Leibniz Supercomputer Centre. Movie on YouTube
|
|
|
- Joseph Lindsey
- 6 years ago
- Views:
Transcription

1 Leibniz Supercomputer Centre Movie on YouTube
2 Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera trillion Peta quadrillion Exa quintillion Zetta sextillion Flops: Floating Point Operations per Seconds
 32 GByte memory Inifiniband network interface Processor has 8 cores 2-way hyperthreading 21.6 GFlops @ 2.7 GHz per core 172.")
3 Distributed Memory Architecture 18 partitions called islands with 512 nodes Node is a shared memory system with 2 processors Sandy Bridge-EP Intel Xeon E C 2.7 GHz (Turbo 3.5 GHz) 32 GByte memory Inifiniband network interface Processor has 8 cores 2-way hyperthreading GHz per core GFlops per processor
4 Sandy Bridge Processor Latency: 4 cycles 12 cycles 31 cycles Core L1 32KB L2 256KB 8 multithreaded cores Core L1 32KB L2 256KB Bandwidth: 2*16/cycle 32 / cycle 32 / cycle L3 2.5 MB Shared L3 L3 2.5 MB Network frequency equal to core frequency Memory QPI PCIe L3 cache Partitioned with cache coherence based on core valid bits Physical addresses distributed by a hash function
5 NUMA Node 4GB 2 QPI links 4GB 4GB 4GB Sandy Bridge Each 2 GT/s Sandy Bridge 4GB 4GB 4GB 4GB 8xPCIe3.0 (8GB/s) Infiniband 2 processors with 32 GB of memory Aggregate memory bandwidth per node GB/s Latency local ~50ns (~135 GHz) remote ~90ns (~240 cycles)
6 Interconnection Network Infiniband FDR-10 FDR means fourteen data rate FDR-10 has an effective data rate of Gb/s Latency: 100 nsec per switch, 1usec MPI Vendor: Mellanox Intra-Island Topology: non-blocking tree 256 communication pairs can talk in parallel. Inter-Island Topology: Pruned Tree 4:1 128 links per island to next level
7 Peak Performance 126 spine 36 port switch 36 port switch switches 19 links Rest for fat node and IO 126 links 648 port switch 516 nodes 516 links 18 islands + IO island 648 port switch

8 9288 Compute Nodes Cold Corridoor Infiniband (red) and Ethernet (green) cabling Matthias Brehm, Herbert Huber, LRZ High Performance Systems Division

9 Infiniband Interconnect 19 Orcas 126 Spine Switches Infiniband Cables Matthias Brehm, Herbert Huber, LRZ High Performance Systems Division
10 IO System Spine Infiniband Switches GPFS for $WORK and $SCRATCH Login nodes $HOME Archive GB/s 5 80 Gb/s 30 10GbE


11 Parallel File System GPFS 10 Pbyte, 200 GigaByte/s I/O Bandwidth 9 DDN SFA 12k Controller TByte SATA Disks Matthias Brehm, Herbert Huber, LRZ High Performance Systems Division

12 SuperMIC Intel Xeon Phi Cluster 32 Nodes 2 Xeon Ivy-Bridge processors E cores each 2.6 GHz clock frequency 2 Intel Xeon Phi coprocessors 5110P GHz Memory 64 GB host memory 2x8 GB Xeon Phi
 per thread context 16 (DP), 32 (SP) 1 TFlop/s (DP), 2 TFlop/s (SP) 512 kb Connection to host 6.")
13 Intel Xeon Phi Number of cores 60 Frequency of cores GDDR5 memory size Number of hardware threads per core SIMD vector registers Flops/cycle Theoretical peak performance L2 cache per core 1.1 GHz 8 GB 4 32 (512-bit wide) per thread context 16 (DP), 32 (SP) 1 TFlop/s (DP), 2 TFlop/s (SP) 512 kb Connection to host 6.2 GB/s
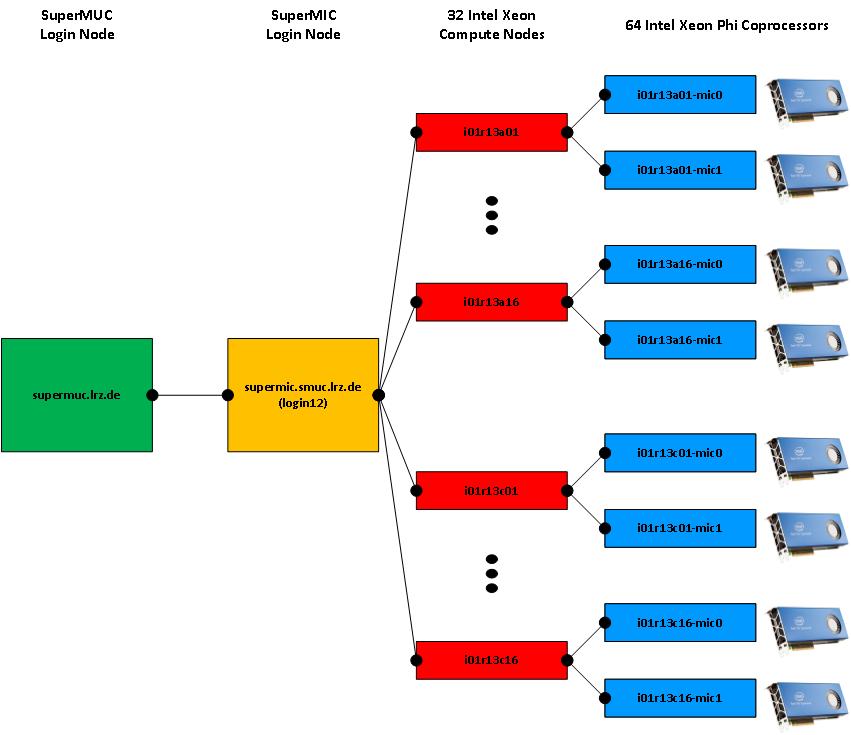
14 Nodes with Coprocessors
15 Access to SuperMIC Login to SuperMUC Login to SuperMIC ssh supermic.smuc.lrz.de Load leveler script with class phi Interactive access to nodes and coprocessors Submit batch script with sleep command. Login to compute nodes ssh i01r13??? Login to MIC coprocessors ssh i01r13???-mic0 ssh i01r13???-mic1 PPK required
16 The Compute Cube of LRZ Rückkühlwerke Hö Höchstleistungsrechner (säulenfrei) (sä Zugangsbrücke Zugangsbrücke Server/Netz Archiv/Backup Archiv/Backup Klima Klima Elektro
17 Run jobs in batch Advantages Reproducable performance Run larger jobs No need to interactive poll for resources Test queue Max 1 island, 32 nodes, 2h, 1 job in queue General queue Max 1 island, 512 nodes, 48 h Large Max 4 islands, 2048 nodes, 48 h Special Max 18 islands
18 Job Script #!/bin/bash wall_clock_limit = 00:4:00 #@ job_name = add #@ job_type = parallel #@ class = test #@ network.mpi = sn_all,not_shared,us #@ output = job$(jobid).out llsubmit job.scp Submission to batch system llq u $USER Check status of own jobs llcancel <jobid> Kill job if no longer needed #@ error = job$(jobid).out #@ node = 2 #@ total_tasks=4 #@ node_usage = not_shared #@ queue. /etc/profile cd ~/apptest/application poe appl
19 Limited CPU Hours available Please Specify job execution as tight as possible. Do not request more nodes than required. We have to pay for all allocated cores, not only the used ones. SHORT (<1sec) sequential runs can be done on the login node. Even SHORT OMP runs can be done on the login node.
20 Login to SuperMUC, Documentation First change the standard password Login via lxhalle due to restriction on connecting machines ssh No outgoing connections allowed Documentation Intel compiler: mposerxe/en-us/2011update/cpp/lin/index.htm
21 Batch Script Parameters energy_policy_tag = NONE Switch of automatic adaptation of core frequency for performance measurements #@ node = 2 #@ total_tasks= 4 #@ task_geometry = {(0,2) (1,3)} #@ tasks_per_node = 2 Limitations on combination documented at LRZ web page
22 Compiler Intel C++ icc Version 12.1 Editors vi emacs xedit
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
UAntwerpen, 24 June 2016
 Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - LRZ,
 Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
High Performance Computing. What is it used for and why?
 High Performance Computing What is it used for and why? Overview What is it used for? Drivers for HPC Examples of usage Why do you need to learn the basics? Hardware layout and structure matters Serial
High Performance Computing What is it used for and why? Overview What is it used for? Drivers for HPC Examples of usage Why do you need to learn the basics? Hardware layout and structure matters Serial
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
LRZ SuperMUC One year of Operation
 LRZ SuperMUC One year of Operation IBM Deep Computing 13.03.2013 Klaus Gottschalk IBM HPC Architect Leibniz Computing Center s new HPC System is now installed and operational 2 SuperMUC Technical Highlights
LRZ SuperMUC One year of Operation IBM Deep Computing 13.03.2013 Klaus Gottschalk IBM HPC Architect Leibniz Computing Center s new HPC System is now installed and operational 2 SuperMUC Technical Highlights
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
DELIVERABLE D5.5 Report on ICARUS visualization cluster installation. John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS)
 Jerome SOUMAGNE (CSCS)") DELIVERABLE D5.5 Report on ICARUS visualization cluster installation John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS) 02 May 2011 NextMuSE 2 Next generation Multi-mechanics Simulation Environment Cluster
DELIVERABLE D5.5 Report on ICARUS visualization cluster installation John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS) 02 May 2011 NextMuSE 2 Next generation Multi-mechanics Simulation Environment Cluster
High Performance Computing. What is it used for and why?
 High Performance Computing What is it used for and why? Overview What is it used for? Drivers for HPC Examples of usage Why do you need to learn the basics? Hardware layout and structure matters Serial
High Performance Computing What is it used for and why? Overview What is it used for? Drivers for HPC Examples of usage Why do you need to learn the basics? Hardware layout and structure matters Serial
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
OpenSees on Teragrid
 OpenSees on Teragrid Frank McKenna UC Berkeley OpenSees Parallel Workshop Berkeley, CA What isteragrid? An NSF sponsored computational science facility supported through a partnership of 13 institutions.
OpenSees on Teragrid Frank McKenna UC Berkeley OpenSees Parallel Workshop Berkeley, CA What isteragrid? An NSF sponsored computational science facility supported through a partnership of 13 institutions.
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Outline. March 5, 2012 CIRMMT - McGill University 2
 Outline CLUMEQ, Calcul Quebec and Compute Canada Research Support Objectives and Focal Points CLUMEQ Site at McGill ETS Key Specifications and Status CLUMEQ HPC Support Staff at McGill Getting Started
Outline CLUMEQ, Calcul Quebec and Compute Canada Research Support Objectives and Focal Points CLUMEQ Site at McGill ETS Key Specifications and Status CLUMEQ HPC Support Staff at McGill Getting Started
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
How to run applications on Aziz supercomputer. Mohammad Rafi System Administrator Fujitsu Technology Solutions
 How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Simulation using MIC co-processor on Helios
 Simulation using MIC co-processor on Helios Serhiy Mochalskyy, Roman Hatzky PRACE PATC Course: Intel MIC Programming Workshop High Level Support Team Max-Planck-Institut für Plasmaphysik Boltzmannstr.
Simulation using MIC co-processor on Helios Serhiy Mochalskyy, Roman Hatzky PRACE PATC Course: Intel MIC Programming Workshop High Level Support Team Max-Planck-Institut für Plasmaphysik Boltzmannstr.
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Philippe Thierry Sr Staff Engineer Intel Corp.
 HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Modern CPU Architectures
 Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
LAB. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 LAB Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012 1 Discovery
LAB Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012 1 Discovery
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Parallel Computer Architecture - Basics -
 Parallel Computer Architecture - Basics - Christian Terboven 29.07.2013 / Aachen, Germany Stand: 22.07.2013 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Overview:
Parallel Computer Architecture - Basics - Christian Terboven 29.07.2013 / Aachen, Germany Stand: 22.07.2013 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Overview:
BlueGene/L (No. 4 in the Latest Top500 List)
") BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
Symmetric Computing. SC 14 Jerome VIENNE
 Symmetric Computing SC 14 Jerome VIENNE viennej@tacc.utexas.edu Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Symmetric Computing SC 14 Jerome VIENNE viennej@tacc.utexas.edu Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Habanero Operating Committee. January
 Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Co-designing an Energy Efficient System
 Co-designing an Energy Efficient System Luigi Brochard Distinguished Engineer, HPC&AI Lenovo lbrochard@lenovo.com MaX International Conference 2018 Trieste 29.01.2018 Industry Thermal Challenges NVIDIA
Co-designing an Energy Efficient System Luigi Brochard Distinguished Engineer, HPC&AI Lenovo lbrochard@lenovo.com MaX International Conference 2018 Trieste 29.01.2018 Industry Thermal Challenges NVIDIA
The Energy Challenge in HPC
 ARNDT BODE Professor Arndt Bode is the Chair for Computer Architecture at the Leibniz-Supercomputing Center. He is Full Professor for Informatics at TU Mü nchen. His main research includes computer architecture,
ARNDT BODE Professor Arndt Bode is the Chair for Computer Architecture at the Leibniz-Supercomputing Center. He is Full Professor for Informatics at TU Mü nchen. His main research includes computer architecture,
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Genius Quick Start Guide
 Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Introduction to HPC Numerical libraries on FERMI and PLX
 Introduction to HPC Numerical libraries on FERMI and PLX HPC Numerical Libraries 11-12-13 March 2013 a.marani@cineca.it WELCOME!! The goal of this course is to show you how to get advantage of some of
Introduction to HPC Numerical libraries on FERMI and PLX HPC Numerical Libraries 11-12-13 March 2013 a.marani@cineca.it WELCOME!! The goal of this course is to show you how to get advantage of some of
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
6/14/2017. The Intel Xeon Phi. Setup. Xeon Phi Internals. Fused Multiply-Add. Getting to rabbit and setting up your account. Xeon Phi Peak Performance
 The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat
 Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
The RWTH Compute Cluster Environment
 The RWTH Compute Cluster Environment Tim Cramer 29.07.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) The RWTH Compute Cluster (1/2) The Cluster provides ~300 TFlop/s No. 32 in TOP500
The RWTH Compute Cluster Environment Tim Cramer 29.07.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) The RWTH Compute Cluster (1/2) The Cluster provides ~300 TFlop/s No. 32 in TOP500
Benchmark results on Knight Landing (KNL) architecture
 architecture") Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Symmetric Computing. Jerome Vienne Texas Advanced Computing Center
 Symmetric Computing Jerome Vienne Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Symmetric Computing Jerome Vienne Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
NCAR Workload Analysis on Yellowstone. March 2015 V5.0
 NCAR Workload Analysis on Yellowstone March 2015 V5.0 Purpose and Scope of the Analysis Understanding the NCAR application workload is a critical part of making efficient use of Yellowstone and in scoping
NCAR Workload Analysis on Yellowstone March 2015 V5.0 Purpose and Scope of the Analysis Understanding the NCAR application workload is a critical part of making efficient use of Yellowstone and in scoping
NERSC. National Energy Research Scientific Computing Center
 NERSC National Energy Research Scientific Computing Center Established 1974, first unclassified supercomputer center Original mission: to enable computational science as a complement to magnetically controlled
NERSC National Energy Research Scientific Computing Center Established 1974, first unclassified supercomputer center Original mission: to enable computational science as a complement to magnetically controlled
Accelerated Earthquake Simulations
 Accelerated Earthquake Simulations Alex Breuer Technische Universität München Germany 1 Acknowledgements Volkswagen Stiftung Project ASCETE: Advanced Simulation of Coupled Earthquake-Tsunami Events Bavarian
Accelerated Earthquake Simulations Alex Breuer Technische Universität München Germany 1 Acknowledgements Volkswagen Stiftung Project ASCETE: Advanced Simulation of Coupled Earthquake-Tsunami Events Bavarian
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Description of Power8 Nodes Available on Mio (ppc[ ])
![Description of Power8 Nodes Available on Mio (ppc[ ])](/thumbs/93/112992376.jpg "Description of Power8 Nodes Available on Mio (ppc[ ])") Description of Power8 Nodes Available on Mio (ppc[001-002]) Introduction: HPC@Mines has released two brand-new IBM Power8 nodes (identified as ppc001 and ppc002) to production, as part of our Mio cluster.
Description of Power8 Nodes Available on Mio (ppc[001-002]) Introduction: HPC@Mines has released two brand-new IBM Power8 nodes (identified as ppc001 and ppc002) to production, as part of our Mio cluster.
Transitioning to Leibniz and CentOS 7
 Transitioning to Leibniz and CentOS 7 Fall 2017 Overview Introduction: some important hardware properties of leibniz Working on leibniz: Logging on to the cluster Selecting software: toolchains Activating
Transitioning to Leibniz and CentOS 7 Fall 2017 Overview Introduction: some important hardware properties of leibniz Working on leibniz: Logging on to the cluster Selecting software: toolchains Activating
GPU Acceleration of Matrix Algebra. Dr. Ronald C. Young Multipath Corporation. fmslib.com
 GPU Acceleration of Matrix Algebra Dr. Ronald C. Young Multipath Corporation FMS Performance History Machine Year Flops DEC VAX 1978 97,000 FPS 164 1982 11,000,000 FPS 164-MAX 1985 341,000,000 DEC VAX
GPU Acceleration of Matrix Algebra Dr. Ronald C. Young Multipath Corporation FMS Performance History Machine Year Flops DEC VAX 1978 97,000 FPS 164 1982 11,000,000 FPS 164-MAX 1985 341,000,000 DEC VAX
New User Seminar: Part 2 (best practices)
") New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
OBTAINING AN ACCOUNT:
 HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
Introduction to High Performance Computing at UEA. Chris Collins Head of Research and Specialist Computing ITCS
 Introduction to High Performance Computing at UEA. Chris Collins Head of Research and Specialist Computing ITCS Introduction to High Performance Computing High Performance Computing at UEA http://rscs.uea.ac.uk/hpc/
Introduction to High Performance Computing at UEA. Chris Collins Head of Research and Specialist Computing ITCS Introduction to High Performance Computing High Performance Computing at UEA http://rscs.uea.ac.uk/hpc/
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Using Cartesius & Lisa
 Using Cartesius & Lisa Introductory course for Cartesius & Lisa Jeroen Engelberts jeroen.engelberts@surfsara.nl Consultant Supercomputing Outline SURFsara About us What we do Cartesius and Lisa Architectures
Using Cartesius & Lisa Introductory course for Cartesius & Lisa Jeroen Engelberts jeroen.engelberts@surfsara.nl Consultant Supercomputing Outline SURFsara About us What we do Cartesius and Lisa Architectures
Lecture 3: Intro to parallel machines and models
 Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Interconnection Network for Tightly Coupled Accelerators Architecture
 Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
ECE 574 Cluster Computing Lecture 4
 ECE 574 Cluster Computing Lecture 4 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 31 January 2017 Announcements Don t forget about homework #3 I ran HPCG benchmark on Haswell-EP
ECE 574 Cluster Computing Lecture 4 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 31 January 2017 Announcements Don t forget about homework #3 I ran HPCG benchmark on Haswell-EP
NCAR s Data-Centric Supercomputing Environment Yellowstone. November 28, 2011 David L. Hart, CISL
 NCAR s Data-Centric Supercomputing Environment Yellowstone November 28, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
NCAR s Data-Centric Supercomputing Environment Yellowstone November 28, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
Job Management on LONI and LSU HPC clusters
 Job Management on LONI and LSU HPC clusters Le Yan HPC Consultant User Services @ LONI Outline Overview Batch queuing system Job queues on LONI clusters Basic commands The Cluster Environment Multiple
Job Management on LONI and LSU HPC clusters Le Yan HPC Consultant User Services @ LONI Outline Overview Batch queuing system Job queues on LONI clusters Basic commands The Cluster Environment Multiple
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
Intel Architecture for Software Developers
 Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
DATARMOR: Comment s'y préparer? Tina Odaka
 DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Introduction to High Performance Computing at UEA. Chris Collins Head of Research and Specialist Computing ITCS
 Introduction to High Performance Computing at UEA. Chris Collins Head of Research and Specialist Computing ITCS Introduction to High Performance Computing High Performance Computing at UEA http://rscs.uea.ac.uk/hpc/
Introduction to High Performance Computing at UEA. Chris Collins Head of Research and Specialist Computing ITCS Introduction to High Performance Computing High Performance Computing at UEA http://rscs.uea.ac.uk/hpc/
PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System
 (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System") INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Advanced cluster techniques with LoadLeveler
 Advanced cluster techniques with LoadLeveler How to get your jobs to the top of the queue Ciaron Linstead 10th May 2012 Outline 1 Introduction 2 LoadLeveler recap 3 CPUs 4 Memory 5 Factors affecting job
Advanced cluster techniques with LoadLeveler How to get your jobs to the top of the queue Ciaron Linstead 10th May 2012 Outline 1 Introduction 2 LoadLeveler recap 3 CPUs 4 Memory 5 Factors affecting job
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk