Session 1 Big Data and Hadoop - Overview. - Dr. M. R. Sanghavi
|
|
|
- Ashley Clarke
- 6 years ago
- Views:
Transcription
1 Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi
2 Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog

3 Big Data & Hadoop
4 Topics
5 What is Data? Distinct pieces of information, usually formatted in a special way. Data can exist in a variety of forms -- as numbers or text on pieces of paper, as bits and bytes stored in electronic memory, or as facts stored in a person's mind.
6 Data Management Data storage Local Place Ex. Company/ Colleges/ Hospitals Security / Size Central Storage Place - Datacenters Older Practices Pay for space Pay for Disk In case of Disaster Local Disk Tape Drives SAN / NAS
7 Data Management 1 Kilobyte 1,000 bits/byte 1 Megabyte 1,000,000 1 Gigabyte 1,000,000,000 1 Terabyte 1,000,000,000,000 1 Petabyte 1,000,000,000,000,000 1 Exabyte 1,000,000,000,000,000,000 1 Zettabyte 1,000,000,000,000,000,000,000

8 What is Bigdata? No single standard definition Big Data is data whose scale, diversity, and complexity require new architecture, techniques, algorithms, and analytics to manage it and extract value and hidden knowledge from it







9 Big Data : unstructured, structured, streaming Website Social Media Billing ERP CRM RFID Network Switches


























10 200+ Customer Stories Finance & Insurance Academic & Gov t Healthcare & Life Sciences Digital Media & Retail Manufacturing & High Tech 10

11 Number of Attendees




12 V3 Architecture
13 Existing challenges
14 Requirements Scalability Flexibility Fault Tolerance Resource Management Security Single System Easy to use




15 HADOOP IS THE SOLUTION

16

17 Hadoop? Hadoop is an open source software project that enables the distributed processing of large data sets across clusters of commodity servers. It is designed to scale up from a single server to thousands of machines, with a very high degree of fault tolerance. Hadoop enables a computing solution Scalable Cost Effective Flexible Fault Tolerance
18 Products developed by vendors Apache Origin Cloudera Hortonworks Intel
19 Hadoop supported platforms Platforms: Unix and on Windows Linux: the only supported production platform. Other variants of Unix, like Mac OS X: run Hadoop for development. Windows + Cygwin: development platform (openssh)
20 Hadoop Components HDFS Mapreduce
21 Hadoop installation modes Standalone (or local) mode : Hadoop Is not installed, but libraries of hadoop are used. Similar to emulator Pseudo-distributed mode : Single node cluster i.e installing hadoop on one machine Fully distributed mode : Here namenode, datanode & secondary namenode appear on one machine and the jobtracker and tasketracker are on other machines

22 Standalone / LocalJobRunner Mode In LocalJobRunner mode, no daemons run Everything runs in a single Java Virtual Machine (JVM) Hadoop uses the machine s standard filesystem for data storage Not HDFS Suitable for testing MapReduce programs during development
 Useful to simulate a cluster on a single machine Convenient for debugging programs before launching them on the real")
23 Pseudo-Distributed Mode In pseudo-distributed mode, all daemons run on the local machine Each runs in its own JVM (Java Virtual Machine) Hadoop uses HDFS to store data (by default) Useful to simulate a cluster on a single machine Convenient for debugging programs before launching them on the real cluster
, the NameNode and JobTracker should each be running on dedicated nodes For small clusters, it s acceptable for both to run on the same")
24 Fully-Distributed Mode In fully-distributed mode, Hadoop daemons run on a cluster of machines HDFS used to distribute data amongst the nodes Unless you are running a small cluster (less than 10 or 20 nodes), the NameNode and JobTracker should each be running on dedicated nodes For small clusters, it s acceptable for both to run on the same physical node

![File System] Mapreduce](/docs-images/79/78973942/images/25-2.jpg "[Parallel Distributed")
25 Hadoop Core omponents HDFS [Hadoop Distributed File System] Mapreduce [Parallel Distributed Platform]


26 HDFS Daemons Namenode Secondary Namenode Datanodes



27 HDFS Architecture Overview Host 1 Namenode Master Host 3 DataNode/Slaves Host 5 DataNode/Slaves Host 2 Secondary NN/Master Host 4 DataNode/Slaves Host n DataNode/Slaves 27
28 HDFS Block Diagram Datanode 1 Datanode 2 Namenode Datanode 3 Datanode 4 Datanode N Secondary Namenode

29 HDFS Features


30 HDFS Block Replication Block Size = 64MB/128 Replication Factor = 3 Blocks HDFS Datanode Datanode Datanode Datanode 2 Datanode 5
31 Namenode (Master node) The NameNode stores all metadata Information about file locations in HDFS Information about file ownership and permissions Names of the individual blocks Locations of the blocks Metadata is stored on disk and read when the NameNode daemon starts up Filename is fsimage When changes to the metadata are required, these are made in RAM Changes are also written to a log file on disk called edits




32 Secondary Namenode / checkpoint node fsimage Latest snapshot of filesystem to which namenode refers Edit logs - changes made to the filesystem after namenode started Namenode fsimage 7 3 Secondary Namenode edit logs are applied to fsimage to get the latest snapshot of the file system on NN restart 1 7 Rare restart of NN in production. Edits will grow larger The following issues we will encounter Editlog become very large, which will be challenging to manage it Namenode restart takes long time because lot of changes has to be merged In the case of crash, we will lost huge amount of metadata since fsimage is very old fsimage edits.log 2 Client 4 4 edits.log fsimage 5 fsimage 6 fsimage
33 Datanodes / Slave nodes Actual contents of the files are stored as blocks on the slave nodes Blocks are simply files on the slave nodes underlying filesystem Named blk_xxxxxxx Nothing on the slave node provides information about what underlying file the block is a part of - (That information is only stored in the NameNode s metadata) Each block is stored on multiple different nodes for redundancy Default is three replicas Each slave node runs a DataNode daemon Controls access to the blocks Communicates with the NameNode
34 DataNodes send hearbeat to the NameNode Once every 3 seconds NameNode uses heartbeats to detect DataNode failure

35 Mapreduce
36 What is Mapreduce MapReduce is a method for distributing a task across multiple nodes Consists of two developer-created phases Map Reduce In between Map and Reduce is the shuffle and sort Sends data from the Mappers to the Reducers



37 Mapreduce the big picture Client JOB


38 How Map and Reduce Work Together Map returns information Reducer accepts information Reducer applies a user defined function to reduce the amount of data
39 Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize, filter, or transform Write the results Outline stays the same, Map and Reduce change to fit the problem

40 Data Flow 1. Mappers read from HDFS 2. Map output is partitioned by key and sent to Reducers 3. Reducers sort input by key 4. Reduce output is written to HDFS

41 MapReduce Job Flow

42 Mapreduce Process can be considered as being similar to Unix pipeline
43 Mapreduce Architecture Overview Host 3 TaskTracker/slaves Host 5 TaskTracker/slaves Host 1 Jobtracker/Master Host 4 TaskTracker/slaves Host n TaskTracker/slaves 43
44 Mapreduce Simple Example Sample input to Mapper: Intermediate data produced

45 Mapreduce Simple Example Input to reducer: Output from reducer:

46

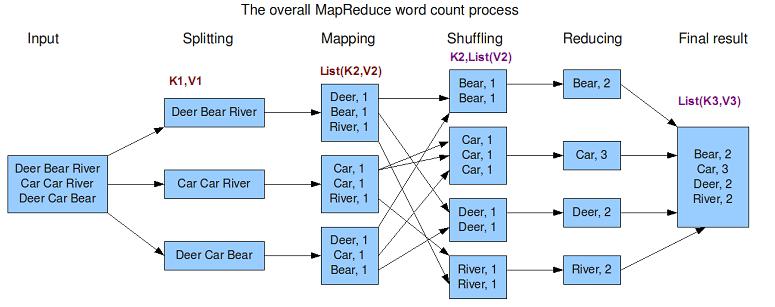
47 Key and Value

48 Hadoop Ecosystem

49 Recent version of Hadoop
50 Questions?
51 Thank You!!! Reference : Hadoop Training shimpisagar@yahoo.com
52 Session 2 Installation Hadoop Single Mode - Ms B. A. Khivasara and Ms K. R. Nirmal
53 >> cd hadoop / >>ls // this gives list of folders in hadoop directory bin ivy => consists of deploy and installed deployment tools) c++ => consists of all header files of c++ lib => libraried needed by hadoop to submit job libexcc => third party libraries conf => configuration files logs => log files docs => help manual webapps
54 >> cd conf >>ls // this gives list of files in /hadoop/conf directory core-site.xml => used to store namenode information hdfs.site.xml => used for Distributed file system replication mapred-site.xml => used to specify the location where the jobtracker must be installed capacity-scheduler.xml=> indicates the job to be executed first
55 In core-site.xml after configuration tag include : hadoop.tmp.dir indicates the location to keep property data : as here it is /tmp : We can specify other directory name here fs.default.name indicates the location to store the namenode: as here it is hdfs://localhost:54310 : We can specify other ipaddress incase of multicluster
56 hdfs.site.xml dfs.replication indicates property of setting the number of replications or clusters : as here it is 1 : We can specify our own also.
57 mapred-site.xml mapred.job.tracker indicates the location where the jobtracker must be installed : as here it is localhost:54311 : We can specify our own also.
58 >> cd.. >>cd bin This folder has following files start-all.sh => used to start all the nodes of hadoop stop-all.sh => used to stop all nodes hadoop => used to i) execute map/reduce program ii) to perform file system operations >>./hadoop namenode format This formats the directory where hadoop is installed

59 This message indicates that namenode has been formated properly

60 >>start-all.sh

61 >> jps // To verify if hadoop is installed
62 Jdk must be installed Machine should be password less ssh (When two m/c s communicate with each other in linux they do it through ssh: i.e secured shell)
63 To make a m/c passworless ssh : >>sshd Not installed then type, >> sudo apt-get install openssh-server >>ssh-keygen t rsa p >>cd.ssh(in home folder) >> ls id_rsa.pub and id_rsa >>sshd if it shows absolute path ssh is installed

64 Create a directory in Hadoop File system using >>./hadoop fs mkdir foldername Browse the namenode in browser to check if folder is created with Namenode : JobTacker: TaskTracker : i) Browse the filesystem ii)click user iii)click gurukul
65 Session 3 Hadoop as Pseudo Distributed Mode (WordCount Program in Hadoop) - Ms K. M. Sanghavi
66 Typical problem solved by MapReduce () Map Process a key/value pair to generate intermediate key/value pairs () Reduce Merge all intermediate values associated with the same key Users implement interface of two primary methods: 1. Map: (key1, val1) (key2, val2) 2. Reduce: (key2, [val2]) [val3] Map - clause group-by (for Key) of an aggregate function of SQL Reduce - aggregate function (e.g., average) that is computed over all the rows with the

67

68

69

70
71 Program to run on Hadoop Download Eclipse IDE, latest version of Eclipse is Kepler 1. Create New Java Project 2. Add dependencies jar Right click on Project properties and select Build Path Add all jars from $HADOOP_HOME/lib and $HADOOP_HOME (where hadoop core and tools jar lives)
72 Program to run on Hadoop 3. Create Mapper 4. Create Reducer 5. Create Driver for MapReduce Job Map Reduce job is executed by useful hadoop utility class ToolRunner 6. Supply Input and Output We need to supply input file that will be used during Map phase and the final output will be generated in output directory by Reduct task.
73 Program to run on Hadoop 7. Map Reduce Job Execution Right click Kdriver and Select Run As Java Application 8. Final Output

74 Program to run on Hadoop

75 Program to run on Hadoop

76 Program to run on Hadoop

77 Mapper import java.io.ioexception; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.longwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.mapper; Mapper< K1,V1, K2,V2 > has the map method <K1,V1,K2,V2>first pair is the input key/value pair, second is the output key/value pair public class KMapper extends protected void map(longwritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
 throws IOException, InterruptedException { LongWritable key, Text value : Data type of the input Key and Value to the mapper. Mapper<LongWritable,Text,Text,LongWritable><K,V>.")
78 Mapper //Map method header protected void map(longwritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { LongWritable key, Text value : Data type of the input Key and Value to the mapper. Mapper<LongWritable,Text,Text,LongWritable><K,V>.Context context : collect data output by the Mapper i.e. intermediate outputs or the output of the job Key and Value from the mapper. EX: < the,1>
79 Mapper //Convert the input line in Text type to a String and split it into words String words[] = value.tostring().split(" "); //Iterate through each word and a form key value pairs for(string w:words) { //Form key value pairs for each word as <word,one> and push it to the output collector } } } context.write(new Text(w), new LongWritable(1));
80 Reducer import java.io.ioexception; import org.apache.hadoop.io.longwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.reducer; public class KReducer extends Reducer<Text,LongWritable,Text,LongWritable> { Reducer< K2,V2, K2,V3 > has the reduce method <K2,V2,K2,V3>first pair is the map key/value pair, second is the output key/value pair
 throws IOException, InterruptedException { Text key, Iterable<LongWritable> value : Data type of the input Key and Value to the Reducer.")
81 Reducer //Reduce method header protected void reduce(text key, Iterable<LongWritable> value, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { Text key, Iterable<LongWritable> value : Data type of the input Key and Value to the Reducer. Iterator so we can go through the sets of values Reducer<LongWritable,Text,Text,LongWritable><K,V>.Context context : collect data output by the Reducer
82 Reducer //Initialize a variable sum as 0 int sum=0; //Iterate through all the values with respect to a key and sum up all of them for(longwritable i :value) sum = sum + 1; //Push to the output collector the Key and the obtained sum as value } } } context.write(key, new LongWritable(sum));
83 Driver import org.apache.hadoop.conf.configured; import org.apache.hadoop.fs.path; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.longwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.job; import org.apache.hadoop.mapreduce.lib.input.fileinputformat; import org.apache.hadoop.mapreduce.lib.input.textinputformat; import org.apache.hadoop.mapreduce.lib.output.fileoutputformat; import org.apache.hadoop.mapreduce.lib.output.textoutputformat; import org.apache.hadoop.util.tool; import org.apache.hadoop.util.toolrunner;
84 Driver public class KDriver extends Configured implements Tool public int run(string[] arg0) throws Exception { //creating a JobConf object and assigning a job name for identification purposes Job job= new Job(getConf(),"KMS"); // The default input format, "TextInputFormat," will load data in as (LongWritable, Text) pairs. The long value is the byte offset of the line in the file. // The basic (default) instance is TextOutputFormat, which writes (key, value) //pairs on individual lines of a text file. job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class);
85 Driver //Providing the mapper and reducer class names job.setmapperclass(kmapper.class); job.setreducerclass(kreducer.class); //Setting configuration object with the Data Type of output Key and Value for //map and reduce job.setmapoutputkeyclass(text.class); job.setmapoutputvalueclass(longwritable.class); job.setoutputkeyclass(text.class); job.setoutputvalueclass(longwritable.class);
86 Driver //The hdfs input and output directory to be fetched FileInputFormat.addInputPath(job, new Path("input")); FileOutputFormat.setOutputPath(job, new Path("out")); //Setting The Jar File name to execute to run on Hadoop job.setjarbyclass(kdriver.class); //Display Logas and wait for the job to complete } job.waitforcompletion(true); return 0;
87 Driver //Map Reduce job is executed by useful hadoop utility class ToolRunner public static void main(string[] args) throws Exception { } } ToolRunner.run(new KDriver(), args);

88 Creating Input Directory/ File as sample.txt

89 Map Reduce Job Execution
90 Final Output
91 Create a text file with some text in Ubuntu system using >>nano filename Check if the file is created using >>ls Copy this file from Ubuntu to Hadoop using >>./hadoop fs copyfromlocal filename foldername For this command to run we must be in hadoop/bin as hadoop command is in bin folder
92 Goto hadoop folder as it contains wordcount jar file >>cd.. Execute the wordcount program >>bin/hadoop jar hadoop-examples jar wordcount foldername ouputfoldername Now Browse the localhost:50070/ /user/prygma and see that outputfolder is created. Click the outputfolder and then click part-r file and see the output


93 Now Browse the localhost:50070/ /user/prygma and see that outputfolder is created.

94 Click the outputfolder and then click part-r file and see the output
95 Session 4 Installation Hadoop Fully Distributed Node - Ms B. A. Khivasara and Ms K. R. Nirmal
96 Stop Hadoop if it is running >>stop-all.sh
97 In core-site.xml after configuration tag include : Replace Local host with IP address of cluster where namenode is Stored.


98 mapred-site.xml mapred.job.tracker indicates the location where the jobtracker must be installed : as here it is


99 hdfs.site.xml dfs.replication indicates property of setting the number of replications or clusters : as here it is 1 : We can specify our own also.
100 Password less ssh for Multi Node: Step # 1: Generate first ssh key generate your first public and private key on a local workstation. workstation#1 $ ssh-keygen -t rsa copy your public key to your remote server using scp scp user@remote.server.com:.ssh/authorized_keys ~/.ssh
101 Step # 2 : Generate next/multiple ssh key i. Login to 2nd workstation ii. Download original the authorized_keys file from remote server using scp workstation#2 $ scp user@remote.server.com:.ssh/authorized_keys ~/.ssh iii. Create the new pub/private key workstation#2 $ ssh-keygen -t rsa
102 iv. APPEND this key to the downloaded authorized_keys file using cat command workstation#2 $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys v. upload authorized_keys to remote server again workstation#2 $ scp ~/.ssh/authorized_keys user@remote.server.com:.ssh/ Repeat step #2 for each user or workstations for remote server.
103 Step #3: Test your setup try to login from Workstation #1, #2 and so on to remote server. You should not be asked for a password: workstation#1 $ ssh user@remote.server.com workstation#2 $ ssh user@remote.server.com






104 Running jps on namenode Running jps on datanode

105 Run jar file from any workstation
106

107 Lastly do not forget to stop hadoop using >>stop-all.sh
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus
 UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
Introduction to Map/Reduce. Kostas Solomos Computer Science Department University of Crete, Greece
 Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Outline Introduction Big Data Sources of Big Data Tools HDFS Installation Configuration Starting & Stopping Map Reduc.
 D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
MapReduce Simplified Data Processing on Large Clusters
 MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
COMP4442. Service and Cloud Computing. Lab 12: MapReduce. Prof. George Baciu PQ838.
 COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
Big Data Analysis using Hadoop. Map-Reduce An Introduction. Lecture 2
 Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java
 MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java Contents Page 1 Copyright IBM Corporation, 2015 US Government Users Restricted Rights - Use, duplication or disclosure restricted
MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java Contents Page 1 Copyright IBM Corporation, 2015 US Government Users Restricted Rights - Use, duplication or disclosure restricted
Hadoop Quickstart. Table of contents
 Table of contents 1 Purpose...2 2 Pre-requisites...2 2.1 Supported Platforms... 2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster...3 5 Standalone
Table of contents 1 Purpose...2 2 Pre-requisites...2 2.1 Supported Platforms... 2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster...3 5 Standalone
Hortonworks HDPCD. Hortonworks Data Platform Certified Developer. Download Full Version :
 Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Steps: First install hadoop (if not installed yet) by, https://sl6it.wordpress.com/2015/12/04/1-study-and-configure-hadoop-for-big-data/
 by, https://sl6it.wordpress.com/2015/12/04/1-study-and-configure-hadoop-for-big-data/") SL-V BE IT EXP 7 Aim: Design and develop a distributed application to find the coolest/hottest year from the available weather data. Use weather data from the Internet and process it using MapReduce. Steps:
SL-V BE IT EXP 7 Aim: Design and develop a distributed application to find the coolest/hottest year from the available weather data. Use weather data from the Internet and process it using MapReduce. Steps:
Guidelines For Hadoop and Spark Cluster Usage
 Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Ghislain Fourny. Big Data 6. Massive Parallel Processing (MapReduce)
") Ghislain Fourny Big Data 6. Massive Parallel Processing (MapReduce) So far, we have... Storage as file system (HDFS) 13 So far, we have... Storage as tables (HBase) Storage as file system (HDFS) 14 Data
Ghislain Fourny Big Data 6. Massive Parallel Processing (MapReduce) So far, we have... Storage as file system (HDFS) 13 So far, we have... Storage as tables (HBase) Storage as file system (HDFS) 14 Data
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Ghislain Fourny. Big Data Fall Massive Parallel Processing (MapReduce)
") Ghislain Fourny Big Data Fall 2018 6. Massive Parallel Processing (MapReduce) Let's begin with a field experiment 2 400+ Pokemons, 10 different 3 How many of each??????????? 4 400 distributed to many volunteers
Ghislain Fourny Big Data Fall 2018 6. Massive Parallel Processing (MapReduce) Let's begin with a field experiment 2 400+ Pokemons, 10 different 3 How many of each??????????? 4 400 distributed to many volunteers
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Data Analysis Using MapReduce in Hadoop Environment
 Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Top 25 Big Data Interview Questions And Answers
 Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Installing Hadoop. You need a *nix system (Linux, Mac OS X, ) with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.
 with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.") Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco (fusco@di.uniroma1.it) Prerequisites You
Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco (fusco@di.uniroma1.it) Prerequisites You
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 16. Big Data Management VI (MapReduce Programming)
") Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
2. MapReduce Programming Model
 Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
The core source code of the edge detection of the Otsu-Canny operator in the Hadoop
 Attachment: The core source code of the edge detection of the Otsu-Canny operator in the Hadoop platform (ImageCanny.java) //Map task is as follows. package bishe; import java.io.ioexception; import org.apache.hadoop.fs.path;
Attachment: The core source code of the edge detection of the Otsu-Canny operator in the Hadoop platform (ImageCanny.java) //Map task is as follows. package bishe; import java.io.ioexception; import org.apache.hadoop.fs.path;
Big Data Retrieving Required Information From Text Files Desmond Hill Yenumula B Reddy (Advisor)
") Big Data Retrieving Required Information From Text Files Desmond Hill Yenumula B Reddy (Advisor) 1 OUTLINE Objective What is Big data Characteristics of Big Data Setup Requirements Hadoop Setup Word Count
Big Data Retrieving Required Information From Text Files Desmond Hill Yenumula B Reddy (Advisor) 1 OUTLINE Objective What is Big data Characteristics of Big Data Setup Requirements Hadoop Setup Word Count
Top 25 Hadoop Admin Interview Questions and Answers
 Top 25 Hadoop Admin Interview Questions and Answers 1) What daemons are needed to run a Hadoop cluster? DataNode, NameNode, TaskTracker, and JobTracker are required to run Hadoop cluster. 2) Which OS are
Top 25 Hadoop Admin Interview Questions and Answers 1) What daemons are needed to run a Hadoop cluster? DataNode, NameNode, TaskTracker, and JobTracker are required to run Hadoop cluster. 2) Which OS are
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Introduction to Hadoop. Scott Seighman Systems Engineer Sun Microsystems
 Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Apache Hadoop Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.
 SDJ INFOSOFT PVT. LTD Apache Hadoop 2.6.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.x Table of Contents Topic Software Requirements
SDJ INFOSOFT PVT. LTD Apache Hadoop 2.6.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.x Table of Contents Topic Software Requirements
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 24 Mass Storage, HDFS/Hadoop Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ What 2
Vendor: Cloudera. Exam Code: CCA-505. Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam.
 CDH5 Upgrade Exam.") Vendor: Cloudera Exam Code: CCA-505 Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam Version: Demo QUESTION 1 You have installed a cluster running HDFS and MapReduce
Vendor: Cloudera Exam Code: CCA-505 Exam Name: Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade Exam Version: Demo QUESTION 1 You have installed a cluster running HDFS and MapReduce
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
UNIT II HADOOP FRAMEWORK
 UNIT II HADOOP FRAMEWORK Hadoop Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models.
UNIT II HADOOP FRAMEWORK Hadoop Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models.
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (1/2) January 10, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (1/2) January 10, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
The Analysis and Implementation of the K - Means Algorithm Based on Hadoop Platform
 Computer and Information Science; Vol. 11, No. 1; 2018 ISSN 1913-8989 E-ISSN 1913-8997 Published by Canadian Center of Science and Education The Analysis and Implementation of the K - Means Algorithm Based
Computer and Information Science; Vol. 11, No. 1; 2018 ISSN 1913-8989 E-ISSN 1913-8997 Published by Canadian Center of Science and Education The Analysis and Implementation of the K - Means Algorithm Based
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Actual4Dumps. Provide you with the latest actual exam dumps, and help you succeed
 Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
CSE6331: Cloud Computing
 CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2017 by Leonidas Fegaras Map-Reduce Fundamentals Based on: J. Simeon: Introduction to MapReduce P. Michiardi: Tutorial on MapReduce
CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2017 by Leonidas Fegaras Map-Reduce Fundamentals Based on: J. Simeon: Introduction to MapReduce P. Michiardi: Tutorial on MapReduce
MRUnit testing framework is based on JUnit and it can test Map Reduce programs written on 0.20, 0.23.x, 1.0.x, 2.x version of Hadoop.
 MRUnit Tutorial Setup development environment 1. Download the latest version of MRUnit jar from Apache website: https://repository.apache.org/content/repositories/releases/org/apache/ mrunit/mrunit/. For
MRUnit Tutorial Setup development environment 1. Download the latest version of MRUnit jar from Apache website: https://repository.apache.org/content/repositories/releases/org/apache/ mrunit/mrunit/. For
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
Java in MapReduce. Scope
 Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Large-scale Information Processing
 Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
MAPREDUCE - PARTITIONER
 MAPREDUCE - PARTITIONER http://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm Copyright tutorialspoint.com A partitioner works like a condition in processing an input dataset. The partition
MAPREDUCE - PARTITIONER http://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm Copyright tutorialspoint.com A partitioner works like a condition in processing an input dataset. The partition
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Big Data and Scripting map reduce in Hadoop
 Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Introduction to the Hadoop Ecosystem - 1
 Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
itpass4sure Helps you pass the actual test with valid and latest training material.
 itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Big Data Analytics by Using Hadoop
 Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Big Data Analytics by Using Hadoop Chaitanya Arava Governors State University
Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Big Data Analytics by Using Hadoop Chaitanya Arava Governors State University
Clustering Documents. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Hadoop Cluster Implementation
 Hadoop Cluster Implementation By Aysha Binta Sayed ID:2013-1-60-068 Supervised By Dr. Md. Shamim Akhter Assistant Professor Department of Computer Science and Engineering East West University A project
Hadoop Cluster Implementation By Aysha Binta Sayed ID:2013-1-60-068 Supervised By Dr. Md. Shamim Akhter Assistant Professor Department of Computer Science and Engineering East West University A project
This brief tutorial provides a quick introduction to Big Data, MapReduce algorithm, and Hadoop Distributed File System.
 About this tutorial Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed
About this tutorial Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Installation and Configuration Documentation
 Installation and Configuration Documentation Release 1.0.1 Oshin Prem Sep 27, 2017 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE INSTALLATION....................................
Installation and Configuration Documentation Release 1.0.1 Oshin Prem Sep 27, 2017 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE INSTALLATION....................................
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Hadoop Integration Guide
 HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 4/7/2016 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 4/7/2016 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
Vendor: Cloudera. Exam Code: CCD-410. Exam Name: Cloudera Certified Developer for Apache Hadoop. Version: Demo
 Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Cloud Computing II. Exercises
 Cloud Computing II Exercises Exercise 1 Creating a Private Cloud Overview In this exercise, you will install and configure a private cloud using OpenStack. This will be accomplished using a singlenode
Cloud Computing II Exercises Exercise 1 Creating a Private Cloud Overview In this exercise, you will install and configure a private cloud using OpenStack. This will be accomplished using a singlenode
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science
 A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science Introduction The Hadoop cluster in Computing Science at Stirling allows users with a valid user account to submit and
A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science Introduction The Hadoop cluster in Computing Science at Stirling allows users with a valid user account to submit and
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Hadoop Integration Guide
 HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 5/2/2018 Legal Notices Warranty The only warranties for Micro Focus products and services are set forth in the express warranty
HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 5/2/2018 Legal Notices Warranty The only warranties for Micro Focus products and services are set forth in the express warranty
Getting Started with Hadoop
 Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce