Introduction to Parallel Programming for Multicore/Manycore Clusters
|
|
|
- Annabella Reynolds
- 5 years ago
- Views:
Transcription
1 duction to Parallel Programming for Multi/Many Clusters General duction Invitation to Supercomputing Kengo Nakajima Information Technology Center The University of Tokyo Takahiro Katagiri Information Technology Center Nagoya University
2 Motivation for Parallel Computing 2 (and this class) Large-scale parallel computer enables fast computing in large-scale scientific simulations with detailed models. Computational science develops new frontiers of science and engineering. Why parallel computing? faster & larger larger is more important from the view point of new frontiers of science & engineering, but faster is also important. + more complicated Ideal: Scalable Solving N x scale problem using N x computational resources during same computation time (weak scaling) Solving a fix-sized problem using N x computational resources in 1/N computation time (strong scaling)
3 3 Scientific Computing = SMASH Science Modeling Algorithm Software Hardware You have to learn many things. Collaboration (or Co-Design) will be important for future career of each of you, as a scientist and/or an engineer. You have to communicate with people with different backgrounds. It is more difficult than communicating with foreign scientists from same area. (Q): Computer Science, Computational Science, or Numerical Algorithms?
4 4 Supercomputers and Computational Science Overview of the Class


5 5 Computer & Central Processing Unit ( 中央処理装置 ): s used in PC and Supercomputers are based on same architecture GHz: Clock Rate Frequency: Number of operations by per second GHz -> 10 9 operations/sec Simultaneous 4-8 instructions per clock

6 6 Multi コア () Single 1 s/ Dual 2 s/ Quad 4 s/ GPU: Many O(10 1 )-O(10 2 ) s More and more s Parallel computing Oakleaf-FX at University of Tokyo: 16 s SPARC64 TM IXfx = Central part of Multi s with 4-8 s are popular Low Power
 s High Memory Bandwidth Cheap NO stand-alone operations Host needed")

7 7 GPU/Manys GPU:Graphic Processing Unit GPGPU: General Purpose GPU O(10 2 ) s High Memory Bandwidth Cheap NO stand-alone operations Host needed Programming: CUDA, OpenACC Intel Xeon/Phi: Many >60 s High Memory Bandwidth Unix, Fortran, C compiler Currently, host needed Stand-alone: Knights Landing
8 8 Parallel Supercomputers Multi s are connected through network
9 9 Supercomputers with Heterogeneous/Hybrid Nodes GPU Many GPU Many GPU Many GPU Many GPU Many C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C C
10 Performance of Supercomputers Performance of : Clock Rate FLOPS (Floating Point Operations per Second) Real Number Recent Multi 4-8 FLOPS per Clock (e.g.) Peak performance of a with 3GHz (or 8)=12(or 24) 10 9 FLOPS=12(or 24)GFLOPS 10 6 FLOPS= 1 Mega FLOPS = 1 MFLOPS 10 9 FLOPS= 1 Giga FLOPS = 1 GFLOPS FLOPS= 1 Tera FLOPS = 1 TFLOPS FLOPS= 1 Peta FLOPS = 1 PFLOPS FLOPS= 1 Exa FLOPS = 1 EFLOPS 10
11 Peak Performance of Reedbush-U Intel Xeon E v4 (Broadwell-EP) 2.1 GHz 16 DP (Double Precision) FLOP operations per Clock Peak Performance (1 ) = 33.6 GFLOPS Peak Performance 1-Socket, 18 s: GFLOPS 2-Sockets, 36 s: 1,209.6 GFLOPS 1-Node 11
12 TOP 500 List Ranking list of supercomputers in the world Performance (FLOPS rate) is measured by Linpack which solves large-scale linear equations. Since 1993 Updated twice a year (International Conferences in June and November) Linpack iphone version is available 12
13 PFLOPS: Peta (=10 15 ) Floating OPerations per Sec. Exa-FLOPS (=10 18 ) will be attained after
14 14 50 th TOP500 List (November, 2017) Site Computer/Year Vendor s R max (TFLOPS) R peak (TFLOPS) Power (kw) National Supercomputing Center in Wuxi, China National Supercomputing Center in Tianjin, China Swiss Natl. Supercomputer Center, Switzerland 4 JAMSTEC, JAPAN 5 6 Oak Ridge National Laboratory, USA Lawrence Livermore National Laboratory, USA 7 DOE/NNSA/LANL/SNL 8 DOE/SC/LBNL/NERSC USA 9 Joint Center for Advanced High Performance Computing, Japan 10 RIKEN AICS, Japan Sunway TaihuLight, Sunway MPP, Sunway SW C 1.45GHz, 2016 NRCPC Tianhe-2, Intel Xeon E5-2692, TH Express-2, Xeon Phi, 2013 NUDT Piz Daint Cray XC30/NVIDIA P100, 2013 Cray Gyoukou, ZettaScaler-2.2 HPC, Xeon D-1571, 2017, ExaScaler Titan Cray XK7/NVIDIA K20x, 2012 Cray Sequoia BlueGene/Q, 2011 IBM Trinity, Cray XC40 Intel Xeon Phi C 1.4GHz, Cray Aries, 2017, Cray Cori, Cray XC40, Intel Xeon Phi C 1.4GHz, Cray Aries, 2016 Cray Oakforest-PACS, PRIMERGY CX600 M1, Intel Xeon Phi Processor C 1.4GHz, Intel Omni-Path, 2016 Fujitsu K computer, SPARC64 VIIIfx, 2011 Fujitsu 10,649,600 3,120,000 93,015 (= 93.0 PF) 33,863 (= 33.9 PF) 125,436 15,371 54,902 17, ,760 19,590 33,863 2,272 19,860 19,136 28,192 1, ,640 17,590 27,113 8,209 1,572,864 17,173 20,133 7, ,968 14,137 43, ,400 14,015 27,881 3, ,056 13,555 24,914 2, ,024 10,510 11,280 12,660 R max : Performance of Linpack (TFLOPS) R peak : Peak Performance (TFLOPS), Power: kw
15 Computational Science The 3 rd Pillar of Science Theoretical & Experimental Science Computational Science The 3 rd Pillar of Science Simulations using Supercomputers Theoretical Computational Experimental 15


16 Methods for Scientific Computing Numerical solutions of PDE (Partial Diff. Equations) Grids, Meshes, Particles Large-Scale Linear Equations Finer meshes provide more accurate solutions 16


17 3D Simulations for Earthquake Generation Cycle San Andreas Faults, CA, USA Stress Accumulation at Transcurrent Plate Boundaries 17


18 Adaptive FEM: High-resolution needed at meshes with large deformation (large accumulation) 18



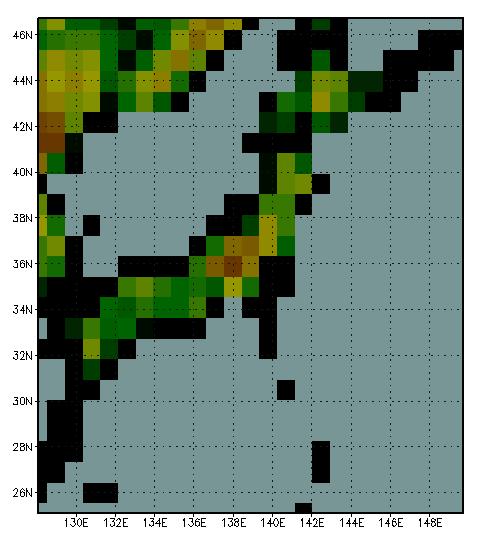
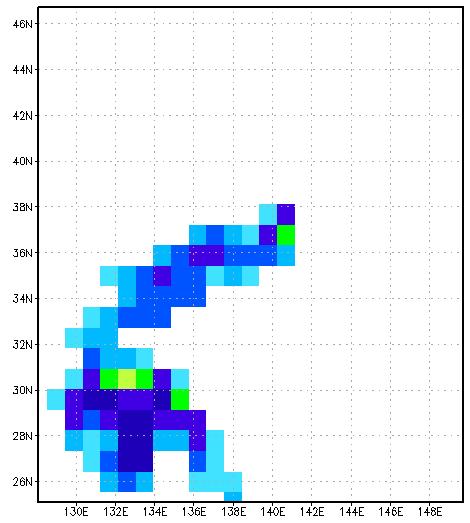
19 19 Typhoon Simulations by FDM Effect of Resolution h=100km h=50km h=5km [JAMSTEC]


20 20 Simulation of Typhoon MANGKHUT in 2003 using the Earth Simulator [JAMSTEC]
 through ppopenimath/mp on")

.")
21 1 Atmosphere-Ocean Coupling on OFP by NICAM/COCO/ppOpen-MATH/MP 21 Highiresolution global atmosphereiocean coupled simulation by NICAM and COCO (Ocean Simulation) through ppopenimath/mp on the K computer is achieved. ppopenimath/mp is a coupling software for the models employing various discretization method. An O(km)imesh NICAMiCOCO coupled simulation is planned on the OakforestiPACS system (3.5kmi0.10deg., 5+B Meshes). A big challenge for optimization of the codes on new Intel Xeon Phi processor New insights for understanding of global climate dynamics [C/O M. Satoh (AORI/UTokyo)@SC16]

22 22 El Niño Simulations (1/2) U.Tokyo, RIKEN Mechanism of the Abrupt Terminate of Super El Niño in 1997/1998 has been investigated by Atmosphere- Ocean Coupling Simulations for the Entire Earth using ppopen-hpc on the K computer
 event remotely accelerates ocean upwelling to abruptly terminate the 1997/1998 super El Niño NICAM (Atmosphere)-COCO (Ocean) Coupling by ppopen-")
23 El Niño Simulations (2/2) U.Tokyo, RIKEN 23 A Madden-Julian Oscillation (MJO) event remotely accelerates ocean upwelling to abruptly terminate the 1997/1998 super El Niño NICAM (Atmosphere)-COCO (Ocean) Coupling by ppopen- MATH/MP ppopen- MATH/MP Data Assimilation + Simulations Integration of Simulations + Data Analyses NICAM: 14km COCO deg. on K Next Target: 3.5km-0.10 deg. (5B Meshes) on OFP
24 24 2 Simulation of Geologic CO 2 Storage [Dr. Hajime Yamamoto, Taisei]
 JAMSTEC (Earth Simulator Center) (Software, Hardware) NEC (Software, Hardware) 2010 Japan Geotechnical Society (JGS)")
25 25 Simulation of Geologic CO 2 Storage International/Interdisciplinary Collaborations Taisei (Science, Modeling) Lawrence Berkeley National Laboratory, USA (Modeling) Information Technology Center, the University of Tokyo (Algorithm, Software) JAMSTEC (Earth Simulator Center) (Software, Hardware) NEC (Software, Hardware) 2010 Japan Geotechnical Society (JGS) Award
26 Simulation of Geologic CO 2 Storage 26 Science Behavior of CO 2 in supercritical state at deep reservoir PDE s 3D Multiphase Flow (Liquid/Gas) + 3D Mass Transfer Method for Computation TOUGH2 code based on FVM, and developed by Lawrence Berkeley National Laboratory, USA More than 90% of computation time is spent for solving large-scale linear equations with more than 10 7 unknowns Numerical Algorithm Fast algorithm for large-scale linear equations developed by Information Technology Center, the University of Tokyo Supercomputer Earth Simulator II (NEX SX9, JAMSTEC, 130 TFLOPS) Oakleaf-FX (Fujitsu PRIMEHP FX10, U.Tokyo, 1.13 PFLOPS

27 Diffusion-Dissolution-Convection Process Injection Well Caprock(Low permeable seal) Supercritical CO 2 Convective Mixing Buoyant scco 2 overrides onto groundwater Dissolution of CO 2 increases water density Denser fluid laid on lighter fluid Rayleigh-Taylor instability invokes convective mixing of groundwater The mixing significantly enhances the CO 2 dissolution into groundwater, resulting in more stable storage Preliminary 2D simulation (Yamamoto et al., GHGT11) [Dr. Hajime Yamamoto, Taisei] COPYRIGHT TAISEI CORPORATION ALL RIGHTS RESERVED 27

![Hajime Yamamoto, Taisei] The meteriscale fingers gradually developed to larger ones in the fieldiscale model Huge number](/docs-images/95/126343999/images/28-2.jpg "of time steps (> 10 5 ) were required to complete the 1,000iyrs simulation Onset time (10i20 yrs) is comparable to")
28 Density convections for 1,000 years: Flow Model Only the far side of the vertical cross section passing through the injection well is depicted. [Dr. Hajime Yamamoto, Taisei] The meteriscale fingers gradually developed to larger ones in the fieldiscale model Huge number of time steps (> 10 5 ) were required to complete the 1,000iyrs simulation Onset time (10i20 yrs) is comparable to theoretical (linear stability analysis, 15.5yrs) COPYRIGHT TAISEI CORPORATION ALL RIGHTS RESERVED 28

29 Calculation Time (sec) Simulation of Geologic CO 2 Storage 30 million DoF (10 million grids 3 DoF/grid node) Average time for solving matrix for one time step Number of Processors TOUGH2-MP on FX10 2i3 times speedup [Dr. Hajime Yamamoto, Taisei] Fujitsu FX10(Oakleaf-FX),30M DOF: 2x-3x improvement 3D Multiphase Flow (Liquid/Gas) + 3D Mass Transfer COPYRIGHT TAISEI CORPORATION ALL RIGHTS RESERVED 29
 up to 17,179,869,184 meshes (64 3 meshes/) Linear")

30 3 3D Ground Water Flow Simulation with up to 4,096 nodes on Fujitsu 30 FX10 (GMG-CG) up to 17,179,869,184 meshes (64 3 meshes/) Linear equations with 17B unknowns can be solved in 7 sec HB 8x2:C0 HB 8x2:C1 HB 8x2:C2 HB 8x2:C3 sec CORE#
31 Motivation for Parallel Computing 31 again Large-scale parallel computer enables fast computing in large-scale scientific simulations with detailed models. Computational science develops new frontiers of science and engineering. Why parallel computing? faster & larger larger is more important from the view point of new frontiers of science & engineering, but faster is also important. + more complicated Ideal: Scalable Solving N x scale problem using N x computational resources during same computation time (weak scaling) Solving a fix-sized problem using N x computational resources in 1/N computation time (strong scaling)
32 32 Supercomputers and Computational Science Overview of the Class
33 33 Goal of SC4SC 2018 If you want to do something on supercomputers, you have to learn parallel programming!! duction to MPI & OpenMP MPI: Message Passing Interface grab the idea of SPMD (Single-Program Multiple-Data) OpenMP: Multithreading Parallel Application Finite-Volume Method (FVM): We start at this part Data Structure for Parallel Computing Parallel FVM by OpenMP Parallel FVM by OpenMP/MPI Hybrid
34 34 Structure of this Short Course Feb. 22 (Th) Feb. 23 (F) Part-I (Katagiri): duction to OpenMP & MPI Feb. 24 (Sa) Feb. 25 (Su) Part-II (Nakajima): Parallel FVM
35 PE: Processing Element Processor, Domain, Process SPMD mpirun -np M <Program> You understand 90% MPI, if you understand this figure. 35 PE #0 PE #1 PE #2 PE #M-1 Program Program Program Program Data #0 Data #1 Data #2 Data #M-1 Each process does same operation for different data Large-scale data is decomposed, and each part is computed by each process It is ideal that parallel program is not different from serial one except communication.
36 36 Our Current Target: Multi Cluster Multi s are connected through network Memory Memory Memory Memory Memory OpenMP Multithreading Intra Node (Intra ) Shared Memory MPI Message Passing Inter Node (Inter ) Distributed Memory
37 37 Our Current Target: Multi Cluster Multi s are connected through network Memory Memory Memory Memory Memory OpenMP Multithreading Intra Node (Intra ) Shared Memory MPI Message Passing Inter Node (Inter ) Distributed Memory
38 38 Flat MPI vs. Hybrid Flat-MPI:Each -> Independent MPI only Intra/Inter Node memory memory memory Hybrid:Hierarchal Structure OpenMP MPI memory memory memory
39 39 Example of OpnMP/MPI Hybrid Sending Messages to Neighboring Processes MPI: Message Passing, OpenMP: Threading with Directives!C!C SEND do neib= 1, NEIBPETOT II= (LEVEL-1)*NEIBPETOT istart= STACK_EXPORT(II+neib-1) inum = STACK_EXPORT(II+neib ) - istart!$omp parallel do do k= istart+1, istart+inum WS(k-NE0)= X(NOD_EXPORT(k)) enddo call MPI_Isend (WS(istart+1-NE0), inum, MPI_DOUBLE_PRECISION, & & NEIBPE(neib), 0, MPI_COMM_WORLD, & & req1(neib), ierr) enddo
40 40 Experiences in Unix/Linux Prerequisites Experiences of programming (Fortran or C/C++) Fundamental numerical algorithms (Gaussian Elimination, LU Factorization, Jacobi/Gauss-Seidel/SOR Iterative Solvers) Experiences in SSH Public Key Authentication Method
41 41 Windows Preparation Cygwin: Please install gcc (C) or gfortran (Fortran) and SSH!! ParaView MacOS, UNIX/Linux ParaView Cygwin: ParaView:
Introduction to Parallel Programming for Multicore/Manycore Clusters
 Introduction to Parallel Programming for Multicore/Manycore Clusters General Introduction Invitation to Supercomputing Kengo Nakajima Information Technology Center The University of Tokyo Takahiro Katagiri
Introduction to Parallel Programming for Multicore/Manycore Clusters General Introduction Invitation to Supercomputing Kengo Nakajima Information Technology Center The University of Tokyo Takahiro Katagiri
Kengo Nakajima Information Technology Center, The University of Tokyo. SC15, November 16-20, 2015 Austin, Texas, USA
 ppopen-hpc Open Source Infrastructure for Development and Execution of Large-Scale Scientific Applications on Post-Peta Scale Supercomputers with Automatic Tuning (AT) Kengo Nakajima Information Technology
ppopen-hpc Open Source Infrastructure for Development and Execution of Large-Scale Scientific Applications on Post-Peta Scale Supercomputers with Automatic Tuning (AT) Kengo Nakajima Information Technology
Introduction to Parallel Programming for Multicore/Manycore Clusters Introduction
 duction to Parallel Programming for Multicore/Manycore Clusters Introduction Kengo Nakajima Information Technology Center The University of Tokyo 2 Motivation for Parallel Computing (and this class) Large-scale
duction to Parallel Programming for Multicore/Manycore Clusters Introduction Kengo Nakajima Information Technology Center The University of Tokyo 2 Motivation for Parallel Computing (and this class) Large-scale
Introduction to Parallel Programming for Multicore/Manycore Clusters Introduction
 duction to Parallel Programming for Multicore/Manycore Clusters Introduction Kengo Nakajima & Tetsuya Hoshino Information Technology Center The University of Tokyo Motivation for Parallel Computing 2 (and
duction to Parallel Programming for Multicore/Manycore Clusters Introduction Kengo Nakajima & Tetsuya Hoshino Information Technology Center The University of Tokyo Motivation for Parallel Computing 2 (and
Introduction to Parallel Programming for Multicore/Manycore Clusters
 duction to Parallel Programming for Multicore/Manycore Clusters duction Kengo Nakajima Information Technology Center The University of Tokyo http://nkl.cc.u-tokyo.ac.jp/18s/ 2 Descriptions of the Class
duction to Parallel Programming for Multicore/Manycore Clusters duction Kengo Nakajima Information Technology Center The University of Tokyo http://nkl.cc.u-tokyo.ac.jp/18s/ 2 Descriptions of the Class
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle
 Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron 140TFLOPS, 31.3TB
Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron 140TFLOPS, 31.3TB
Introduction to Parallel Programming for Multicore/Manycore Clusters Part II-3: Parallel FVM using MPI
 Introduction to Parallel Programming for Multi/Many Clusters Part II-3: Parallel FVM using MPI Kengo Nakajima Information Technology Center The University of Tokyo 2 Overview Introduction Local Data Structure
Introduction to Parallel Programming for Multi/Many Clusters Part II-3: Parallel FVM using MPI Kengo Nakajima Information Technology Center The University of Tokyo 2 Overview Introduction Local Data Structure
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Overview of Reedbush-U How to Login
 Overview of Reedbush-U How to Login Information Technology Center The University of Tokyo http://www.cc.u-tokyo.ac.jp/ Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 11 12 13 14 15 16 17 18
Overview of Reedbush-U How to Login Information Technology Center The University of Tokyo http://www.cc.u-tokyo.ac.jp/ Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 11 12 13 14 15 16 17 18
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Multigrid Method using OpenMP/MPI Hybrid Parallel Programming Model on Fujitsu FX10
 Multigrid Method using OpenMP/MPI Hybrid Parallel Programming Model on Fujitsu FX0 Kengo Nakajima Information Technology enter, The University of Tokyo, Japan November 4 th, 0 Fujitsu Booth S Salt Lake
Multigrid Method using OpenMP/MPI Hybrid Parallel Programming Model on Fujitsu FX0 Kengo Nakajima Information Technology enter, The University of Tokyo, Japan November 4 th, 0 Fujitsu Booth S Salt Lake
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Communication-Computation Overlapping with Dynamic Loop Scheduling for Preconditioned Parallel Iterative Solvers on Multicore/Manycore Clusters
 Communication-Computation Overlapping with Dynamic Loop Scheduling for Preconditioned Parallel Iterative Solvers on Multicore/Manycore Clusters Kengo Nakajima, Toshihiro Hanawa Information Technology Center,
Communication-Computation Overlapping with Dynamic Loop Scheduling for Preconditioned Parallel Iterative Solvers on Multicore/Manycore Clusters Kengo Nakajima, Toshihiro Hanawa Information Technology Center,
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
3D Parallel FEM (III) Parallel Visualization using ppopen-math/vis
 Parallel Visualization using ppopen-math/vis") 3D Parallel FEM (III) Parallel Visualization using ppopen-math/vis Kengo Nakajima Technical & Scientific Computing I (4820-1027) Seminar on Computer Science I (4810-1204) Parallel FEM ppopen-hpc Open Source
3D Parallel FEM (III) Parallel Visualization using ppopen-math/vis Kengo Nakajima Technical & Scientific Computing I (4820-1027) Seminar on Computer Science I (4810-1204) Parallel FEM ppopen-hpc Open Source
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Overview of Reedbush-U How to Login
 Overview of Reedbush-U How to Login Information Technology Center The University of Tokyo http://www.cc.u-tokyo.ac.jp/ Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 08 09 10 11 12 13 14 15
Overview of Reedbush-U How to Login Information Technology Center The University of Tokyo http://www.cc.u-tokyo.ac.jp/ Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 08 09 10 11 12 13 14 15
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
2018/9/25 (1), (I) 1 (1), (I)
, (I) 1 (1), (I)") 2018/9/25 (1), (I) 1 (1), (I) 2018/9/25 (1), (I) 2 1. 2. 3. 4. 5. 2018/9/25 (1), (I) 3 1. 2. MPI 3. D) http://www.compsci-alliance.jp http://www.compsci-alliance.jp// 2018/9/25 (1), (I) 4 2018/9/25 (1),
2018/9/25 (1), (I) 1 (1), (I) 2018/9/25 (1), (I) 2 1. 2. 3. 4. 5. 2018/9/25 (1), (I) 3 1. 2. MPI 3. D) http://www.compsci-alliance.jp http://www.compsci-alliance.jp// 2018/9/25 (1), (I) 4 2018/9/25 (1),
Extreme Simulations on ppopen-hpc
 Extreme Simulations on ppopen-hpc Kengo Nakajima Information Technology Center The University of Tokyo Challenges in Extreme Engineering Algorithms ISC 16, June 20, 2016 Frankfurt am Main, Germany Summary
Extreme Simulations on ppopen-hpc Kengo Nakajima Information Technology Center The University of Tokyo Challenges in Extreme Engineering Algorithms ISC 16, June 20, 2016 Frankfurt am Main, Germany Summary
Overview of Supercomputer Systems. Supercomputing Division Information Technology Center The University of Tokyo
 Overview of Supercomputer Systems Supercomputing Division Information Technology Center The University of Tokyo Supercomputers at ITC, U. of Tokyo Oakleaf-fx (Fujitsu PRIMEHPC FX10) Total Peak performance
Overview of Supercomputer Systems Supercomputing Division Information Technology Center The University of Tokyo Supercomputers at ITC, U. of Tokyo Oakleaf-fx (Fujitsu PRIMEHPC FX10) Total Peak performance
ECE 574 Cluster Computing Lecture 2
 ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
High-Performance Computing - and why Learn about it?
 High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Overview of HPC and Energy Saving on KNL for Some Computations
 Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
Experiences in Optimizations of Preconditioned Iterative Solvers for FEM/FVM Applications & Matrix Assembly of FEM using Intel Xeon Phi
 Experiences in Optimizations of Preconditioned Iterative Solvers for FEM/FVM Applications & Matrix Assembly of FEM using Intel Xeon Phi Kengo Nakajima Supercomputing Research Division Information Technology
Experiences in Optimizations of Preconditioned Iterative Solvers for FEM/FVM Applications & Matrix Assembly of FEM using Intel Xeon Phi Kengo Nakajima Supercomputing Research Division Information Technology
3D Parallel FEM (III) Parallel Visualization using ppopen-math/vis
 Parallel Visualization using ppopen-math/vis") 3D Parallel FEM (III) Parallel Visualization using ppopen-math/vis Kengo Nakajima Programming for Parallel Computing (616-2057) Seminar on Advanced Computing (616-4009) ppopen HPC Open Source Infrastructure
3D Parallel FEM (III) Parallel Visualization using ppopen-math/vis Kengo Nakajima Programming for Parallel Computing (616-2057) Seminar on Advanced Computing (616-4009) ppopen HPC Open Source Infrastructure
Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC
 Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Towards Exascale Computing with the Atmospheric Model NUMA
 Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Fujitsu s Technologies to the K Computer
 Fujitsu s Technologies to the K Computer - a journey to practical Petascale computing platform - June 21 nd, 2011 Motoi Okuda FUJITSU Ltd. Agenda The Next generation supercomputer project of Japan The
Fujitsu s Technologies to the K Computer - a journey to practical Petascale computing platform - June 21 nd, 2011 Motoi Okuda FUJITSU Ltd. Agenda The Next generation supercomputer project of Japan The
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC
 A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
System Packaging Solution for Future High Performance Computing May 31, 2018 Shunichi Kikuchi Fujitsu Limited
 System Packaging Solution for Future High Performance Computing May 31, 2018 Shunichi Kikuchi Fujitsu Limited 2018 IEEE 68th Electronic Components and Technology Conference San Diego, California May 29
System Packaging Solution for Future High Performance Computing May 31, 2018 Shunichi Kikuchi Fujitsu Limited 2018 IEEE 68th Electronic Components and Technology Conference San Diego, California May 29
3D FEM for Solid Mechanics on Knights Landing and OmniPath Architecture
 3D FEM for Solid Mechanics on Knights Landing and OmniPath Architecture Toshihiro Hanawa Kengo Nakajima Satoshi Ohshima Informa8on Technology Center, The University of Tokyo U y =0 @ y=y min (N z -1) elements
3D FEM for Solid Mechanics on Knights Landing and OmniPath Architecture Toshihiro Hanawa Kengo Nakajima Satoshi Ohshima Informa8on Technology Center, The University of Tokyo U y =0 @ y=y min (N z -1) elements
Accelerated Computing Activities at ITC/University of Tokyo
 Accelerated Computing Activities at ITC/University of Tokyo Kengo Nakajima Information Technology Center (ITC) The University of Tokyo ADAC-3 Workshop January 25-27 2017, Kashiwa, Japan Three Major Campuses
Accelerated Computing Activities at ITC/University of Tokyo Kengo Nakajima Information Technology Center (ITC) The University of Tokyo ADAC-3 Workshop January 25-27 2017, Kashiwa, Japan Three Major Campuses
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
Performance of deal.ii on a node
 Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Overview of Supercomputer Systems. Supercomputing Division Information Technology Center The University of Tokyo
 Overview of Supercomputer Systems Supercomputing Division Information Technology Center The University of Tokyo Supercomputers at ITC, U. of Tokyo Oakleaf-fx (Fujitsu PRIMEHPC FX10) Total Peak performance
Overview of Supercomputer Systems Supercomputing Division Information Technology Center The University of Tokyo Supercomputers at ITC, U. of Tokyo Oakleaf-fx (Fujitsu PRIMEHPC FX10) Total Peak performance
CSE5351: Parallel Procesisng. Part 1B. UTA Copyright (c) Slide No 1
 Slide No 1") Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek
 1 HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse, b known, x computed. An optimized implementation
1 HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse, b known, x computed. An optimized implementation
3D Parallel FEM (V) Communication-Computation Overlapping
 Communication-Computation Overlapping") 3D Parallel FEM (V) Communication-Computation Overlapping Kengo Nakajima Programming for Parallel Computing (616-2057) Seminar on Advanced Computing (616-4009) 2 z Uniform Distributed Force in z-direction
3D Parallel FEM (V) Communication-Computation Overlapping Kengo Nakajima Programming for Parallel Computing (616-2057) Seminar on Advanced Computing (616-4009) 2 z Uniform Distributed Force in z-direction
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Overview. High Performance Computing - History of the Supercomputer. Modern Definitions (II)
") Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Confessions of an Accidental Benchmarker
 Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Introduction of Oakforest-PACS
 Introduction of Oakforest-PACS Hiroshi Nakamura Director of Information Technology Center The Univ. of Tokyo (Director of JCAHPC) Outline Supercomputer deployment plan in Japan What is JCAHPC? Oakforest-PACS
Introduction of Oakforest-PACS Hiroshi Nakamura Director of Information Technology Center The Univ. of Tokyo (Director of JCAHPC) Outline Supercomputer deployment plan in Japan What is JCAHPC? Oakforest-PACS
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
Overview of Supercomputer Systems. Supercomputing Division Information Technology Center The University of Tokyo
 Overview of Supercomputer Systems Supercomputing Division Information Technology Center The University of Tokyo Supercomputers at ITC, U. of Tokyo Oakleaf-fx (Fujitsu PRIMEHPC FX10) Total Peak performance
Overview of Supercomputer Systems Supercomputing Division Information Technology Center The University of Tokyo Supercomputers at ITC, U. of Tokyo Oakleaf-fx (Fujitsu PRIMEHPC FX10) Total Peak performance
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks
 An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek
 www.hpcg-benchmark.org 1 HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek www.hpcg-benchmark.org 2 HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse,
www.hpcg-benchmark.org 1 HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek www.hpcg-benchmark.org 2 HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse,
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
Report on the Sunway TaihuLight System. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
An Empirical Study of Computation-Intensive Loops for Identifying and Classifying Loop Kernels
 An Empirical Study of Computation-Intensive Loops for Identifying and Classifying Loop Kernels Masatomo Hashimoto Masaaki Terai Toshiyuki Maeda Kazuo Minami 26/04/2017 ICPE2017 1 Agenda Performance engineering
An Empirical Study of Computation-Intensive Loops for Identifying and Classifying Loop Kernels Masatomo Hashimoto Masaaki Terai Toshiyuki Maeda Kazuo Minami 26/04/2017 ICPE2017 1 Agenda Performance engineering
Current Status of the Next- Generation Supercomputer in Japan. YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN
 Current Status of the Next- Generation Supercomputer in Japan YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN International Workshop on Peta-Scale Computing Programming Environment, Languages
Current Status of the Next- Generation Supercomputer in Japan YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN International Workshop on Peta-Scale Computing Programming Environment, Languages
HPC and Big Data: Updates about China. Haohuan FU August 29 th, 2017
 HPC and Big Data: Updates about China Haohuan FU August 29 th, 2017 1 Outline HPC and Big Data Projects in China Recent Efforts on Tianhe-2 Recent Efforts on Sunway TaihuLight 2 MOST HPC Projects 2016
HPC and Big Data: Updates about China Haohuan FU August 29 th, 2017 1 Outline HPC and Big Data Projects in China Recent Efforts on Tianhe-2 Recent Efforts on Sunway TaihuLight 2 MOST HPC Projects 2016
Communication-Computation. 3D Parallel FEM (V) Overlapping. Kengo Nakajima
 Overlapping. Kengo Nakajima") 3D Parallel FEM (V) Communication-Computation Overlapping Kengo Nakajima Programming for Parallel Computing (616-2057) Seminar on Advanced Computing (616-4009) U y =0 @ y=y min (N z -1) elements N z nodes
3D Parallel FEM (V) Communication-Computation Overlapping Kengo Nakajima Programming for Parallel Computing (616-2057) Seminar on Advanced Computing (616-4009) U y =0 @ y=y min (N z -1) elements N z nodes
HPC Algorithms and Applications
 HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
Trends of Network Topology on Supercomputers. Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27
 Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Basic Specification of Oakforest-PACS
 Basic Specification of Oakforest-PACS Joint Center for Advanced HPC (JCAHPC) by Information Technology Center, the University of Tokyo and Center for Computational Sciences, University of Tsukuba Oakforest-PACS
Basic Specification of Oakforest-PACS Joint Center for Advanced HPC (JCAHPC) by Information Technology Center, the University of Tokyo and Center for Computational Sciences, University of Tsukuba Oakforest-PACS
Chapter 5 Supercomputers
 Chapter 5 Supercomputers Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 5 Supercomputers Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Update of Post-K Development Yutaka Ishikawa RIKEN AICS
 Update of Post-K Development Yutaka Ishikawa RIKEN AICS 11:20AM 11:40AM, 2 nd of November, 2017 FLAGSHIP2020 Project Missions Building the Japanese national flagship supercomputer, post K, and Developing
Update of Post-K Development Yutaka Ishikawa RIKEN AICS 11:20AM 11:40AM, 2 nd of November, 2017 FLAGSHIP2020 Project Missions Building the Japanese national flagship supercomputer, post K, and Developing
Experiences of the Development of the Supercomputers
 Experiences of the Development of the Supercomputers - Earth Simulator and K Computer YOKOKAWA, Mitsuo Kobe University/RIKEN AICS Application Oriented Systems Developed in Japan No.1 systems in TOP500
Experiences of the Development of the Supercomputers - Earth Simulator and K Computer YOKOKAWA, Mitsuo Kobe University/RIKEN AICS Application Oriented Systems Developed in Japan No.1 systems in TOP500
Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning
 5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
The Architecture and the Application Performance of the Earth Simulator
 The Architecture and the Application Performance of the Earth Simulator Ken ichi Itakura (JAMSTEC) http://www.jamstec.go.jp 15 Dec., 2011 ICTS-TIFR Discussion Meeting-2011 1 Location of Earth Simulator
The Architecture and the Application Performance of the Earth Simulator Ken ichi Itakura (JAMSTEC) http://www.jamstec.go.jp 15 Dec., 2011 ICTS-TIFR Discussion Meeting-2011 1 Location of Earth Simulator
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Accelerated Earthquake Simulations
 Accelerated Earthquake Simulations Alex Breuer Technische Universität München Germany 1 Acknowledgements Volkswagen Stiftung Project ASCETE: Advanced Simulation of Coupled Earthquake-Tsunami Events Bavarian
Accelerated Earthquake Simulations Alex Breuer Technische Universität München Germany 1 Acknowledgements Volkswagen Stiftung Project ASCETE: Advanced Simulation of Coupled Earthquake-Tsunami Events Bavarian
High Performance Linear Algebra
 High Performance Linear Algebra Hatem Ltaief Senior Research Scientist Extreme Computing Research Center King Abdullah University of Science and Technology 4th International Workshop on Real-Time Control
High Performance Linear Algebra Hatem Ltaief Senior Research Scientist Extreme Computing Research Center King Abdullah University of Science and Technology 4th International Workshop on Real-Time Control
Advanced Topics in Numerical Analysis: High Performance Computing
 Advanced Topics in Numerical Analysis: High Performance Computing MATH-GA 2012.001 & CSCI-GA 2945.001 Georg (Stadler) Courant Institute, NYU stadler@cims.nyu.edu Spring 2017, Thursday, 5:10 7:00PM, WWH
Advanced Topics in Numerical Analysis: High Performance Computing MATH-GA 2012.001 & CSCI-GA 2945.001 Georg (Stadler) Courant Institute, NYU stadler@cims.nyu.edu Spring 2017, Thursday, 5:10 7:00PM, WWH
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future
 Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
The Future of High- Performance Computing
 Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
High Performance Computing. What is it used for and why?
 High Performance Computing What is it used for and why? Overview What is it used for? Drivers for HPC Examples of usage Why do you need to learn the basics? Hardware layout and structure matters Serial
High Performance Computing What is it used for and why? Overview What is it used for? Drivers for HPC Examples of usage Why do you need to learn the basics? Hardware layout and structure matters Serial
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Emerging Heterogeneous Technologies for High Performance Computing
 MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics
 CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
Intro To Parallel Computing. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Intro To Parallel Computing John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want to orient
Intro To Parallel Computing John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want to orient
The ECMWF forecast model, quo vadis?
 The forecast model, quo vadis? by Nils Wedi European Centre for Medium-Range Weather Forecasts wedi@ecmwf.int contributors: Piotr Smolarkiewicz, Mats Hamrud, George Mozdzynski, Sylvie Malardel, Christian
The forecast model, quo vadis? by Nils Wedi European Centre for Medium-Range Weather Forecasts wedi@ecmwf.int contributors: Piotr Smolarkiewicz, Mats Hamrud, George Mozdzynski, Sylvie Malardel, Christian
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Memory Footprint of Locality Information On Many-Core Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25
 ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters