What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
|
|
|
- Marilyn Oliver
- 5 years ago
- Views:
Transcription
1 Introduction
2 What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
3 What are we trying to achieve?

4 Example from Scott Satkin



5 3D interpretation from image Geometric labels Volumetric layout

6 Sparse primitives Dense reconstruction 3D scene model
7 Why are we doing this? Applications
8 3D for motion when there is no direct way to get 3D
9

10




11
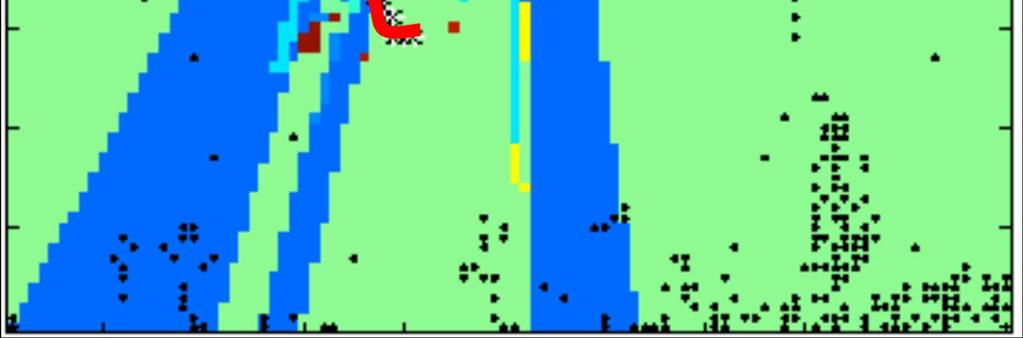

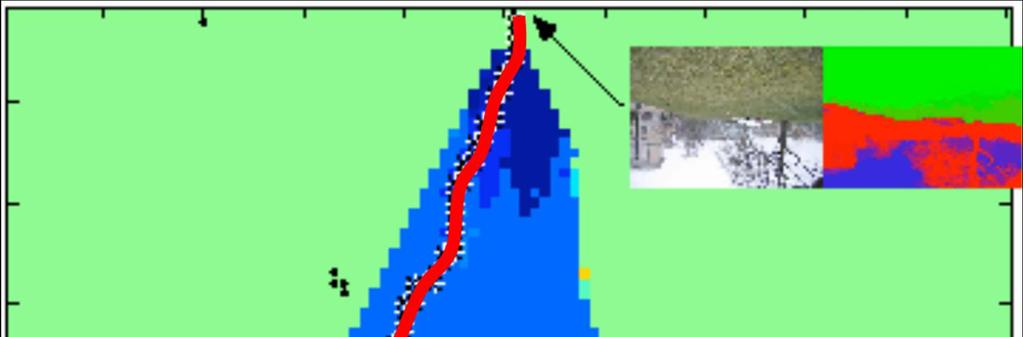
12
13 Informing detectors

14

15 D. Hoiem, A. A. Efros, and M. Hebert. Putting Objects in Perspective. International Journal of Computer Vision, Vol. 80, No. 1, October, 2008.


16








17 Learned Primitives (Examples) 747/203


18

19 Contact points

20 Object surfaces + Contact points
21 Editing images


22 Pose sampling

23
24 Predicting actions
25 Input Image Estimated Geometry

26 Application: Affordance Estimation Estimated Geometry Predicted Sitting Locations


27 Application: Affordance Estimation Sitting Upright Sitting Reclined Laying Down Reaching (4 poses)

28 Application: Affordance Estimation
29 Application: Affordance Estimation Sitting Upright Sitting Reclined Laying Down Reaching (4 poses)
30 Separating style and structure






31 Style vs. structure? Tenenbaum& Freeman. Separating Style and Content with Bilinear Models. Neural Computation




32 Casablanca Hotel, New York
33

34
35 What do we learn from past history? Historical perspective
36 First era: Geometric/symbolic reasoning




37 Huffman 71, Clowes 71, Kanade80, 81 Sugihara 86, Malik 87, etc.

38 Kanade s Origami World, 1978


39 Kanade schair (Artificial Intelligence, 1981)
![Scene parsing [Ohta & Kanade 1978] Guzman](/docs-images/92/109528327/images/40-0.jpg "(SEE), 1968 Yakimovsky & Feldman, 1973")
, 1979 Ohta&")
40 Scene parsing [Ohta & Kanade 1978] Guzman (SEE), 1968 Yakimovsky & Feldman, 1973 Hansen & Riseman(VISIONS), 1978 Barrow & Tenenbaum 1978 Brooks (ACRONYM), 1979 Ohta& Kanade, 1978
41 Issues Assumed good (perfect?) geometric elements inferred from the image. Limitations on computation, data, inference techniques prevented practical estimation of geometric primitives.
42 Second era: Statistical machine learning







43 Input Learned model Classification Training data
44 Now we have the opposite problem: Powerful tools to estimate low-level geometric cues (e.g., surface labels) Does not incorporate high-level geometric constraints (e.g., orthogonality, intersections, etc.) Does not incorporate higher-level reasoning
45 Now (Part I): learning+reasoning


")
46 Structured prediction tools Orientation maps(lee et al. 2009) Geometric Context(Hoiem et al. 2007) [Schwing/Urtasun 2012]

47 Structured prediction tools+ search Input image features Generate hypotheses Search through hypotheses to pick the best one Best = maximum score Scene configuration hypotheses Score computation learned from data using structured prediction tools Final scene configuration



48 Optimization tools Convex Concave [Fouhey et al. ECCV 2014]
49 + Richer representations, including reasoning about geometric primitives (e.g., relative placement of surfaces, contact relationships, etc.) - Taming the combinatorics: How to generate and search hypothesis space efficiently? - Summarizes a large amount of training data into a simple model - Difficult to capture the richness of big data
50 Now (Part II): Data-driven interpretation


51 Label transfer Karsch, Liu, Kang. Depth Extraction from Video Using Non-parametric Sampling. ECCV Fouhey, Gupta, Hebert. Data-Driven 3D Primitives for Single-Image Understanding. ICCV 2013.




52 Object transfer Input image DPM output Lots of object models Output Matched models Seeing 3D chairs: exemplar part-based 2D-3D alignment using a large dataset of CAD models. M. Aubry, D. Maturana, A. Efros, B. Russell and J. Sivic CVPR, 2014.





53 Object transfer Training Testing W. Choi, Y.-W. Chao, C. Pantofaru, and S. Savarese. Understanding Indoor Scenes using 3D Geometric Phrases. CVPR 2013.










54 Scene transfer Lots of 3D models Nearestneighbor search
55 (Arbitrarily) richer description: Transfer of semantics, 3D poses, segmentation, material properties, etc. How to relate 2D/appearance features to purely 3D geometric representations? What matching score/distance metric should be used? How to rank matches?
56 What will we talk about today?
57 Tutorial Outline Bottom up classifiers More explicit constraint+reasoning Qualitative Explicit/Quantitative










58 Outline Part 1: Derek Bottom-up Methods for Regions and Boundaries, Global Constraints Part 2: Abhinav Volumetric and Functional Constraints Part 3: David Data-driven Models Region labels + Boundaries and objects Stronger geometric constraints from domain knowledge + physical constraints +functional constraints
59 Big Questions How to estimate geometric properties from an image? How to incorporate geometric constraints and which ones? How to combine reasoning tools with statistical classification/regression tools? How to use large-scale 3D data (3D models, kinect) How to combine with other 3D estimation methods?
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models
 Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding
 3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding Scott Satkin Google Inc satkin@googlecom Martial Hebert Carnegie Mellon University hebert@ricmuedu Abstract We present a new algorithm
3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding Scott Satkin Google Inc satkin@googlecom Martial Hebert Carnegie Mellon University hebert@ricmuedu Abstract We present a new algorithm
Data-Driven 3D Primitives for Single Image Understanding
 2013 IEEE International Conference on Computer Vision Data-Driven 3D Primitives for Single Image Understanding David F. Fouhey, Abhinav Gupta, Martial Hebert The Robotics Institute, Carnegie Mellon University
2013 IEEE International Conference on Computer Vision Data-Driven 3D Primitives for Single Image Understanding David F. Fouhey, Abhinav Gupta, Martial Hebert The Robotics Institute, Carnegie Mellon University
Unfolding an Indoor Origami World
 Unfolding an Indoor Origami World David F. Fouhey, Abhinav Gupta, and Martial Hebert The Robotics Institute, Carnegie Mellon University Abstract. In this work, we present a method for single-view reasoning
Unfolding an Indoor Origami World David F. Fouhey, Abhinav Gupta, and Martial Hebert The Robotics Institute, Carnegie Mellon University Abstract. In this work, we present a method for single-view reasoning
From 3D Scene Geometry to Human Workspace
 From 3D Scene Geometry to Human Workspace Abhinav Gupta, Scott Satkin, Alexei A. Efros and Martial Hebert The Robotics Institute, Carnegie Mellon University {abhinavg,ssatkin,efros,hebert}@ri.cmu.edu Abstract
From 3D Scene Geometry to Human Workspace Abhinav Gupta, Scott Satkin, Alexei A. Efros and Martial Hebert The Robotics Institute, Carnegie Mellon University {abhinavg,ssatkin,efros,hebert}@ri.cmu.edu Abstract
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Focusing Attention on Visual Features that Matter
 TSAI, KUIPERS: FOCUSING ATTENTION ON VISUAL FEATURES THAT MATTER 1 Focusing Attention on Visual Features that Matter Grace Tsai gstsai@umich.edu Benjamin Kuipers kuipers@umich.edu Electrical Engineering
TSAI, KUIPERS: FOCUSING ATTENTION ON VISUAL FEATURES THAT MATTER 1 Focusing Attention on Visual Features that Matter Grace Tsai gstsai@umich.edu Benjamin Kuipers kuipers@umich.edu Electrical Engineering
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
CS 558: Computer Vision 13 th Set of Notes
 CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
Semantic Classification of Boundaries from an RGBD Image
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Semantic Classification of Boundaries from an RGBD Image Soni, N.; Namboodiri, A.; Ramalingam, S.; Jawahar, C.V. TR2015-102 September 2015
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Semantic Classification of Boundaries from an RGBD Image Soni, N.; Namboodiri, A.; Ramalingam, S.; Jawahar, C.V. TR2015-102 September 2015
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Context. CS 554 Computer Vision Pinar Duygulu Bilkent University. (Source:Antonio Torralba, James Hays)
") Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Multi-view stereo. Many slides adapted from S. Seitz
 Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Revisiting 3D Geometric Models for Accurate Object Shape and Pose
 Revisiting 3D Geometric Models for Accurate Object Shape and Pose M. 1 Michael Stark 2,3 Bernt Schiele 3 Konrad Schindler 1 1 Photogrammetry and Remote Sensing Laboratory Swiss Federal Institute of Technology
Revisiting 3D Geometric Models for Accurate Object Shape and Pose M. 1 Michael Stark 2,3 Bernt Schiele 3 Konrad Schindler 1 1 Photogrammetry and Remote Sensing Laboratory Swiss Federal Institute of Technology
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Can Similar Scenes help Surface Layout Estimation?
 Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
arxiv: v1 [cs.cv] 3 Jul 2016
![arxiv: v1 [cs.cv] 3 Jul 2016](/thumbs/95/123101257.jpg "arxiv: v1 [cs.cv] 3 Jul 2016") A Coarse-to-Fine Indoor Layout Estimation (CFILE) Method Yuzhuo Ren, Chen Chen, Shangwen Li, and C.-C. Jay Kuo arxiv:1607.00598v1 [cs.cv] 3 Jul 2016 Abstract. The task of estimating the spatial layout
A Coarse-to-Fine Indoor Layout Estimation (CFILE) Method Yuzhuo Ren, Chen Chen, Shangwen Li, and C.-C. Jay Kuo arxiv:1607.00598v1 [cs.cv] 3 Jul 2016 Abstract. The task of estimating the spatial layout
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
LEARNING BOUNDARIES WITH COLOR AND DEPTH. Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen
 LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
EECS 442 Computer vision. 3D Object Recognition and. Scene Understanding
 EECS 442 Computer vision 3D Object Recognition and Scene Understanding Interpreting the visual world Object: Building 8-10 meters away Object: Traffic light Object: Car, ¾ view 2-3 meters away How can
EECS 442 Computer vision 3D Object Recognition and Scene Understanding Interpreting the visual world Object: Building 8-10 meters away Object: Traffic light Object: Car, ¾ view 2-3 meters away How can
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
Single Image Super-resolution. Slides from Libin Geoffrey Sun and James Hays
 Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Shape Anchors for Data-driven Multi-view Reconstruction
 Shape Anchors for Data-driven Multi-view Reconstruction Andrew Owens MIT CSAIL Jianxiong Xiao Princeton University Antonio Torralba MIT CSAIL William Freeman MIT CSAIL andrewo@mit.edu xj@princeton.edu
Shape Anchors for Data-driven Multi-view Reconstruction Andrew Owens MIT CSAIL Jianxiong Xiao Princeton University Antonio Torralba MIT CSAIL William Freeman MIT CSAIL andrewo@mit.edu xj@princeton.edu
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Local cues and global constraints in image understanding
 Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry
 3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry Bryan C. Russell et al. SIGGRAPH Asia 2013 Presented by YoungBin Kim 2014. 01. 10 Abstract Produce annotated 3D
3D Wikipedia: Using online text to automatically label and navigate reconstructed geometry Bryan C. Russell et al. SIGGRAPH Asia 2013 Presented by YoungBin Kim 2014. 01. 10 Abstract Produce annotated 3D
Finding Structure in Large Collections of 3D Models
 Finding Structure in Large Collections of 3D Models Vladimir Kim Adobe Research Motivation Explore, Analyze, and Create Geometric Data Real Virtual Motivation Explore, Analyze, and Create Geometric Data
Finding Structure in Large Collections of 3D Models Vladimir Kim Adobe Research Motivation Explore, Analyze, and Create Geometric Data Real Virtual Motivation Explore, Analyze, and Create Geometric Data
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
FPM: Fine Pose Parts-Based Model with 3D CAD Models
 FPM: Fine Pose Parts-Based Model with 3D CAD Models The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher
FPM: Fine Pose Parts-Based Model with 3D CAD Models The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher
Support surfaces prediction for indoor scene understanding
 2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
Unsupervised discovery of category and object models. The task
 Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Building Part-based Object Detectors via 3D Geometry
 Building Part-based Object Detectors via 3D Geometry Abhinav Shrivastava Abhinav Gupta The Robotics Institute, Carnegie Mellon University http://graphics.cs.cmu.edu/projects/gdpm Abstract This paper proposes
Building Part-based Object Detectors via 3D Geometry Abhinav Shrivastava Abhinav Gupta The Robotics Institute, Carnegie Mellon University http://graphics.cs.cmu.edu/projects/gdpm Abstract This paper proposes
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation
 Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Painting-to-3D Model Alignment Via Discriminative Visual Elements. Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA)
 Bryan Russell (Intel) Josef Sivic (INRIA)") Painting-to-3D Model Alignment Via Discriminative Visual Elements Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA) This work Browsing across time 1699 1740 1750 1800 1800 1699 1740 1750
Painting-to-3D Model Alignment Via Discriminative Visual Elements Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA) This work Browsing across time 1699 1740 1750 1800 1800 1699 1740 1750
arxiv: v3 [cs.cv] 18 Aug 2017
![arxiv: v3 [cs.cv] 18 Aug 2017](/thumbs/73/69392953.jpg "arxiv: v3 [cs.cv] 18 Aug 2017") Predicting Complete 3D Models of Indoor Scenes Ruiqi Guo UIUC, Google Chuhang Zou UIUC Derek Hoiem UIUC arxiv:1504.02437v3 [cs.cv] 18 Aug 2017 Abstract One major goal of vision is to infer physical models
Predicting Complete 3D Models of Indoor Scenes Ruiqi Guo UIUC, Google Chuhang Zou UIUC Derek Hoiem UIUC arxiv:1504.02437v3 [cs.cv] 18 Aug 2017 Abstract One major goal of vision is to infer physical models
Closing the Loop in Scene Interpretation
 Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
3D layout propagation to improve object recognition in egocentric videos
 3D layout propagation to improve object recognition in egocentric videos Alejandro Rituerto, Ana C. Murillo and José J. Guerrero {arituerto,acm,josechu.guerrero}@unizar.es Instituto de Investigación en
3D layout propagation to improve object recognition in egocentric videos Alejandro Rituerto, Ana C. Murillo and José J. Guerrero {arituerto,acm,josechu.guerrero}@unizar.es Instituto de Investigación en
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Revisiting Depth Layers from Occlusions
 Revisiting Depth Layers from Occlusions Adarsh Kowdle Cornell University apk64@cornell.edu Andrew Gallagher Cornell University acg226@cornell.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract
Revisiting Depth Layers from Occlusions Adarsh Kowdle Cornell University apk64@cornell.edu Andrew Gallagher Cornell University acg226@cornell.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract
Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Announcements. Stereo Vision Wrapup & Intro Recognition
 Announcements Stereo Vision Wrapup & Intro Introduction to Computer Vision CSE 152 Lecture 17 HW3 due date postpone to Thursday HW4 to posted by Thursday, due next Friday. Order of material we ll first
Announcements Stereo Vision Wrapup & Intro Introduction to Computer Vision CSE 152 Lecture 17 HW3 due date postpone to Thursday HW4 to posted by Thursday, due next Friday. Order of material we ll first
Opportunities of Scale
 Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Parsing Indoor Scenes Using RGB-D Imagery
 Robotics: Science and Systems 2012 Sydney, NSW, Australia, July 09-13, 2012 Parsing Indoor Scenes Using RGB-D Imagery Camillo J. Taylor and Anthony Cowley GRASP Laboratory University of Pennsylvania Philadelphia,
Robotics: Science and Systems 2012 Sydney, NSW, Australia, July 09-13, 2012 Parsing Indoor Scenes Using RGB-D Imagery Camillo J. Taylor and Anthony Cowley GRASP Laboratory University of Pennsylvania Philadelphia,
Understanding Bayesian rooms using composite 3D object models
 2013 IEEE Conference on Computer Vision and Pattern Recognition Understanding Bayesian rooms using composite 3D object models Luca Del Pero Joshua Bowdish Bonnie Kermgard Emily Hartley Kobus Barnard University
2013 IEEE Conference on Computer Vision and Pattern Recognition Understanding Bayesian rooms using composite 3D object models Luca Del Pero Joshua Bowdish Bonnie Kermgard Emily Hartley Kobus Barnard University
arxiv: v2 [cs.cv] 24 Apr 2017
![arxiv: v2 [cs.cv] 24 Apr 2017](/thumbs/74/71202274.jpg "arxiv: v2 [cs.cv] 24 Apr 2017") IM2CAD Hamid Izadinia University of Washington Qi Shan Zillow Group Steven M. Seitz University of Washington arxiv:1608.05137v2 [cs.cv] 24 Apr 2017 Figure 1: IM2CAD takes a single photo of a real scene
IM2CAD Hamid Izadinia University of Washington Qi Shan Zillow Group Steven M. Seitz University of Washington arxiv:1608.05137v2 [cs.cv] 24 Apr 2017 Figure 1: IM2CAD takes a single photo of a real scene
Geometric and Semantic 3D Reconstruction: Part 4A: Volumetric Semantic 3D Reconstruction. CVPR 2017 Tutorial Christian Häne UC Berkeley
 Geometric and Semantic 3D Reconstruction: Part 4A: Volumetric Semantic 3D Reconstruction CVPR 2017 Tutorial Christian Häne UC Berkeley Dense Multi-View Reconstruction Goal: 3D Model from Images (Depth
Geometric and Semantic 3D Reconstruction: Part 4A: Volumetric Semantic 3D Reconstruction CVPR 2017 Tutorial Christian Häne UC Berkeley Dense Multi-View Reconstruction Goal: 3D Model from Images (Depth
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Understanding Indoor Scenes using 3D Geometric Phrases
 23 IEEE Conference on Computer Vision and Pattern Recognition Understanding Indoor Scenes using 3D Geometric Phrases Wongun Choi, Yu-Wei Chao, Caroline Pantofaru 2, and Silvio Savarese University of Michigan,
23 IEEE Conference on Computer Vision and Pattern Recognition Understanding Indoor Scenes using 3D Geometric Phrases Wongun Choi, Yu-Wei Chao, Caroline Pantofaru 2, and Silvio Savarese University of Michigan,
arxiv: v1 [cs.cv] 25 Oct 2017
![arxiv: v1 [cs.cv] 25 Oct 2017](/thumbs/89/99640500.jpg "arxiv: v1 [cs.cv] 25 Oct 2017") ZOU, LI, HOIEM: COMPLETE 3D SCENE PARSING FROM SINGLE RGBD IMAGE 1 arxiv:1710.09490v1 [cs.cv] 25 Oct 2017 Complete 3D Scene Parsing from Single RGBD Image Chuhang Zou http://web.engr.illinois.edu/~czou4/
ZOU, LI, HOIEM: COMPLETE 3D SCENE PARSING FROM SINGLE RGBD IMAGE 1 arxiv:1710.09490v1 [cs.cv] 25 Oct 2017 Complete 3D Scene Parsing from Single RGBD Image Chuhang Zou http://web.engr.illinois.edu/~czou4/
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
arxiv: v1 [cs.cv] 5 May 2016
![arxiv: v1 [cs.cv] 5 May 2016](/thumbs/90/102819411.jpg "arxiv: v1 [cs.cv] 5 May 2016") Learning Action Maps of Large Environments via First-Person Vision Nicholas Rhinehart, Kris M. Kitani The Robotics Institute Carnegie Mellon University {nrhineha, kkitani}@cs.cmu.edu arxiv:1605.01679v1
Learning Action Maps of Large Environments via First-Person Vision Nicholas Rhinehart, Kris M. Kitani The Robotics Institute Carnegie Mellon University {nrhineha, kkitani}@cs.cmu.edu arxiv:1605.01679v1
Video Object Proposals
 Video Object Proposals Gilad Sharir Tinne Tuytelaars KU Leuven ESAT/PSI - IBBT Abstract In this paper, we extend a recently proposed method for generic object detection in images, category-independent
Video Object Proposals Gilad Sharir Tinne Tuytelaars KU Leuven ESAT/PSI - IBBT Abstract In this paper, we extend a recently proposed method for generic object detection in images, category-independent
The Hilbert Problems of Computer Vision. Jitendra Malik UC Berkeley & Google, Inc.
 The Hilbert Problems of Computer Vision Jitendra Malik UC Berkeley & Google, Inc. This talk The computational power of the human brain Research is the art of the soluble Hilbert problems, circa 2004 Hilbert
The Hilbert Problems of Computer Vision Jitendra Malik UC Berkeley & Google, Inc. This talk The computational power of the human brain Research is the art of the soluble Hilbert problems, circa 2004 Hilbert
Window based detectors
 Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Marr Revisited: 2D-3D Alignment via Surface Normal Prediction
 Marr Revisited: 2D-3D Alignment via Surface Normal Prediction Aayush Bansal 1 Bryan Russell 2 Abhinav Gupta 1 1 Carnegie Mellon University 2 Adobe Research http://www.cs.cmu.edu/ aayushb/marrrevisited/
Marr Revisited: 2D-3D Alignment via Surface Normal Prediction Aayush Bansal 1 Bryan Russell 2 Abhinav Gupta 1 1 Carnegie Mellon University 2 Adobe Research http://www.cs.cmu.edu/ aayushb/marrrevisited/
Single-view 3D reasoning
 Single-view 3D reasoning Lecturer: Bryan Russell UW CSE 576, May 2013 Slides borrowed from Antonio Torralba, Alyosha Efros, Antonio Criminisi, Derek Hoiem, Steve Seitz, Stephen Palmer, Abhinav Gupta, James
Single-view 3D reasoning Lecturer: Bryan Russell UW CSE 576, May 2013 Slides borrowed from Antonio Torralba, Alyosha Efros, Antonio Criminisi, Derek Hoiem, Steve Seitz, Stephen Palmer, Abhinav Gupta, James
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
Patch to the Future: Unsupervised Visual Prediction
 Patch to the Future: Unsupervised Visual Prediction Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu Abstract In this
Patch to the Future: Unsupervised Visual Prediction Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu Abstract In this
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
PanoContext: A Whole-room 3D Context Model for Panoramic Scene Understanding
 PanoContext: A Whole-room D Context Model for Panoramic Scene Understanding Yinda Zhang Shuran Song Ping Tan Jianxiong Xiao Princeton University Simon Fraser University http://panocontext.cs.princeton.edu
PanoContext: A Whole-room D Context Model for Panoramic Scene Understanding Yinda Zhang Shuran Song Ping Tan Jianxiong Xiao Princeton University Simon Fraser University http://panocontext.cs.princeton.edu
Fitting (LMedS, RANSAC)
") Fitting (LMedS, RANSAC) Thursday, 23/03/2017 Antonis Argyros e-mail: argyros@csd.uoc.gr LMedS and RANSAC What if we have very many outliers? 2 1 Least Median of Squares ri : Residuals Least Squares n 2
Fitting (LMedS, RANSAC) Thursday, 23/03/2017 Antonis Argyros e-mail: argyros@csd.uoc.gr LMedS and RANSAC What if we have very many outliers? 2 1 Least Median of Squares ri : Residuals Least Squares n 2
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Learning-based Localization
 Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Part-Based Models for Object Class Recognition Part 3
 High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
CS381V Experiment Presentation. Chun-Chen Kuo
 CS381V Experiment Presentation Chun-Chen Kuo The Paper Indoor Segmentation and Support Inference from RGBD Images. N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. ECCV 2012. 50 100 150 200 250 300 350
CS381V Experiment Presentation Chun-Chen Kuo The Paper Indoor Segmentation and Support Inference from RGBD Images. N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. ECCV 2012. 50 100 150 200 250 300 350
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
3D Scene Understanding by Voxel-CRF
 3D Scene Understanding by Voxel-CRF Byung-soo Kim University of Michigan bsookim@umich.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Silvio Savarese Stanford University ssilvio@stanford.edu
3D Scene Understanding by Voxel-CRF Byung-soo Kim University of Michigan bsookim@umich.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Silvio Savarese Stanford University ssilvio@stanford.edu
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan yuxiang@umich.edu Silvio Savarese Stanford University ssilvio@stanford.edu Abstract We propose a novel framework
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan yuxiang@umich.edu Silvio Savarese Stanford University ssilvio@stanford.edu Abstract We propose a novel framework
Lecture 8 Active stereo & Volumetric stereo
 Lecture 8 Active stereo & Volumetric stereo Active stereo Structured lighting Depth sensing Volumetric stereo: Space carving Shadow carving Voxel coloring Reading: [Szelisky] Chapter 11 Multi-view stereo
Lecture 8 Active stereo & Volumetric stereo Active stereo Structured lighting Depth sensing Volumetric stereo: Space carving Shadow carving Voxel coloring Reading: [Szelisky] Chapter 11 Multi-view stereo
Detecting Object Instances Without Discriminative Features
 Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
Binge Watching: Scaling Affordance Learning from Sitcoms
 Binge Watching: Scaling Affordance Learning from Sitcoms Xiaolong Wang Rohit Girdhar Abhinav Gupta The Robotics Institute, Carnegie Mellon University http://www.cs.cmu.edu/ xiaolonw/affordance.html Abstract
Binge Watching: Scaling Affordance Learning from Sitcoms Xiaolong Wang Rohit Girdhar Abhinav Gupta The Robotics Institute, Carnegie Mellon University http://www.cs.cmu.edu/ xiaolonw/affordance.html Abstract
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
Scale-less Dense Correspondences
 Scale-less Dense Correspondences The Open University of Israel ICCV 13 Tutorial on Dense Image Correspondences for Computer Vision Matching Pixels In different views, scales, scenes, etc. Invariant detectors
Scale-less Dense Correspondences The Open University of Israel ICCV 13 Tutorial on Dense Image Correspondences for Computer Vision Matching Pixels In different views, scales, scenes, etc. Invariant detectors
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
Combining Monocular Geometric Cues with Traditional Stereo Cues for Consumer Camera Stereo
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 Combining Monocular Geometric
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 Combining Monocular Geometric
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Some Thoughts on Visibility
 Some Thoughts on Visibility Frédo Durand MIT Lab for Computer Science Visibility is hot! 4 papers at Siggraph 4 papers at the EG rendering workshop A wonderful dedicated workshop in Corsica! A big industrial
Some Thoughts on Visibility Frédo Durand MIT Lab for Computer Science Visibility is hot! 4 papers at Siggraph 4 papers at the EG rendering workshop A wonderful dedicated workshop in Corsica! A big industrial
Dynamic visual understanding of the local environment for an indoor navigating robot
 Dynamic visual understanding of the local environment for an indoor navigating robot Grace Tsai and Benjamin Kuipers Abstract We present a method for an embodied agent with vision sensor to create a concise
Dynamic visual understanding of the local environment for an indoor navigating robot Grace Tsai and Benjamin Kuipers Abstract We present a method for an embodied agent with vision sensor to create a concise
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for