14:332:331 Pipelined Datapath
|
|
|
- Sarah Hamilton
- 6 years ago
- Views:
Transcription
1 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate the slowest instruction Clk Single Cycle Implementation: Cycle 1 Cycle 2 lw sw Waste Is wasteful of area since some functional units must be duplicated since they can not be shared during a clock cycle (e.g., adders, memory units) But, it is simple and easy to understand 1
2 Multi-cycle Advantages & Disadvantages Uses the clock cycle efficiently the clock cycle is timed to accommodate the slowest instruction step balance the amount of work to be done in each step restrict each step to use only one major functional unit Multi-cycle implementations allow functional units to be used more than once per instruction, as long as they are used on different clock cycles Allow faster clock rates than single cycle architecture Different instructions to take a different number of clock cycles But requires additional internal state registers, multiplexers, and more complicated (Finite State Machine) control The Five Stages of Load Instruction We will consider only a subset of instructions (lw, sw, add, sub, and, or, slt, beq) IFetch: Instruction Fetch and Update PC Dec: Registers Read and Instruction Decode Exec: calculate memory address Mem: Read the data from the Data Memory WB: Write the data back to the register file lw Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 IFetch Dec RR Exec Mem WB 2 ns 2
3 What if. Several instructions were worked on by the CPU at the same time Each major logic unit works on a different stage of a different instruction - Like doing laundry for different roommates Pipelined MIPS Processor Start the next instruction while still working on the current one Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 lw IFetch Dec RR Exec Mem WB sw IFetch Dec RR Exec Mem WB R-type IFetch Dec RR Exec Mem WB Improves throughput - total amount of work done in a given time If pipeline is full (ideal situation) Time between Inst Pipelined = Time between inst. Non-pipelined Number of pipeline stages Instruction latency is not reduced - time from the start of an instruction to its completion 3

4 Single Cycle, Multi Cycle, vs. Pipelined Single Cycle Implementation: Cycle 1 Cycle 2 Clk Load Store Waste Multiple Cycle Implementation: Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9Cycle 10 Clk lw IFetch Dec Exec Mem WB sw IFetch Dec Exec Mem R-type IFetch Pipeline Implementation: lw IFetch Dec Exec Mem WB wasted cycle sw IFetch Dec Exec Mem WB R-type IFetch Dec Exec Mem WB Single Cycle Implementation: Single Cycle, vs. Pipelined Assume memory and ops take 200 ps, Reg ops take 100 ps Pipelined Implementation: Time savings Instruction 2 Time savings Instruction 3 4
5 Designing MIPS Instructions for Pipelining What makes it easy - all instructions are the same length (32 bits) - The first two pipeline stages are the same for all instructions. few instruction formats (three) with symmetry across formats - registers addresses are in the same location and thus can be read while instructions are being decoded memory operations can occur only in loads and stores, thus the can compute memory addresses in EX stage operands are aligned in memory so a single data transfer requires only one memory access MIPS Pipeline Datapath Modifications What do we need to add/modify in our single-cycle per instruction datapath to make it pipelined? The MIPS instruction has (up to) five stages, thus pipeliene has 5 stages: Ifetch to fetch the instruction from Instruction memory Dec to decode the instruction and read Register File registers Exec to do the operations Mem to read from/write into Data Memory WB to write back into the register file. So we need a way to separate the data path into five pieces, without losing intermediate results. We will introduce Pipeline registers between pipeline stages to isolate them 5
6 MIPS Pipeline Datapath Modifications All instructions advance during one clock cycle between one pipeline register and the next IFetch Dec Exec Mem WB 1 0 PC 4 Instruction Memory Read Address Add IFetch/Dec Read Addr 1 Register Read Read Addr 2Data 1 File Write Addr Read Data 2 Write Data Dec/Exec Shift left Add Exec/Mem Data Address Memory Write Data Read Data Mem/WB 1 0 System Clock 16 Sign Extend 32 MIPS Pipeline Datapath Modifications Because all data is passed through the pipeline, the address of the register where data needs to be loaded (lw) also needs to be passed IFetch 1 0 Dec Exec Mem WB PC 4 Instruction Memory Read Address Add IFetch/Dec Read Addr 1 Register Read Read Addr 2Data 1 File Write Addr Read Data 2 Write Data Dec/Exec Shift left Add Exec/Mem Data Address Memory Write Data Read Data Mem/WB 1 0 System Clock 16 Sign Extend 32 6

7 MIPS Pipeline Control Path Modifications All control signals are determined during Decode and held in the pipeline registers between pipeline stages IFetch 1 0 Dec Exec Mem WB Control PC 4 Add Instruction Memory Read Address IFetch/Dec Read Addr 1 Register Read Read Addr 2Data 1 File Write Addr Read Data 2 Write Data Dec/Exec Shift left Add Exec/Mem Data Address Memory Write Data Read Data Mem/WB 1 0 System Clock 16 Sign Extend 32 MIPS Pipeline Control Path Modifications The modified control path is
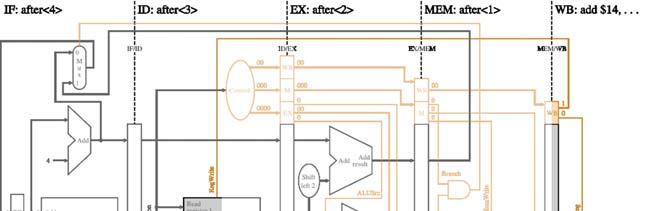
 before <4> before <3> before <2> before <1> lw $10, 20($1) sub $11, $2, $3 and $12, $4, $5 or $13, $6, $7 add $14, $8, $9")
8 Pipeline Example How does the non-dependent instruction sequence execute in a pipeline? (no support for forwarding) before <4> before <3> before <2> before <1> lw $10, 20($1) sub $11, $2, $3 and $12, $4, $5 or $13, $6, $7 add $14, $8, $9 after <1> after <2> Pipeline Example - before <4> completes 8



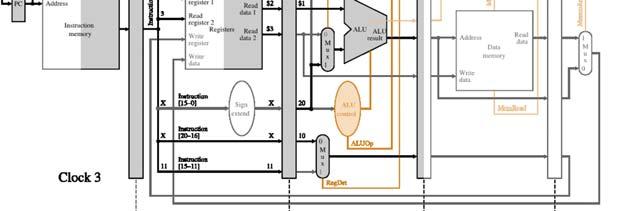
9 Pipeline Example - before <3> completes Pipeline Example - before <2> completes




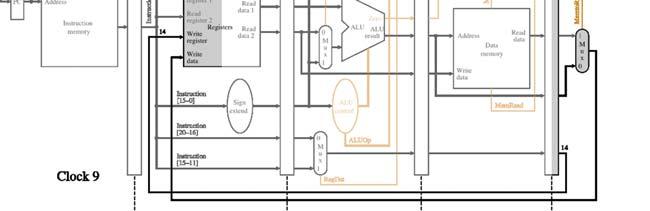
10 Pipeline Example - before <1> completes $4, $ Pipeline Example - lw completes Data memory not used (MEM control lines 0) $5 12 destination register 10



 $9 14 11")
11 Pipeline Example - sub completes $6, $7 Data memory not used (MEM control lines 0) $7 13 Pipeline Example - and completes Normal PC+4 increment (PCSrc=0) $


12 Pipeline Example - or completes Pipeline Example - add completes 12
13 Graphically Representing MIPS Pipeline So-far we saw the single-clock-cycle pipeline diagrams show the state of the entire datapath during a clock cycle (instructions are identified above the pipeline stages). Multi-clock-cycle pipeline diagram are simpler, and can help answer how many cycles does it take to execute this code Or what is the doing during a certain cycle Can represent multiple instructions in a single figure If there is a hazard, it shows why it occurs, and how it can be fixed Why Pipeline? For Throughput! Time (clock cycles) I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Once the pipeline is full, one instruction is completed every cycle Inst 4 Time to fill the pipeline 13

14 Example of graphical representation Can be converted in a single-clock-cycle pipeline diagram M Example of single-clock-cycle pipeline representation 14
15 Pipelining the MIPS ISA What makes it hard - structural hazards: what if we had only one memory - then the pipeline cannot have one instruction read from memory (fetch stage), while at the same time another instruction writes into memory (sw) control hazards: need to make a decision based on the results of one instruction, while that instruction is still executing. what about branches? Stalling Impact of branch stalling We assume that all instructions in the pipeline have a CPI of 1. Branches which always are followed by a stall have a CPI of 2. In a typical program branches occur 13% of the time. Thus we can compute the aggregate CPI of the alwaysstall for branch architecture as: n Then CPI = Σ CPI i x F i i=1 CPI always stall = 1 x 87% + 2 x 13% = 1.13 cycles/instruction Thus CPU Perform. always stall = Inst. Count x CPI no stall x Clock Perform. no stall Inst. CountxCPI always stall xclock Perform. always stall = 1 = ( 88.5%) Perform. no stall
.")
16 Pipelining the MIPS ISA control hazards: Another approach is prediction - either static - always execute the instruction following a branch (assume always that the branch is not taken), or predict dynamically (keep a history of each branch as taken or not taken - accurate 90% of time). Branch not taken Branch taken Pipelining the MIPS ISA We can represent the pipeline in a simplified way, shading the blocks that are used in a given clock cycle. data hazards: what if an instruction s input operands depend on the output of a previous instruction that did not finish? Example an add followed by a sub. ns Forwarding 16
17 Pipelining the MIPS ISA Forwarding will fail for a lw followed immediately by an instruction that uses the results of the lw operation. Example lw followed by a sub. Pipelining the MIPS ISA Solution - stall pipeline one clock cycle, then forward Forward from the MEM/WB pipeline register Another solution - optimize compiler, such that lw is followed by an instruction which does not depend on the loaded word. 17
18 How About Register File Access? Time (clock cycles) I n s t r. add Inst 1 Can fix register file access hazard by doing reads in the second half of the cycle and writes in the first half. O r d e r Inst 2 add Inst 4 Branch Instructions Cause Control Hazards Dependencies backward in time cause hazards time I n s t r. O r d e r add beq lw Inst 3 Inst 4 18
19 One Way to Fix a Control Hazard I n s t r. add beq Can fix branch hazard by waiting stall but affects throughput O r d e r stall stall lw Inst 3 Register Usage Can Cause Data Hazards Dependencies backward in time cause hazards I n s t r. O r d e r add r1,r2,r3 sub r4,r1,r5 and r6,r1,r7 or r8, r1, r9 xor r4,r1,r5 Data hazard No data hazard 19
20 One Way to Fix a Data Hazard I n s t r. add r1,r2,r3 stall Can fix data hazard by waiting stall but affects throughput O r d e r stall sub r4,r1,r5 and r6,r1,r7 Loads Can Cause Data Hazards Dependencies backward in time cause hazards I n s t r. O r d e r lw r1,100(r2) sub r4,r1,r5 and r6,r1,r7 or r8, r1, r9 xor r4,r1,r5 20
21 Stores Can Cause Data Hazards Dependencies backward in time cause hazards I n s t r. O r d e r add r1,r2,r3 sw r1,100(r5) and r6,r1,r7 or r8, r1, r9 xor r4,r1,r5 Pipeline Changes to accommodate Forwarding To avoid slowing down throughput, we need to add a hardware that detects data hazards. We call this the forwarding unit. Data needs to be forwarded to the when a data hazard is detected. Thus the forwarding unit controls forwarding data through additional multiplexing at the input. This logic unit needs input from the three pipeline registers. It also needs to detect if the RegWrite control signal is asserted so it needs input from the control lines also. No forwarding if EX/MEM.RegisterRd=$0 and MEM/WB.RegisterRd=$0 21
22 Pipeline Changes to accommodate Forwarding It needs to detect one of four cases of data hazards: if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0 and (EX/MEM.RegisterRd=ID/EX.RegisterRs) Forward similarly if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0 and (EX/MEM.RegisterRd=ID/EX.RegisterRt) Forward Pipeline Changes to accommodate Forwarding similarly if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0 and (MEM/WB.RegisterRd=ID/EX.RegisterRs) Forward similarly if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0 and (MEM/WB.RegisterRd=ID/EX.RegisterRt) Forward 22
23 Pipeline Changes to accommodate Forwarding Pipeline Changes to accommodate Forwarding 0 1 Src ForwardA 00 ID/EX input to 1 - no fwd 01 MEM/WB input to 1 10 EX/MEM input to 1 ForwardB 00 ID/EX input to 2 01 MEM/WB input to 2 10 EX/MEM input to 2 ForwardB 11 sign extension input to 2 OR add another multiplexer 23

24 Forwarding Pipeline Example How does the dependent instruction sequence execute in a pipeline with support for forwarding? before <4> before <3> before <2> before <1> sub $2, $1, $3 and $4, $2, $5 or $4, $4, $2 add $9, $4, $2 after <1> after <2> Forw. Pipeline Example - before <2> completes 24



25 Forw. Pipeline Example - before <1> completes Use this value of $2 not the one fetched from register file EX/MEM.RegWrite is asserted EX/MEM.RegisterRd=ID/EX.RegisterRs Forw. Pipeline Example - sub completes Both $4 and $2 are forwarded EX/MEM.RegWrite is asserted MEM/WB.RegWrite is asserted EX/MEM.RegisterRd=ID/EX.RegisterRs MEM/WB.RegisterRd=ID/EX.RegisterRt 25

 and $4, $2, $5 or $8, $2, $6 The pipeline needs to be")
26 Forwarding Pipeline Example - and completes Use this value of $4 not the one fetched from register file EX/MEM.RegWrite is asserted EX/MEM.RegisterRd=ID/EX.RegisterRs Pipeline Changes to accommodate Stalls Forwarding does not work when an instruction following a lw tries to read the value from the destination register of lw lw $2, 20($1) and $4, $2, $5 or $8, $2, $6 The pipeline needs to be stalled, and data forwarded from the MEM/WB pipeline register Forwarding does not work 26

27 How Stalls are inserted Stalls happen in the EX stage, such that the subsequent two instructions in the pipeline both repeat what they were doing for one cycle This allows forwarding to work Stall in CC4 and and or repeat what they did in CC3 Pipeline Changes to accommodate Stalls We need a logic unit which detects hazards and then stalls. The hazard detection unit operates in the instruction decode stage, and tests to see if the instruction is a load (if ID/EX.MemRead control line is asserted) Then it checks if either of the source registers of the instruction currently being decoded is the same as the target/destination register of the lw being executed (that is if ID/EX.RegisterRt=IF/ID.RegisterRs or ID/ EX.RegisterRt= IF/ID.RegisterRt) During stalling the PC is prevented from incrementing and the instruction in the IF/ID pipeline register is preserved. Need additional control lines for the IF/ID register and for the PC. The bubble is inserted by setting the pipelined control signals in the ID/EX pipeline register to 0. So we need a way to change the values of the control lines. 27




28 Pipeline Changes to do Hazard Detection ID/EX.RegisterRt Instruction source registers Pipeline Changes to do Hazard Detection Stall by 0-ing all 9 control lines PCwrite IF/ID write 28




29 Pipeline stalling example before<3> completes Pipeline stalling example before<2> completes Hazard is detected 29




30 Pipeline stalling example before<1> completes PCWrite is asserted Bubble inserted 0 0 IF/IDWrite is asserted Registers continue to be read Pipeline stalling example lw completes Forwarding unit sets src multiplexer to use value from WB register 30


31 Pipeline stalling example bubble completes Forwarding unit sets src multiplexer to use value from EX/MEM register Example Consider executing the following code add $5, $6, $7 lw $6, 100($7) sub $7, $6, $8 How many cycles will it take to execute the code? Draw a diagram that illustrates the dependencies that need to be resolved CC 7 CC 8 add $5,$6,$7 lw $6,100($7) sub $7, $6, $8 31
32 Example - continued Draw a diagram that illustrates how the code will actually be executed (incorporating any stalls or forwarding to solve the identified problems) CC 7 CC 8 add.. lw $6,100($7) Stall one cycle forwarding sub $7, $6, $8 MIPS Pipeline Control Path Modifications Branch decision in MEM stage 32
33 Pipeline Changes to accommodate Control Hazards Control hazards are due to branch hazards and to exceptions (I/O interrupts, requests from the OS, overflow, or an unknown instruction). A branch hazard occurs less frequently than data hazards, and is detected in the MEM stage of the pipeline. Assume branch not taken, the three instructions following a branch that is taken will be in the pipeline, and need to be flushed. branch detected CC4 40 beq $1,$3,7 44 and $12,$2,$5 48 or $13,$6,$2 52 add $14,$2,$ lw $4,50($7) Pipeline Changes to accommodate Branch Hazards The pipeline throughput can be improved by moving the decision whether the branch is taken or not to the Decode stage of the pipeline; Then if the branch is taken, only one instruction needs to be flushed (discarded) - the instruction immediately after the branch instruction. Thus we need a new logic circuit which compares the contents of the register file outputs; Since the decision is taken in the decode stage, the branch address needs to be computed in the decode phase too, in case the branch is to be taken Thus we need a new adder in the decode phase, as well as add an IF Flush control line to flush the IF/ID pipeline register. 33





34 Pipeline Changes to accommodate Branch Hazards Branch Switch to branch address Compute branch address Check for equality Pipelined branch example <before 2> completes PC-relative branch *4=72 Branch IF Flush 2 Flushing means instruction field is 0s 34
 at the time when the comparator needs it Pipeline needs to be stalled and")
35 Pipelined branch example <before 1> completes 3 Pipeline Changes to accommodate Branch Hazards The above scheme will fail if we have the following series of instructions: 36 add $1, $6, $7 40 beq $1, $3, and $12, $2, $5 72 lw Because the correct value of register $1 is not in the decode stage (in the register file) at the time when the comparator needs it Pipeline needs to be stalled and the value of $1 needs to be forwarded from EX/Mem pipeline register 35
36 Pipeline Changes to accommodate Branch Hazards 36 add $1, $6, $7 40 beq $1, $3, and $12, $2, $5 72 lw Pipeline Changes to accommodate Branch Hazards 36 add $1, $6, $7 Stall 40 beq $1, $3, 28 flush 72 lw 36
 addi $3, $3, 4 beq $3, $4, Loop We cannot put addi after the beq since it modifies register $3 We cannot just put lw after the beq since register $3 had changed First we")
37 Pipeline Changes to accommodate Branch Hazards Example How can the following code be modified to make use of a delayed branch slot?: Loop: lw $2, 100($3) addi $3, $3, 4 beq $3, $4, Loop We cannot put addi after the beq since it modifies register $3 We cannot just put lw after the beq since register $3 had changed First we re-write the code as Loop: addi $3, $3, 4 lw $2, 96($3) beq $3, $4, Loop Then we can move the lw after the beq Loop: addi $3, $3, 4 beq $3, $4, Loop lw $2, 96($3) 37
38 Example 2 Consider the pipelined datapath that does not accommodate branch hazards. Can an attempt to flush and an attempt to stall occur simultaneously? You may want to consider the following code sequence to help you answer this question: beq $1, $2, TARGET #assume the branch is taken lw $3, 40($4) add $3, $3, $3 sw $3, 40($4) TARGET: or $10,$11, $12 If the beq resolution is in the MEM stage, and the branch is taken, it requires a flush of the IF/ID pipeline register (means the register needs to be written to) and a change of the PC to the branch address; this happens in clock cycle 4. Example 2 - continued At the same time a hazard is detected between lw and the next instruction (add) which is dependent (due to $3 used as source register). Thus the hazard detection unit issues a stall, and requests that the PC and the IF/ID registers not be written to. The answer is YES, a flush and a stall are issued simultaneously. If there are any conflicting actions, which should take priority? Flush should take priority Is there a simple change you can make to the datapath to ensure the necessary priority? 38


39 Example 2- continued The hazard detection unit should be changed to see the RegWrite signal in the execution stage after it goes through the MUX used to flush the pipeline RegWrite Dynamic branch prediction The static branch predicts that it will not be taken and then flush if it was taken works for simple pipelines, but is wasteful for performance for aggressive pipelining architecture (such as the multiple issue of Pentium IV). One approach is to have a branch prediction buffer (a small memory unit indexed by the lower portion of the address in the branch instruction). It contains a bit that says if the branch was recently taken or not. The value of the prediction bit is inverted if the prediction turned out to be wrong. When the branch is almost always taken, this 1-bit predictor will predict wrong twice (at the start and end of the run of branches). 39



40 Dynamic branch prediction A better approach is to use a two-bit scheme, which must be wrong twice to change the direction of prediction. The branch prediction is stored in a special buffer which is accessed with the beq instruction in the IF stage. If the beq is predicted as taken, then fetching begins from the target once beq is in ID. Not Taken Taken Taken Not Taken Not Taken Taken Further optimization with a global predictor taking into consideration the global behavior of recently executed branches. Each branch has two predictors, and tournament predictor keeps track and favors the one that was more accurate. Dynamic branch prediction with compiler optimization Furthermore, compilers place instructions that always execute in the delay spot For mostly taken branches Best choice 40

41 Pipeline Changes to accommodate Exceptions Overflow is discovered at the end of the execute stage when the sends a signal to the control unit. Following notification of an overflow the control unit has to flush the two instructions that followed the one causing the overflow. These instructions are now in the IF and ID stages of the pipeline. Thus we add an input to the MUX in the ID stage that 0s the control signals using an ID.Flush signal ID.Flush IF.Flush Overflow Pipeline Changes to accommodate Exceptions The instruction that cause the overflow (which is detected in the EX stage) needs to be flushed from the pipeline. This means that an EX.Flush signal needs to be sent to two multiplexers to zero the control signals for the last two stages of the pipeline. Overflow is only one of the many possible exception causes. The cause is stored in a Cause register below: 4 address error exception (load) 5- address error exception (store) 10 unknown instructions or reserved instruction 12 arithmetic overflow 15 floating point exception 41
42 Pipeline Changes to accommodate Exceptions An additional input is added to the PC MUX that sends to the PC hex (system reserved memory address for overflow) The address of the instruction following the offending command is saved in the Exception Program Counter (EPC) register and the cause in the Cause Register. If there are multiple exceptions, their causes are stored in the cause register, such that hardware can interrupt based on later exceptions once the earliest exception has been serviced. In case of an I/o interrupt, the execution jumps to the system routine needed to deal with the I/o, followed by a return to the address stored in the EPC for program completion. The OS responds to an exception either by terminating the process that caused the exception or by performing some action. The process who s exception is due to an unimplemented instruction is killed by the OS. Pipeline Changes to accommodate Overflow Branch EX.Flush Overflow 42
 80000180 0 0 Pipelined exception example: and completes 80000180 54 Overflow")
43 Pipeline Changes to accommodate Unknown Instruction Branch EX.Flush (LOW) Pipelined exception example: and completes Overflow 50 add causes an overflow 43
 results in shorter clock cycles.")
 - Instruction execution rate exceeds")
 Architectures try to issue 3 to 8")
.")
44 Pipelined exception example or completes OS instruction fetched Pipelining Speed-ups One way to speed up pipelines is to have more stages (up to eight) results in shorter clock cycles. Another way is superscalar architectures which have CPI less than 1. Multiple instructions can be launched at the same time (multiple issue) - Instruction execution rate exceeds the clock rate! We re talking of number of Instructions per Clock Cycle (IPC instead of CPI) Architectures try to issue 3 to 8 instructions at every clock cycle. A third way is to balance load through dynamic pipeline scheduling, to avoid hazards (stalls). The price for these speed-ups is more hardware, more complicated control and a more complicated instruction execution model. If instructions are launched in pairs, only the first instruction is launched if dynamic conditions are not met. 44
45 Static Multiple Issue Used in embedded processors and VLIW processors Can improve performance by up to 200% Layout is restricted to simplify the decoding and instruction issue Instructions are issued in pairs, aligned on a 64-bit boundary with the and branch portion operating first; If one of the instruction of the pair cannot be used, it is replaced by a no-op. The hardware detects data hazards and generates stalls between two issue packets, but the compiler is required to avoid all dependencies within the instruction pair. A load will cause the next two instructions to stall if they were to use the loaded word. CC 7 CC 8 add lw beq sw sub lw 45
46 Static two-issue datapath We need two output ports for Instruction memory, two more read and one more write ports for the Register file, two s (one handles address computation for Data memory access), and two sign-extending units Three Primary Units of Dynamically Scheduled Pipeline Dynamic pipeline scheduling chooses which instruction to execute next, re-ordering them to avoid stalls Buffer holding all the operands and the operation Results sent to other reservation stations or the commit unit Buffers results until it is safe to put them in the register file or in data memory (store) Commit unit serves as a forwarding station For operands that are needed before they were written back in the register file 46

47 AMD Opteron X4 12-stage pipeline Speculative pipeline that executes 3 instructions/clock cycle Register renaming removes antidependencies. In case of incorrect speculation, the mapping between architectural and physical registers is undone. Memory address calculation Actual memory access Intel Core pipeline Each core can execute 4 instructions simultaneously A Core duo can execute 8 instructions simultaneously Better branch prediction Enhanced Less power consumption 47
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
ECE260: Fundamentals of Computer Engineering
 Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture.
 zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Pipelining. Ideal speedup is number of stages in the pipeline. Do we achieve this? 2. Improve performance by increasing instruction throughput ...
 CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Pipelined datapath Staging data. CS2504, Spring'2007 Dimitris Nikolopoulos
 Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
CO Computer Architecture and Programming Languages CAPL. Lecture 18 & 19
 CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
CPE 335 Computer Organization. Basic MIPS Pipelining Part I
 CPE 335 Computer Organization Basic MIPS Pipelining Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Pipelining
CPE 335 Computer Organization Basic MIPS Pipelining Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Pipelining
ECS 154B Computer Architecture II Spring 2009
 ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Design a MIPS Processor (2/2)
") 93-2Digital System Design Design a MIPS Processor (2/2) Lecturer: Chihhao Chao Advisor: Prof. An-Yeu Wu 2005/5/13 Friday ACCESS IC LABORTORY Outline v 6.1 An Overview of Pipelining v 6.2 A Pipelined Datapath
93-2Digital System Design Design a MIPS Processor (2/2) Lecturer: Chihhao Chao Advisor: Prof. An-Yeu Wu 2005/5/13 Friday ACCESS IC LABORTORY Outline v 6.1 An Overview of Pipelining v 6.2 A Pipelined Datapath
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12
 Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12 (2) Lecture notes from MKP, H. H. Lee and S.
 Lecture notes from MKP, H. H. Lee and S.") Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
LECTURE 9. Pipeline Hazards
 LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CPE 335 Computer Organization. Basic MIPS Architecture Part I
 CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Improve performance by increasing instruction throughput
 Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
Chapter 4 (Part II) Sequential Laundry
 Sequential Laundry") Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Midnight Laundry. IC220 Set #19: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Return to Chapter 4
 Life. Return to Chapter 4") IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
COSC121: Computer Systems. ISA and Performance
 COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
Unresolved data hazards. CS2504, Spring'2007 Dimitris Nikolopoulos
 Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Unresolved data hazards 81 Unresolved data hazards Arithmetic instructions following a load, and reading the register updated by the load: if (ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
Introduction to Pipelined Datapath
 14:332:331 Computer Architecture and Assembly Language Week 12 Introduction to Pipelined Datapath [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 W12.1 Review:
14:332:331 Computer Architecture and Assembly Language Week 12 Introduction to Pipelined Datapath [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 W12.1 Review:
What do we have so far? Multi-Cycle Datapath (Textbook Version)
") What do we have so far? ulti-cycle Datapath (Textbook Version) CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instruction being processed in datapath How to lower CPI further? #1 Lec # 8 Summer2001
What do we have so far? ulti-cycle Datapath (Textbook Version) CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instruction being processed in datapath How to lower CPI further? #1 Lec # 8 Summer2001
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
COMP2611: Computer Organization. The Pipelined Processor
 COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
ECEC 355: Pipelining
 ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
ECE473 Computer Architecture and Organization. Pipeline: Data Hazards
 Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
EE557--FALL 1999 MAKE-UP MIDTERM 1. Closed books, closed notes
 NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
Suggested Readings! Recap: Pipelining improves throughput! Processor comparison! Lecture 17" Short Pipelining Review! ! Readings!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
1! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 17" Short Pipelining Review! 3! Processor components! Multicore processors and programming! Recap: Pipelining
Basic Instruction Timings. Pipelining 1. How long would it take to execute the following sequence of instructions?
 Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Question 1: (20 points) For this question, refer to the following pipeline architecture.
 For this question, refer to the following pipeline architecture.") This is the Mid Term exam given in Fall 2018. Note that Question 2(a) was a homework problem this term (was not a homework problem in Fall 2018). Also, Questions 6, 7 and half of 5 are from Chapter 5,
This is the Mid Term exam given in Fall 2018. Note that Question 2(a) was a homework problem this term (was not a homework problem in Fall 2018). Also, Questions 6, 7 and half of 5 are from Chapter 5,
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Chapter 6 ADMIN. Reading for Chapter 6: 6.1,
 Life. Chapter 6 ADMIN. Reading for Chapter 6: 6.1,") SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Chapter 6 ADMIN ing for Chapter 6: 6., 6.9-6.2 2 Midnight Laundry Task order A 6 PM 7 8 9 0 2 2 AM B C D 3 Smarty
SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Chapter 6 ADMIN ing for Chapter 6: 6., 6.9-6.2 2 Midnight Laundry Task order A 6 PM 7 8 9 0 2 2 AM B C D 3 Smarty
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Homework 5. Start date: March 24 Due date: 11:59PM on April 10, Monday night. CSCI 402: Computer Architectures
 Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Chapter Six. Dataı access. Reg. Instructionı. fetch. Dataı. Reg. access. Dataı. Reg. access. Dataı. Instructionı fetch. 2 ns 2 ns 2 ns 2 ns 2 ns
 Chapter Si Pipelining Improve perfomance by increasing instruction throughput eecutionı Time lw $, ($) 2 6 8 2 6 8 access lw $2, 2($) 8 ns access lw $3, 3($) eecutionı Time lw $, ($) lw $2, 2($) 2 ns 8
Chapter Si Pipelining Improve perfomance by increasing instruction throughput eecutionı Time lw $, ($) 2 6 8 2 6 8 access lw $2, 2($) 8 ns access lw $3, 3($) eecutionı Time lw $, ($) lw $2, 2($) 2 ns 8
Pipeline Data Hazards. Dealing With Data Hazards
 Pipeline Data Hazards Warning, warning, warning! Dealing With Data Hazards In Software inserting independent instructions In Hardware inserting bubbles (stalling the pipeline) data forwarding Data Data
Pipeline Data Hazards Warning, warning, warning! Dealing With Data Hazards In Software inserting independent instructions In Hardware inserting bubbles (stalling the pipeline) data forwarding Data Data
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 20 SE-273: Processor Design Courtesy: Prof. Vishwani Agrawal
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 20 SE-273: Processor Design Courtesy: Prof. Vishwani Agrawal
CS 251, Winter 2019, Assignment % of course mark
 CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
CENG 3531 Computer Architecture Spring a. T / F A processor can have different CPIs for different programs.
 Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
CS 251, Winter 2018, Assignment % of course mark
 CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
CPE 335. Basic MIPS Architecture Part II
 CPE 335 Computer Organization Basic MIPS Architecture Part II Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part II Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Architecture
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
Lecture 4: Review of MIPS. Instruction formats, impl. of control and datapath, pipelined impl.
 Lecture 4: Review of MIPS Instruction formats, impl. of control and datapath, pipelined impl. 1 MIPS Instruction Types Data transfer: Load and store Integer arithmetic/logic Floating point arithmetic Control
Lecture 4: Review of MIPS Instruction formats, impl. of control and datapath, pipelined impl. 1 MIPS Instruction Types Data transfer: Load and store Integer arithmetic/logic Floating point arithmetic Control
CSE 533: Advanced Computer Architectures. Pipelining. Instructor: Gürhan Küçük. Yeditepe University
 CSE 533: Advanced Computer Architectures Pipelining Instructor: Gürhan Küçük Yeditepe University Lecture notes based on notes by Mark D. Hill and John P. Shen Updated by Mikko Lipasti Pipelining Forecast
CSE 533: Advanced Computer Architectures Pipelining Instructor: Gürhan Küçük Yeditepe University Lecture notes based on notes by Mark D. Hill and John P. Shen Updated by Mikko Lipasti Pipelining Forecast
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
T = I x CPI x C. Both effective CPI and clock cycle C are heavily influenced by CPU design. CPI increased (3-5) bad Shorter cycle good
 bad Shorter cycle good") CPU performance equation: T = I x CPI x C Both effective CPI and clock cycle C are heavily influenced by CPU design. For single-cycle CPU: CPI = 1 good Long cycle time bad On the other hand, for multi-cycle
CPU performance equation: T = I x CPI x C Both effective CPI and clock cycle C are heavily influenced by CPU design. For single-cycle CPU: CPI = 1 good Long cycle time bad On the other hand, for multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some