An Overview of High Performance Computing. Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/2005 1
|
|
|
- Walter O’Connor’
- 6 years ago
- Views:
Transcription

1 An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face us Hardware Software Algorithms 2 1



2 Technology Trends: Microprocessor Chip Capacity Gordon Moore (co-founder of Intel) Electronics Magazine, 1965 Number of devices/chip doubles every 18 months Microprocessors have become smaller, denser, and more powerful. Not just processors, bandwidth, storage, etc. 2X memory and processor speed and 2X transistors/chip Every 1.5 years Moore s Law ½ size, cost, & power every 18 3 months. H. Meuer, H. Simon, E. Strohmaier, & JD - Listing of the 5 most powerful Computers in the World - Yardstick: Rmax from LINPACK MPP Ax=b, dense problem TPP performance - Updated twice a year Size SC xy in the States in November Meeting in Germany in June - All data available from 4 Rate 2
3 Performance Development 1 Pflop/s 2.3 PF/s 28.6 TF/s 1 Tflop/s 1 Tflop/s 1 Tflop/s 1 Gflop/s 1 Gflop/s 1 Gflop/s TF/s 59.7 GF/s Fujitsu 'NWT' NAL.4 GF/s SUM N=1 Intel ASCI Red Sandia N=5 NEC Earth Simulator IBM ASCI White LLNL My Laptop IBM BlueGene/L TF/s 1 Mflop/s Tightly Architecture/Systems Continuum Coupled Custom processor Best processor performance for with custom interconnect codes Custom that are not cache 8% friendly Cray X1 NEC SX-8 Good communication performance IBM Regatta Simpler programming model IBM Blue Gene/L 6% Most expensive Commodity processor with custom interconnect SGI Altix Intel Itanium 2 Cray XT3, XD1 AMD Opteron 2% Commodity processor with commodity interconnect Best price/performance (for codes that work well with caches Clusters Commod % and are latency tolerant) Pentium, Itanium, Opteron, Alpha More complex programming model GigE, Infiniband, Myrinet, Quadrics Loosely NEC TX7 Coupled IBM eserver Dawning 6 1% 4% Good communication Hybrid performance Good scalability Jun-93 Dec-93 Jun-94 Dec-94 Jun-95 Dec-95 Jun-96 Dec-96 Jun-97 Dec-97 Jun-98 Dec-98 Jun-99 Dec-99 Jun- Dec- Jun-1 Dec-1 Jun-2 Dec-2 Jun-3 Dec-3 Jun-4 3


 2 Constellations 1 SMP MPP 1993 1994 1995 1996 1997 1998 1999 2 21 22 23")
4 Commodity Processors Intel Pentium Nocona 3.6 GHz, peak = 7.2 Gflop/s Linpack 1 = 1.8 Gflop/s Linpack 1 = 4.2 Gflop/s Intel Itanium GHz, peak = 6.4 Gflop/s Linpack 1 = 1.7 Gflop/s Linpack 1 = 5.7 Gflop/s AMD Opteron 2.6 GHz, peak = 5.2 Gflop/s Linpack 1 = 1.6 Gflop/s Linpack 1 = 3.9 Gflop/s 7 5 Architectures / Systems 4 SIMD Single Proc. 3 Cluster (36) 2 Constellations 1 SMP MPP Cluster: Commodity processors & Commodity interconnect 8 Constellation: # of procs/node nodes in the system 4

5 Interconnects / Systems Others Cray Interconnect SP Switch Crossbar Quadrics Infiniband Myrinet (11) Gigabit Ethernet (249) N/A Processor Types SIMD Sparc Vector MIPS Alpha HP AMD IBM Power Intel
6 Processors Used in Each of the 5 Systems Hitachi SR8 % Sun Sparc 1% NEC 1% HP Alpha 1% Cray 2% HP PA-RISC 3% Intel IA-64 9% Intel IA-32 41% 91% = 66% Intel 15% IBM 11% AMD Intel EM64T 16% AMD x86_64 IBM Power 11% 15% 11 26th List: The TOP1 Manufacturer Computer Rmax [TF/s] Installation Site Country Year #Proc 1 IBM BlueGene/L eserver Blue Gene 28.6 DOE/NNSA/LLNL USA IBM BGW eserver Blue Gene IBM Thomas Watson USA IBM ASC Purple Power5 p DOE/NNSA/LLNL USA SGI Columbia Altix, Itanium/Infiniband NASA Ames USA Dell Cray NEC IBM IBM Thunderbird Pentium/Infiniband Red Storm Cray XT3 AMD Earth-Simulator SX-5 MareNostrum PPC 97/Myrinet eserver Blue Gene Sandia Sandia Earth Simulator Center Barcelona Supercomputer Center ASTRON University Groningen Jaguar 1 Cray 2.53 Oak Ridge National Lab USA 52 Cray XT3 AMD 12 USA USA Japan Spain Netherlands
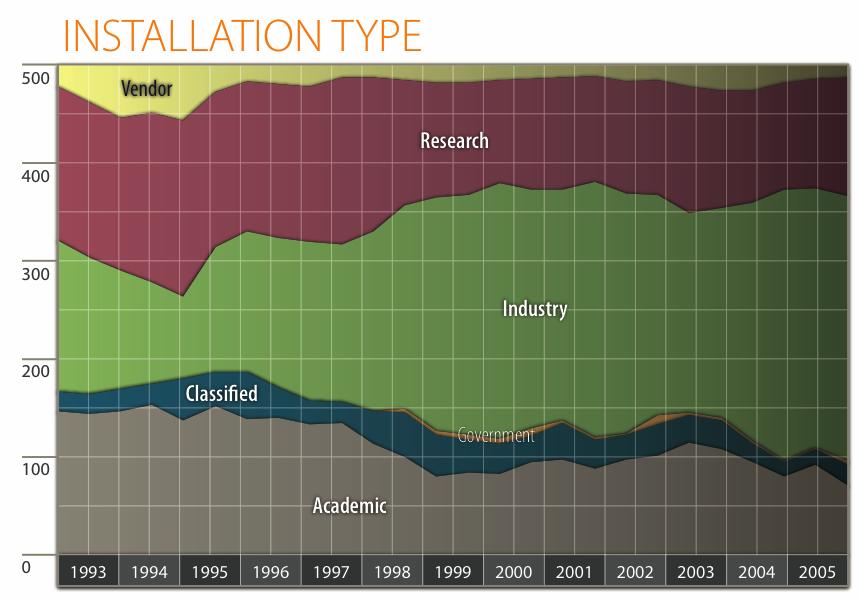
7 Customer Segments / Performance 1% 9% 8% 7% 6% 5% 4% 3% 2% 1% % Classified Vendor Academic Industry Research Government Countries / Performance 1% 9% Others 8% 7% 6% France China 1.% 2.6% 5% 4% 3% Germany 3.% UK 5.4% 2% 1% % Japan 6.% US 68%
8 Asian Countries / Systems Others India Korea China 17 Japan Concurrency Levels of the Top k-128k 32k-64k 16k-32k 8k-16k 4k-8k
 System 1.")
 16 Compute Cards 64 processors Compute Card (2 chips, 2x1x1) 4 processors Chip (2")


9 Concurrency Levels of the Top5 1,, 1, Maximum 131K # processors 1, 1, 1 Average Minimum Jun-93 Jun-94 Jun-95 Jun-96 Jun-97 Jun-98 Jun-99 Jun- Jun-1 Jun-2 Jun-3 Jun-4 Jun-5 17 IBM BlueGene/L 131,72 Processors (#1-64K and #2-4K) System 1.6 MWatts (16 homes) (64 racks, 64x32x32) 43, ops/s/person Rack 131,72 procs (32 Node boards, 8x8x16) 248 processors BlueGene/L Compute ASIC Node Board (32 chips, 4x4x2) 16 Compute Cards 64 processors Compute Card (2 chips, 2x1x1) 4 processors Chip (2 processors) 2.8/5.6 GF/s 4 MB (cache) 5.6/11.2 GF/s 1 GB DDR 9/18 GF/s 16 GB DDR 2.9/5.7 TF/s.5 TB DDR 18/36 TF/s 32 TB DDR Fastest Computer BG/L 7 MHz 131K proc The compute node ASICs include all networking and processor functionality. 64 racks Each compute ASIC includes two 32-bit superscalar PowerPC 44 embedded Peak: 367 Tflop/s cores (note that L1 cache coherence is not maintained between these cores). 18 (13K sec about 3.6 hours; n=1.8m Linpack: 281 Tflop/s 77% of peak Full system total of 131,72 processors 9

10 Performance Projection 1 Eflop/s 1 Pflop/s 1 Pflop/s 1 Pflop/s 1 Tflop/s 1 Tflop/s 1 Tflop/s SUM DARPA HPCS 1 Gflop/s 1 Gflop/s N=1 My Laptop 1 Gflop/s N=5 1 Mflop/s A PetaFlop Computer by the End of the Decade 1 Companies working on a building a Petaflop system by the end of the decade. Cray } IBM Sun Dawning } Galactic Chinese Companies Lenovo Hitachi Japanese NEC } Life Simulator (1 Pflop/s) Fujitsu Bull 2 1
11 Flops per Gross Domestic Product Based on the November Top Isreal USA 21 New Zealand Switzerland Russia UK Netherlands Australian South Korea Saudi Arabia China Japan Ireland Spain Germany Taiwan Canada Brazil KFlop/s per Capita (Flops/Pop) Based on the November Top Hint: Peter Jackson had something to do with this United States Switzerland Israel New Zealand WETA Digital (Lord of the Rings) United Kingdom Netherlands Australia Japan Germany Spain Canada Korea, South Sweden Saudia Arabia France Taiwan Italy Brazil Mexico China Russia India 22 Has nothing to do with the 47.2 million sheep in NZ 11

 Cray X1E (2GB) ASCI Q - Alpha 1.2 5 GHz IBM p5 575 1.9 GHz Sys tem X 2.3 GHz Apple XServe/ SGI Altix 37 1.")

12 Fuel Efficiency: GFlops/Watt G Flops/Watt BlueGe ne/l Blue Ge ne ASC Purple p5 1.9 GHz Columbia - SGI Altix 1.5 GHz Red Storm Cray XT3, 2. GHz Earth-Simulator Thunderbird - Pentium 3.6 GHz Jaguar - Cray X T3, 2.4 GHz MareNostrum PPC 97, 2.2 GHz Blue Ge ne Thunder - Intel Itanium2 1.4GHz Blue Ge ne Blue Ge ne Cray XT3, 2.6 GHz Apple XServe, 2. GHz Cray X1E (4GB) Cray X1E (2GB) ASCI Q - Alpha GHz IBM p GHz Sys tem X 2.3 GHz Apple XServe/ SGI Altix GHz Top 2 systems 23 Based on processor power rating only (3,>1,>8) 1, Sun s s Surface Power Density (W/cm 2 ) 1, Hot Plate 486 Nuclear Reactor Rocket Nozzle Pentium Cube relationship between the cycle time and power. 24 Intel Developer Forum, Spring - Pat Gelsinger (Pentium at 9 W) 12

13 Lower Voltage Increase Clock Rate & Transistor Density We have seen increasing number of gates on a chip and increasing clock speed. Heat becoming an unmanageable problem, Intel Processors > 1 Watts We will not see the dramatic increases in clock speeds in the future. However, the number of gates on a chip will continue to increase. Intel Yonah will double the processing power on 25 a per watt basis. Operations per second for serial code Free Lunch For Traditional Software (It just runs twice as fast every 18 months with no change to the code!) 24 GHz, 1 Core 12 GHz, 1 Core 6 GHz 1 Core 3GHz 1 Core 1 Core 3 GHz 2 Cores No Free Lunch For Traditional Software (Without highly concurrent software it won t get any faster!) 2 Cores 3 GHz, 4 Cores 4 Cores 3 GHz, 8 Cores 8 Cores 26 Additional operations per second if code can take advantage of concurrency 13
14 CPU Desktop Trends Relative processing power will continue to double every 18 months 256 logical processors per chip in late Year Hardware Threads Per Chip Cores Per Processor Chip Commodity Processor Trends Bandwidth/Latency is the Critical Issue, not FLOPS Annual increase Typical value in Typical value in 21 Got Bandwidth? Typical value in 22 Single-chip floating-point performance 59% 4 GFLOP/s 32 GFLOP/s 33 GFLOP/s Front-side bus bandwidth 23% 1 GWord/s =.25 word/flop 3.5 GWord/s =.11 word/flop 27 GWord/s =.8 word/flop DRAM latency (5.5%) 7 ns = 28 FP ops = 7 loads 5 ns = 16 FP ops = 17 loads 28 ns = 94, FP ops = 78 loads Source: Getting Up to Speed: The Future of Supercomputing, National Research Council, pages,, National Academies Press, Washington DC, ISBN
15 Fault Tolerance: Motivation Trends in HPC: High end systems with thousand of processors Increased probability of a node failure Most systems nowadays are robust MPI widely accepted in scientific computing Process faults not tolerated in MPI model Mismatch between hardware and (non faulttolerant) programming paradigm of MPI. 29 Reliability of Leading-Edge HPC Systems System LANL ASCI Q LLNL ASCI White Pittsburgh Lemieux CPUs 8,192 8,192 3,16 Reliability MTBI: 6.5 hours. Leading outage sources: storage, CPU, memory. MTBF: 5. hours ( 1) and 4 hours ( 3). Leading outage sources: storage, CPU, 3 rd - party HW. MTBI: 9.7 hours. MTBI: mean time between interrupts = wall clock hours / # downtime periods MTBF: mean time between failures (measured) 1K processor systems are here we have fundamental challenges in dealing with machines of this size 3 and little in the way of programming support 15

16 Future Challenge: Developing the Ecosystem for HPC From the NRC Report on The Future of Supercomputing : Hardware, software, algorithms, tools, networks, institutions, applications, and people who solve supercomputing applications can be thought of collectively as an ecosystem Research investment in HPC should be informed by the ecosystem point of view - progress must come on a broad front of interrelated technologies, rather than in the form of individual breakthroughs. A supercomputer ecosystem is a continuum of computing platforms, system software, algorithms, tools, networks, and the people who know how to exploit them to solve computational science applications. 31 Real Crisis With HPC Is With The Software Our ability to configure a hardware system capable of 1 PetaFlop (1 15 ops/s) is without question just a matter of time and $$. A supercomputer application and software are usually much more long-lived than a hardware Hardware life typically five years at most. Apps 2-3 years Fortran and C are the main programming models (still!!) The REAL CHALLENGE is Software Programming hasn t changed since the 7 s HUGE manpower investment MPI is that all there is? Often requires HERO programming Investments in the entire software stack is required (OS, libs, etc.) Software is a major cost component of modern technologies. The tradition in HPC system procurement is to assume that the software is free SOFTWARE COSTS (over and over) 32 16
: Global Address")
17 Summary of Current Unmet Needs Performance / Portability Fault tolerance Memory bandwidth/latency Adaptability: Some degree of autonomy to self optimize, test, or monitor. Able to change mode of operation: static or dynamic Better programming models Global shared address space Visible locality Maybe coming soon (incremental, yet offering real benefits): Global Address Space (GAS) languages: UPC, Co-Array Fortran, Titanium, Chapel) Minor extensions to existing languages More convenient than MPI Have performance transparency via explicit remote memory references 33 Collaborators / Support Top5 Team Erich Strohmaier, NERSC Hans Meuer, Mannheim Horst Simon, NERSC
18 35 Next Steps Software to determine the checkpointing interval and number of checkpoint processors from the machine characteristics. Perhaps use historical information. Monitoring Migration of task if potential problem Local checkpoint and restart algorithm. Coordination of local checkpoints. Processors hold backups of neighbors. Have the checkpoint processes participate in the computation and do data rearrangement when a failure occurs. Use p processors for the computation and have k of them hold checkpoint. Generalize the ideas to provide a library of routines to do the diskless check pointing. Look at real applications and investigate Lossy algorithms
19 Operating Systems / Systems Others FreeBSD N/A BSD Based Linux Unix Clusters / Systems Others Intel Itanium Sun Fire Alpha Cluster 2 Sun Cluster 15 Dell Cluster 1 AMD Cluster HP AlphaServer Intel Pentium HP Cluster IBM Cluster 38 19

20 39 4 2

21 Japanese: Tightly-Coupled Heterogeneous System Would like to get to 1 PetaFlop/s by 211 Scalable, fits any computer center Size, cost, ratio of components Easy and low-cost to develop new component Scale merit of components Present Faster interconnect Vector Node Switch Slower connection Faster Faster interconnect interconnect Scalar Node MD Node Future system Vector Node Faster interconnect Scalar Node MD Node FPGA Node 41 How Big Is Big? Every 1X brings new challenges 64 processors was once considered large it hasn t been large for quite a while 124 processors is today s medium size 896 processors is today s large we re struggling even here 1K processor systems are in construction we have fundamental challenges in dealing with machines of this size and little in the way of programming support 42 21
22 Interconnects / Systems Cray Interconnect SP Switch Crossbar Others Infiniband Quadrics Gigabit Ethernet Myrinet N/A 24% 28% Myrinet and GigE > 5% of market Real Crisis With HPC Is With The Software Programming is stuck Arguably hasn t changed since the 6 s It s time for a change Complexity is rising dramatically highly parallel and distributed systems From 1 to 1 to 1 to 1 to 1 of processors!! multidisciplinary applications A supercomputer application and software are usually much more long-lived than a hardware Hardware life typically five years at most. Fortran and C are the main programming models Software is a major cost component of modern technologies. The tradition in HPC system procurement is to assume that the software is free. We have too few ideas about how to solve this problem
23 Processor Types SIMD Sparc MIPS Intel HP PA-Risc HP Alpha IBM Power Other scalar Vector 45 Today s s Processors pipelining (superscalar, OOO, VLIW, branch prediction, predication) simultaneous multithreading (SMT, Hyper-Threading, multi-core) SIMD vector instructions (VIS, MMX/SSE, AltiVec) caches and the memory hierarchy Intel added 36 instructions per year to IA-32, or 3 instructions per month! 46 23
24 KFlop/s per Capita (Flops/Pop) Based on the November Top5 only Hint: Peter Jackson had something to do with this WETA Digital (Lord of the Rings) China Brazil Italy Mexico France Korea, South Saudia Arabia Germany Belarus Switzerland Canada Spain Japan Israel United Kingdom New Zealand United States 47 Has nothing to do with the 47.2 million sheep in NZ Today s s CPU Architecture Moore s Law for Power Consumption Heat is becoming an unmanageable problem 48 24

25 Self Adapting Numerical Software The process of arriving at an efficient solution involves many decisions by an expert. Algorithm decisions Data decisions Management of the computing environment Processor specific tuning Proceedings of the IEEE, V: 93 #: 2 Feb. Issue on Program Generation, Optimization, and Platform Adaptation Complex set of interaction between Users applications Algorithm Programming language Compiler Machine instruction Hardware Many layers of translation from the application to the hardware. Changing with each generation 49 of hardware. 25
An Overview of High Performance Computing
 IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
Self Adapting Numerical Software. Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms
 Effort and Fault Tolerance in Linear Algebra Algorithms") Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 9/19/2005 1 Overview Quick look at
Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 9/19/2005 1 Overview Quick look at
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
Presentation of the 16th List
 Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
TOP500 Listen und industrielle/kommerzielle Anwendungen
 TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
Outline. Execution Environments for Parallel Applications. Supercomputers. Supercomputers
 Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
The TOP500 list. Hans-Werner Meuer University of Mannheim. SPEC Workshop, University of Wuppertal, Germany September 13, 1999
 The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
The TOP500 Project of the Universities Mannheim and Tennessee
 The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
Chapter 5b: top500. Top 500 Blades Google PC cluster. Computer Architecture Summer b.1
 Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
Recent Trends in the Marketplace of High Performance Computing
 Recent Trends in the Marketplace of High Performance Computing Erich Strohmaier 1, Jack J. Dongarra 2, Hans W. Meuer 3, and Horst D. Simon 4 High Performance Computing, HPC Market, Supercomputer Market,
Recent Trends in the Marketplace of High Performance Computing Erich Strohmaier 1, Jack J. Dongarra 2, Hans W. Meuer 3, and Horst D. Simon 4 High Performance Computing, HPC Market, Supercomputer Market,
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Leistungsanalyse von Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen 10. November 2010 Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen 10. November 2010 Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra INNOVATIVE COMP ING LABORATORY. University i of Tennessee Oak Ridge National Laboratory
 Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Supercomputing im Jahr eine Analyse mit Hilfe der TOP500 Listen
 Supercomputing im Jahr 2000 - eine Analyse mit Hilfe der TOP500 Listen Hans Werner Meuer Universität Mannheim Feierliche Inbetriebnahme von CLIC TU Chemnitz 11. Oktober 2000 TOP500 CLIC TU Chemnitz View
Supercomputing im Jahr 2000 - eine Analyse mit Hilfe der TOP500 Listen Hans Werner Meuer Universität Mannheim Feierliche Inbetriebnahme von CLIC TU Chemnitz 11. Oktober 2000 TOP500 CLIC TU Chemnitz View
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics
 CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
Recent trends in the marketplace of high performance computing
 Parallel Computing 31 (2005) 261 273 www.elsevier.com/locate/parco Recent trends in the marketplace of high performance computing Erich Strohmaier a, *, Jack J. Dongarra b,c, Hans W. Meuer d, Horst D.
Parallel Computing 31 (2005) 261 273 www.elsevier.com/locate/parco Recent trends in the marketplace of high performance computing Erich Strohmaier a, *, Jack J. Dongarra b,c, Hans W. Meuer d, Horst D.
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
Parallel Computing: From Inexpensive Servers to Supercomputers
 Parallel Computing: From Inexpensive Servers to Supercomputers Lyle N. Long The Pennsylvania State University & The California Institute of Technology Seminar to the Koch Lab http://www.personal.psu.edu/lnl
Parallel Computing: From Inexpensive Servers to Supercomputers Lyle N. Long The Pennsylvania State University & The California Institute of Technology Seminar to the Koch Lab http://www.personal.psu.edu/lnl
CSC 447: Parallel Programming for Multi- Core and Cluster Systems
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Why Parallel Computing? Haidar M. Harmanani Spring 2017 Definitions What is parallel? Webster: An arrangement or state that permits several
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Why Parallel Computing? Haidar M. Harmanani Spring 2017 Definitions What is parallel? Webster: An arrangement or state that permits several
EE 4683/5683: COMPUTER ARCHITECTURE
 3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
Architetture di calcolo e di gestione dati a alte prestazioni in HEP IFAE 2006, Pavia
 Architetture di calcolo e di gestione dati a alte prestazioni in HEP IFAE 2006, Pavia Marco Briscolini Deep Computing Sales Marco_briscolini@it.ibm.com IBM Pathways to Deep Computing Single Integrated
Architetture di calcolo e di gestione dati a alte prestazioni in HEP IFAE 2006, Pavia Marco Briscolini Deep Computing Sales Marco_briscolini@it.ibm.com IBM Pathways to Deep Computing Single Integrated
Algorithms and Architecture. William D. Gropp Mathematics and Computer Science
 Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Parallel Computer Architecture II
 Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
HPCS HPCchallenge Benchmark Suite
 HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
European energy efficient supercomputer project
 http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory
 Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title TOP500 Supercomputers for June 2005 Permalink https://escholarship.org/uc/item/4h84j873 Authors Strohmaier, Erich Meuer,
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title TOP500 Supercomputers for June 2005 Permalink https://escholarship.org/uc/item/4h84j873 Authors Strohmaier, Erich Meuer,
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
HW Trends and Architectures
 Pavel Tvrdík, Jiří Kašpar (ČVUT FIT) HW Trends and Architectures MI-POA, 2011, Lecture 1 1/29 HW Trends and Architectures prof. Ing. Pavel Tvrdík CSc. Ing. Jiří Kašpar Department of Computer Systems Faculty
Pavel Tvrdík, Jiří Kašpar (ČVUT FIT) HW Trends and Architectures MI-POA, 2011, Lecture 1 1/29 HW Trends and Architectures prof. Ing. Pavel Tvrdík CSc. Ing. Jiří Kašpar Department of Computer Systems Faculty
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Parallel computer architecture classification
 Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Blue Gene: A Next Generation Supercomputer (BlueGene/P)
") Blue Gene: A Next Generation Supercomputer (BlueGene/P) Presented by Alan Gara (chief architect) representing the Blue Gene team. 2007 IBM Corporation Outline of Talk A brief sampling of applications on
Blue Gene: A Next Generation Supercomputer (BlueGene/P) Presented by Alan Gara (chief architect) representing the Blue Gene team. 2007 IBM Corporation Outline of Talk A brief sampling of applications on
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Dheeraj Bhardwaj May 12, 2003
 HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
CSC 447: Parallel Programming for Multi- Core and Cluster Systems. Lectures TTh, 11:00-12:15 from January 16, 2018 until 25, 2018 Prerequisites
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Introduction and A dministrivia Haidar M. Harmanani Spring 2018 Course Introduction Lectures TTh, 11:00-12:15 from January 16, 2018 until
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Introduction and A dministrivia Haidar M. Harmanani Spring 2018 Course Introduction Lectures TTh, 11:00-12:15 from January 16, 2018 until
Computer Architecture. Fall Dongkun Shin, SKKU
 Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Top500
 Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Supercomputing and Mass Market Desktops
 Supercomputing and Mass Market Desktops John Manferdelli Microsoft Corporation This presentation is for informational purposes only. Microsoft makes no warranties, express or implied, in this summary.
Supercomputing and Mass Market Desktops John Manferdelli Microsoft Corporation This presentation is for informational purposes only. Microsoft makes no warranties, express or implied, in this summary.
Computer Architecture
 Informatics 3 Computer Architecture Dr. Boris Grot and Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh General Information Instructors: Boris
Informatics 3 Computer Architecture Dr. Boris Grot and Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh General Information Instructors: Boris
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
High Performance Computing
 CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
Evolution of Computers & Microprocessors. Dr. Cahit Karakuş
 Evolution of Computers & Microprocessors Dr. Cahit Karakuş Evolution of Computers First generation (1939-1954) - vacuum tube IBM 650, 1954 Evolution of Computers Second generation (1954-1959) - transistor
Evolution of Computers & Microprocessors Dr. Cahit Karakuş Evolution of Computers First generation (1939-1954) - vacuum tube IBM 650, 1954 Evolution of Computers Second generation (1954-1959) - transistor
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
CSE5351: Parallel Procesisng. Part 1B. UTA Copyright (c) Slide No 1
 Slide No 1") Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Brand-New Vector Supercomputer
 Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Why Parallel Architecture
 Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Node Hardware. Performance Convergence
 Node Hardware Improved microprocessor performance means availability of desktop PCs with performance of workstations (and of supercomputers of 10 years ago) at significanty lower cost Parallel supercomputers
Node Hardware Improved microprocessor performance means availability of desktop PCs with performance of workstations (and of supercomputers of 10 years ago) at significanty lower cost Parallel supercomputers
Chapter 2: Computer-System Structures. Hmm this looks like a Computer System?
 Chapter 2: Computer-System Structures Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure of a computer system and understanding
Chapter 2: Computer-System Structures Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure of a computer system and understanding
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I. Thomas Schulthess
 High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Uniprocessor Computer Architecture Example: Cray T3E
 Chapter 2: Computer-System Structures MP Example: Intel Pentium Pro Quad Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure
Chapter 2: Computer-System Structures MP Example: Intel Pentium Pro Quad Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure
An Overview of High Performance Computing and Challenges for the Future
 An Overview of High Performance Computing and Challenges for the Future Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 6/15/2009 1 H. Meuer, H. Simon, E. Strohmaier,
An Overview of High Performance Computing and Challenges for the Future Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 6/15/2009 1 H. Meuer, H. Simon, E. Strohmaier,
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Jack Dongarra University of Tennessee Oak Ridge National Laboratory
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
CCS HPC. Interconnection Network. PC MPP (Massively Parallel Processor) MPP IBM
 MPP IBM") CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
Administration. Coursework. Prerequisites. CS 378: Programming for Performance. 4 or 5 programming projects
 CS 378: Programming for Performance Administration Instructors: Keshav Pingali (Professor, CS department & ICES) 4.126 ACES Email: pingali@cs.utexas.edu TA: Hao Wu (Grad student, CS department) Email:
CS 378: Programming for Performance Administration Instructors: Keshav Pingali (Professor, CS department & ICES) 4.126 ACES Email: pingali@cs.utexas.edu TA: Hao Wu (Grad student, CS department) Email:
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Technology Trends Presentation For Power Symposium
 Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org