OpenACC2 vs.openmp4. James Lin 1,2 and Satoshi Matsuoka 2
|
|
|
- Arline Wilkins
- 6 years ago
- Views:
Transcription

1 Jose Shanghai Jiao Tong University Tokyo Institute of Technology OpenACC2 vs.openmp4 he Strong, the Weak, and the Missing to Develop Performance Portable Applica>ons on GPU and Xeon Phi James Lin 1,2 and Satoshi Matsuoka 2 1 Center for High Performance Computing 2 Satoshi MATSUOKA Laboratory
2 Outline OpenACC2 and OpenMP4 Systematic Optimizations to Portable Performance on GPU and Xeon Phi Summary 2

3 Why Direc>ve- based Programming? We may have many reasons to use directive-based programming, but for me, it can keep the code readable/ maintainable from the application developers' point of view CUDA Experts CUDA Version 1 Port to CUDA Unmaintainable to applica>on developers Applica>on Developers Version 1 Version 2 is based on develops own version 3
4 Direc>ve- based Programming for Accelerators [1] Standard OpenACC OpenMP >=4.0 Product PGI Accelerators HMPP Research Projects R-Stream HiCUDA OpenMPC/OpenMP for accelerators [1] S. Lee and J. S. VeTer, Early evalua>on of direc>ve- based GPU programming models for produc>ve exascale compu>ng, presented at the High Performance Compu>ng, Networking, Storage and Analysis (SC), 2012 Interna>onal Conference for, 2012, pp
5 OpenACC2 Standard version evolution is much faster than OpenMP and MPI : ~1.5year Standard/Version OpenACC Nov 2011 July OpenMP- Fortran Oct 1997 Nov 2000 May 2008 July 2013 MPI June 1994 July 1997 Sept Supported by PGI/CAPS/CRAY compiler 5
6 OpenMP 4.0 for Accelerators Released in July 2013, it supports on directivebased programming on accelerators, such as GPU and Xeon Phi Directives for Parallelism: target/parallel Data: target data Two levels of parallelism: teams/distribute 6
7 OpenACC2 Parallel Kernel Data Loop Host data Cache Update Wait Declare {enter, exit} data rou>ne Async wait Tile Device_type Atomic N/A OpenMP4 Target N/A Target Data Distribute/Do/for/SIMD N/A N/A Target Update N/A Declare Target N/A Declare target N/A N/A N/A Atomic Cri>cal sec>ons Barrier OpenACC2 has richer features than OpenMP4 7
8 Experimental Setup 2 Target Devices Accelerators used in Supercomputers, so NO AMD GPU GPU Kepler: K40 Xeon Phi KNC: 5110p 3 Compilers OpenACC: CAPS Compiler V3.4.1, support OpenACC 2.0 OpenARC is not public available yet OpenMP4: HOMP-ROSE for GPU, Intel Compiler for Xeon Phi 2 Test Cases HydroBench is a miniapp Copy benchmark 8
9 HOMP, OpenMP compiler for CUDA Developed by LLNL, it is build on ROSE [1], a source-to-source compiler It is an early research implementation [2] of OpenMP4.0 on GPU for CUDA5.0 Support C/C++ only now [1] htp://rosecompiler.org [2] C. Liao, Y. Yan, B. R. Supinski, D. J. Quinlan, and B. Chapman, Early Experiences with the 9 OpenMP Accelerator Model, IWOMP13
10 Tools used OpenACC CAPS3.4 CUDA5.5 nvcc* based on LLVM PTX is open HOMP OpenCL1.2 ICC SPIR OpenMP4.0 ICC13.0 Offload OBJ ptxas/ocelet GPU Assemble Code X86 Assemble Code asfemi+ Kepler K20/20X/40 KNC 3/5/7110p 10
11 11
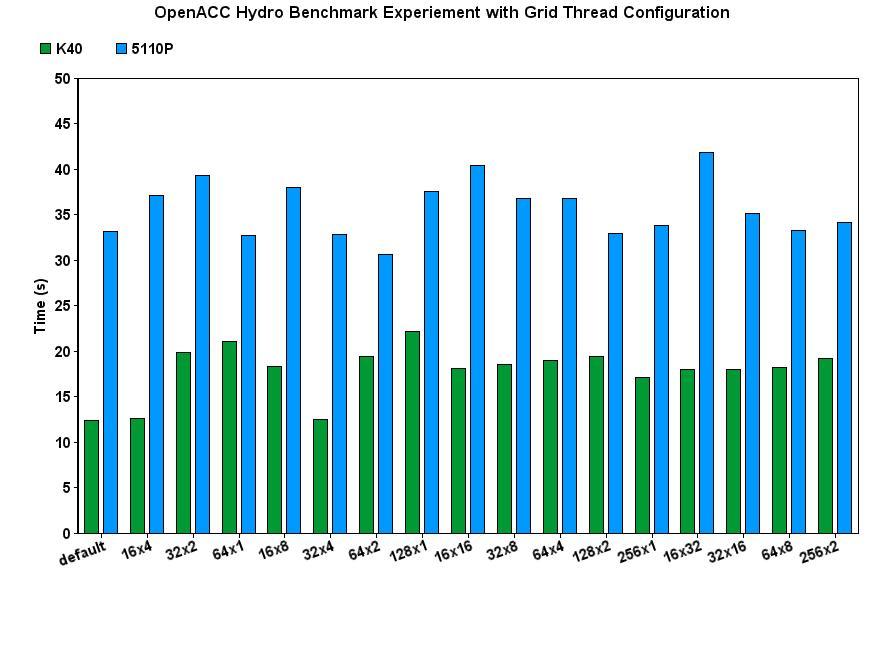
12 12
13 Performance impact of K40 and 5110P measure with data transfer 13
14 Outline OpenACC2 and OpenMP4 Systematic Optimizations to Portable Performance on GPU and Xeon Phi Summary 14
15 Performance Portability Includes source code portability of a kernel implementation and performance that is commensurate with a device-specific implementation of that kernel [Kokks] Portability for Accelerators used in HPC Different accelerators: GPU V.S. Xeon Phi Different generations: Kepler V.S. Fermi Different versions: K20 V.S. K40 15



16 Portable Performance Op>miza>ons Ninja version, Best op>miza>on, Ideal performance Frog version, achieving reasonable performance on both GPU and Xeon Phi Algorithm changes Compiler technology Naïve version, simple direc>ves, 0 op>miza>on 16

