27. Parallel Programming I
|
|
|
- Darren Abner Long
- 5 years ago
- Views:
Transcription
1 Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling [Task-Scheduling: Cormen et al, Kap. 27] [Concurrency, Scheduling: Williams, Kap ]
2 The Free Lunch The free lunch is over "The Free Lunch is Over", a fundamental turn toward concurrency in software, Herb Sutter, Dr. Dobb s Journal,

3 Moore s Law 762 Observation by Gordon E. Moore: The number of transistors on integrated circuits doubles approximately every two years. Gordon E. Moore (1929)
4 763
5 764 For a long time... the sequential execution became faster ("Instruction Level Parallelism", "Pipelining", Higher Frequencies) more and smaller transistors = more performance programmers simply waited for the next processor generation
6 765 Today the frequency of processors does not increase significantly and more (heat dissipation problems) the instruction level parallelism does not increase significantly any more the execution speed is dominated by memory access times (but caches still become larger and faster)

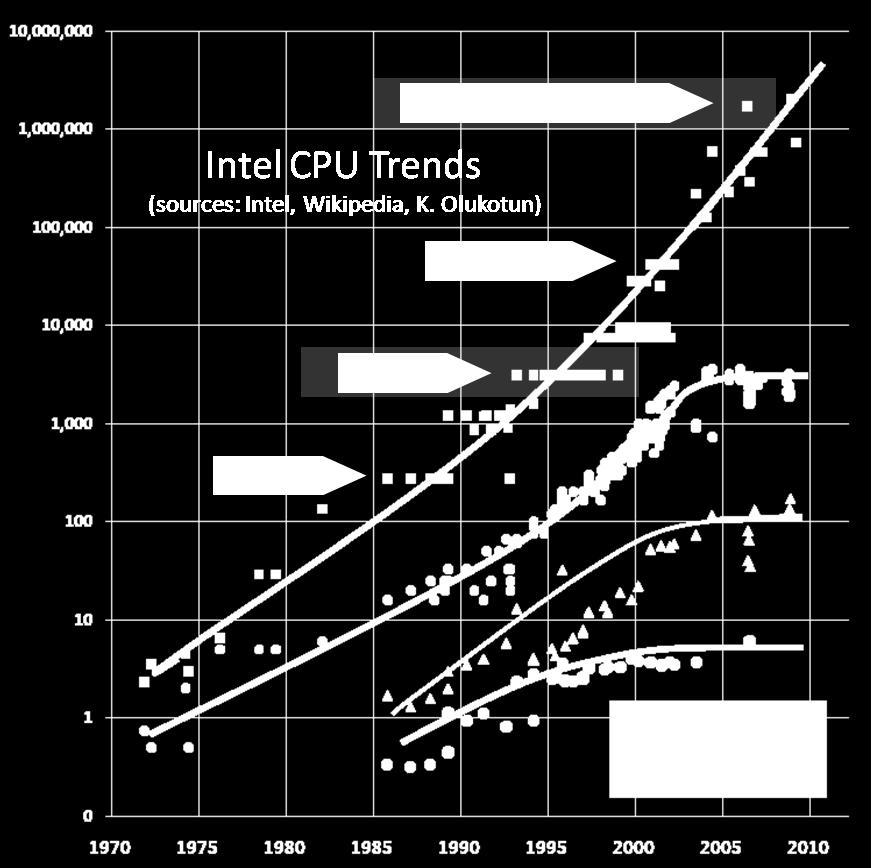
7 Trends 766
8 767 Multicore Use transistors for more compute cores Parallelism in the software Programmers have to write parallel programs to benefit from new hardware
9 768 Forms of Parallel Execution Vectorization Pipelining Instruction Level Parallelism Multicore / Multiprocessing Distributed Computing
10 Vectorization Parallel Execution of the same operations on elements of a vector (register) skalar x y + x + y
11 Vectorization Parallel Execution of the same operations on elements of a vector (register) skalar x y + x + y vector x 1 x 2 x 3 x 4 y 1 y 2 y 3 y 4 + x 1 + y 1 x 2 + y 2 x 3 + y 3 x 4 + y 4
12 Vectorization 769 Parallel Execution of the same operations on elements of a vector (register) skalar x y + x + y vector vector x 1 x 2 x 3 x 4 y 1 y 2 y 3 y 4 + x 1 + y 1 x 2 + y 2 x 3 + y 3 x 4 + y 4 x 1 x 2 x 3 x 4 y 1 y 2 y 3 y 4 fma x, y

13 Home Work 770

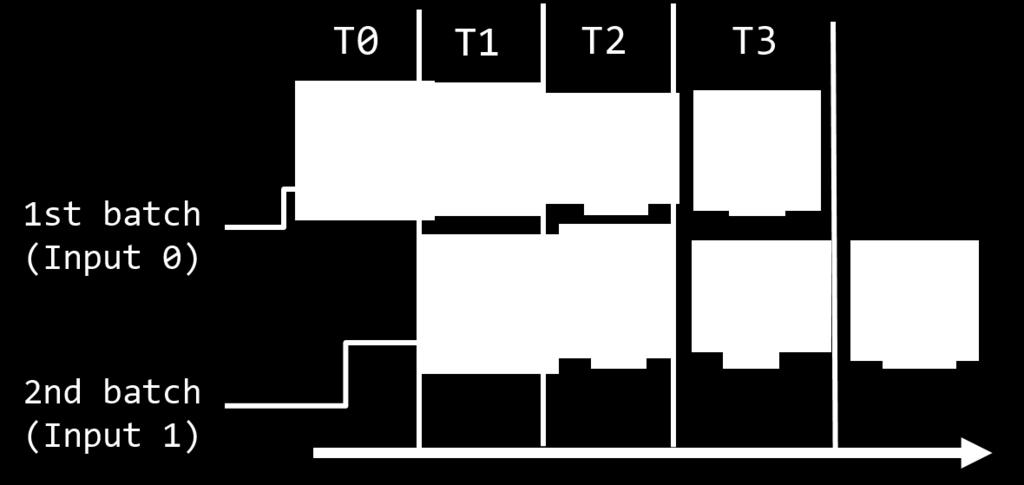
14 More efficient 771

15 Pipeline 772
16 Balanced / Unbalanced Pipeline 773 A pipeline is called balanced, if each step takes the same computation time. Software-Pipelines are often unbalanced. In the following we assume that each step of the pipeline takes as long as the longest step.
17 774 Throughput Throughput = Input or output data rate Number operations per time unit larger througput is better throughput = ignores lead-in and lead-out times 1 max(computationtime(stages))
18 Latency 775 Time to perform a computation latency = #stages max(computationtime(stages))
19 776 Homework Example Washing T 0 = 1h, Drying T 1 = 2h, Ironing T 2 = 1h, Tidy up T 3 = 0.5h Latency L = 8h In the long run: 1 batch every 2h (0.5/h).
20 777 Throughput vs. Latency Increasing throughput can increase latency Stages of the pipeline need to communicate and synchronize: overhead
21 778 Pipelines in CPUs Fetch Decode Execute Data Fetch Writeback Multiple Stages Every instruction takes 5 time units (cycles) In the best case: 1 instruction per cycle, not always possible ( stalls ) Paralellism (several functional units) leads to faster execution.
22 779 ILP Instruction Level Parallelism Modern CPUs provide several hardware units and execute independent instructions in parallel. Pipelining Superscalar CPUs (multiple instructions per cycle) Out-Of-Order Execution (Programmer observes the sequential execution) Speculative Execution ()
23 27.2 Hardware Architectures 780
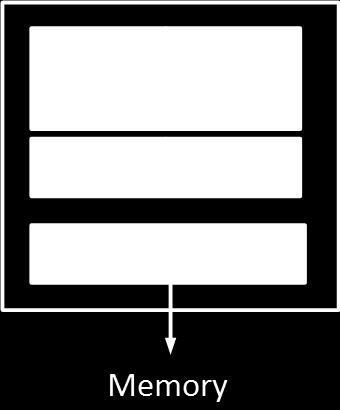
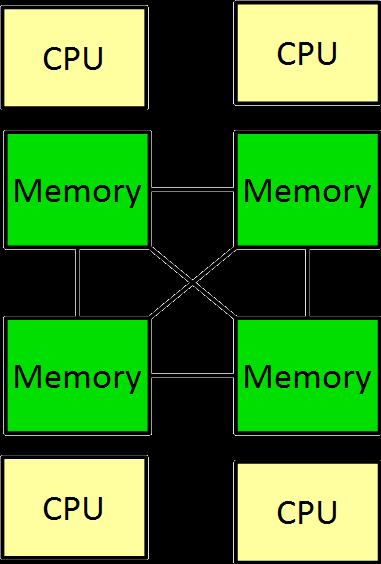
24 Shared vs. Distributed Memory 781 Shared Memory Distributed Memory CPU CPU CPU CPU CPU CPU Mem Mem Mem Mem Interconnect
25 Shared vs. Distributed Memory Programming 782 Categories of programming interfaces Communication via message passing Communication via memory sharing It is possible: to program shared memory systems as distributed systems (e.g. with message passing MPI) program systems with distributed memory as shared memory systems (e.g. partitioned global address space PGAS)
26 783 Shared Memory Architectures Multicore (Chip Multiprocessor - CMP) Symmetric Multiprocessor Systems (SMP) Simultaneous Multithreading (SMT = Hyperthreading) one physical core, Several Instruction Streams/Threads: several virtual cores Between ILP (several units for a stream) and multicore (several units for several streams). Limited parallel performance. Non-Uniform Memory Access (NUMA) Same programming interface



27 Overview 784 CMP SMP NUMA

28 785 An Example AMD Bulldozer: between CMP and SMT 2x integer core 1x floating point core
29 Flynn s Taxonomy SI = Single Instruction MI = Multiple Instructions SD = Single Data MD = Multiple Data
30 Flynn s Taxonomy Single-Core SI = Single Instruction MI = Multiple Instructions SD = Single Data MD = Multiple Data
31 Flynn s Taxonomy Single-Core Fehlertoleranz SI = Single Instruction MI = Multiple Instructions SD = Single Data MD = Multiple Data
32 Flynn s Taxonomy Single-Core Fehlertoleranz SI = Single Instruction MI = Multiple Instructions SD = Single Data MD = Multiple Data Vector Computing / GPU

33 Flynn s Taxonomy Single-Core Fehlertoleranz SI = Single Instruction MI = Multiple Instructions SD = Single Data MD = Multiple Data Vector Computing / GPU Multi-Core 786
34 Massively Parallel Hardware 787 [General Purpose] Graphical Processing Units ([GP]GPUs) Revolution in High Performance Computing SIMD Calculation 4.5 TFlops vs. 500 GFlops Memory Bandwidth 170 GB/s vs. 40 GB/s High data parallelism Requires own programming model. Z.B. CUDA / OpenCL
35 27.3 Multi-Threading, Parallelism and Concurrency 788
36 Processes and Threads 789 Process: instance of a program each process has a separate context, even a separate address space OS manages processes (resource control, scheduling, synchronisation) Threads: threads of execution of a program Threads share the address space fast context switch between threads
37 790 Why Multithreading? Avoid polling resources (files, network, keyboard) Interactivity (e.g. responsivity of GUI programs) Several applications / clients in parallel Parallelism (performance!)
38 Multithreading conceptually 791 Thread 1 Single Core Thread 2 Thread 3 Thread 1 Multi Core Thread 2 Thread 3
39 Thread switch on one core (Preemption) thread 1 thread 2
40 Thread switch on one core (Preemption) thread 1 thread 2 busy Interrupt Store State t 1 idle
41 Thread switch on one core (Preemption) thread 1 thread 2 busy Interrupt Store State t 1 idle Load State t 2
42 Thread switch on one core (Preemption) thread 1 thread 2 busy Interrupt Store State t 1 idle Load State t 2 idle Store State t 2 Interrupt busy
43 Thread switch on one core (Preemption) 792 thread 1 thread 2 busy Interrupt Store State t 1 idle Load State t 2 idle Store State t 2 Interrupt busy busy Load State t 1 idle
44 Parallelität vs. Concurrency 793 Parallelism: Use extra resources to solve a problem faster Concurrency: Correctly and efficiently manage access to shared resources Begriffe überlappen offensichtlich. Bei parallelen Berechnungen besteht fast immer Synchronisierungsbedarf. Parallelism Work Concurrency Requests Resources Resources
45 Thread Safety 794 Thread Safety means that in a concurrent application of a program this always yields the desired results. Many optimisations (Hardware, Compiler) target towards the correct execution of a sequential program. Concurrent programs need an annotation that switches off certain optimisations selectively.


46 795 Example: Caches Access to registers faster than to shared memory. Principle of locality. Use of Caches (transparent to the programmer) If and how far a cache coherency is guaranteed depends on the used system.
47 27.4 Scalability: Amdahl and Gustafson 796
48 797 Scalability In parallel Programming: Speedup when increasing number p of processors What happens if p? Program scales linearly: Linear speedup.
49 798 Parallel Performance Given a fixed amount of computing work W (number computing steps) Sequential execution time T 1 Parallel execution time on p CPUs Perfection: T p = T 1 /p Performance loss: T p > T 1 /p (usual case) Sorcery: T p < T 1 /p
50 799 Parallel Speedup Parallel speedup S p on p CPUs: S p = W/T p W/T 1 = T 1 T p. Perfection: linear speedup S p = p Performance loss: sublinear speedup S p < p (the usual case) Sorcery: superlinear speedup S p > p Efficiency:E p = S p /p
51 Reachable Speedup? 800 Parallel Program Parallel Part Seq. Part 80% 20% T 1 = 10 T 8 =?
52 Reachable Speedup? 800 Parallel Program Parallel Part Seq. Part 80% 20% T 1 = T 8 = = = 3
53 Reachable Speedup? Parallel Program Parallel Part Seq. Part 80% 20% T 1 = T 8 = = = 3 8 S 8 = T 1 = 10 T < 8 (!) 800
54 Amdahl s Law: Ingredients 801 Computational work W falls into two categories Paralellisable part W p Not parallelisable, sequential part W s Assumption: W can be processed sequentially by one processor in W time units (T 1 = W ): T 1 = W s + W p T p W s + W p /p
55 Amdahl s Law 802 S p = T 1 T p W s + W p W s + W p p
56 Amdahl s Law 803 With sequential, not parallelizable fraction λ: W s = λw, W p = (1 λ)w : 1 S p λ + 1 λ p
57 Amdahl s Law 803 With sequential, not parallelizable fraction λ: W s = λw, W p = (1 λ)w : 1 S p λ + 1 λ p Thus S 1 λ
58 Illustration Amdahl s Law p = 1 W s t W p
59 Illustration Amdahl s Law p = 1 p = 2 W s W s t W p W p
60 Illustration Amdahl s Law 804 p = 1 p = 2 p = 4 W s W s W s W p t W p W p T 1
61 Amdahl s Law is bad news 805 All non-parallel parts of a program can cause problems
62 806 Gustafson s Law Fix the time of execution Vary the problem size. Assumption: the sequential part stays constant, the parallel part becomes larger
63 Illustration Gustafson s Law p = 1 W s t W p
64 Illustration Gustafson s Law p = 1 p = 2 W s W s t W p W p W p
65 Illustration Gustafson s Law 807 p = 1 p = 2 p = 4 W s W s W s t W p W p W p W p W p W p W p T
66 Gustafson s Law 808 Work that can be executed by one processor in time T : W s + W p = T Work that can be executed by p processors in time T : W s + p W p = λ T + p (1 λ) T Speedup: S p = W s + p W p = p (1 λ) + λ W s + W p = p λ(p 1)
67 Amdahl vs. Gustafson Amdahl Gustafson
68 Amdahl vs. Gustafson Amdahl Gustafson p = 4
69 Amdahl vs. Gustafson 809 Amdahl Gustafson p = 4 p = 4
70 Amdahl vs. Gustafson 810 The laws of Amdahl and Gustafson are models of speedup for parallelization. Amdahl assumes a fixed relative sequential portion, Gustafson assumes a fixed absolute sequential part (that is expressed as portion of the work W 1 and that does not increase with increasing work). The two models do not contradict each other but describe the runtime speedup of different problems and algorithms.
71 27.5 Task- and Data-Parallelism 811
72 812 Parallel Programming Paradigms Task Parallel: Programmer explicitly defines parallel tasks. Data Parallel: Operations applied simulatenously to an aggregate of individual items.
73 Example Data Parallel (OMP) 813 double sum = 0, A[MAX]; #pragma omp parallel for reduction (+:ave) for (int i = 0; i< MAX; ++i) sum += A[i]; return sum;
74 Example Task Parallel (C++11 Threads/Futures) 814 double sum(iterator from, Iterator to) { auto len = from to; if (len > threshold){ auto future = std::async(sum, from, from + len / 2); return sums(from + len / 2, to) + future.get(); } else return sums(from, to); }
75 Work Partitioning and Scheduling 815 Partitioning of the work into parallel task (programmer or system) One task provides a unit of work Granularity? Scheduling (Runtime System) Assignment of tasks to processors Goal: full resource usage with little overhead
76 Example: Fibonacci P-Fib 816 if n 1 then return n else x spawn P-Fib(n 1) y spawn P-Fib(n 2) sync return x + y;

77 P-Fib Task Graph 817
78 P-Fib Task Graph 818
79 Question Each Node (task) takes 1 time unit. Arrows depict dependencies. Minimal execution time when number of processors =?
80 819 Question Each Node (task) takes 1 time unit. Arrows depict dependencies. Minimal execution time when number of processors =? critical path
81 820 Performance Model p processors Dynamic scheduling T p : Execution time on p processors
82 Performance Model 821 T p : Execution time on p processors T 1 : work: time for executing total work on one processor T 1 /T p : Speedup
83 Performance Model 822 T : span: critical path, execution time on processors. Longest path from root to sink. T 1 /T : Parallelism: wider is better Lower bounds: T p T 1 /p T p T Work law Span law
84 Greedy Scheduler 823 Greedy scheduler: at each time it schedules as many as availbale tasks. Theorem On an ideal parallel computer with p processors, a greedy scheduler executes a multi-threaded computation with work T 1 and span T in time T p T 1 /p + T
85 Beispiel Assume p = 2.
86 Beispiel Assume p = 2.
87 Beispiel Assume p = 2.
88 Beispiel Assume p = 2.
89 Beispiel Assume p = 2.
90 Beispiel Assume p = 2. T p = 5
91 Beispiel Assume p = 2. T p = 5
92 Beispiel Assume p = 2. T p = 5
93 Beispiel Assume p = 2. T p = 5
94 Beispiel Assume p = 2. T p = 5
95 Beispiel 824 Assume p = 2. T p = 5 T p = 4
96 Proof of the Theorem 825 Assume that all tasks provide the same amount of work. Complete step: p tasks are available. incomplete step: less than p steps available. Assume that number of complete steps larger than T 1 /p. Executed work T 1 /p p + p = T 1 T 1 mod p + p > T 1. Contradiction. Therefore maximally T 1 /p complete steps. We now consider the graph of tasks to be done. Any maximal (critical) path starts with a node t with deg (t) = 0. An incomplete step executes all available tasks t with deg (t) = 0 and thus decreases the length of the span. Number incomplete steps thus limited by T.
97 Consequence 826 if p T 1 /T, i.e. T T 1 /p, then T p T 1 /p. Example Fibonacci T 1 (n)/t (n) = Θ(φ n /n). For moderate sizes of n we can use a lot of processors yielding linear speedup.
98 Granularity: how many tasks? 827 #Tasks = #Cores?
99 827 Granularity: how many tasks? #Tasks = #Cores? Problem if a core cannot be fully used
100 827 Granularity: how many tasks? #Tasks = #Cores? Problem if a core cannot be fully used Example: 9 units of work. 3 core. Scheduling of 3 sequential tasks.
101 827 Granularity: how many tasks? #Tasks = #Cores? Problem if a core cannot be fully used Example: 9 units of work. 3 core. Scheduling of 3 sequential tasks. Exclusive utilization: P1 s1 P2 s2 P3 s3 Execution Time: 3 Units Foreign thread disturbing: P1 s1 P2 s2 s1 P3 s3 Execution Time: 5 Units
102 828 Granularity: how many tasks? #Tasks = Maximum? Example: 9 units of work. 3 cores. Scheduling of 9 sequential tasks.
103 828 Granularity: how many tasks? #Tasks = Maximum? Example: 9 units of work. 3 cores. Scheduling of 9 sequential tasks. Exclusive utilization: P1 P2 P3 s1 s2 s3 s4 s5 s6 s7 s8 s9 Execution Time: 3 + ε Units Foreign thread disturbing: P1 P2 P3 s1 s2 s3 s4 s6 s5 s7 s8 s9 Execution Time: 4 Units. Full utilization.
104 829 Granularity: how many tasks? #Tasks = Maximum? Example: 10 6 tiny units of work.
105 829 Granularity: how many tasks? #Tasks = Maximum? Example: 10 6 tiny units of work. P1 P2 P3 Execution time: dominiert vom Overhead.
106 Granularity: how many tasks? 830 Answer: as many tasks as possible with a sequential cutoff such that the overhead can be neglected.
107 Example: Parallelism of Mergesort 831 Work (sequential runtime) of Mergesort T 1 (n) = Θ(n log n). Span T (n) = Θ(n) Parallelism T 1 (n)/t (n) = Θ(log n) (Maximally achievable speedup with p = processors) split merge
27. Parallel Programming I
 The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
27. Parallel Programming I
 771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
Datenstrukturen und Algorithmen
 1 Datenstrukturen und Algorithmen Exercise 12 FS 2018 Program of today 2 1 Feedback of last exercise 2 Repetition theory 3 Programming Tasks 1. Feedback of last exercise 3 Football Championship 4 Club
1 Datenstrukturen und Algorithmen Exercise 12 FS 2018 Program of today 2 1 Feedback of last exercise 2 Repetition theory 3 Programming Tasks 1. Feedback of last exercise 3 Football Championship 4 Club
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
High Performance Computing Systems
 High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
18-447: Computer Architecture Lecture 30B: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013
 18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
ELE 455/555 Computer System Engineering. Section 4 Parallel Processing Class 1 Challenges
 ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer Architecture: Parallel Processing Basics. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Computer Architecture Crash course
 Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
CS377P Programming for Performance Multicore Performance Multithreading
 CS377P Programming for Performance Multicore Performance Multithreading Sreepathi Pai UTCS October 14, 2015 Outline 1 Multiprocessor Systems 2 Programming Models for Multicore 3 Multithreading and POSIX
CS377P Programming for Performance Multicore Performance Multithreading Sreepathi Pai UTCS October 14, 2015 Outline 1 Multiprocessor Systems 2 Programming Models for Multicore 3 Multithreading and POSIX
10th August Part One: Introduction to Parallel Computing
 Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
Multithreaded Algorithms Part 1. Dept. of Computer Science & Eng University of Moratuwa
 CS4460 Advanced d Algorithms Batch 08, L4S2 Lecture 11 Multithreaded Algorithms Part 1 N. H. N. D. de Silva Dept. of Computer Science & Eng University of Moratuwa Announcements Last topic discussed is
CS4460 Advanced d Algorithms Batch 08, L4S2 Lecture 11 Multithreaded Algorithms Part 1 N. H. N. D. de Silva Dept. of Computer Science & Eng University of Moratuwa Announcements Last topic discussed is
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Fundamentals of Computers Design
 Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Multithreaded Parallelism and Performance Measures
 Multithreaded Parallelism and Performance Measures Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS 3101 (Moreno Maza) Multithreaded Parallelism and Performance Measures CS 3101
Multithreaded Parallelism and Performance Measures Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS 3101 (Moreno Maza) Multithreaded Parallelism and Performance Measures CS 3101
Today: Amortized Analysis (examples) Multithreaded Algs.
 Multithreaded Algs.") Today: Amortized Analysis (examples) Multithreaded Algs. COSC 581, Algorithms March 11, 2014 Many of these slides are adapted from several online sources Reading Assignments Today s class: Chapter 17 (Amortized
Today: Amortized Analysis (examples) Multithreaded Algs. COSC 581, Algorithms March 11, 2014 Many of these slides are adapted from several online sources Reading Assignments Today s class: Chapter 17 (Amortized
Chapter 7. Multicores, Multiprocessors, and Clusters. Goal: connecting multiple computers to get higher performance
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Introduction. CSCI 4850/5850 High-Performance Computing Spring 2018
 Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
CPU Architecture Overview. Varun Sampath CIS 565 Spring 2012
 CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CS 31: Intro to Systems Threading & Parallel Applications. Kevin Webb Swarthmore College November 27, 2018
 CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Chapter 5: Thread-Level Parallelism Part 1
 Chapter 5: Thread-Level Parallelism Part 1 Introduction What is a parallel or multiprocessor system? Why parallel architecture? Performance potential Flynn classification Communication models Architectures
Chapter 5: Thread-Level Parallelism Part 1 Introduction What is a parallel or multiprocessor system? Why parallel architecture? Performance potential Flynn classification Communication models Architectures
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Shared-memory Parallel Programming with Cilk Plus
 Shared-memory Parallel Programming with Cilk Plus John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 4 30 August 2018 Outline for Today Threaded programming
Shared-memory Parallel Programming with Cilk Plus John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 4 30 August 2018 Outline for Today Threaded programming
Parallel Computing Why & How?
 Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Multicore Programming
 Multi Programming Parallel Hardware and Performance 8 Nov 00 (Part ) Peter Sewell Jaroslav Ševčík Tim Harris Merge sort 6MB input (-bit integers) Recurse(left) ~98% execution time Recurse(right) Merge
Multi Programming Parallel Hardware and Performance 8 Nov 00 (Part ) Peter Sewell Jaroslav Ševčík Tim Harris Merge sort 6MB input (-bit integers) Recurse(left) ~98% execution time Recurse(right) Merge
TDT4260/DT8803 COMPUTER ARCHITECTURE EXAM
 Norwegian University of Science and Technology Department of Computer and Information Science Page 1 of 13 Contact: Magnus Jahre (952 22 309) TDT4260/DT8803 COMPUTER ARCHITECTURE EXAM Monday 4. June Time:
Norwegian University of Science and Technology Department of Computer and Information Science Page 1 of 13 Contact: Magnus Jahre (952 22 309) TDT4260/DT8803 COMPUTER ARCHITECTURE EXAM Monday 4. June Time:
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Parallel Algorithms. 6/12/2012 6:42 PM gdeepak.com 1
 Parallel Algorithms 1 Deliverables Parallel Programming Paradigm Matrix Multiplication Merge Sort 2 Introduction It involves using the power of multiple processors in parallel to increase the performance
Parallel Algorithms 1 Deliverables Parallel Programming Paradigm Matrix Multiplication Merge Sort 2 Introduction It involves using the power of multiple processors in parallel to increase the performance
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Why do we care about parallel?
 Threads 11/15/16 CS31 teaches you How a computer runs a program. How the hardware performs computations How the compiler translates your code How the operating system connects hardware and software The
Threads 11/15/16 CS31 teaches you How a computer runs a program. How the hardware performs computations How the compiler translates your code How the operating system connects hardware and software The
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Plan. 1 Parallelism Complexity Measures. 2 cilk for Loops. 3 Scheduling Theory and Implementation. 4 Measuring Parallelism in Practice
 lan Multithreaded arallelism and erformance Measures Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS 3101 1 2 cilk for Loops 3 4 Measuring arallelism in ractice 5 Announcements
lan Multithreaded arallelism and erformance Measures Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS 3101 1 2 cilk for Loops 3 4 Measuring arallelism in ractice 5 Announcements
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol
 Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Parallel Computing Introduction
 Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Written Exam / Tentamen
 Written Exam / Tentamen Computer Organization and Components / Datorteknik och komponenter (IS1500), 9 hp Computer Hardware Engineering / Datorteknik, grundkurs (IS1200), 7.5 hp KTH Royal Institute of
Written Exam / Tentamen Computer Organization and Components / Datorteknik och komponenter (IS1500), 9 hp Computer Hardware Engineering / Datorteknik, grundkurs (IS1200), 7.5 hp KTH Royal Institute of
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Comp. Org II, Spring
 Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Chapter 18 - Multicore Computers
 Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Parallel Processing & Multicore computers
 Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Introduction to parallel computing
 Introduction to parallel computing 3. Parallel Software Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Last time Parallel hardware Multi-core
Introduction to parallel computing 3. Parallel Software Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Last time Parallel hardware Multi-core
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline