Intro To Parallel Computing. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
|
|
|
- Candice Smith
- 6 years ago
- Views:
Transcription
1 Intro To Parallel Computing John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
2 Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want to orient you a bit before parachuting you down into the trenches to deal with MPI. This talk bookends our technical content along with the Outro to Parallel Computing talk. The Intro has a strong emphasis on hardware, as this dictates the reasons that the software has the form and function that it has. Hopefully our programming constraints will seem less arbitrary. The Outro talk can discuss alternative software approaches in a meaningful way because you will then have one base of knowledge against which we can compare and contrast. The plan is that you walk away with a knowledge of not just MPI, etc. but where it fits into the world of High Performance Computing.
3 1 st Theme We need Exascale computing We aren t getting to Exascale without parallel What does parallel computing look like Where is this going



4 FLOPS we need: Climate change analysis Simulations Cloud resolution, quantifying uncertainty, understanding tipping points, etc., will drive climate to exascale platforms New math, models, and systems support will be needed Courtesy Horst Simon, LBNL Extreme data Reanalysis projects need 100 more computing to analyze observations Machine learning and other analytics are needed today for petabyte data sets Combined simulation/observation will empower policy makers and scientists

5 Qualitative Improvement of Simulation with Higher Resolution (2011) Michael Wehner, Prabhat, Chris Algieri, Fuyu Li, Bill Collins, Lawrence Berkeley National Laboratory; Kevin Reed, University of Michigan; Andrew Gettelman, Julio Bacmeister, Richard Neale, National Center for Atmospheric Research





")



6 Exascale combustion simulations Goal: 50% improvement in engine efficiency Center for Exascale Simulation of Combustion in Turbulence (ExaCT) Combines simulation and experimentation Uses new algorithms, programming models, and computer science Courtesy Horst Simon, LBNL








7 Modha Group at IBM Almaden Mouse Rat Cat Monkey Human N: 16 x x x x x 10 9 S: 128 x x x x x Almaden Watson WatsonShaheen LLNL Dawn Recent simulations achieve unprecedented scale of 65*10 9 neurons and 16*10 12 synapses LLNL Sequoia BG/L BG/L BG/P BG/P BG/Q December, 2006 April, 2007 March, 2009 May, 2009 June, 2012 Courtesy Horst Simon, LBNL


8 Also important: We aren t going to be left behind. Data from TOP500.org; Figure from Science; Vol 335; 27 January 2012 Courtesy Horst Simon, LBNL
9 2 nd Theme We will have Exascale computing You aren t getting to Exascale without going very parallel What does parallel computing look like Where is this going
10 Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt data




 2 4 8 16 32 64")

11 Moore s Law is not at all dead Intel process technology capabilities High Volume Manufacturing Feature Size 90nm 65nm 45nm 32nm 22nm 16nm 11nm 8nm Integration Capacity (Billions of Transistors) nm Transistor for 90nm Process Source: Intel Influenza Virus Source: CDC
12 At end of day, we keep using all those new transistors. Courtesy Horst Simon, LBNL
13 That Power and Clock Inflection Point in 2004 didn t get better. Fun fact: At 100+ Watts and <1V, currents are beginning to exceed 100A at the point of load! Source: Kogge and Shalf, IEEE CISE Courtesy Horst Simon, LBNL

14 Not a new problem, just a new scale CPU Power W) Cray-2 with cooling tower in foreground, circa 1985
15 And how to get more performance from more transistors with the same power. A 15% Reduction In Voltage Yields RULE OF THUMB Frequency Power Performance Reduction Reduction Reduction 15% 45% 10% SINGLE CORE DUAL CORE Area = 1 Voltage = 1 Freq = 1 Power = 1 Perf = 1 Area = 2 Voltage = 0.85 Freq = 0.85 Power = 1 Perf = ~1.8
16 Single Socket Parallelism Processor Year Vector Bits SP FLOPs / core / cycle Cores FLOPs/cycle Pentium III 1999 SSE Pentium IV 2001 SSE Core 2006 SSE Nehalem 2008 SSE Sandybridge 2011 AVX Haswell 2013 AVX KNC 2012 AVX KNL 2016 AVX Skylake 2017 AVX
17 3 rd Theme We will have Exascale computing You will get there by going very parallel What does parallel computing look like? Where is this going
18 Parallel Computing One woman can make a baby in 9 months. Can 9 woman make a baby in 1 month? But 9 women can make 9 babies in 9 months. First two bullets are Brook s Law. From The Mythical Man-Month.

19 Prototypical Application: Serial Weather Model CPU MEMORY

20 First Parallel Weather Modeling Algorithm: Richardson in 1917 Courtesy John Burkhardt, Virginia Tech

21 Weather Model: Shared Memory (OpenMP) Core Core Core Core MEMORY Four meteorologists in the same room sharing the map.

")



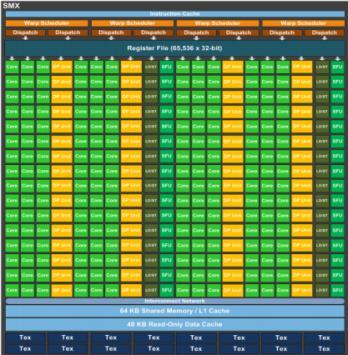
22 Weather Model: Accelerator (OpenACC) CPU Memory GPU Memory PCI Bus CPU GPU 1 meteorologist coordinating 1000 math savants using tin cans and a string.

23 Weather Model: Distributed Memory (MPI) MEMORY CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory CPU & Memory 50 meteorologists using telegraphs.
24 The pieces fit like this OpenACC MPI OpenMP
25 Many Levels and Types of Parallelism Vector (SIMD) Instruction Level (ILP) Instruction pipelining Superscaler (multiple instruction units) Out-of-order Register renaming Speculative execution Branch prediction Compiler (not your problem) OpenMP OpenACC MPI Multi-Core (Threads) SMP/Multi-socket Accelerators: GPU & MIC Clusters MPPs Also Important ASIC/FPGA/DSP RAID/IO
26 I will try to use the term PE consistently myself, but I may slip up. Get used to it as you will quite often hear all of the above terms used interchangeably where they shouldn t be. Context usually makes it clear. Cores, Nodes, Processors, PEs? Nodes is used to refer to an actual physical unit with a network connection; usually a circuit board or "blade" in a cabinet. These often have multiple processors. Processors refer to a physical chip. Today these almost always have more than one core. A core can run an independent thread of code. Hence the temptation to refer to it as a processor. To avoid this ambiguity, it is precise to refer to the the smallest useful computing device as a Processing Element, or PE. On normal processors this corresponds to a core.

27 Multi-socket Motherboards Dual and Quad socket boards are very common in the enterprise and HPC world. Less desirable in consumer world.

28 Shared-Memory Processing at Extreme Scale Programming OpenMP, Pthreads, Shmem Examples All multi-socket motherboards SGI UV (Blacklight!) Intel Xeon 8 dual core processors linked by the UV interconnect 4096 cores sharing 32 TB of memory As big as it gets right now
 Sequoia (LLNL) 16.")


29 MPPs (Massively Parallel Processors) Distributed memory at largest scale. Often shared memory at lower level. Titan (ORNL) Sequoia (LLNL) petaflops Rmax and petaflops Rpeak IBM Blue Gene/Q 98,304 compute nodes AMD Opteron 6274 processors (Interlagos) 560,640 cores Gemini interconnect (3-D Torus) Accelerated node design using NVIDIA multi-core accelerators 20+ PFlops peak system performance 1.6 million processor cores 1.6 PB of memory


30 Networks 3 characteristics sum up the network: Latency The time to send a 0 byte packet of data on the network Bandwidth The rate at which a very large packet of information can be sent Topology The configuration of the network that determines how processing units are directly connected.

31 Ethernet with Workstations
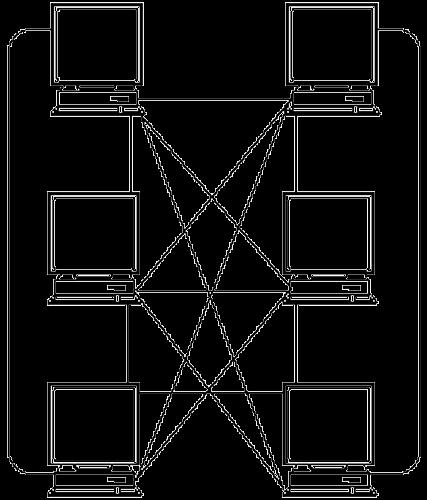

32 Complete Connectivity
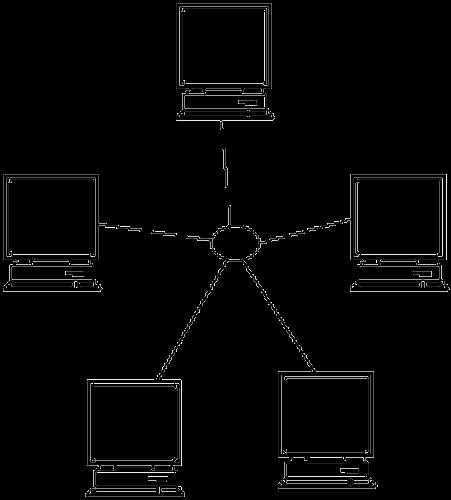

33 Crossbar

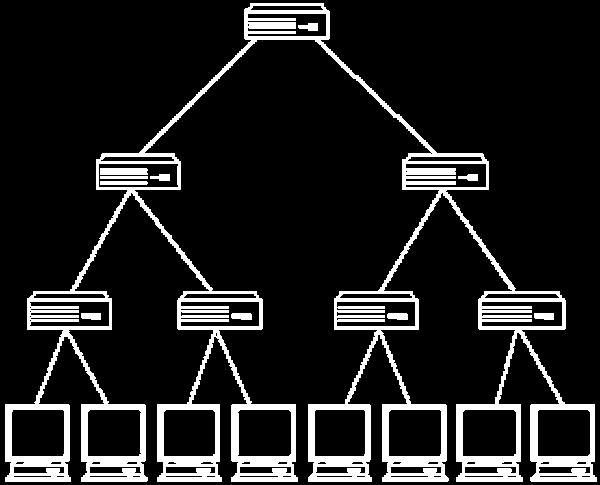
34 Binary Tree
35 Fat Tree ogies/




36 Other Fat Trees Big IU IU LLNL ORNL From Torsten Hoefler's Network Topology Repository at Tokyo Inst. of Tech

37 3-D Torus (T3D XT7 ) XT3 has Global Addressing hardware, and this helps to simulate shared memory. Torus means that ends are connected. This means A is really connected to B and the cube has no real boundary.
38 Top 10 Systems as of November 2017 # Site Manufacturer Computer CPU Interconnect [Accelerator] Cores Rmax (Tflops) Rpeak (Tflops) Power (MW) 1 National Super Computer Center in Guangzhou China NRCPC Sunway TaihuLight Sunway SW C 1.45GHz 10,649,600 93, , OpenACC is a first class API! 2 National Super Computer Center in Guangzhou China NUDT Tianhe-2 (MilkyWay-2) Intel Xeon E GHz TH Express-2 Intel Xeon Phi 31S1P 3,120,000 33,862 54, Swiss National Supercomputing Centre (CSCS) Switzerland Cray Piz Daint Cray XC50 Xeon E GHz Aries NVIDIA P ,760 19,590 25, Japan Agency for Marine-Earth Science Japan ExaScaler Gyoukou Xeon D GHz Infiniband EDR 19,860,000 19,135 28, DOE/SC/Oak Ridge National Laboratory United States Cray Titan Cray XK7 Opteron GHz Gemini NVIDIA K20x 560,640 17,590 27, DOE/NNSA/LLNL United States IBM Sequoia BlueGene/Q Power BQC 1.6 GHz Custom 1,572,864 17,173 20, DOE/NNSA/LANL/SNL United States Cray Trinity Cray XC40 Xeon E5-2698v3 2.3 GHz Aries Intel Xeon Phi ,968 17,173 20, DOE/SC/LBNL/NERSC United States Cray Cori Cray XC40 Aries Intel Xeon Phi ,336 14,014 27, Joint Center for Advanced High Performance Computing Japan Fujitsu Oakforest Primergy Intel OPA Intel Xeon Phi ,104 13,554 24, RIKEN Advanced Institute for Fujitsu K Computer SPARC64 VIIIfx 2.0 GHz 705,024 10,510 11,
. Build a large, fast, reliable filesystem from a collection of smaller drives.")
39 Parallel IO (RAID ) There are increasing numbers of applications for which many PB of data need to be written. Checkpointing is also becoming very important due to MTBF issues (a whole nother talk). Build a large, fast, reliable filesystem from a collection of smaller drives. Supposed to be transparent to the programmer. Increasingly mixing in SSD.
40 4 th Theme We will have Exascale computing You will get there by going very parallel What does parallel computing look like? Where is this going?




41 Exascale? exa = = 1,000,000,000,000,000,000 = quintillion 23,800 X 833,000 X or Cray Red Storm Tflops NVIDIA K Tflops
42 1E+11 1E+10 1E Eflop/s 100 Pflop/s 10 Pflop/s 1 Pflop/s 100 Tflop/s 10 Tflop/s 1 Tflop/s 100 Gflop/s 10 Gflop/s 1 Gflop/s 100 Mflop/s Projected Performance Development SUM N=1 N= Courtesy Horst Simon, LBNL
43 Trends with ends. Source: Kogge and Shalf, IEEE CISE Courtesy Horst Simon, LBNL

44 Two Additional Boosts to Improve Flops/Watt and Reach Exascale Target Third Boost: SiPh ( ) Second Boost: 3D ( ) First boost: many-core/accelerator We will be able to reach usable Exaflops for ~20 MW by 2024 But at what cost? Will any of the other technologies give additional boosts after 2025? Courtesy Horst Simon, LBNL

45 PicoJoules pico joules / bit Adapted from John Shalf Courtesy Horst Simon, LBNL Power Issues by 2018 FLOPs will cost less than on-chip data movement! now DP FLOP Register 1mm on-chip 5mm on-chip Off-chip/DRAM local interconnect Cross system
46 Flops are free? At exascale, >99% of power is consumed by moving operands across machine. Does it make sense to focus on flops, or should we optimize around data movement? To those that say the future will simply be Big Data: All science is either physics or stamp collecting. - Ernest Rutherford

 Uniformity: Assume uniform system performance")



47 Picojoules Per Opera on It is not just exaflops we are changing the whole computational model Current programming systems have WRONG optimization targets Old Constraints Peak clock frequency as primary limiter for performance improvement Cost: FLOPs are biggest cost for system: optimize for compute Concurrency: Modest growth of parallelism by adding nodes Memory scaling: maintain byte per flop capacity and bandwidth Locality: MPI+X model (uniform costs within node & between nodes) Uniformity: Assume uniform system performance Reliability: It s the hardware s problem New Constraints Power is primary design constraint for future HPC system design Cost: Data movement dominates: optimize to minimize data movement Concurrency: Exponential growth of parallelism within chips Memory Scaling: Compute growing 2x faster than capacity or bandwidth Locality: must reason about data locality and possibly topology Heterogeneity: Architectural and performance non-uniformity increase Reliability: Cannot count on hardware protection alone Fundamentally breaks our current programming paradigm and computing ecosystem! ####"! ###"! ##"! #"! " $%"&' ( %" ) *+,-.*/" Internode/MPI Intranode/SMP Communica on Communica on On-chip / CMP communica on! 0 0 "12345,6" 70 0 "12345,6" ( 8345,69$) : ; " <14=<",2.*/4122*4." >/1--"-?-.*0 " Adapted from John Shalf 21@" A#! B"




48 Courtesy Horst Simon, LBNL End of Moore s Law Will Lead to New Architectures Non-von Neumann ARCHITECTURE NEUROMORPHIC QUANTUM COMPUTING von Neumann TODAY BEYOND CMOS CMOS TECHNOLOGY Beyond CMOS

49 It would only be the 6 th paradigm.
50 As a last resort, we could will learn to program again. It has become a mantra of contemporary programming philosophy that developer hours are so much more valuable than hardware, that the best design compromise is to throw more hardware at slower code. This might well be valid for some Java dashboard app used twice a week by the CEO. But this has spread and results in The common observation that a modern PC (or phone) seems to be more laggy than one from a few generations ago that had literally one thousandth the processing power. Moore s Law has been the biggest enabler (or more accurately rationalization) for this trend. If Moore s Law does indeed end, then progress will require good programming. No more garbage collecting, script languages. I am looking at you, Java, Python, Matlab.

51 We can do better. We have a role model. Straight forward extrapolation results in a real-time human brain scale simulation at about 1-10 Exaflop/s with 4 PB of memory Current predictions envision Exascale computers in with a power consumption of at best MW The human brain takes 20W Even under best assumptions in 2020 our brain will still be a million times more power efficient Courtesy Horst Simon, LBNL
52 Why you should be (extra) motivated. This parallel computing thing is no fad. The laws of physics are drawing this roadmap. If you get on board (the right bus), you can ride this trend for a long, exciting trip. Let s learn how to use these things!
53 In Conclusion OpenACC MPI OpenMP

54 Credits Horst Simon of LBNL His many beautiful graphics are a result of his insightful perspectives He puts his money where his mouth is: $2000 bet in 2012 that Exascale machine would not exist by end of decade Intel Many datapoints flirting with NDA territory Top500.org Data and tools Supporting cast: Erich Strohmaier (LBNL) Jack Dongarra (UTK) Rob Leland (Sandia) John Shalf (LBNL) Scott Aronson (MIT) Bob Lucas (USC-ISI) John Kubiatowicz (UC Berkeley) Dharmendra Modha and team(ibm) Karlheinz Meier (Univ. Heidelberg)
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Intro To Parallel Computing. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Intro To Parallel Computing John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want to orient
Intro To Parallel Computing John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want to orient
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory
 Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory 2013 International Workshop on Computational Science and Engineering National University of Taiwan
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory 2013 International Workshop on Computational Science and Engineering National University of Taiwan
Why we need Exascale and why we won t get there by 2020
 Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory August 27, 2013 Overview Current state of HPC: petaflops firmly established Why we won t get to
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory August 27, 2013 Overview Current state of HPC: petaflops firmly established Why we won t get to
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
CSE5351: Parallel Procesisng. Part 1B. UTA Copyright (c) Slide No 1
 Slide No 1") Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
High-Performance Computing - and why Learn about it?
 High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Report on the Sunway TaihuLight System. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
ECE 574 Cluster Computing Lecture 2
 ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I. Thomas Schulthess
 High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
The Exascale Challenge:
 The Exascale Challenge: How Technology Disruptions Fundamentally Change Programming Systems John Shalf Department Head: Computer Science and Data Sciences (CSDS) CTO: National Energy Research Scientific
The Exascale Challenge: How Technology Disruptions Fundamentally Change Programming Systems John Shalf Department Head: Computer Science and Data Sciences (CSDS) CTO: National Energy Research Scientific
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
ECE 574 Cluster Computing Lecture 18
 ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
HPC Algorithms and Applications
 HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC as a Driver for Computing Technology and Education
 HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Towards Exascale Computing with the Atmospheric Model NUMA
 Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Emerging Heterogeneous Technologies for High Performance Computing
 MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Overview. Idea: Reduce CPU clock frequency This idea is well suited specifically for visualization
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
System Packaging Solution for Future High Performance Computing May 31, 2018 Shunichi Kikuchi Fujitsu Limited
 System Packaging Solution for Future High Performance Computing May 31, 2018 Shunichi Kikuchi Fujitsu Limited 2018 IEEE 68th Electronic Components and Technology Conference San Diego, California May 29
System Packaging Solution for Future High Performance Computing May 31, 2018 Shunichi Kikuchi Fujitsu Limited 2018 IEEE 68th Electronic Components and Technology Conference San Diego, California May 29
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Overview of HPC and Energy Saving on KNL for Some Computations
 Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
HPC Technology Update Challenges or Chances?
 HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
Seagate ExaScale HPC Storage
 Seagate ExaScale HPC Storage Miro Lehocky System Engineer, Seagate Systems Group, HPC1 100+ PB Lustre File System 130+ GB/s Lustre File System 140+ GB/s Lustre File System 55 PB Lustre File System 1.6
Seagate ExaScale HPC Storage Miro Lehocky System Engineer, Seagate Systems Group, HPC1 100+ PB Lustre File System 130+ GB/s Lustre File System 140+ GB/s Lustre File System 55 PB Lustre File System 1.6
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics
 CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
Parallel Computing: From Inexpensive Servers to Supercomputers
 Parallel Computing: From Inexpensive Servers to Supercomputers Lyle N. Long The Pennsylvania State University & The California Institute of Technology Seminar to the Koch Lab http://www.personal.psu.edu/lnl
Parallel Computing: From Inexpensive Servers to Supercomputers Lyle N. Long The Pennsylvania State University & The California Institute of Technology Seminar to the Koch Lab http://www.personal.psu.edu/lnl
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
International Conference Russian Supercomputing Days. September 25-26, 2017, Moscow
 International Conference Russian Supercomputing Days September 25-26, 2017, Moscow International Conference Russian Supercomputing Days Supported by the Russian Foundation for Basic Research Platinum Sponsor
International Conference Russian Supercomputing Days September 25-26, 2017, Moscow International Conference Russian Supercomputing Days Supported by the Russian Foundation for Basic Research Platinum Sponsor
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MARCH 17 TH, MIC Workshop PAGE 1. MIC workshop Guillaume Colin de Verdière
 EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING Top 10 Supercomputers in the World as of November 2013*
 CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014 COMPUTERS : PRESENT, PAST & FUTURE Top 10 Supercomputers in the World as of November 2013* No Site Computer Cores Rmax + (TFLOPS) Rpeak (TFLOPS)
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014 COMPUTERS : PRESENT, PAST & FUTURE Top 10 Supercomputers in the World as of November 2013* No Site Computer Cores Rmax + (TFLOPS) Rpeak (TFLOPS)
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
How HPC Hardware and Software are Evolving Towards Exascale
 How HPC Hardware and Software are Evolving Towards Exascale Kathy Yelick Associate Laboratory Director and NERSC Director Lawrence Berkeley National Laboratory EECS Professor, UC Berkeley NERSC Overview
How HPC Hardware and Software are Evolving Towards Exascale Kathy Yelick Associate Laboratory Director and NERSC Director Lawrence Berkeley National Laboratory EECS Professor, UC Berkeley NERSC Overview
Top500
 Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Parallel Languages: Past, Present and Future
 Parallel Languages: Past, Present and Future Katherine Yelick U.C. Berkeley and Lawrence Berkeley National Lab 1 Kathy Yelick Internal Outline Two components: control and data (communication/sharing) One
Parallel Languages: Past, Present and Future Katherine Yelick U.C. Berkeley and Lawrence Berkeley National Lab 1 Kathy Yelick Internal Outline Two components: control and data (communication/sharing) One
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Introduction to Parallel Programming for Multicore/Manycore Clusters
 duction to Parallel Programming for Multi/Many Clusters General duction Invitation to Supercomputing Kengo Nakajima Information Technology Center The University of Tokyo Takahiro Katagiri Information Technology
duction to Parallel Programming for Multi/Many Clusters General duction Invitation to Supercomputing Kengo Nakajima Information Technology Center The University of Tokyo Takahiro Katagiri Information Technology
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
The Future of High- Performance Computing
 Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Lecture 20: Distributed Memory Parallelism. William Gropp
 Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Chapter 1. Introduction
 Chapter 1 Introduction Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand
Chapter 1 Introduction Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand
Parallel Computing. Parallel Computing. Hwansoo Han
 Parallel Computing Parallel Computing Hwansoo Han What is Parallel Computing? Software with multiple threads Parallel vs. concurrent Parallel computing executes multiple threads at the same time on multiple
Parallel Computing Parallel Computing Hwansoo Han What is Parallel Computing? Software with multiple threads Parallel vs. concurrent Parallel computing executes multiple threads at the same time on multiple
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Trends of Network Topology on Supercomputers. Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27
 Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Inauguration Cartesius June 14, 2013
 Inauguration Cartesius June 14, 2013 Hardware is Easy...but what about software/applications/implementation/? Dr. Peter Michielse Deputy Director 1 Agenda History Cartesius Hardware path to exascale: the
Inauguration Cartesius June 14, 2013 Hardware is Easy...but what about software/applications/implementation/? Dr. Peter Michielse Deputy Director 1 Agenda History Cartesius Hardware path to exascale: the