Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
|
|
|
- Sydney Horn
- 6 years ago
- Views:
Transcription




1 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
2 Agenda accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native mode programming & hands on
3 Why do we Need Coprocessors/or Accelerators on HPC? In the past, computers got faster by increasing the clock frequency of the core, but this has now reached its limit mainly due to power requirements and heat dissipation restrictions (unmanageable problem). Today, processor cores are not getting any faster, but instead the number of cores per chip increases. On HPC, we need a chip that can provide higher computing performance at lower energy.

4 Why do we Need Coprocessors/or Accelerators on HPC? The actual solution is a heterogeneous system containing both CPUs and accelerators, plus other forms of parallelism such as vector instruction support. Widely accepted that heterogeneous systems with accelerators deliver the highest performance and energy efficient computing in HPC. Today!! the accelerated computing is revolutionising HPC.
5 Why do we Need Coprocessors/or Accelerators on HPC?
6 TOP 4 Sites for June Jun 2016 Intel MIC Programming Workshop


 Same problem executed on many data elements")
7 Architectures Comparison (CPU vs GPU) Control ALU ALU ALU ALU Cache DRAM DRAM - Large cache and sophisticated flow control minimise latency for arbitrary memory access for serial process. Simple flow control and limited cache. More transistors for computing in parallel (up to 17 billion on Pascal GPU) Same problem executed on many data elements in parallel (SIMD)
8 Intel Xeon Phi Products The first product was released in 2012 named Knights Corner (KNC) which is the first architecture supporting 512 bit vectors. The 2 nd generation released last week named Knights Landing (KNL) also support 512bit vectors with a new instruction set called Intel Advanced Vector Instructions 512 (Intel AVX-512) KNL has a peak performance of 6 TFLOP/s in single precision ~ 3 times what KNC had, due to 2 vector processing units (VPUs) per core, doubled compared to the KNC. Each VPU operates independently on 512-bit vector registers, which can hold 16 single precision or 8 double precession floating-point numbers.
9 Intel Xeon Phi: KNC Coprocessors Add-on to CPU based systems (PCIe interface) High power efficiency ~ 1 TFLOP/s in DP Heterogeneous clustering Currently it s a major part of the world s 2fastest supercomputer: Tianhe-2 in Guangzhou, China Today most of the major HPC venders are supporting Xeon Phi

 ~ 1 GHz 22 nm 512-bit vector registers Parallel Programming and Optimization with")
10 Intel Xeon Phi Coprocessors & MIC Architecture Multi-core Intel Xeon processor ~ 16 physical cores ~ 3 GHz e.g Intel Sandy-Bridge 32 nm (AVX) 256-bit vector registers Many-core Intel Xeon Phi coprocessor ~ 61 cores (244) ~ 1 GHz 22 nm 512-bit vector registers Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, Colfax

11 Intel MIC Architecture in common with Intel multi-core Xeon CPUs! X86 architecture C, C++ and Fortran Standard parallelisation libraries Similar optimisation methods Up to 18 cores/socket Up to 3 GHz Up to 768 GB of DDR3 RAM 256 bit AVX vectors 2-way hyper-threading PCIe bus connection IP-addressable Own Linux version OS Full Intel software tool suite 8-16 GB GDDR5 DRAM (cached) Up to 61 x86 (64 bit) cores Up to 1 GHz 512 bit wide vector registers 4 way hyper-threading 64-bit addressing SSE, AVX or AVX2: are not supported Intel Initial Many Core Instructions (IMCI).


12 Architectures Comparison Control ALU ALU ALU ALU Cache DRAM DRAM DRAM General-purpose architecture Power-efficient Multiprocessor X86 design architecture Massively data parallel
, PCIe client logic, GDDR5")
13 The Intel Xeon Phi Microarchitecture High bandwidth network interconnect by bidirectional ring topology. The ring connects all the 61 cores, L2 caches through a distributed global Tag Directory (TD), PCIe client logic, GDDR5 memory controllers etc.

14 Network Access Network access possible using TCP/IP tools like ssh. NFS mounts on Xeon Phi Supported. First experiences with the Intel MIC architecture at LRZ, Volker Weinberg and Momme Allalen, inside Vol. 11 No.2 Autumn2013
 64 pages of size 4KB (256KB coverage) Coverage options (L1, data) 8 pages of size 2MB (16MB coverage) Intel's Jim Jeffers and James")
15 Cache Structure Cache line size 64B L1 size 32KB data cache, 32KB instruction code L1 latency 1 cycle L2 size 512 KB L2 ways 8 L2 latency cycles Memory à L2 prefetching hardware and software L2 à L1 prefetching software only Translation Lookside Buffer (TLB) 64 pages of size 4KB (256KB coverage) Coverage options (L1, data) 8 pages of size 2MB (16MB coverage) Intel's Jim Jeffers and James Reinders: Intel Xeon Phi Coprocessor High Performance Programming, the first book on how to program this HPC vector chip, is available on Amazon 15
16 Cache Structure L2 size depends on how data/code is shared between the cores If no data is shared between cores: L2 size is 30.5 MB (61 cores). If every core shares the same data: L2 size is 512 KB. Cache coherency across the entire coprocessor. Data remains consistent without software intervention.
17 Features of the Initial Many Core Instructions (IMCI) Set 512-bit wide registers can pack up to eight 64-bit elements (long int, double) up to sixteen 32-bit elements (int, float) Arithmetic Instructions Addition, subtraction and multiplication Fused Multiply-Add instruction (FMA) Division and reciprocal calculation Exponential functions and the power function Logarithms (natural, base 2 and base 10) Square root, inverse square root, hypothenuse value and cubic root Trigonometric functions (sin, cos, tan, sinh, cosh, tanh, asin, acos, atan)
18 Lab1: Access SuperMIC
19 Interacting with Intel Xeon Phi Coprocessors listdevices MicInfo Utility Log Created Thu Jan 7 09:33: List of Available Devices deviceid domain bus# pcidev# hardwareid b user@host~$ micinfo grep -i cores Cores Total No of Active Cores : 61 Cores Total No of Active Cores : 61
20 Interacting with Intel Xeon Phi Coprocessors /sbin/lspci grep -i "co-processor 20:00.0 Co-processor: Intel Corporation Xeon Phi. (rev 20) 8b:00.0 Co-processor: Intel Corporation Xeon Phi. (rev 20) cat /etc/hosts grep mic1 cat /etc/hosts grep mic1-ib0 wc l user@host~$ ssh mic0 or ssh mic1 user@host-mic0~$ ls / bin boot dev etc home init lib lib64 lrz media mnt proc root sbin sys tmp usr var micsmc a utility for monitoring the physical parameters of Intel Xeon Phi coprocessors: model, memory, core rail temperatures, core frequency, power usage, etc.



21 Parallelism on the Heterogeneous Systems 1 L1D L2 L1D L2 2 3 L3 L1D L2 L1D L2 L1D L2 L1D L2 L3 L1D L2 L1D L2 4 Memory Interface Memory Interface 5 6 Other I/O Memory Memory Vectorisation - SIMD 1 Parallelism MPI/OpenMP ccnuma domains 3 Multiple accelerators 4 2 PCIe buses 5 Other I/O resources 6
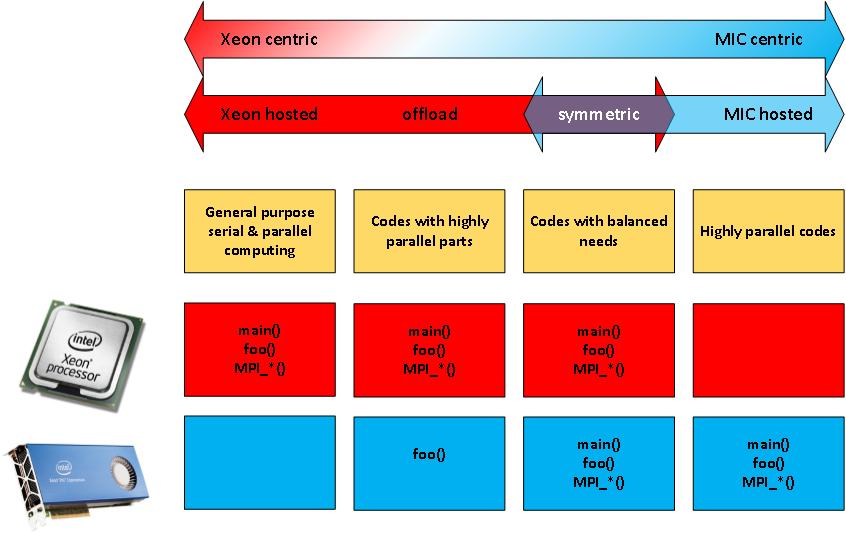
22 MIC Programming Models
23 MIC Programming Models Native Mode Programs started on Xeon Phi Cross-compilation using mmic User access to Xeon Phi is necessary Offload to MIC Offload using OpenMP extensions Automatically offload some routines using MKL MKL Compiled assisted offload (CAO) MKL automatic Offload (AO) MPI tasks on Host and MIC Treat the coprocessor like another host Host main() { #pragma offload target(mic) MPI only and MPI + X (X may be OpenMP, TBB, Cilk, OpenCL etc.) } Host main() { #pragma offload target(mic) } MIC MIC myfunction();
24 MIC Programming Models
25 Native Mode First ensure that the application is suitable for native execution. The application runs entirely on the MIC coprocessor without offload from a host system. Compile the application for native execution using the flag: -mmic Build also the required libraries for native execution. Copy the executable and any dependencies, such as run time libraries to the coprocessor. Mount file shares to the coprocessor for accessing input data sets and saving output data sets. Login to the coprocessor via console, setup the environment and run the executable. You can debug the native application via a debug server running on the coprocessor.
26 Native Mode Compile on the Host: ~$ $INTEL_BASE/linux/bin/compilervars.sh intel64 ~$ icpc -mmic hello.c -o hello ~$ifort -mmic hello.f90 -o hello Launch execution from the MIC: ~$ scp hello $HOST-mic0: ~$ ssh $HOST-mic0 ~$./hello hello, world
27 Native Mode: micnativeloadex The tool automatically transfer the code and dependent libraries and execute from the host: ~$./hello -bash:./hello: cannot execute Binary file ~$ export SINK_LIBRARY_PATH= /intel/compiler/lib/mic ~$ micnativeloadex./hello hello, world ~$ micnativeloadex./hello -v hello, world Remote process returned: 0 Exit reason: SHUTDOWN OK
28 Native Mode Use the Intel compiler flag mmic Remove assembly and unnecessary dependencies Use host= host=x86_64 to avoid program does not run errors Example, the GNU Multiple Precision Arithmetic Library (GMP): ~$host: wget ~$host: tar xf gmp tar.bz2 ~$host: cd gmp ~$host:./configure --prefix=${gmp_build} CC=icc CFLAGS= -mmic host=x86_64 disable-assembly --enable-cxx ~$host: make
29 Lab 2: Native Mode
30 micinfo and _SC_NPROCESSORS_ONLN ~$ micinfo listdevices ~$ micinfo grep -i cores ~$ cat hello.c #include <stdio.h> #include <unistd.h> int main(){ printf("hello world! I have %ld logical cores.\n", } sysconf(_sc_nprocessors_onln)); ~$ icc hello.c o hello-host &&./hello-host ~$ icc mmic hello.c o hello-mic ~$ micnativeloadex./hello-mic

31 Thank you.
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
Intel MIC Programming Workshop, Hardware Overview & Native Execution. Ostrava,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution Ostrava, 7-8.2.2017 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution Ostrava, 7-8.2.2017 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Scientific Computing with Intel Xeon Phi Coprocessors
 Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Overview of Intel Xeon Phi Coprocessor
 Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
6/14/2017. The Intel Xeon Phi. Setup. Xeon Phi Internals. Fused Multiply-Add. Getting to rabbit and setting up your account. Xeon Phi Peak Performance
 The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Knights Corner: Your Path to Knights Landing
 Knights Corner: Your Path to Knights Landing James Reinders, Intel Wednesday, September 17, 2014; 9-10am PDT Photo (c) 2014, James Reinders; used with permission; Yosemite Half Dome rising through forest
Knights Corner: Your Path to Knights Landing James Reinders, Intel Wednesday, September 17, 2014; 9-10am PDT Photo (c) 2014, James Reinders; used with permission; Yosemite Half Dome rising through forest
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor 1 Agenda Introduction Intel Xeon Phi Architecture Programming Models Outlook Summary 2 Intel Multicore Architecture Intel Many Integrated Core Architecture (Intel MIC) Foundation
Intel Xeon Phi Coprocessor 1 Agenda Introduction Intel Xeon Phi Architecture Programming Models Outlook Summary 2 Intel Multicore Architecture Intel Many Integrated Core Architecture (Intel MIC) Foundation
Many-core Processor Programming for beginners. Hongsuk Yi ( 李泓錫 ) KISTI (Korea Institute of Science and Technology Information)
 KISTI (Korea Institute of Science and Technology Information)") Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
PRACE PATC Course: Intel MIC Programming Workshop, MKL LRZ,
 PRACE PATC Course: Intel MIC Programming Workshop, MKL LRZ, 27.6-29.6.2016 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi - Compiler Assisted Offload - Automatic Offload - Native Execution
PRACE PATC Course: Intel MIC Programming Workshop, MKL LRZ, 27.6-29.6.2016 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi - Compiler Assisted Offload - Automatic Offload - Native Execution
PRACE PATC Course: Intel MIC Programming Workshop MPI LRZ,
 PRACE PATC Course: Intel MIC Programming Workshop MPI LRZ, 27.6.- 29.6.2016 Intel Xeon Phi Programming Models: MPI MPI on Hosts & MICs MPI @ LRZ Default Module: SuperMUC: mpi.ibm/1.4 SuperMIC: mpi.intel/5.1
PRACE PATC Course: Intel MIC Programming Workshop MPI LRZ, 27.6.- 29.6.2016 Intel Xeon Phi Programming Models: MPI MPI on Hosts & MICs MPI @ LRZ Default Module: SuperMUC: mpi.ibm/1.4 SuperMIC: mpi.intel/5.1
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - LRZ,
 Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Native Computing and Optimization. Hang Liu December 4 th, 2013
 Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture
 Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
E, F. Best-known methods (BKMs), 153 Boot strap processor (BSP),
, 153 Boot strap processor (BSP),") Index A Accelerated Strategic Computing Initiative (ASCI), 3 Address generation interlock (AGI), 55 Algorithm and data structures, 171. See also General matrix-matrix multiplication (GEMM) design rules,
Index A Accelerated Strategic Computing Initiative (ASCI), 3 Address generation interlock (AGI), 55 Algorithm and data structures, 171. See also General matrix-matrix multiplication (GEMM) design rules,
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
rabbit.engr.oregonstate.edu What is rabbit?
 1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Intel MIC Architecture. Dr. Momme Allalen, LRZ, PRACE PATC: Intel MIC&GPU Programming Workshop
 Intel MKL @ MIC Architecture Dr. Momme Allalen, LRZ, allalen@lrz.de PRACE PATC: Intel MIC&GPU Programming Workshop 1 2 Momme Allalen, HPC with GPGPUs, Oct. 10, 2011 What is the Intel MKL? Math library
Intel MKL @ MIC Architecture Dr. Momme Allalen, LRZ, allalen@lrz.de PRACE PATC: Intel MIC&GPU Programming Workshop 1 2 Momme Allalen, HPC with GPGPUs, Oct. 10, 2011 What is the Intel MKL? Math library
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Xeon Phi Coprocessors on Turing
 Xeon Phi Coprocessors on Turing Table of Contents Overview...2 Using the Phi Coprocessors...2 Example...2 Intel Vtune Amplifier Example...3 Appendix...8 Sources...9 Information Technology Services High
Xeon Phi Coprocessors on Turing Table of Contents Overview...2 Using the Phi Coprocessors...2 Example...2 Intel Vtune Amplifier Example...3 Appendix...8 Sources...9 Information Technology Services High
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Xeon Phi coprocessor (codename Knights Corner) George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012
 George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012") Intel Xeon Phi coprocessor (codename Knights Corner) George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012 Legal Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Intel Xeon Phi coprocessor (codename Knights Corner) George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012 Legal Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Evaluation of Intel Xeon Phi "Knights Corner": Opportunities and Shortcomings
 ERLANGEN REGIONAL COMPUTING CENTER Evaluation of Intel Xeon Phi "Knights Corner": Opportunities and Shortcomings J. Eitzinger 29.6.2016 Technologies Driving Performance Technology 1991 1992 1993 1994 1995
ERLANGEN REGIONAL COMPUTING CENTER Evaluation of Intel Xeon Phi "Knights Corner": Opportunities and Shortcomings J. Eitzinger 29.6.2016 Technologies Driving Performance Technology 1991 1992 1993 1994 1995
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Investigation of Intel MIC for implementation of Fast Fourier Transform
 Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation
 S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Programming Intel R Xeon Phi TM
 Programming Intel R Xeon Phi TM An Overview Anup Zope Mississippi State University 20 March 2018 Anup Zope (Mississippi State University) Programming Intel R Xeon Phi TM 20 March 2018 1 / 46 Outline 1
Programming Intel R Xeon Phi TM An Overview Anup Zope Mississippi State University 20 March 2018 Anup Zope (Mississippi State University) Programming Intel R Xeon Phi TM 20 March 2018 1 / 46 Outline 1
Lab MIC Offload Experiments 7/22/13 MIC Advanced Experiments TACC
 Lab MIC Offload Experiments 7/22/13 MIC Advanced Experiments TACC # pg. Subject Purpose directory 1 3 5 Offload, Begin (C) (F90) Compile and Run (CPU, MIC, Offload) offload_hello 2 7 Offload, Data Optimize
Lab MIC Offload Experiments 7/22/13 MIC Advanced Experiments TACC # pg. Subject Purpose directory 1 3 5 Offload, Begin (C) (F90) Compile and Run (CPU, MIC, Offload) offload_hello 2 7 Offload, Data Optimize
PRACE PATC Course: Intel MIC Programming Workshop, MKL. Ostrava,
 PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
PRACE PATC Course: Intel MIC Programming Workshop, MKL Ostrava, 7-8.2.2017 1 Agenda A quick overview of Intel MKL Usage of MKL on Xeon Phi Compiler Assisted Offload Automatic Offload Native Execution Hands-on
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Intel Math Kernel Library (Intel MKL) Latest Features
 Latest Features") Intel Math Kernel Library (Intel MKL) Latest Features Sridevi Allam Technical Consulting Engineer Sridevi.allam@intel.com 1 Agenda - Introduction to Support on Intel Xeon Phi Coprocessors - Performance
Intel Math Kernel Library (Intel MKL) Latest Features Sridevi Allam Technical Consulting Engineer Sridevi.allam@intel.com 1 Agenda - Introduction to Support on Intel Xeon Phi Coprocessors - Performance
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
GRID Testing and Profiling. November 2017
 GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Leibniz Supercomputer Centre. Movie on YouTube
 SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
SCALABLE HYBRID PROTOTYPE
 SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Technical Report. Document Id.: CESGA Date: July 28 th, Responsible: Andrés Gómez. Status: FINAL
 Technical Report Abstract: This technical report presents CESGA experience of porting three applications to the new Intel Xeon Phi coprocessor. The objective of these experiments was to evaluate the complexity
Technical Report Abstract: This technical report presents CESGA experience of porting three applications to the new Intel Xeon Phi coprocessor. The objective of these experiments was to evaluate the complexity
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Laurent Duhem Intel Alain Dominguez - Intel
 Laurent Duhem Intel Alain Dominguez - Intel Agenda 2 What are Intel Xeon Phi Coprocessors? Architecture and Platform overview Intel associated software development tools Execution and Programming model
Laurent Duhem Intel Alain Dominguez - Intel Agenda 2 What are Intel Xeon Phi Coprocessors? Architecture and Platform overview Intel associated software development tools Execution and Programming model
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
OpenCL Vectorising Features. Andreas Beckmann
 Mitglied der Helmholtz-Gemeinschaft OpenCL Vectorising Features Andreas Beckmann Levels of Vectorisation vector units, SIMD devices width, instructions SMX, SP cores Cus, PEs vector operations within kernels
Mitglied der Helmholtz-Gemeinschaft OpenCL Vectorising Features Andreas Beckmann Levels of Vectorisation vector units, SIMD devices width, instructions SMX, SP cores Cus, PEs vector operations within kernels
1. Many Core vs Multi Core. 2. Performance Optimization Concepts for Many Core. 3. Performance Optimization Strategy for Many Core
 1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
Lab MIC Experiments 4/25/13 TACC
 Lab MIC Experiments 4/25/13 TACC # pg. Subject Purpose directory 1 3 5 Offload, Begin (C) (F90) Compile and Run (CPU, MIC, Offload) offload_hello 2 7 Offload, Data Optimize Offload Data Transfers offload_transfer
Lab MIC Experiments 4/25/13 TACC # pg. Subject Purpose directory 1 3 5 Offload, Begin (C) (F90) Compile and Run (CPU, MIC, Offload) offload_hello 2 7 Offload, Data Optimize Offload Data Transfers offload_transfer
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Simulation using MIC co-processor on Helios
 Simulation using MIC co-processor on Helios Serhiy Mochalskyy, Roman Hatzky PRACE PATC Course: Intel MIC Programming Workshop High Level Support Team Max-Planck-Institut für Plasmaphysik Boltzmannstr.
Simulation using MIC co-processor on Helios Serhiy Mochalskyy, Roman Hatzky PRACE PATC Course: Intel MIC Programming Workshop High Level Support Team Max-Planck-Institut für Plasmaphysik Boltzmannstr.
arxiv: v2 [hep-lat] 3 Nov 2016
![arxiv: v2 [hep-lat] 3 Nov 2016](/thumbs/90/103721354.jpg "arxiv: v2 [hep-lat] 3 Nov 2016") MILC staggered conjugate gradient performance on Intel KNL arxiv:1611.00728v2 [hep-lat] 3 Nov 2016 Department of Physics, Indiana University, Bloomington IN 47405, USA E-mail: ruizli@umail.iu.edu Carleton
MILC staggered conjugate gradient performance on Intel KNL arxiv:1611.00728v2 [hep-lat] 3 Nov 2016 Department of Physics, Indiana University, Bloomington IN 47405, USA E-mail: ruizli@umail.iu.edu Carleton
HPC code modernization with Intel development tools
 HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor