MANY-CORE COMPUTING. 7-Oct Ana Lucia Varbanescu, UvA. Original slides: Rob van Nieuwpoort, escience Center
|
|
|
- Alvin Hubbard
- 5 years ago
- Views:
Transcription









1 MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center
2 Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics ( ) 3. Programming: advanced ( ) 4. Case study: LOFAR telescope with many-cores by Rob van Nieuwpoort ( )
3 What are many-cores? 3 From Wikipedia: A many-core processor is a multicore processor in which the number of cores is large enough that traditional multi-processor techniques are no longer efficient largely because of issues with congestion in supplying instructions and data to the many processors. In this course: Multi-core/many-core CPUs (GP)GPUs
4 What are many-cores 4 How many is many? Several tens of cores How are they different from multi-core CPUs? Non-uniform memory access (NUMA) Private memories Network-on-chip Examples Multi-core CPUs (48-core AMD magny-cours) Graphics Processing Units (GPUs) n GPGPU = general purpose programming on GPUs Server processors (Sun Niagara) HPC processors n Cell B.E. (PlayStation 3) n Intel Xeon Phi (aka Intel MIC, former Larrabee)
5 Today s Topics 5 Why do many-cores exist? History Hardware introduction Performance model: Arithmetic Intensity and Roofline
6 6 Why many-cores? Moore s law Many-cores in real-life



7 Moore s Law 7 Gordon Moore (co-founder of Intel) predicted in 1965 that the transistor density of semiconductor chips would double roughly every 18 months. The complexity for minimum component costs has increased at a rate of roughly a factor of two per year... Certainly over the short term this rate can be expected to continue, if not to increase... Electronics Magazine 1965
8 8 Transistor Counts (Intel)
9 Impact of device shrinking 9 Assume transistor size shrinks by a factor of x! Transistors per unit area: up by x*x Die size? Assume the same Clock rate? may go up by x because wires are shorter Raw computing power? Programs could go x*x*x times faster In reality? Power consumption, memory, parallelism impose stricter bounds!


10 Revolution in Processors 10 Chip density is continuing to increase about 2x every 2 years BUT Clock speed is not ILP is not Power is not
11 New ways to use transistors 11 Parallelism on-chip: multi-core processors Multicore revolution Every machine will soon be a parallel machine What about performance? Can applications use this parallelism? Do they have to be rewritten from scratch? Will all programmers have to be parallel programmers? New programming models are needed Try to hide complexity from most programmers
![Top500 [1/4] 12 State of the art in HPC (top500.](/docs-images/82/86241687/images/12-0.jpg "org) Trial for all new HPC architectures 195 cores/node!")
12 Top500 [1/4] 12 State of the art in HPC (top500.org) Trial for all new HPC architectures 195 cores/node! Accelerated! Accelerated!
![Top500 [2/4] 13 Performance is dominated by](/docs-images/82/86241687/images/13-0.jpg "multi-/many-cores Multi-core CPUs")
13 Top500 [2/4] 13 Performance is dominated by multi-/many-cores Multi-core CPUs Accelerators
![Top500 [3/4] 14 Accelerators?](/docs-images/82/86241687/images/14-0.jpg "Relatively low numbers High")
14 Top500 [3/4] 14 Accelerators? Relatively low numbers High performance impact

15 China's Tianhe-1A 15 #10 in top500 list June 2013 (#1 in Top500 in November 2010) pflops peak pflops max 14,336 Xeon X5670 processors 7168 Nvidia Tesla M2050 GPUs x 448 cores = 3,211,264 cores
 = 3.120.")
16 China's Tianhe-2 16 #1 in Top500 June pflops peak pflops max nodes = x (2 x Xeon IvyBridge + 3 x Xeon Phi) = cores ( => 195 cores/node)

17 17 Top500: prediction

18 18 GPUs vs. Top500

19 Why do we need many-cores? 19 T12 GT200 G80 NV30 NV40 G70 3GHz Dual Core P4 3GHz Core2 Duo 3GHz Xeon Quad

20 20 Why do we need many-cores?
21 21 Power efficiency

22 22 Graphics in 1980

23 23 Graphics in 2000

24 Realism of modern GPUs 24 v=bjdeipvpjgq&feature=pla yer_embedded#t=49s Courtesy techradar.com
25 Why do we need many-cores? 25 Performance Large scale parallelism Power Efficiency Use transistors more efficiently Price (GPUs) Game market is huge, bigger than Hollywood Mass production, economy of scale spotty teenagers pay for our HPC needs! Prestige Reach ExaFLOP by 2019
26 26 History

27 27 Intel







28 GPGPU History 28 Fermi 3B xtors GeForce 256 RIVA M xtors 3M xtors GeForce 3 60M xtors GeForce FX 125M xtors GeForce M xtors Current generation: NVIDIA Kepler 7.1 transistors More cores, more parallelism, more performance
29 GPGPU History 29 Use Graphics primitives for HPC Ikonas [England 1978] Pixel Machine [Potmesil & Hoffert 1989] Pixel-Planes 5 [Rhoades, et al. 1992] Programmable shaders, around 1998 DirectX / OpenGL Map application onto graphics domain! GPGPU Brook (2004), Cuda (2007), OpenCL (Dec 2008),...
30 CUDA C/C++ Continuous Innovation July 07 Nov 07 April 08 Aug 08 July 09 Nov 09 Mar 10 CUDA Toolkit 1.0 CUDA Toolkit 1.1 CUDA Visual Profiler 2.2 CUDA Toolkit 2.0 CUDA Toolkit 2.3 Parallel Nsight Beta CUDA Toolkit 3.0 C Compiler C Extensions Single Precision BLAS FFT SDK 40 examples Win XP 64 Atomics support Multi-GPU support cuda-gdb HW Debugger Double Precision Compiler Optimizations Vista 32/64 Mac OSX DP FFT Conversion intrinsics Performance enhancements C++ inheritance Fermi support Tools updates Driver / RT interop 3D Textures HW Interpolation




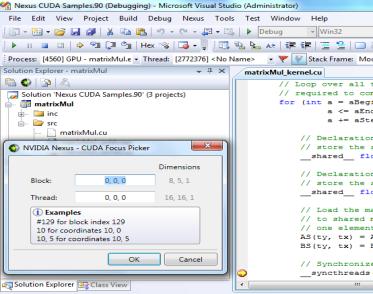
31 Cuda Tools 31 Parallel Nsight Visual Studio Visual Profiler For Linux cuda-gdb For Linux

32 32 Another GPGPU history

33 33 AMD
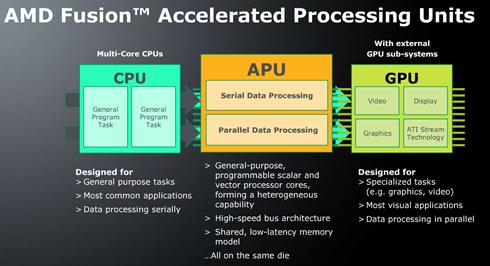
34 34 AMD
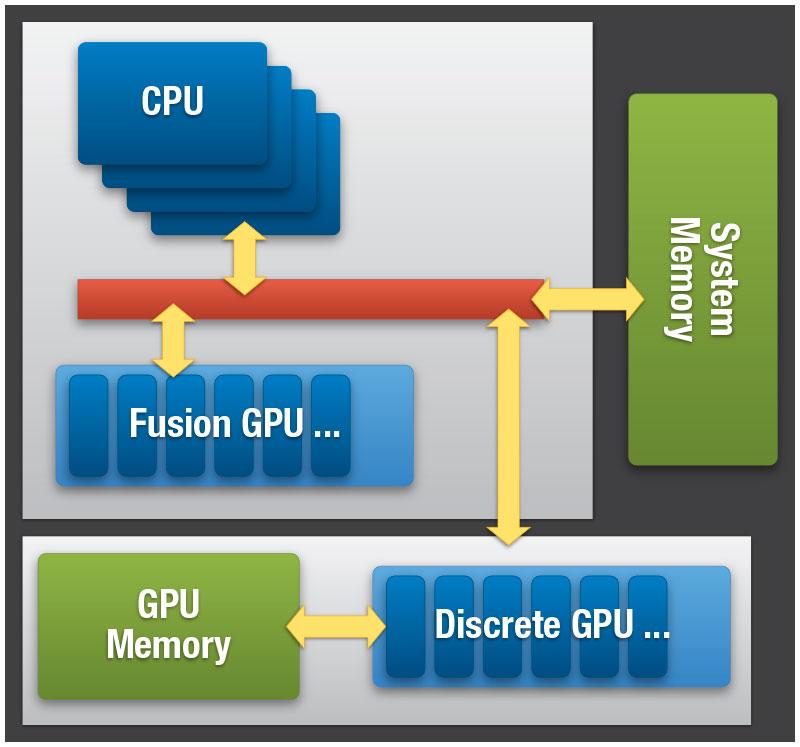
35 35 AMD

36 36 ARM
37 37 Many-core hardware
38 Choices 38 Core type(s): Fat or slim? Vectorized (SIMD)? Homogeneous or heterogeneous? Number of cores: Few or many? Memory Shared-memory or distributed-memory? Parallelism Instruction-level parallelism, threads, vectors,
39 A taxonomy 39 Based on field-of-origin : General-purpose n Intel, AMD Graphics Processing Units (GPUs) n NVIDIA, ATI Gaming/Entertainment n Sony/Toshiba/IBM Embedded systems n Philips/NXP, ARM Servers n Oracle, IBM, Intel High Performance Computing n Intel, IBM,
 Homogeneous Stand-alone Memory Shared,")
 Message passing Multi-threading")
40 General Purpose Processors 40 Architecture Few fat cores Vectorization (SSE, AVX) Homogeneous Stand-alone Memory Shared, multi-layered Per-core cache and shared cache Programming Processes (OS Scheduler) Message passing Multi-threading Coarse-grained parallelism


41 Server-side 41 General-purpose-like with more hardware threads Lower performance per thread high throughput Examples Sun Niagara II n 8 cores x 8 threads IBM POWER7 n 8 cores x 4 threads Intel SCC n 48 cores, all can run their own OS
42 Graphics Processing Units 42 Architecture Hundreds/thousands of slim cores Homogeneous Accelerator Memory Very complex hierarchy Both shared and per-core Programming Off-load model Many fine-grained symmetrical threads Hardware scheduler
 + 1 trimmed PowerPC (PPE) Memory Per-core memory, network-on-chip")
43 Cell/B.E. 43 Architecture Heterogeneous 8 vector-processors (SPEs) + 1 trimmed PowerPC (PPE) Memory Per-core memory, network-on-chip Programming User-controlled scheduling 6 levels of parallelism, all under user control Fine- and coarse-grain parallelism

44 Xeon Phi 44 Architecture ~60 homogeneous cores n 4 threads per core x86 architecture Memory Per-core caches (L1,L2) n Coherence UMA [?] Programming SPMD/MPMD Fine- and coarse-grain parallelism (vector processing and threads, respectively
45 Take home message 45 Variety of platforms Core types & counts Memory architecture & sizes Parallelism layers & types Scheduling Open questions: Why so many? How many platforms do we need? Can any application run on any platform?
46 46 Hardware performance metrics
![Hardware Performance metrics 47 Clock frequency [GHz] = absolute hardware speed Memories, CPUs, interconnects Operational speed [GFLOPs]](/docs-images/82/86241687/images/47-0.jpg "Operations per cycle Memory bandwidth [GB/s] differs a lot between different memories on chip Power [Watt] Derived metrics FLOP/Byte,")
47 Hardware Performance metrics 47 Clock frequency [GHz] = absolute hardware speed Memories, CPUs, interconnects Operational speed [GFLOPs] Operations per cycle Memory bandwidth [GB/s] differs a lot between different memories on chip Power [Watt] Derived metrics FLOP/Byte, FLOP/Watt
48 Theoretical peak performance 48 Peak = chips * cores * vectorwidth * FLOPs/cycle * clockfrequency Examples from DAS-4: Intel Core i7 CPU n 2 chips * 4 cores * 4-way vectors * 2 FLOPs/cycle * 2.4 GHz = 154 GFLOPs NVIDIA GTX 580 GPU n 1 chip * 16 SMs * 32 cores * 2 FLOPs/cycle * GhZ = 1581 GFLOPs ATI HD 6970 n 1 chip * 24 SIMD engines * 16 cores * 4-way vectors * 2 FLOPs/cycle * GhZ = 2703 GFLOPs
49 DRAM Memory bandwidth 49 Throughput = memory bus frequency * bits per cycle * bus width Memory clock!= CPU clock! In bits, divide by 8 for GB/s Examples: Intel Core i7 DDR3: * 2 * 64 = 21 GB/s NVIDIA GTX 580 GDDR5: * 4 * 384 = 192 GB/s ATI HD 6970 GDDR5: * 4 * 256 = 176 GB/s
50 Memory bandwidths 50 On-chip memory can be orders of magnitude faster Registers, shared memory, caches, E.g., AMD HD 7970 L1 cache achieves 2 TB/s Other memories: depends on the interconnect Intel s technology: QPI (Quick Path Interconnect) n 25.6 GB/s AMD s technology: HT3 (Hyper Transport 3) n 19.2 GB/s Accelerators: PCI-e 2.0 n 8 GB/s
51 Power 51 Chip manufactures specify Thermal Design Power (TDP) We can measure dissipated power Whole system Typically (much) lower than TDP Power efficiency FLOPS / Watt Examples (with theoretical peak and TDP) Intel Core i7: 154 / 160 = 1.0 GFLOPs/W NVIDIA GTX 580: ATI HD 6970: 1581 / 244 = 6.3 GFLOPs/W 2703 / 250 = 10.8 GFLOPs/W
52 Summary Cores Threads/ALUs GFLOPS Bandwidth FLOPs/Byte Sun Niagara IBM bg/p IBM Power Intel Core i AMD Barcelona AMD Istanbul AMD Magny-Cours Cell/B.E NVIDIA GTX NVIDIA GTX AMD HD AMD HD
53 Absolute hardware performance 53 Only achieved in the optimal conditions: Processing units 100% used All parallelism 100% exploited All data transfers at maximum bandwidth In real life No application is like this Can we reason about real performance?
54 54 Performance analysis Operational Intensity and the Roofline model
55 An Example 55 I am the CEO of SmartSoftwareSolutions. I have an application that runs on my old Pentium laptop in 2.5 hours. I want to hire you to use many-cores to improve the performance. Metrics I will judge candidates by: How fast can the application be: n Execution time => what the users are interested in! How many times faster can you make it: n Speed-up => use the best possible sequential performance How do I know I should chose you? n Achievable performance => reason how far the performance is n Depends on application, hardware, and dataset! Is this architecture a good one to use? n Utilization => did I really need this hardware?
56 Questions? Comments? 56 For questions, comments, suggestions, : A.L.Varbanescu@uva.nl
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
MANY-CORE COMPUTING. 10-Oct Ana Lucia Varbanescu, UvA. Original slides: Rob van Nieuwpoort, escience Center
 MANY-CORE COMPUTING 10-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics 2. Programming many-cores (10/10) 1. Performance
MANY-CORE COMPUTING 10-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics 2. Programming many-cores (10/10) 1. Performance
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU COMPUTING. Ana Lucia Varbanescu (UvA)
") GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5)
") PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5) Rob van Nieuwpoort Vrije Universiteit Amsterdam & Astron, the Netherlands Institute for Radio Astronomy Why Radio? Credit: NASA/IPAC
PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5) Rob van Nieuwpoort Vrije Universiteit Amsterdam & Astron, the Netherlands Institute for Radio Astronomy Why Radio? Credit: NASA/IPAC
Parallel programming: Introduction to GPU architecture
 Parallel programming: Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr http://www.irisa.fr/alf/collange/ PPAR - 2018 Outline of the course March
Parallel programming: Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr http://www.irisa.fr/alf/collange/ PPAR - 2018 Outline of the course March
From Brook to CUDA. GPU Technology Conference
 From Brook to CUDA GPU Technology Conference A 50 Second Tutorial on GPU Programming by Ian Buck Adding two vectors in C is pretty easy for (i=0; i
From Brook to CUDA GPU Technology Conference A 50 Second Tutorial on GPU Programming by Ian Buck Adding two vectors in C is pretty easy for (i=0; i
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GPU Computing Séminaire Calcul Hybride Aristote 25 Mars 2010
 NVIDIA GPU Computing 2010 Séminaire Calcul Hybride Aristote 25 Mars 2010 NVIDIA GPU Computing 2010 Tesla 3 rd generation Full OEM coverage Ecosystem focus Value Propositions per segments Card System Module
NVIDIA GPU Computing 2010 Séminaire Calcul Hybride Aristote 25 Mars 2010 NVIDIA GPU Computing 2010 Tesla 3 rd generation Full OEM coverage Ecosystem focus Value Propositions per segments Card System Module
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
Optimization Techniques for Parallel Code 2. Introduction to GPU architecture
 Optimization Techniques for Parallel Code 2. Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr OPT - 2017 What
Optimization Techniques for Parallel Code 2. Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr OPT - 2017 What
What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University. * slides thanks to Kavita Bala & many others
 What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University * slides thanks to Kavita Bala & many others Final Project Demo Sign-Up: Will be posted outside my office after lecture today.
What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University * slides thanks to Kavita Bala & many others Final Project Demo Sign-Up: Will be posted outside my office after lecture today.
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Multimedia in Mobile Phones. Architectures and Trends Lund
 Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
CONSOLE ARCHITECTURE
 CONSOLE ARCHITECTURE Introduction Part 1 What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design What
CONSOLE ARCHITECTURE Introduction Part 1 What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design What
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Introduction to GPU architecture
 Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr ADA - 2017 Graphics processing unit (GPU) GPU or GPU Graphics
Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr ADA - 2017 Graphics processing unit (GPU) GPU or GPU Graphics
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
John W. Romein. Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands
 Dwingeloo, the Netherlands") Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
General Purpose Computing on Graphical Processing Units (GPGPU(
 General Purpose Computing on Graphical Processing Units (GPGPU( / GPGP /GP 2 ) By Simon J.K. Pedersen Aalborg University, Oct 2008 VGIS, Readings Course Presentation no. 7 Presentation Outline Part 1:
General Purpose Computing on Graphical Processing Units (GPGPU( / GPGP /GP 2 ) By Simon J.K. Pedersen Aalborg University, Oct 2008 VGIS, Readings Course Presentation no. 7 Presentation Outline Part 1:
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Scaling through more cores
 Scaling through more cores From single to multi core by Thomas Walther Seminar on 30.11.2015 1/32 Index 1. Introduction 2. Scaling with single core until 2005 Problems and barriers 3. Solution through
Scaling through more cores From single to multi core by Thomas Walther Seminar on 30.11.2015 1/32 Index 1. Introduction 2. Scaling with single core until 2005 Problems and barriers 3. Solution through
ECE 571 Advanced Microprocessor-Based Design Lecture 20
 ECE 571 Advanced Microprocessor-Based Design Lecture 20 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 12 April 2016 Project/HW Reminder Homework #9 was posted 1 Raspberry Pi
ECE 571 Advanced Microprocessor-Based Design Lecture 20 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 12 April 2016 Project/HW Reminder Homework #9 was posted 1 Raspberry Pi
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Optimization Techniques for Parallel Code 3. Introduction to GPU architecture
 Optimization Techniques for Parallel Code 3. Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr OPT - 2018 Graphics
Optimization Techniques for Parallel Code 3. Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr OPT - 2018 Graphics
A Data-Parallel Genealogy: The GPU Family Tree. John Owens University of California, Davis
 A Data-Parallel Genealogy: The GPU Family Tree John Owens University of California, Davis Outline Moore s Law brings opportunity Gains in performance and capabilities. What has 20+ years of development
A Data-Parallel Genealogy: The GPU Family Tree John Owens University of California, Davis Outline Moore s Law brings opportunity Gains in performance and capabilities. What has 20+ years of development
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
GPGPU, 4th Meeting Mordechai Butrashvily, CEO GASS Company for Advanced Supercomputing Solutions
 GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
PARALLEL PROGRAMMING MANY-CORE COMPUTING FOR THE LOFAR TELESCOPE ROB VAN NIEUWPOORT. Rob van Nieuwpoort
 PARALLEL PROGRAMMING MANY-CORE COMPUTING FOR THE LOFAR TELESCOPE ROB VAN NIEUWPOORT Rob van Nieuwpoort rob@cs.vu.nl Who am I 10 years of Grid / Cloud computing 6 years of many-core computing, radio astronomy
PARALLEL PROGRAMMING MANY-CORE COMPUTING FOR THE LOFAR TELESCOPE ROB VAN NIEUWPOORT Rob van Nieuwpoort rob@cs.vu.nl Who am I 10 years of Grid / Cloud computing 6 years of many-core computing, radio astronomy
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Parallel programming: Introduction to GPU architecture. Sylvain Collange Inria Rennes Bretagne Atlantique
 Parallel programming: Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr Outline of the course Feb 29: Introduction to GPU architecture Let's pretend
Parallel programming: Introduction to GPU architecture Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr Outline of the course Feb 29: Introduction to GPU architecture Let's pretend
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First