The ICARUS white paper: A scalable, energy-efficient, solar-powered HPC center based on low power GPUs
|
|
|
- Erika Peters
- 6 years ago
- Views:
Transcription

1 The ICARUS white paper: A scalable, energy-efficient, solar-powered HPC center based on low power GPUs Markus Geveler, Dirk Ribbrock, Daniel Donner, Hannes Ruelmann, Christoph Höppke, David Schneider, Daniel Tomaschewski, Stefan Turek Unconventional HPC, EuroPar 2016, Grenoble, 2016 / 8 / 23 markus.geveler@math.tu-dortmund.de
2 Outline Introduction Simulation, Hardware-oriented numerics and energy-efficiency We are energy consumers and why we can not continue like this (Digital-)Computer hardware (in a general sense) of the future ICARUS Architecture and white sheet system integration of high-end photovoltaic-, battery- and embedded tech benchmarking of basic kernels and applications node level cluster level







3 Preface: what we usually do Simulation of technical flows with FEATFLOW Performance engineering for hardware efficiency numerical efficiency energy efficiency
4 Motivation Computers will require more energy than the world generates by 2040 "Conventional approaches are running into physical limits. Reducing the 'energy cost' of managing data on-chip requires coordinated research in new materials, devices, and architectures" - the Semiconductor Industry Association (SIA), 2015 world energy production 1E+21 J = 1000 Exajoule smaller transistors,... today's systems consumption future systems consumption E [J/year] 1E+14 J lower bound systems consumption (Landauer Limit)
5 Motivation What we can do enhance supplies enhance energy efficiency build renewable power source into system 1E+21 J = 1000 Exajoule higher production world energy production today's systems consumption future systems consumption E [J/year] 1E+14 J clever engineering (chip level), more EE in hardware (system level) lower bound systems consumption (Landauer Limit)
6 HPC Hardware Today's HPC facilities (?) Green500 list Nov 2015 Green 500 rank Top 500 rank Total power [kw] MFlops per watt Year Hardware architecture ExaScaler Brick, Xeon E5-2618Lv3 8C 2.3GHz, Infiniband FDR, PEZY-SC LX 1U-4GPU/104Re-1G Cluster, Intel Xeon E5-2620v2 6C 2.1GHz, Infiniband FDR, NVIDIA Tesla K ASUS ESC4000 FDR/G2S, Intel Xeon E5-2690v2 10C 3GHz, Infiniband FDR, AMD FirePro S Sugon Cluster W780I, Xeon E5-2640v3 8C 2.6GHz, Infiniband QDR, NVIDIA Tesla K Cray CS-Storm, Intel Xeon E5-2680v2 10C 2.8GHz, Infiniband FDR, Nvidia K Inspur TS10000 HPC Server, Xeon E5-2620v3 6C 2.4GHz, 10G Ethernet, NVIDIA Tesla K Inspur TS10000 HPC Server, Intel Xeon E5-2620v2 6C 2.1GHz, 10G Ethernet, NVIDIA Tesla K40 No Top500 top-scorer Top500 #1: 17,000 kw, 1,900 MFlop/s/W unconventional hardware
7 What we can expect from hardware Arithmetic Intensity (AI) copy2dram SpMV, Performance BLAS 1,2, FEM Lattice Methods stream bandwidth * AI GEMM theoretical peak performance AI = #flops / #bytes Particle Methods (close to peak performance)
8 Total efficiency of simulation software Aspects Numerical efficiency dominates asymptotic behaviour and wall clock time Hardware-efficiency exploit all levels of parallelism provided by hardware (SIMD, multithreading on a chip/device/socket, multiprocessing in a cluster, hybrids) then try to reach good scalability (communication optimisations, block comm/comp) Energy-efficiency by hardware: what is the most energy-efficient computer hardware? What is the best core frequency? What is the optimal number of cores used? by software as a direct result of performance but: its not all about performance Hardware-oriented Numerics: Enhance hardware- and numerical efficiency simultaneously, use (most) energy-efficient Hardware(-settings) where available! Attention: codependencies!
9 Hardware-oriented Numerics Energy Efficiency energy consumption/efficiency is one of the major challenges for future supercomputers 'exascale'-challenge in 2012 we proved: we can solve PDEs for less energy 'than normal' simply by switching computational hardware from commodity to embedded Tegra 2 (2x ARM Cortex A9) in the Tibidabo system of the MontBlanc project tradeoff between energy and wall clock time ~3x less energy ~5x more time!
10 Hardware-oriented Numerics Energy Efficiency To be more energy-efficient with different computational hardware, this hardware would have to dissipate less power at the same performance as the other! More performance per Watt! powerdown > speeddown ~3x less energy ~5x more time!
 is build upon the A15 core (higher frequency) and had more RAM and LPDDR3 instead of LPDDR2 Tegra K1 (32 Bit, late 2014) CPU pretty much like Tegra 4 but higher freq.")
11 Hardware-oriented Numerics Energy Efficiency: technology of ARM-based SoCs since 2012 Something has been happening in the mobile computing hardware evolution: Tegra 3 (late 2012) was also based on A9 but had 4 cores Tegra 4 (2013) is build upon the A15 core (higher frequency) and had more RAM and LPDDR3 instead of LPDDR2 Tegra K1 (32 Bit, late 2014) CPU pretty much like Tegra 4 but higher freq., more memory TK1 went GPGPU and comprises a programmable Kepler GPU on the same SoC! the promise: 350+ Gflop/s for less than 11W for comparison: Tesla K40 + x86 CPU: 4200 Gflop/s for 385W 2.5x higher EE promised interesting for Scientific Computing! Higher EE than commodity accelerator (of that time)! TU Dortmund


 specially tailored numerics,")
")
12 An off-grid compute center of the future Vision Insular Compute center for Applied Mathematics with Renewables-provided power supply based on Unconventional compute hardware empaired with Simulation Software for technical processes Motivation system integration for Scientific HPC high-end unconventional compute hardware high-end renewable power source (photovoltaic) specially tailored numerics, simulation software no future spendings due to energy consumtion SME-class resource: <80K Scalability, modular design (simplicity) (maintainability) (safety)...
: www.")
13 Cluster Whitesheet nodes: 60 x NVIDIA Jetson TK 1 #cores (ARM Cortex-A15): 240 #GPUs (Kepler, 192 cores): 60 RAM/core: 2GB LPDDR3 switches (GiBit Ethernet): 3xL1, 1xL2 cluster theoretical peak perf: ~20TFlop/s SP cluster peak power: < 1kW, provided by PV PV capacity: 8kWp battery: 8kWh Software: FEAT (optimised for Tegra K1):
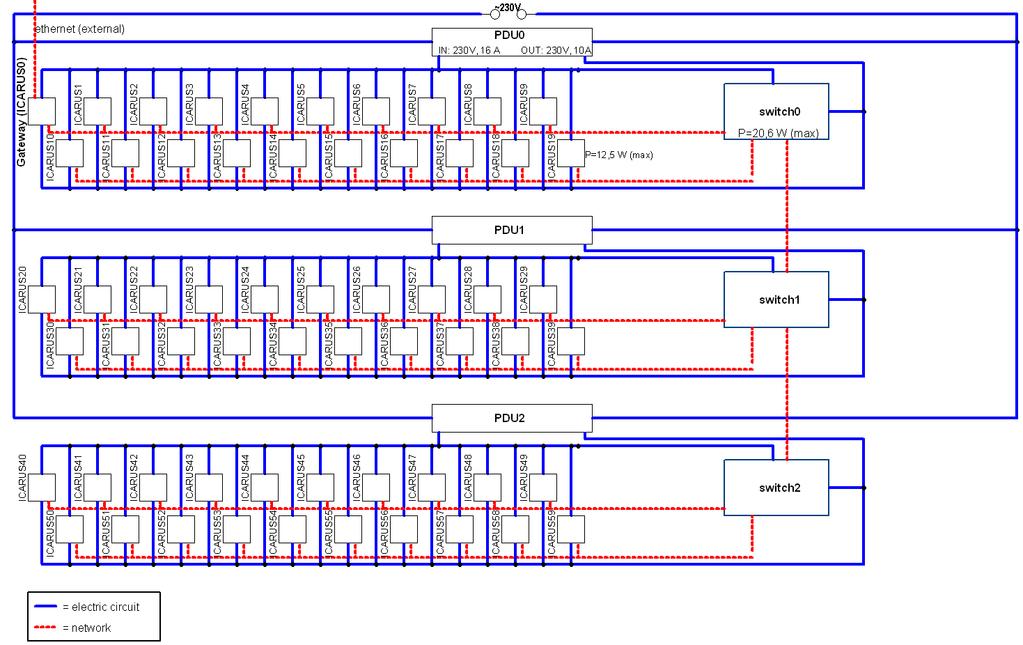
14 Cluster Architecture



 only")
15 Housing and power supply Photovoltaic units and battery rack primary: approx. 16m x 3m area, 8kWp secondary: for ventilation and cooling battery: Li-Ion, 8kWh 2 solar converters, 1 battery converter Modified overseas cargo container Steel Dry Cargo Container (High Cube) with dimensions 20 x 8 x 10 feet climate isolation (90mm) only connection to infrastructure: network cable
16 ICARUS compute hardware We can build better computers
 all power needed for")

17 Testhardware and measuring Complete 'box' measure power at AC-converter (inlet) all power needed for the node wikimedia wikimedia TU Dortmund Note: not a chip-to-chip comparison, but a system-to-system one
18 Sample results Compute-bound, CPU
19 Sample results Compute-bound, GPU
20 Sample results Memory bandwidth-bound, GPU




21 Sample results Applications, DG-FEM, single node
22 Sample results Applications, LBM, full cluster CPU GPU
23 Sample results Power supply
24 More experiences so far Reliability cluster operation since March Jetson boards 57 working permanently 4 with uncritical fan failure uptime: since first startup (almost), exept for maintenance Temperature on warm days (31 degrees Celsius external, 50% humidity): 33 degrees Celsius ambient temperature in container 35% relative humidity degrees Celsius on chip in idle mode approx. 68 degrees Celsius at load monitored by rack PDU sensors
25 Conclusion and outlook ICARUS built-in power source built-in ventilation, cooling, heating no infrastructure-needs (except for area) Jetson boards are 'cool': with the currently installed hardware, no additional cooling needed versatile: compute (or other-) hardware can be exchanged easily off-grid resource: can be deployed in areas with weak infrastructure: in developing nations/regions as secondary/emergency system
26 Conclusion and outlook To be very clear We do not see a future where Jetson TK 1 or similar boards are the compute nodes We wanted to show, that we can build compute hardware differently and for a certain kind of application, it works We showed, that system integration of renewables and compute tech is possible build renewable power source into system The future world energy production today's systems consumption future systems consumption E [J/year] Tegra X1,, or other commodity GPUs (?) collect data all year (weather!) learn how to improve all components lower bound systems consumption (Landauer Limit)
27 Thank you This work has been supported in part by the German Research Foundation (DFG) through the Priority Program 1648 Software for Exascale Computing (grant TU 102/48). ICARUS hardware is financed by MIWF NRW under the lead of MERCUR.
Energy efficiency of the simulation of three-dimensional coastal ocean circulation on modern commodity and mobile processors
 Energy efficiency of the simulation of three-dimensional coastal ocean circulation on modern commodity and mobile processors A case study based on the Haswell and Cortex-A15 microarchitectures Dominik
Energy efficiency of the simulation of three-dimensional coastal ocean circulation on modern commodity and mobile processors A case study based on the Haswell and Cortex-A15 microarchitectures Dominik
Realization of a low energy HPC platform powered by renewables - A case study: Technical, numerical and implementation aspects
 Realization of a low energy HPC platform powered by renewables - A case study: Technical, numerical and implementation aspects Markus Geveler, Stefan Turek, Dirk Ribbrock PACO Magdeburg 2015 / 7 / 7 markus.geveler@math.tu-dortmund.de
Realization of a low energy HPC platform powered by renewables - A case study: Technical, numerical and implementation aspects Markus Geveler, Stefan Turek, Dirk Ribbrock PACO Magdeburg 2015 / 7 / 7 markus.geveler@math.tu-dortmund.de
Performance engineering for hardware-, numericaland energy-efficiency in FEM frameworks: modeling and control
 Performance engineering for hardware-, numericaland energy-efficiency in FEM frameworks: modeling and control Hardware-oriented Numerics in the FEAT software family Markus Geveler Higher-order DG methods
Performance engineering for hardware-, numericaland energy-efficiency in FEM frameworks: modeling and control Hardware-oriented Numerics in the FEAT software family Markus Geveler Higher-order DG methods
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Total efficiency of core components in Finite Element frameworks
 Total efficiency of core components in Finite Element frameworks Markus Geveler Inst. for Applied Mathematics TU Dortmund University of Technology, Germany markus.geveler@math.tu-dortmund.de MAFELAP13:
Total efficiency of core components in Finite Element frameworks Markus Geveler Inst. for Applied Mathematics TU Dortmund University of Technology, Germany markus.geveler@math.tu-dortmund.de MAFELAP13:
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Exploring the limits of mixed precision FEM based computations on the Tegra-K1 micro-architecture
 Exploring the limits of mixed precision FEM based computations on the Tegra-K1 micro-architecture Christoph Höppke, Daniel Tomaschewski TU Dortmund Date: 2016/06/01 Content 1 Mixed precision definition
Exploring the limits of mixed precision FEM based computations on the Tegra-K1 micro-architecture Christoph Höppke, Daniel Tomaschewski TU Dortmund Date: 2016/06/01 Content 1 Mixed precision definition
Prototyping in PRACE PRACE Energy to Solution prototype at LRZ
 Prototyping in PRACE PRACE Energy to Solution prototype at LRZ Torsten Wilde 1IP-WP9 co-lead and 2IP-WP11 lead (GSC-LRZ) PRACE Industy Seminar, Bologna, April 16, 2012 Leibniz Supercomputing Center 2 Outline
Prototyping in PRACE PRACE Energy to Solution prototype at LRZ Torsten Wilde 1IP-WP9 co-lead and 2IP-WP11 lead (GSC-LRZ) PRACE Industy Seminar, Bologna, April 16, 2012 Leibniz Supercomputing Center 2 Outline
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures
 Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Building supercomputers from commodity embedded chips
 http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
TSUBAME-KFC : Ultra Green Supercomputing Testbed
 TSUBAME-KFC : Ultra Green Supercomputing Testbed Toshio Endo,Akira Nukada, Satoshi Matsuoka TSUBAME-KFC is developed by GSIC, Tokyo Institute of Technology NEC, NVIDIA, Green Revolution Cooling, SUPERMICRO,
TSUBAME-KFC : Ultra Green Supercomputing Testbed Toshio Endo,Akira Nukada, Satoshi Matsuoka TSUBAME-KFC is developed by GSIC, Tokyo Institute of Technology NEC, NVIDIA, Green Revolution Cooling, SUPERMICRO,
Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing
 Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing Gaurav Mitra Andrew Haigh Luke Angove Anish Varghese Eric McCreath Alistair P. Rendell Research School of Computer Science Australian
Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing Gaurav Mitra Andrew Haigh Luke Angove Anish Varghese Eric McCreath Alistair P. Rendell Research School of Computer Science Australian
Managing Hardware Power Saving Modes for High Performance Computing
 Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr timo.minartz@informatik.uni-hamburg.de
Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr timo.minartz@informatik.uni-hamburg.de
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Exploiting CUDA Dynamic Parallelism for low power ARM based prototypes
 www.bsc.es Exploiting CUDA Dynamic Parallelism for low power ARM based prototypes Vishal Mehta Engineer, Barcelona Supercomputing Center vishal.mehta@bsc.es BSC/UPC CUDA Centre of Excellence (CCOE) Training
www.bsc.es Exploiting CUDA Dynamic Parallelism for low power ARM based prototypes Vishal Mehta Engineer, Barcelona Supercomputing Center vishal.mehta@bsc.es BSC/UPC CUDA Centre of Excellence (CCOE) Training
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
The Mont-Blanc Project
 http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
16th. Wu Feng. November synergy.cs.vt.edu
 16th Wu Feng November 2014 synergy.cs.vt.edu The Ul6mate Goal of The Green500 List Raise awareness in the energy efficiency of supercompu6ng. Drive energy efficiency as a first- order design constraint
16th Wu Feng November 2014 synergy.cs.vt.edu The Ul6mate Goal of The Green500 List Raise awareness in the energy efficiency of supercompu6ng. Drive energy efficiency as a first- order design constraint
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè. ARM64 and GPGPU
 E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè ARM64 and GPGPU 1 E4 Computer Engineering Company E4 Computer Engineering S.p.A. specializes in the manufacturing of high performance IT systems of medium
E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè ARM64 and GPGPU 1 E4 Computer Engineering Company E4 Computer Engineering S.p.A. specializes in the manufacturing of high performance IT systems of medium
Manycore and GPU Channelisers. Seth Hall High Performance Computing Lab, AUT
 Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Hybrid Warm Water Direct Cooling Solution Implementation in CS300-LC
 Hybrid Warm Water Direct Cooling Solution Implementation in CS300-LC Roger Smith Mississippi State University Giridhar Chukkapalli Cray, Inc. C O M P U T E S T O R E A N A L Y Z E 1 Safe Harbor Statement
Hybrid Warm Water Direct Cooling Solution Implementation in CS300-LC Roger Smith Mississippi State University Giridhar Chukkapalli Cray, Inc. C O M P U T E S T O R E A N A L Y Z E 1 Safe Harbor Statement
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
NVIDIA Jetson Platform Characterization
 NVIDIA Jetson Platform Characterization Hassan Halawa, Hazem A. Abdelhafez, Andrew Boktor, Matei Ripeanu The University of British Columbia {hhalawa, hazem, boktor, matei}@ece.ubc.ca Abstract. This study
NVIDIA Jetson Platform Characterization Hassan Halawa, Hazem A. Abdelhafez, Andrew Boktor, Matei Ripeanu The University of British Columbia {hhalawa, hazem, boktor, matei}@ece.ubc.ca Abstract. This study
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Heterogenous Computing
 Heterogenous Computing Fall 2018 CS, SE - Freshman Seminar 11:00 a 11:50a Computer Architecture What are the components of a computer? How do these components work together to perform computations? How
Heterogenous Computing Fall 2018 CS, SE - Freshman Seminar 11:00 a 11:50a Computer Architecture What are the components of a computer? How do these components work together to perform computations? How
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Brand-New Vector Supercomputer
 Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Planning for Liquid Cooling Patrick McGinn Product Manager, Rack DCLC
 Planning for Liquid Cooling -------------------------------- Patrick McGinn Product Manager, Rack DCLC February 3 rd, 2015 Expertise, Innovation & Delivery 13 years in the making with a 1800% growth rate
Planning for Liquid Cooling -------------------------------- Patrick McGinn Product Manager, Rack DCLC February 3 rd, 2015 Expertise, Innovation & Delivery 13 years in the making with a 1800% growth rate
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
PORTABLE AND SCALABLE SOLUTIONS FOR CFD ON MODERN SUPERCOMPUTERS
 PORTABLE AND SCALABLE SOLUTIONS FOR CFD ON MODERN SUPERCOMPUTERS Ricard Borrell Pol Head and Mass Transfer Technological Center cttc.upc.edu Termo Fluids S.L termofluids.co Barcelona Supercomputing Center
PORTABLE AND SCALABLE SOLUTIONS FOR CFD ON MODERN SUPERCOMPUTERS Ricard Borrell Pol Head and Mass Transfer Technological Center cttc.upc.edu Termo Fluids S.L termofluids.co Barcelona Supercomputing Center
HPC and the AppleTV-Cluster
 HPC and the AppleTV-Cluster Dieter Kranzlmüller, Karl Fürlinger, Christof Klausecker Munich Network Management Team Ludwig-Maximilians-Universität München (LMU) & Leibniz Supercomputing Centre (LRZ) Outline
HPC and the AppleTV-Cluster Dieter Kranzlmüller, Karl Fürlinger, Christof Klausecker Munich Network Management Team Ludwig-Maximilians-Universität München (LMU) & Leibniz Supercomputing Centre (LRZ) Outline
HPC projects. Grischa Bolls
 HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
in Action Fujitsu High Performance Computing Ecosystem Human Centric Innovation Innovation Flexibility Simplicity
 Fujitsu High Performance Computing Ecosystem Human Centric Innovation in Action Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Innovation Flexibility Simplicity INTERNAL USE ONLY 0 Copyright
Fujitsu High Performance Computing Ecosystem Human Centric Innovation in Action Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Innovation Flexibility Simplicity INTERNAL USE ONLY 0 Copyright
S THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE. Presenter: Louis Capps, Solution Architect, NVIDIA,
 S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
HP Update. Bill Mannel VP/GM HPC & Big Data Business Unit Apollo Servers
 Update Bill Mannel VP/GM C & Big Data Business Unit Apollo Servers The most exciting shifts of our time are underway Cloud Security Mobility Time to revenue is critical Big Data Decisions must be rapid
Update Bill Mannel VP/GM C & Big Data Business Unit Apollo Servers The most exciting shifts of our time are underway Cloud Security Mobility Time to revenue is critical Big Data Decisions must be rapid
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Multicore Computing and Scientific Discovery
 scientific infrastructure Multicore Computing and Scientific Discovery James Larus Dennis Gannon Microsoft Research In the past half century, parallel computers, parallel computation, and scientific research
scientific infrastructure Multicore Computing and Scientific Discovery James Larus Dennis Gannon Microsoft Research In the past half century, parallel computers, parallel computation, and scientific research
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
High Performance Computing on ARM
 C. Steinhaus C. Wedding christian.{wedding, steinhaus}@rwth-aachen.de February 12, 2015 Overview 1 Dense Linear Algebra 2 MapReduce 3 Spectral Methods 4 Structured Grids 5 Conclusion and future prospect
C. Steinhaus C. Wedding christian.{wedding, steinhaus}@rwth-aachen.de February 12, 2015 Overview 1 Dense Linear Algebra 2 MapReduce 3 Spectral Methods 4 Structured Grids 5 Conclusion and future prospect
Co-designing an Energy Efficient System
 Co-designing an Energy Efficient System Luigi Brochard Distinguished Engineer, HPC&AI Lenovo lbrochard@lenovo.com MaX International Conference 2018 Trieste 29.01.2018 Industry Thermal Challenges NVIDIA
Co-designing an Energy Efficient System Luigi Brochard Distinguished Engineer, HPC&AI Lenovo lbrochard@lenovo.com MaX International Conference 2018 Trieste 29.01.2018 Industry Thermal Challenges NVIDIA
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
HPC Cineca Infrastructure: State of the art and towards the exascale
 HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
On the efficiency of the Accelerated Processing Unit for scientific computing
 24 th High Performance Computing Symposium Pasadena, April 5 th 2016 On the efficiency of the Accelerated Processing Unit for scientific computing I. Said, P. Fortin, J.-L. Lamotte, R. Dolbeau, H. Calandra
24 th High Performance Computing Symposium Pasadena, April 5 th 2016 On the efficiency of the Accelerated Processing Unit for scientific computing I. Said, P. Fortin, J.-L. Lamotte, R. Dolbeau, H. Calandra
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Fast Hardware For AI
 Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Umeå University
 HPC2N: Introduction to HPC2N and Kebnekaise, 2017-09-12 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N
HPC2N: Introduction to HPC2N and Kebnekaise, 2017-09-12 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N
Umeå University
 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N HPC at a glance. HPC2N Abisko, Kebnekaise HPC Programming
HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N HPC at a glance. HPC2N Abisko, Kebnekaise HPC Programming
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
Barcelona Supercomputing Center
 www.bsc.es Barcelona Supercomputing Center Centro Nacional de Supercomputación EMIT 2016. Barcelona June 2 nd, 2016 Barcelona Supercomputing Center Centro Nacional de Supercomputación BSC-CNS objectives:
www.bsc.es Barcelona Supercomputing Center Centro Nacional de Supercomputación EMIT 2016. Barcelona June 2 nd, 2016 Barcelona Supercomputing Center Centro Nacional de Supercomputación BSC-CNS objectives:
Digital Signal Processor Supercomputing
 Digital Signal Processor Supercomputing ENCM 515: Individual Report Prepared by Steven Rahn Submitted: November 29, 2013 Abstract: Analyzing the history of supercomputers: how the industry arrived to where
Digital Signal Processor Supercomputing ENCM 515: Individual Report Prepared by Steven Rahn Submitted: November 29, 2013 Abstract: Analyzing the history of supercomputers: how the industry arrived to where
John W. Romein. Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands
 Dwingeloo, the Netherlands") Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
A176 Cyclone. GPGPU Fanless Small FF RediBuilt Supercomputer. IT and Instrumentation for industry. Aitech I/O
 The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS, and it consumes less than 17W at full load (8-10W at typical
The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS, and it consumes less than 17W at full load (8-10W at typical
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
THE LEADER IN VISUAL COMPUTING
 MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT
 7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
EE 7722 GPU Microarchitecture. Offered by: Prerequisites By Topic: Text EE 7722 GPU Microarchitecture. URL:
 00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics