Towards Building Large-Scale Multimodal Knowledge Bases
|
|
|
- Ruby Young
- 5 years ago
- Views:
Transcription
1 Towards Building Large-Scale Multimodal Knowledge Bases Dihong Gong Advised by Dr. Daisy Zhe Wang








2 Knowledge Itself is Power --Francis Bacon Analytics Social Robotics
 Represent relations between")
3 Knowledge Graph Nodes Represent entities in the world Directed Links (typed) Represent relations between entities
4 Given 1. A directed edge-typed graph GG 2. Relation RR x, yy 3. Source node ss Find A set of nodes TT in GG: each tt TT the relation RR ss, tt is true. Link Prediction A generic framework for knowledge expansion
 extract text knowledge from web.")
: initial seeds => training")
5 Related Work (AAAI 2015) NELL: Text Knowledge Miner Tasks: (1) extract text knowledge from web. (2) focused on link prediction with type is-a. Learning iteratively (24x7): initial seeds => training extractors => extract instances => repeat

6 Related Work (ICCV 2013) NEIL: Image Knowledge Miner
")

7 Related Work (ArXiv 2015) Multimodal Knowledge as a Factor Graph
8 Proposed Multimodal Framework Multimodal Knowledge Graph Nodes Represent entities in the world Entities are multimodal: text, image, audio Directed Links (typed) Represent relations between entities Relations link entities within & across modalities



9 Proposed Multimodal Framework Example Sea Scenery castle Island sunset Nodes image text visual-concept: textual-concept Maui Edge Types is-a has-visual-object meta-of has-tag co-locate-with Beach sky Building
10 Multimodal Link Prediction Physical Links The links that represent physical relations between nodes. These links are directly accessible (e.g. by document parsing) without further logical reasoning. Examples: co-locate-with, has-tag, meta-of, etc. Logical Links The links that represent logical relations between nodes. These links are obtained by logical reasoning, or link prediction. Examples: is-a (text), has-visual-object (image).
11 Why is Multimodal Appealing? 1. Encode relations between multimodal objects. Visual question answering (VQA). Complicated scene understanding, e.g. autonomous driving. 2. Multimodal information is complementary. Information from different independent sources complement each other. 3. Multimodal information is correlated. Information tends to correlate, which provides additional redundancy for better robustness.
12 Contributions Multimodal Named Entity Recognition (MNER) Utilize visual relations in the multimodal knowledge graph for enhanced text is-a link prediction. D. Gong, D. Wang, Y. Peng, Multimodal Learning for Web Information Extraction, ACM Multimedia, (Rank A+ conference) Visual Text-Assisted Knowledge Extraction (VTAKE) Employ textual relations to improve precision of has-visual-object link prediction. D. Gong, D. Wang, Extracting Visual Knowledge from the Web with Multimodal Learning, IJCAI, (Rank A+ conference) Multimodal Convolutional Neural Network (MCNN) Improve from VTAKE, by a unified end-to-end CNN model, for has-visual-object link prediction. D. Gong, D. Wang, Multimodal Convolutional Neural Networks for Visual Knowledge Extraction, AAAI, (Under review)
13 MNER Goal: extract text instances of predefined categories (e.g. predicting is-a links). Textual Rules Companies such as _ _ is river Visual Rules acura->car->automobilemaker adam_sandler->person>director
14 Overview Three Stages 1. Multimodal Relation Analysis 2. Learn Multimodal Rules 3. Multimodal Information Extraction

15 Stage #1: Multimodal Relation Analysis Relations: 1. Vehicle Bus 2. Vehicle Warplane 3. Vehicle Truck
16 Stage #2: Learn Multimodal Rules Rules Template: Rules Measurement: Example Visual Rules
17 Stage #3: Multimodal Information Extraction Ranking

18
19 500M English web pages. 20M images with title, name and alt meta information. 42 text categories, with each category having 15 seed instances. Evaluation 116 image categories, with each category having 250 seed instances.
20 Results Comparative Approaches CPL: Coupled Pattern Learner (text-only) CPL-NMF: Fuse CPL score with visual score in a naive manner Observations Based on the testing categories, the proposed approach outperforms the text-only CPL by clear margin. However, for categories that do not have stable visual correspondence, the improvement is not significant. It remains a challenge to generalize the approach to general categories.
21 Significantly Improved (>10%) Vehicle (+16%): bus(0.70,0.20), warplane(0.27,0.20), car(0.11,0.4) Fish (+12%): striped_bass(0.55,0.36), game_fish(0.48,0.21), salmon(0.32,0.43) Bird (+13%): wading_bird(0.65,0.20), crane(0.21,0.16), insect(0.10,0.07) Fairly Improved (<5%) Governmentorganization (3%): government_building(0.20,0.33) Coach (+3%): player(0.12,0.2), man s clothing(0.08,0.64) Athlete (2%): player(0.18,0.53), people(0.06,0.25), man s clothing(0.03,0.41) Declined Drug (-2%): mouse(0.06,0.08) City (-4%): window(0.09,0.17), sky(0.06,0.15), people(0.01,0.35) Ceo (-1%): sunglasses(0.04,0.25), civilian_clothing(0.02,0.31), man s_clothing(0.01,0.43) Example Visual Rules

22 VTAKE Goal: extract object bounding boxes from web images (e.g. predicting has-visual-object links). Challenge As of 2016, the best visual object detection programs on ImageNet challenge has 66% mean average precision (200 categories).
23 Traditional Approaches vs. Our Approach
24 Overview
25 Multimodal Embedding: Skip-Gram Model Learn vector representation of multimodal objects, by maximizing probability of predicting nearby words: e.g. {person, dog(v), chair, girl, dog(t), room} should predicts each other. Thus, their vector representation is closed to each other.
26 Learning Sparse Logistic Regression Model Train one model per image category. Training data: all image instances that detect objects in category C are positive samples, and the rest are negative samples. Sparsity: efficiently suppress unrelated multimodal words. Maximize:
![Evaluation Metric #relevant(sk,c) => #samples in Sk that are relevant to image category [c].](/docs-images/81/84219540/images/27-0.jpg "card(sk) := 1,000 We estimate #relevant(sk,c) by randomly sampling 100 images which are reviewed by")
27 Evaluation Metric #relevant(sk,c) => #samples in Sk that are relevant to image category [c]. card(sk) := 1,000 We estimate #relevant(sk,c) by randomly sampling 100 images which are reviewed by human judges.

28 Results #objects Image Only Proposed

29 Extraction Examples 29
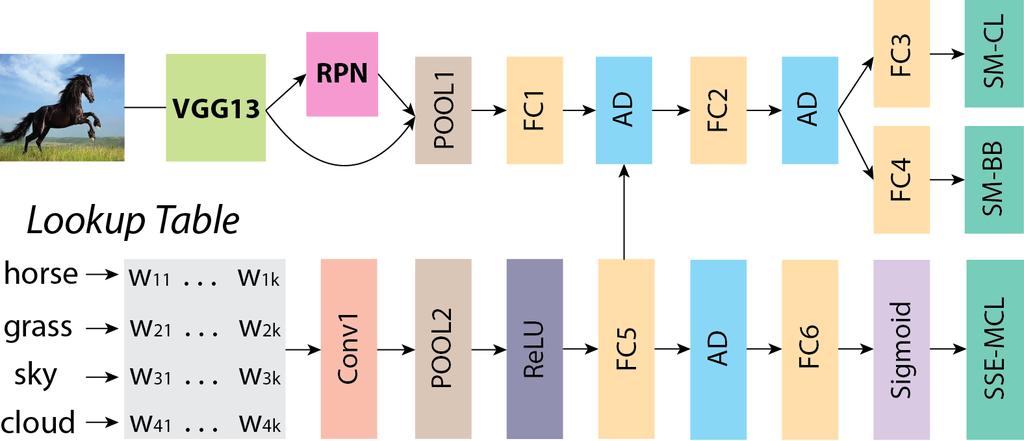
30 MCNN
31 MCNN vs. VTAKE MCNN has two subnets: text CNN and image CNN. MCNN is end-toend trainable & predictable. MCNN fuses at feature level, while VTAKE at prediction level.

32 Evaluation Results

33 Illustrative Comparison
34 Summary Future Work We present a multimodal knowledge graph. We propose three different approaches to utilize multimodal information for knowledge expansion with multimodal link prediction. Based on our current knowledge graph, with limited relations, extract richer knowledge by defining and predicting new multimodal links. Further improve link prediction precision by utilizing richer multimodal links. Summary & Future Work
35 References Karpathy, Andrej, and Li Fei-Fei. "Deep visual-semantic alignments for generating image descriptions." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Zhu, Yuke, and Li Fei-Fei. "Building a large-scale multimodal knowledge base system for answering visual queries." arxiv preprint arxiv: (2015). Antol, Stanislaw, et al. "Vqa: Visual question answering." Proceedings of the IEEE International Conference on Computer Vision Mitchell, T. M., Cohen, W. W., Hruschka Jr, E. R., Talukdar, P. P., Betteridge, J., Carlson, A.,... & Lao, N. (2015, January). Never Ending Learning. In AAAI (pp ). Chen, Xinlei, Abhinav Shrivastava, and Abhinav Gupta. "Neil: Extracting visual knowledge from web data." Proceedings of the IEEE International Conference on Computer Vision
Semantic image search using queries
 Semantic image search using queries Shabaz Basheer Patel, Anand Sampat Department of Electrical Engineering Stanford University CA 94305 shabaz@stanford.edu,asampat@stanford.edu Abstract Previous work,
Semantic image search using queries Shabaz Basheer Patel, Anand Sampat Department of Electrical Engineering Stanford University CA 94305 shabaz@stanford.edu,asampat@stanford.edu Abstract Previous work,
Learning to Match. Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li
 Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Novel Image Captioning
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Learning Semantic Video Captioning using Data Generated with Grand Theft Auto
 A dark car is turning left on an exit Learning Semantic Video Captioning using Data Generated with Grand Theft Auto Alex Polis Polichroniadis Data Scientist, MSc Kolia Sadeghi Applied Mathematician, PhD
A dark car is turning left on an exit Learning Semantic Video Captioning using Data Generated with Grand Theft Auto Alex Polis Polichroniadis Data Scientist, MSc Kolia Sadeghi Applied Mathematician, PhD
16-785: Integrated Intelligence in Robotics: Vision, Language, and Planning. Spring 2018 Lecture 14. Image to Text
 16-785: Integrated Intelligence in Robotics: Vision, Language, and Planning Spring 2018 Lecture 14. Image to Text Input Output Classification tasks 4/1/18 CMU 16-785: Integrated Intelligence in Robotics
16-785: Integrated Intelligence in Robotics: Vision, Language, and Planning Spring 2018 Lecture 14. Image to Text Input Output Classification tasks 4/1/18 CMU 16-785: Integrated Intelligence in Robotics
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Multimodal Learning. Victoria Dean. MIT 6.S191 Intro to Deep Learning IAP 2017
 Multimodal Learning Victoria Dean Talk outline What is multimodal learning and what are the challenges? Flickr example: joint learning of images and tags Image captioning: generating sentences from images
Multimodal Learning Victoria Dean Talk outline What is multimodal learning and what are the challenges? Flickr example: joint learning of images and tags Image captioning: generating sentences from images
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
Grounded Compositional Semantics for Finding and Describing Images with Sentences
 Grounded Compositional Semantics for Finding and Describing Images with Sentences R. Socher, A. Karpathy, V. Le,D. Manning, A Y. Ng - 2013 Ali Gharaee 1 Alireza Keshavarzi 2 1 Department of Computational
Grounded Compositional Semantics for Finding and Describing Images with Sentences R. Socher, A. Karpathy, V. Le,D. Manning, A Y. Ng - 2013 Ali Gharaee 1 Alireza Keshavarzi 2 1 Department of Computational
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
with Deep Learning A Review of Person Re-identification Xi Li College of Computer Science, Zhejiang University
 A Review of Person Re-identification with Deep Learning Xi Li College of Computer Science, Zhejiang University http://mypage.zju.edu.cn/xilics Email: xilizju@zju.edu.cn Person Re-identification Associate
A Review of Person Re-identification with Deep Learning Xi Li College of Computer Science, Zhejiang University http://mypage.zju.edu.cn/xilics Email: xilizju@zju.edu.cn Person Re-identification Associate
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Image-Sentence Multimodal Embedding with Instructive Objectives
 Image-Sentence Multimodal Embedding with Instructive Objectives Jianhao Wang Shunyu Yao IIIS, Tsinghua University {jh-wang15, yao-sy15}@mails.tsinghua.edu.cn Abstract To encode images and sentences into
Image-Sentence Multimodal Embedding with Instructive Objectives Jianhao Wang Shunyu Yao IIIS, Tsinghua University {jh-wang15, yao-sy15}@mails.tsinghua.edu.cn Abstract To encode images and sentences into
Computer vision: teaching computers to see
 Computer vision: teaching computers to see Mats Sjöberg Department of Computer Science Aalto University mats.sjoberg@aalto.fi Turku.AI meetup June 5, 2018 Computer vision Giving computers the ability to
Computer vision: teaching computers to see Mats Sjöberg Department of Computer Science Aalto University mats.sjoberg@aalto.fi Turku.AI meetup June 5, 2018 Computer vision Giving computers the ability to
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Robust Face Recognition Based on Convolutional Neural Network
 2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2 Robust Face Recognition Based on Convolutional Neural Network Ying Xu, Hui Ma,
2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2 Robust Face Recognition Based on Convolutional Neural Network Ying Xu, Hui Ma,
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Extracting Visual Knowledge from the Web with Multimodal Learning
 Extracting Visual Knowledge from the Web with Multimodal Learning Dihong Gong, Daisy Zhe Wang Department of Computer and Information Science and Engineering University of Florida {gongd, daisyw}@ufl.edu
Extracting Visual Knowledge from the Web with Multimodal Learning Dihong Gong, Daisy Zhe Wang Department of Computer and Information Science and Engineering University of Florida {gongd, daisyw}@ufl.edu
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Random Walk Inference and Learning. Carnegie Mellon University 7/28/2011 EMNLP 2011, Edinburgh, Scotland, UK
 Random Walk Inference and Learning in A Large Scale Knowledge Base Ni Lao, Tom Mitchell, William W. Cohen Carnegie Mellon University 2011.7.28 1 Outline Motivation Inference in Knowledge Bases The NELL
Random Walk Inference and Learning in A Large Scale Knowledge Base Ni Lao, Tom Mitchell, William W. Cohen Carnegie Mellon University 2011.7.28 1 Outline Motivation Inference in Knowledge Bases The NELL
CS5670: Computer Vision
 CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
Computer Vision: Making machines see
 Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
arxiv: v1 [cs.mm] 12 Jan 2016
![arxiv: v1 [cs.mm] 12 Jan 2016](/thumbs/73/69424856.jpg "arxiv: v1 [cs.mm] 12 Jan 2016") Learning Subclass Representations for Visually-varied Image Classification Xinchao Li, Peng Xu, Yue Shi, Martha Larson, Alan Hanjalic Multimedia Information Retrieval Lab, Delft University of Technology
Learning Subclass Representations for Visually-varied Image Classification Xinchao Li, Peng Xu, Yue Shi, Martha Larson, Alan Hanjalic Multimedia Information Retrieval Lab, Delft University of Technology
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Structure-oriented Networks of Shape Collections
 Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong Feb 04, 2016 Today Administrivia Attention Modeling in Image Captioning, by Karan Neural networks & Backpropagation
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong Feb 04, 2016 Today Administrivia Attention Modeling in Image Captioning, by Karan Neural networks & Backpropagation
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
 Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction by Noh, Hyeonwoo, Paul Hongsuck Seo, and Bohyung Han.[1] Presented : Badri Patro 1 1 Computer Vision Reading
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction by Noh, Hyeonwoo, Paul Hongsuck Seo, and Bohyung Han.[1] Presented : Badri Patro 1 1 Computer Vision Reading
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Deep Learning. Deep Learning. Practical Application Automatically Adding Sounds To Silent Movies
 http://blog.csdn.net/zouxy09/article/details/8775360 Automatic Colorization of Black and White Images Automatically Adding Sounds To Silent Movies Traditionally this was done by hand with human effort
http://blog.csdn.net/zouxy09/article/details/8775360 Automatic Colorization of Black and White Images Automatically Adding Sounds To Silent Movies Traditionally this was done by hand with human effort
Introduction to object recognition. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others
 Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
From 3D descriptors to monocular 6D pose: what have we learned?
 ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
Instance Retrieval at Fine-grained Level Using Multi-Attribute Recognition
 Instance Retrieval at Fine-grained Level Using Multi-Attribute Recognition Roshanak Zakizadeh, Yu Qian, Michele Sasdelli and Eduard Vazquez Cortexica Vision Systems Limited, London, UK Australian Institute
Instance Retrieval at Fine-grained Level Using Multi-Attribute Recognition Roshanak Zakizadeh, Yu Qian, Michele Sasdelli and Eduard Vazquez Cortexica Vision Systems Limited, London, UK Australian Institute
Exploiting noisy web data for largescale visual recognition
 Exploiting noisy web data for largescale visual recognition Lamberto Ballan University of Padova, Italy CVPRW WebVision - Jul 26, 2017 Datasets drive computer vision progress ImageNet Slide credit: O.
Exploiting noisy web data for largescale visual recognition Lamberto Ballan University of Padova, Italy CVPRW WebVision - Jul 26, 2017 Datasets drive computer vision progress ImageNet Slide credit: O.
arxiv:submit/ [cs.cv] 13 Jan 2018
![arxiv:submit/ [cs.cv] 13 Jan 2018](/thumbs/91/104718543.jpg "arxiv:submit/ [cs.cv] 13 Jan 2018") Benchmark Visual Question Answer Models by using Focus Map Wenda Qiu Yueyang Xianzang Zhekai Zhang Shanghai Jiaotong University arxiv:submit/2130661 [cs.cv] 13 Jan 2018 Abstract Inferring and Executing
Benchmark Visual Question Answer Models by using Focus Map Wenda Qiu Yueyang Xianzang Zhekai Zhang Shanghai Jiaotong University arxiv:submit/2130661 [cs.cv] 13 Jan 2018 Abstract Inferring and Executing
LSTM for Language Translation and Image Captioning. Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia
 1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation. Deepak Pathak, Philipp Krähenbühl and Trevor Darrell
 Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
SocialML: machine learning for social media video creators
 SocialML: machine learning for social media video creators Tomasz Trzcinski a,b, Adam Bielski b, Pawel Cyrta b and Matthew Zak b a Warsaw University of Technology b Tooploox firstname.lastname@tooploox.com
SocialML: machine learning for social media video creators Tomasz Trzcinski a,b, Adam Bielski b, Pawel Cyrta b and Matthew Zak b a Warsaw University of Technology b Tooploox firstname.lastname@tooploox.com
VISION & LANGUAGE From Captions to Visual Concepts and Back
 VISION & LANGUAGE From Captions to Visual Concepts and Back Brady Fowler & Kerry Jones Tuesday, February 28th 2017 CS 6501-004 VICENTE Agenda Problem Domain Object Detection Language Generation Sentence
VISION & LANGUAGE From Captions to Visual Concepts and Back Brady Fowler & Kerry Jones Tuesday, February 28th 2017 CS 6501-004 VICENTE Agenda Problem Domain Object Detection Language Generation Sentence
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Apparel Classifier and Recommender using Deep Learning
 Apparel Classifier and Recommender using Deep Learning Live Demo at: http://saurabhg.me/projects/tag-that-apparel Saurabh Gupta sag043@ucsd.edu Siddhartha Agarwal siagarwa@ucsd.edu Apoorve Dave a1dave@ucsd.edu
Apparel Classifier and Recommender using Deep Learning Live Demo at: http://saurabhg.me/projects/tag-that-apparel Saurabh Gupta sag043@ucsd.edu Siddhartha Agarwal siagarwa@ucsd.edu Apoorve Dave a1dave@ucsd.edu
Object and Action Detection from a Single Example
 Object and Action Detection from a Single Example Peyman Milanfar* EE Department University of California, Santa Cruz *Joint work with Hae Jong Seo AFOSR Program Review, June 4-5, 29 Take a look at this:
Object and Action Detection from a Single Example Peyman Milanfar* EE Department University of California, Santa Cruz *Joint work with Hae Jong Seo AFOSR Program Review, June 4-5, 29 Take a look at this:
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Faceted Navigation for Browsing Large Video Collection
 Faceted Navigation for Browsing Large Video Collection Zhenxing Zhang, Wei Li, Cathal Gurrin, Alan F. Smeaton Insight Centre for Data Analytics School of Computing, Dublin City University Glasnevin, Co.
Faceted Navigation for Browsing Large Video Collection Zhenxing Zhang, Wei Li, Cathal Gurrin, Alan F. Smeaton Insight Centre for Data Analytics School of Computing, Dublin City University Glasnevin, Co.
Visual Query Suggestion
 Visual Query Suggestion Zheng-Jun Zha, Linjun Yang, Tao Mei, Meng Wang, Zengfu Wang University of Science and Technology of China Textual Visual Query Suggestion Microsoft Research Asia Motivation Framework
Visual Query Suggestion Zheng-Jun Zha, Linjun Yang, Tao Mei, Meng Wang, Zengfu Wang University of Science and Technology of China Textual Visual Query Suggestion Microsoft Research Asia Motivation Framework
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Multimodal Information Spaces for Content-based Image Retrieval
 Research Proposal Multimodal Information Spaces for Content-based Image Retrieval Abstract Currently, image retrieval by content is a research problem of great interest in academia and the industry, due
Research Proposal Multimodal Information Spaces for Content-based Image Retrieval Abstract Currently, image retrieval by content is a research problem of great interest in academia and the industry, due
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
MULTIMODAL SEMI-SUPERVISED IMAGE CLASSIFICATION BY COMBINING TAG REFINEMENT, GRAPH-BASED LEARNING AND SUPPORT VECTOR REGRESSION
 MULTIMODAL SEMI-SUPERVISED IMAGE CLASSIFICATION BY COMBINING TAG REFINEMENT, GRAPH-BASED LEARNING AND SUPPORT VECTOR REGRESSION Wenxuan Xie, Zhiwu Lu, Yuxin Peng and Jianguo Xiao Institute of Computer
MULTIMODAL SEMI-SUPERVISED IMAGE CLASSIFICATION BY COMBINING TAG REFINEMENT, GRAPH-BASED LEARNING AND SUPPORT VECTOR REGRESSION Wenxuan Xie, Zhiwu Lu, Yuxin Peng and Jianguo Xiao Institute of Computer
Towards Large-Scale Semantic Representations for Actionable Exploitation. Prof. Trevor Darrell UC Berkeley
 Towards Large-Scale Semantic Representations for Actionable Exploitation Prof. Trevor Darrell UC Berkeley traditional surveillance sensor emerging crowd sensor Desired capabilities: spatio-temporal reconstruction
Towards Large-Scale Semantic Representations for Actionable Exploitation Prof. Trevor Darrell UC Berkeley traditional surveillance sensor emerging crowd sensor Desired capabilities: spatio-temporal reconstruction
Word2vec and beyond. presented by Eleni Triantafillou. March 1, 2016
 Word2vec and beyond presented by Eleni Triantafillou March 1, 2016 The Big Picture There is a long history of word representations Techniques from information retrieval: Latent Semantic Analysis (LSA)
Word2vec and beyond presented by Eleni Triantafillou March 1, 2016 The Big Picture There is a long history of word representations Techniques from information retrieval: Latent Semantic Analysis (LSA)
Internet of things that video
 Video recognition from a sentence Cees Snoek Intelligent Sensory Information Systems Lab University of Amsterdam The Netherlands Internet of things that video 45 billion cameras by 2022 [LDV Capital] 2
Video recognition from a sentence Cees Snoek Intelligent Sensory Information Systems Lab University of Amsterdam The Netherlands Internet of things that video 45 billion cameras by 2022 [LDV Capital] 2
Building the Software 2.0 Stack. Andrej Karpathy May 10, 2018
 Building the Software 2.0 Stack Andrej Karpathy May 10, 2018 1M years ago Engineering: approach by decomposition AWS stack 1. Identify a problem 2. Break down a big problem to smaller problems 3.
Building the Software 2.0 Stack Andrej Karpathy May 10, 2018 1M years ago Engineering: approach by decomposition AWS stack 1. Identify a problem 2. Break down a big problem to smaller problems 3.
MULTI-VIEW FEATURE FUSION NETWORK FOR VEHICLE RE- IDENTIFICATION
 MULTI-VIEW FEATURE FUSION NETWORK FOR VEHICLE RE- IDENTIFICATION Haoran Wu, Dong Li, Yucan Zhou, and Qinghua Hu School of Computer Science and Technology, Tianjin University, Tianjin, China ABSTRACT Identifying
MULTI-VIEW FEATURE FUSION NETWORK FOR VEHICLE RE- IDENTIFICATION Haoran Wu, Dong Li, Yucan Zhou, and Qinghua Hu School of Computer Science and Technology, Tianjin University, Tianjin, China ABSTRACT Identifying
Online Cross-Modal Hashing for Web Image Retrieval
 Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-6) Online Cross-Modal Hashing for Web Image Retrieval Liang ie Department of Mathematics Wuhan University of Technology, China
Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-6) Online Cross-Modal Hashing for Web Image Retrieval Liang ie Department of Mathematics Wuhan University of Technology, China
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
arxiv: v1 [cs.cv] 2 Sep 2018
![arxiv: v1 [cs.cv] 2 Sep 2018](/thumbs/85/92128474.jpg "arxiv: v1 [cs.cv] 2 Sep 2018") Natural Language Person Search Using Deep Reinforcement Learning Ankit Shah Language Technologies Institute Carnegie Mellon University aps1@andrew.cmu.edu Tyler Vuong Electrical and Computer Engineering
Natural Language Person Search Using Deep Reinforcement Learning Ankit Shah Language Technologies Institute Carnegie Mellon University aps1@andrew.cmu.edu Tyler Vuong Electrical and Computer Engineering
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Semi-supervised Data Representation via Affinity Graph Learning
 1 Semi-supervised Data Representation via Affinity Graph Learning Weiya Ren 1 1 College of Information System and Management, National University of Defense Technology, Changsha, Hunan, P.R China, 410073
1 Semi-supervised Data Representation via Affinity Graph Learning Weiya Ren 1 1 College of Information System and Management, National University of Defense Technology, Changsha, Hunan, P.R China, 410073
Target-driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Zhu et al. 2017]
![Target-driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Zhu et al. 2017]](/thumbs/94/122265679.jpg "Target-driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Zhu et al. 2017]") REINFORCEMENT LEARNING FOR ROBOTICS Target-driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Zhu et al. 2017] A. James E. Cagalawan james.cagalawan@gmail.com University of Waterloo
REINFORCEMENT LEARNING FOR ROBOTICS Target-driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Zhu et al. 2017] A. James E. Cagalawan james.cagalawan@gmail.com University of Waterloo
Graph-based Techniques for Searching Large-Scale Noisy Multimedia Data
 Graph-based Techniques for Searching Large-Scale Noisy Multimedia Data Shih-Fu Chang Department of Electrical Engineering Department of Computer Science Columbia University Joint work with Jun Wang (IBM),
Graph-based Techniques for Searching Large-Scale Noisy Multimedia Data Shih-Fu Chang Department of Electrical Engineering Department of Computer Science Columbia University Joint work with Jun Wang (IBM),
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Using Maximum Entropy for Automatic Image Annotation
 Using Maximum Entropy for Automatic Image Annotation Jiwoon Jeon and R. Manmatha Center for Intelligent Information Retrieval Computer Science Department University of Massachusetts Amherst Amherst, MA-01003.
Using Maximum Entropy for Automatic Image Annotation Jiwoon Jeon and R. Manmatha Center for Intelligent Information Retrieval Computer Science Department University of Massachusetts Amherst Amherst, MA-01003.
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Deep Learning for Virtual Shopping. Dr. Jürgen Sturm Group Leader RGB-D
 Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
Machine Learning Concepts for Adaptive Video Streaming Systems (SS17)
") Machine Learning Concepts for Adaptive Video Streaming Systems (SS17) Kickoff Denny Stohr, M.Sc. Jeremias Blendin Prof. Dr.-Ing. Wolfgang Effelsberg www.dms.informatik.tu-darmstadt.de 21.04.17 Department
Machine Learning Concepts for Adaptive Video Streaming Systems (SS17) Kickoff Denny Stohr, M.Sc. Jeremias Blendin Prof. Dr.-Ing. Wolfgang Effelsberg www.dms.informatik.tu-darmstadt.de 21.04.17 Department
Using Machine Learning for Classification of Cancer Cells
 Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS
 AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS Nilam B. Lonkar 1, Dinesh B. Hanchate 2 Student of Computer Engineering, Pune University VPKBIET, Baramati, India Computer Engineering, Pune University VPKBIET,
AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS Nilam B. Lonkar 1, Dinesh B. Hanchate 2 Student of Computer Engineering, Pune University VPKBIET, Baramati, India Computer Engineering, Pune University VPKBIET,
CSE 258. Web Mining and Recommender Systems. Advanced Recommender Systems
 CSE 258 Web Mining and Recommender Systems Advanced Recommender Systems This week Methodological papers Bayesian Personalized Ranking Factorizing Personalized Markov Chains Personalized Ranking Metric
CSE 258 Web Mining and Recommender Systems Advanced Recommender Systems This week Methodological papers Bayesian Personalized Ranking Factorizing Personalized Markov Chains Personalized Ranking Metric
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Transfer Learning. Style Transfer in Deep Learning
 Transfer Learning & Style Transfer in Deep Learning 4-DEC-2016 Gal Barzilai, Ram Machlev Deep Learning Seminar School of Electrical Engineering Tel Aviv University Part 1: Transfer Learning in Deep Learning
Transfer Learning & Style Transfer in Deep Learning 4-DEC-2016 Gal Barzilai, Ram Machlev Deep Learning Seminar School of Electrical Engineering Tel Aviv University Part 1: Transfer Learning in Deep Learning
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition
 Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2013) Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan,
Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2013) Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan,
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
A Study of MatchPyramid Models on Ad hoc Retrieval
 A Study of MatchPyramid Models on Ad hoc Retrieval Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Xueqi Cheng Institute of Computing Technology, Chinese Academy of Sciences Text Matching Many text based
A Study of MatchPyramid Models on Ad hoc Retrieval Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Xueqi Cheng Institute of Computing Technology, Chinese Academy of Sciences Text Matching Many text based
arxiv: v1 [cs.cv] 13 Jan 2019
![arxiv: v1 [cs.cv] 13 Jan 2019](/thumbs/93/113760929.jpg "arxiv: v1 [cs.cv] 13 Jan 2019") Auto-Retoucher(ART) A Framework for Background Replacement and Foreground Adjustment Yunxuan Xiao, Yikai Li, Yuwei Wu, Lizhen Zhu Shanghai Jiao Tong University 8 Dongchuan RD. Shanghai, China {xiaoyunxuan,
Auto-Retoucher(ART) A Framework for Background Replacement and Foreground Adjustment Yunxuan Xiao, Yikai Li, Yuwei Wu, Lizhen Zhu Shanghai Jiao Tong University 8 Dongchuan RD. Shanghai, China {xiaoyunxuan,
Slides credited from Dr. David Silver & Hung-Yi Lee
 Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to