ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape
|
|
|
- Buck Austin
- 5 years ago
- Views:
Transcription







: our 2D detections, 3D boxes, and meshed shapes inferred from a single monocular image in one forward pass.")
1 ROI-D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape Fabian Manhardt TU Munich Wadim Kehl Toyota Research Institute Adrien Gaidon Toyota Research Institute Abstract We present a deep learning method for end-to-end monocular 3D object detection and metric shape retrieval. We propose a novel loss formulation by lifting 2D detection, orientation, and scale estimation into 3D space. Instead of optimizing these quantities separately, the 3D instantiation allows to properly measure the metric misalignment of boxes. We experimentally show that our D lifting of sparse 2D Regions of Interests (RoIs) achieves great results both for 6D pose and recovery of the textured metric geometry of instances. This further enables 3D synthetic data augmentation via inpainting recovered meshes directly onto the 2D scenes. We evaluate on KITTI3D against other strong monocular methods and demonstrate that our approach doubles the AP on the 3D pose metrics on the official test set, defining the new state of the art.. Introduction How much can one understand a scene from a single color image? Using large annotated datasets and deep neural networks, the Computer Vision community has steadily pushed the envelope of what was thought possible, not just for semantic understanding but also in terms of 3D properties of scenes and objects. In particular, Deep learning methods on monocular imagery have proven competitive with multi-sensor approaches for important ill-posed inverse problems like 3D object detection ([3, 3, 2, 34, 24], 6D pose tracking [3, 4], depth prediction [9,, 3, 42, 33], or shape recovery [8, 23]. These improvements have been mainly accomplished by incorporating strong implicit or explicit priors that regularize the underconstrained output space towards geometrically-coherent solutions. Furthermore, these models benefit directly from being end-toend trainable in general. This leads to increased accuracy, since networks are discriminatively tuned towards the target The first two authors contributed equally to this work. This work was part of an internship stay at TRI. Figure : Top (from left to right): our 2D detections, 3D boxes, and meshed shapes inferred from a single monocular image in one forward pass. Middle: our predictions on top of a LIDAR point cloud, demonstrating metric accuracy. Bottom: example well-localized, metrically-accurate, textured meshes predicted by our network. objective instead of intermediate outputs followed by nontrainable post-processing heuristics. The main challenge, though, is to design a model and differentiable loss function that lend itself to well-behaved minimization. In this work we introduce a new end-to-end method for metrically accurate monocular 3D object detection, i.e. the task of predicting the location and extent of objects in 3D using a single RGB image as input. Our key idea is to regress oriented 3D bounding boxes by lifting predicted 2D Regions of Interest (RoIs) using a monocular depth network. Our main contributions are:
2 an end-to-end multi-scale deep network for monocular 3D object detection, including a differentiable 2D to 3D RoI lifting map that internally regresses all required components for 3D box instantiation; a loss function that aligns those 3D boxes in metric space, directly minimizing their error with respect to ground truth 3D boxes; an extension of our model to predict metric textured meshes, enabling further 3D reasoning, including 3Dcoherent synthetic data augmentation. We call our method ROI-D, as it lifts 2D regions of interests to 3D for prediction of 6 degrees of freedom pose (rotation and translation), 3 DoF spatial extents, and or more DoF shape. Experiments on the KITTI3D [2] benchmarks show that our approach enables accurate predictions from a single RGB image. Furthermore, we show that our monocular 3D poses are competitive or better than the state of the art. 2. Related Work Since the amount of work on object detection has expanded significantly over the last years, we will narrow our focus to recent advances among RGB-based methods for 3D object detection. 3DOP from Chen et al. [4] use KITTI [2] stereo data and additional scene priors to create 3D object proposals followed by a CNN-based scoring. In their follow-up work Mono3D [3], the authors replace the stereobased priors by exploiting various monocular counterparts such as shape, segmentation, location, and spatial context. Mousavian et al. [3] propose to couple single-shot 2D detection with an additional binning of azimuth orientations plus offset regression. Similarly, SSD-6D from Kehl et al. [2] introduces a structured discretization of the full rotational space for single-shot 6D pose estimation. The work from Xu et al. [4] incorporates a monocular depth module to further boost the accuracy of inferred poses on KITTI. Instead of discretizing SO(3), [34, 37] formulate the 6D estimation problem as a regression of the 2D projections of the 3D bounding box. These methods assume the scale of the objects to be known and can therefore use a perspectiven-point (PnP) variant to recover poses from 2D-3D correspondences. Grabner et al. [4] present a mixed approach where they regress 2D control points and absolute scale to recover pose and, subsequently, the object category. In addition, Rad et al. [34] empirically show the superiority of this proxy loss over standard regression of the 6 degrees of freedom. In contrast, [4, 24, 3] directly encode the 6D pose. In particular, Xiang et al. [4] first regress the rotation as Euler angles and the 3D translation as the backprojected 2D centroid. Thereafter, they transform the 3D mesh into the camera frame and measure the average distance of the model points [6] towards the ground truth. Similarly, [24] also minimizes the average distance of model points for 6D pose refinement. Manhardt et al. [3] also conduct 6D pose refinement but regress a 4D update quaternion to describe the 3D rotation. Their proxy loss samples and transforms 3D contour points to maximize projective alignment. Notably, all these direct encoding methods require knowledge of the precise 3D model. However, when working at a category-level the 3D models are usually not available, and these approaches are not designed to handle intraclass 3D shape variations (for instance between different types of cars). We therefore propose a more robust way of lifting to 3D that only requires bounding boxes. Thereby, the extents of these bounding boxes can also be of variable size. Similar to us, [7] use RoIs to lift 2D detections, but their pipeline is not trained end-to-end and reliant on RGB- D input for 3D box instantiation. In terms of monocular shape recovery, 3D-RCNN from Kundu et al. [23] uses an RPN to estimate the orientation and shape of cars on KITTI with a render-and-compare loss. Kanazawa et al. [8] predict instance shape, texture, and camera pose using a differentiable mesh renderer [9]. While these methods show very impressive results as part of their synthesis error minimization, they recover shapes only up to scale. Furthermore, our approach does not require differentiable rendering or approximations thereof. 3. Monocular lifting to D for pose and shape In this section we describe our method of detecting objects in 2D space and consequently, computing their 6D pose and metric shape from a single monocular image. First, we give an overview of our network architecture. Second, we explain how we lift the loss computation to 3D in order to improve pose accuracy. Third, we describe our learned metric shape space and its use for 3D reconstruction from estimated shape parameters. Finally, we describe how our shape estimation enables 3D-coherent data augmentation to improve detection. 3.. End-to-end Monocular Architecture Our architecture (Figure 2) follows a two-stage approach, similar to Faster R-CNN [36], where we first produce 2D region proposals and then run subsequent predictions for each. For the first stage we employ a RetinaNet [26] that uses a ResNet-34 backbone with FPN structure [25] and focal loss weighting. For each detected and precise 2D object proposal, we then use the RoIAlign operation [5] to extract localized features for each region. In contrast to the aforementioned related works, we do not directly regress 3D information independently for each proposal from these localized features. Predicting this information from monocular data, in particular absolute translation, is ill-posed due to scale and reprojection ambigui- 2
 to extract fused feature maps from the ResNet-FPN and depth network via a RoIAlign operation before regressing 3D bounding boxes, a process we call RoI")

3 Figure 2: We process our input image with a ResNet-FPN architecture for 2D detection and a monocular depth prediction network. We use the predicted Regions of Interest (RoI) to extract fused feature maps from the ResNet-FPN and depth network via a RoIAlign operation before regressing 3D bounding boxes, a process we call RoI lifting. ties, which the lack of context exacerbates. In contrast, networks that aim to predict global depth information over the whole scene can overcome these ambiguities by leveraging geometric constraints as supervision []. Consequently, we use a parallel stream based on the state-of-the-art SuperDepth network [33], which predicts per-pixel depth from the same monocular image. We use these predicted depth maps to support distance reasoning in the subsequent 3D lifting part of our network. Besides the aforementioned localized feature maps from our 2D RPN, we also want to include the corresponding regions in the predicted depth map. For better localization accuracy, we furthermore decided to include a 2D coordinates map [27]. We thus propagate all the information to our fusion module, which consists of two convolutional layers with Group Normalization [39] for each input modality. Finally, we concatenate all features, use RoIAlign and run into separate branches for the regression of 3D rotation, translation, absolute (metric) extents, and object shape, as described in the following sections From Monocular 2D Instance to 6D Pose Formally, our approach towards the problem is to define a fully-differentiable lifting mapping F : R 4 R 8 3 from a 2D RoI X to a 3D box B := {B,..., B 8 } of eight ordered 3D points. We chose to encode the rotation as a 4D quaternion and the translation as the projective 2D object centroid (similar to [3, 2, 4]) together with the associated depth. In addition, we describe the 3D extents as the deviation from the mean extents over the whole data set. Given RoI X, our lifting F(X ) runs RoIAlign at that position, followed by separate prediction heads to recover rotation q, RoI-relative 2D centroid (x, y), depth z and metric extents (w, h, l). From this we build the 8 corners B i : B i := q ±w/2 ±h/2 q + K x z y z () ±l/2 z with K being the inverse camera intrinsics. We build the Figure 3: Our lifting F regresses all components to estimate a 3D box B (blue). From here, our loss minimizes the pointwise distances towards the ground truth B (red). We visualize three of the eight correspondences in green. points B i in a defined order to preserve absolute orientation. We depict the instantiation in Figure 3. Our formulation is reminiscent of 3D anchoring (as MV3D [5], AVOD [22]). However, our 2D instantiation of those 3D anchors is sparse and works over the whole image plane. While such 3D anchors explicitly provide the object s 3D location, our additional degree of freedom also requires the estimation of the depth. Lifting Pose Error Estimation to 3D When estimating the pose from monocular data only, little deviations in pixelspace can induce big errors in 3D. Additionally, penalizing each term individually can lead to volatile optimization and is prone to suboptimal local minima. We propose to lift the problem to 3D and employ a proxy loss describing the full 6D pose. Consequently, we do not force to optimize all terms equally at the same time, but let the network decide its focus during training. Given a ground truth 3D box B := {B,..., B8} and its associated 2D detection X in the image, we run our lifting map to retrieve the 3D predic- 3
 = B.")
 We depict some of the 3D-3D correspondences that the loss is aligning as green lines in Figure 3.")
![When deriving the loss, the chain rule leads to [ F(X ), F(X ) q (x, y), F(X ) ] F(X ) L( ), z (w, l, h) F(X ) L( ) (3) and shows clearly the individual impact that each lifting component contributes](/docs-images/95/124910722/images/4-2.jpg "towards 3D alignment. Similar to work that employ projective or geometric constraints [29, 3], we observe that we require a warm-up period to bring regression into proper numerical regimes.")

