
 MULTIPHYSICS SIMULATION USING GPU Arman Pazouki Simulation-Based Engineering Laboratory Department of Mechanical Engineering University of Wisconsin - Madison Acknowledgements Prof. Dan Negrut Dr. Radu
MULTIPHYSICS SIMULATION USING GPU Arman Pazouki Simulation-Based Engineering Laboratory Department of Mechanical Engineering University of Wisconsin - Madison Acknowledgements Prof. Dan Negrut Dr. Radu
Accelerating Double Precision FEM Simulations with GPUs
 Accelerating Double Precision FEM Simulations with GPUs Dominik Göddeke 1 3 Robert Strzodka 2 Stefan Turek 1 dominik.goeddeke@math.uni-dortmund.de 1 Mathematics III: Applied Mathematics and Numerics, University
Accelerating Double Precision FEM Simulations with GPUs Dominik Göddeke 1 3 Robert Strzodka 2 Stefan Turek 1 dominik.goeddeke@math.uni-dortmund.de 1 Mathematics III: Applied Mathematics and Numerics, University
Recent developments in simulation, optimization and control of flexible multibody systems
 Recent developments in simulation, optimization and control of flexible multibody systems Olivier Brüls Department of Aerospace and Mechanical Engineering University of Liège o.bruls@ulg.ac.be Katholieke
Recent developments in simulation, optimization and control of flexible multibody systems Olivier Brüls Department of Aerospace and Mechanical Engineering University of Liège o.bruls@ulg.ac.be Katholieke
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms
 Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
cuibm A GPU Accelerated Immersed Boundary Method
 cuibm A GPU Accelerated Immersed Boundary Method S. K. Layton, A. Krishnan and L. A. Barba Corresponding author: labarba@bu.edu Department of Mechanical Engineering, Boston University, Boston, MA, 225,
cuibm A GPU Accelerated Immersed Boundary Method S. K. Layton, A. Krishnan and L. A. Barba Corresponding author: labarba@bu.edu Department of Mechanical Engineering, Boston University, Boston, MA, 225,
GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU
 April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
Accelerating the Conjugate Gradient Algorithm with GPUs in CFD Simulations
 Accelerating the Conjugate Gradient Algorithm with GPUs in CFD Simulations Hartwig Anzt 1, Marc Baboulin 2, Jack Dongarra 1, Yvan Fournier 3, Frank Hulsemann 3, Amal Khabou 2, and Yushan Wang 2 1 University
Accelerating the Conjugate Gradient Algorithm with GPUs in CFD Simulations Hartwig Anzt 1, Marc Baboulin 2, Jack Dongarra 1, Yvan Fournier 3, Frank Hulsemann 3, Amal Khabou 2, and Yushan Wang 2 1 University
Driven Cavity Example
 BMAppendixI.qxd 11/14/12 6:55 PM Page I-1 I CFD Driven Cavity Example I.1 Problem One of the classic benchmarks in CFD is the driven cavity problem. Consider steady, incompressible, viscous flow in a square
BMAppendixI.qxd 11/14/12 6:55 PM Page I-1 I CFD Driven Cavity Example I.1 Problem One of the classic benchmarks in CFD is the driven cavity problem. Consider steady, incompressible, viscous flow in a square
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Parallel High-Order Geometric Multigrid Methods on Adaptive Meshes for Highly Heterogeneous Nonlinear Stokes Flow Simulations of Earth s Mantle
 ICES Student Forum The University of Texas at Austin, USA November 4, 204 Parallel High-Order Geometric Multigrid Methods on Adaptive Meshes for Highly Heterogeneous Nonlinear Stokes Flow Simulations of
ICES Student Forum The University of Texas at Austin, USA November 4, 204 Parallel High-Order Geometric Multigrid Methods on Adaptive Meshes for Highly Heterogeneous Nonlinear Stokes Flow Simulations of
HIPS : a parallel hybrid direct/iterative solver based on a Schur complement approach
 HIPS : a parallel hybrid direct/iterative solver based on a Schur complement approach Mini-workshop PHyLeaS associated team J. Gaidamour, P. Hénon July 9, 28 HIPS : an hybrid direct/iterative solver /
HIPS : a parallel hybrid direct/iterative solver based on a Schur complement approach Mini-workshop PHyLeaS associated team J. Gaidamour, P. Hénon July 9, 28 HIPS : an hybrid direct/iterative solver /
Computational Fluid Dynamics - Incompressible Flows
 Computational Fluid Dynamics - Incompressible Flows March 25, 2008 Incompressible Flows Basis Functions Discrete Equations CFD - Incompressible Flows CFD is a Huge field Numerical Techniques for solving
Computational Fluid Dynamics - Incompressible Flows March 25, 2008 Incompressible Flows Basis Functions Discrete Equations CFD - Incompressible Flows CFD is a Huge field Numerical Techniques for solving
Maximum flow problem CE 377K. March 3, 2015
 Maximum flow problem CE 377K March 3, 2015 Informal evaluation results 2 slow, 16 OK, 2 fast Most unclear topics: max-flow/min-cut, WHAT WILL BE ON THE MIDTERM? Most helpful things: review at start of
Maximum flow problem CE 377K March 3, 2015 Informal evaluation results 2 slow, 16 OK, 2 fast Most unclear topics: max-flow/min-cut, WHAT WILL BE ON THE MIDTERM? Most helpful things: review at start of
Title. Author(s)P. LATCHAROTE; Y. KAI. Issue Date Doc URL. Type. Note. File Information
P. LATCHAROTE; Y. KAI. Issue Date Doc URL. Type. Note. File Information") Title HIGH PERFORMANCE COMPUTING OF DYNAMIC STRUCTURAL RES INTEGRATED EARTHQUAKE SIMULATION Author(s)P. LATCHAROTE; Y. KAI Issue Date 2013-09-13 Doc URL http://hdl.handle.net/2115/54441 Type proceedings
Title HIGH PERFORMANCE COMPUTING OF DYNAMIC STRUCTURAL RES INTEGRATED EARTHQUAKE SIMULATION Author(s)P. LATCHAROTE; Y. KAI Issue Date 2013-09-13 Doc URL http://hdl.handle.net/2115/54441 Type proceedings
(Sparse) Linear Solvers
 Linear Solvers") (Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 2 Don t you just invert
(Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 2 Don t you just invert
Simulation in Computer Graphics. Particles. Matthias Teschner. Computer Science Department University of Freiburg
 Simulation in Computer Graphics Particles Matthias Teschner Computer Science Department University of Freiburg Outline introduction particle motion finite differences system of first order ODEs second
Simulation in Computer Graphics Particles Matthias Teschner Computer Science Department University of Freiburg Outline introduction particle motion finite differences system of first order ODEs second
Accelerating the Iterative Linear Solver for Reservoir Simulation
 Accelerating the Iterative Linear Solver for Reservoir Simulation Wei Wu 1, Xiang Li 2, Lei He 1, Dongxiao Zhang 2 1 Electrical Engineering Department, UCLA 2 Department of Energy and Resources Engineering,
Accelerating the Iterative Linear Solver for Reservoir Simulation Wei Wu 1, Xiang Li 2, Lei He 1, Dongxiao Zhang 2 1 Electrical Engineering Department, UCLA 2 Department of Energy and Resources Engineering,
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
ME451 Kinematics and Dynamics of Machine Systems
 ME451 Kinematics and Dynamics of Machine Systems Introduction September 4, 2013 Radu Serban University of Wisconsin, Madison Overview, Today s Lecture 2 Discuss Syllabus Discuss schedule related issues
ME451 Kinematics and Dynamics of Machine Systems Introduction September 4, 2013 Radu Serban University of Wisconsin, Madison Overview, Today s Lecture 2 Discuss Syllabus Discuss schedule related issues
Comparison of parallel preconditioners for a Newton-Krylov flow solver
 Comparison of parallel preconditioners for a Newton-Krylov flow solver Jason E. Hicken, Michal Osusky, and David W. Zingg 1Introduction Analysis of the results from the AIAA Drag Prediction workshops (Mavriplis
Comparison of parallel preconditioners for a Newton-Krylov flow solver Jason E. Hicken, Michal Osusky, and David W. Zingg 1Introduction Analysis of the results from the AIAA Drag Prediction workshops (Mavriplis
Numerical schemes for Hamilton-Jacobi equations, control problems and games
 Numerical schemes for Hamilton-Jacobi equations, control problems and games M. Falcone H. Zidani SADCO Spring School Applied and Numerical Optimal Control April 23-27, 2012, Paris Lecture 2/3 M. Falcone
Numerical schemes for Hamilton-Jacobi equations, control problems and games M. Falcone H. Zidani SADCO Spring School Applied and Numerical Optimal Control April 23-27, 2012, Paris Lecture 2/3 M. Falcone
GPU Implementation of Elliptic Solvers in NWP. Numerical Weather- and Climate- Prediction
 1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
2 Fundamentals of Serial Linear Algebra
 . Direct Solution of Linear Systems.. Gaussian Elimination.. LU Decomposition and FBS..3 Cholesky Decomposition..4 Multifrontal Methods. Iterative Solution of Linear Systems.. Jacobi Method Fundamentals
. Direct Solution of Linear Systems.. Gaussian Elimination.. LU Decomposition and FBS..3 Cholesky Decomposition..4 Multifrontal Methods. Iterative Solution of Linear Systems.. Jacobi Method Fundamentals
CS 395T Lecture 12: Feature Matching and Bundle Adjustment. Qixing Huang October 10 st 2018
 CS 395T Lecture 12: Feature Matching and Bundle Adjustment Qixing Huang October 10 st 2018 Lecture Overview Dense Feature Correspondences Bundle Adjustment in Structure-from-Motion Image Matching Algorithm
CS 395T Lecture 12: Feature Matching and Bundle Adjustment Qixing Huang October 10 st 2018 Lecture Overview Dense Feature Correspondences Bundle Adjustment in Structure-from-Motion Image Matching Algorithm
Introduction to Optimization
 Introduction to Optimization Second Order Optimization Methods Marc Toussaint U Stuttgart Planned Outline Gradient-based optimization (1st order methods) plain grad., steepest descent, conjugate grad.,
Introduction to Optimization Second Order Optimization Methods Marc Toussaint U Stuttgart Planned Outline Gradient-based optimization (1st order methods) plain grad., steepest descent, conjugate grad.,
GPU-Accelerated Algebraic Multigrid for Commercial Applications. Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA
 GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
ME451 Kinematics and Dynamics of Machine Systems
 ME451 Kinematics and Dynamics of Machine Systems Basic Concepts in Planar Kinematics 3.1, 3.2 September 18, 2013 Radu Serban University of Wisconsin-Madison 2 Before we get started Last time: Velocity
ME451 Kinematics and Dynamics of Machine Systems Basic Concepts in Planar Kinematics 3.1, 3.2 September 18, 2013 Radu Serban University of Wisconsin-Madison 2 Before we get started Last time: Velocity
Modern GPUs (Graphics Processing Units)
") Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX 580 512 cores 1.6 Tera FLOPs 1.5 GB
Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX 580 512 cores 1.6 Tera FLOPs 1.5 GB
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Integrated Estimation, Guidance & Control II
 Optimal Control, Guidance and Estimation Lecture 32 Integrated Estimation, Guidance & Control II Prof. Radhakant Padhi Dept. of Aerospace Engineering Indian Institute of Science - Bangalore Motivation
Optimal Control, Guidance and Estimation Lecture 32 Integrated Estimation, Guidance & Control II Prof. Radhakant Padhi Dept. of Aerospace Engineering Indian Institute of Science - Bangalore Motivation
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs
 3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
Inter and Intra-Modal Deformable Registration:
 Inter and Intra-Modal Deformable Registration: Continuous Deformations Meet Efficient Optimal Linear Programming Ben Glocker 1,2, Nikos Komodakis 1,3, Nikos Paragios 1, Georgios Tziritas 3, Nassir Navab
Inter and Intra-Modal Deformable Registration: Continuous Deformations Meet Efficient Optimal Linear Programming Ben Glocker 1,2, Nikos Komodakis 1,3, Nikos Paragios 1, Georgios Tziritas 3, Nassir Navab
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Olivier Brüls. Department of Aerospace and Mechanical Engineering University of Liège
 Fully coupled simulation of mechatronic and flexible multibody systems: An extended finite element approach Olivier Brüls Department of Aerospace and Mechanical Engineering University of Liège o.bruls@ulg.ac.be
Fully coupled simulation of mechatronic and flexible multibody systems: An extended finite element approach Olivier Brüls Department of Aerospace and Mechanical Engineering University of Liège o.bruls@ulg.ac.be