17 Op>miza>on for Portable Performance SystemaDc Accelerators OpDmizaDons Applica>ons Direc>ves SM SIMD Friendly Algo Arithme>c Intensity REG Register Level Data Locality SGEMM SHMEM SHMEM Level Data Locality FFT LBM Data Direc>ves GM GM Level Data Locality Algorithm Changes Stencil SPMV Loop Direc>ves HM Compiler Technology 17


18 Global Memory Level Memory Coalescing Thread-Grid Mapping [ISCA09] [MuCoCoS13] 18

19 Shared Memory/L2 (SHMEM) Level SHMEM Blocking (data tiling) Data Layout: AOS->SOA Avoid SHMEM bank conflict Avoid SHMEM bank Conflict 19

20 Register Level Prefetching Loop Unrolling and Jam Undocumented Register Bank Conflicts in Kepler [CGO13] 20
21 SIMD Friendly Algorithm [ISCA12] 21
22 Compiler Technology Fast math, -fastmath For sin(), replace several FMAD (Floating Point Multiply-Add) with SFU Intrinsic functions Faster, but SP only and loss some accuracy Replace FMAD with FMA, -fmad=false FMAD -> RND(RND(a*b)+c) FMA (Fused Multiply-Add) -> RND(a*b+c), Improve both accuracy and performance Asynchronous Using async clauses (OpenACC only) 22
23 Opportuni>es for auto- tuning with single source code base Code Level: self-embed code Compiler Level: support vendor intrinsic Tool Level: CAPS Auto-tuning tool Library Level: Lib for portable performance: Kokkos Drop-in support for CUDA math Lib and MKL 23
24 Outline OpenACC2 and OpenMP4 Systematic Optimizations to Portable Performance on GPU and Xeon Phi Summary 24
25 Summary Portable performance would be an important feature for directive programming approach OpenACC2 is in early stage gridfication is recommended gang/work/vector directive is weak tile directive is weak cache directive support is still missing OpenMP4 is not ready yet teams/distribute support on GPU is still missing Systematic optimization would be needed 25
Achieving Portable Performance for GTC-P with OpenACC on GPU, multi-core CPU, and Sunway Many-core Processor
 Achieving Portable Performance for GTC-P with OpenACC on GPU, multi-core CPU, and Sunway Many-core Processor Stephen Wang 1, James Lin 1,4, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See 1,3
Achieving Portable Performance for GTC-P with OpenACC on GPU, multi-core CPU, and Sunway Many-core Processor Stephen Wang 1, James Lin 1,4, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See 1,3
Analysis of Performance Gap Between OpenACC and the Native Approach on P100 GPU and SW26010: A Case Study with GTC-P
 Analysis of Performance Gap Between OpenACC and the Native Approach on P100 GPU and SW26010: A Case Study with GTC-P Stephen Wang 1, James Lin 1, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See
Analysis of Performance Gap Between OpenACC and the Native Approach on P100 GPU and SW26010: A Case Study with GTC-P Stephen Wang 1, James Lin 1, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators
 Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2
 Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
A case study of performance portability with OpenMP 4.5
 A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
Early Experiences with the OpenMP Accelerator Model
 Early Experiences with the OpenMP Accelerator Model Canberra, Australia, IWOMP 2013, Sep. 17th * University of Houston LLNL-PRES- 642558 This work was performed under the auspices of the U.S. Department
Early Experiences with the OpenMP Accelerator Model Canberra, Australia, IWOMP 2013, Sep. 17th * University of Houston LLNL-PRES- 642558 This work was performed under the auspices of the U.S. Department
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Understanding Performance Portability of OpenACC for Supercomputers
 Understanding Performance Portability of OpenACC for Supercomputers Suttinee Sawadsitang, James Lin, Simon See, Francois Bodin, Satoshi Matsuoka Shanghai Jiao Tong University, China Tokyo Institute of
Understanding Performance Portability of OpenACC for Supercomputers Suttinee Sawadsitang, James Lin, Simon See, Francois Bodin, Satoshi Matsuoka Shanghai Jiao Tong University, China Tokyo Institute of
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Early Experiences With The OpenMP Accelerator Model
 Early Experiences With The OpenMP Accelerator Model Chunhua Liao 1, Yonghong Yan 2, Bronis R. de Supinski 1, Daniel J. Quinlan 1 and Barbara Chapman 2 1 Center for Applied Scientific Computing, Lawrence
Early Experiences With The OpenMP Accelerator Model Chunhua Liao 1, Yonghong Yan 2, Bronis R. de Supinski 1, Daniel J. Quinlan 1 and Barbara Chapman 2 1 Center for Applied Scientific Computing, Lawrence
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening. Alberto Magni, Christophe Dubach, Michael O'Boyle
 A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives
 Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives José M. Andión, Manuel Arenaz, François Bodin, Gabriel Rodríguez and Juan Touriño 7th International Symposium on High-Level Parallel
Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives José M. Andión, Manuel Arenaz, François Bodin, Gabriel Rodríguez and Juan Touriño 7th International Symposium on High-Level Parallel
OpenMP 4.0: A Significant Paradigm Shift in Parallelism
 OpenMP 4.0: A Significant Paradigm Shift in Parallelism Michael Wong OpenMP CEO michaelw@ca.ibm.com http://bit.ly/sc13-eval SC13 OpenMP 4.0 released 2 Agenda The OpenMP ARB History of OpenMP OpenMP 4.0
OpenMP 4.0: A Significant Paradigm Shift in Parallelism Michael Wong OpenMP CEO michaelw@ca.ibm.com http://bit.ly/sc13-eval SC13 OpenMP 4.0 released 2 Agenda The OpenMP ARB History of OpenMP OpenMP 4.0
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
SIMD Exploitation in (JIT) Compilers
 Compilers") SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Compiling a High-level Directive-Based Programming Model for GPGPUs
 Compiling a High-level Directive-Based Programming Model for GPGPUs Xiaonan Tian, Rengan Xu, Yonghong Yan, Zhifeng Yun, Sunita Chandrasekaran, and Barbara Chapman Department of Computer Science, University
Compiling a High-level Directive-Based Programming Model for GPGPUs Xiaonan Tian, Rengan Xu, Yonghong Yan, Zhifeng Yun, Sunita Chandrasekaran, and Barbara Chapman Department of Computer Science, University
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
OpenStaPLE, an OpenACC Lattice QCD Application
 OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
Physis: An Implicitly Parallel Framework for Stencil Computa;ons
 Physis: An Implicitly Parallel Framework for Stencil Computa;ons Naoya Maruyama RIKEN AICS (Formerly at Tokyo Tech) GTC12, May 2012 1 è Good performance with low programmer produc;vity Mul;- GPU Applica;on
Physis: An Implicitly Parallel Framework for Stencil Computa;ons Naoya Maruyama RIKEN AICS (Formerly at Tokyo Tech) GTC12, May 2012 1 è Good performance with low programmer produc;vity Mul;- GPU Applica;on
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2016
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Auto-Generation and Auto-Tuning of 3D Stencil Codes on GPU Clusters
 Auto-Generation and Auto-Tuning of 3D Stencil s on GPU Clusters Yongpeng Zhang, Frank Mueller North Carolina State University CGO 2012 Outline Motivation DSL front-end and Benchmarks Framework Experimental
Auto-Generation and Auto-Tuning of 3D Stencil s on GPU Clusters Yongpeng Zhang, Frank Mueller North Carolina State University CGO 2012 Outline Motivation DSL front-end and Benchmarks Framework Experimental
OpenCL Vectorising Features. Andreas Beckmann
 Mitglied der Helmholtz-Gemeinschaft OpenCL Vectorising Features Andreas Beckmann Levels of Vectorisation vector units, SIMD devices width, instructions SMX, SP cores Cus, PEs vector operations within kernels
Mitglied der Helmholtz-Gemeinschaft OpenCL Vectorising Features Andreas Beckmann Levels of Vectorisation vector units, SIMD devices width, instructions SMX, SP cores Cus, PEs vector operations within kernels
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
CPU GPU. Regional Models. Global Models. Bigger Systems More Expensive Facili:es Bigger Power Bills Lower System Reliability
 Xbox 360 Successes and Challenges using GPUs for Weather and Climate Models DOE Jaguar Mark GoveM Jacques Middlecoff, Tom Henderson, Jim Rosinski, Craig Tierney CPU Bigger Systems More Expensive Facili:es
Xbox 360 Successes and Challenges using GPUs for Weather and Climate Models DOE Jaguar Mark GoveM Jacques Middlecoff, Tom Henderson, Jim Rosinski, Craig Tierney CPU Bigger Systems More Expensive Facili:es
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
Evaluating OpenMP s Effectiveness in the Many-Core Era
 Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
LLVM for the future of Supercomputing
 LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Auto-tuning a High-Level Language Targeted to GPU Codes. By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos
 Auto-tuning a High-Level Language Targeted to GPU Codes By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos GPU Computing Utilization of GPU gives speedup on many algorithms
Auto-tuning a High-Level Language Targeted to GPU Codes By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos GPU Computing Utilization of GPU gives speedup on many algorithms
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise. June 2011
 MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
A low memory footprint OpenCL simulation of short-range particle interactions
 A low memory footprint OpenCL simulation of short-range particle interactions Raymond Namyst STORM INRIA Group With Samuel Pitoiset, Inria and Emmanuel Cieren, Laurent Colombet, Laurent Soulard, CEA/DAM/DPTA
A low memory footprint OpenCL simulation of short-range particle interactions Raymond Namyst STORM INRIA Group With Samuel Pitoiset, Inria and Emmanuel Cieren, Laurent Colombet, Laurent Soulard, CEA/DAM/DPTA
Analyzing and improving performance portability of OpenCL applications via auto-tuning
 Analyzing and improving performance portability of OpenCL applications via auto-tuning James Price & Simon McIntosh-Smith University of Bristol - High Performance Computing Group http://uob-hpc.github.io
Analyzing and improving performance portability of OpenCL applications via auto-tuning James Price & Simon McIntosh-Smith University of Bristol - High Performance Computing Group http://uob-hpc.github.io
Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core
 Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core Tom Henderson NOAA/OAR/ESRL/GSD/ACE Thomas.B.Henderson@noaa.gov Mark Govett, Jacques Middlecoff Paul Madden,
Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core Tom Henderson NOAA/OAR/ESRL/GSD/ACE Thomas.B.Henderson@noaa.gov Mark Govett, Jacques Middlecoff Paul Madden,
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Pragma-based GPU Programming and HMPP Workbench. Scott Grauer-Gray
 Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA
 Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle,
Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle,
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC
 A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
An Introduc+on to OpenACC Part II
 An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
Parallel Hybrid Computing Stéphane Bihan, CAPS
 Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
An Evaluation of Unified Memory Technology on NVIDIA GPUs
 An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Designing and Optimizing LQCD code using OpenACC
 Designing and Optimizing LQCD code using OpenACC E Calore, S F Schifano, R Tripiccione Enrico Calore University of Ferrara and INFN-Ferrara, Italy GPU Computing in High Energy Physics Pisa, Sep. 10 th,
Designing and Optimizing LQCD code using OpenACC E Calore, S F Schifano, R Tripiccione Enrico Calore University of Ferrara and INFN-Ferrara, Italy GPU Computing in High Energy Physics Pisa, Sep. 10 th,
Parallel and Distributed Programming Introduction. Kenjiro Taura
 Parallel and Distributed Programming Introduction Kenjiro Taura 1 / 21 Contents 1 Why Parallel Programming? 2 What Parallel Machines Look Like, and Where Performance Come From? 3 How to Program Parallel
Parallel and Distributed Programming Introduction Kenjiro Taura 1 / 21 Contents 1 Why Parallel Programming? 2 What Parallel Machines Look Like, and Where Performance Come From? 3 How to Program Parallel
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Optimization Case Study for Kepler K20 GPUs: Synthetic Aperture Radar Backprojection
 Optimization Case Study for Kepler K20 GPUs: Synthetic Aperture Radar Backprojection Thomas M. Benson 1 Daniel P. Campbell 1 David Tarjan 2 Justin Luitjens 2 1 Georgia Tech Research Institute {thomas.benson,dan.campbell}@gtri.gatech.edu
Optimization Case Study for Kepler K20 GPUs: Synthetic Aperture Radar Backprojection Thomas M. Benson 1 Daniel P. Campbell 1 David Tarjan 2 Justin Luitjens 2 1 Georgia Tech Research Institute {thomas.benson,dan.campbell}@gtri.gatech.edu
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Fast-multipole algorithms moving to Exascale
 Numerical Algorithms for Extreme Computing Architectures Software Institute for Methodologies and Abstractions for Codes SIMAC 3 Fast-multipole algorithms moving to Exascale Lorena A. Barba The George
Numerical Algorithms for Extreme Computing Architectures Software Institute for Methodologies and Abstractions for Codes SIMAC 3 Fast-multipole algorithms moving to Exascale Lorena A. Barba The George
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
GLAF: A Visual Programming and Auto- Tuning Framework for Parallel Computing
 GLAF: A Visual Programming and Auto- Tuning Framework for Parallel Computing Student: Konstantinos Krommydas Collaborator: Dr. Ruchira Sasanka (Intel) Advisor: Dr. Wu-chun Feng Motivation High-performance
GLAF: A Visual Programming and Auto- Tuning Framework for Parallel Computing Student: Konstantinos Krommydas Collaborator: Dr. Ruchira Sasanka (Intel) Advisor: Dr. Wu-chun Feng Motivation High-performance
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
OpenACC Standard. Credits 19/07/ OpenACC, Directives for Accelerators, Nvidia Slideware
 OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures
 Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Post-K Supercomputer Overview. Copyright 2016 FUJITSU LIMITED
 Post-K Supercomputer Overview 1 Post-K supercomputer overview Developing Post-K as the successor to the K computer with RIKEN Developing HPC-optimized high performance CPU and system software Selected
Post-K Supercomputer Overview 1 Post-K supercomputer overview Developing Post-K as the successor to the K computer with RIKEN Developing HPC-optimized high performance CPU and system software Selected
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Accelerator programming with OpenACC
 ..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling