A Configurable High-Throughput Linear Sorter System
|
|
|
- Adam Hoover
- 5 years ago
- Views:
Transcription



1 A Configurable High-Throughput Linear Sorter System Jorge Ortiz Information and Telecommunication Technology Center 2335 Irving Hill Road Lawrence, KS David Andrews Computer Science and Computer Engineering The University of Arkansas 504 J.B. Hunt Building, Fayetteville, AR

2 Introduction
3 Introduction Sorting an important system function Popular sorting algorithms not efficient or fast in hardware implementations Linear sorters ideal for hardware, but sort at a rate of 1 value per cycle Sorting networks better at throughput, but with high area and latency cost Need a better solution for high throughput, low latency sorting
4 Contributions Expanding the linear sorter implementation and making it versatile, reconfigurable and better suited for streaming input and output Parallelizing the linear sorter for increased throughput Implementing the high-throughput linear sorter, and outmatching the performance of current linear sorter approaches
5 Background
6 Background Software quicksort, mergesort and heapsort use divide-and-conquer techniques to achieve efficiency Hardware sorting plagued with overhead from data movements, synchronization, bookkeeping and memory accesses Need better use of concurrent data comparisons and swaps, rather than the extended execution of multiple assembly instructions like its software counterpart
7 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
8 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
9 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
10 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
11 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
12 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
13 Sorting Networks Swap comparators sort pairs of values Sink lowest value, then operate on remaining S n-1 items Receive parallel data at inputs High #PE and latency, resort with each new insertion Bubble Sort
14 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: Output:
15 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: 3 Output:
16 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: 2 3 Output:
17 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: Output:
18 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: Output:
19 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: Output:
20 Linear Sorters Sorted insertions Forwards incoming value to all nodes Each node shifts autonomously depending on neighbors values Single clock latency, small logic & regular structure Streaming input & output Serial input, need higher throughput Input: Output:
21 Configurable Linear Sorter
22 Configurable Linear Sorter Increase versatility for linear sorters Configurable: Linear sorter depth Sorting direction Sort on tags (for example, timestamps) rather than data User-defined data and tag size
23 Configurable Linear Sorter Increase functionality for linear sorters 1. Detect full conditions 2. Buffer input while full 3. Retrieve output serially for streaming 4. Delete top value, freeing nodes 5. Augment with left shift functionality 6. Test tags before deleting them
24 Extended Linear Sorter System 0 5 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6
25 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 5
26 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
27 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
28 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
29 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
30 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node

31 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
32 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
33 Interleaved Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
34 Interleaved Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
35 Interleaved Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
36 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
37 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
38 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
39 Extended Linear Sorter System Node 1 Node 2 Node 3 Node 4 Node 5 Node
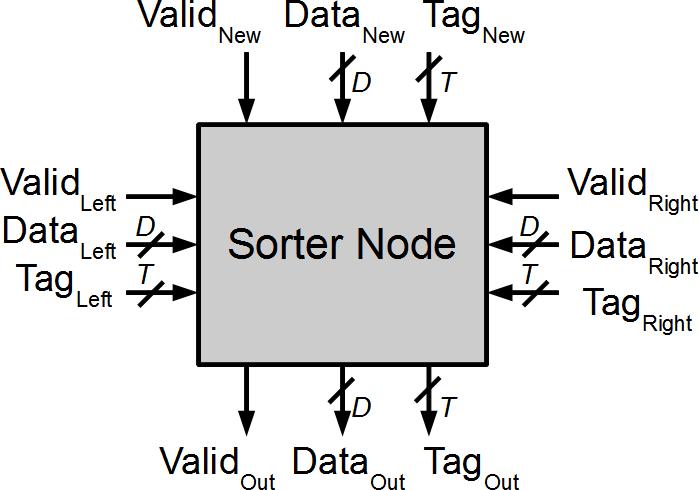
40 Sorter Node Architecture
41 Interleaved Linear Sorter
42 Interleaved Linear Sorter Increase throughput by using multiple linear sorters with parallel inputs Interleave parallel inputs into linear sorters through modulo arithmetic Distribute data evenly among linear sorters to avoid full conditions Service each linear sorter in roundrobin fashion to resort their outputs
43 Interleaved Linear Sorter ILS width = 4 Four parallel inputs {13, 04, 03, 10} After interleaving mod 4 {04, 13, 10, 03} [00, 01, 02, 03] But, what happens for inputs {07, 05, 01, 06}?
44 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS
45 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Inserted
46 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Preempted Inserted

47 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Preempted Inserted
48 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Preempted Inserted
49 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Preempted Inserted
50 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Preempted Inserted
51 Interleaved Linear Sorter Inserted Tags LS 0 LS 1 LS 2 LS Preempted Inserted
52 Input Distribution and Latency Assume uniformly distributed data With W = 2, 50% chance of interleaving delays, adding an extra clock cycle With W > 2, more probabilities of stalling, adding 1+ clock cycles Average latency for Interleaved Linear Sorters of length W ILS Width W Clock Cycles Larger ILS widths allow parallel sorting and increase throughput. However, they have complex routing and additional delays
 Service in round-robin fashion: Test the top tag of each linear sorter before")
53 Output Logic Accumulate values before output becomes relevant Increase linear sorter depth to accumulate more data Re-sort top values from each linear sorter to ensure continuity (particularly for contiguous values) Service in round-robin fashion: Test the top tag of each linear sorter before deleting
54 Streaming output LS 0 LS 1 LS 2 LS OK OK Output {8,9}; Wait for
55 Hardware Implementation
 1 278 17.4 2.3% 7 2 641 20.0 17.6% 113 4 1294 20.2 18.8% 243 8 2612 20.4 20.0% 522 16 5250 20.5 20.")
56 FPGA Area Xilinx Virtex-5 FPGA 8-bit tags, 8-bit data 17 slices per sorter node Linear Sorter depth of 16 Interleaved Linear Sorter FPGA Area Linear Sorters, W Total Slices Slices/Node Area Overhead Interleaving Area (slices) % % % % % 1081
57 FPGA Throughput f clk x ILS width W Includes logic and routing delay for interleaving data for W linear sorters Averaged for sorter depth from 1 up to 256 nodes Interleaved Linear Sorter FPGA Frequency & Throughput Linear Sorters, W Frequency (MHz) Throughput (millions/sec)
58 FPGA Throughput W=16, large logic & routing delays at inputs First three cases need single 6-input LUT for routing. Two and four LUTs needed for W=8 and W=16, respectively. Interleaved Linear Sorter FPGA Frequency & Throughput Linear Sorters, W Frequency (MHz) Throughput (millions/sec)
59 Maximum ILS Throughput Average speedups of 1.0, 1.8, 3.7 and 3.5 against single linear sorter
60 Throughput considerations Interleaving contention results in an average latency which increases with ILS width W Average latency for Interleaved Linear Sorters of length W ILS Width W Clock Cycles


61 Normalized ILS Throughput Average speedups of 1.0, 1.3, 1.8 and 1.4 against single linear sorter

62 Virtex II-Pro implementation 100 MHz bus frequency Data resided on BlockRAMs Tested Interleaved Linear Sorter W=4 Compared against MicroBlaze running quicksort in C Timing includes bus arbitration, read and writes over the OPB Final result is saved in BlockRAM
63 Three test scenarios 1. MicroBlaze BRAM write & read-back MB writes BRAM unsorted data MB sends start signal to ILS MB reads back sorted values over OPB 2. MicroBlaze BRAM write Same as scenario 1 No need for read back into MB 3. No MicroBlaze Hardware-only streaming output approach No need for OPB requests Output consumed by other hardware components immediately
64 ILS speedup over MicroBlaze System Clock cycles Speedup MicroBlaze quicksort 49,982 1 ILS 1 MB write & read ILS 2 MB write ILS 3 Hardware-only bit data 16-bit tags 64 values ILS width of 4
65 ILS speedup against Sorting Network System Execution time (ns) Speedup Batcher odd-even ILS Hardware only bit data-tags 32 values ILS width of 4 Sorting network requires static data set Re-sorts the full set of data upon a single new insertion
66 Conclusions
67 Conclusions Linear sorters appropriate to overcome sorting network disadvantages, but limited throughput Interleaved Linear Sorters allow high throughput, configuration of width, depth, tag and data size to match system requirements ILS speedup of 1.8 over regular linear sorter (3.7 for best case) ILS speedup of 68 against embedded software counterpart (1666 for best case)

68 Questions
CHAPTER 6 FPGA IMPLEMENTATION OF ARBITERS ALGORITHM FOR NETWORK-ON-CHIP
 133 CHAPTER 6 FPGA IMPLEMENTATION OF ARBITERS ALGORITHM FOR NETWORK-ON-CHIP 6.1 INTRODUCTION As the era of a billion transistors on a one chip approaches, a lot of Processing Elements (PEs) could be located
133 CHAPTER 6 FPGA IMPLEMENTATION OF ARBITERS ALGORITHM FOR NETWORK-ON-CHIP 6.1 INTRODUCTION As the era of a billion transistors on a one chip approaches, a lot of Processing Elements (PEs) could be located
Basic FPGA Architectures. Actel FPGAs. PLD Technologies: Antifuse. 3 Digital Systems Implementation Programmable Logic Devices
 3 Digital Systems Implementation Programmable Logic Devices Basic FPGA Architectures Why Programmable Logic Devices (PLDs)? Low cost, low risk way of implementing digital circuits as application specific
3 Digital Systems Implementation Programmable Logic Devices Basic FPGA Architectures Why Programmable Logic Devices (PLDs)? Low cost, low risk way of implementing digital circuits as application specific
Multi MicroBlaze System for Parallel Computing
 Multi MicroBlaze System for Parallel Computing P.HUERTA, J.CASTILLO, J.I.MÁRTINEZ, V.LÓPEZ HW/SW Codesign Group Universidad Rey Juan Carlos 28933 Móstoles, Madrid SPAIN Abstract: - Embedded systems need
Multi MicroBlaze System for Parallel Computing P.HUERTA, J.CASTILLO, J.I.MÁRTINEZ, V.LÓPEZ HW/SW Codesign Group Universidad Rey Juan Carlos 28933 Móstoles, Madrid SPAIN Abstract: - Embedded systems need
Hardware/Software Codesign of Schedulers for Real Time Systems
 Hardware/Software Codesign of Schedulers for Real Time Systems Jorge Ortiz Committee David Andrews, Chair Douglas Niehaus Perry Alexander Presentation Outline Background Prior work in hybrid co-design
Hardware/Software Codesign of Schedulers for Real Time Systems Jorge Ortiz Committee David Andrews, Chair Douglas Niehaus Perry Alexander Presentation Outline Background Prior work in hybrid co-design
Parallel FIR Filters. Chapter 5
 Chapter 5 Parallel FIR Filters This chapter describes the implementation of high-performance, parallel, full-precision FIR filters using the DSP48 slice in a Virtex-4 device. ecause the Virtex-4 architecture
Chapter 5 Parallel FIR Filters This chapter describes the implementation of high-performance, parallel, full-precision FIR filters using the DSP48 slice in a Virtex-4 device. ecause the Virtex-4 architecture
Hardware Design. University of Pannonia Dept. Of Electrical Engineering and Information Systems. MicroBlaze v.8.10 / v.8.20
 University of Pannonia Dept. Of Electrical Engineering and Information Systems Hardware Design MicroBlaze v.8.10 / v.8.20 Instructor: Zsolt Vörösházi, PhD. This material exempt per Department of Commerce
University of Pannonia Dept. Of Electrical Engineering and Information Systems Hardware Design MicroBlaze v.8.10 / v.8.20 Instructor: Zsolt Vörösházi, PhD. This material exempt per Department of Commerce
The Lekha 3GPP LTE FEC IP Core meets 3GPP LTE specification 3GPP TS V Release 10[1].
![The Lekha 3GPP LTE FEC IP Core meets 3GPP LTE specification 3GPP TS V Release 10[1].](/thumbs/75/72771698.jpg "The Lekha 3GPP LTE FEC IP Core meets 3GPP LTE specification 3GPP TS V Release 10[1].") Lekha IP 3GPP LTE FEC Encoder IP Core V1.0 The Lekha 3GPP LTE FEC IP Core meets 3GPP LTE specification 3GPP TS 36.212 V 10.5.0 Release 10[1]. 1.0 Introduction The Lekha IP 3GPP LTE FEC Encoder IP Core
Lekha IP 3GPP LTE FEC Encoder IP Core V1.0 The Lekha 3GPP LTE FEC IP Core meets 3GPP LTE specification 3GPP TS 36.212 V 10.5.0 Release 10[1]. 1.0 Introduction The Lekha IP 3GPP LTE FEC Encoder IP Core
INTRODUCTION TO CATAPULT C
 INTRODUCTION TO CATAPULT C Vijay Madisetti, Mohanned Sinnokrot Georgia Institute of Technology School of Electrical and Computer Engineering with adaptations and updates by: Dongwook Lee, Andreas Gerstlauer
INTRODUCTION TO CATAPULT C Vijay Madisetti, Mohanned Sinnokrot Georgia Institute of Technology School of Electrical and Computer Engineering with adaptations and updates by: Dongwook Lee, Andreas Gerstlauer
April 7, 2010 Data Sheet Version: v4.00
 logimem SDR/DDR/DDR2 SDRAM Memory Controller April 7, 2010 Data Sheet Version: v4.00 Xylon d.o.o. Fallerovo setaliste 22 10000 Zagreb, Croatia Phone: +385 1 368 00 26 Fax: +385 1 365 51 67 E-mail: support@logicbricks.com
logimem SDR/DDR/DDR2 SDRAM Memory Controller April 7, 2010 Data Sheet Version: v4.00 Xylon d.o.o. Fallerovo setaliste 22 10000 Zagreb, Croatia Phone: +385 1 368 00 26 Fax: +385 1 365 51 67 E-mail: support@logicbricks.com
EECS 151/251A Spring 2019 Digital Design and Integrated Circuits. Instructor: John Wawrzynek. Lecture 18 EE141
 EECS 151/251A Spring 2019 Digital Design and Integrated Circuits Instructor: John Wawrzynek Lecture 18 Memory Blocks Multi-ported RAM Combining Memory blocks FIFOs FPGA memory blocks Memory block synthesis
EECS 151/251A Spring 2019 Digital Design and Integrated Circuits Instructor: John Wawrzynek Lecture 18 Memory Blocks Multi-ported RAM Combining Memory blocks FIFOs FPGA memory blocks Memory block synthesis
The Next Generation 65-nm FPGA. Steve Douglass, Kees Vissers, Peter Alfke Xilinx August 21, 2006
 The Next Generation 65-nm FPGA Steve Douglass, Kees Vissers, Peter Alfke Xilinx August 21, 2006 Hot Chips, 2006 Structure of the talk 65nm technology going towards 32nm Virtex-5 family Improved I/O Benchmarking
The Next Generation 65-nm FPGA Steve Douglass, Kees Vissers, Peter Alfke Xilinx August 21, 2006 Hot Chips, 2006 Structure of the talk 65nm technology going towards 32nm Virtex-5 family Improved I/O Benchmarking
Farhad Shafai, Sarance Technologies March, 2008 SARANCE TECHNOLOGIES
 Technical Feasibility of 100G/40G MLD Farhad Shafai, Sarance Technologies March, 08 1 Outline Presentation is focused on the implementation of the digital logic Agenda: MLD overview 100G implementation
Technical Feasibility of 100G/40G MLD Farhad Shafai, Sarance Technologies March, 08 1 Outline Presentation is focused on the implementation of the digital logic Agenda: MLD overview 100G implementation
Digital Integrated Circuits
 Digital Integrated Circuits Lecture 9 Jaeyong Chung Robust Systems Laboratory Incheon National University DIGITAL DESIGN FLOW Chung EPC6055 2 FPGA vs. ASIC FPGA (A programmable Logic Device) Faster time-to-market
Digital Integrated Circuits Lecture 9 Jaeyong Chung Robust Systems Laboratory Incheon National University DIGITAL DESIGN FLOW Chung EPC6055 2 FPGA vs. ASIC FPGA (A programmable Logic Device) Faster time-to-market
Parallel Systems Course: Chapter VIII. Sorting Algorithms. Kumar Chapter 9. Jan Lemeire ETRO Dept. November Parallel Sorting
 Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. November 2014 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. November 2014 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
 University of Crete School of Sciences & Engineering Computer Science Department Master Thesis by Michael Papamichael Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
University of Crete School of Sciences & Engineering Computer Science Department Master Thesis by Michael Papamichael Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
Fast Scalable FPGA-Based Network-on-Chip Simulation Models
 We thank Xilinx for their FPGA and tool donations. We thank Bluespec for their tool donations and support. Computer Architecture Lab at Carnegie Mellon Fast Scalable FPGA-Based Network-on-Chip Simulation
We thank Xilinx for their FPGA and tool donations. We thank Bluespec for their tool donations and support. Computer Architecture Lab at Carnegie Mellon Fast Scalable FPGA-Based Network-on-Chip Simulation
A Hardware Cache memcpy Accelerator
 A Hardware memcpy Accelerator Stephan Wong, Filipa Duarte, and Stamatis Vassiliadis Computer Engineering, Delft University of Technology Mekelweg 4, 2628 CD Delft, The Netherlands {J.S.S.M.Wong, F.Duarte,
A Hardware memcpy Accelerator Stephan Wong, Filipa Duarte, and Stamatis Vassiliadis Computer Engineering, Delft University of Technology Mekelweg 4, 2628 CD Delft, The Netherlands {J.S.S.M.Wong, F.Duarte,
Memory-efficient and fast run-time reconfiguration of regularly structured designs
 Memory-efficient and fast run-time reconfiguration of regularly structured designs Brahim Al Farisi, Karel Heyse, Karel Bruneel and Dirk Stroobandt Ghent University, ELIS Department Sint-Pietersnieuwstraat
Memory-efficient and fast run-time reconfiguration of regularly structured designs Brahim Al Farisi, Karel Heyse, Karel Bruneel and Dirk Stroobandt Ghent University, ELIS Department Sint-Pietersnieuwstraat
Vendor Agnostic, High Performance, Double Precision Floating Point Division for FPGAs
 Vendor Agnostic, High Performance, Double Precision Floating Point Division for FPGAs Xin Fang and Miriam Leeser Dept of Electrical and Computer Eng Northeastern University Boston, Massachusetts 02115
Vendor Agnostic, High Performance, Double Precision Floating Point Division for FPGAs Xin Fang and Miriam Leeser Dept of Electrical and Computer Eng Northeastern University Boston, Massachusetts 02115
Parallel Systems Course: Chapter VIII. Sorting Algorithms. Kumar Chapter 9. Jan Lemeire ETRO Dept. Fall Parallel Sorting
 Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. Fall 2017 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. Fall 2017 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Sorting Algorithms
 Parallel Sorting Algorithms Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2016/2017 (Slides based on the book Parallel Programming:
Parallel Sorting Algorithms Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2016/2017 (Slides based on the book Parallel Programming:
Efficiency and memory footprint of Xilkernel for the Microblaze soft processor
 Efficiency and memory footprint of Xilkernel for the Microblaze soft processor Dariusz Caban, Institute of Informatics, Gliwice, Poland - June 18, 2014 The use of a real-time multitasking kernel simplifies
Efficiency and memory footprint of Xilkernel for the Microblaze soft processor Dariusz Caban, Institute of Informatics, Gliwice, Poland - June 18, 2014 The use of a real-time multitasking kernel simplifies
Embedded Systems. 7. System Components
 Embedded Systems 7. System Components Lothar Thiele 7-1 Contents of Course 1. Embedded Systems Introduction 2. Software Introduction 7. System Components 10. Models 3. Real-Time Models 4. Periodic/Aperiodic
Embedded Systems 7. System Components Lothar Thiele 7-1 Contents of Course 1. Embedded Systems Introduction 2. Software Introduction 7. System Components 10. Models 3. Real-Time Models 4. Periodic/Aperiodic
FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow
 FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow Abstract: High-level synthesis (HLS) of data-parallel input languages, such as the Compute Unified Device Architecture
FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow Abstract: High-level synthesis (HLS) of data-parallel input languages, such as the Compute Unified Device Architecture
Introduction to ATM Technology
 Introduction to ATM Technology ATM Switch Design Switching network (N x N) Switching network (N x N) SP CP SP CP Presentation Outline Generic Switch Architecture Specific examples Shared Buffer Switch
Introduction to ATM Technology ATM Switch Design Switching network (N x N) Switching network (N x N) SP CP SP CP Presentation Outline Generic Switch Architecture Specific examples Shared Buffer Switch
CPE/EE 422/522. Introduction to Xilinx Virtex Field-Programmable Gate Arrays Devices. Dr. Rhonda Kay Gaede UAH. Outline
 CPE/EE 422/522 Introduction to Xilinx Virtex Field-Programmable Gate Arrays Devices Dr. Rhonda Kay Gaede UAH Outline Introduction Field-Programmable Gate Arrays Virtex Virtex-E, Virtex-II, and Virtex-II
CPE/EE 422/522 Introduction to Xilinx Virtex Field-Programmable Gate Arrays Devices Dr. Rhonda Kay Gaede UAH Outline Introduction Field-Programmable Gate Arrays Virtex Virtex-E, Virtex-II, and Virtex-II
An FPGA Based Adaptive Viterbi Decoder
 An FPGA Based Adaptive Viterbi Decoder Sriram Swaminathan Russell Tessier Department of ECE University of Massachusetts Amherst Overview Introduction Objectives Background Adaptive Viterbi Algorithm Architecture
An FPGA Based Adaptive Viterbi Decoder Sriram Swaminathan Russell Tessier Department of ECE University of Massachusetts Amherst Overview Introduction Objectives Background Adaptive Viterbi Algorithm Architecture
FPGA VHDL Design Flow AES128 Implementation
 Sakinder Ali FPGA VHDL Design Flow AES128 Implementation Field Programmable Gate Array Basic idea: two-dimensional array of logic blocks and flip-flops with a means for the user to configure: 1. The interconnection
Sakinder Ali FPGA VHDL Design Flow AES128 Implementation Field Programmable Gate Array Basic idea: two-dimensional array of logic blocks and flip-flops with a means for the user to configure: 1. The interconnection
Copyright 2011 Society of Photo-Optical Instrumentation Engineers. This paper was published in Proceedings of SPIE (Proc. SPIE Vol.
 Copyright 2011 Society of Photo-Optical Instrumentation Engineers. This paper was published in Proceedings of SPIE (Proc. SPIE Vol. 8008, 80080E, DOI: http://dx.doi.org/10.1117/12.905281 ) and is made
Copyright 2011 Society of Photo-Optical Instrumentation Engineers. This paper was published in Proceedings of SPIE (Proc. SPIE Vol. 8008, 80080E, DOI: http://dx.doi.org/10.1117/12.905281 ) and is made
An FPGA based rapid prototyping platform for wavelet coprocessors
 An FPGA based rapid prototyping platform for wavelet coprocessors Alonzo Vera a, Uwe Meyer-Baese b and Marios Pattichis a a University of New Mexico, ECE Dept., Albuquerque, NM87131 b FAMU-FSU, ECE Dept.,
An FPGA based rapid prototyping platform for wavelet coprocessors Alonzo Vera a, Uwe Meyer-Baese b and Marios Pattichis a a University of New Mexico, ECE Dept., Albuquerque, NM87131 b FAMU-FSU, ECE Dept.,
Performance and Optimization Issues in Multicore Computing
 Performance and Optimization Issues in Multicore Computing Minsoo Ryu Department of Computer Science and Engineering 2 Multicore Computing Challenges It is not easy to develop an efficient multicore program
Performance and Optimization Issues in Multicore Computing Minsoo Ryu Department of Computer Science and Engineering 2 Multicore Computing Challenges It is not easy to develop an efficient multicore program
Core Facts. Documentation Design File Formats. Verification Instantiation Templates Reference Designs & Application Notes Additional Items
 (FFT_PIPE) Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com Core Facts Documentation
(FFT_PIPE) Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com Core Facts Documentation
Core Facts. Documentation Design File Formats. Verification Instantiation Templates Reference Designs & Application Notes Additional Items
 (FFT_MIXED) November 26, 2008 Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com
(FFT_MIXED) November 26, 2008 Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com
Memory. Lecture 22 CS301
 Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor. David Johnson Systems Technology Division Hewlett-Packard Company
 Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Fast Bit Sort. A New In Place Sorting Technique. Nando Favaro February 2009
 Fast Bit Sort A New In Place Sorting Technique Nando Favaro February 2009 1. INTRODUCTION 1.1. A New Sorting Algorithm In Computer Science, the role of sorting data into an order list is a fundamental
Fast Bit Sort A New In Place Sorting Technique Nando Favaro February 2009 1. INTRODUCTION 1.1. A New Sorting Algorithm In Computer Science, the role of sorting data into an order list is a fundamental
FPGA Matrix Multiplier
 FPGA Matrix Multiplier In Hwan Baek Henri Samueli School of Engineering and Applied Science University of California Los Angeles Los Angeles, California Email: chris.inhwan.baek@gmail.com David Boeck Henri
FPGA Matrix Multiplier In Hwan Baek Henri Samueli School of Engineering and Applied Science University of California Los Angeles Los Angeles, California Email: chris.inhwan.baek@gmail.com David Boeck Henri
RiceNIC. Prototyping Network Interfaces. Jeffrey Shafer Scott Rixner
 RiceNIC Prototyping Network Interfaces Jeffrey Shafer Scott Rixner RiceNIC Overview Gigabit Ethernet Network Interface Card RiceNIC - Prototyping Network Interfaces 2 RiceNIC Overview Reconfigurable and
RiceNIC Prototyping Network Interfaces Jeffrey Shafer Scott Rixner RiceNIC Overview Gigabit Ethernet Network Interface Card RiceNIC - Prototyping Network Interfaces 2 RiceNIC Overview Reconfigurable and
Memory Hierarchy. Caching Chapter 7. Locality. Program Characteristics. What does that mean?!? Exploiting Spatial & Temporal Locality
 Caching Chapter 7 Basics (7.,7.2) Cache Writes (7.2 - p 483-485) configurations (7.2 p 487-49) Performance (7.3) Associative caches (7.3 p 496-54) Multilevel caches (7.3 p 55-5) Tech SRAM (logic) SRAM
Caching Chapter 7 Basics (7.,7.2) Cache Writes (7.2 - p 483-485) configurations (7.2 p 487-49) Performance (7.3) Associative caches (7.3 p 496-54) Multilevel caches (7.3 p 55-5) Tech SRAM (logic) SRAM
A SIMULINK-TO-FPGA MULTI-RATE HIERARCHICAL FIR FILTER DESIGN
 A SIMULINK-TO-FPGA MULTI-RATE HIERARCHICAL FIR FILTER DESIGN Xiaoying Li 1 Fuming Sun 2 Enhua Wu 1, 3 1 University of Macau, Macao, China 2 University of Science and Technology Beijing, Beijing, China
A SIMULINK-TO-FPGA MULTI-RATE HIERARCHICAL FIR FILTER DESIGN Xiaoying Li 1 Fuming Sun 2 Enhua Wu 1, 3 1 University of Macau, Macao, China 2 University of Science and Technology Beijing, Beijing, China
Hardware Design. MicroBlaze 7.1. This material exempt per Department of Commerce license exception TSU Xilinx, Inc. All Rights Reserved
 Hardware Design MicroBlaze 7.1 This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: List the MicroBlaze 7.1 Features List
Hardware Design MicroBlaze 7.1 This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: List the MicroBlaze 7.1 Features List
Data Side OCM Bus v1.0 (v2.00b)
") 0 Data Side OCM Bus v1.0 (v2.00b) DS480 January 23, 2007 0 0 Introduction The DSOCM_V10 core is a data-side On-Chip Memory (OCM) bus interconnect core. The core connects the PowerPC 405 data-side OCM interface
0 Data Side OCM Bus v1.0 (v2.00b) DS480 January 23, 2007 0 0 Introduction The DSOCM_V10 core is a data-side On-Chip Memory (OCM) bus interconnect core. The core connects the PowerPC 405 data-side OCM interface
Quick Sort. CSE Data Structures May 15, 2002
 Quick Sort CSE 373 - Data Structures May 15, 2002 Readings and References Reading Section 7.7, Data Structures and Algorithm Analysis in C, Weiss Other References C LR 15-May-02 CSE 373 - Data Structures
Quick Sort CSE 373 - Data Structures May 15, 2002 Readings and References Reading Section 7.7, Data Structures and Algorithm Analysis in C, Weiss Other References C LR 15-May-02 CSE 373 - Data Structures
Sorting Units for FPGA-Based Embedded Systems
 Sorting Units for FPGA-Based Embedded Systems Rui Marcelino, Horácio Neto, and João M. P. Cardoso Abstract Sorting is an important operation for a number of embedded applications. As sorting large datasets
Sorting Units for FPGA-Based Embedded Systems Rui Marcelino, Horácio Neto, and João M. P. Cardoso Abstract Sorting is an important operation for a number of embedded applications. As sorting large datasets
Lecture 8 Parallel Algorithms II
 Lecture 8 Parallel Algorithms II Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Original slides from Introduction to Parallel
Lecture 8 Parallel Algorithms II Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Original slides from Introduction to Parallel
Overview of ROCCC 2.0
 Overview of ROCCC 2.0 Walid Najjar and Jason Villarreal SUMMARY FPGAs have been shown to be powerful platforms for hardware code acceleration. However, their poor programmability is the main impediment
Overview of ROCCC 2.0 Walid Najjar and Jason Villarreal SUMMARY FPGAs have been shown to be powerful platforms for hardware code acceleration. However, their poor programmability is the main impediment
Coherent Shared Memories for FPGAs. David Woods
 Coherent Shared Memories for FPGAs by David Woods A thesis submitted in conformity with the requirements for the degree of Master of Applied Sciences Graduate Department of Electrical and Computer Engineering
Coherent Shared Memories for FPGAs by David Woods A thesis submitted in conformity with the requirements for the degree of Master of Applied Sciences Graduate Department of Electrical and Computer Engineering
Sorting (I) Hwansoo Han
 Hwansoo Han") Sorting (I) Hwansoo Han Sorting Algorithms Sorting for a short list Simple sort algorithms: O(n ) time Bubble sort, insertion sort, selection sort Popular sorting algorithm Quicksort: O(nlogn) time on
Sorting (I) Hwansoo Han Sorting Algorithms Sorting for a short list Simple sort algorithms: O(n ) time Bubble sort, insertion sort, selection sort Popular sorting algorithm Quicksort: O(nlogn) time on
A memcpy Hardware Accelerator Solution for Non Cache-line Aligned Copies
 A memcpy Hardware Accelerator Solution for Non Cache-line Aligned Copies Filipa Duarte and Stephan Wong Computer Engineering Laboratory Delft University of Technology Abstract In this paper, we present
A memcpy Hardware Accelerator Solution for Non Cache-line Aligned Copies Filipa Duarte and Stephan Wong Computer Engineering Laboratory Delft University of Technology Abstract In this paper, we present
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
ECE 30 Introduction to Computer Engineering
 ECE 0 Introduction to Computer Engineering Study Problems, Set #9 Spring 01 1. Given the following series of address references given as word addresses:,,, 1, 1, 1,, 8, 19,,,,, 7,, and. Assuming a direct-mapped
ECE 0 Introduction to Computer Engineering Study Problems, Set #9 Spring 01 1. Given the following series of address references given as word addresses:,,, 1, 1, 1,, 8, 19,,,,, 7,, and. Assuming a direct-mapped
ENGN 2910A Homework 03 (140 points) Due Date: Oct 3rd 2013
 Due Date: Oct 3rd 2013") ENGN 2910A Homework 03 (140 points) Due Date: Oct 3rd 2013 Professor: Sherief Reda School of Engineering, Brown University 1. [from Debois et al. 30 points] Consider the non-pipelined implementation of
ENGN 2910A Homework 03 (140 points) Due Date: Oct 3rd 2013 Professor: Sherief Reda School of Engineering, Brown University 1. [from Debois et al. 30 points] Consider the non-pipelined implementation of
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Optimizing Memory Performance for FPGA Implementation of PageRank
 Optimizing Memory Performance for FPGA Implementation of PageRank Shijie Zhou, Charalampos Chelmis, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles,
Optimizing Memory Performance for FPGA Implementation of PageRank Shijie Zhou, Charalampos Chelmis, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles,
Introduction to Partial Reconfiguration Methodology
 Methodology This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Define Partial Reconfiguration technology List common applications
Methodology This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Define Partial Reconfiguration technology List common applications
What is Pipelining? RISC remainder (our assumptions)
") What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
User Manual for FC100
 Sundance Multiprocessor Technology Limited User Manual Form : QCF42 Date : 6 July 2006 Unit / Module Description: IEEE-754 Floating-point FPGA IP Core Unit / Module Number: FC100 Document Issue Number:
Sundance Multiprocessor Technology Limited User Manual Form : QCF42 Date : 6 July 2006 Unit / Module Description: IEEE-754 Floating-point FPGA IP Core Unit / Module Number: FC100 Document Issue Number:
Deep-Pipelined FPGA Implementation of Ellipse Estimation for Eye Tracking
 Deep-Pipelined FPGA Implementation of Ellipse Estimation for Eye Tracking Keisuke Dohi, Yuma Hatanaka, Kazuhiro Negi, Yuichiro Shibata, Kiyoshi Oguri Graduate school of engineering, Nagasaki University,
Deep-Pipelined FPGA Implementation of Ellipse Estimation for Eye Tracking Keisuke Dohi, Yuma Hatanaka, Kazuhiro Negi, Yuichiro Shibata, Kiyoshi Oguri Graduate school of engineering, Nagasaki University,
Parallel graph traversal for FPGA
 LETTER IEICE Electronics Express, Vol.11, No.7, 1 6 Parallel graph traversal for FPGA Shice Ni a), Yong Dou, Dan Zou, Rongchun Li, and Qiang Wang National Laboratory for Parallel and Distributed Processing,
LETTER IEICE Electronics Express, Vol.11, No.7, 1 6 Parallel graph traversal for FPGA Shice Ni a), Yong Dou, Dan Zou, Rongchun Li, and Qiang Wang National Laboratory for Parallel and Distributed Processing,
! Parallel machines are becoming quite common and affordable. ! Databases are growing increasingly large
 Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases. Introduction
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
EECS150 - Digital Design Lecture 11 SRAM (II), Caches. Announcements
, Caches. Announcements") EECS15 - Digital Design Lecture 11 SRAM (II), Caches September 29, 211 Elad Alon Electrical Engineering and Computer Sciences University of California, Berkeley http//www-inst.eecs.berkeley.edu/~cs15 Fall
EECS15 - Digital Design Lecture 11 SRAM (II), Caches September 29, 211 Elad Alon Electrical Engineering and Computer Sciences University of California, Berkeley http//www-inst.eecs.berkeley.edu/~cs15 Fall
Fast dynamic and partial reconfiguration Data Path
 Fast dynamic and partial reconfiguration Data Path with low Michael Hübner 1, Diana Göhringer 2, Juanjo Noguera 3, Jürgen Becker 1 1 Karlsruhe Institute t of Technology (KIT), Germany 2 Fraunhofer IOSB,
Fast dynamic and partial reconfiguration Data Path with low Michael Hübner 1, Diana Göhringer 2, Juanjo Noguera 3, Jürgen Becker 1 1 Karlsruhe Institute t of Technology (KIT), Germany 2 Fraunhofer IOSB,
RUN-TIME PARTIAL RECONFIGURATION SPEED INVESTIGATION AND ARCHITECTURAL DESIGN SPACE EXPLORATION
 RUN-TIME PARTIAL RECONFIGURATION SPEED INVESTIGATION AND ARCHITECTURAL DESIGN SPACE EXPLORATION Ming Liu, Wolfgang Kuehn, Zhonghai Lu, Axel Jantsch II. Physics Institute Dept. of Electronic, Computer and
RUN-TIME PARTIAL RECONFIGURATION SPEED INVESTIGATION AND ARCHITECTURAL DESIGN SPACE EXPLORATION Ming Liu, Wolfgang Kuehn, Zhonghai Lu, Axel Jantsch II. Physics Institute Dept. of Electronic, Computer and
PowerPC on NetFPGA CSE 237B. Erik Rubow
 PowerPC on NetFPGA CSE 237B Erik Rubow NetFPGA PCI card + FPGA + 4 GbE ports FPGA (Virtex II Pro) has 2 PowerPC hard cores Untapped resource within NetFPGA community Goals Evaluate performance of on chip
PowerPC on NetFPGA CSE 237B Erik Rubow NetFPGA PCI card + FPGA + 4 GbE ports FPGA (Virtex II Pro) has 2 PowerPC hard cores Untapped resource within NetFPGA community Goals Evaluate performance of on chip
Dynamically Reconfigurable Coprocessors in FPGA-based Embedded Systems
 Dynamically Reconfigurable Coprocessors in PGA-based Embedded Systems Ph.D. Thesis March, 2006 Student: Ivan Gonzalez Director: ranciso J. Gomez Ivan.Gonzalez@uam.es 1 Agenda Motivation and Thesis Goal
Dynamically Reconfigurable Coprocessors in PGA-based Embedded Systems Ph.D. Thesis March, 2006 Student: Ivan Gonzalez Director: ranciso J. Gomez Ivan.Gonzalez@uam.es 1 Agenda Motivation and Thesis Goal
Near Memory Key/Value Lookup Acceleration MemSys 2017
 Near Key/Value Lookup Acceleration MemSys 2017 October 3, 2017 Scott Lloyd, Maya Gokhale Center for Applied Scientific Computing This work was performed under the auspices of the U.S. Department of Energy
Near Key/Value Lookup Acceleration MemSys 2017 October 3, 2017 Scott Lloyd, Maya Gokhale Center for Applied Scientific Computing This work was performed under the auspices of the U.S. Department of Energy
ISSN Vol.02, Issue.11, December-2014, Pages:
 ISSN 2322-0929 Vol.02, Issue.11, December-2014, Pages:1208-1212 www.ijvdcs.org Implementation of Area Optimized Floating Point Unit using Verilog G.RAJA SEKHAR 1, M.SRIHARI 2 1 PG Scholar, Dept of ECE,
ISSN 2322-0929 Vol.02, Issue.11, December-2014, Pages:1208-1212 www.ijvdcs.org Implementation of Area Optimized Floating Point Unit using Verilog G.RAJA SEKHAR 1, M.SRIHARI 2 1 PG Scholar, Dept of ECE,
High-Performance Linear Algebra Processor using FPGA
 High-Performance Linear Algebra Processor using FPGA J. R. Johnson P. Nagvajara C. Nwankpa 1 Extended Abstract With recent advances in FPGA (Field Programmable Gate Array) technology it is now feasible
High-Performance Linear Algebra Processor using FPGA J. R. Johnson P. Nagvajara C. Nwankpa 1 Extended Abstract With recent advances in FPGA (Field Programmable Gate Array) technology it is now feasible
Program-Driven Fine-Grained Power Management for the Reconfigurable Mesh
 Program-Driven Fine-Grained Power Management for the Reconfigurable Mesh Heiner Giefers, Marco Platzner Computer Engineering Group University of Paderborn {hgiefers, platzner}@upb.de Outline 1. Introduction
Program-Driven Fine-Grained Power Management for the Reconfigurable Mesh Heiner Giefers, Marco Platzner Computer Engineering Group University of Paderborn {hgiefers, platzner}@upb.de Outline 1. Introduction
Double Precision Floating-Point Multiplier using Coarse-Grain Units
 Double Precision Floating-Point Multiplier using Coarse-Grain Units Rui Duarte INESC-ID/IST/UTL. rduarte@prosys.inesc-id.pt Mário Véstias INESC-ID/ISEL/IPL. mvestias@deetc.isel.ipl.pt Horácio Neto INESC-ID/IST/UTL
Double Precision Floating-Point Multiplier using Coarse-Grain Units Rui Duarte INESC-ID/IST/UTL. rduarte@prosys.inesc-id.pt Mário Véstias INESC-ID/ISEL/IPL. mvestias@deetc.isel.ipl.pt Horácio Neto INESC-ID/IST/UTL
4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.
 Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
What is Pipelining. work is done at each stage. The work is not finished until it has passed through all stages.
 PIPELINING What is Pipelining A technique used in advanced microprocessors where the microprocessor begins executing a second instruction before the first has been completed. - A Pipeline is a series of
PIPELINING What is Pipelining A technique used in advanced microprocessors where the microprocessor begins executing a second instruction before the first has been completed. - A Pipeline is a series of
TSEA44 - Design for FPGAs
 2015-11-24 Now for something else... Adapting designs to FPGAs Why? Clock frequency Area Power Target FPGA architecture: Xilinx FPGAs with 4 input LUTs (such as Virtex-II) Determining the maximum frequency
2015-11-24 Now for something else... Adapting designs to FPGAs Why? Clock frequency Area Power Target FPGA architecture: Xilinx FPGAs with 4 input LUTs (such as Virtex-II) Determining the maximum frequency
A Novel Design Framework for the Design of Reconfigurable Systems based on NoCs
 Politecnico di Milano & EPFL A Novel Design Framework for the Design of Reconfigurable Systems based on NoCs Vincenzo Rana, Ivan Beretta, Donatella Sciuto Donatella Sciuto sciuto@elet.polimi.it Introduction
Politecnico di Milano & EPFL A Novel Design Framework for the Design of Reconfigurable Systems based on NoCs Vincenzo Rana, Ivan Beretta, Donatella Sciuto Donatella Sciuto sciuto@elet.polimi.it Introduction
55 Streaming Sorting Networks
 55 Streaming Sorting Networks MARCELA ZULUAGA, Department of Computer Science, ETH Zurich PETER MILDER, Department of Electrical and Computer Engineering, Stony Brook University MARKUS PÜSCHEL, Department
55 Streaming Sorting Networks MARCELA ZULUAGA, Department of Computer Science, ETH Zurich PETER MILDER, Department of Electrical and Computer Engineering, Stony Brook University MARKUS PÜSCHEL, Department
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Data Storage and Query Answering. Data Storage and Disk Structure (2)
") Data Storage and Query Answering Data Storage and Disk Structure (2) Review: The Memory Hierarchy Swapping, Main-memory DBMS s Tertiary Storage: Tape, Network Backup 3,200 MB/s (DDR-SDRAM @200MHz) 6,400
Data Storage and Query Answering Data Storage and Disk Structure (2) Review: The Memory Hierarchy Swapping, Main-memory DBMS s Tertiary Storage: Tape, Network Backup 3,200 MB/s (DDR-SDRAM @200MHz) 6,400
Chapter 18: Parallel Databases
 Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases. Chapter 18: Parallel Databases. Parallelism in Databases. Introduction
 Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Today. Comments about assignment Max 1/T (skew = 0) Max clock skew? Comments about assignment 3 ASICs and Programmable logic Others courses
 Max clock skew? Comments about assignment 3 ASICs and Programmable logic Others courses") Today Comments about assignment 3-43 Comments about assignment 3 ASICs and Programmable logic Others courses octor Per should show up in the end of the lecture Mealy machines can not be coded in a single
Today Comments about assignment 3-43 Comments about assignment 3 ASICs and Programmable logic Others courses octor Per should show up in the end of the lecture Mealy machines can not be coded in a single
LogiCORE IP Serial RapidIO Gen2 v1.2
 LogiCORE IP Serial RapidIO Gen2 v1.2 Product Guide Table of Contents Chapter 1: Overview System Overview............................................................ 5 Applications.................................................................
LogiCORE IP Serial RapidIO Gen2 v1.2 Product Guide Table of Contents Chapter 1: Overview System Overview............................................................ 5 Applications.................................................................
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA
 Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
ECE 341 Final Exam Solution
 ECE 341 Final Exam Solution Time allowed: 110 minutes Total Points: 100 Points Scored: Name: Problem No. 1 (10 points) For each of the following statements, indicate whether the statement is TRUE or FALSE.
ECE 341 Final Exam Solution Time allowed: 110 minutes Total Points: 100 Points Scored: Name: Problem No. 1 (10 points) For each of the following statements, indicate whether the statement is TRUE or FALSE.
Creating High-Speed Memory Interfaces with Virtex-II and Virtex-II Pro FPGAs Author: Nagesh Gupta, Maria George
 XAPP688 (v1.2) May 3, 2004 R Application Note: Virtex-II Families Creating High-Speed Memory Interfaces with Virtex-II and Virtex-II Pro FPGAs Author: Nagesh Gupta, Maria George Summary Designing high-speed
XAPP688 (v1.2) May 3, 2004 R Application Note: Virtex-II Families Creating High-Speed Memory Interfaces with Virtex-II and Virtex-II Pro FPGAs Author: Nagesh Gupta, Maria George Summary Designing high-speed
EFFICIENT AUTOMATED SYNTHESIS, PROGRAMING, AND IMPLEMENTATION OF MULTI-PROCESSOR PLATFORMS ON FPGA CHIPS. Hristo Nikolov Todor Stefanov Ed Deprettere
 EFFICIENT AUTOMATED SYNTHESIS, PROGRAMING, AND IMPLEMENTATION OF MULTI-PROCESSOR PLATFORMS ON FPGA CHIPS Hristo Nikolov Todor Stefanov Ed Deprettere Leiden Embedded Research Center Leiden Institute of
EFFICIENT AUTOMATED SYNTHESIS, PROGRAMING, AND IMPLEMENTATION OF MULTI-PROCESSOR PLATFORMS ON FPGA CHIPS Hristo Nikolov Todor Stefanov Ed Deprettere Leiden Embedded Research Center Leiden Institute of
FPGA Implementation of MIPS RISC Processor
 FPGA Implementation of MIPS RISC Processor S. Suresh 1 and R. Ganesh 2 1 CVR College of Engineering/PG Student, Hyderabad, India 2 CVR College of Engineering/ECE Department, Hyderabad, India Abstract The
FPGA Implementation of MIPS RISC Processor S. Suresh 1 and R. Ganesh 2 1 CVR College of Engineering/PG Student, Hyderabad, India 2 CVR College of Engineering/ECE Department, Hyderabad, India Abstract The
Large-Scale Network Simulation Scalability and an FPGA-based Network Simulator
 Large-Scale Network Simulation Scalability and an FPGA-based Network Simulator Stanley Bak Abstract Network algorithms are deployed on large networks, and proper algorithm evaluation is necessary to avoid
Large-Scale Network Simulation Scalability and an FPGA-based Network Simulator Stanley Bak Abstract Network algorithms are deployed on large networks, and proper algorithm evaluation is necessary to avoid
ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing
 ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing Daniel Chang Chris Jenkins, Philip Garcia, Syed Gilani, Paula Aguilera, Aishwarya Nagarajan, Michael Anderson, Matthew
ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing Daniel Chang Chris Jenkins, Philip Garcia, Syed Gilani, Paula Aguilera, Aishwarya Nagarajan, Michael Anderson, Matthew
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
A Device-Controlled Dynamic Configuration Framework Supporting Heterogeneous Resource Management
 A Device-Controlled Dynamic Configuration Framework Supporting Heterogeneous Resource Management H. Tan and R. F. DeMara Department of Electrical and Computer Engineering University of Central Florida
A Device-Controlled Dynamic Configuration Framework Supporting Heterogeneous Resource Management H. Tan and R. F. DeMara Department of Electrical and Computer Engineering University of Central Florida
Resolve: Generation of High Performance Sorting Architectures from High Level Synthesis
 Resolve: Generation of High Performance Sorting Architectures from High Level Synthesis Janarbek Matai, Dustin Richmond, Dajung Lee, Zac Blair, Qiongzhi Wu, Amin Abazari, Ryan Kastner Department of Computer
Resolve: Generation of High Performance Sorting Architectures from High Level Synthesis Janarbek Matai, Dustin Richmond, Dajung Lee, Zac Blair, Qiongzhi Wu, Amin Abazari, Ryan Kastner Department of Computer
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Adding the ILA Core to an Existing Design Lab
 Adding the ILA Core to an Existing Introduction This lab consists of adding a ChipScope Pro software ILA core with the Core Inserter tool and debugging a nonfunctioning design. The files for this lab are
Adding the ILA Core to an Existing Introduction This lab consists of adding a ChipScope Pro software ILA core with the Core Inserter tool and debugging a nonfunctioning design. The files for this lab are
Module 4c: Pipelining
 Module 4c: Pipelining R E F E R E N C E S : S T A L L I N G S, C O M P U T E R O R G A N I Z A T I O N A N D A R C H I T E C T U R E M O R R I S M A N O, C O M P U T E R O R G A N I Z A T I O N A N D A
Module 4c: Pipelining R E F E R E N C E S : S T A L L I N G S, C O M P U T E R O R G A N I Z A T I O N A N D A R C H I T E C T U R E M O R R I S M A N O, C O M P U T E R O R G A N I Z A T I O N A N D A
Enabling success from the center of technology. Interfacing FPGAs to Memory
 Interfacing FPGAs to Memory Goals 2 Understand the FPGA/memory interface Available memory technologies Available memory interface IP & tools from Xilinx Compare Performance Cost Resources Demonstrate a
Interfacing FPGAs to Memory Goals 2 Understand the FPGA/memory interface Available memory technologies Available memory interface IP & tools from Xilinx Compare Performance Cost Resources Demonstrate a
Vendor Agnostic, High Performance, Double Precision Floating Point Division for FPGAs
 Vendor Agnostic, High Performance, Double Precision Floating Point Division for FPGAs Presented by Xin Fang Advisor: Professor Miriam Leeser ECE Department Northeastern University 1 Outline Background
Vendor Agnostic, High Performance, Double Precision Floating Point Division for FPGAs Presented by Xin Fang Advisor: Professor Miriam Leeser ECE Department Northeastern University 1 Outline Background