4 Figure 4: Comparison between egocentric (top) and allocentric (bottom) poses. While egocentric poses undergo viewpoint changes towards the camera when translated, allocentric poses always exhibit the same view, independent of the object s location. tion F(X ) = B. The loss itself is the mean over the eight corner distances in metric space: L(F(X ), B ) = 8 i {..8} F(X ) i B i. (2) We depict some of the 3D-3D correspondences that the loss is aligning as green lines in Figure 3. When deriving the loss, the chain rule leads to [ F(X ), F(X ) q (x, y), F(X ) ] F(X ) L( ), z (w, l, h) F(X ) L( ) (3) and shows clearly the individual impact that each lifting component contributes towards 3D alignment. Similar to work that employ projective or geometric constraints [29, 3], we observe that we require a warm-up period to bring regression into proper numerical regimes. We therefore train with separate terms until we reach a stable 3D box instantiation and switch then to our lifting loss. We also want to stress that our parametrization allows for general 6D pose regression. Although the object annotations in KITTI3D exhibit only changing azimuths, many driving scenarios and most robotic use cases require solving for all 6 degrees of freedom. Allocentric Regression and Egocentric Lifting Multiple works [3, 23] emphasize the importance of estimating the allocentric pose for monocular data, especially for larger fields of view. The difference is depicted in Figure 4 where the relative object translation with respect to the camera changes the observed viewpoint. Accordingly, we follow the same principle since RoIs lose the global context. Therefore, rotations q are considered allocentric during regression inside F and then corrected with the inferred translation to build the egocentric 3D boxes Object Shape Learning & Retrieval In this section we explain how we extend our end-toend monocular 3D object detection method to additionally predict meshes and how to use them for data augmentation. Figure 5: Top: Median of each category in the learned shape space. Bottom: Smooth interpolation on the latent hypersphere between two categories. Learning of a Smooth Shape Space Given a set of CAD models of cars, we created projective truncated signed distances fields (TSDF) φ i and initially used PCA to learn a low-dimensional shape, similar to [23]. During experimentation we found the shape space to be quickly discontinuous away from the mean, inducing degenerated meshes. Using PCA to generate proper shapes requires to evaluate each dimension according to its standard deviation. To avoid this tedious process, we instead switched to a 3D convolutional autoencoder, consisting of encoder E as well as decoder D, and enforced different constraints on the output TSDF. In particular, we map all latent representations on the unit hypersphere to ensure smoothness within the embedding. Furthermore, we penalize jumps in the output level set via total variation, which regularizes towards smoother surfaces. The final loss is the sum of all these components: L tsdf (E, D, φ) = D(E(φ)) φ + ( E(φ) ) + D(E(φ)) We additionally classified each CAD model as either Small,, Large or SUV. Afterwards, we computed the median shape over each class, and all cars together, using the Weiszfeld algorithm [38], as illustrated in Fig. 5 (top). Below, we show our ability to smoothly interpolate between the median shapes in the embedding. We observed that we could safely traverse all intermediate points on the embedding without degenerate shapes and found a six-dimensionsal latent space to be a good compromise between smoothness and detail. Ground truth shape annotation. To avoid gradient approximation through central differences as [23], we labeled the KITTI3D car instances offline. Running greedy search initialized from every median, we seek for the minimal projective discrepancy in LIDAR and segmentation from [5]. For the shape branch of our 3D lifter, we measure the similarity between predicted shape s and ground truth shape (4) 4
 = arccos ( 2 s, s 2 ) (5) During inference we predict the low-dimensional latent vector and feed it to the decoder to obtain its TSDF representation.")
5 s as the angle between the two points on the hypersphere. L shape (s, s ) = arccos ( 2 s, s 2 ) (5) During inference we predict the low-dimensional latent vector and feed it to the decoder to obtain its TSDF representation. We can also compute the 3D mesh from the TSDF employing marching cubes [28]. Simple mesh texturing. Since our method computes absolute scale and 6D pose, we conduct projective texturing of the retrieved 3D mesh. To this end, we project each vertex that faces towards the camera onto the image plane and assign the corresponding pixel value. Afterwards, we mirror the colors along the symmetry axis for completion Synthetic 3D data augmentation Since annotating monocular data with metrically accurate 3D annotations is usually costly and difficult, many recent works leverage synthetic data [, 8, 2, ] to train their methods [2, 7, 35]. Nevertheless, this often comes with a significant drop in performance due to the domain gap. This is especially true for KITTI3D, since it is a very small dataset with only around 7k images (or 3.5k images for train and val respectively with the split from [3]). This can easily result in severe overfitting to the training data distribution. An interesting solution to this domain gap, proposed by Alhaija et al. [], consists in extending the dataset by inpainting 3D synthetic renderings of objects onto real-world image backgrounds. Inspired by this Augmented Reality type of approach, we propose to utilize our previously extracted meshes in order to produce realistic renderings. This allows for increased realism and diversity, in contrast to using a small set of fixed CAD models as in []. Furthermore, we do not use strong manual or map priors to place the synthetic objects in the scene. Instead, we employ the allocentric pose to move the object in 3D without changing the viewpoint. We apply some rotational perturbations in 3D to generate new unseen poses and decrease overfitting. Fig. 6 illustrates one synthetically generated training sample. While the red bounding boxes show the original ground truth annotations, the green bounding boxes depict the synthetically added cars and their sampled 6D pose Implementation details The method was implemented in PyTorch [32] and we employed AWS p3.6xlarge instances for training. We used SGD with momentum, a batch size of 8 and a learning rate of. with linear warm-up. We ran a total of 2k iterations and decayed the learning rate after 2k and 8k steps by.. We employed both scale-jittering and horizontal flipping to augment the dataset. For the synthetic car augmentations, we extracted in total 4 meshes from Figure 6: Synthetically generated training sample. Top: Green bounding boxes show original ground truth cars and poses. In contrast, red boxes illustrate the rendered meshes from a sampled 6D pose. Bottom: Augmented depth map from SuperDepth [33]. Notice that we utilized the annotated meshes, which we colored using the ground truth pose and our projective texturing. the training sequences, which we textured using the corresponding ground truth poses. We then augmented each input sample with up to 3 different cars by shooting rays in random directions and sampling a 3D translation along the ray. Additionally, we employed the original allocentric rotation to avoid textural artifacts, however, perturbed the rotations up to degrees in order to always produce new unseen 6D poses. Our shape space is six-dimensional although smaller dimensionality can lead to well-behaving spaces, too. We show qualitative results in the supplement. During testing, we resize the shorter side of the image to 6 and run 2D detection. We filter the detections with 2D- NMS at 5 before RoI-lifting. The resulting 3D boxes are then processed by a very strict bird s eye view-nms at.5 that prevents physical intersections. 4. Evaluation In this section, we describe our evaluation protocol, compare to the state of the art for RGB-based approaches, and provide an ablative analysis discussing the merits of our individual contributions. 4.. Evaluation Protocol We use the standard KITTI3D benchmark [2] and its official evaluation metrics. We evaluate our method on three different difficulties: easy, moderate, hard. Furthermore, as suggested we also set the IoU threshold to.7 for both 2D and 3D. For the pose, we compute the average precision (AP) in the Bird s eye view, which measures the overlap of the 3D bounding boxes projected on the ground plane. We also compute the AP for the full 3D bounding box. 5
6 Method Type Bird Eye View AP [val / test] 3D Detection AP [val / test] Mono3D [3] Mono 5.22 / 5.9 / 4.3 / 2.53 / 2.3 / 2.3 / 3DOP[4] Stereo 2.63 / 9.49 / 7.59 / 6.55 / 5.7 / 4. / Xu et al. [4] Mono 22.3 / / / / / / 4.68 ROI-D Mono 4.76 / / /.39 5 / / / 9.39 Table : 3D detection performance on KITTI3D validation [3] and official KITTI3D test set. We report our AP for Bird s eye view challenge and 3D IoU. We employ the official IoU threshold of.7 for each metric. Method 2D Detection AP [val /test] Mono3D [3] / / / DOP[4] 93.8 / / / 79. Xu et al. [4] / 93 / / ROI-D / / /6.8 Table 2: 2D performance on KITTI3D validation [3] and official test set. We report our AP for 2D IoU. We employ the official IoU threshold of.7 for each metric Comparison to Related Work We compare ourselves on the train/validation split from [3] and on the official test set against state-of-the-art RGBbased methods on KITTI3D, namely (stereo-based) 3DOP [4], Mono3D [3], and Xu et al. [4] which also uses a depth module for better reasoning. Note that, although slightly lower in 2D AP, our model using synthetic data provides the best pose accuracy among our trained networks and we chose this model to compete against the others. As can be seen in Table and 2, our method performs worse in 2D due to our strict 3D-NMS, but we are by far the strongest in the Bird s Eye View and the 3D AP. This underlines the important aspect of directly minimizing 3D alignment instead of intermediate quantities. On the official test set, we get around twice the 3D AP of our closest monocular competitor. It is noteworthy that [4] trained their depth module on both KITTI3D and Cityscapes [6] for better generalization whereas the SuperDepth model we use has been pre-trained on KITTI data only. Interestingly, they have a strong drop in numbers when moving from the validation set onto the test set, which suggests aggressive tuning towards the validation set with known ground truth. We want to mention that the evaluation protocol forces the 3D AP and Bird s eye view AP to be bounded from above by the 2D detection AP since missed detections in 2D always reflect negatively on the pose metrics. This strengthens our case further since our pose metric numbers would be even higher if we were to correct them with a 2D AP normalization Ablative Analysis In the ablative analysis we want to first investigate how our new loss specifically minimizes the alignment problem. Additionally, we will identify where and why certain poses in KITTI3D are so much more difficult to estimate right. Finally, we analyze our method in respect to different inputs and how well our loss affects the quality of the poses. Lifting Loss We run a controlled experiment where, isolating one instance with ground truth RoI X and 3D box B, we solely optimize the lifting module F with randomly initialized parameters. The step-wise improvement in alignment between F(X ) and B is depicted in Figure 7 and we refer to the supplementary material for the full animations. Independent of initialization, we can observe that our loss always converges smoothly towards the global optimum. We also show the magnitude of each Jacobian component from Eq. 3 and can see that the loss focuses strongly on depth while steadily increasing importance towards rotation and 2D centroid position. Since our scale regression recovers deviation from the average car size, it was mostly neglected during optimization since the original error in extents was minimal. Without manually enforcing any principal direction during optimization or scaling the magnitudes, the loss steers the impact of each component quite well. Pose vs. Training Data To better understand our strengths and weaknesses, in Fig. 8 we show our recall for different bins for depth and rotation on the train/val split from [3]. We accept a detection if the Bird s Eye View IoU is larger than.5. Note that we followed the KITTI convention, such that an angle of degrees corresponds to an object facing to the right. Since the dataset is rather small for deep learning methods, we also plot the training data distribution to understand if there is a correlation between sample frequency and pose quality. For translation we did not discover any connection between the number of occurrences in the training data and the pose results. Nevertheless, closer objects are in general significantly better localized in 3D than objects further away. This can be explained by the fact that the network strongly relies on the predicted depth map to estimate the distance. However, the uncertainty of our monocular depth estimation also grows with distance. Very interestingly, utilizing our synthetic data generation improves the results across all bins. This confirms that, since the variety of scenes is limited, the network learns biases quickly and risks over-fitting 6
![Method 2D Detection AP [.7] Bird s Eye View AP [.5 /.7] 3D Detection AP [.5 /.7] No Weighting 88.95 87.54 78.68 4.7 /.85 27.85 / 7.32 24.49 / 7.22 33.95 / 7.47 22.53 / 4.83 2.78 / 3.](/docs-images/95/124910722/images/7-0.jpg "76 Multi-Task Weighting [2] 88.2 83.8 74.87 36.22 /. 26.82 / 6.6 23.2 / 5.84 3.4 / 6.7 2.4 / 4.64 7.32 / 3.63 ROI-D (w/o depth) 78.57 73.44 63.69 36.2 / 4.4 24.9 / 3.69 2.3 / 3.56 29.38/ 9.8 /.76 8.")
7 Method 2D Detection AP [.7] Bird s Eye View AP [.5 /.7] 3D Detection AP [.5 /.7] No Weighting / / / / / / 3.76 Multi-Task Weighting [2] / / / / / / 3.63 ROI-D (w/o depth) / / / / 9.8 / /.3 ROI-D / / / / / / 3.95 ROI-D (Synthetic) / / / / / / 6.29 Table 3: Different weighting strategies and input modalities on the train/validation split from [3]. We report our AP referring to 2D detection, the bird s eye view challenge and 3D IoU. Besides the official IoU threshold of.7, we also report for a softer threshold of.5. Figure 7: Controlled lifting loss experiment with given 2D RoI X over multiple runs with different seeding. Top: Visualizing F(X ) during optimization in camera and bird s eye view. Bottom: Gradient magnitudes of each lifting component, averaged over all runs. We refer to the supplement for the full animations. without our proposed augmentation. Our synthetic approach also clearly leads to better rotation estimates. In contrast to translation, we can find a strong correlation between the training data distribution and pose quality. While our method achieves good results on frequent viewpoints, the recall naturally drops when objects are seen from an underrepresented angle. Loss and input data We trained networks with different loss and data configurations on the train/validation [3] split Figure 8: of orientation and depth against the ground truth split distributions. Evidently, there exists a strong correlation between model performance and sample distribution. Synthetically augmenting underrepresented bins leads to overall better results. to incrementally highlight our contributions. In the first two rows of Table 3 we ran training with separate regression terms instead of our lifting loss. While the first row shows the results with uniform weighting of all terms of F, the second row shows training with the adaptive multi-task weighting from Kendall et al. [2]. Interestingly, we were not able to see an improvement with the adaptive weighting. We believe it comes from the fact that each term s magnitude is not at all comparable: while the (x, y) centroid moves in RoI-normalized image coordinates, the depth z is metric, the extents (w, h, l) are multiples of standard deviation from the mean extent, and the rotation q moves on a 4D 7

 where we show clearly that we can recover")






8 Figure 9: Qualitative results on the test (left) and validation (right) set. Noteworthy, we only trained on the train split to ensure that we never saw any of these images. For the validation samples, we additionally depict the ground truth poses in red. To get a proper estimate of the accuracy of the poses, we also plot the Bird s eye view (right) where we show clearly that we can recover accurate poses and proper metric shapes for unseen data, even at a distance. unit sphere. Any weighting that is not informed about the actual 3D instantiation has no means to properly assess the relative importance apart from numerical magnitude, thus comparing apples to oranges. to another introduced bias. We also show some qualitative results in Figure 9. Table 3 also presents results of a trained variant without monocular depth vs. results for our method on real-world data, with or without synthetic augmentation. The results without depth cues are clearly worse, but we nonetheless get respectable numbers for the Bird s eye view and 3D AP. Unfortunately, our aggressive 3D-NMS discarded some correct solutions because of wrongly-regressed overlapping z-values, reducing our 2D AP significantly. Our synthetic data training shows strong improvement on the pose metrics since we reduced the rotational data sample imbalance. By inspecting the drop in 2D AP, we realized that we designed our augmentations to be occlusion-free to avoid unrealistic intersections with the environment. In turn, this led to a weaker representation of strongly-occluded instances and We proposed a monocular deep network that can lift 2D detections in 3D for metrically accurate pose estimation and shape recovery, optimizing directly a novel 3D loss formulation. We found that maximizing 3D alignment end-toend for 6D pose estimation leads to very good results since we optimize for exactly the quantity we seek. We provided some insightful analysis on pose distributions in KITTI3D and how to leverage this information with recovered meshes for synthetic data augmentation. We found this reflection to be very helpful and quite important to improve the pose recall. Non-maximum-suppression in 2D and 3D is, however, a major influence on the final results and should to be addressed in future work, too. 5. Conclusion 8




9 ROI-D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape Supplementary Material. Synthetic Data Generation We show more qualitative examples of our extracted textured shapes in Figure. Note that we recover metrically-accurate models, but depict them here at different relative sizes to fit onto the page. We want to stress the high visual fidelity of both the geometry and the projective texturing. This level of quality requires a very precise overlap between 2D pixels and projected 3D shape. In Figure 2 we show additional images from our synthetic augmentation scheme during training. Figure : Extracted textured meshes from the train set. Two cars in the center column show red parts that depict missing image information. We inpaint these via texture mirroring along the symmetry axis. 9








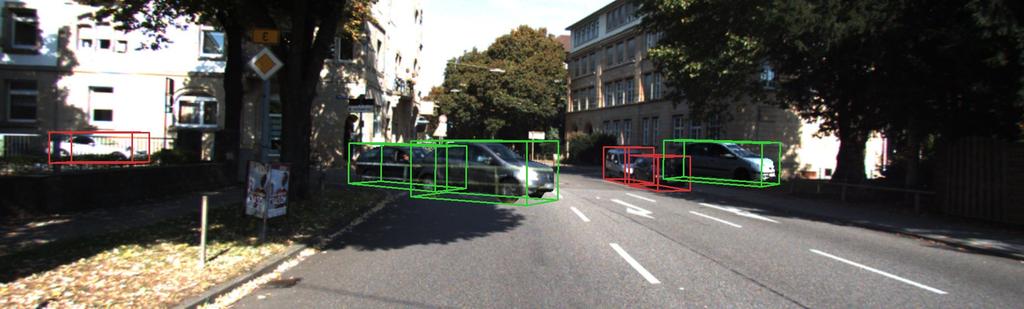







10 Figure 2: Synthetic training images. The red boxes illustrate the original ground truth instances. The green boxes show the synthetically-added data via rendering random instances from our generated car collection in new poses. The noisy patterns in some images enforce ignore -annotated parts of the image to not be used by negative mining during training.




11 2. ROI-D Results on KITTI RAW Additionally to the D results on some KITTI RAW sequences in the supplementary video, we show some recovered meshes in more detail in Figure 3. Note that although these images have not been seen during training, we can retrieve accurate poses and shapes, and in consequence, textured meshes. Even for highly occluded or far-away instances our predictions for pose and shape are quite accurate. For these cases, though, projective texturing can lead to visual artifacts such as overlaps or pixelation. Figure 3: D detections and recovered meshes on KITTI RAW.



12 3. Shape space dimensionality As mentioned in the paper, we trained a 3D convolutional autoencoder with a latent dimensionality of 6 for our shape space. We tried different dimensionalities and found 6 to be a good compromise between feature compactness as well as expressional power and detail preservation. We depict in Figure 4 the shape interpolation between two median shapes, similar to what has been shown in the paper, but for different latent dimensionalities. As can be seen, even for shape spaces trained with a single latent dimension (top row), we are able to traverse the manifold in a smooth, non-destructive way. In fact, the visual differences are marginal: lower dimensions lead to smoother surfaces and identical side mirrors whereas higher dimensions allow for harder edges and generally more irregularity. Figure 4: Interpolation between two median shapes with a shape space dimensionality of (from top to bottom), 3, 6, 6. 2
13 4. 2D Detection and 6D Pose Metrics We first show the plots produced by the offline evaluation tool for the val set from split of [3] in Figure 5. Additionally, we show the plots provided by the official servers for the test set in Figure 6. Orientation Similarity (a) 2D Detection AP (b) Orientation AP (c) Bird s Eye View AP No Weighting (d) 3D Detection AP Orientation Similarity (a) 2D Detection AP (b) Orientation AP (c) Bird s Eye View AP Multi-Task Weighting (d) 3D Detection AP Orientation Similarity (a) 2D Detection AP (b) Orientation AP (c) Bird s Eye View AP (d) 3D Detection AP ROI-D Standard formulation (without SuperDepth module) Orientation Similarity (a) 2D Detection AP (b) Orientation AP (c) Bird s Eye View AP ROI-D Standard formulation (d) 3D Detection AP Orientation Similarity (a) 2D Detection AP (b) Orientation AP (c) Bird s Eye View AP (d) 3D Detection AP ROI-D Standard formulation with additional synthetic training data Figure 5: Plots of the ablative evaluation on the val split from [3] for different configurations of our method. 3
14 Orientation Similarity (a) 2D Detection AP (b) Orientation AP (c) Bird s Eye View AP (d) 3D Detection AP Figure 6: Results of our synthetically-augmented model on the official test set. [2] References [] H. A. Alhaija, S. K. Mustikovela, L. Mescheder, A. Geiger, and C. Rother. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. International Journal of Computer Vision, 26(9):96 972, [2] K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. CVPR, pages 95 4, [3] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun. Monocular 3d object detection for autonomous driving. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 26., 2, 5, 6, 7, 3 [4] X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals for accurate object class detection. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume, NIPS, pages , Cambridge, MA, USA, 25. MIT Press. 2, 6 [5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, [6] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), [7] Z. Deng and L. J. Latecki. Amodal detection of 3d objects: Inferring 3d bounding boxes from 2d ones in rgb-depth images. In Conference on Computer Vision and Pattern Recognition (CVPR), [8] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. CARLA: An open urban driving simulator. In Proceedings of the st Annual Conference on Robot Learning, pages 6, [9] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In Advances in neural information processing systems, pages , 24. [] A. Gaidon, Q. Wang, Y. Cabon, and E. Vig. Virtual worlds as proxy for multi-object tracking analysis. In CVPR, [] R. Garg, V. K. BG, G. neiro, and I. Reid. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In European Conference on Computer Vision, pages Springer, 26., 3 [2] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR), 22. 2, 5, 4 [3] C. Godard, O. Mac Aodha, and G. J. Brostow. Unsupervised monocular depth estimation with left-right consistency. In CVPR, volume 2, page 7, 27. [4] A. Grabner, P. M. Roth, and V. Lepetit. 3D Pose Estimation and 3D Model Retrieval for Objects in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [5] K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask R-CNN. In Proceedings of the InternationalConference on Computer Vision (ICCV), 27. 2, 4 [6] S. Hinterstoisser, V. Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige,, and N. Navab. Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. In Asian Conference on Computer Vision, [7] S. Hinterstoisser, V. Lepetit, P. Wohlhart, and K. Konolige. On pre-trained image features and synthetic images for deep learning. CoRR, abs/7.7, [8] A. Kanazawa, S. Tulsiani, A. A. Efros, and J. Malik. Learning category-specific mesh reconstruction from image collections. In ECCV, 28., 2 [9] H. Kato, Y. Ushiku, and T. Harada. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [2] W. Kehl, F. Manhardt, F. Tombari, S. Ilic, and N. Navab. Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again. In The IEEE International Conference on Computer Vision (ICCV), Oct 27., 2, 3, 5 [2] A. Kendall, Y. Gal, and R. Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
15 [22] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. Waslander. Joint 3d proposal generation and object detection from view aggregation. IROS, [23] A. Kundu, Y. Li, and J. M. Rehg. 3d-rcnn: Instance-level 3d object reconstruction via render-and-compare. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 28., 2, 4 [24] Y. Li, G. Wang, X. Ji, Y. Xiang, and D. Fox. Deepim: Deep iterative matching for 6d pose estimation. In The European Conference on Computer Vision (ECCV), September 28., 2 [25] T.-Y. Lin, P. Dollár, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie. Feature pyramid networks for object detection. In CVPR, volume, page 4, [26] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár. Focal loss for dense object detection. IEEE transactions on pattern analysis and machine intelligence, [27] R. Liu, J. Lehman, P. Molino, F. P. Such, E. Frank, A. Sergeev, and J. Yosinski. An intriguing failing of convolutional neural networks and the coordconv solution. CoRR, abs/ , [28] W. E. Lorensen and H. E. Cline. Marching cubes: A high resolution 3d surface construction algorithm. In Proceedings of the 4th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 87, pages 63 69, New York, NY, USA, 987. ACM. 5 [29] R. Mahjourian, M. Wicke, and A. Angelova. Unsupervised learning of depth and egomotion from monocular video using 3d geometric constraints. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June [3] F. Manhardt, W. Kehl, N. Navab, and F. Tombari. Deep model-based 6d pose refinement in rgb. In The European Conference on Computer Vision (ECCV), September 28., 2, 4 [3] A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka. 3d bounding box estimation using deep learning and geometry. 27 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages , 27., 2, 3, 4 [32] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch. In NIPS-W, [33] S. Pillai, R. Ambrus, and A. Gaidon. Superdepth: Self-supervised, super-resolved monocular depth estimation, 28., 3, 5 [34] M. Rad and V. Lepetit. Bb8: A scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth. In The IEEE International Conference on Computer Vision (ICCV), Oct 27., 2 [35] M. Rad, M. Oberweger, and V. Lepetit. Feature mapping for learning fast and accurate 3d pose inference from synthetic images. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), [36] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In Neural Information Processing Systems (NIPS), [37] B. Tekin, S. N. Sinha, and P. Fua. Real-time seamless single shot 6d object pose prediction. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June [38] E. Weiszfeld. Sur le point pour lequel la somme des distances de n points donnés est minimum. Tohoku Mathematical Journal, First Series, 43: , [39] Y. Wu and K. He. Group normalization. In CVPR, [4] Y. Xiang, T. Schmidt, V. Narayanan, and D. Fox. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. Robotics: Science and Systems (RSS), 28., 2, 3 [4] B. Xu and Z. Chen. Multi-level fusion based 3d object detection from monocular images. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 28. 2, 6 [42] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe. Unsupervised learning of depth and ego-motion from video. In CVPR, volume 2, page 7, 27. 5
From 3D descriptors to monocular 6D pose: what have we learned?
 ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Supplementary: Cross-modal Deep Variational Hand Pose Estimation
 Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials)
") ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
BOP: Benchmark for 6D Object Pose Estimation
 BOP: Benchmark for 6D Object Pose Estimation Hodan, Michel, Brachmann, Kehl, Buch, Kraft, Drost, Vidal, Ihrke, Zabulis, Sahin, Manhardt, Tombari, Kim, Matas, Rother 4th International Workshop on Recovering
BOP: Benchmark for 6D Object Pose Estimation Hodan, Michel, Brachmann, Kehl, Buch, Kraft, Drost, Vidal, Ihrke, Zabulis, Sahin, Manhardt, Tombari, Kim, Matas, Rother 4th International Workshop on Recovering
arxiv: v4 [cs.cv] 12 Jul 2018
![arxiv: v4 [cs.cv] 12 Jul 2018](/thumbs/82/85481048.jpg "arxiv: v4 [cs.cv] 12 Jul 2018") Joint 3D Proposal Generation and Object Detection from View Aggregation Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven L. Waslander arxiv:1712.02294v4 [cs.cv] 12 Jul 2018 Abstract We
Joint 3D Proposal Generation and Object Detection from View Aggregation Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven L. Waslander arxiv:1712.02294v4 [cs.cv] 12 Jul 2018 Abstract We
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image - Supplementary Material -
 Uncertainty-Driven 6D Pose Estimation of s and Scenes from a Single RGB Image - Supplementary Material - Eric Brachmann*, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Uncertainty-Driven 6D Pose Estimation of s and Scenes from a Single RGB Image - Supplementary Material - Eric Brachmann*, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning 6D Object Pose Estimation and Tracking
 Learning 6D Object Pose Estimation and Tracking Carsten Rother presented by: Alexander Krull 21/12/2015 6D Pose Estimation Input: RGBD-image Known 3D model Output: 6D rigid body transform of object 21/12/2015
Learning 6D Object Pose Estimation and Tracking Carsten Rother presented by: Alexander Krull 21/12/2015 6D Pose Estimation Input: RGBD-image Known 3D model Output: 6D rigid body transform of object 21/12/2015
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
arxiv: v1 [cs.cv] 27 Mar 2019
![arxiv: v1 [cs.cv] 27 Mar 2019](/thumbs/96/129261901.jpg "arxiv: v1 [cs.cv] 27 Mar 2019") Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles Siddharth Srivastava 1, Frederic Jurie 2 and Gaurav Sharma 3 arxiv:1904.08494v1 [cs.cv] 27 Mar 2019 Abstract We address the
Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles Siddharth Srivastava 1, Frederic Jurie 2 and Gaurav Sharma 3 arxiv:1904.08494v1 [cs.cv] 27 Mar 2019 Abstract We address the
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Multi-Level Fusion based 3D Object Detection from Monocular Images
 Multi-Level Fusion based 3D Object Detection from Monocular Images Bin Xu, Zhenzhong Chen School of Remote Sensing and Information Engineering, Wuhan University, China {ysfalo,zzchen}@whu.edu.cn Abstract
Multi-Level Fusion based 3D Object Detection from Monocular Images Bin Xu, Zhenzhong Chen School of Remote Sensing and Information Engineering, Wuhan University, China {ysfalo,zzchen}@whu.edu.cn Abstract
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
A Survey of Light Source Detection Methods
 A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
Joint Object Detection and Viewpoint Estimation using CNN features
 Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images
 Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd Supplementary Material
 Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd Supplementary Material Andreas Doumanoglou 1,2, Rigas Kouskouridas 1, Sotiris Malassiotis 2, Tae-Kyun Kim 1 1 Imperial College London
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd Supplementary Material Andreas Doumanoglou 1,2, Rigas Kouskouridas 1, Sotiris Malassiotis 2, Tae-Kyun Kim 1 1 Imperial College London
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA
 TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey
 Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014
 Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Supplemental Material for End-to-End Learning of Video Super-Resolution with Motion Compensation
 Supplemental Material for End-to-End Learning of Video Super-Resolution with Motion Compensation Osama Makansi, Eddy Ilg, and Thomas Brox Department of Computer Science, University of Freiburg 1 Computation
Supplemental Material for End-to-End Learning of Video Super-Resolution with Motion Compensation Osama Makansi, Eddy Ilg, and Thomas Brox Department of Computer Science, University of Freiburg 1 Computation
A Study of Vehicle Detector Generalization on U.S. Highway
 26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos
 Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos Yang Wang 1 Zhenheng Yang 2 Peng Wang 1 Yi Yang 1 Chenxu Luo 3 Wei Xu 1 1 Baidu Research 2 University of Southern California
Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos Yang Wang 1 Zhenheng Yang 2 Peng Wang 1 Yi Yang 1 Chenxu Luo 3 Wei Xu 1 1 Baidu Research 2 University of Southern California
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
arxiv: v1 [cs.cv] 1 Dec 2016
![arxiv: v1 [cs.cv] 1 Dec 2016](/thumbs/89/98666847.jpg "arxiv: v1 [cs.cv] 1 Dec 2016") arxiv:1612.00496v1 [cs.cv] 1 Dec 2016 3D Bounding Box Estimation Using Deep Learning and Geometry Arsalan Mousavian George Mason University Dragomir Anguelov Zoox, Inc. John Flynn Zoox, Inc. amousavi@gmu.edu
arxiv:1612.00496v1 [cs.cv] 1 Dec 2016 3D Bounding Box Estimation Using Deep Learning and Geometry Arsalan Mousavian George Mason University Dragomir Anguelov Zoox, Inc. John Flynn Zoox, Inc. amousavi@gmu.edu
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material
 Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
VISION FOR AUTOMOTIVE DRIVING
 VISION FOR AUTOMOTIVE DRIVING French Japanese Workshop on Deep Learning & AI, Paris, October 25th, 2017 Quoc Cuong PHAM, PhD Vision and Content Engineering Lab AI & MACHINE LEARNING FOR ADAS AND SELF-DRIVING
VISION FOR AUTOMOTIVE DRIVING French Japanese Workshop on Deep Learning & AI, Paris, October 25th, 2017 Quoc Cuong PHAM, PhD Vision and Content Engineering Lab AI & MACHINE LEARNING FOR ADAS AND SELF-DRIVING
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Direct Methods in Visual Odometry
 Direct Methods in Visual Odometry July 24, 2017 Direct Methods in Visual Odometry July 24, 2017 1 / 47 Motivation for using Visual Odometry Wheel odometry is affected by wheel slip More accurate compared
Direct Methods in Visual Odometry July 24, 2017 Direct Methods in Visual Odometry July 24, 2017 1 / 47 Motivation for using Visual Odometry Wheel odometry is affected by wheel slip More accurate compared
arxiv: v1 [cs.ro] 24 Jul 2018
![arxiv: v1 [cs.ro] 24 Jul 2018](/thumbs/82/86968787.jpg "arxiv: v1 [cs.ro] 24 Jul 2018") ClusterNet: Instance Segmentation in RGB-D Images Lin Shao, Ye Tian, Jeannette Bohg Stanford University United States lins2,yetian1,bohg@stanford.edu arxiv:1807.08894v1 [cs.ro] 24 Jul 2018 Abstract: We
ClusterNet: Instance Segmentation in RGB-D Images Lin Shao, Ye Tian, Jeannette Bohg Stanford University United States lins2,yetian1,bohg@stanford.edu arxiv:1807.08894v1 [cs.ro] 24 Jul 2018 Abstract: We
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
CHAPTER 6 PERCEPTUAL ORGANIZATION BASED ON TEMPORAL DYNAMICS
 CHAPTER 6 PERCEPTUAL ORGANIZATION BASED ON TEMPORAL DYNAMICS This chapter presents a computational model for perceptual organization. A figure-ground segregation network is proposed based on a novel boundary
CHAPTER 6 PERCEPTUAL ORGANIZATION BASED ON TEMPORAL DYNAMICS This chapter presents a computational model for perceptual organization. A figure-ground segregation network is proposed based on a novel boundary
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
arxiv: v1 [cs.cv] 29 Nov 2017
![arxiv: v1 [cs.cv] 29 Nov 2017](/thumbs/76/73780978.jpg "arxiv: v1 [cs.cv] 29 Nov 2017") PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation Danfei Xu Stanford Unviersity danfei@cs.stanford.edu Dragomir Anguelov Zoox Inc. drago@zoox.com Ashesh Jain Zoox Inc. ashesh@zoox.com arxiv:1711.10871v1
PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation Danfei Xu Stanford Unviersity danfei@cs.stanford.edu Dragomir Anguelov Zoox Inc. drago@zoox.com Ashesh Jain Zoox Inc. ashesh@zoox.com arxiv:1711.10871v1
Colored Point Cloud Registration Revisited Supplementary Material
 Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
arxiv: v2 [cs.cv] 14 May 2018
![arxiv: v2 [cs.cv] 14 May 2018](/thumbs/79/79495201.jpg "arxiv: v2 [cs.cv] 14 May 2018") ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
Chapter 7. Conclusions and Future Work
 Chapter 7 Conclusions and Future Work In this dissertation, we have presented a new way of analyzing a basic building block in computer graphics rendering algorithms the computational interaction between
Chapter 7 Conclusions and Future Work In this dissertation, we have presented a new way of analyzing a basic building block in computer graphics rendering algorithms the computational interaction between
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document
 Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
3D Object Proposals using Stereo Imagery for Accurate Object Class Detection
 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. X, NO. Y, MONTH Z 3D Object Proposals using Stereo Imagery for Accurate Object Class Detection Xiaozhi Chen, Kaustav Kundu, Yukun Zhu,
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. X, NO. Y, MONTH Z 3D Object Proposals using Stereo Imagery for Accurate Object Class Detection Xiaozhi Chen, Kaustav Kundu, Yukun Zhu,
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
HDNET: Exploiting HD Maps for 3D Object Detection
 HDNET: Exploiting HD Maps for 3D Object Detection Bin Yang 1,2 Ming Liang 1 Raquel Urtasun 1,2 1 Uber Advanced Technologies Group 2 University of Toronto {byang10, ming.liang, urtasun}@uber.com Abstract:
HDNET: Exploiting HD Maps for 3D Object Detection Bin Yang 1,2 Ming Liang 1 Raquel Urtasun 1,2 1 Uber Advanced Technologies Group 2 University of Toronto {byang10, ming.liang, urtasun}@uber.com Abstract:
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation
 ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
Final Report: Smart Trash Net: Waste Localization and Classification
 Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Outdoor Scene Reconstruction from Multiple Image Sequences Captured by a Hand-held Video Camera
 Outdoor Scene Reconstruction from Multiple Image Sequences Captured by a Hand-held Video Camera Tomokazu Sato, Masayuki Kanbara and Naokazu Yokoya Graduate School of Information Science, Nara Institute
Outdoor Scene Reconstruction from Multiple Image Sequences Captured by a Hand-held Video Camera Tomokazu Sato, Masayuki Kanbara and Naokazu Yokoya Graduate School of Information Science, Nara Institute
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object