ELE 655 Microprocessor System Design
|
|
|
- Mabel Lindsey
- 5 years ago
- Views:
Transcription
1 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1
2 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half of the clock cycle, reads on the first half 2 tj


3 Basic Pipeline Implementation Notes: Writes occur on the second half of the clock cycle, reads on the first half 3 tj
4 Basic Pipeline with Control 4 tj
5 Pipeline Hazards Hazards are conditions where the next instruction cannot perform its assigned pipeline action in the next clock cycle 3 types Structural Data Control 5 tj
6 Structural Hazards These hazards result from a resource conflict Classic case is Harvard vs. vonneuman memory architectures vonneuman architectures share a single memory for program and data A lw or sw command requires access to data memory to load or store the data value It would not be possible to fetch the appropriate instruction during this clock cycle since the memory would be in use The IF would be stalled and a bubble would be created in the pipeline 6 tj
7 Structural Hazards vonneuman memory architecture Time IF LW 2 3 Stall ID LW 2 3 bubble EX LW 2 3 bubble MEM LW 2 3 bubble WB data memory access prevents a concurrent LW instruction 2 fetch 3 bubble tj
8 Structural Hazards Too few registers Complex instructions multi resource requirements (dual write) Non-pipelined functions Mismatched pipelines 8 tj
9 Data Hazards These hazards result from a dependence of one instruction on another instruction still in the pipeline Consider the following code snippit add $s0, $t0, $t1 sub $t2, $s0, $t3 The value of $s0 is needed to perform the subtraction 9 tj
10 Data Hazards add $s0, $t0, $t1 sub $t2, $s0, $t3 Time IF add sub ID add stall stall EX add bubble bubble MEM add bubble bubble WB add bubble bubble clock cycle bubbles are created It would be 3 bubbles except we can take advantage of our convention writes occur in the first half of the clock cycle reads occur in the second half of the clock cycle the WB occurs during the same clock cycle as the register read 10 tj

11 Data Hazards add $s0, $t0, $t1 sub $t2, $s0, $t3 2 clock cycle bubbles are created It would be 3 bubbles except we can take advantage of our convention writes occur in the first half of the clock cycle reads occur in the second half of the clock cycle the WB occurs during the same clock cycle as the register read 11 tj
12 Data Hazards In many cases the compiler can avoid a data hazard add $s0, $t0, $t1 sub $t2, $s0, $t3 or $s2, $t0, $t1 and $s3, $t0, $t3 add $s4, $t1, $t3 add $s0, $t0, $t1 or $s2, $t0, $t1 and $s3, $t0, $t3 add $s4, $t1, $t3 sub $t2, $s0, $t3 re-order the instruction to remove the hazard condition 12 tj


13 Data Hazards Hardware can also be used to avoid data hazards called forwarding or bypassing provide the needed data as soon as it is valid requires extra circuitry 13 tj

14 Data Hazards 14 tj
15 Detecting the need for Forwarding Conditions: 1a) EX/MEM.RegisterRd = ID/EX.RegisterRs EX/MEM currently holds a value needed by an instruction about to enter EX 1b) ) EX/MEM.RegisterRd = ID/EX.RegisterRt EX/MEM currently holds a value needed by an instruction about to enter EX 2a) MEM/WB.RegisterRd = ID/EX.RegisterRs MEM/WB currently holds a value needed by an instruction about to enter EX 2b) MEM/WB.RegisterRd = ID/EX.RegisterRt MEM/WB currently holds a value needed by an instruction about to enter EX 15 tj

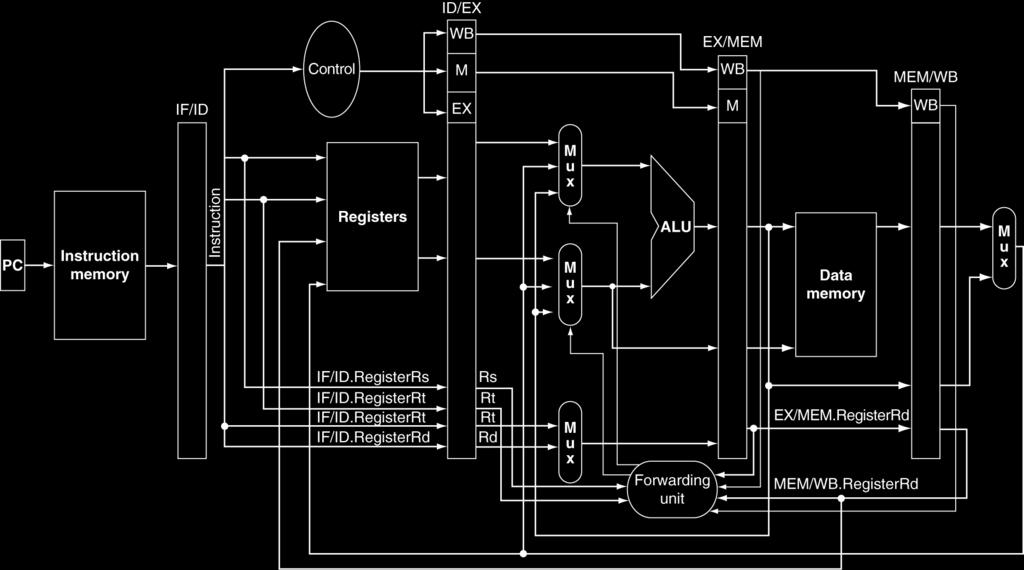
16 Pipeline with Forwarding 16 tj


 sub")
17 Data Hazards Hardware cannot avoid all data hazards cannot go backwards in time! lw $s0, 20($t1) sub $t2, $s0, $t3 17 tj
18 Data Hazards Forwarding plus compiler optimizations can avoid additional data hazards stall stall lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 13 cycles lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t2 sw $t3, 12($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 11 cycles 18 tj


19 Stalling the pipeline and inserting a bubble 19 tj
20 Branch Hazard Consider the following code snippit beq $1, $3, skip and $13, $6, $2 add $14, $2, $2 skip lw $4, 50($7) The branch decision is known after the calculation of the branch address and the comparison (subtract and check for zero), and is available in the MEM stage If the branch is ignored we will have the and, add and lw instructions in the pipeline all is well If the branch is taken we will have the and, add and lw instructions in the pipeline but we do not want them to execute 20 tj
21 Addition of Branch Logic 21 tj
22 Branch Hazard In our current implementation We assume branches are not taken We would need to flush the pipeline for taken branches Branch decision is available in the MEM stage Assuming the branch target is not already in the pipeline inserting 3 bubbles into the pipeline? How far can we move the decision forward to reduce the impact of taken branches 22 tj
23 Branch Hazard Most branches are simple comparisons equal all bits the same negative/positive look at msb We can move most of the branch prediction logic forward to the ID stage We have register values (some may be forwarded!) Need to modify the forwarding logic to account for branches We can move the branch address calculation forward to the ID stage Still have a single cycle stall IF of the next instruction is occurring in parallel with ID detection of the taken branch 23 tj


24 Early Branch Detection 24 tj
 beq $1, $4, skip the lw result will not be available until the MEM cycle is complete 2 stall cycles 25")
25 Branch Hazard This approach reduces the impact of branch hazards There may still be data hazards that cannot be avoided Branch dependent on previous lw instruction lw $1, 50($7) beq $1, $4, skip the lw result will not be available until the MEM cycle is complete 2 stall cycles 25 tj
26 Branch Prediction For deeper pipelines the cost of missing a branch decision can be significant many clock cycles lost Leads to branch prediction Static Compile Time Dynamic Execution time 26 tj
27 Static Branch Prediction Freeze the pipeline until decision known Do not allow additional instructions until branch decision known Insert No-op instruction(s) Assume NOT taken Allow sequential instruction into pipeline HW must prevent commits until decision known Must have HW to nop currently executing instructions This is our simple pipeline solution Compiler can help by ordering instructions to match the HW Assume Taken As soon as target address available start reading instructions Used when complicated conditional instructions are part of the IS 27 tj
28 Static Branch Prediction Delayed Branch Branch instruction Sequential successor Branch target if taken (always executed instruction) - delay slot 28 tj
29 Static Branch Prediction Delayed Branch Branch instruction Sequential successor Branch target if taken Must be OK whether branch taken or not 29 tj
30 Static Branch Prediction Better than nothing but not good enough for complex pipelines 30 tj
31 Dynamic Branch Prediction 1 bit Use a small branch prediction buffer n words deep 1 bit of prediction value (1 bit word) n is derived from the PC value last 8 bits of PC 256 words deep The PC value references one of n predictions values Assuming a branch instruction Take the branch if the prediction value is set to 1 Don t take the branch if the prediction value is set to 0 If the prediction was wrong invert the prediction value 31 tj
32 Dynamic Branch Prediction 1 bit PC Branch Table ADDR B 0x x x x x tj
33 Dynamic Branch Prediction 1 bit Issues Multiple PC values point to the same branch table location over write each other wrong guesses Each incorrect guess can lead to 2 wrong guesses eg. Assume mostly loop back bit set to 1 when you do not loop back you stall and set bit to 0 next cycle you want to loop back but bit is 0 stall and set bit to 1 2 stalls 33 tj
34 Control Hazards Dynamic Branch Prediction 2 bit Use 2 bits to make prediction decisions Only change the prediction on 2 successive mispredictions Resolves the 2 stall issue of 1 bit prediction PC Branch Table ADDR B1 B0 0x x x Option: Include bits in cache block instead of separate location issue? 0x x tj

35 Dynamic Branch Prediction 2 bit 35 tj
36 Dynamic Branch Prediction 2 bit 36 tj
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Pipelined datapath Staging data. CS2504, Spring'2007 Dimitris Nikolopoulos
 Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
ECE260: Fundamentals of Computer Engineering
 Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture.
 zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
LECTURE 9. Pipeline Hazards
 LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
ECE473 Computer Architecture and Organization. Pipeline: Data Hazards
 Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
14:332:331 Pipelined Datapath
 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
ECE473 Computer Architecture and Organization. Pipeline: Control Hazard
 Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
ECE260: Fundamentals of Computer Engineering
 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Orange Coast College. Business Division. Computer Science Department. CS 116- Computer Architecture. Pipelining
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 20 SE-273: Processor Design Courtesy: Prof. Vishwani Agrawal
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 20 SE-273: Processor Design Courtesy: Prof. Vishwani Agrawal
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Midnight Laundry. IC220 Set #19: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Return to Chapter 4
 Life. Return to Chapter 4") IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 251, Winter 2019, Assignment % of course mark
 CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
CS 251, Winter 2018, Assignment % of course mark
 CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Suggested Readings! Recap: Pipelining improves throughput! Processor comparison! Lecture 17" Short Pipelining Review! ! Readings!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
CS 2506 Computer Organization II Test 2. Do not start the test until instructed to do so! printed
 Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted fact sheet, with a restriction: 1) one 8.5x11 sheet, both sides, handwritten
Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted fact sheet, with a restriction: 1) one 8.5x11 sheet, both sides, handwritten
ECS 154B Computer Architecture II Spring 2009
 ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
Unresolved data hazards. CS2504, Spring'2007 Dimitris Nikolopoulos
 Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Pipelining is Hazardous!
 Pipelining is Hazardous! Hazards are situations where pipelining does not work as elegantly as we would like Three kinds Structural hazards -- we have run out of a hardware resource. Data hazards -- an
Pipelining is Hazardous! Hazards are situations where pipelining does not work as elegantly as we would like Three kinds Structural hazards -- we have run out of a hardware resource. Data hazards -- an
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions.
 Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
Control Hazards - branching causes problems since the pipeline can be filled with the wrong instructions Stage Instruction Fetch Instruction Decode Execution / Effective addr Memory access Write-back Abbreviation
CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions
 CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions Tutorial Questions 2. [AY2014/5 Semester 2 Exam] Refer to the following MIPS program: # register $s0 contains a 32-bit
CS2100 Computer Organisation Tutorial #10: Pipelining Answers to Selected Questions Tutorial Questions 2. [AY2014/5 Semester 2 Exam] Refer to the following MIPS program: # register $s0 contains a 32-bit
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
The Processor Pipeline. Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes.
 The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
CSE Lecture 13/14 In Class Handout For all of these problems: HAS NOT CANNOT Add Add Add must wait until $5 written by previous add;
 CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Chapter 6 Exercises with solutions
 Islamic University Gaza Engineering Faculty Department of Computer Engineering ECOM 3010: Computer Architecture Discussion Chapter 6 Exercises with solutions Eng. Eman R. Habib December, 2013 2 Computer
Islamic University Gaza Engineering Faculty Department of Computer Engineering ECOM 3010: Computer Architecture Discussion Chapter 6 Exercises with solutions Eng. Eman R. Habib December, 2013 2 Computer
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Basic Pipelining Concepts
 Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic Instruction Timings. Pipelining 1. How long would it take to execute the following sequence of instructions?
 Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
(Basic) Processor Pipeline
 Processor Pipeline") (Basic) Processor Pipeline Nima Honarmand Generic Instruction Life Cycle Logical steps in processing an instruction: Instruction Fetch (IF_STEP) Instruction Decode (ID_STEP) Operand Fetch (OF_STEP) Might
(Basic) Processor Pipeline Nima Honarmand Generic Instruction Life Cycle Logical steps in processing an instruction: Instruction Fetch (IF_STEP) Instruction Decode (ID_STEP) Operand Fetch (OF_STEP) Might
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
Computer Organization and Structure
 Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline and Cache
 Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
The Processor: Improving the performance - Control Hazards
 The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary
The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary
Chapter 3. Pipelining. EE511 In-Cheol Park, KAIST
 Chapter 3. Pipelining EE511 In-Cheol Park, KAIST Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup
Chapter 3. Pipelining EE511 In-Cheol Park, KAIST Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup
EE 4980 Modern Electronic Systems. Processor Advanced
 EE 4980 Modern Electronic Systems Processor Advanced Architecture General Purpose Processor User Programmable Intended to run end user selected programs Application Independent PowerPoint, Chrome, Twitter,
EE 4980 Modern Electronic Systems Processor Advanced Architecture General Purpose Processor User Programmable Intended to run end user selected programs Application Independent PowerPoint, Chrome, Twitter,
Pipeline Data Hazards. Dealing With Data Hazards
 Pipeline Data Hazards Warning, warning, warning! Dealing With Data Hazards In Software inserting independent instructions In Hardware inserting bubbles (stalling the pipeline) data forwarding Data Data
Pipeline Data Hazards Warning, warning, warning! Dealing With Data Hazards In Software inserting independent instructions In Hardware inserting bubbles (stalling the pipeline) data forwarding Data Data
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue