Can Similar Scenes help Surface Layout Estimation?
|
|
|
- Benedict Hicks
- 5 years ago
- Views:
Transcription

1 Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. Abstract We describe a preliminary investigation of utilising large amounts of unlabelled image data to help in the estimation of rough scene layout. We take the single-view geometry estimation system of Hoiem et al [3] as the baseline and see if it is possible to improve its performance by considering a set of similar scenes gathered from the web. The two complimentary approaches being considered are 1) improving surface classification by using average geometry estimated from the matches, and 2) improving surface segmentation by injecting segments generated from the average of the matched images. The system is evaluated using the labelled 300-image dataset of Hoiem et al. and shows promising results. Figure 1. In this paper we show that Geometric Context [3] performance can be improved by using a set of scene matches drawn from a large unlabelled image collection 1. Introduction Reasoning about a scene from a photograph is an inherently ambiguous task. This is because a single image in itself does not carry enough information to disambiguate the world that it is depicting. Of course, humans have no problems understanding photographs because of all the prior visual experience they can bring to bear on the task. How can we help computers do the same? After a lull of some 30 years, there is a resurgence of interest in single view approaches to scene understanding. Good progress has been made on a number of fronts, including contextual priming [10], depth estimation [6, 8], surface layout estimation [3] and classification [5], among others. One common ingredient in all these approaches is that they pose the problem in terms of supervised learning, using training datasets of labelled input/output image pairs. However, labelled data is hard to come by, especially in large enough quantities that are likely to be necessary for modelling the full richness of our visual world. At the same time, the popularity of Internet photo-sharing websites such as Flickr means that there are now enormous amounts of freely available but largely unlabelled data, literally billions of images! Some approaches suggested using this data via keyword searches, as a way of providing weak text-based annotations. But while this works really well for specific (and well-known) geographic locations [9] or specific objects [12], it fails to find more generic scene types (e.g. alleyway ). Very recently, a new class of approaches have emerged which successfully use huge amounts of completely unlabelled visual data. Hays and Efros [2] demonstrate that it is possible to find semantically similar scene matches in a dataset of 2 million Flickr images and use that information to fill holes in images. Torralba et al. [11] show that using a dataset of 80 million images, it is possible to perform operations such as gray-image colorization and detecting image orientation without any labels, just from the power of the data itself. But we believe that these application are only scratching the surface of what is possible with very-large-scale, unlabelled image databases Overview In this paper, we will describe a preliminary investigation of utilising large amounts of unlabelled image data to help in the estimation of rough scene layout (See Fig. 1). We will take the single-view geometry estimation system of Hoiem et al. [3] as the baseline and see if it is possible to improve its performance by considering a set of similar scenes gathered from the web. Given an input image, the system 1
2 attempts to segment it into meaningful surfaces and to classify each surface into a set of geometric classes which correspond to rough surface orientations. The system provides two classifiers: the main one, deciding between ground, vertical, and sky classes, and the sub-classifier which predicts the orientation of the vertical surface into planar left, center, and right, and non-planar porous and solid classes. The performance of the main classifier as reported in [3] is already at the level close to the labelling noise and is unlikely to be improved further. The performance of the sub-classifier however is still rather weak, and that is where we will concentrate our efforts here. We propose to improve the performance of the system of Hoiem et al. by considering not only the actual input image to the system, but also a set of similar scenes found in a large image dataset of 6 million images collected from Flickr. Following the approach of Hays and Efros [2], we use the scene gist descriptor of Oliva and Torralba [6] to query a large image dataset to find a set of nearest neighbour matches. Our goal is to use these scene matches to help improve the algorithm s understanding of the input image at hand. Of course, the matches are not labelled, so it is not immediately obvious that any improvement can be achieved since little new information is being added to the process. However, in this paper we argue that even without labels, similar matching images could be of help for a difficult single-image task. In the case of the Geometric Context system of Hoiem et al., we consider two complimentary approaches for improving the performance: Improving surface classification Consider a surface such as a side of a building, but with an unusual or confusing texture which prevents the geometric context algorithm from estimating the surface orientation correctly. Now further consider that a set of similar scenes is available where the geometric arrangement of buildings is very much like in the original image, but the texturing of the surfaces is different. In this case, the geometric context output for the matches might produce better results than for the original image. Now, if we can figure out a way of injecting this new knowledge into the system, we can improve the performance of surface classification (See Fig. 2). Improving surface segmentation Another problem with the geometric context approach is that it often does not find a suitable segmentation for each surface, which leads to poor surface classification performance. Indeed, Hoiem et al. have shown that their classification performance improves a great deal if a perfect ground-truth segmentation is used in their system. This suggests a potential benefit to try and improve segmentation. Again, consider an input image where the boundary between two surfaces is not welldefined in the image and thus is missed by all the segmentations of Hoiem et al. s multiple segmentation algorithm. Now consider the set of scene matches which, hopefully, depict geometrically similar scenes, but perhaps with different failure modes. Therefore, one can hope that on average, the two surfaces in question would be visually more dissimilar and easier to segment out. Again, if we could utilise the knowledge provided by the set of matching scenes, and inject it into the segmentation algorithm, we might be able to improve the performance of the system (See Fig. 4). In the rest of this paper, we will describe our approach for operationalizing these two ideas and thereby present results of our investigation on the images from the Geometric Context dataset [3] with scene matches retrieved from Flickr. In the following, we use the words scene matches, nearest neighbours and similar scene images interchangeably. 2. Improving Surface Classification Our basic motivation is to use information from huge amounts of unlabelled but similar images to aid the surface classification of an input image. As mentioned before, we retrieve a set of similar scene images for an input image from the vast collection of digital images on Flickr using the method of [2]. The nearest neighbours are based on the GIST feature descriptor plus color. The top 200 of the retrieved nearest neighbours are used in our algorithm. Given these neighbour images, we apply the Geometric Context (GC) algorithm to obtain their coarse image geometry. The GC algorithm proposed by Hoiem et al. [3] employs a multiple segmentation framework to build larger segments by merging simple super-pixel [1] elements of an image. By using the features extracted from these larger segments in a classification framework, the mapping between scene features and their corresponding rough surface layout is learnt. The algorithm outputs a confidence vector V s for every super-pixel s in the image (which indicates the probability of the super-pixel element belonging to either of the seven geometric classes) and the max component of this vector is chosen as the most probable label. The nearest neighbours retrieved using [2] are similar to the input image with respect to their overall scene appearance (based on GIST). As no geometrical cues are utilized in the matching process, some of the retrieved matches could be random and may not have any relation to the input image in terms of their surface layout. In order to filter the matches, we perform a clustering step. It must be emphasised that in [2] scene matches were filtered by user interaction, while in [7] the problem was resolved by clustering on the ground-truth labels associated with the matches. As we do not have access to the labels, we perform a meanshift clustering of the images by using the GC output confidences as the features for clustering. More precisely, the
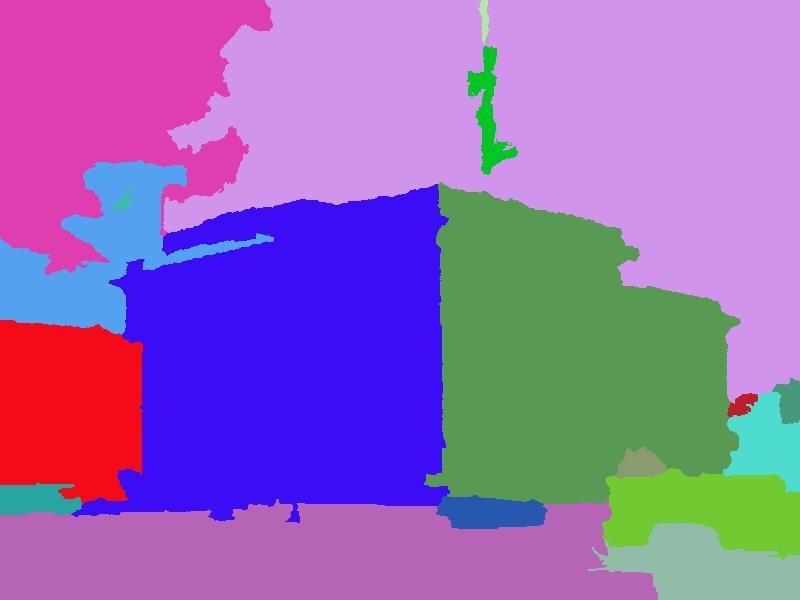
 and their Geometric Context outputs (below) (g) Top 12 scene matches obtained after clustering (above) and their")
: Given an input image, the scene matches retrieved using [2] (second row) are clustered based on their GC output confidences to obtain a")


).")
 as against the scene prior from all the neighbours (accuracy was 61.7%).")


3 Input image Ground truth Hoiem et al. Average scene prior Our result Top 12 scene matches retrieved using GIST (above) and their Geometric Context outputs (below) (g) Top 12 scene matches obtained after clustering (above) and their Geometric Context outputs (below) Figure 2. Using average scene prior to aid Geometric Context (GC): Given an input image, the scene matches retrieved using [2] (second row) are clustered based on their GC output confidences to obtain a relevant set of matches (third row). The clustering helps in filtering out poor scene matches (images 4,5,6,11 in the second row). Using the clustered matches, the average scene prior is computed by marginalizing over their GC confidences and is used as a feature for the input image (only the max component is displayed in figure). This has helped in improving the surface layout result of the brick wall scene. confidence vectors V s obtained for every pixel in the ith neighbour image are vectorized to obtain a single large confidence vector V i and is used as the feature vector to cluster the N neighbours. At the end of the clustering process, we only consider the images belonging to the largest cluster and ignore the rest. The clustering step is quite helpful in obtaining a refined set of matches with similar rough surface layouts amongst them (as observed in Fig.2(g)). Moreover we observed a quantitative improvement in the sub-classifier classifier accuracy (of around 1.5%) when using the average scene prior from clustered neighbours (accuracy was 63.2%) as against the scene prior from all the neighbours (accuracy was 61.7%). Given the clustered scene matches, we can now get an average geometric scene prior for the input image by marginalizing the GC output confidences over the clustered scene matches. More precisely, given a super-pixel element s of the input image, the GC confidence vectors V s of the corresponding pixel elements across the neighbour images are averaged to yield a prior confidence vector P s for the super-pixel. As the matches possess similar surface layout, by marginalizing their output confidences, we could obtain a good guess of the most probable geometric class label of a super-pixel element in the input image. In Fig. 3, we see that this average prior by itself performs well in classifying Input image Ground truth Average scene prior Figure 3. The average scene prior performs surprisingly well in estimating the surface layout of an input image. the input image. Interestingly (as we will see in Section. 4), the classification accuracy obtained just by using this prior information (without actually looking at the image) is comparable to the baseline result of Hoiem et al. The average geometric scene prior acts as a good cue for scene classification of the input image. Thus we use it as a feature in conjunction with the the original set of features employed by Hoiem et al. in their algorithm (i.e., colour, texture, location and perspectivity) and retrain the classifiers. Had this prior information contained discriminative characteristics about the input image, it should have aided in the better classification of the super-pixels. We indeed observed that the classifiers had used these features during
 generated using average image features Average image Super-pixels Ground")

![matches (retrieved using [2]) are extracted and marginalised to obtain an average scene feature (which could be](/docs-images/85/92766734/images/4-2.jpg "visualised as the feature corresponding to the average image).")


 nearest neighbour matches retrieved by [2] are")


 the entire block of the")


![improving segmentation and classification [3, 4].](/docs-images/85/92766734/images/4-11.jpg "Unfortunately, this task is not easy and it is often a challenge to produce good segmentations (corresponding to")


.")

 to obtain an average in the feature space.")
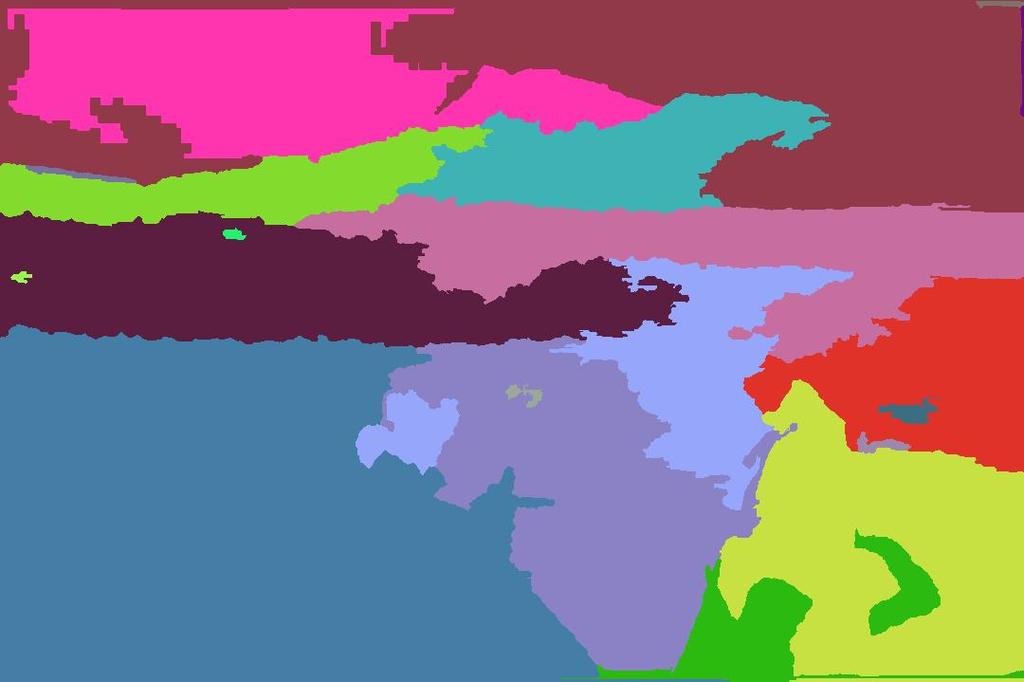
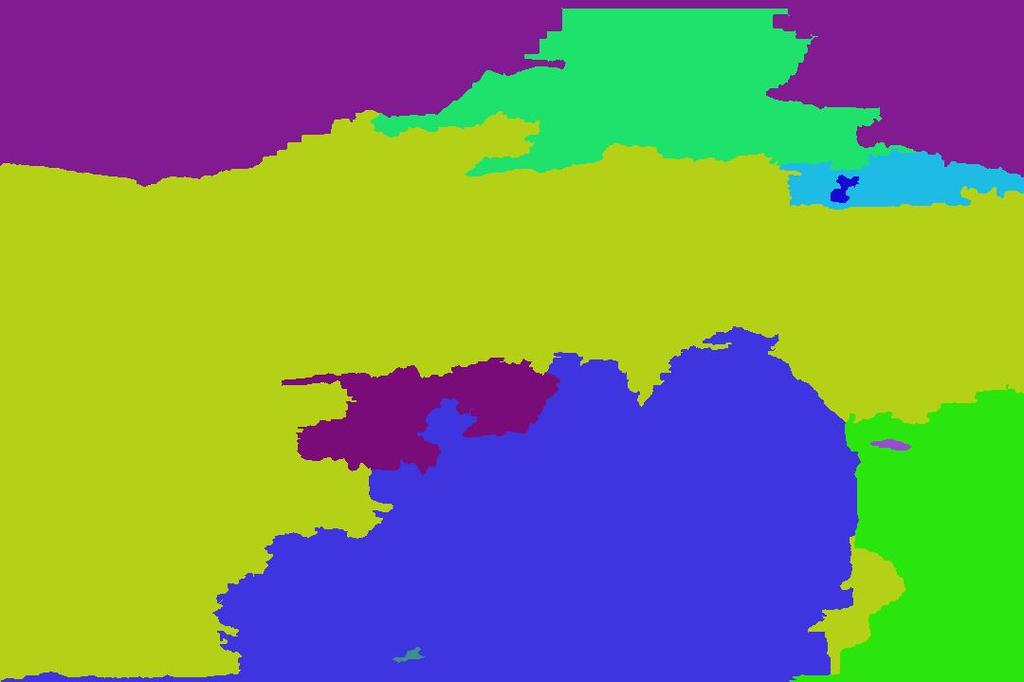
4 Input image Multiple segmentations (5,10,15,20,25) generated using input image features Example scene matches Multiple segmentations (5,10,15,20,25) generated using average image features Average image Super-pixels Ground truth segments Ground truth labels (i) Hoiem et al. (j) Our result Figure 4. Similar scenes aid in proposing better segmentations for an image: Given an input image, features from its scene matches (retrieved using [2]) are extracted and marginalised to obtain an average scene feature (which could be visualised as the feature corresponding to the average image). The multiple segmentations generated using this average feature set are characterised based on the overall scene geometry and thus could be helpful in the classification of the input image. Observe the improvement in the surface layout result of the shore scene. the classification process which signifies the prior as a useful cue. Fig. 2 graphically illustrates the overall approach. Given the input image of a brick wall scene, the top 12 (of the 200) nearest neighbour matches retrieved by [2] are displayed along with their Geometric Context outputs. Some of the top matches (e.g., images 4,5,6,11) fail to possess similar surface layout as the original image. However by clustering the scene matches based on their GC output confidences, we gather a cluster of matches with similar surface layouts. Using these clustered neighbours, average scene prior is computed by marginalizing over them and is used as a feature in the classification algorithm. Observe that the estimated average scene geometry correctly predicts (with few errors) the entire block of the brick wall as a single large vertical class segment. This helps in an improved estimation of the perspectivity cues that leads to its correct sub-classification as belonging to the planar left class. 3. Improving Surface Segmentation Having good spatial support for regions in the input image significantly helps in improving segmentation and classification [3, 4]. Unfortunately, this task is not easy and it is often a challenge to produce good segmentations (corresponding to different homogeneous regions in an image) by only using the information from the image. Here we study the possibility of utilising the information from the retrieved scene matches to aid the surface segmentation task. In the previous section, we had considered the average scene geometry for improving the classification result. It is also possible to consider the average of the neighbour images themselves in hope that they can improve the segmentation. However, we did not find the direct pixel-wise average of the scene matches to be useful (see Fig. 4). Instead, given the retrieved scene matches, we marginalise the low-level scene features i.e., colour, texture, location (that were already computed while applying the Geometric Context on them) to obtain an average in the feature space. The average feature vector is a useful cue for forming better segments of the input image. To see this, consider the case where the input image consists of a ground region with varying texture and colour characteristics. In such a case, using the super-pixel features exclusively from the input image would fail to merge these regions together to form a holistic ground segment. However, by retrieving the similar scene matches and computing the average scene feature, the overall structure of the scene (unaffected by artifacts such as shadows etc) could be captured. Thus the averaging yields a high-level descriptor for the super-pixel elements of the input image based on the global scene organisation. Using this descriptor potentially helps in forming improved segmentations that better convey the overall scene structure and in turn offer good spatial support. Fig. 4 illustrates our idea. Given the shore scene image, the features corresponding to its similar scene matches are
5 used to obtain an average scene feature (as it is difficult to visualise the feature vectors corresponding to scene matches and the average, we instead display the images). Using these features, we generate the multiple segmentations as done in Hoiem et al. These multiple segmentations provide improved spatial support for different homogeneous regions and when used along with the segmentations generated using input image features leads to an improved surface layout estimation for the scene. Hence the scene matches can be used for improving the segmentation of the input image, in addition to improving the classification accuracy. 4. Experimental Results The evaluation of the proposed hypothesis was performed on the 300 images of the Geometric Context dataset [3]. The top 200 scene matches to each image were retrieved using the method of [2] from the collection of six million images in Flickr. By applying the Geometric Context algorithm on these images and marginalizing their output confidences, we obtain an average scene prior (as described in Section. 2). In Fig. 5, we analyse the quality of this scene prior estimated with a varying number of neighbour images. The figure displays the main-classifier and vertical sub-classifier classifier accuracies obtained by employing only the scene prior and without using any input image features. It is interesting to note that by just using the scene prior, one could achieve a modest classification result (i.e., the accuracies drop only by around 5-8% compared to the baseline result of Hoiem et al.). Also the peak is obtained when around top 40 nearest neighbours are used. In Fig. 6, we demonstrate few results of using the average scene prior as a useful cue for improved surface classification. The figure illustrates few of the examples where the surface layout result was improved by inclusion of the scene prior. Notice that the clustering process helps in gathering similar scenes out of the nearest neighbour image matches and the marginalization results in providing the overall spatial layout of the scene. In Fig. 7, we display few results of the improved segmentations. For every input image, the features from the retrieved scene matches are marginalised to obtain an average feature vector. This feature vector is used in the segmentation process to yield better spatial support for the homogeneous regions within the image. Notice that the improved spatial support has helped in obtaining better Geometric context result. We supplement the above qualitative analysis of the approach by a quantitative performance analysis. In Table. 4, the classification accuracies obtained for the main-class and the vertical sub-class classifiers are displayed for the various cases. As mentioned in Section. 1.1, we mainly focus on the improvement of the sub-classifier classifier. Notice that using the augmented features set (i.e., with the inclusion of average scene prior from clustered neighbours) helps in improving the sub-classifier classifier accuracy by around 3%, while using the average scene features yields an improvement around 1.5%. The improvements are statistically significant (p < 0.05). However, by combining both sources of information, we do not see much additive increase in the accuracies suggesting that the two sources of information are not completely independent. Table 1. Classification Accuracies Sub-Class Main-Class 1. Baseline (by Hoiem et al.) 60.5% 87.2% 2. Using only average scene prior (without using input image features) 52.3% 82.5% 3. Augmenting feature set 63.2% 87.3% with the average scene prior 4. Using segmentations from 61.5% 87.7% the average scene features 5. Combining both 3 & % 87.9% above Figure 5. Accuracies obtained by employing only the average scene prior computed from a varying number of scene matches. By using only scene matches (and no information from the input image), we could achieve an accuracy of 82.5% for the mainclassifier and 52.3% for the sub-classifier. 5. Discussion In this work, we have analysed the utility of large amounts of unlabelled image data to aid the process of surface layout estimation. By using information from similar scene matches to an input image, the Geometric context [3] result was improved. The improvement in accuracy is modest (from 60.5% to 63.6%). But it should be noted that the maximum possible sub-classifier classifier accuracy when tested on ground-truth segmentations using a classifier trained on multiple segmentations is 65.5%. (If the classifier is trained and tested both on ground-truth segmentations, then it acheives 71.5% [3] but this is not realistic). Thus the problem of achieving improved performance is quite challenging (as we are close to the optimal


6 Figure 6. Using average scene prior as an input image feature helps in improving the Geometric Context (GC) result. Input image Ground truth labelling Result from Hoiem et al. [3] Average scene prior Our result Top few scene matches and their corresponding Geometric Context outputs. In this example, the classification of the tree is corrected upon inclusion of the scene prior. operating point). Also further evaluating the qualitative results, we observe that for many example images where good scene matches were acquired, the improvement in the result is substantial. While for many other, the approach of Hoiem et al. already performs well and thus there is little scope for improvement. For the remaining cases (i.e., extremely complicated scenes), the retrieved scene matches were poor and had not aided the classification. Nevertheless the most interesting observation is that even without using any input image features, one can achieve a good classification accuracy by just marginalizing the scene matches. This suggests that there exists an inherent consistancy amongst real world scenes that is captured by these unlabelled scene matches, thus providing a global constraint over any given test image. Our preliminary investigation has shown the potential for using unlabelled data along with labelled data to achieve improved performance. Our future plan is to study better methods for injecting the scene prior (such as a mixture of experts framework) to further effectively use this information. Also our proposed approach could act as a potential tool for gathering more data for training the classifiers in a co-training based framework. Acknowledgments We thank Derek Hoiem for providing the code and data used in [3], and James Hays for generating the scene matches from his Flickr dataset. This research was supported in part by the National Science Foundation under Grant IIS References [1] P. Felzenszwalb and D. Huttenlocher. Efficient graphbased image segmentation. IJCV, 25, [2] J. Hays and A. A. Efros. Scene completion using millions of photographs. ACM Transactions on Graphics (SIGGRAPH), 26(3), [3] D. Hoiem, A. Efros, and M. Hebert. Recovering surface layout from an image. International Journal of Computer Vision, 75(1), [4] T. Malisiewicz and A. A. Efros. Improving spatial support for objects via multiple segmentations. British Machine Vision Conference, [5] V. Nedovic, A. W. Smeulders, A. G. Redert, and Jan-Mark. Depth information by stage classification. ICCV, [6] A. Oliva and A. Torralba. Modeling the shape of the scene: a holistic representation of the spatial envelope. Int. Journal of Computer Vision, 42(3): , [7] B. Russell, A. Torralba, C. Liu, R. Fergus, and W. T. Freeman. Object recognition by scene alignment. In NIPS, [8] A. Saxena, S. Chung, and A. Ng. Depth reconstruction from a single still image. International Journal of Computer Vision, 74(1), [9] N. Snavely, S. M. Seitz, and R. Szeliski. Photo tourism: Exploring photo collections in 3D. ACM Transactions on Graphics (SIGGRAPH), 25(3), [10] A. Torralba. Contextual priming for object detection. Int. Journal of Computer Vision, 53(2): , [11] A. Torralba, R. Fergus, and W. T. Freeman. Tiny images. Technical Report MIT-CSAIL-TR , MIT CSAIL, [12] A. Torralba and A. Oliva. Depth estimation from image structure. PAMI, 24(9), 2002.











7 Figure 6(contd). Using average scene prior as an input image feature helps in improving the Geometric Context (GC) result. Input image Ground truth labelling Result from Hoiem et al. [3] Average scene prior Our result Top few scene matches and their corresponding Geometric Context outputs. The classification of the tree, side of the alley and the wall in examples 1, 2 and 3 respectively is improved upon inclusion of the scene prior.
 (j)")























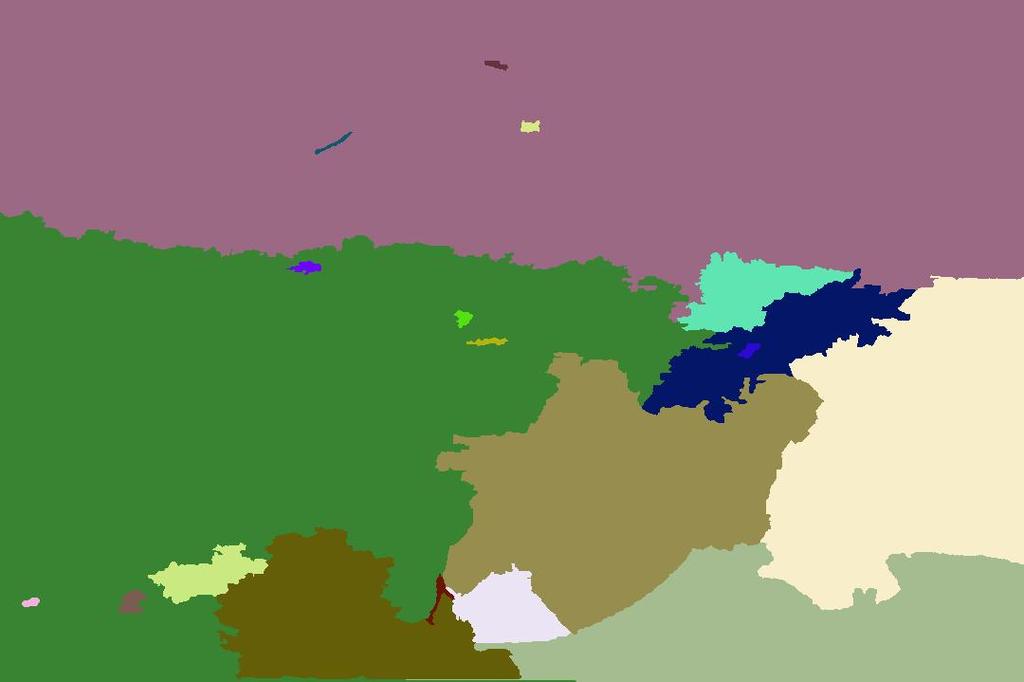




















8 (g) (h) (i) (j) (g) (h) (i) (j) (g) (h) (i) Figure 7. Similar scenes can aid the segmentation of an image. Input image 5 multiple segmentations (5,10,15,20,25 segments) generated using input image features Example scene matches 5 multiple segmentations (5,10,15,20,25 segments) using average scene features Average neighbour image Super-pixeled image (g) Ground-truth segmentation (h) Ground-truth labelling (i) Hoiem et al. [3] (j) Our result. The multiple segmentations generated using the average image features characterise the overall scene geometry and are helpful in estimating an improved surface layout for the input image. (j)
Unsupervised Patch-based Context from Millions of Images
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
CS 558: Computer Vision 13 th Set of Notes
 CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
Context. CS 554 Computer Vision Pinar Duygulu Bilkent University. (Source:Antonio Torralba, James Hays)
") Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Correcting User Guided Image Segmentation
 Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Closing the Loop in Scene Interpretation
 Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Opportunities of Scale
 Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Texton Clustering for Local Classification using Scene-Context Scale
 Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Matching and Predicting Street Level Images
 Matching and Predicting Street Level Images Biliana Kaneva 1, Josef Sivic 2, Antonio Torralba 1, Shai Avidan 3, and William T. Freeman 1 1 Massachusetts Institute of Technology {biliana,torralba,billf}@csail.mit.edu
Matching and Predicting Street Level Images Biliana Kaneva 1, Josef Sivic 2, Antonio Torralba 1, Shai Avidan 3, and William T. Freeman 1 1 Massachusetts Institute of Technology {biliana,torralba,billf}@csail.mit.edu
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Previous Lecture - Coded aperture photography
 Previous Lecture - Coded aperture photography Depth from a single image based on the amount of blur Estimate the amount of blur using and recover a sharp image by deconvolution with a sparse gradient prior.
Previous Lecture - Coded aperture photography Depth from a single image based on the amount of blur Estimate the amount of blur using and recover a sharp image by deconvolution with a sparse gradient prior.
Visual localization using global visual features and vanishing points
 Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
ELL 788 Computational Perception & Cognition July November 2015
 ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
FACE DETECTION AND LOCALIZATION USING DATASET OF TINY IMAGES
 FACE DETECTION AND LOCALIZATION USING DATASET OF TINY IMAGES Swathi Polamraju and Sricharan Ramagiri Department of Electrical and Computer Engineering Clemson University ABSTRACT: Being motivated by the
FACE DETECTION AND LOCALIZATION USING DATASET OF TINY IMAGES Swathi Polamraju and Sricharan Ramagiri Department of Electrical and Computer Engineering Clemson University ABSTRACT: Being motivated by the
Single Image Super-resolution. Slides from Libin Geoffrey Sun and James Hays
 Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation
 Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Admin. Data driven methods. Overview. Overview. Parametric model of image patches. Data driven (Non parametric) Approach 3/31/2008
 Approach 3/31/2008") Admin Office hours straight after class today Data driven methods Assignment 3 out, due in 2 weeks Lecture 8 Projects.. Overview Overview Texture synthesis Quilting Image Analogies Super resolution Scene
Admin Office hours straight after class today Data driven methods Assignment 3 out, due in 2 weeks Lecture 8 Projects.. Overview Overview Texture synthesis Quilting Image Analogies Super resolution Scene
Viewpoint Invariant Features from Single Images Using 3D Geometry
 Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Optimizing Monocular Cues for Depth Estimation from Indoor Images
 Optimizing Monocular Cues for Depth Estimation from Indoor Images Aditya Venkatraman 1, Sheetal Mahadik 2 1, 2 Department of Electronics and Telecommunication, ST Francis Institute of Technology, Mumbai,
Optimizing Monocular Cues for Depth Estimation from Indoor Images Aditya Venkatraman 1, Sheetal Mahadik 2 1, 2 Department of Electronics and Telecommunication, ST Francis Institute of Technology, Mumbai,
Indoor Object Recognition of 3D Kinect Dataset with RNNs
 Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Course Administration
 Course Administration Project 2 results are online Project 3 is out today The first quiz is a week from today (don t panic!) Covers all material up to the quiz Emphasizes lecture material NOT project topics
Course Administration Project 2 results are online Project 3 is out today The first quiz is a week from today (don t panic!) Covers all material up to the quiz Emphasizes lecture material NOT project topics
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Dimensionality Reduction using Relative Attributes
 Dimensionality Reduction using Relative Attributes Mohammadreza Babaee 1, Stefanos Tsoukalas 1, Maryam Babaee Gerhard Rigoll 1, and Mihai Datcu 1 Institute for Human-Machine Communication, Technische Universität
Dimensionality Reduction using Relative Attributes Mohammadreza Babaee 1, Stefanos Tsoukalas 1, Maryam Babaee Gerhard Rigoll 1, and Mihai Datcu 1 Institute for Human-Machine Communication, Technische Universität
SuperParsing: Scalable Nonparametric Image Parsing with Superpixels
 SuperParsing: Scalable Nonparametric Image Parsing with Superpixels Joseph Tighe and Svetlana Lazebnik Dept. of Computer Science, University of North Carolina at Chapel Hill Chapel Hill, NC 27599-3175
SuperParsing: Scalable Nonparametric Image Parsing with Superpixels Joseph Tighe and Svetlana Lazebnik Dept. of Computer Science, University of North Carolina at Chapel Hill Chapel Hill, NC 27599-3175
Homographies and RANSAC
 Homographies and RANSAC Computer vision 6.869 Bill Freeman and Antonio Torralba March 30, 2011 Homographies and RANSAC Homographies RANSAC Building panoramas Phototourism 2 Depth-based ambiguity of position
Homographies and RANSAC Computer vision 6.869 Bill Freeman and Antonio Torralba March 30, 2011 Homographies and RANSAC Homographies RANSAC Building panoramas Phototourism 2 Depth-based ambiguity of position
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
Geometric Context from Videos
 2013 IEEE Conference on Computer Vision and Pattern Recognition Geometric Context from Videos S. Hussain Raza Matthias Grundmann Irfan Essa Georgia Institute of Technology, Atlanta, GA, USA http://www.cc.gatech.edu/cpl/projects/videogeometriccontext
2013 IEEE Conference on Computer Vision and Pattern Recognition Geometric Context from Videos S. Hussain Raza Matthias Grundmann Irfan Essa Georgia Institute of Technology, Atlanta, GA, USA http://www.cc.gatech.edu/cpl/projects/videogeometriccontext
CS 4758: Automated Semantic Mapping of Environment
 CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Interpreting 3D Scenes Using Object-level Constraints
 Interpreting 3D Scenes Using Object-level Constraints Rehan Hameed Stanford University 353 Serra Mall, Stanford CA rhameed@stanford.edu Abstract As humans we are able to understand the structure of a scene
Interpreting 3D Scenes Using Object-level Constraints Rehan Hameed Stanford University 353 Serra Mall, Stanford CA rhameed@stanford.edu Abstract As humans we are able to understand the structure of a scene
Object Detection Using Cascaded Classification Models
 Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Tag Recommendation for Photos
 Tag Recommendation for Photos Gowtham Kumar Ramani, Rahul Batra, Tripti Assudani December 10, 2009 Abstract. We present a real-time recommendation system for photo annotation that can be used in Flickr.
Tag Recommendation for Photos Gowtham Kumar Ramani, Rahul Batra, Tripti Assudani December 10, 2009 Abstract. We present a real-time recommendation system for photo annotation that can be used in Flickr.
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Figure 1: Workflow of object-based classification
 Technical Specifications Object Analyst Object Analyst is an add-on package for Geomatica that provides tools for segmentation, classification, and feature extraction. Object Analyst includes an all-in-one
Technical Specifications Object Analyst Object Analyst is an add-on package for Geomatica that provides tools for segmentation, classification, and feature extraction. Object Analyst includes an all-in-one
Image Classification. RS Image Classification. Present by: Dr.Weerakaset Suanpaga
 Image Classification Present by: Dr.Weerakaset Suanpaga D.Eng(RS&GIS) 6.1 Concept of Classification Objectives of Classification Advantages of Multi-Spectral data for Classification Variation of Multi-Spectra
Image Classification Present by: Dr.Weerakaset Suanpaga D.Eng(RS&GIS) 6.1 Concept of Classification Objectives of Classification Advantages of Multi-Spectral data for Classification Variation of Multi-Spectra
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Segmenting Scenes by Matching Image Composites
 Segmenting Scenes by Matching Image Composites Bryan C. Russell 1 Alexei A. Efros 2,1 Josef Sivic 1 William T. Freeman 3 Andrew Zisserman 4,1 1 INRIA 2 Carnegie Mellon University 3 CSAIL MIT 4 University
Segmenting Scenes by Matching Image Composites Bryan C. Russell 1 Alexei A. Efros 2,1 Josef Sivic 1 William T. Freeman 3 Andrew Zisserman 4,1 1 INRIA 2 Carnegie Mellon University 3 CSAIL MIT 4 University
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE
 SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE S. Hirose R&D Center, TOPCON CORPORATION, 75-1, Hasunuma-cho, Itabashi-ku, Tokyo, Japan Commission
SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE S. Hirose R&D Center, TOPCON CORPORATION, 75-1, Hasunuma-cho, Itabashi-ku, Tokyo, Japan Commission
IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues
 2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Photo Tourism: Exploring Photo Collections in 3D
 Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Modeling and Recognition of Landmark Image Collections Using Iconic Scene Graphs
 Modeling and Recognition of Landmark Image Collections Using Iconic Scene Graphs Xiaowei Li, Changchang Wu, Christopher Zach, Svetlana Lazebnik, Jan-Michael Frahm 1 Motivation Target problem: organizing
Modeling and Recognition of Landmark Image Collections Using Iconic Scene Graphs Xiaowei Li, Changchang Wu, Christopher Zach, Svetlana Lazebnik, Jan-Michael Frahm 1 Motivation Target problem: organizing
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Semantic Visual Decomposition Modelling for Improving Object Detection in Complex Scene Images
 Semantic Visual Decomposition Modelling for Improving Object Detection in Complex Scene Images Ge Qin Department of Computing University of Surrey United Kingdom g.qin@surrey.ac.uk Bogdan Vrusias Department
Semantic Visual Decomposition Modelling for Improving Object Detection in Complex Scene Images Ge Qin Department of Computing University of Surrey United Kingdom g.qin@surrey.ac.uk Bogdan Vrusias Department
Contextual priming for artificial visual perception
 Contextual priming for artificial visual perception Hervé Guillaume 1, Nathalie Denquive 1, Philippe Tarroux 1,2 1 LIMSI-CNRS BP 133 F-91403 Orsay cedex France 2 ENS 45 rue d Ulm F-75230 Paris cedex 05
Contextual priming for artificial visual perception Hervé Guillaume 1, Nathalie Denquive 1, Philippe Tarroux 1,2 1 LIMSI-CNRS BP 133 F-91403 Orsay cedex France 2 ENS 45 rue d Ulm F-75230 Paris cedex 05
CEng Computational Vision
 CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Simultaneous surface texture classification and illumination tilt angle prediction
 Simultaneous surface texture classification and illumination tilt angle prediction X. Lladó, A. Oliver, M. Petrou, J. Freixenet, and J. Martí Computer Vision and Robotics Group - IIiA. University of Girona
Simultaneous surface texture classification and illumination tilt angle prediction X. Lladó, A. Oliver, M. Petrou, J. Freixenet, and J. Martí Computer Vision and Robotics Group - IIiA. University of Girona
Requesting changes to the grades, please write to me in an with descriptions. Move my office hours to the morning. 11am - 12:30pm Thursdays
 Lab1 graded. Requesting changes to the grades, please write to me in an email with descriptions. Move my office hours to the morning. 11am - 12:30pm Thursdays Internet-scale texture synthesis With slides
Lab1 graded. Requesting changes to the grades, please write to me in an email with descriptions. Move my office hours to the morning. 11am - 12:30pm Thursdays Internet-scale texture synthesis With slides
Contextual Classification with Functional Max-Margin Markov Networks
 Contextual Classification with Functional Max-Margin Markov Networks Dan Munoz Nicolas Vandapel Drew Bagnell Martial Hebert Geometry Estimation (Hoiem et al.) Sky Problem 3-D Point Cloud Classification
Contextual Classification with Functional Max-Margin Markov Networks Dan Munoz Nicolas Vandapel Drew Bagnell Martial Hebert Geometry Estimation (Hoiem et al.) Sky Problem 3-D Point Cloud Classification
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Support surfaces prediction for indoor scene understanding
 2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
Automatic Generation of An Infinite Panorama
 Automatic Generation of An Infinite Panorama Lisa H. Chan Alexei A. Efros Carnegie Mellon University Original Image Scene Matches Output Image Figure 1: Given an input image, scene matching from a large
Automatic Generation of An Infinite Panorama Lisa H. Chan Alexei A. Efros Carnegie Mellon University Original Image Scene Matches Output Image Figure 1: Given an input image, scene matching from a large
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Comparing Local Feature Descriptors in plsa-based Image Models
 Comparing Local Feature Descriptors in plsa-based Image Models Eva Hörster 1,ThomasGreif 1, Rainer Lienhart 1, and Malcolm Slaney 2 1 Multimedia Computing Lab, University of Augsburg, Germany {hoerster,lienhart}@informatik.uni-augsburg.de
Comparing Local Feature Descriptors in plsa-based Image Models Eva Hörster 1,ThomasGreif 1, Rainer Lienhart 1, and Malcolm Slaney 2 1 Multimedia Computing Lab, University of Augsburg, Germany {hoerster,lienhart}@informatik.uni-augsburg.de
Indoor-Outdoor Classification with Human Accuracies: Image or Edge Gist?
 IEEE CVPR Workshop on Advancing Computer Vision with Humans in the Loop, San Francisco, CA, June 14, Indoor-Outdoor Classification with Human Accuracies: Image or Edge Gist? Christina Pavlopoulou Stella
IEEE CVPR Workshop on Advancing Computer Vision with Humans in the Loop, San Francisco, CA, June 14, Indoor-Outdoor Classification with Human Accuracies: Image or Edge Gist? Christina Pavlopoulou Stella
Linear combinations of simple classifiers for the PASCAL challenge
 Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
Sea Turtle Identification by Matching Their Scale Patterns
 Sea Turtle Identification by Matching Their Scale Patterns Technical Report Rajmadhan Ekambaram and Rangachar Kasturi Department of Computer Science and Engineering, University of South Florida Abstract
Sea Turtle Identification by Matching Their Scale Patterns Technical Report Rajmadhan Ekambaram and Rangachar Kasturi Department of Computer Science and Engineering, University of South Florida Abstract
Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation
 ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
Structure from Motion
 /8/ Structure from Motion Computer Vision CS 43, Brown James Hays Many slides adapted from Derek Hoiem, Lana Lazebnik, Silvio Saverese, Steve Seitz, and Martial Hebert This class: structure from motion
/8/ Structure from Motion Computer Vision CS 43, Brown James Hays Many slides adapted from Derek Hoiem, Lana Lazebnik, Silvio Saverese, Steve Seitz, and Martial Hebert This class: structure from motion
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
Efficient Acquisition of Human Existence Priors from Motion Trajectories
 Efficient Acquisition of Human Existence Priors from Motion Trajectories Hitoshi Habe Hidehito Nakagawa Masatsugu Kidode Graduate School of Information Science, Nara Institute of Science and Technology
Efficient Acquisition of Human Existence Priors from Motion Trajectories Hitoshi Habe Hidehito Nakagawa Masatsugu Kidode Graduate School of Information Science, Nara Institute of Science and Technology
CHAPTER 1 INTRODUCTION
 CHAPTER 1 INTRODUCTION 1.1 Introduction Pattern recognition is a set of mathematical, statistical and heuristic techniques used in executing `man-like' tasks on computers. Pattern recognition plays an
CHAPTER 1 INTRODUCTION 1.1 Introduction Pattern recognition is a set of mathematical, statistical and heuristic techniques used in executing `man-like' tasks on computers. Pattern recognition plays an
3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding
 3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding Scott Satkin Google Inc satkin@googlecom Martial Hebert Carnegie Mellon University hebert@ricmuedu Abstract We present a new algorithm
3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding Scott Satkin Google Inc satkin@googlecom Martial Hebert Carnegie Mellon University hebert@ricmuedu Abstract We present a new algorithm
3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry
 3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry Bryan C. Russell et al. SIGGRAPH Asia 2013 Presented by YoungBin Kim 2014. 01. 10 Abstract Produce annotated 3D
3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry Bryan C. Russell et al. SIGGRAPH Asia 2013 Presented by YoungBin Kim 2014. 01. 10 Abstract Produce annotated 3D
Medial Features for Superpixel Segmentation
 Medial Features for Superpixel Segmentation David Engel Luciano Spinello Rudolph Triebel Roland Siegwart Heinrich H. Bülthoff Cristóbal Curio Max Planck Institute for Biological Cybernetics Spemannstr.
Medial Features for Superpixel Segmentation David Engel Luciano Spinello Rudolph Triebel Roland Siegwart Heinrich H. Bülthoff Cristóbal Curio Max Planck Institute for Biological Cybernetics Spemannstr.
Improving Latent Fingerprint Matching Performance by Orientation Field Estimation using Localized Dictionaries
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
Pull the Plug? Predicting If Computers or Humans Should Segment Images Supplementary Material
 In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, June 2016. Pull the Plug? Predicting If Computers or Humans Should Segment Images Supplementary Material
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, June 2016. Pull the Plug? Predicting If Computers or Humans Should Segment Images Supplementary Material
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
24 hours of Photo Sharing. installation by Erik Kessels
 24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
then assume that we are given the image of one of these textures captured by a camera at a different (longer) distance and with unknown direction of i
 distance and with unknown direction of i") Image Texture Prediction using Colour Photometric Stereo Xavier Lladó 1, Joan Mart 1, and Maria Petrou 2 1 Institute of Informatics and Applications, University of Girona, 1771, Girona, Spain fllado,joanmg@eia.udg.es
Image Texture Prediction using Colour Photometric Stereo Xavier Lladó 1, Joan Mart 1, and Maria Petrou 2 1 Institute of Informatics and Applications, University of Girona, 1771, Girona, Spain fllado,joanmg@eia.udg.es
Shape Anchors for Data-driven Multi-view Reconstruction
 Shape Anchors for Data-driven Multi-view Reconstruction Andrew Owens MIT CSAIL Jianxiong Xiao Princeton University Antonio Torralba MIT CSAIL William Freeman MIT CSAIL andrewo@mit.edu xj@princeton.edu
Shape Anchors for Data-driven Multi-view Reconstruction Andrew Owens MIT CSAIL Jianxiong Xiao Princeton University Antonio Torralba MIT CSAIL William Freeman MIT CSAIL andrewo@mit.edu xj@princeton.edu
Structured Models in. Dan Huttenlocher. June 2010
 Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Recovering the Spatial Layout of Cluttered Rooms
 Recovering the Spatial Layout of Cluttered Rooms Varsha Hedau Electical and Computer Engg. Department University of Illinois at Urbana Champaign vhedau2@uiuc.edu Derek Hoiem, David Forsyth Computer Science
Recovering the Spatial Layout of Cluttered Rooms Varsha Hedau Electical and Computer Engg. Department University of Illinois at Urbana Champaign vhedau2@uiuc.edu Derek Hoiem, David Forsyth Computer Science
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Evaluation of GIST descriptors for web scale image search
 Evaluation of GIST descriptors for web scale image search Matthijs Douze Hervé Jégou, Harsimrat Sandhawalia, Laurent Amsaleg and Cordelia Schmid INRIA Grenoble, France July 9, 2009 Evaluation of GIST for
Evaluation of GIST descriptors for web scale image search Matthijs Douze Hervé Jégou, Harsimrat Sandhawalia, Laurent Amsaleg and Cordelia Schmid INRIA Grenoble, France July 9, 2009 Evaluation of GIST for
HOW USEFUL ARE COLOUR INVARIANTS FOR IMAGE RETRIEVAL?
 HOW USEFUL ARE COLOUR INVARIANTS FOR IMAGE RETRIEVAL? Gerald Schaefer School of Computing and Technology Nottingham Trent University Nottingham, U.K. Gerald.Schaefer@ntu.ac.uk Abstract Keywords: The images
HOW USEFUL ARE COLOUR INVARIANTS FOR IMAGE RETRIEVAL? Gerald Schaefer School of Computing and Technology Nottingham Trent University Nottingham, U.K. Gerald.Schaefer@ntu.ac.uk Abstract Keywords: The images
Random projection for non-gaussian mixture models
 Random projection for non-gaussian mixture models Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 gyozo@cs.ucsd.edu Abstract Recently,
Random projection for non-gaussian mixture models Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 gyozo@cs.ucsd.edu Abstract Recently,
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE
 OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
Miniature faking. In close-up photo, the depth of field is limited.
 Miniature faking In close-up photo, the depth of field is limited. http://en.wikipedia.org/wiki/file:jodhpur_tilt_shift.jpg Miniature faking Miniature faking http://en.wikipedia.org/wiki/file:oregon_state_beavers_tilt-shift_miniature_greg_keene.jpg
Miniature faking In close-up photo, the depth of field is limited. http://en.wikipedia.org/wiki/file:jodhpur_tilt_shift.jpg Miniature faking Miniature faking http://en.wikipedia.org/wiki/file:oregon_state_beavers_tilt-shift_miniature_greg_keene.jpg
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this