CS 152 Computer Architecture and Engineering
|
|
|
- Samson Greene
- 5 years ago
- Views:
Transcription
1 CS 152 Computer Architecture and Engineering Lecture 14 - Cache Design and Coherence John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1
2 Today: Shared Cache Design and Coherence CPU... CPU CPU multi-threading Keeps memory system busy. Private Cache... Private Cache Crossbars and Rings How to do on-chip sharing. Shared Caches DRAM Shared Ports I/O Concurrent requests Interfaces that don t stall. Coherency Protocols Building coherent caches. 2

3 Multithreading Sun Microsystems Niagara series 3
4 The case for multithreading Amdahl s Law tells us that optimizing C is the wrong thing to do... Some applications spend their lives waiting for memory. C = compute M = waiting Single issue ILP TLP (on shared single issue pipeline) C M C M C M C M C M C M C C M C M M Time saved Memory latency Compute latency Idea: Create a design that can multiplex threads onto one pipeline. Goal: Maximize throughput of a large number of threads. 4
5 Multi-threading: Assuming perfect caches Interleave 4 threads, T1-T4, on non-bypassed 5-stage pipe T1: LW r1, 0(r2) T2: ADD r7, r1, r4 T3: XORI r5, r4, #12 T4: SW 0(r7), r5 T1: LW r5, 12(r1) Labels show this state: t0 t1 t2 t3 t4 t5 t6 t7 t8 F D X M W F D X M W F D X M W F D X M W F D X M W t9 Last instruction in a thread always completes writeback before next instruction in same thread reads regfile 4 CPUs, 1/4 clock. S. Cray, PC PC PC 1 PC I$ IR GPR1 GPR1 GPR1 GPR1 X Y D$ +1 T4 2 Thread select 2 T3 T2 T1 5
6 Bypass network is no longer needed... Result: Critical path shortens -- can trade for speed or power. IR ID (Decode) IR EX IR MEM IR WE, MemToReg WB Mux,Logic From WB 32 op rs1 rs2 RegFile rd1 A 32 A L U 32 Y Data Memory Addr Dout Din WE MemToReg R ws wd WE rd2 M M Ext B 6
7 Multi-threading: Supporting cache misses A thread scheduler keeps track of information about all threads that share pipeline. When a thread experiences a cache miss, it is taken off the pipeline during the miss penalty period. PC PC PC 1 PC I$ IR GPR1 GPR1 GPR1 GPR1 X Y D$ +1 Thread scheduler 7

8 Sun Niagara II # threads/core? 8 threads/core: Enough to keep one core busy, given clock speed, memory system latency, and target application characteristics. 8
9 Crossbar Networks 9
10 Shared-memory CPU Private Cache Shared Caches DRAM Shared Ports I/O CPU Private Cache CPUs share lower level of memory system, and I/O. Common address space, one operating system image. Communication occurs through the memory system (100ns latency, 20 GB/s bandwidth) 10
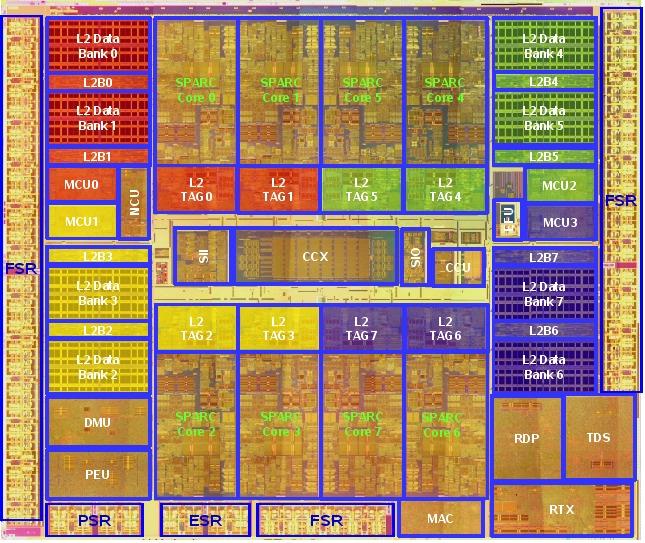
11 Sun s Niagara II: Single-chip implementation... SPC == SPARC Core. Only DRAM is not on chip. 11
12 Crossbar: Like N ports on an N-register file sel(ws) 5 WE D E M U X... clk wd R0 - The constant 0 Q 32 Flexible, but... reads slows down as O(N 2 )... D D D En En En R1 R2... R31 Q Q Q... Why? Number of loads on each Q goes as O(N), and the wire length to port mux goes as O(N) sel(rs1)... M U X M U X 5 32 rd1 sel(rs2) rd2 12
13 Design challenge: High-performance crossbar Niagara II: 8 cores, 8 L2 banks, 4 DRAM channels. Apps are locality-poor. Goal: saturate DRAM BW. Each DRAM channel: 50 GB/s Read, 25 GB/s Write BW. Crossbar BW: 270 GB/s total (Read + Write). 13
14 Sun Niagara II 8 x 9 Crossbar Tri-state distributed mux, as in microcode talk. Every cross of blue and purple is a tri-state buffer with a unique control signal. 72 control signals (if distributed unencoded). 14
 100-200 wires/ port (each way).")

15 Sun Niagara II 8 x 9 Crossbar 8 ports on CPU side (one per core) wires/ port (each way). 4 cycle latency (715ps/cycle). Cycles 1-3 are for arbitration. Transmit data on cycle 4. Pipelined. 8 ports for L2 banks, plus one for I/0 15
16 A complete switch transfer (4 epochs) Epoch 1: All input ports (that are ready to send data) request an output port. Epoch 2: Allocation algorithm decides which inputs get to write. Epoch 3: Allocation system informs the winning inputs and outputs. Epoch 4: Actual data transfer takes place. Allocation is pipelined: a data transfer happens on every cycle, as does the three allocation stages, for different sets of requests. 16
 W X Y Z A 0 0 1 0 B 1 0 0 0 C 0 0 1 0 D 1 0 0 0 A 1 codes that an input")


17 Epoch 3: The Allocation Problem (4 x 4) Output Ports (W, X, Y, Z) Input Ports (A, B, C, D) W X Y Z A B C D A 1 codes that an input has data ready to send to an output. Allocator returns a matrix with at most one 1 in each row and column to set switches. Algorithm should be fair, so no port always loses... should also scale to run large matrices fast. CS 152 L21: Networks and Routers W X Y Z A B C D UC Regents Fall 2006 UCB 17
18 Sun Niagara II Crossbar Notes Low latency: 4 cycles (less than 3 ns). Uniform latency between all port pairs. Crossbar defines floorplan: all port devices should be equidistant to the crossbar. 18
19 19



20 Sun Niagara II Energy Facts Crossbar only 1% of total power. 20
21 Sun Niagara II Crossbar Notes Low latency: 4 cycles (less than 3 ns). Uniform latency between all port pairs. Crossbar defines floorplan: all port devices should be equidistant to the crossbar. Did not scale up for 16-core Rainbow Falls. Rainbow Falls keeps the 8 x 9 crossbar, and shares each CPU-side port with two cores. Design alternatives to crossbar? 21

22 CLOS Networks: From telecom world... Build a high-port switch by tiling fixed-sized shuffle units. Pipeline registers naturally fit between tiles. Trades scalability for latency. 22

23 CLOS Networks: An example route Numbers on left and right are port numbers. Colors show routing paths for an exchange. Arbitration still needed to prevent blocking. 23
24 Ring Networks 24

25 Intel Xeon Data Center server chip 20% of Intel s revenues, 40% of profits. Why? Cloud is growing, Xeon is dominant. 25
26 Compiled Chips Xeon is a chip family, varying by # of cores, L3 cache size. Chip family mask layouts generated automatically, by adding core/cache slices. Ring Bus 26
27 Bi-directional Ring Bus connects: Cores, cache banks, DRAM controllers, off-chip I/O. Chip compiler might size the ring bus to scale bandwidth with # of cores. Ring latency increases with # of cores. But compared to baseline, small. Ring Stop 27


28 Tiles along x-axis are 20 ways of cache 2.5 MB L3 cache slice from Xeon E5 Ring stop interface lives in the Cache Control Box (CBOX) Wednesday, March 5, Fig MB L3 cache floor-plan. 28
29 Ring bus (perhaps 1024 wires), with address, data, and header fields (sender #, recipient #, command) 1024 Ring Stop #1 Ring Stop #2 Ring Stop #3 Empty Data Data Out In Control Ring Stop #2 Interface Reading: Sense Data Out to see if message is for Ring Stop #2. If so, latch data, mux Empty onto ring. Writing: Check is Data Out is Empty. If so, mux a message onto the ring via the Data In port. 29
30 In practice: Extreme EE to co-optimize bandwidth, reliability. 30
31 Debugging: Network analyzer built into chip to capture ring messages of a particular kind. Sent off chip via an aux port. 31


32 A derivative of this ring bus is also used on laptop and desktop chips. 32
33 Break Play: 33
34 Hit-over-Miss Caches 34
35 Recall: CPU-cache port that doesn t stall on a miss CPU makes a request by placing the following items in Queue 1: CMD: Read, write, etc... From CPU To CPU Queue 1 Queue 2 MTYPE: 8-bit, 16-bit, 32-bit, or 64-bit. TAG: 9-bit number identifying the request. MADDR: Memory address of first byte. STORE-DATA: For stores, the data to store. 35
36 This cache is used in an ASPIRE CPU (Rocket) When request is ready, cache places the following items in Queue 2: From CPU To CPU Queue 1 Queue 2 TAG: Identity of the completed command. LOAD-DATA: For loads, the requested data. CPU saves info about requests, indexed by TAG. Why use TAG approach? Multiple misses can proceed in parallel. Loads can return out of order. 36
37 Today: How a read request proceeds in L1 D-Cache CPU requests a read by placing MTYPE, TAG, MADDR in Queue 1. From CPU To CPU Queue 1 Queue 2 We == L1 D-Cache controller We do a normal cache access. If there is a hit, we put place load result in Queue 2... In the case of a miss, we use the Inverted Miss Status Holding Register. 37
38 Inverted MSHR (Miss Status Holding Register) (1) Associatively look up block # of memory address in table. If there are no hits, do memory request. To look up a memory address... Cache Block # 42 0 Valid Bit MTYPE 1 0 1st Byte in Block 4 0 Tag ID (ROM) 8 0 = 0 Hit Valid Qualifies Hit [... ] 512-entry table, so that every 9-bit TAG value has an entry. [... ] = 511 Hit Valid Qualifies Hit Assumptions: 32-byte blocks, 48-bit physical address space. 38
39 Inverted MSHR (Miss Status Holding Register) (2) Index into table using 9-bit TAG, and set all fields using MADDR and MTYPE queue values. To look up a memory address... This indexing always finds V=0, because CPU promises not to reuse in-flight tags. Cache Block # 42 0 Valid Bit MTYPE st Byte in Block 4 0 TAG (9 bits) Tag ID (ROM) 8 0 = 0 Hit Valid Qualifies Hit [... ] 512-entry table, so that every 9-bit TAG value has an entry. [... ] = 511 Hit Valid Qualifies Hit Assumptions: 32-byte blocks, 48-bit physical address space. 39
40 Inverted MSHR (Miss Status Holding Register) (3) Whenever memory system returns data, associatively look up block # to find all pending transactions. Place transaction data for all hits in Queue 2, and clear valid bits. Also update L1 cache. To look up a memory address... Cache Block # 42 0 Valid Bit MTYPE 1 0 1st Byte in Block 4 0 Tag ID (ROM) 8 0 = 0 Hit Valid Qualifies Hit [... ] 512-entry table, so that every 9-bit TAG value has an entry. [... ] = 511 Hit Valid Qualifies Hit Assumptions: 32-byte blocks, 48-bit physical address space. 40
41 Inverted MHSR notes. Structural hazards only occur when TAG space is exhausted by the CPU. High cost (# comparators + SRAM cells). See Farkas and Jouppi on class website, for low-cost designs that are often good enough. We will return to MHSRs to discuss CPI performance later in the semester. 41
42 Coherency Hardware 42
43 Cache Placement 43
44 Two CPUs, two caches, shared DRAM... CPU0 Cache CPU1 Cache Addr Value Addr Value Shared Main Memory Addr 16 Value 5 Write-through caches 0 CPU0: LW R2, 16(R0) CPU1: LW R2, 16(R0) CPU1: SW R0,16(R0) View of memory no longer coherent. Loads of location 16 from CPU0 and CPU1 see different values! Today: What to do... 44
45 The simplest solution... one cache! CPU0 CPU1 Memory Switch Shared Multi-Bank Cache Shared Main Memory CPUs do not have internal caches. Only one cache, so different values for a memory address cannot appear in 2 caches! Multiple caches banks support read/writes by both CPUs in a switch epoch, unless both target same bank. In that case, one request is stalled. 45
46 Not a complete solution... good for L2. CPU0 CPU1 For modern clock rates, access to shared cache through switch takes 10+ cycles. Memory Switch Shared Multi-Bank Cache Using shared cache as the L1 data cache is tantamount to slowing down clock 10X for LWs. Not good. Shared Main Memory Sequent Systems (1980s) This approach was a complete solution in the days when DRAM row access time and CPU clock period were well matched. 46
47 Modified form: Private L1s, shared L2 CPU0 CPU1 L1 Caches L1 Caches Memory Switch or Bus Shared Multi-Bank L2 Cache Shared Main Memory Thus, we need to solve the cache coherency problem for L1 cache. Advantages of shared L2 over private L2s: Processors communicate at cache speed, not DRAM speed. Constructive interference, if both CPUs need same data/instr. Disadvantage: CPUs share BW to L2 cache... 47

48 IBM Power 4 (2001) Dual core Shared, multi-bank L2 cache. Private L1 caches Off-chip L3 caches 48
49 Cache Coherency 49
50 Cache coherency goals... Addr CPU0 Cache Value CPU1 Shared Memory Hierarchy Addr 16 Addr Cache Value Value Only one processor at a time has write permission for a memory location. 2. No processor can load a stale copy of a location after a write. 50
51 Simple Implementation: Snoopy Caches CPU0 CPU1 Cache Snooper Cache Memory bus Snooper Shared Main Memory Hierarchy Each cache has the ability to sno op on memory bus transactions of other CPUs. The bus also has mechanisms to let a CPU intervene to stop a bus transaction, and to invalidate cache lines of other CPUs. 51
52 Writes from 10,000 feet... for write-thru L1 For write-thru caches... Cache CPU0 Snooper Cache Memory bus CPU1 Shared Main Memory Hierarchy Snooper To a first-order, reads will just work if write-thru caches implement this policy. A two-state protocol (cache lines are valid or invalid ). 1. Writing CPU takes control of bus. 2. Address to be written is invalidated in all other caches. Reads will no longer hit in cache and get stale data. 3. Write is sent to main memory. Reads will cache miss, retrieve new value from main memory 52
53 Limitations of the write-thru approach CPU0 CPU1 Every write goes to the bus. Cache Snooper Cache Memory bus Shared Main Memory Hierarchy Snooper Total bus write bandwidth does not support more than 2 CPUs, in modern practice. Write-back big trick: add extra states. Simplest version: MSI -- Modified, Shared, Invalid. More efficient versions add more states (MESI adds Exclusive). State definitions are subtle... To scale further, we need to use write-back caches. 53





54 Figure 5.5, page the best starting point. 54
55 Read misses... for a MESI protocol... For write-back caches... Cache CPU0 Snooper Cache Memory bus CPU1 Shared Main Memory Hierarchy Snooper These sketches are just to give you a sense of how coherency protocols work. Deep understand requires understanding the complete state machine for protocol. 1. A cache requests a cache-line fill for a read miss. 2. Another cache with an exclusive on this line responds with fresh data. Reads miss will not hit main memory, retrieve stale data. 3. The responding cache changes line from exclusive to modified. Future writes will go to bus to be snooped.. 55
56 Snoopy mechanism doesn t scale... CPU0 CPU1 Cache Snooper Cache Memory bus Snooper Shared Main Memory Hierarchy Single-chip implementations have moved to a centralized directory service that tracks the status of each line of each private cache. Multi-socket systems use distributed directories. 56

57 Directories attached to on-chip cache network... 57
58 2 socket system... each socket a multi-core chip Each chip has its own bank of DRAM. 58

59 Distributed directories for multi-socket systems Directories for Chip 0... and Chip 1 L1 L1 L2 L2 Directory for Chip 0 DRAM. Directory for Chip 1 DRAM. 59


60 Figure 5.21, page directory message basics Conceptually similar to snoopy caches... but the different mechanisms require rethinking the protocol to get correct behaviors. 60
61 Other Machine Architectures 61
62 NUMA: Non-uniform Memory Access CPU 0... CPU 1023 Each CPU has part of main memory attached to it. Cache DRAM Cache DRAM To access other parts of main memory, use the interconnection network. Interconnection Network Network uses coherent global address space. Directory protocols over fiber networking. For best results, applications take the non-uniform memory latency into account. 62
.")
63 Clusters: Supercomputing version of WSC Connect large numbers of 1-CPU or 2-CPU rack mount computers together with high-end network technology (not normal Ethernet). University of Illinois, CPU Apple Xserve cluster, connected with Myrinet (3.5 μs ping time - low latency network). Instead of using hardware to create a shared memory abstraction, let an application build its own memory model. 63
64 On Tuesday We return to CPU design... Have a good weekend! 64
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 27 Multiprocessors 2005-4-28 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last Time:
CS 152 Computer Architecture and Engineering Lecture 27 Multiprocessors 2005-4-28 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last Time:
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2005-4-12 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2005-4-12 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 19 Advanced Processors III 2006-11-2 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1 Last
CS 152 Computer Architecture and Engineering Lecture 19 Advanced Processors III 2006-11-2 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1 Last
CS 152 Computer Architecture and Engineering
 CS 52 Computer Architecture and Engineering Lecture 26 Mid-Term II Review 26--3 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs52/ CS 52 L26: Mid-Term
CS 52 Computer Architecture and Engineering Lecture 26 Mid-Term II Review 26--3 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs52/ CS 52 L26: Mid-Term
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 10 -- Cache I 2014-2-20 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152 L10: Cache I UC
CS 152 Computer Architecture and Engineering Lecture 10 -- Cache I 2014-2-20 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152 L10: Cache I UC
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 6 Superpipelining + Branch Prediction 2014-2-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play:
CS 152 Computer Architecture and Engineering Lecture 6 Superpipelining + Branch Prediction 2014-2-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play:
12 Cache-Organization 1
 12 Cache-Organization 1 Caches Memory, 64M, 500 cycles L1 cache 64K, 1 cycles 1-5% misses L2 cache 4M, 10 cycles 10-20% misses L3 cache 16M, 20 cycles Memory, 256MB, 500 cycles 2 Improving Miss Penalty
12 Cache-Organization 1 Caches Memory, 64M, 500 cycles L1 cache 64K, 1 cycles 1-5% misses L2 cache 4M, 10 cycles 10-20% misses L3 cache 16M, 20 cycles Memory, 256MB, 500 cycles 2 Improving Miss Penalty
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 12 -- Virtual Memory 2014-2-27 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152 L12: Virtual
CS 152 Computer Architecture and Engineering Lecture 12 -- Virtual Memory 2014-2-27 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152 L12: Virtual
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 4 Pipelining
 CS 152 Computer rchitecture and Engineering Lecture 4 Pipelining 2014-1-30 John Lazzaro (not a prof - John is always OK) T: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 otorola 68000 Next week
CS 152 Computer rchitecture and Engineering Lecture 4 Pipelining 2014-1-30 John Lazzaro (not a prof - John is always OK) T: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 otorola 68000 Next week
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2005-9-20 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/ Office Hours
CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2005-9-20 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/ Office Hours
CS Digital Systems Project Laboratory. Lecture 10: Advanced Processors II
 CS 194-6 Digital Systems Project Laboratory Lecture 10: Advanced Processors II 2008-11-24 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TA: Greg Gibeling www-inst.eecs.berkeley.edu/~cs194-6/
CS 194-6 Digital Systems Project Laboratory Lecture 10: Advanced Processors II 2008-11-24 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TA: Greg Gibeling www-inst.eecs.berkeley.edu/~cs194-6/
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
EECS Digital Design
 EECS 150 -- Digital Design Lecture 11-- Processor Pipelining 2010-2-23 John Wawrzynek Today s lecture by John Lazzaro www-inst.eecs.berkeley.edu/~cs150 1 Today: Pipelining How to apply the performance
EECS 150 -- Digital Design Lecture 11-- Processor Pipelining 2010-2-23 John Wawrzynek Today s lecture by John Lazzaro www-inst.eecs.berkeley.edu/~cs150 1 Today: Pipelining How to apply the performance
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
SGI Challenge Overview
 CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 2 (Case Studies) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 2 (Case Studies) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 15 Cache II 2005-3-8 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last Time: Locality
CS 152 Computer Architecture and Engineering Lecture 15 Cache II 2005-3-8 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last Time: Locality
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Lecture 29 Review" CPU time: the best metric" Be sure you understand CC, clock period" Common (and good) performance metrics"
 performance metrics") Be sure you understand CC, clock period Lecture 29 Review Suggested reading: Everything Q1: D[8] = D[8] + RF[1] + RF[4] I[15]: Add R2, R1, R4 RF[1] = 4 I[16]: MOV R3, 8 RF[4] = 5 I[17]: Add R2, R2, R3
Be sure you understand CC, clock period Lecture 29 Review Suggested reading: Everything Q1: D[8] = D[8] + RF[1] + RF[4] I[15]: Add R2, R1, R4 RF[1] = 4 I[16]: MOV R3, 8 RF[4] = 5 I[17]: Add R2, R2, R3
CENG 3420 Computer Organization and Design. Lecture 08: Cache Review. Bei Yu
 CENG 3420 Computer Organization and Design Lecture 08: Cache Review Bei Yu CEG3420 L08.1 Spring 2016 A Typical Memory Hierarchy q Take advantage of the principle of locality to present the user with as
CENG 3420 Computer Organization and Design Lecture 08: Cache Review Bei Yu CEG3420 L08.1 Spring 2016 A Typical Memory Hierarchy q Take advantage of the principle of locality to present the user with as
CPU Pipelining Issues
 CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2006-9-19 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ Last Time: ipod
CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2006-9-19 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ Last Time: ipod
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 10: Introduction to Coherence. The Lecture Contains:
 The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Fall 2003 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Lec20.1 Fall 2003 Head
14:332:331 Computer Architecture and Assembly Language Fall 2003 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Lec20.1 Fall 2003 Head
18-447: Computer Architecture Lecture 25: Main Memory. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013
 18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
CS252 Spring 2017 Graduate Computer Architecture. Lecture 12: Cache Coherence
 CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
EECS151/251A Spring 2018 Digital Design and Integrated Circuits. Instructors: John Wawrzynek and Nick Weaver. Lecture 19: Caches EE141
 EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
Modern CPU Architectures
 Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Memory. Lecture 22 CS301
 Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Parallel Programming Platforms
 arallel rogramming latforms Ananth Grama Computing Research Institute and Department of Computer Sciences, urdue University ayg@cspurdueedu http://wwwcspurdueedu/people/ayg Reference: Introduction to arallel
arallel rogramming latforms Ananth Grama Computing Research Institute and Department of Computer Sciences, urdue University ayg@cspurdueedu http://wwwcspurdueedu/people/ayg Reference: Introduction to arallel
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
CS 152 Computer Architecture and Engineering
 CS 152 Computer rchitecture and Engineering Lecture 10 Pipelining III 2005-2-17 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Ts: Ted Hong and David arquardt www-inst.eecs.berkeley.edu/~cs152/ Last time:
CS 152 Computer rchitecture and Engineering Lecture 10 Pipelining III 2005-2-17 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Ts: Ted Hong and David arquardt www-inst.eecs.berkeley.edu/~cs152/ Last time:
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 26 -- Midterm II Review Session 2014-4-29 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152
CS 152 Computer Architecture and Engineering Lecture 26 -- Midterm II Review Session 2014-4-29 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. Lecture 18 Cache Coherence
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 18 Cache Coherence Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 18 Cache Coherence Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18: Directory-Based Cache Protocols John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia 2 Recap:
CS 152 Computer Architecture and Engineering Lecture 18: Directory-Based Cache Protocols John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia 2 Recap:
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley
 Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
CS 152 Computer Architecture and Engineering. Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Mo Money, No Problems: Caches #2...
 Mo Money, No Problems: Caches #2... 1 Reminder: Cache Terms... Cache: A small and fast memory used to increase the performance of accessing a big and slow memory Uses temporal locality: The tendency to
Mo Money, No Problems: Caches #2... 1 Reminder: Cache Terms... Cache: A small and fast memory used to increase the performance of accessing a big and slow memory Uses temporal locality: The tendency to
Show Me the $... Performance And Caches
 Show Me the $... Performance And Caches 1 CPU-Cache Interaction (5-stage pipeline) PCen 0x4 Add bubble PC addr inst hit? Primary Instruction Cache IR D To Memory Control Decode, Register Fetch E A B MD1
Show Me the $... Performance And Caches 1 CPU-Cache Interaction (5-stage pipeline) PCen 0x4 Add bubble PC addr inst hit? Primary Instruction Cache IR D To Memory Control Decode, Register Fetch E A B MD1
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, Textbook web site:
 Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
Portland State University ECE 588/688. Cray-1 and Cray T3E
 Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Lecture 15: DRAM Main Memory Systems. Today: DRAM basics and innovations (Section 2.3)
") Lecture 15: DRAM Main Memory Systems Today: DRAM basics and innovations (Section 2.3) 1 Memory Architecture Processor Memory Controller Address/Cmd Bank Row Buffer DIMM Data DIMM: a PCB with DRAM chips
Lecture 15: DRAM Main Memory Systems Today: DRAM basics and innovations (Section 2.3) 1 Memory Architecture Processor Memory Controller Address/Cmd Bank Row Buffer DIMM Data DIMM: a PCB with DRAM chips
Interconnection Networks
 Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
CMSC411 Fall 2013 Midterm 1
 CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
Announcements. ! Previous lecture. Caches. Inf3 Computer Architecture
 Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Simple Instruction Pipelining
 Simple Instruction Pipelining Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Processor Performance Equation Time = Instructions * Cycles * Time Program Program Instruction
Simple Instruction Pipelining Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Processor Performance Equation Time = Instructions * Cycles * Time Program Program Instruction
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
EE414 Embedded Systems Ch 5. Memory Part 2/2
 EE414 Embedded Systems Ch 5. Memory Part 2/2 Byung Kook Kim School of Electrical Engineering Korea Advanced Institute of Science and Technology Overview 6.1 introduction 6.2 Memory Write Ability and Storage
EE414 Embedded Systems Ch 5. Memory Part 2/2 Byung Kook Kim School of Electrical Engineering Korea Advanced Institute of Science and Technology Overview 6.1 introduction 6.2 Memory Write Ability and Storage
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
CSE 431 Computer Architecture Fall Chapter 5A: Exploiting the Memory Hierarchy, Part 1
 CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
Memory. From Chapter 3 of High Performance Computing. c R. Leduc
 Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CPU Architecture Overview. Varun Sampath CIS 565 Spring 2012
 CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1)
") 1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
Course Administration
 Spring 207 EE 363: Computer Organization Chapter 5: Large and Fast: Exploiting Memory Hierarchy - Avinash Kodi Department of Electrical Engineering & Computer Science Ohio University, Athens, Ohio 4570
Spring 207 EE 363: Computer Organization Chapter 5: Large and Fast: Exploiting Memory Hierarchy - Avinash Kodi Department of Electrical Engineering & Computer Science Ohio University, Athens, Ohio 4570
Cache Coherence and Atomic Operations in Hardware
 Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
Introduction to cache memories
 Course on: Advanced Computer Architectures Introduction to cache memories Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Summary Summary Main goal Spatial and temporal
Course on: Advanced Computer Architectures Introduction to cache memories Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Summary Summary Main goal Spatial and temporal
Modern Computer Architecture
 Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
Snoop-Based Multiprocessor Design III: Case Studies
 Snoop-Based Multiprocessor Design III: Case Studies Todd C. Mowry CS 41 March, Case Studies of Bus-based Machines SGI Challenge, with Powerpath SUN Enterprise, with Gigaplane Take very different positions
Snoop-Based Multiprocessor Design III: Case Studies Todd C. Mowry CS 41 March, Case Studies of Bus-based Machines SGI Challenge, with Powerpath SUN Enterprise, with Gigaplane Take very different positions
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Computer Systems Architecture I. CSE 560M Lecture 18 Guest Lecturer: Shakir James
 Computer Systems Architecture I CSE 560M Lecture 18 Guest Lecturer: Shakir James Plan for Today Announcements No class meeting on Monday, meet in project groups Project demos < 2 weeks, Nov 23 rd Questions
Computer Systems Architecture I CSE 560M Lecture 18 Guest Lecturer: Shakir James Plan for Today Announcements No class meeting on Monday, meet in project groups Project demos < 2 weeks, Nov 23 rd Questions
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
3/13/2008 Csci 211 Lecture %/year. Manufacturer/Year. Processors/chip Threads/Processor. Threads/chip 3/13/2008 Csci 211 Lecture 8 4
 Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Handout 4 Memory Hierarchy
 Handout 4 Memory Hierarchy Outline Memory hierarchy Locality Cache design Virtual address spaces Page table layout TLB design options (MMU Sub-system) Conclusion 2012/11/7 2 Since 1980, CPU has outpaced
Handout 4 Memory Hierarchy Outline Memory hierarchy Locality Cache design Virtual address spaces Page table layout TLB design options (MMU Sub-system) Conclusion 2012/11/7 2 Since 1980, CPU has outpaced
COMP Parallel Computing. SMM (1) Memory Hierarchies and Shared Memory
 Memory Hierarchies and Shared Memory") COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC