Chapter 7. Multicores, Multiprocessors, and Clusters
|
|
|
- Spencer Nichols
- 5 years ago
- Views:
Transcription
1 Chapter 7 Multicores, Multiprocessors, and Clusters
2 Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level) parallelism High throughput for independent jobs Parallel processing program Single program run on multiple processors Multicore microprocessors Chips with multiple processors (cores) 7.1 Introduction Chapter 7 Multicores, Multiprocessors, and Clusters 2

3 Hardware and Software (Quad core) (Quad core) Sequential/concurrent software can run on serial/parallel hardware Challenge: making effective use of parallel hardware Chapter 7 Multicores, Multiprocessors, and Clusters 3
4 The trouble with multi-core No clear notion how to program multi-core processors No further scaling in single core power wall Intel would dedicate»all of our future product designs to multi-core environments«now-defunct companies Ardent, Convex, Encore, Floating Point Systems, Inmos, Kendall Square Research, MasPar, ncube, Sequent, Tandem, Thinking Machines, Chapter 7 Multicores, Multiprocessors, and Clusters 4
5 Research since the 1960s Search for the right computer language: Hundreds, but none made it as fast, efficient and flexible as traditional sequential languages Design the hardware properly: No one has yet succeeded. Software to automatically parallelize sequential program: Depending on program, some benefit for 2, 4, (8) cores Chapter 7 Multicores, Multiprocessors, and Clusters 5
6 Progress in some communities Data base systems for transaction processing (ATM, reservation systems) It is much easier to parallelize programs that deal with lots of users doing the same thing rather than a single user doing something very complicated inherent task-level parallelism Computer graphics (animated movies, special effects) individual scenes computed in parallel GPUs contain hundreds of processors, each tackling a small piece of rendering an image data-level parallelism Scientific computing (whether, crash simulations) data-level parallelism Chapter 7 Multicores, Multiprocessors, and Clusters 6
7 Reasons for optimism The whole computer industry is working on the problem Shift to parallelism is starting and growing slowly Programmers start with dual- and quad-core-processors Degree of motivation: No further waiting for next generation processor Synergy between many-core processing and software as a service (cloud computing, applications running in a remote data center with millions of users) task-level parallelism Research working on a few important applications (e.g. speech recognition (understanding) in crowded, noisy, reverberant environments) Chapter 7 Multicores, Multiprocessors, and Clusters 7
8 Hardware Microprocessors with a large number of cores not yet manufactured no platform to run experimental software on FPGAs to simulate future computers, e.g. RAMP (Research Accelerator for Multiple Processors) MicroBlaze (32 Bit DLX-µP) cores in FPGAs (Virtex-II Pro) on boards Chapter 7 Multicores, Multiprocessors, and Clusters 8




9 Intel: 48-Core Single-Chip Cloud Computer 24 Dual-core tiles 24 Routers Mesh network with 256 GB/s bisection bandwidth 4 Integrated DDR 3 memory controllers 1.3 Billion transistors L2 Cache Dual-core SCC Tile Core 1 MEMORY CONTROLLER R R R 1TILE ROUTER Message Buffer R R R L2 Cache Core 2 ROUTER Chapter 7 Multicores, Multiprocessors, and Clusters 9

10 Chapter 7 Multicores, Multiprocessors, and Clusters 10
11 2020 (David Patterson) 1. Practical number of cores hits limit: Broad impact on IT: µp (products) still getting cheaper, but no more computational power. Netbook-path + cloud computing 2. Only multimedia apps can exploit data-level parallelism. Are such applications able to sustain the growth of IT? GPU-path 3. Someone figures out how to make dependable parallel software providing the future for the next 30 years optimistic path Chapter 7 Multicores, Multiprocessors, and Clusters 11
12 Chapter 7 Multicores, Multiprocessors, and Clusters 12
13 What We ve Already Covered 2.11: Parallelism and Instructions Synchronization (atomic exchange) 3.6: Parallelism and Computer Arithmetic Associativity (floating point) 4.10: Parallelism and Advanced Instruction-Level Parallelism (pipel., superscalar) 5.8: Parallelism and Memory Hierarchies Cache Coherence 6.9: Parallelism and I/O: Redundant Arrays of Inexpensive Disks Chapter 7 Multicores, Multiprocessors, and Clusters 13
14 Parallel Programming Parallel software is the problem Need to get significant performance improvement Otherwise, just use a faster uniprocessor, since it s easier! Difficulties Partitioning, load balancing Coordination, synchronization Communications overhead Sequential dependencies 7.2 The Difficulty of Creating Parallel Processing Programs Chapter 7 Multicores, Multiprocessors, and Clusters 14
15 Amdahl s Law Sequential part can limit speedup Example: 100 processors, 90 speedup? T new = T parallelizable /100 + T sequential Speedup = (1 F parallelizable 1 ) + F parallelizable /100 = 90 Solving: F parallelizable = Need sequential part to be 0.1% of original time Chapter 7 Multicores, Multiprocessors, and Clusters 15
16 Scaling Example Workload: sum of 10 scalars, and matrix sum Speed up from 10 to 100 processors Single processor: Time = ( ) t add 10 processors Time = 10 t add + 100/10 t add = 20 t add Speedup = 110/20 = 5.5 (55% of potential) 100 processors Time = 10 t add + 100/100 t add = 11 t add Speedup = 110/11 = 10 (10% of potential) Assumes load can be balanced across processors Chapter 7 Multicores, Multiprocessors, and Clusters 16
17 Scaling Example (cont) What if matrix size is ? Single processor: Time = ( ) t add 10 processors Time = 10 t add /10 t add = 1010 t add Speedup = 10010/1010 = 9.9 (99% of potential) 100 processors Time = 10 t add /100 t add = 110 t add Speedup = 10010/110 = 91 (91% of potential) Assuming load balanced Chapter 7 Multicores, Multiprocessors, and Clusters 17
18 Strong vs Weak Scaling Strong scaling: speedup can be achieved on a multiprocessor without increasing the size of the problem Weak scaling: speedup is achieved on a multiprocessor by increasing the size of the problem proportionally to the increase in the number of processors Chapter 7 Multicores, Multiprocessors, and Clusters 18


19 Shared Memory SMP: shared memory multiprocessor Hardware provides single physical address space for all processors Synchronize shared variables using locks Memory access time UMA (uniform) vs. NUMA (nonuniform) 7.3 Shared Memory Multiprocessors Chapter 7 Multicores, Multiprocessors, and Clusters 19
20 Summing 100,000 Numbers on 100 Proc. SMP Processors start by running a loop that sums their subset of vector A numbers (vectors A and sum are shared variables, Pn is the processor s number, i is a private variable) sum[pn] = 0; for (i = 1000*Pn; i< 1000*(Pn+1); i = i + 1) sum[pn] = sum[pn] + A[i]; The processors then coordinate in adding together the partial sums (half is a private variable initialized to 100 (the number of processors)) reduction repeat synch(); /*synchronize first if (half%2!= 0 && Pn == 0) sum[0] = sum[0] + sum[half-1]; half = half/2 if (Pn<half) sum[pn] = sum[pn] + sum[pn+half] until (half == 1); /*final sum in sum[0] Chapter 7 Multicores, Multiprocessors, and Clusters 20
21 An Example with 10 Processors sum[p0] sum[p1] sum[p2] sum[p3] sum[p4] sum[p5] sum[p6] sum[p7] sum[p8] sum[p9] P0 P1 P2 P3 P4 P5 P6 P7 P8 P9 half = 10 P0 P1 P2 P3 P4 half = 5 P0 P1 half = 2 P0 half = 1 Chapter 7 Multicores, Multiprocessors, and Clusters 21

22 Message Passing Each processor has private physical address space Hardware sends/receives messages between processors 7.4 Clusters and Other Message-Passing Multiprocessors Chapter 7 Multicores, Multiprocessors, and Clusters 22
23 Loosely Coupled Clusters Network of Workstations (NOW) Clusters Network of independent computers Each has private memory and OS Connected using I/O system E.g., Ethernet/Switch, Internet Suitable for applications with independent tasks Web servers, databases, simulations, High availability, scalable, affordable Problems Administration cost Low interconnect bandwidth c.f. processor/memory bandwidth on an SMP Chapter 7 Multicores, Multiprocessors, and Clusters 23
24 Sum Reduction (Again) Sum 100,000 on 100 processors First distribute 100 numbers to each The do partial sums sum = 0; for (i = 0; i<1000; i = i + 1) sum = sum + AN[i]; Reduction Half the processors send, other half receive and add The quarter send, quarter receive and add, Chapter 7 Multicores, Multiprocessors, and Clusters 24
25 Sum Reduction (Again) Given send() and receive() operations limit = 100; half = 100;/* 100 processors */ repeat half = (half+1)/2; /* send vs. receive dividing line */ if (Pn >= half && Pn < limit) send(pn - half, sum); if (Pn < (limit/2)) sum = sum + receive(); limit = half; /* upper limit of senders */ until (half == 1); /* exit with final sum */ Send/receive also provide synchronization Assumes send/receive take similar time to addition (which is unrealistic) Chapter 7 Multicores, Multiprocessors, and Clusters 25
26 An Example with 10 Processors sum sum sum sum sum sum sum sum sum sum P0 P1 P2 P3 P4 P5 P6 P7 P8 P9 send P0 P1 P2 P3 P4 receive send receive P0 P1 P2 send receive P0 P1 send half = 10 limit = 10 half = 5 limit = 5 half = 3 limit = 3 half = 2 limit = 2 P0 receive half = 1 Chapter 7 Multicores, Multiprocessors, and Clusters 26
27 Pros and Cons of Message Passing Message sending and receiving is much slower than addition But message passing multiprocessors are much easier for hardware designers to design Don t have to worry about cache coherency for example The advantage for programmers is that communication is explicit, so there are fewer performance surprises than with the implicit communication in cache-coherent SMPs. However, its harder to port a sequential program to a message passing multiprocessor since every communication must be identified in advance. With cache-coherent shared memory the hardware figures out what data needs to be communicated Chapter 7 Multicores, Multiprocessors, and Clusters 27
28 Grid Computing Separate computers interconnected by long-haul networks E.g., Internet connections Work units farmed out, results sent back Can make use of idle time on PCs E.g., World Community Grid Chapter 7 Multicores, Multiprocessors, and Clusters 28
29 Multithreading on a Chip Find a way to hide true data dependency stalls, cache miss stalls, and branch stalls by finding instructions (from other process threads) that are independent of those stalling instructions Hardware multithreading increase the utilization of resources on a chip by allowing multiple processes (threads) to share the functional units of a single processor Processor must duplicate the state hardware for each thread a separate register file, PC, instruction buffer, and store buffer for each thread The caches, TLBs, BHT, BTB, RUU can be shared (although the miss rates may increase if they are not sized accordingly) The memory can be shared through virtual memory mechanisms Hardware must support efficient thread context switching Chapter 7 Multicores, Multiprocessors, and Clusters 29
30 Types of Multithreading Fine-grain multithreading Switch threads after each cycle Interleave instruction execution If one thread stalls, others are executed Coarse-grain multithreading Only switch on long stall (e.g., L2-cache miss) Simplifies hardware, but doesn t hide short stalls (eg, data hazards) 7.5 Hardware Multithreading Chapter 7 Multicores, Multiprocessors, and Clusters 30
31 Simultaneous Multithreading (SMT) In multiple-issue dynamically scheduled processor Schedule instructions from multiple threads Instructions from independent threads execute when function units are available Within threads, dependencies handled by scheduling and register renaming Example: Intel Pentium-4 HyperThreading Two threads: duplicated registers, shared function units and caches Chapter 7 Multicores, Multiprocessors, and Clusters 31
32 Threading on a 4-way SS Processor Example Coarse MT (32 c.) Fine M (25 c.) SMT (14 c.) Issue slots Thread A Thread B Time Thread C Thread D Chapter 7 Multicores, Multiprocessors, and Clusters 32
33 Future of Multithreading Will it survive? In what form? Power considerations simplified microarchitectures Simpler forms of multithreading Tolerating cache-miss latency Thread switch may be most effective Multiple simple cores might share resources more effectively Chapter 7 Multicores, Multiprocessors, and Clusters 33
34 Instruction and Data Streams An alternate (Flynn) classification Instruction Streams Single Multiple Single SISD: Intel Pentium 4 MISD: No examples today Data Streams Multiple SIMD: SSE instructions of x86 MIMD: Intel Xeon e5345 SPMD: Single Program Multiple Data A single parallel program on a MIMD computer running across all processors 7.6 SISD, MIMD, SIMD, SPMD, and Vector Chapter 7 Multicores, Multiprocessors, and Clusters 34
35 SIMD Processors PE PE PE PE Control PE PE PE PE PE PE PE PE PE PE PE PE Single control unit (one copy of the code) Multiple datapaths (Processing Elements PEs) running in parallel Chapter 7 Multicores, Multiprocessors, and Clusters 35
36 SIMD Operate element wise on vectors of data E.g., MMX and SSE instructions in x86 Multiple data elements in 128-bit wide registers All processors execute the same instruction at the same time Each with different data address, etc. Simplifies synchronization Reduced instruction control hardware Works best for highly data-parallel applications Chapter 7 Multicores, Multiprocessors, and Clusters 36
37 Examples of SIMD Machines Maker Year # PEs # b/ PE Did SIMDs die out in the early 1990s? No, today they are everywhere! Max memory (MB) PE clock (MHz) System BW (MB/s) Illiac IV UIUC ,560 DAP ICL , ,560 MPP Goodyear , ,480 CM-2 Thinking Machines , ,384 MP-1216 MasPar , ,000 Chapter 7 Multicores, Multiprocessors, and Clusters 37
38 Vector Processors Highly pipelined function units Stream data from/to vector registers to units Data collected from memory into registers Results stored from registers to memory Example: Vector extension to MIPS element registers (64-bit elements) Vector instructions lv, sv: load/store vector addv.d: add vectors of double addvs.d: add scalar to each element of vector of double Significantly reduces instruction-fetch bandwidth Chapter 7 Multicores, Multiprocessors, and Clusters 38
39 Example: DAXPY (Y = a X + Y) Conventional MIPS code l.d $f0,a($sp) ;load scalar a addiu r4,$s0,#512 ;upper bound of what to load loop: l.d $f2,0($s0) ;load x(i) mul.d $f2,$f2,$f0 ;a x(i) l.d $f4,0($s1) ;load y(i) add.d $f4,$f4,$f2 ;a x(i) + y(i) s.d $f4,0($s1) ;store into y(i) addiu $s0,$s0,#8 ;increment index to x addiu $s1,$s1,#8 ;increment index to y subu $t0,r4,$s0 ;compute bound bne $t0,$zero,loop ;check if done Vector MIPS code l.d $f0,a($sp) ;load scalar a lv $v1,0($s0) ;load vector x mulvs.d $v2,$v1,$f0 ;vector-scalar multiply lv $v3,0($s1) ;load vector y addv.d $v4,$v2,$v3 ;add y to product sv $v4,0($s1) ;store the result Pipeline stalls once per vector operation, rather than once by vector element Chapter 7 Multicores, Multiprocessors, and Clusters 39
40 Vector vs. Scalar Vector architectures and compilers Simplify data-parallel programming Explicit statement of absence of loop-carried dependences Reduced checking in hardware Regular access patterns benefit from interleaved and burst memory Avoid control hazards by avoiding loops More general than ad-hoc media extensions (such as MMX, SSE) Better match with compiler technology Chapter 7 Multicores, Multiprocessors, and Clusters 40
41 Supercomputer Style Migration (Top500) Uniprocessors and SIMDs disappeared while Clusters and Constellations grew from 3% to 80%. Now its 98% Clusters and MPPs. 2010: 2 Constellations, 84 MPP, 414 Clusters Clusters Constellations SIMDs MPPs SMPs Uniproc's Cluster whole computers interconnected using their I/O bus Constellation a cluster that uses an SMP multiprocessor as the building block Chapter 7 Multicores, Multiprocessors, and Clusters 41



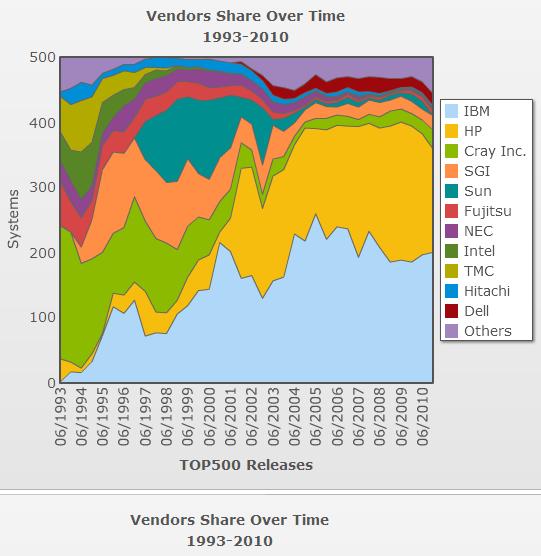
42 Top 500 Statistics / Charts / Development Chapter 7 Multicores, Multiprocessors, and Clusters 42
43 History of GPUs Early video cards Frame buffer memory with address generation for video output 3D graphics processing Originally high-end computers (e.g., SGI) Moore s Law lower cost, higher density 3D graphics cards for PCs and game consoles Graphics Processing Units Processors oriented to 3D graphics tasks Vertex/pixel processing, shading, texture mapping, rasterization 7.7 Introduction to Graphics Processing Units Chapter 7 Multicores, Multiprocessors, and Clusters 43


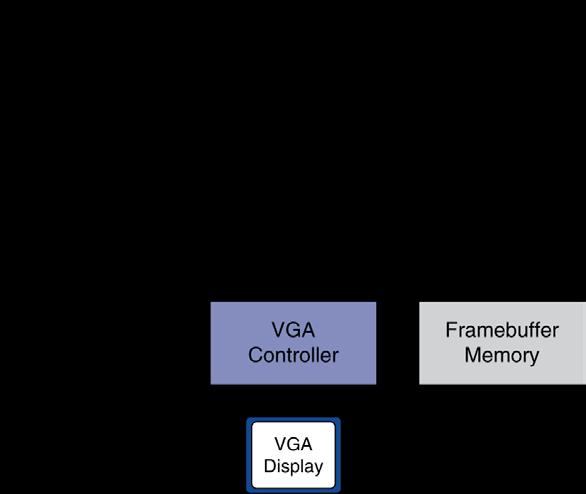
44 Graphics in the System Chapter 7 Multicores, Multiprocessors, and Clusters 44
45 GPU Architectures Processing is highly data-parallel GPUs are highly multithreaded Use thread switching to hide memory latency Less reliance on multi-level caches Graphics memory is wide and high-bandwidth Trend toward general purpose GPUs Heterogeneous CPU/GPU systems CPU for sequential code, GPU for parallel code Programming languages/apis DirectX, OpenGL C for Graphics (Cg), High Level Shader Language (HLSL) Compute Unified Device Architecture (CUDA) Chapter 7 Multicores, Multiprocessors, and Clusters 45


 2D Mesh")


46 Interconnection Networks Network topologies Arrangements of processors, switches, and links Bus Ring N-cube (N = 3) 2D Mesh Fully connected 7.8 Introduction to Multiprocessor Network Topologies Chapter 7 Multicores, Multiprocessors, and Clusters 46
47 Fat Trees Trees are good structures. People in CS use them all the time. Suppose we wanted to make a tree network. A B C D Any time A wants to send to C, it ties up the upper links, so that B can't send to D. The solution is to 'thicken' the upper links. Have more links as you work towards the root of the tree Chapter 7 Multicores, Multiprocessors, and Clusters 47
48 Network Characteristics Performance Latency per message (unloaded network) Throughput Link bandwidth Total network bandwidth (represents best case) bandwidth of each link * number of links Bisection bandwidth (closer to worst case) divide the machine in two parts, each with half the nodes and sum the bandwidth of the links that cross the dividing line Congestion delays (depending on traffic) Cost Power Routability in silicon (NoC) Chapter 7 Multicores, Multiprocessors, and Clusters 48
49 Parallel Benchmarks Linpack: matrix linear algebra SPECrate: parallel run of SPEC CPU programs Job-level parallelism SPLASH: Stanford Parallel Applications for Shared Memory Mix of kernels and applications, strong scaling NAS (NASA Advanced Supercomputing) suite computational fluid dynamics kernels PARSEC (Princeton Application Repository for Shared Memory Computers) suite Multithreaded applications using Pthreads and OpenMP 7.9 Multiprocessor Benchmarks Chapter 7 Multicores, Multiprocessors, and Clusters 49
50 Code or Applications? Traditional benchmarks Fixed code and data sets Parallel programming is evolving Should algorithms, programming languages, and tools be part of the system? Compare systems, provided they implement a given application E.g., Linpack, Berkeley Design Patterns Would foster innovation in approaches to parallelism Chapter 7 Multicores, Multiprocessors, and Clusters 50
51 Fallacies Amdahl s Law doesn t apply to parallel computers Since we can achieve linear speedup But only on applications with weak scaling Peak performance tracks observed performance Marketers like this approach! But compare Xeon with others in example Need to be aware of bottlenecks 7.12 Fallacies and Pitfalls Chapter 7 Multicores, Multiprocessors, and Clusters 51
52 Pitfalls Not developing the software to take account of a multiprocessor architecture Chapter 7 Multicores, Multiprocessors, and Clusters 52
53 Concluding Remarks Goal: higher performance by using multiple processors Difficulties Developing parallel software Devising appropriate architectures Many reasons for optimism Changing software and application environment Chip-level multiprocessors with lower latency, higher bandwidth interconnect An ongoing challenge for computer architects! 7.13 Concluding Remarks Chapter 7 Multicores, Multiprocessors, and Clusters 53
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Chapter 7. Multicores, Multiprocessors, and Clusters
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Chapter 7. Multicores, Multiprocessors, and
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher h performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher h performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Chapter 7. Multicores, Multiprocessors, and Clusters. Goal: connecting multiple computers to get higher performance
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
ELE 455/555 Computer System Engineering. Section 4 Parallel Processing Class 1 Challenges
 ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
Parallel computing and GPU introduction
 國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Vector Processing. Computer Organization Architectures for Embedded Computing. Friday, 13 December 13
 Vector Processing Computer Organization Architectures for Embedded Computing Friday, 13 December 13 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Vector Processing Computer Organization Architectures for Embedded Computing Friday, 13 December 13 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
5DV118 Computer Organization and Architecture Umeå University Department of Computing Science Stephen J. Hegner. Topic 7: Support for Parallelism
 5DV118 Computer Organization and Architecture Umeå University Department of Computing Science Stephen J. Hegner Topic 7: Support for Parallelism These slides are mostly taken verbatim, or with minor changes,
5DV118 Computer Organization and Architecture Umeå University Department of Computing Science Stephen J. Hegner Topic 7: Support for Parallelism These slides are mostly taken verbatim, or with minor changes,
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Chapter Seven. Idea: create powerful computers by connecting many smaller ones
 Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Mestrado em Informática
 Sistemas de Computação e Desempenho Arquitecturas Paralelas Mestrado em Informática 2010/11 A.J.Proença Tema Arquitecturas Paralelas (1) Estrutura do tema AP 1. A evolução das arquitecturas pelo paralelismo
Sistemas de Computação e Desempenho Arquitecturas Paralelas Mestrado em Informática 2010/11 A.J.Proença Tema Arquitecturas Paralelas (1) Estrutura do tema AP 1. A evolução das arquitecturas pelo paralelismo
CS 61C: Great Ideas in Computer Architecture. Amdahl s Law, Thread Level Parallelism
 CS 61C: Great Ideas in Computer Architecture Amdahl s Law, Thread Level Parallelism Instructor: Alan Christopher 07/17/2014 Summer 2014 -- Lecture #15 1 Review of Last Lecture Flynn Taxonomy of Parallel
CS 61C: Great Ideas in Computer Architecture Amdahl s Law, Thread Level Parallelism Instructor: Alan Christopher 07/17/2014 Summer 2014 -- Lecture #15 1 Review of Last Lecture Flynn Taxonomy of Parallel
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Advanced Computer Architecture
 Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.
 Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
An Introduction to Parallel Architectures
 An Introduction to Parallel Architectures Andrea Marongiu a.marongiu@unibo.it Impact of Parallel Architectures From cell phones to supercomputers In regular CPUs as well as GPUs Parallel HW Processing
An Introduction to Parallel Architectures Andrea Marongiu a.marongiu@unibo.it Impact of Parallel Architectures From cell phones to supercomputers In regular CPUs as well as GPUs Parallel HW Processing
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chapter 4 Data-Level Parallelism
 CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Intro to Multiprocessors
 The Big Picture: Where are We Now? Intro to Multiprocessors Output Output Datapath Input Input Datapath [dapted from Computer Organization and Design, Patterson & Hennessy, 2005] Multiprocessor multiple
The Big Picture: Where are We Now? Intro to Multiprocessors Output Output Datapath Input Input Datapath [dapted from Computer Organization and Design, Patterson & Hennessy, 2005] Multiprocessor multiple
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Parallel Processing. Computer Architecture. Computer Architecture. Outline. Multiple Processor Organization
 Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Static Compiler Optimization Techniques
 Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Computer Organization and Design, 5th Edition: The Hardware/Software Interface
 Computer Organization and Design, 5th Edition: The Hardware/Software Interface 1 Computer Abstractions and Technology 1.1 Introduction 1.2 Eight Great Ideas in Computer Architecture 1.3 Below Your Program
Computer Organization and Design, 5th Edition: The Hardware/Software Interface 1 Computer Abstractions and Technology 1.1 Introduction 1.2 Eight Great Ideas in Computer Architecture 1.3 Below Your Program
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Multicore and Parallel Processing
 Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
CS3350B Computer Architecture
 CS3350B Computer Architecture Winter 2015 Lecture 7.2: Multicore TLP (1) Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and Design, Patterson & Hennessy,
CS3350B Computer Architecture Winter 2015 Lecture 7.2: Multicore TLP (1) Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and Design, Patterson & Hennessy,
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. P & H Chapter 4.10, 1.7, 1.8, 5.10, 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Overview. Processor organizations Types of parallel machines. Real machines
 Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
Data-Level Parallelism in SIMD and Vector Architectures. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano
 Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
! An alternate classification. Introduction. ! Vector architectures (slides 5 to 18) ! SIMD & extensions (slides 19 to 23)
 ! SIMD & extensions (slides 19 to 23)") Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Chapter 18 Parallel Processing
 Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
CMSC 611: Advanced. Parallel Systems
 CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
Chapter 1. Introduction: Part I. Jens Saak Scientific Computing II 7/348
 Chapter 1 Introduction: Part I Jens Saak Scientific Computing II 7/348 Why Parallel Computing? 1. Problem size exceeds desktop capabilities. Jens Saak Scientific Computing II 8/348 Why Parallel Computing?
Chapter 1 Introduction: Part I Jens Saak Scientific Computing II 7/348 Why Parallel Computing? 1. Problem size exceeds desktop capabilities. Jens Saak Scientific Computing II 8/348 Why Parallel Computing?