The instruction scheduling problem with a focus on GPU. Ecole Thématique ARCHI 2015 David Defour
|
|
|
- Drusilla Woods
- 5 years ago
- Views:
Transcription

1 The instruction scheduling problem with a focus on GPU Ecole Thématique ARCHI 2015 David Defour





2 Scheduling in GPU s Stream are scheduled among GPUs Kernel of a Stream are scheduler on a given GPUs using FIFO Instruction Cache Scheduler Scheduler Dispatch Dispatch Register File Core Core Core Core Core Core Core Core Block are scheduled among s with a round robin algorithm Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Warp are scheduled to SIMT processor using a round robin algorithm with priority and aging Data dependencies are handle using a scoreboard Core Core Core Core Core Core Core Core Load/Store Units x 16 Special Func Units x 4 Interconnect Network 64K Configurable Cache/Shared Mem Uniform Cache
3 Topics covered Definition of the scheduling problem Scheduling on superscalar architecture Scheduling on vector architecture How to schedule New problems
4 Principle of scheduling Complexity of Networks, Computers, Processors & Applications is increasing Need of efficient scheduling at each level
5 Level of Scheduling Intra-computer Local scheduling (memory hierarchy, device, functional unit ) Computer level Among cores (threads) Inter-computer Global scheduling (tasks) Memory hierarchy Device/Functional Unit Multiprocessor Multiple computer
6 The scheduling problem: the 5 components Set 1 (tasks, job, inst ) Set 2 (processors, core, FU ) 1. Events Smallest indivisible schedulable entity 2. Environment Characteristics and capabilities of the surrounding that will impact schedule 3. Requirement Real time deadline, improvement in performance 4. Schedule Set of ordered pairs of events and times 5. Scheduler Takes events, Environment & requirement and produce a schedule
7 The scheduling problem: the 5 components Processing power Interconnect # Processor Set 1 (tasks, job, inst ) Set 2 (processors, core, FU ) 1. Events Smallest indivisible schedulable entity 2. Environment Characteristics and capabilities of the surrounding that will impact schedule 3. Requirement Real time deadline, improvement in performance 4. Schedule Set of ordered pairs of events and times 5. Scheduler Takes events, Environment & requirement and produce a schedule
8 The scheduling problem: the 5 components Interconnect # Processor Processing power Set 1 (tasks, job, inst ) Set 2 (processors, core, FU ) Objectives (performance, power consumption,..) 1. Events Smallest indivisible schedulable entity 2. Environment Characteristics and capabilities of the surrounding that will impact schedule 3. Requirement Real time deadline, improvement in performance 4. Schedule Set of ordered pairs of events and times 5. Scheduler Takes events, Environment & requirement and produce a schedule
9 The scheduling problem: the 5 components Interconnect # Processor Processing power Mapping Schedule Set 1 (tasks, job, inst ) Set 2 (processors, core, FU ) Objectives (performance, power consumption,..) 1. Events Smallest indivisible schedulable entity 2. Environment Characteristics and capabilities of the surrounding that will impact schedule 3. Requirement Real time deadline, improvement in performance 4. Schedule Set of ordered pairs of events and times 5. Scheduler Takes events, Environment & requirement and produce a schedule
10 The scheduling problem: the 5 components Interconnect # Processor Processing power Scheduler Mapping Schedule Set 1 (tasks, job, inst ) Set 2 (processors, core, FU ) Objectives (performance, power consumption,..) 1. Events Smallest indivisible schedulable entity 2. Environment Characteristics and capabilities of the surrounding that will impact schedule 3. Requirement Real time deadline, improvement in performance 4. Schedule Set of ordered pairs of events and times 5. Scheduler Takes events, Environment & requirement and produce a schedule
11 Topics covered Definition of the scheduling problem Scheduling on superscalar architecture Scheduling on vector architecture How to schedule New problems
12 Scheduling on superscalar architecture Use available transistors to do more work per unit of time Throughput per Cycle Issue multiple instruction per clock cycle, deeper pipeline to increase ILP Latency in Cycles Parallelism = Troughput * Latency 1 Operation

13 Instruction Level Parallelism (ILP) Increase in instruction width and depth of machine pipeline Increase of independent instruction required to keep processor busy Increase the number of partially in flight executed instructions Difficult to build machines that control large numbers of in-flight instructions Either for dynamically or statically schedule machine
14 Dynamically scheduled Growth of Instruction windows Reorder buffer Rename Register files machine Number of port on each of those element must grow with the width The logic to track dependencies in-flight instruction grow cubically in the number of instructions
15 Control logic scaling Issue Width W Issue Group Lifetime L Previously Issued Instructions Each d inst. must make interlock checks against W*L inst., Growth in interlock ~W*(W*L) In-order machines: L related to pipeline latency Out-of-order machines: L related to inst. buffer (ROB, ) Increase in W => increase in inst. windows to find enough // => greater L 3 => Out-Of-Order logic grows in ~W
16 Statically scheduled machine (VLIW) Shift most of the schedule burden to the compiler To support more in-flight instructions, requires more registers, more ports per register, more hazard interlock logic Results in a quadratic increase of complexity and circuit size
17 Topics covered Definition of the scheduling problem Scheduling on superscalar architecture Scheduling on vector architecture How to schedule New problems
18 Vector architecture Basic idea: Read set of data elements into «vector registers» Operate on those registers Disperse the results back into memory Registers are controlled by compiler Used to hide memory latency Leverage memory bandwidth
 Reduce instruction fetch and decode bandwidth needed to keep multiple deeply pipeline FU busy 2.")
19 Vector processing (1) Vector processing solves some problems related to ILP logic 1. A single instruction specifies a great deal of work (Execute an entire loop) Reduce instruction fetch and decode bandwidth needed to keep multiple deeply pipeline FU busy 2. Compiler/programmer indicates that the computation of each results in a vector is independent of the computation of other results in the same vector Elements in a vector can be computed using an array of parallel FU or single very deeply pipeline FU or any intermediate configuration
20 Vector processing (2) 3. Hardware need only check for data hazards between two instructions once per vector operand, not for every element in a vector. Reduce control logic 4. Vector instructions that access memory have known access pattern Adjacent data within a vector can be fetch from a set of heavily interleaved memory banks Access latency to main memory is seen only once, not for every element 5. Loops are replaced by vector instruction whose behavior is predetermined, control hazard that would arise from loop branch are non-existent 6. Traditional cache are replaced by prefetching and blocking technics to increase locality
21 Short vector: SIMD x86 processors: Expect 2 additional cores per chip per year SIMD width to double every four years Potential speedup from SIMD to be twice that from MIMD Media applications operate on data types narrower than the native word size Example: disconnect carry chains to partition adder Limitations, compared to vector instructions: Number of data operands encoded into op code No sophisticated addressing modes (strided, scatter-gather) No mask registers Operands must be consecutive and aligned memory locations.

22 Long vector Today s die are big enough to embed thousand s of FU Problem: Managing vector of 1000 s elements Memory Hierarchie Register File Issuing instructions over 1000 s FU Memory hierarchy accesses, Instruction Solution: Clustering 1000 s FU
23 Long vector: Clustering Divide machine into cluster of local register files and local functional units Lower bandwidth / Higher latency interconnect between clusters Software responsible of correct mapping of computations and minimization of communication overhead
24 Long vector: Clustering DRAM DRAM DRAM DRAM DRAM DRAM DRAM DRAM G80
25 Long vector: Clustering DRAM DRAM DRAM DRAM DRAM DRAM DRAM DRAM G80
26 DRAM DRAM DRAM DRAM DRAM DRAM DRAM DRAM Long vector: Clustering G80

27 TPC L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM Long vector: Nvidia G80 Interconnect network L1 TPC L1 TPC L1 TPC L1 TPC L1 TPC L1 TPC L1
28 L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM L2 DRAM Long vector: FERMI L1 L1 L1 L1 L1 L1 L1 L1 Interconnect network
29 CUDA execution (1) CPU Stream1 Stream2 Stream3 Kernel 6 Kernel 4 Kernel 5 Kernel 7 Kernel Scheduler / Dispatcher GPU 1 GPU 2 Kernel 1 Kernel 2 Kernel 3
30 CUDA execution (2) GPU 1 Kernel 1, Grid 1 Block 1 Block 5 Block 2 Block 6 Block 3 Block 7 Block 4 Block Block Kernel 2, Grid 2 Block 1 Block 2 Block 3 Block Block 5 Block 6 Block 7 Block 8
31 CUDA execution (3) GPU 1 Kernel 1, Grid 1 Kernel 2, Grid 2 Block Scheduler / Dispatcher Kernel context state: TLB, dirty data in caches Registers, shared mem. Fermi: Can dispatch 1 kernel to each 8-32 blocks / L1 L1 L1 L1 L1
32 CUDA execution (4) Block 0 Block Warp instruction queue warps / 1 Block 0, Warp IPC 33 Block 1, Warp IPC 33 Block 0, Warp IPC IPC
33 CUDA execution (5) FERMI Odd Warp Instruction Queues Scoreboarded Warp Scheduler Instruction Cache Register File Even Warp Instruction Queues 1/2 warp instruction 1/2 warp instruction 1/2 warp instruction Scoreboarded Warp Scheduler 1/2 warp instruction 48 queues, 1 for each warp Scoreboard: Track availability of operands handle structural hazards (FP64, SFU, ) Port 0 Port 1 Scheduler complexity: Large variety of instructions with different execution latency (factor 4) 32 bit ALU x16 32 bit FPU x16 SFU x4 64 KB L1D, Shared Memory 32 bit FPU x16 32 bit ALU x16 Handle priority (ex: register usage), ready to execute warp, mark certain queues as not ready based on expected latency of instruction
34 Subtleties (6) Operand collector / Temporal register cache Hardware which read in many register values and buffer them for later consumption. Could be useful for broadcasting values to FU Result queue Similar concept but for results Could be used for forwarding results to FU (CPU)



35 Evolution: Fermi, Kepler, Maxwell Simpler scoreboard No register dependency analysis Only keep track of long latency inst.
36 Some figures Maximum number of threads per block 1024 Maximum number of resident blocks per multiprocessor 8-32 Maximum number of resident warps per multiprocessor Number of 32-bit registers per multiprocessor 32K-128K
37 Topics covered Definition of the scheduling problem Scheduling on superscalar architecture Scheduling on vector architecture How to schedule New problems
38 Scheduling in GPU s Stream are scheduled among GPUs ex: Red/Black tree (Used at OS Level) Instruction Cache Scheduler Scheduler Dispatch Dispatch Kernel of a Stream are scheduler on a given GPUs using FIFO Register File Core Core Core Core Core Core Core Core Core Core Core Core Block are scheduled among s with a round robin algorithm Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Warp are scheduled to SIMT processor using a round robin algorithm with priority and aging Data dependencies are handle using a scoreboard Core Core Core Core Load/Store Units x 16 Special Func Units x 4 Interconnect Network 64K Configurable Cache/Shared Mem Uniform Cache

 O(n) Search O(log")
39 Scheduling at OS level Example: Completely Fair Scheduler (CFS, Linux kernel ) Maximize CPU usage & performance Based on Red/Black tree indexed with execution time Average Worst case Space O(n) O(n) Search O(log n) O(log n) Insert O(log n) O(log n) Delete O(log n) O(log n)
40 Scoreboard Keeps track of dependencies, state or operations Instruction status (which steps the instruction is in) Issue, Read Operands, Execution, Write Results Function unit status (For each functional unit) Busy: Indicates whether the unit is busy or not Op: Operation to perform in the unit (e.g., + or ) Fi: Destination register Fj, Fk: Source-register numbers Qj, Qk: Functional units producing source registers Fj, Fk Rj, Rk: Flags indicating when Fj, Fk are ready Register result status Indicates which functional unit will write each register, If one exists. Blank when no pending instructions will write that register
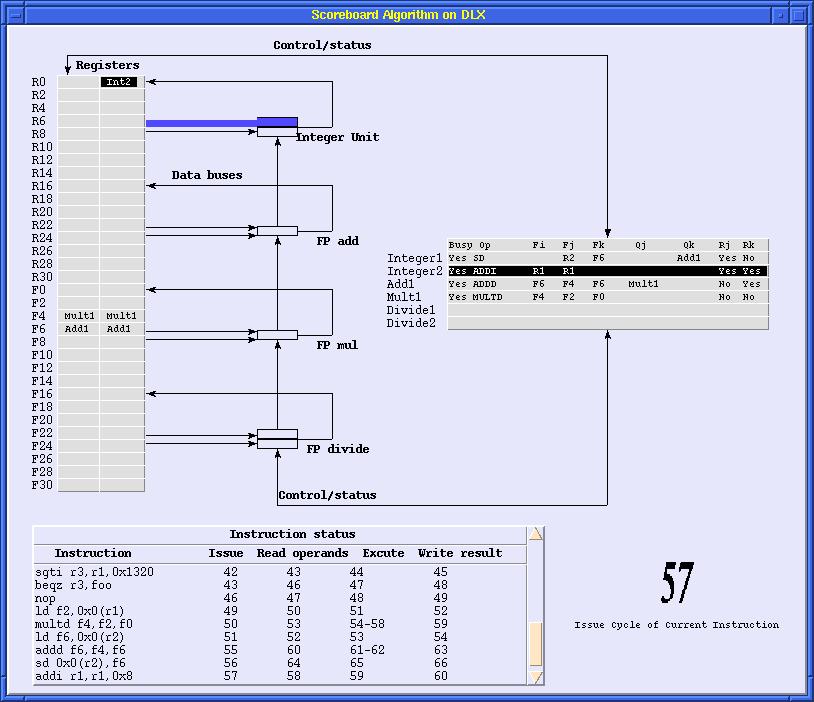
41

42 FIFO First implementation in electronics of FIFO: 1969 Fairchild Semiconductor by Peter Alfke. Queues processes in the order that they arrive in the queue Minimal overhead No prioritization Implementations Hardware Shift Register Memory Structure Circular buffer List Hardware Set of Read and Write pointers, Storage (dual-port SRAM, flip-flops, latches), Control logic Synchronous (same clock) Asynchronous (stability pb, use of gray code for read/write pointers to ensure correct flag) Flags : full/empty, almost full, almost empty, Head Tail
43 FIFO (2) FIFO Empty Flag: When the read address register reaches the write address register, the FIFO triggers the Empty signal. FIFO Full Flag: When the write address register reaches the read address register, the FIFO triggers the FULL signal. Both case == Distinguish both cases: add 1 bit to inverted each time wraps R@ = W@ => FIFO empty LSB( R@ ) = LSB( W@ ) => FIFO full

44 Priority Idea: Schedule the highest-priority eligible element first Implementation: (Static version) Rely on a priority enforcer/ encoder chain of elements with a ripple signal «Nobody above is eligible». Ripple signal can be replaced with a tree of OR gates to detects the presence of eligible entries (carry lookahead) Element 1 0 Element 2 0 Element 3 1 Element 4 0 Element 5 1 Eligibility Flags Element N 1 Priority High S Low
45 Priority encoder Each unit i send a request by setting Ai, and receive a granting bit Yi Y1 = A1, Y2 = A2. A1, Y3 = A3. A2. A1, A1 A2 AN Priority encoder Y1 Y2 YN YN = AN. AN-1..A2. A1,
46 Priority encoder Tradeoffs between delay and gate count

47 Round Robin Time slices are assigned to each process in equal portions and in circular order. No priority Simple, easy to implement, starvation free Known worst case wait time = function of the number of element -1 P0 P0 P3 P1 P1 P2 P3 P2
48 Round-Robin (1) Eligibility Flags Position Mask 1 element served each cycle Last scheduled schedule now Circular encoder/enforcer Each element has the capability to break the chain and become «head» element (similar to carry chain)
49 Round Robin (2) Round Robin Matching algorithm 2-dimensional round-robin scheduler (2DDR) Inputs Ouputs Accept all request on 1st diagonal Ignore other requests on same row/ column of accepted requests Accept all request on 2nd diagonal and ignore other
50 LaMaire, DN Serpanos - IEEE/ACM Transactions on Networking (TON), 1994 Round-Robin with Fairness The first diagonal should be selected in a round robin fashion among {0,1, N-1} Order of applying next diagonals should not always be «left-to-rigth» next_diagonal = (rev_diagonal + offset) mod M offset = ID of first_diagonal +1 M = smallest prime number >= N+1

51 Aging Implementation N 0: (2 elements) 1 bit counter (alternate between 0 and 1) 0 1 Implementation #1: 64 bit counter, incremented after every instruction Select the element with the oldest counter and reset it. rely on sorting networks Implementation #2: Use a matrix M of n x n element initialized at 0 Oldest : Select row k with lowest number of 1 Set all bits in row k of M to 1 Set all bits in column k of M to 0
52 New problems Loss of determinism Complicates debugging, test of correctness Key question How to avoid structural hazard and those problems at reasonable cost
53 Determinism Various solutions Langage (SHIM, NESL, HASKELL, ) Compiler Software /Algorithm Hardware (Grace, Dthreads)
 Numerical reproducibility Weak Enforce an execution order Ex: GPUBurn Strong Independent of the arch.")
54 Example: Algorithmic level Numerical with FP numbers Non-associativity of FP Numbers ( ) - 100!= ( ) Numerical reproducibility Weak Enforce an execution order Ex: GPUBurn Strong Independent of the arch., ~correctly rounded Ex: Hierarchical Kulisch Accumulator
55 Conclusions GPU s aren t simple processors Scheduling is as challenging as in traditional CPU Hardware solutions mostly unknown (only guess) Trend Toward simpler solution (ex: simpler scoreboard in Kepler) There is a need for deterministic execution



: http://www.")
56 Links Hardware description Rise of the Graphics Processor: Scheduling Books Network architecture (Manolis Katevenis): «An Investigation of the performance of various dynamic scheduling techniques»: butler_micro25.pdf
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor. David Johnson Systems Technology Division Hewlett-Packard Company
 Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Main Points of the Computer Organization and System Software Module
 Main Points of the Computer Organization and System Software Module You can find below the topics we have covered during the COSS module. Reading the relevant parts of the textbooks is essential for a
Main Points of the Computer Organization and System Software Module You can find below the topics we have covered during the COSS module. Reading the relevant parts of the textbooks is essential for a
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
PIPELINE AND VECTOR PROCESSING
 PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
Scoreboard information (3 tables) Four stages of scoreboard control
 Four stages of scoreboard control") Scoreboard information (3 tables) Instruction : issued, read operands and started execution (dispatched), completed execution or wrote result, Functional unit (assuming non-pipelined units) busy/not busy
Scoreboard information (3 tables) Instruction : issued, read operands and started execution (dispatched), completed execution or wrote result, Functional unit (assuming non-pipelined units) busy/not busy
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Architectures & instruction sets R_B_T_C_. von Neumann architecture. Computer architecture taxonomy. Assembly language.
 Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Limitations of Scalar Pipelines
 Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Data-Level Parallelism in SIMD and Vector Architectures. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano
 Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Nam Sung Kim. w/ Syed Zohaib Gilani * and Michael J. Schulte * University of Wisconsin-Madison Advanced Micro Devices *
 Nam Sung Kim w/ Syed Zohaib Gilani * and Michael J. Schulte * University of Wisconsin-Madison Advanced Micro Devices * modern GPU architectures deeply pipelined for efficient resource sharing several buffering
Nam Sung Kim w/ Syed Zohaib Gilani * and Michael J. Schulte * University of Wisconsin-Madison Advanced Micro Devices * modern GPU architectures deeply pipelined for efficient resource sharing several buffering
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Good luck and have fun!
 Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Chapter 2. Parallel Hardware and Parallel Software. An Introduction to Parallel Programming. The Von Neuman Architecture
 An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
06-2 EE Lecture Transparency. Formatted 14:50, 4 December 1998 from lsli
 06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Active thread Idle thread
 Active thread Idle thread") Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
 University of Crete School of Sciences & Engineering Computer Science Department Master Thesis by Michael Papamichael Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
University of Crete School of Sciences & Engineering Computer Science Department Master Thesis by Michael Papamichael Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Preventing Stalls: 1
 Preventing Stalls: 1 2 PipeLine Pipeline efficiency Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: best possible (1 as n ) Structural hazards:
Preventing Stalls: 1 2 PipeLine Pipeline efficiency Pipeline CPI = Ideal pipeline CPI + Structural Stalls + Data Hazard Stalls + Control Stalls Ideal pipeline CPI: best possible (1 as n ) Structural hazards:
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
What is ILP? Instruction Level Parallelism. Where do we find ILP? How do we expose ILP?
 What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Computer Architecture 计算机体系结构. Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Detailed Scoreboard Pipeline Control. Three Parts of the Scoreboard. Scoreboard Example Cycle 1. Scoreboard Example. Scoreboard Example Cycle 3
 1 From MIPS pipeline to Scoreboard Lecture 5 Scoreboarding: Enforce Register Data Dependence Scoreboard design, big example Out-of-order execution divides ID stage: 1.Issue decode instructions, check for
1 From MIPS pipeline to Scoreboard Lecture 5 Scoreboarding: Enforce Register Data Dependence Scoreboard design, big example Out-of-order execution divides ID stage: 1.Issue decode instructions, check for
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
CE 431 Parallel Computer Architecture Spring Graphics Processor Units (GPU) Architecture
 Architecture") CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Chapter 8 & Chapter 9 Main Memory & Virtual Memory
 Chapter 8 & Chapter 9 Main Memory & Virtual Memory 1. Various ways of organizing memory hardware. 2. Memory-management techniques: 1. Paging 2. Segmentation. Introduction Memory consists of a large array
Chapter 8 & Chapter 9 Main Memory & Virtual Memory 1. Various ways of organizing memory hardware. 2. Memory-management techniques: 1. Paging 2. Segmentation. Introduction Memory consists of a large array
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
c. What are the machine cycle times (in nanoseconds) of the non-pipelined and the pipelined implementations?
 of the non-pipelined and the pipelined implementations?") Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
CS450/650 Notes Winter 2013 A Morton. Superscalar Pipelines
 CS450/650 Notes Winter 2013 A Morton Superscalar Pipelines 1 Scalar Pipeline Limitations (Shen + Lipasti 4.1) 1. Bounded Performance P = 1 T = IC CPI 1 cycletime = IPC frequency IC IPC = instructions per
CS450/650 Notes Winter 2013 A Morton Superscalar Pipelines 1 Scalar Pipeline Limitations (Shen + Lipasti 4.1) 1. Bounded Performance P = 1 T = IC CPI 1 cycletime = IPC frequency IC IPC = instructions per
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Superscalar Processor
 Superscalar Processor Design Superscalar Architecture Virendra Singh Indian Institute of Science Bangalore virendra@computer.orgorg Lecture 20 SE-273: Processor Design Superscalar Pipelines IF ID RD ALU
Superscalar Processor Design Superscalar Architecture Virendra Singh Indian Institute of Science Bangalore virendra@computer.orgorg Lecture 20 SE-273: Processor Design Superscalar Pipelines IF ID RD ALU
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
18-447: Computer Architecture Lecture 25: Main Memory. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013
 18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
Vector Processors and Graphics Processing Units (GPUs)
") Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
COSC 6385 Computer Architecture - Pipelining (II)
") COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Advanced CUDA Programming. Dr. Timo Stich
 Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput