GPUs: The Hype, The Reality, and The Future
|
|
|
- Allan Brown
- 6 years ago
- Views:
Transcription

1 Uppsala Programming for Multicore Architectures Research Center GPUs: The Hype, The Reality, and The Future David Black- Schaffer Assistant Professor, Department of Informa<on Technology Uppsala University
2 Uppsala University / Department of Informa<on Technology 25/11/ Today 1. The hype 2. What makes a GPU a GPU? 3. Why are GPUs scaling so well? 4. What are the problems? 5. What s the Future?
3 Uppsala University / Department of Informa<on Technology 25/11/ THE HYPE
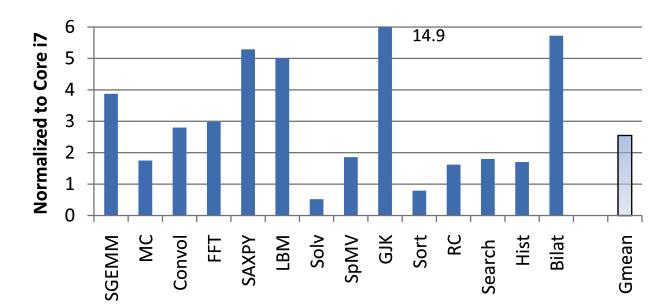



4 Uppsala University / Department of Informa<on Technology 25/11/ How Good are GPUs? 100x 3x


5 Uppsala University / Department of Informa<on Technology 25/11/ Real World SoVware Press release 10 Nov 2011: NVIDIA today announced that four leading applica<ons have added support for mul<ple GPU accelera<on, enabling them to cut simula/on /mes from days to hours. GROMACS 2-3x overall Implicit solvers 10x, PME simula<ons 1x LAMPS 2-8x for double precision Up to 15x for mixed QMCPACK 3x 2x is AWESOME! Most research claims 5-10%.


6 Uppsala University / Department of Informa<on Technology 25/11/ GPUs for Linear Algebra 5 CPUs = 75% of 1 GPU StarPU for MAGMA
 5 791 Normalized to Intel 3960X 4 3 2 1 130 244 250")

7 Uppsala University / Department of Informa<on Technology 25/11/ GPUs by the Numbers (Peak and TDP) Normalized to Intel 3960X Intel 32nm vs. 40nm 36% smaller per transistor WaEs GFLOP Bandwidth GHz Transistors Intel 3960X Nvidia GTX 580 AMD 6970

 GPUs are enormously more efficient")

8 Uppsala University / Department of Informa<on Technology 25/11/ Efficiency 4 But how close to peak do you really get? (DP, peak) GPUs are enormously more efficient designs for doing FLOPs 400 GFLOP/W FLOP/cycle/B Transistors 0 Intel 3960X GTX 580 AMD 6970 Energy Efficiency Design Efficiency 0



9 Uppsala University / Department of Informa<on Technology 25/11/ Efficiency in Perspec<ve Nvidia 4 says that ARM + Laptop GPU 7.5GFLOPS/W 3 Energy Efficiency LINPACK: Green 500 #1 Blue Gene/Q LINPACK: Green 500 #6 GPU/CPU GFLOP/W 2 1 Peak Peak Peak Actual Actual 0 Intel 3960X GTX 580 AMD 6970 Blue Gene/Q DEGIMA Cluster




10 Uppsala University / Department of Informa<on Technology 25/11/ Intel s Response Larabee Manycore x86- light to compete with Nvidia/AMD in graphics and compute Didn t work out so well (despite huge fab advantages graphics is hard) Reposi/oned it as an HPC co- processor Knight s Corner 1TF double precision in a huge (expensive) single 22nm chip At 300W this would beat Nvidia s peak efficiency today (40nm)


11 Uppsala University / Department of Informa<on Technology 25/11/ Show Me the Money Revenue in Billion USD % of this is GPU in HPC AMD Q3 Nvidia Q3 Intel Q3 Professional Graphics Embedded Processors
12 Uppsala University / Department of Informa<on Technology 25/11/ WHAT MAKES A GPU A GPU?


13 Uppsala University / Department of Informa<on Technology 25/11/ GPU Characteris<cs Architecture Data parallel processing Hardware thread scheduling High memory bandwidth Graphics rasteriza<on units Limited caches (with texture filtering hardware) Programming/Interface Data parallel kernels Throughput- focused Limited synchroniza<on Limited OS interac<on
14 Uppsala University / Department of Informa<on Technology 25/11/ GPU Innova<ons SMT (for latency hiding) Massive numbers of threads Programming SMT is far easier than SIMD SIMT (thread groups) Amor<ze scheduling/control/data access Warps, wavefronts, work- groups, gangs Memory systems op/mized for graphics Special storage formats Texture filtering in the memory system Bank op<miza<ons across threads Limited synchroniza/on Improves hardware scalability (They didn t invent any of these, but they made them successful.)
15 Uppsala University / Department of Informa<on Technology 25/11/ WHY ARE GPUS SCALING SO WELL?
 Lack of OS- level issues Memory alloca<on")
16 Uppsala University / Department of Informa<on Technology 25/11/ Lots of Room to Grow the Hardware Simple cores Short pipelines No branch predic<on In- order Simple memory system Limited caches* No coherence Split address space* 1600 Simple control Limited context switching Limited processes (But do have to schedule 1000s of threads ) Lack of OS- level issues Memory alloca<on Preemp<on But, they do have a lot TLBs for VM I- caches Complex hardware thread schedulers Trading off simplicity for features and programmability. 400 GFLOPs (SP) Bandwidth (GB/s) FLOP/cycle FLOP/cycle/B Transistors 0 G80 GT200 GF G80 GT200 GF100 0 GFLOP (SP) Bandwidth Architecture Efficiency Design Efficiency

; data[id] = sin(data[id]); } Expensive Synchronization OK.! No Synchronization.! Easy to scale!")
17 Uppsala University / Department of Informa<on Technology 25/11/ Nice Programming Model All GPU programs have: Explicit parallelism Hierarchical structure Restricted synchroniza<on Data locality Inherent in graphics Enforced in compute by performance Latency tolerance void kernel calcsin(global float *data) { int id = get_global_id(0); data[id] = sin(data[id]); } Expensive Synchronization OK.! No Synchronization.! Easy to scale! Cheap
18 Uppsala University / Department of Informa<on Technology 25/11/ Why are GPUs Scaling So Well? Room in the hardware design Scalable sovware They re not burdened with 30 years of cru6 and legacy code lucky them.
19 Uppsala University / Department of Informa<on Technology 25/11/ WHERE ARE THE PROBLEMS?
20 Uppsala University / Department of Informa<on Technology 25/11/ Amdahl s Law Always have serial code GPU single threaded performance is terrible Solu/on: Heterogeneity A few fat latency- op/mized cores Many thin throughput- op/mized cores Plus hard- coded accelerators Nvidia Project Denver ARM for latency GPU for throughput AMD Fusion x86 for latency GPU for throughput Intel MIC x86 for latency X86- light for throughput Maximum Speedup Number of Cores Limits of Amdahl s Law 99% Parallel (91x) 90% Parallel (10x) 75% Parallel (4x)
21 Uppsala University / Department of Informa<on Technology 25/11/ It s an Accelerator Moving data to the GPU is slow Moving data from the GPU is slow Moving data to/from the GPU is really slow. Limited data storage Limited interac<on with OS GRAM 1.5GB 192GB/s GPU Nvidia GTX mm 2 5 GB/s PCIe GB/s CPU Intel 3960X 435mm 2 51GB/s DRAM 16GB


22 Uppsala University / Department of Informa<on Technology 25/11/ Legacy Code Code lives forever Amdahl: Even op<mizing the 90% of hot code limits speedup to 10x Many won t invest in proprietary technology Programming models are immature CUDA mature low- level Nvidia, PGI OpenCL immature low- level Nvidia, AMD, Intel, ARM, Altera, Apple OpenHMPP mature high- level CAPS OpenACC immature high- level CAPS, Nvidia, Cray, PGI
23 Uppsala University / Department of Informa<on Technology 25/11/ Code that Doesn t Look Like Graphics If it s not painfully data- parallel you have to redesign your algorithm Example: scan- based techniques for zero coun<ng in JPEG Why? It s only 64 entries! Single- threaded performance is terrible. Need to parallelize. Overhead of transferring data to CPU is too high. If it s not accessing memory well you have to re- order your algorithm Example: DCT in JPEG Need to make sure your access to local memory has no bank conflicts across threads. Libraries star/ng to help Lack of composability Example: Combining linear algebra opera<ons to keep data on the device Most code is not purely data- parallel Very expensive to synchronize with the CPU (data transfer) No effec<ve support for task- based parallelism No ability to launch kernels from within kernels
24 Uppsala University / Department of Informa<on Technology 25/11/ Corollary: What are GPUs Good For? Data parallel code Lots of threads Easy to express parallelism (no SIMD nas<ness) High arithme/c intensity and simple control flow Lots of FPUs No branch predictors High reuse of limited data sets Very high bandwidth to memory (1-6GB) Extremely high bandwidth to local memory (16-64kB) Code with predictable access paeerns Small (or no) caches User- controlled local memories
25 Uppsala University / Department of Informa<on Technology 25/11/ WHAT S THE FUTURE OF GPUS?
, operating points provided by current mobile platforms with a single application processor to allow the OS to")




26 In the big.little task migration use model the OS and applications only ever execute on Cortex-A15 or Cortex-A7 and never both processors at the same time. This use-model is a natural extension to the Dynamic Voltage and Frequency Scaling (DVFS), operating points provided by current mobile platforms with a single application processor to allow the OS to match the performance of the platform 25/11/2011 2to 7 the Uppsala University / Department of Informa<on Technology performance required by the application. David Black- Schaffer! However, in a Cortex-A15-Cortex-A7 platform these operating points are applied both to Cortex-A15 and Cortex-A7. When Cortex-A7 is executing the OS can tune the operating points as it would for an existing platform with a single applications processor. Once Cortex-A7 is at its highest operating point if more Introduction performance is required a task migration can be invoked!that picks up the OS and applications and The range of performance being demanded from modern, high-performance, mobile platforms is moves them to Cortex-A15. Heterogeneity for Efficiency unprecedented. Users require platforms to be accomplished at high processing intensity tasks such as gaming and web browsing while providing long battery life for low processing intensity tasks such as texting,applications and audio. to be executed on Cortex-A7 with better energy This allows low and medium intensity efficiency than Cortex-A15 can achieve the high applications characterize today s Cortex -A15 that processor is paired with a LITTLE In the first while big.little system fromintensity ARM a big ARM Queue Issue Cortex -A7 processor to Writeback create a system that can accomplish both high intensity and low intensity tasks smartphones can execute on Cortex-A15. in the most energy efficient manner. By coherently connecting the Cortex-A15 and Cortex-A7 processors Integer Fetch No way around it in sight Specialize to get beeer efficiency Integer via the CCI-400 coherent interconnect the system is flexible enough to support a variety of big.little use models, which can be tailored to the processing requirements of the tasks. Multiply Decode, Rename & Dispatch Floating-Point / NEON The Processors Branch Loop Cache Figure 2 Cortex-A15 Pipeline Load of big.little is that the processors are architecturally identical. Both Cortex-A15 and The central tenet Store Cortex-A7 implement the full ARM v7a architecture including Virtualization and Large Physical Address Extensions. Accordingly all instructions will execute in an architecturally consistent way on both CortexA15 and Cortex-A7, albeit with different performances. The implementation defined of feature set of Cortex-A15 and Cortex-A7 is also similar. Both processors can Since the energy consumed by the execution of an instruction is partially related to the number pipeline be configured have between one and four cores and both integrate a level-2 cache inside the stages it must traverse, a significant difference in energy between Cortex-A15 andtocortex-a7 comes from processing cluster. Additionally, each processor implements a single AMBA 4 coherent interface that the different pipeline lengths. can be connected to a coherent interconnect such as CCI-400. In general, there is a different ethos taken in the Cortex-A15 micro-architecture than with the Cortex-A7 It is in the micro-architectures that the differences between Cortex-A15 and Cortex-A7 become clear. micro-architecture. When appropriate, Cortex-A15 trades off energy efficiency for performance, while While Cortex-A7 1) is an in-order, non-symmetric dual-issue processor with a pipeline length of Cortex-A7 will trade off performance for energy efficiency. A good example of these(figure micro-architectural between 8-stages and 10-stages, trade-offs is in the level-2 cache design. While a more area optimized approach would have been to Cortex-A15 (Figure 2) is an out-of-order sustained triple-issue processor with a pipeline length from of between 15-stages and 24-stages. share a single level-2 cache between Cortex-A15 and Cortex-A7 this part of the design can benefit optimizations in favor of energy efficiency or performance. As such Cortex-A15 and Cortex-A7 have Writeback integrated level-2 caches. Integer This is why GPUs are more efficient today Heterogeneous mixes Throughput- oriented thin cores Latency- focused fat cores Fixed- func/on accelerators Video, audio, network, etc. Already in OpenCL 1.2 Table 1 illustrates the difference in performance and energy between Cortex-A15 and Cortex-A7 across a variety of benchmarks and micro-benchmarks. The first column describes the uplift in performance from Cortex-A7 to Cortex-A15, while the second column considers both the performance and power difference Lowest Decode Issue Cortexto show the improvement in energy efficiency from Cortex-A15 to Cortex-A7. All measurements are on A15 complete, frequency optimized layouts of Cortex-A15 and Cortex-A7 using the same cell and RAM Operati libraries. All code that is executed on Cortex-A7 is compiled for Cortex-A15. ng PointFe tch Dhrystone FDCT IMDCT MemCopy L1 MemCopy L2 Cortex-A15 vs Cortex-A7 Performance 1.9x 2.3x 3.0x 1.9x 1.9x Cortex-A7 vs Cortex-A15 Energy Efficiency 3.5x 3.8x 3.0x 2.3x 3.4x Multiply Floating-Point / NEON Dual Issue Load/Store Queue Figure 1 Cortex-A7 Pipeline ARM big.little Figure 4 Cortex-A15-Cortex-A7 DVFS Curves Table 1 Cortex-A15 & Cortex-A7 Performance & Energy Comparison 2011 ARM Limited. All rights reserved. An important consideration of a big.little system iscopyright the time it takes to migrate a task between the Cortex-A15 cluster and the Cortex-A7 cluster. If it takes too long then it may become noticeable to the operating system and the system power may outweigh the benefit of task migration for some time. Therefore, the Cortex-A15-Cortex-A7 system is designed to migrate in less than 20,000-cycles, or 20microSeconds with processors operating at 1GHz. Copyright 2011 ARM Limited. All rights reserved. It should be observed from Table 1 that although Cortex-A7 is labeled the LITTLE processor its The ARM logo is a registered trademark of ARM Ltd. All other trademarks are the property of their respective owners and are acknowledged performance potential is considerable. In fact, due to micro-architecture advances Cortex-A7 provides Page 2 of 8 higher performance than current Cortex-A8 based implementations for a fraction of the power. As such a significant amount of processing can remain on Cortex-A7 without resorting to Cortex-A15. The ARM logo is a registered trademark of ARM Ltd. All other trademarks are the property of their respective owners and are acknowledged Page 3 of 8 Copyright 2011 ARM Limited. All rights reserved. The ARM logo is a registered trademark of ARM Ltd. All other trademarks are the property of their respective owners and are acknowledged Page 5 of 8 Dark silicon OS/run<me/app will have to adapt Energy will be a shared resource Nvidia Tegra 3: 4 fast cores + 1 slow core


27 Uppsala University / Department of Informa<on Technology 25/11/ The Future is Not in Accelerators Memory Unified memory address space Low performance coherency High performance scratchpads OS interac/on between all cores Nvidia Project Denver ARM for latency GPU for throughput AMD Fusion x86 for latency GPU for throughput Intel MIC x86 for latency X86- light for throughput Shared I/O GPU Cores CPU CPU CPU CPU AMD Fusion
 1,600 1,400 1,200 1,000 800 600 400 200 Single- precision performance Double- precision performance Memory bandwidth Single-precision")
28 Uppsala University / Department of Informa<on Technology 25/11/ Focus on Data Locality Floating-point performance (Gflops) 1,600 1,400 1,200 1, Single- precision performance Double- precision performance Memory bandwidth Single-precision performance Double-precision performance Memory bandwidth Requires 2x bandwidth and storage 1,600 1,400 1,200 1, Memory bandwidth (Gbytes/sec.) S. Keckler, et. al. GPUs and the Future of Parallel Compu<ng. IEEE Micro, Sept/Oct Figure 1. GPU processor and memory-system performance trends. Initially, memory bandwidth nearly doubled every two years, but this trend has slowed over the past few years. On-die GPU performance has continued to grow at about 45 percent per year for
29 Uppsala University / Department of Informa<on Technology 25/11/ Focus on Data Locality Not just on- chip/off- chip but within a chip Sooware controllable memories Configure for cache/scratch pad Enable/disable coherency Programmable DMA/prefetch engines Program must expose data movement/locality Explicit informa<on to the run<me/compiler Auto- tuning, data- flow, op<miza<on But we will have global coherency to get code correct (See the Micro paper GPUs and the Future of Parallel Compu<ng from Nvidia about their Echelon project and design.)
30 Uppsala University / Department of Informa<on Technology 25/11/ Graphics will (s<ll) be a Priority It s where the money is Fixed- func<on graphics units Memory- system hardware for texture interpola<on will live forever Half- precision floa<ng point will live forever (And others else might actually use it. Hint hint.)
31 Uppsala University / Department of Informa<on Technology 25/11/ CONCLUSIONS
32 Uppsala University / Department of Informa<on Technology 25/11/ Breaking Through The Hype Real efficiency advantage Intel is pushing hard to minimize it Much larger for single precision Real performance advantage About 2-5x But you have to re- write your code The market for GPUs is /ny compared to CPUs Everyone believes that specializa/on is necessary to tackle energy efficiency
33 Uppsala University / Department of Informa<on Technology 25/11/ The Good, The Bad, and The Future The Good: Limited domain allows more efficient implementa<on Good choice of domain allows good scaling The Bad: Limited domain focus makes some algorithms hard They are not x86/linux (legacy code) The Future: Throughput- cores + latency- cores + fixed accelerators Code that runs well on GPUs today will port well We may share hardware with the graphics subsystem, but we won t program GPUs Uppsala Programming for Multicore Architectures Research Center
Big.LITTLE Processing with ARM Cortex -A15 & Cortex-A7
 Big.LITTLE Processing with ARM Cortex -A15 & Cortex-A7 Improving Energy Efficiency in High-Performance Mobile Platforms Peter Greenhalgh, ARM September 2011 This paper presents the rationale and design
Big.LITTLE Processing with ARM Cortex -A15 & Cortex-A7 Improving Energy Efficiency in High-Performance Mobile Platforms Peter Greenhalgh, ARM September 2011 This paper presents the rationale and design
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
GPU Background. GPU Architectures for Non-Graphics People. David Black-Schaffer David Black-Schaffer 1
 GPU Architectures for Non-Graphics People GPU Background David Black-Schaffer david.black-schaffer@it.uu.se David Black-Schaffer 1 David Black-Schaffer 2 GPUs: Architectures for Drawing Triangles Fast!
GPU Architectures for Non-Graphics People GPU Background David Black-Schaffer david.black-schaffer@it.uu.se David Black-Schaffer 1 David Black-Schaffer 2 GPUs: Architectures for Drawing Triangles Fast!
Each Milliwatt Matters
 Each Milliwatt Matters Ultra High Efficiency Application Processors Govind Wathan Product Manager, CPG ARM Tech Symposia China 2015 November 2015 Ultra High Efficiency Processors Used in Diverse Markets
Each Milliwatt Matters Ultra High Efficiency Application Processors Govind Wathan Product Manager, CPG ARM Tech Symposia China 2015 November 2015 Ultra High Efficiency Processors Used in Diverse Markets
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor.
 on a single die. Also called a chip-multiprocessor.") CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Graphics Processor Acceleration and YOU
 Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Integrating CPU and GPU, The ARM Methodology. Edvard Sørgård, Senior Principal Graphics Architect, ARM Ian Rickards, Senior Product Manager, ARM
 Integrating CPU and GPU, The ARM Methodology Edvard Sørgård, Senior Principal Graphics Architect, ARM Ian Rickards, Senior Product Manager, ARM The ARM Business Model Global leader in the development of
Integrating CPU and GPU, The ARM Methodology Edvard Sørgård, Senior Principal Graphics Architect, ARM Ian Rickards, Senior Product Manager, ARM The ARM Business Model Global leader in the development of
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Amber Baruffa Vincent Varouh
 Amber Baruffa Vincent Varouh Advanced RISC Machine 1979 Acorn Computers Created 1985 first RISC processor (ARM1) 25,000 transistors 32-bit instruction set 16 general purpose registers Load/Store Multiple
Amber Baruffa Vincent Varouh Advanced RISC Machine 1979 Acorn Computers Created 1985 first RISC processor (ARM1) 25,000 transistors 32-bit instruction set 16 general purpose registers Load/Store Multiple
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
ECE 574 Cluster Computing Lecture 18
 ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
EE 7722 GPU Microarchitecture. Offered by: Prerequisites By Topic: Text EE 7722 GPU Microarchitecture. URL:
 00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
ECSE 425 Lecture 25: Mul1- threading
 ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
Multimedia in Mobile Phones. Architectures and Trends Lund
 Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Arm s Latest CPU for Laptop-Class Performance
 Arm s Latest CPU for Laptop-Class Performance 2018 Arm Limited Aditya Bedi Arm Tech Symposia India Untethered. Connected. Immersive. Innovation continues to drive growth and performance demands on our
Arm s Latest CPU for Laptop-Class Performance 2018 Arm Limited Aditya Bedi Arm Tech Symposia India Untethered. Connected. Immersive. Innovation continues to drive growth and performance demands on our
CSC573: TSHA Introduction to Accelerators
 CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
CPU Architecture Overview. Varun Sampath CIS 565 Spring 2012
 CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
Chapter 5. Introduction ARM Cortex series
 Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
THE FUTURE OF GPU DATA MANAGEMENT. Michael Wolfe, May 9, 2017
 THE FUTURE OF GPU DATA MANAGEMENT Michael Wolfe, May 9, 2017 CPU CACHE Hardware managed What data to cache? Where to store the cached data? What data to evict when the cache fills up? When to store data
THE FUTURE OF GPU DATA MANAGEMENT Michael Wolfe, May 9, 2017 CPU CACHE Hardware managed What data to cache? Where to store the cached data? What data to evict when the cache fills up? When to store data
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
GPU Cluster Computing. Advanced Computing Center for Research and Education
 GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
Administrivia. HW0 scores, HW1 peer-review assignments out. If you re having Cython trouble with HW2, let us know.
 Administrivia HW0 scores, HW1 peer-review assignments out. HW2 out, due Nov. 2. If you re having Cython trouble with HW2, let us know. Review on Wednesday: Post questions on Piazza Introduction to GPUs
Administrivia HW0 scores, HW1 peer-review assignments out. HW2 out, due Nov. 2. If you re having Cython trouble with HW2, let us know. Review on Wednesday: Post questions on Piazza Introduction to GPUs
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
ECE 571 Advanced Microprocessor-Based Design Lecture 22
 ECE 571 Advanced Microprocessor-Based Design Lecture 22 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 19 April 2018 HW#11 will be posted Announcements 1 Reading 1 Exploring DynamIQ
ECE 571 Advanced Microprocessor-Based Design Lecture 22 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 19 April 2018 HW#11 will be posted Announcements 1 Reading 1 Exploring DynamIQ
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
Lecture 27: Multiprocessors. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs
 GPUs") Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Energy Efficient Transparent Library Accelera4on with CAPI Heiner Giefers IBM Research Zurich
 Energy Efficient Transparent Library Accelera4on with CAPI Heiner Giefers IBM Research Zurich Revolu'onizing the Datacenter Datacenter Join the Conversa'on #OpenPOWERSummit Towards highly efficient data
Energy Efficient Transparent Library Accelera4on with CAPI Heiner Giefers IBM Research Zurich Revolu'onizing the Datacenter Datacenter Join the Conversa'on #OpenPOWERSummit Towards highly efficient data
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 1. Copyright 2012, Elsevier Inc. All rights reserved. Computer Technology
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated