PREcision Timed (PRET) Architecture
|
|
|
- Quentin Thompson
- 5 years ago
- Views:
Transcription
1 PREcision Timed (PRET) Architecture Isaac Liu Advisor Edward A. Lee Dissertation Talk April 24, 2012 Berkeley, CA
2 Acknowledgements Many people were involved in this project: Edward A. Lee UC Berkeley David Broman UC Berkeley Ben Lickly UC Berkeley Hiren Patel University of Waterloo Jan Reineke Saarland University Stephen Edwards Columbia University Sungjun Kim Columbia University Matt Viele Drivven Inc. Gerald Wang National Instruments Hugo Andrade National Instruments And many more 2/38



 Key")

![07]: Composability Military](/docs-images/94/119458127/images/3-6.jpg "systems: Timing")

3 Cyber Physical Systems Two key characteristics of physical processes Inherently Concurrency Uncontrollable passage of time E-Corner, Siemens Avionics: Instrumentation (Soleil Synchrotron) Key Challenges [Sangiovanni-Vincentelli, 07]: Composability Military systems: Timing Predictability Dependability Concurrency Automotive: Passage of Time Daimler-Chrysler Courtesy of Doug Schmidt! 3/38
&)\"+.,&)'+<11$/\"+.,\"</'+7.//&2-8''6-'-7<;/'\"/' \"/,&#%.,<%',<'<*,\"1\">&',7&',<,.2'-&,'<3'+<1*$,7&'456'&0.1*2&@',7&'<*,\"1\">&)'-&,'<3'-7.")
(*+,$'-+$#../01'(/2$/3$4&15+?&/,%.2'c%<+&--\"/#'d/\",-'a?")
$+&)'3%<1' +<1*$,\"/#'%&-<$%+&-'.%&'.22<+.,&)',<',7&'N 3<$%',<'</&8''!")
=/.1\"+.22='1./.#&'-*.%&'%&,7%<$#7',7&'1./\"*$2.,\"</'<3',7&'+</3\"#$%.,\",.:2&-8''97&'-=-,&1'\"/,&#%.,<%'+<$2)'.22<+., %&-<$%+&-',<'&.+7'\"/)\"G\")$.2'N<-,&)'!$/+,\" ;7\"+7'\"-'.")
![F"/',<',7&'-*.%&'.22<+.,"</'*%<+&3&)&%.,&)'&/G"%</1&/,8''456'.))-',7&'.))" +.*.:"2",=',<'%&-&%G&'.'-*.%&'%&-<$%+&'*<<2'.:2&',<':&'.22<+.,&)',<'./='N<-,&)'!$/+,"</ [ CB. Watkins, 07] [CB. Watkins, 07]! -7.](/docs-images/94/119458127/images/4-4.jpg "%\"/#',7&'%&-<$%+&8''97\"-'#\"G&-',7&'-=-,&1 \"/,&#%.,<%',7&')=/.1\"+'.:\"2\",=',<'\"/+%&.-&'< [Sangiovanni-Vincentelli, ee249 lecture 1] \"#$%&'!()!*+,-.&#/+0!+1!.0!23.,-4'!\"'5'&.6'5! )&+%&.-&',7&'%&-<$%+&'.")
4 +,-./,(& $%&'()* Composability Electronics and the Car!"# 3<$%',<'</&8'' )&G&2<*&)'.-',7%&&'-&*.%.,&'$/",-'+<//&+,&)':=' 6/'456'.%+7",&+,$%&'.22<;-',7&'-=-,&1 )&)"+.,&)'+<11$/"+.,"</'+7.//&2-8''6-'-7<;/'"/' %&-<$%+&-8''97&':&/&3",-',<'456'.%&'%<<,&)' +<1*$,"/#'%&-<$%+&-'$-&-'2&--'*7=-"+.2'%&-<$%+&-' <*,"1">.,"</'+.*.:"2","&-8' ;7&/'+<1*.%&)',<',7&'3&)&%.,&)'-=-,&1',7.,'7<-,-' 6/)&7'(28$9+,/750+,$,7%&&',<'</&8''97&'+<11$/"+.,"</'"/,&%3.+&-'.%&'!More than 30% of the cost of a car is now in Electron %&)$+&)'3%<1'3"G&',<'3<$%8''!"/.22=@',7&'/$1:&%'<3' M",7"/'./'456'.%+7",&+,$%&@',7&'-7.%&! 9 0% of all innovations will be based on electronic sy *7=-"+.2'+<11$/"+.,"</'+7.//&2-'"-'%&)$+&)'3%<1' +<1*$,"/#'%&-<$%+&-'.%&'.22<+.,&)',<',7&'N 3<$%',<'</&8''!$/+,"</-',7%<$#7',7&'$-&'<3'+</3"#$%.,"</ 97&-&'-7.%&)'%&-<$%+&-'"/+2$)&',7&'+<1*$, *%<+&--<%A-E@'+<11</'+<11$/"+.,"</-'/&,./)'+<11</'4OP'$/",A-E8''Q$%"/#',7&'.22<+. *%<+&--@',7&'-=-,&1'"/,&#%.,<%'1."/,."/-',7& 32&0":"2",=',<')=/.1"+.22='1./.#&'-*.%&'%&,7%<$#7',7&'1./"*$2.,"</'<3',7&'+</3"#$%.,",.:2&-8''97&'-=-,&1'"/,&#%.,<%'+<$2)'.22<+., %&-<$%+&-',<'&.+7'"/)"G")$.2'N<-,&)'!$/+," ;7"+7'"-'.F"/',<',7&'-*.%&'.22<+.,"</'*%<+&3&)&%.,&)'&/G"%</1&/,8''456'.))-',7&'.))" +.*.:"2",=',<'%&-&%G&'.'-*.%&'%&-<$%+&'*<<2'.:2&',<':&'.22<+.,&)',<'./='N<-,&)'!$/+,"</ [ CB. Watkins, 07] [CB. Watkins, 07]! -7.%"/#',7&'%&-<$%+&8''97"-'#"G&-',7&'-=-,&1 "/,&#%.,<%',7&')=/.1"+'.:"2",=',<'"/+%&.-&'< [Sangiovanni-Vincentelli, ee249 lecture 1] "#$%&'!()!*+,-.&#/+0!+1!.0!23.,-4'!"'5'&.6'5! )&+%&.-&',7&'%&-<$%+&'.22<+.,"</'3<%'.'#"G&/.05!789!9&:;#6':6%&'! Dissertation Talk, Apr. 24, /38!$/+,"</'"/',7&'3$,$%&@'<%',<'.))'.'/&;'N<+,-./,(& $%&'()*!"# +,-./,(&,-./,(& $%&'()* %&'()*!"#!"# IMA Integrated Modular Avionics
 if ( a[i] > b[i] ) else Let s assume we know n 10 c[i] = c[i-1] + a[i]; c[i] = c[i-1] + b[i]; Branch predicted correctly?")
5 Timing Predictability How long does it take to execute the following code? Cache Hit? Miss? Data Dependency for (i = 1; i < n; i++) if ( a[i] > b[i] ) else Let s assume we know n 10 c[i] = c[i-1] + a[i]; c[i] = c[i-1] + b[i]; Branch predicted correctly? Out of order execution? Multithreading? Assume branch mispredict, cache miss? 5/38

![, 99] [Wenzel et al.](/docs-images/94/119458127/images/6-3.jpg ", 05] [Reineke et al.")
6 Timing Anomalies [Lundqvist et al., 99] [Wenzel et al., 05] [Reineke et al., 06] [Engblom, 03] 6/38
7 Challenges in WCET Analysis However, both the precision of the results and the efficiency of the analysis methods are highly dependent on the predictability of the execution platform. In fact, the architecture determines whether a static timing analysis is practically feasible at all and whether the most precise obtainable results are precise enough. (Emphasis added) [Wilhelm, 03] Heckmann et al., The influence of processor architecture on the design and the results of wcet tools, IEEE 03 7/38
8 Contribution Propose an architecture that allows for timing predictability and composable resource sharing without sacrificing performance. 8/38


9 Architecture Improvements 10 cycle Cache 1 cycle $ Mem Avg. Time WCET Pipelines inst1 IF! ID! EX! M! WB! inst2: if x>0 IF! ID! EX! M! WB! inst3 1 cycle IF! ID! EX! M! WB! inst3 3 cycle IF! ID! EX! M! WB! Avg. Time WCET Superscalar Out of Order Multicore inst1 inst2 inst3 IF! ID! EX! M! WB! IF! ID! EX! M! WB! IF! ID! EX! M! WB! inst4 IF! ID! EX! M! WB! inst5 IF! ID! EX! M! WB! inst6 IF! ID! EX! M! WB! Avg. Time WCET Shared resources Avg. Time WCET [Courtesy of Sami Yehia, Thales] 9/38

10 Execution Time Variance [Wilhelm et al., 08] Future applications, including safety-critical and active-safety ones, need shorter latencies and time determinism - reduced jitter - to increase performance. [Sangiovanni-Vincentelli, 07] 10/38
11 Related Work Modifying Modern Processors Superscalar [Rochange et al., 05], [Whitham et al., 08] VLIW [Yan et al., 08] Multithreading [Kreuzinger et al., 00], [El-Haj-Mahmoud et al., 05] SMT [Barre et al., 08], [Mische et al., 08], [Metzlaff et al., 08] WCET Analysis Pipeline Analysis [Schneider et al., 99], [Ferdinand et al., 01], [Lagenbach et al., 02], [Kirner et al. 09] Cache Analysis [Heckmann et al., 03], [Reineke et al., 07] Stack Based Architecture Java Optimized Processor [Schoeberl, 06] 11/38
12 Precision Timed Architecture Summary of architectural features: Traditional Deep out-of-order pipelines (Instructional level parallelism) Caches (Hardware replacement policy) Best effort DRAM Controller PRET Thread-interleaved pipelines (Thread level parallelism) Scratchpads (Software controlled replacement) Predictable DRAM Controller See S. Edwards and E. A. Lee, "The Case for the Precision Timed (PRET) Machine," in the Wild and Crazy Ideas Track of the Design Automation Conference (DAC), June /38
13 Pipelining LD R1, 45(r2) DADD R5, R1, R7 BE R5, R3, R0 ST R5, 48(R2) Unpipelined The Dream F D E M W F D E M W F D E M W F D E M W F D E M W F D E M W F D E M W F D E M W F D E M W The Reality F D E M W Memory Hazard F D E M W Data Hazard F D E M W Branch Hazard Edwards, RePP 09 13/38
14 Interleaved Pipeline t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11 t12 t13 t14 F D X M W F D D D F F F D X M W F D D D F F F D X M W F D D D D PC PC PC PC IR GPR1 GPR1 X Y D$ Denelcor, HEP (1981), Lee and Messerschmitt, DSP (1987), CDC 6000 (1961) t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 F D X M W F D X M W F D X M W F D X M W F D X M W Remove Data Dependencies!! [Asonavic, CS252 lecture F07] Also called Fine Grained Multithreading! 14/38
15 Thread Interleaved Execution cycle gcd: cmp r0, r1 beq end blt less sub r0, r0, r1 b gcd less: sub r1, r1, r0 b gcd end: add r1, r1, r0 mov r3, r1 add r0, r1, r2 sub r1, r0, r1 ldr r2, [r1] sub r0, r2, r1 cmp r0, r3 cmp r0, r1 F D E M W Thread 0 add r0, r1, r2 F D E M W Thread 2 blt less F D E M W ldr r2, [r1] F D E M W Thread 4 b gcd F D E M W beq end F D E M W sub r1, r0, r1 F D E M W sub r1, r1, r0 F D E M W ldr r2, [r1] F D E M W cmp r0, r1 F D E M W cycle cycle blt less F D E M W Thread ldr r2, [r1] F D E M W cmp Thread r0, r13 cmp b gcd add r0, r1, r2 add F D E M Memory Access sub r0, r2, r1 F D E beq end beq sub r1, r0, r0 sub beq end F D blt less blt ldr r2, [r1] ldr sub r0, r0, r1 F sub r0, r0, r1 sub sub r0, r2, r1 sub b gcd cmp b cmp r0, r3 Thread 0: GCD with conditional branches Thread 1: Data dependent code 15/38
16 Interleaved Pipeline Trade-offs: Need enough concurrency to utilize processor Favor throughput over latency However Simpler WCET analysis (Timing Predictability) Interference free multiple context execution (Composability) Simple pipeline design (Energy, Cost ) Improved throughput and clock rate (Performance) 16/38


17 Memory Hierarchy CPU Register File L1 Cache CPU L2 Cache Register File Main Memory Scratchpad Memory Main Memory Use Scratchpads instead of Caches! 17/38
18 Scratchpads Trade-offs: Need explicit management from the software (compiler/programmer) However Simpler WCET analysis (Timing Predictability) Customize to workload (Performance) Simple circuit design (Energy, Cost ) 18/38

19 Main Memory DRAMs: Two key problems: Bank Conflicts DRAM Refresh Variable Access Times 19/38



20 PRET DRAM Controller Rank 0: Bank 0 Bank 1 Bank 2 Bank 3 Provides four independent and predictable resources Rank 1: Bank 0 Bank 1 Bank 2 Bank 3 Allows for predictable refreshes [Reineke, CODES 11] 20/38
21 Main Memory Trade-Offs: Shared memory on scratchpad Longer average memory latencies However Predictable access latencies (Timing Predictability) Better throughput and latency when fully utilized (Performance) Reineke et al., PRET DRAM Controller: Bank Privatization for Predictability and Temporal Isolation, CODES 11 21/38

22 PTARM PTARM Thread-Interleaved Pipeline Addr. Mux Scratchpads BootROM DRAM Controller I/O Bus UART UART Gateway DVI Controller LED Registers Integrated Logic Analyzer xcvlx110t RS232 DVI Transmitter On Board LEDs DDR2 DRAM Memory Module Download at 22/38
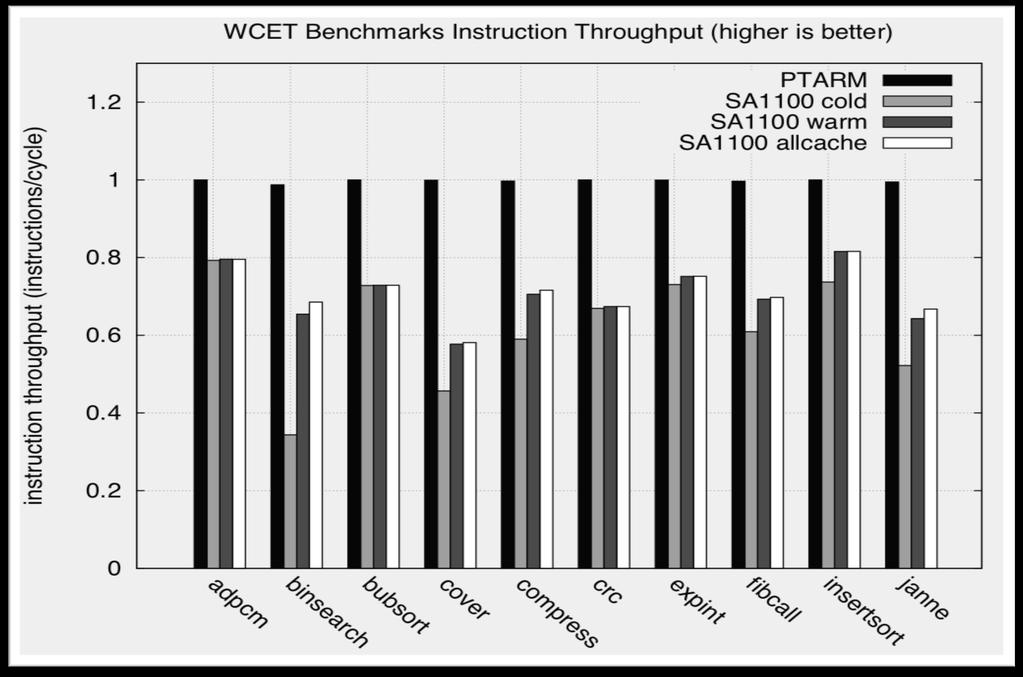
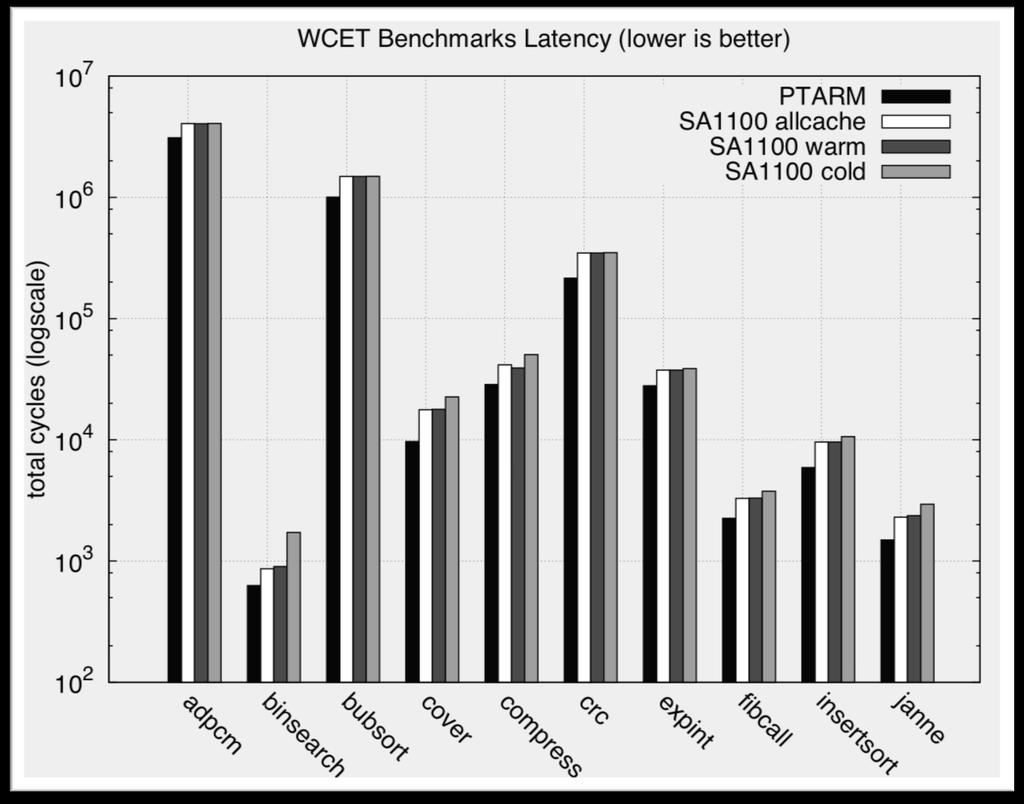
23 Pipeline Performance 23/38
24 DRAM Performance Varying Interference Varying Bandwidth Reineke et al., PRET DRAM Controller: Bank Privatization for Predictability and Temporal Isolation, CODES 11 24/38
25 Contribution Propose an architecture that allows for timing predictability and composable resource sharing without sacrificing performance. Use architectural techniques that provides composability and timing predictability Expose time in the Instruction Set Architecture. 25/38





26 Current Methods WCET Fly-by-wire aircraft controlled by software. They have to purchase and store microprocessors for at least 50 years production and maintenance 26/38
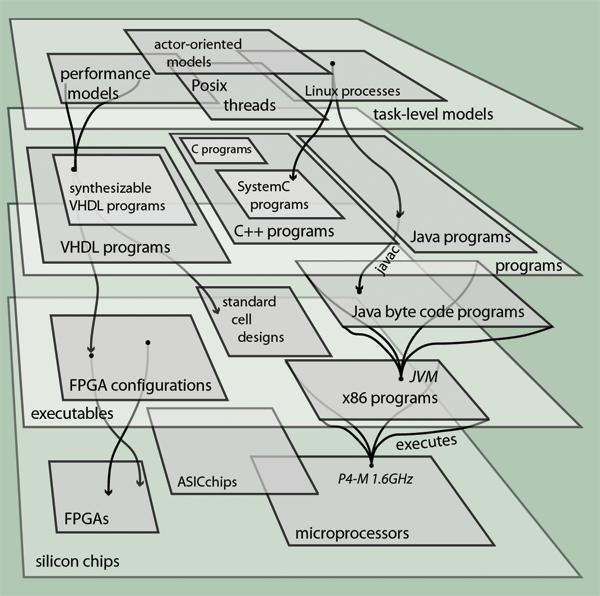

27 Levels of Abstraction [Lee, 08] 27/38
28 ISA with time Extend Instruction Set with timing instructions that specify and control timing behaviors of code blocks. Assume a platform clock synchronous with the execution of instructions Timing instructions use platform clock to control execution time Deadline of Task A) Finish the task, and detect at the end if deadline was missed B) Immediately handle a a missed deadline C) Continue as long as execution time does not exceed D) Ensure execution does not continue until specified time Task Next Task Stall Miss Handler Interrupted Code 28/38
 Processor frequency Task (execution time in clock cycles) Padding using delay until Where could this be useful?")
29 Timing Control New instruction get time (gt) gt r1, r2 ; get time (ns) -- Code block -- adds r2, r2, #500 ; add 500 ns adc r1, r1, #0 ; add with carry (time in 2 32-bit reg) du r1, r2 ; delay until 500ns have elapsed New instruction delay until (du) Processor frequency Task (execution time in clock cycles) Padding using delay until Where could this be useful? - Finishing early is not always better: - Scheduling Anomalies (Graham s anomalies) - Communication protocols and External synchronization 29/38
 ee r1, r2 ; register timer exception -- Code block -- de ;")
 Exception handler Where could this be useful?")
30 Timing Exceptions New instruction exception on expire (ee) gt r1, r2 ; get time (ns) adds r2, r2, #500 ; add 500 ns adc r1, r1, #0 ; add with carry (time in 2 32-bit reg) ee r1, r2 ; register timer exception -- Code block -- de ; deactivate exception New instruction deactivate exception (de) Processor frequency Task (execution time in clock cycles) Exception handler Where could this be useful? - Immediate deadline miss detection Hardware exception thrown 30/38
31 ISA with time Traditional Approach Programming Model Timing Dependent on the Hardware Platform Our Objective Programming Model Make time an engineering abstraction within the programming model Timing is independent of the hardware platform (within certain constraints) A Timing Requirements-Aware Scratchpad Memory Allocation Scheme for a Precision Timed Architecture [Patel et al. 08] 31/38
32 Contribution Propose an architecture that allows for timing predictability and composable resource sharing without sacrificing performance. Use architectural techniques that provides composability and timing predictability Expose time in the Instruction Set Architecture. ISA extensions to specify temporal properties 32/38


33 Real-Time Engine Fuel Rail Simulation PRET Cores 1D CFD Simulation Network of Pipes Real-Time requirements: 5.33us Common Fuel Rail: 234 nodes Implemented on Xilinx V6 FPGA 33/38


34 Timing Side-Channel Attacks Timing exploits: Algorithms Caches Branch Predictors Pipelines Root cause: uncontrollable timing side effects! Execution Time 34/38
35 Summary Problem Statement: Conventional methods are limiting the scaling of Cyber Physical Systems design because of its lack of precise timing control and analysis Solution: To rethink the design of the bottom layers of abstraction, with emphasis on temporal predictability for Cyber Physical Systems Outcome of Research: Precision To propose Timed changes Architecture in the abstraction (PRET) for layer timing to expose predictability time throughout and composability layers, and propose with ISA a computer extensions for architecture exposing temporal that focuses properties on timing predictability and composability for Cyber Physical Systems. 35/38
36 Publications Liu, Viele, Wang, Lee, Andrade, A Heterogeneous Architecture for Evaluating Real-Time One Dimensional Computational Fluid Dynamics, FCCM 12 Reineke, Liu, Patel, Kim, Lee, PRET DRAM Controller: Bank Privatization for Predictability and Temporal Isolation, CODES 11 Bui, Lee, Liu, Patel, Reineke, Temporal Isolation on Multiprocessing Architectures, DAC 11 Liu, Reineke, Lee, A PRET Architecture Supporting Concurrent Programs with Composable Timing Properties, ACSSC 10 Edwards, Kim, Lee, Liu, Patel, Schoeberl, A Disruptive Computer Design Idea: Architectures with Repeatable Timing, ICCD 09 Liu, Lickly, Patel, Lee, Poster Abstract: Timing Instructions - ISA Extensions for Timing Guarantees, RTAS 09 Liu and McGrogan. Elimination of Side Channel Attacks on a Precision Timed Architecture, Technical Report, UCB 2009 Lickly, Liu, Kim, Patel, Edwards, Lee, Predictable Programming on a Precision Timed Architecture, CASES 08 36/38

37 Thank You Please visit Questions?
38 BACKUP SLIDES 38/25
39 Thank You Qual Committee Edward A. Lee - Berkeley Hiren Patel Univ. of Waterloo Martin Schoeberl Univ. of Denmark Stephen A. Edwards Columbia Univ. Ben Lickly, Sungjun Kim John Eidson, Marc Geilen, Sami Yehia (Thales), Maarten Wiggers, Jan Reineke, Slobodon Matic, Jia Zou Christopher Brooks, Mary Stewart My Family 39/25




40 Research Efforts In All Fronts 40/25
41 Definitions Predictability The ability to analyze the execution time Repeatability The ability to repeat the execution given the same inputs Composability The functional and temporal behavior of an application is the same, irrespective of the presence or absence of other applications Robust Small changes in input leads to small changes in output 41/25

42 WCET Analysis 42/25
43 Computer Architecture Typical metrics in processor design for Embedded Systems Performance (Average Case) Power Area (Size) Compiler Support (Developmental Effort) Cost Multiple Context Analyzability 43/25
44 Branch Prediction Anomaly Experiment for{k=1; k<32; k++) { starttimer(); for(n=0; n < ; n++) // OUTER LOOP { for(i=0; i < k; i++) // INNER LOOP { nop(); // Some compiler-dependent way to get a nop } } stoptimer(); recordtime(); } 44/25

45 Richard s Anomalies Increasing the number of processors C 1 = 3 C 2 = C 9 = 9 C 8 = 4 9 tasks with precedences and the shown execution times, where lower numbered tasks have higher priority than higher numbered tasks. Optimal 3 processor schedule: C 3 = C 7 = 4 C 4 = C 6 = 4 5 C 5 = 4 The optimal schedule with four processors has a longer execution time. 45/25

46 Richard s Anomalies Reducing all execution times by 1 Reducing computation times C 1 = 2 C 2 = C 9 = 8 C 8 = 3 9 tasks with precedences and the shown execution times, where lower numbered tasks have higher priority than higher numbered tasks. Optimal 3 processor schedule: C 3 = C 7 = 3 C 4 = C 6 = 3 5 C 5 = 3 Reducing the computation times by 1 also results in a longer execution time. 46/25

47 Richard s Anomalies Removing precedence constraints Weakening the precedence constraints C 1 = 3 C 2 = C 9 = 9 C 8 = 4 9 tasks with precedences and the shown execution times, where lower numbered tasks have higher priority than higher numbered tasks. Optimal 3 processor schedule: C 3 = C 7 = 4 C 4 = C 6 = 4 5 C 5 = 4 Weakening precedence constraints can also result in a longer schedule. 47/25
48 Progress Work Completed: SPARC instruction set simulator C++ cycle accurate simulator PTARM architecture Synthesizable VHDL ARM core VGA controller and Serial Communication Work in Progress: WCET analysis tool (~2 weeks) Benchmarking the pipeline (~ 1 semester) Scratchpad allocation with timed programming models (~1 semester) Proof of concept workflow (~ 1 semesters) 48/25
49 Contribution Expose time in the abstraction layers. ISA extensions to specify temporal properties Propose an architecture that allows for timing predictability and composable resource sharing. 49/25
Precision Timed (PRET) Machines
 Machines") Precision Timed (PRET) Machines Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley BWRC Open House, Berkeley, CA February, 2012 Key Collaborators on work shown here: Steven Edwards Jeff
Precision Timed (PRET) Machines Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley BWRC Open House, Berkeley, CA February, 2012 Key Collaborators on work shown here: Steven Edwards Jeff
Design and Analysis of Time-Critical Systems Timing Predictability and Analyzability + Case Studies: PTARM and Kalray MPPA-256
 Design and Analysis of Time-Critical Systems Timing Predictability and Analyzability + Case Studies: PTARM and Kalray MPPA-256 Jan Reineke @ saarland university computer science ACACES Summer School 2017
Design and Analysis of Time-Critical Systems Timing Predictability and Analyzability + Case Studies: PTARM and Kalray MPPA-256 Jan Reineke @ saarland university computer science ACACES Summer School 2017
Precision Timed Machines
 Precision Timed Machines Isaac Liu Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-113 http://www.eecs.berkeley.edu/pubs/techrpts/2012/eecs-2012-113.html
Precision Timed Machines Isaac Liu Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-113 http://www.eecs.berkeley.edu/pubs/techrpts/2012/eecs-2012-113.html
Predictable Programming on a Precision Timed Architecture
 Predictable Programming on a Precision Timed Architecture Ben Lickly, Isaac Liu, Hiren Patel, Edward Lee, University of California, Berkeley Sungjun Kim, Stephen Edwards, Columbia University, New York
Predictable Programming on a Precision Timed Architecture Ben Lickly, Isaac Liu, Hiren Patel, Edward Lee, University of California, Berkeley Sungjun Kim, Stephen Edwards, Columbia University, New York
Timing Analysis of Embedded Software for Families of Microarchitectures
 Analysis of Embedded Software for Families of Microarchitectures Jan Reineke, UC Berkeley Edward A. Lee, UC Berkeley Representing Distributed Sense and Control Systems (DSCS) theme of MuSyC With thanks
Analysis of Embedded Software for Families of Microarchitectures Jan Reineke, UC Berkeley Edward A. Lee, UC Berkeley Representing Distributed Sense and Control Systems (DSCS) theme of MuSyC With thanks
The Internet of Important Things
 The Internet of Important Things Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Keynote Time Sensitive Networks and Applications (TSNA) April 28-29, 2015. Santa Clara, CA The Context
The Internet of Important Things Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Keynote Time Sensitive Networks and Applications (TSNA) April 28-29, 2015. Santa Clara, CA The Context
Temporal Semantics in Concurrent and Distributed Software
 Temporal Semantics in Concurrent and Distributed Software Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Workshop on Strategic Directions in Software at Scale (S@S) Berkeley, CA, August
Temporal Semantics in Concurrent and Distributed Software Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Workshop on Strategic Directions in Software at Scale (S@S) Berkeley, CA, August
Embedded Tutorial CPS Foundations
 Embedded Tutorial CPS Foundations Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Special Session: Cyber-Physical Systems Demystified Design Automation Conference (DAC 2010) Annaheim,
Embedded Tutorial CPS Foundations Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Special Session: Cyber-Physical Systems Demystified Design Automation Conference (DAC 2010) Annaheim,
Reconciling Repeatable Timing with Pipelining and Memory Hierarchy
 Reconciling Repeatable Timing with Pipelining and Memory Hierarchy Stephen A. Edwards 1, Sungjun Kim 1, Edward A. Lee 2, Hiren D. Patel 2, and Martin Schoeberl 3 1 Columbia University, New York, NY, USA,
Reconciling Repeatable Timing with Pipelining and Memory Hierarchy Stephen A. Edwards 1, Sungjun Kim 1, Edward A. Lee 2, Hiren D. Patel 2, and Martin Schoeberl 3 1 Columbia University, New York, NY, USA,
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
Assuming ideal conditions (perfect pipelining and no hazards), how much time would it take to execute the same program in: b) A 5-stage pipeline?
, how much time would it take to execute the same program in: b) A 5-stage pipeline?") 1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
Single-Path Programming on a Chip-Multiprocessor System
 Single-Path Programming on a Chip-Multiprocessor System Martin Schoeberl, Peter Puschner, and Raimund Kirner Vienna University of Technology, Austria mschoebe@mail.tuwien.ac.at, {peter,raimund}@vmars.tuwien.ac.at
Single-Path Programming on a Chip-Multiprocessor System Martin Schoeberl, Peter Puschner, and Raimund Kirner Vienna University of Technology, Austria mschoebe@mail.tuwien.ac.at, {peter,raimund}@vmars.tuwien.ac.at
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
PTIDES: A Discrete-Event-Based Programming Model for Distributed Embedded Systems
 PTIDES: A Discrete-Event-Based Programming Model for Distributed Embedded Systems John C. Eidson Edward A. Lee Slobodan Matic Sanjit A. Seshia Jia Zou UC Berkeley Tutorial on Modeling and Analyzing Real-Time
PTIDES: A Discrete-Event-Based Programming Model for Distributed Embedded Systems John C. Eidson Edward A. Lee Slobodan Matic Sanjit A. Seshia Jia Zou UC Berkeley Tutorial on Modeling and Analyzing Real-Time
Synthesis of Distributed Real- Time Embedded Software
 Synthesis of Distributed Real- Time Embedded Software Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Keynote talk Electronic System Level Synthesis Conference June 5-6, 2011 San Diego,
Synthesis of Distributed Real- Time Embedded Software Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Keynote talk Electronic System Level Synthesis Conference June 5-6, 2011 San Diego,
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
A Template for Predictability Definitions with Supporting Evidence
 A Template for Predictability Definitions with Supporting Evidence Daniel Grund 1, Jan Reineke 2, and Reinhard Wilhelm 1 1 Saarland University, Saarbrücken, Germany. grund@cs.uni-saarland.de 2 University
A Template for Predictability Definitions with Supporting Evidence Daniel Grund 1, Jan Reineke 2, and Reinhard Wilhelm 1 1 Saarland University, Saarbrücken, Germany. grund@cs.uni-saarland.de 2 University
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CS 152 Computer Architecture and Engineering. Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Multithreading Processors and Static Optimization Review. Adapted from Bhuyan, Patterson, Eggers, probably others
 Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Computer Systems Architecture Spring 2016
 Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Short Answer: [3] What is the primary difference between Tomasulo s algorithm and Scoreboarding?
![Short Answer: [3] What is the primary difference between Tomasulo s algorithm and Scoreboarding?](/thumbs/83/88057083.jpg "Short Answer: [3] What is the primary difference between Tomasulo s algorithm and Scoreboarding?") Short Answer: [] What is the primary difference between Tomasulo s algorithm and Scoreboarding? [] Which data hazard occurs when instructions are allowed to complete out of order? Which one occurs when
Short Answer: [] What is the primary difference between Tomasulo s algorithm and Scoreboarding? [] Which data hazard occurs when instructions are allowed to complete out of order? Which one occurs when
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Two hours. No special instructions. UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE. Date. Time
 Two hours No special instructions. UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date Time Please answer any THREE Questions from the FOUR questions provided Use a SEPARATE answerbook
Two hours No special instructions. UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date Time Please answer any THREE Questions from the FOUR questions provided Use a SEPARATE answerbook
Computing Needs Time
 Computing Needs Time Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Invited Talk: Distinguished Lecture Series on Cyber-Physical Systems Thanks to: Danica Chang David Culler Gage Eads
Computing Needs Time Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Invited Talk: Distinguished Lecture Series on Cyber-Physical Systems Thanks to: Danica Chang David Culler Gage Eads
The University of Texas at Austin
 EE382 (20): Computer Architecture - Parallelism and Locality Lecture 4 Parallelism in Hardware Mattan Erez The University of Texas at Austin EE38(20) (c) Mattan Erez 1 Outline 2 Principles of parallel
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 4 Parallelism in Hardware Mattan Erez The University of Texas at Austin EE38(20) (c) Mattan Erez 1 Outline 2 Principles of parallel
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
CPU Pipelining Issues
 CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
 ECE 154B Dmitri Strukov") Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Model-Based Design for Signal Processing Systems
 Model-Based Design for Signal Processing Systems Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Invited Keynote Talk IEEE Workshop on Signal Processing Systems (SiPS) Tampere, Finland
Model-Based Design for Signal Processing Systems Edward A. Lee Robert S. Pepper Distinguished Professor UC Berkeley Invited Keynote Talk IEEE Workshop on Signal Processing Systems (SiPS) Tampere, Finland
Predictable Processors for Mixed-Criticality Systems and Precision-Timed I/O
 Predictable Processors for Mixed-Criticality Systems and Precision-Timed I/O Michael Zimmer Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2015-181
Predictable Processors for Mixed-Criticality Systems and Precision-Timed I/O Michael Zimmer Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2015-181
Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
From Application to Technology OpenCL Application Processors Chung-Ho Chen
 From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
CHAPTER 8: CPU and Memory Design, Enhancement, and Implementation
 CHAPTER 8: CPU and Memory Design, Enhancement, and Implementation The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 5th Edition, Irv Englander John
CHAPTER 8: CPU and Memory Design, Enhancement, and Implementation The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 5th Edition, Irv Englander John
Pipelining, Instruction Level Parallelism and Memory in Processors. Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010
 Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Design and Analysis of Real-Time Systems Predictability and Predictable Microarchitectures
 Design and Analysis of Real-Time Systems Predictability and Predictable Microarcectures Jan Reineke Advanced Lecture, Summer 2013 Notion of Predictability Oxford Dictionary: predictable = adjective, able
Design and Analysis of Real-Time Systems Predictability and Predictable Microarcectures Jan Reineke Advanced Lecture, Summer 2013 Notion of Predictability Oxford Dictionary: predictable = adjective, able
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 14 - Cache Design and Coherence 2014-3-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 Today:
CS 152 Computer Architecture and Engineering Lecture 14 - Cache Design and Coherence 2014-3-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 Today:
Towards a Time-predictable Dual-Issue Microprocessor: The Patmos Approach
 Towards a Time-predictable Dual-Issue Microprocessor: The Patmos Approach Martin Schoeberl 1, Pascal Schleuniger 1, Wolfgang Puffitsch 2, Florian Brandner 3, Christian W. Probst 1, Sven Karlsson 1, and
Towards a Time-predictable Dual-Issue Microprocessor: The Patmos Approach Martin Schoeberl 1, Pascal Schleuniger 1, Wolfgang Puffitsch 2, Florian Brandner 3, Christian W. Probst 1, Sven Karlsson 1, and
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
Using a Model Checker to Determine Worst-case Execution Time
 Using a Model Checker to Determine Worst-case Execution Time Sungjun Kim Department of Computer Science Columbia University New York, NY 10027, USA skim@cs.columbia.edu Hiren D. Patel Electrical Engineering
Using a Model Checker to Determine Worst-case Execution Time Sungjun Kim Department of Computer Science Columbia University New York, NY 10027, USA skim@cs.columbia.edu Hiren D. Patel Electrical Engineering
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Research Article Time-Predictable Computer Architecture
 Hindawi Publishing Corporation EURASIP Journal on Embedded Systems Volume 2009, Article ID 758480, 17 pages doi:10.1155/2009/758480 Research Article Time-Predictable Computer Architecture Martin Schoeberl
Hindawi Publishing Corporation EURASIP Journal on Embedded Systems Volume 2009, Article ID 758480, 17 pages doi:10.1155/2009/758480 Research Article Time-Predictable Computer Architecture Martin Schoeberl
Design and Analysis of Time-Critical Systems Introduction
 Design and Analysis of Time-Critical Systems Introduction Jan Reineke @ saarland university ACACES Summer School 2017 Fiuggi, Italy computer science Structure of this Course 2. How are they implemented?
Design and Analysis of Time-Critical Systems Introduction Jan Reineke @ saarland university ACACES Summer School 2017 Fiuggi, Italy computer science Structure of this Course 2. How are they implemented?
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions.
 Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
Embedded Systems. 8. Hardware Components. Lothar Thiele. Computer Engineering and Networks Laboratory
 Embedded Systems 8. Hardware Components Lothar Thiele Computer Engineering and Networks Laboratory Do you Remember? 8 2 8 3 High Level Physical View 8 4 High Level Physical View 8 5 Implementation Alternatives
Embedded Systems 8. Hardware Components Lothar Thiele Computer Engineering and Networks Laboratory Do you Remember? 8 2 8 3 High Level Physical View 8 4 High Level Physical View 8 5 Implementation Alternatives
" # " $ % & ' ( ) * + $ " % '* + * ' "
 * + $ % '* + * '") ! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
FlexPRET: A Processor Platform for Mixed-Criticality Systems
 FlexPRET: A Processor Platform for Mixed-Criticality Systems Michael Zimmer David Broman Christopher Shaver Edward A. Lee Electrical Engineering and Computer Sciences University of California at Berkeley
FlexPRET: A Processor Platform for Mixed-Criticality Systems Michael Zimmer David Broman Christopher Shaver Edward A. Lee Electrical Engineering and Computer Sciences University of California at Berkeley
Suggested Readings! Recap: Pipelining improves throughput! Processor comparison! Lecture 17" Short Pipelining Review! ! Readings!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
FlexPRET: A Processor Platform for Mixed-Criticality Systems
 This is the author prepared accepted version. 2014 IEEE. The published version is: Michael Zimmer, David Broman, Chris Shaver, and Edward A. Lee. FlexPRET: A Processor Platform for Mixed-Criticality Systems.
This is the author prepared accepted version. 2014 IEEE. The published version is: Michael Zimmer, David Broman, Chris Shaver, and Edward A. Lee. FlexPRET: A Processor Platform for Mixed-Criticality Systems.
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
CS 152 Computer Architecture and Engineering. Lecture 5 - Pipelining II (Branches, Exceptions)
") CS 152 Computer Architecture and Engineering Lecture 5 - Pipelining II (Branches, Exceptions) John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 5 - Pipelining II (Branches, Exceptions) John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Outline. Exploiting Program Parallelism. The Hydra Approach. Data Speculation Support for a Chip Multiprocessor (Hydra CMP) HYDRA
 HYDRA") CS 258 Parallel Computer Architecture Data Speculation Support for a Chip Multiprocessor (Hydra CMP) Lance Hammond, Mark Willey and Kunle Olukotun Presented: May 7 th, 2008 Ankit Jain Outline The Hydra
CS 258 Parallel Computer Architecture Data Speculation Support for a Chip Multiprocessor (Hydra CMP) Lance Hammond, Mark Willey and Kunle Olukotun Presented: May 7 th, 2008 Ankit Jain Outline The Hydra
SIC: Provably Timing-Predictable Strictly In-Order Pipelined Processor Core
 SIC: Provably Timing-Predictable Strictly In-Order Pipelined Processor Core Sebastian Hahn and Jan Reineke RTSS, Nashville December, 2018 saarland university computer science SIC: Provably Timing-Predictable
SIC: Provably Timing-Predictable Strictly In-Order Pipelined Processor Core Sebastian Hahn and Jan Reineke RTSS, Nashville December, 2018 saarland university computer science SIC: Provably Timing-Predictable
CPU Architecture Overview. Varun Sampath CIS 565 Spring 2012
 CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
Portable Real-Time Code from PTIDES Models
 Portable Real-Time Code from PTIDES Models Patricia Derler, John Eidson, Edward A. Lee, Slobodan Matic, Christos Stergiou, Michael Zimmer UC Berkeley Invited Talk Workshop on Time Analysis and Model-Based
Portable Real-Time Code from PTIDES Models Patricia Derler, John Eidson, Edward A. Lee, Slobodan Matic, Christos Stergiou, Michael Zimmer UC Berkeley Invited Talk Workshop on Time Analysis and Model-Based
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Multithreading and the Tera MTA. Multithreading for Latency Tolerance
 Multithreading and the Tera MTA Krste Asanovic krste@lcs.mit.edu http://www.cag.lcs.mit.edu/6.893-f2000/ 6.893: Advanced VLSI Computer Architecture, October 31, 2000, Lecture 6, Slide 1. Krste Asanovic
Multithreading and the Tera MTA Krste Asanovic krste@lcs.mit.edu http://www.cag.lcs.mit.edu/6.893-f2000/ 6.893: Advanced VLSI Computer Architecture, October 31, 2000, Lecture 6, Slide 1. Krste Asanovic
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Improve performance by increasing instruction throughput
 Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Computer Architecture Crash course
 Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Timing Predictability of Processors
 Timing Predictability of Processors Introduction Airbag opens ca. 100ms after the crash Controller has to trigger the inflation in 70ms Airbag useless if opened too early or too late Controller has to
Timing Predictability of Processors Introduction Airbag opens ca. 100ms after the crash Controller has to trigger the inflation in 70ms Airbag useless if opened too early or too late Controller has to
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
ait: WORST-CASE EXECUTION TIME PREDICTION BY STATIC PROGRAM ANALYSIS
 ait: WORST-CASE EXECUTION TIME PREDICTION BY STATIC PROGRAM ANALYSIS Christian Ferdinand and Reinhold Heckmann AbsInt Angewandte Informatik GmbH, Stuhlsatzenhausweg 69, D-66123 Saarbrucken, Germany info@absint.com
ait: WORST-CASE EXECUTION TIME PREDICTION BY STATIC PROGRAM ANALYSIS Christian Ferdinand and Reinhold Heckmann AbsInt Angewandte Informatik GmbH, Stuhlsatzenhausweg 69, D-66123 Saarbrucken, Germany info@absint.com
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer