Self-Supervised Learning & Visual Discovery
|
|
|
- Marion Mills
- 6 years ago
- Views:
Transcription

1 CS 2770: Computer Vision Self-Supervised Learning & Visual Discovery Prof. Adriana Kovashka University of Pittsburgh April 10, 2017
2 Motivation So far we ve assumed access to plentiful labeled data How is this data obtained?

3 Crowdsourcing Workers Is this a dog? o Yes o No $0.01 Task Broker Task: Dog? Answer: Yes Pay: $0.01 Alex Sorokin
4 Crowdsourcing via games The ESP Game Two-player online game Partners don t know each other and can t communicate Objective of the game: type the same word The only thing in common is an image von Ahn and Dabbish, Labeling Images with a Computer Game, CHI 2004
5 THE ESP GAME PLAYER 1 PLAYER 2 GUESSING: CAR GUESSING: HAT GUESSING: KID SUCCESS! YOU AGREE ON CAR GUESSING: BOY GUESSING: CAR SUCCESS! YOU AGREE ON CAR von Ahn and Dabbish, Labeling Images with a Computer Game, CHI 2004
6 Motivation So far we ve assumed access to plentiful labeled data What if we have limited or no labeled data? One approach: learn from unlabeled data (unsupervised learning) Mine for interesting patterns (discovery) Use supervision (labels) inherent in the data (selfsupervised learning) Another approach (not discussed): carefully choose which data to label Active learning, human-in-the-loop
7 Plan for this lecture Self-supervised learning From surrounding regions (ICCV 2015) From temporal order (ECCV 2016) From ego-motion (ICCV 2015) Visual discovery From surrounding objects (CVPR 2010) Elements of architectural styles (SIGGRAPH 2012) Gradual style changes in time/space (ICCV 2013)
8 Unsupervised Visual Representation Learning by Context Prediction Carl Doersch, Alexei Efros and Abhinav Gupta ICCV 2015
9 ImageNet + Deep Learning Beagle Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV Image Retrieval - Detection (RCNN) - Segmentation (FCN) - Depth Estimation -

10 ImageNet + Deep Learning Beagle Materials? Pose? Do we Do even we need semantic this task? labels? Geometry? Parts? Boundaries? Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015

11 Context as Supervision [Collobert & Weston 2008; Mikolov et al. 2013] Deep Net
12 Context Prediction for Images A B Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015




13 Semantics from a non-semantic task Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015
14 Relative Position Task 8 possible locations Classifier CNN CNN Randomly Sample Patch Sample Second Patch Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015
15 Classifier Patch Embedding Input Nearest Neighbors CNN CNN Note: connects across instances! Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015
16 Architecture Softmax loss Fully connected Fully connected Fully connected Max Pooling Convolution Convolution Convolution LRN Max Pooling Convolution LRN Max Pooling Convolution Tied Weights Fully connected Max Pooling Convolution Convolution Convolution LRN Max Pooling Convolution LRN Max Pooling Convolution Patch 1 Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015 Patch 2
17 What is learned? Input Ours ImageNet AlexNet Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015

18 Pre-Training for R-CNN Pre-train on relative-position task, w/o labels Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015 [Girshick et al. 2014]
19 % Average Precision VOC 2007 Performance (pretraining for R-CNN) ImageNet Labels Ours No Pretraining Doersch et al., Unsupervised Visual Representation Learning by Context Prediction, ICCV 2015
20 Shuffle and Learn: Unsupervised Learning using Temporal Order Verification Ishan Misra, C. Lawrence Zitnick, and Martial Hebert ECCV 2016

21 Misra et al., Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV 2016

22 Misra et al., Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV 2016
23 Misra et al., Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV 2016
24 Learning image representations tied to ego-motion Dinesh Jayaraman and Kristen Grauman ICCV 2015
![The kitten carousel experiment [Held & Hein, 1963] active](/docs-images/79/80291373/images/25-0.jpg "kitten passive kitten Key to perceptual development:")

25 The kitten carousel experiment [Held & Hein, 1963] active kitten passive kitten Key to perceptual development: self-generated motion + visual feedback Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015


26 Problem with today s visual learning Status quo: Learn from disembodied bag of labeled snapshots. Our goal: Learn in the context of acting and moving in the world. Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015





27 Our idea: Ego-motion vision Goal: Teach computer vision system the connection: how I move how my visual surroundings change + Ego-motion motor signals Unlabeled video Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015




28 Ego-motion vision: view prediction After moving: Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015
29 Ego-motion vision for recognition Learning this connection requires: Depth, 3D geometry Semantics Context Also key to recognition! Can be learned without manual labels! Our approach: unsupervised feature learning using egocentric video + motor signals Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015
30 Approach idea: Ego-motion equivariance Invariant features: unresponsive to some classes of transformations z gx z(x) Equivariant features : predictably responsive to some classes of transformations, through simple mappings (e.g., linear) z gx M g z(x) equivariance map Invariance discards information; equivariance organizes it. Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015










31 motor signal Approach idea: Ego-motion equivariance Training data Unlabeled video + motor signals Equivariant embedding organized by ego-motions left turn right turn forward time Learn Pairs of frames related by similar ego-motion should be related by same feature transformation Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015
32 Approach overview Our approach: unsupervised feature learning using egocentric video + motor signals 1. Extract training frame pairs from video 2. Learn ego-motion-equivariant image features 3. Train on target recognition task in parallel Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015



33 yaw change Training frame pair mining Discovery of ego-motion clusters g =left turn g =forward g =right turn Right turn forward distance Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015

 Unsupervised training x i")

 2 x z k θ (x W i ) softmax")


34 Ego-motion equivariant feature learning Given: Desired: for all motions g and all images x, z θ gx M g z θ (x) Unsupervised training x i g gx i θ θ z θ (x i ) z θ (gx i ) Supervised Feature space training θ z θ (x k ) M g M g z θ (x i ) z θ (gx i ) 2 x z k θ (x W i ) softmax loss L C (x k, y k ) M g class y k θ, M g and W jointly trained z θ (gx i ) Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015





35 RESULTS APPROACH Summary Ego-motion training pairs Neural network training Equivariant embedding θ θ M g L E θ W L C Scene and object recognition Next-best view selection Football field? Pagoda? Airport? Cathedral? Army base? cup frying pan Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015









36 Results: Recognition Learn from unlabeled car video (KITTI) Geiger et al, IJRR 13 Exploit features for static scene classification (SUN, 397 classes) Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015 Xiao et al, CVPR 10

37 recognition accuracy (%) Results: Recognition Do ego-motion equivariant features improve recognition? KITTI SUN labeled training examples per class 397 classes invariance Up to 30% accuracy increase over state of the art! Jayaraman and Grauman, Learning image representations tied to ego-motion, ICCV 2015
38 Discussion Many types of supervision cues have been tried What other types of supervision for free can we use? How do we know if a certain supervision type would work? Can we make this type of learning perform on par with supervised learning?
39 Plan for next two lectures Self-supervised learning From surrounding regions (ICCV 2015) From temporal order (ECCV 2016) From ego-motion (ICCV 2015) Visual discovery From surrounding objects (CVPR 2010) Elements of architectural styles (SIGGRAPH 2012) Gradual style changes in time/space (ICCV 2013)
40 Object-Graphs for Context-Aware Category Discovery Yong Jae Lee and Kristen Grauman CVPR 2010









41 Goal Unlabeled Image Data Discovered categories Discover new object categories, based on their relation to categories for which we have trained models Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010
42 Existing approaches Previous work treats unsupervised visual discovery as an appearance-grouping problem Can you identify the recurring pattern? Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010
43 Our idea How can seeing previously learned objects in novel images help to discover new categories? Can you identify the recurring pattern? Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010
44 Our idea Discover visual categories within unlabeled images by modeling interactions between the unfamiliar regions and familiar objects Can you identify the recurring pattern? Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010





45 Context-aware visual discovery??? sky sky sky driveway house? grass grass house truck fence grass house?? driveway driveway Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010





















46 Learn Models Detect Unknowns Object-level Context Discovery Learn Known Categories tree building sky road Offline: Train region-based classifiers for N known categories using labeled training data. Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010









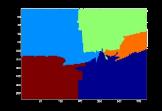

47 Learn Models Detect Unknowns Object-level Context Discovery Identifying Unknown Objects Input: unlabeled pool of novel images Compute multiple-segmentations for each unlabeled image Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010



48 P(class region) P(class region) P(class region) P(class region) Learn Models Detect Unknowns Object-level Context Discovery Identifying Unknown Objects Prediction: known High entropy Prediction: unknown Prediction: known Prediction: known For all segments, use classifiers to compute posteriors for the N known categories. Deem each segment as known or unknown based on resulting entropy. Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010
49 Learn Models Detect Unknowns Object-level Context Discovery Object-Graphs An unknown region within an image 0 Model the topology of category predictions relative to the unknown (unfamiliar) region. Incorporate uncertainty from classifiers. Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010

 b t s r 1a above b t s r H 1 (s) 1b below g(s) = [,,, ] b t s r Lee and Grauman, Object-Graphs for Context-Aware")
50 Learn Models Detect Unknowns Object-level Context Discovery An unknown region within an image Object-Graphs Closest nodes in its object-graph 3a 1a 2a S 0 3b 2b 1b Consider spatially near regions above and below, record distributions for each known class. 0 self H 0 (s) b t s r 1a above b t s r H 1 (s) 1b below g(s) = [,,, ] b t s r Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR self b t s r Ra above b t s r H R (s) Rb below b t s r 1 st nearest region out to R th nearest
 = [ :,, : ]?")
51 Learn Models Detect Unknowns Object-level Context Discovery Object-Graph matching Known classes b: building t: tree g: grass r: road building / road building tree / road building? building road / road above below above below b t g r b t g r b t g r b t g r g(s 1 ) = [ :,, : ]? building road / road above below above below b t g r b t g r b t g r b t g r g(s 2 ) = [ :,, : ] H 1 (s) H R (s) H 1 (s) H R (s) Object-graphs are very similar produces a strong match Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010
 = [ :,, : ]?")
52 Learn Models Detect Unknowns Object-level Context Discovery Object-Graph matching Known classes b: building t: tree g: grass r: road building / road building building grass? building road / road above below above below b t g r b t g r b t g r b t g r g(s 1 ) = [ :,, : ]? road road above below above below b t g r b t g r b t g r b t g r g(s 2 ) = [ :,, : ] H 1 (s) H R (s) H 1 (s) H R (s) Object-graphs are partially similar produces a fair match Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010

53 Learn Models Detect Unknowns Object-level Context Discovery Clusters from region-region affinities Unknown Regions Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010












































54 Object Discovery Accuracy MSRC-v2 PASCAL 2008 MSRC-v0 Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010 Corel




55 Examples of Discovered Categories Lee and Grauman, Object-Graphs for Context-Aware Category Discovery, CVPR 2010
56 What Makes Paris Look like Paris? Carl Doersch, Saurabh Singh, Abhinav Gupta, Josef Sivic, Alexei Efros SIGGRAPH 2012
57 this is Paris One of these is from Paris Raise your hand if Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012

58 Raise your hand if We showed 20 subjects: Random Street View Images - 50 from Paris - They classified Paris vs non-paris - Accuracy: 79% How do they know? Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012

59 We showed 20 subjects: Random Street View Images - 50 from Paris - They classified Paris non-paris - Accuracy: 79% How do they know? Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
60 Our Goal: Given a large geo-tagged image dataset, we automatically discover visual elements that characterize a geographic location Why might this be a useful task? Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
61 Our Hypothesis The visual elements that capture Paris: Frequent: Occur often in Paris Discriminative: Are not found outside Paris Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012

62 Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012

63 Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012

64 London Prague New York Boston Paris Milan San Barcelona Philadelphia Francisco Tokyo Mexico City Sao Paulo Positive Set Negative Set Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
65 patch Step 1: Nearest Neighbors for Every Patch Using normalized correlation of HOG features as a distance metric nearest neighbors Paris Not Paris Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012









































66 Sort by # Paris Neighbors Step 2: Find the Parisian Clusters by Sorting patch nearest neighbors patch nearest neighbors Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
67 Approach Summary 1. A Cluster for Every Patch Paris Not Paris Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
68 Our Approach 1. A cluster for every patch 2. Find clusters that are mostly Parisian Paris Not Paris Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
69 Approach Summary 1. A cluster for every patch 2. Find clusters that are mostly Parisian 3. Refine clusters by making them more Parisian Paris Not Paris Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
70 Paris: A Few Top Elements Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012

71 Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
72 Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
73 Elements from Prague Elements from London Elements from Barcelona Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
74 In the U.S. Elements from San Francisco Elements from Boston Doersch et al., What Makes Paris Look Like Paris?, SIGGRAPH 2012
75 Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time Yong Jae Lee, Alexei A. Efros, and Martial Hebert ICCV 2013









76 Our Goal Mine mid-level visual elements in temporally- and spatially-varying data and model their visual style year when? Historical dating of cars where? Geolocalization of StreetView images Lee et al., Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time, ICCV 2013
")


77 1) Establish connections Key Idea ) Model style-specific differences closed-world Lee et al., Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time, ICCV 2013
78 Mining style-sensitive elements Patch Nearest neighbors Lee et al., Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time, ICCV 2013




79 Mining style-sensitive elements Patch Nearest neighbors tight uniform Lee et al., Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time, ICCV 2013
 Peaky (low-entropy) clusters Lee et al.")
80 Style-sensitive elements (a) Peaky (low-entropy) clusters Lee et al., Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time, ICCV 2013


81 Uninformative elements (b) Uniform (high-entropy) clusters Lee et al., Style-aware Mid-level Representation for Discovering Visual Connections in Space and Time, ICCV 2013
ECS 289H: Visual Recognition Fall Yong Jae Lee Department of Computer Science
 ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science Plan for today Questions? Research overview Standard supervised visual learning building Category models Annotators tree
ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science Plan for today Questions? Research overview Standard supervised visual learning building Category models Annotators tree
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised discovery of category and object models. The task
 Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Learning image representations tied to egomotion from unlabeled video
 IJCV Special Issue (Best Papers from ICCV 2015) manuscript No. (will be inserted by the editor) Learning image representations tied to egomotion from unlabeled video Dinesh Jayaraman Kristen Grauman Received:
IJCV Special Issue (Best Papers from ICCV 2015) manuscript No. (will be inserted by the editor) Learning image representations tied to egomotion from unlabeled video Dinesh Jayaraman Kristen Grauman Received:
Learning image representations equivariant to ego-motion (Supplementary material)
") Learning image representations equivariant to ego-motion (Supplementary material) Dinesh Jayaraman UT Austin dineshj@cs.utexas.edu Kristen Grauman UT Austin grauman@cs.utexas.edu max-pool (3x3, stride2)
Learning image representations equivariant to ego-motion (Supplementary material) Dinesh Jayaraman UT Austin dineshj@cs.utexas.edu Kristen Grauman UT Austin grauman@cs.utexas.edu max-pool (3x3, stride2)
CS 1674: Intro to Computer Vision. Object Recognition. Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018
 CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Self-Supervised Segmentation by Grouping Optical-Flow
 Self-Supervised Segmentation by Grouping Optical-Flow Aravindh Mahendran James Thewlis Andrea Vedaldi Visual Geometry Group Dept of Engineering Science, University of Oxford {aravindh,jdt,vedaldi}@robots.ox.ac.uk
Self-Supervised Segmentation by Grouping Optical-Flow Aravindh Mahendran James Thewlis Andrea Vedaldi Visual Geometry Group Dept of Engineering Science, University of Oxford {aravindh,jdt,vedaldi}@robots.ox.ac.uk
General Principal. Huge Dataset. Images. Info from Most Similar Images. Input Image. Associated Info
 Devin Montes General Principal Huge Dataset Input Image Images Associated Info image matching Info from Most Similar Images Hopefully, If you have enough images, the dataset will contain very similar images
Devin Montes General Principal Huge Dataset Input Image Images Associated Info image matching Info from Most Similar Images Hopefully, If you have enough images, the dataset will contain very similar images
Weakly Supervised Object Recognition with Convolutional Neural Networks
 GDR-ISIS, Paris March 20, 2015 Weakly Supervised Object Recognition with Convolutional Neural Networks Ivan Laptev ivan.laptev@inria.fr WILLOW, INRIA/ENS/CNRS, Paris Joint work with: Maxime Oquab Leon
GDR-ISIS, Paris March 20, 2015 Weakly Supervised Object Recognition with Convolutional Neural Networks Ivan Laptev ivan.laptev@inria.fr WILLOW, INRIA/ENS/CNRS, Paris Joint work with: Maxime Oquab Leon
End-to-End Localization and Ranking for Relative Attributes
 End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee Presented by Minhao Cheng [Farhadi et al. 2009, Kumar et al. 2009, Lampert et al. 2009, [Slide: Xiao and
End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee Presented by Minhao Cheng [Farhadi et al. 2009, Kumar et al. 2009, Lampert et al. 2009, [Slide: Xiao and
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Recognition Tools: Support Vector Machines
 CS 2770: Computer Vision Recognition Tools: Support Vector Machines Prof. Adriana Kovashka University of Pittsburgh January 12, 2017 Announcement TA office hours: Tuesday 4pm-6pm Wednesday 10am-12pm Matlab
CS 2770: Computer Vision Recognition Tools: Support Vector Machines Prof. Adriana Kovashka University of Pittsburgh January 12, 2017 Announcement TA office hours: Tuesday 4pm-6pm Wednesday 10am-12pm Matlab
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
CS230: Lecture 3 Various Deep Learning Topics
 CS230: Lecture 3 Various Deep Learning Topics Kian Katanforoosh, Andrew Ng Today s outline We will learn how to: - Analyse a problem from a deep learning approach - Choose an architecture - Choose a loss
CS230: Lecture 3 Various Deep Learning Topics Kian Katanforoosh, Andrew Ng Today s outline We will learn how to: - Analyse a problem from a deep learning approach - Choose an architecture - Choose a loss
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models
 Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
CS 1674: Intro to Computer Vision. Attributes. Prof. Adriana Kovashka University of Pittsburgh November 2, 2016
 CS 1674: Intro to Computer Vision Attributes Prof. Adriana Kovashka University of Pittsburgh November 2, 2016 Plan for today What are attributes and why are they useful? (paper 1) Attributes for zero-shot
CS 1674: Intro to Computer Vision Attributes Prof. Adriana Kovashka University of Pittsburgh November 2, 2016 Plan for today What are attributes and why are they useful? (paper 1) Attributes for zero-shot
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Day 3 Lecture 1. Unsupervised Learning
 Day 3 Lecture 1 Unsupervised Learning Semi-supervised and transfer learning Myth: you can t do deep learning unless you have a million labelled examples for your problem. Reality You can learn useful representations
Day 3 Lecture 1 Unsupervised Learning Semi-supervised and transfer learning Myth: you can t do deep learning unless you have a million labelled examples for your problem. Reality You can learn useful representations
CS 2750: Machine Learning. Clustering. Prof. Adriana Kovashka University of Pittsburgh January 17, 2017
 CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Copyright by Dinesh Jayaraman 2017
 Copyright by Dinesh Jayaraman 2017 The Dissertation Committee for Dinesh Jayaraman certifies that this is the approved version of the following dissertation: Embodied Learning for Visual Recognition Committee:
Copyright by Dinesh Jayaraman 2017 The Dissertation Committee for Dinesh Jayaraman certifies that this is the approved version of the following dissertation: Embodied Learning for Visual Recognition Committee:
CS4495/6495 Introduction to Computer Vision. 8C-L1 Classification: Discriminative models
 CS4495/6495 Introduction to Computer Vision 8C-L1 Classification: Discriminative models Remember: Supervised classification Given a collection of labeled examples, come up with a function that will predict
CS4495/6495 Introduction to Computer Vision 8C-L1 Classification: Discriminative models Remember: Supervised classification Given a collection of labeled examples, come up with a function that will predict
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Multiple-Choice Questionnaire Group C
 Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Attributes and More Crowdsourcing
 Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Object Recognition II
 Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Introduction to object recognition. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others
 Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Lecture 12 Recognition
 Institute of Informatics Institute of Neuroinformatics Lecture 12 Recognition Davide Scaramuzza 1 Lab exercise today replaced by Deep Learning Tutorial Room ETH HG E 1.1 from 13:15 to 15:00 Optional lab
Institute of Informatics Institute of Neuroinformatics Lecture 12 Recognition Davide Scaramuzza 1 Lab exercise today replaced by Deep Learning Tutorial Room ETH HG E 1.1 from 13:15 to 15:00 Optional lab
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Learning Deep Structured Models for Semantic Segmentation. Guosheng Lin
 Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Instances on a Budget
 Retrieving Similar or Informative Instances on a Budget Kristen Grauman Dept. of Computer Science University of Texas at Austin Work with Sudheendra Vijayanarasimham Work with Sudheendra Vijayanarasimham,
Retrieving Similar or Informative Instances on a Budget Kristen Grauman Dept. of Computer Science University of Texas at Austin Work with Sudheendra Vijayanarasimham Work with Sudheendra Vijayanarasimham,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Bias-Variance Trade-off (cont d) + Image Representations
 + Image Representations") CS 275: Machine Learning Bias-Variance Trade-off (cont d) + Image Representations Prof. Adriana Kovashka University of Pittsburgh January 2, 26 Announcement Homework now due Feb. Generalization Training
CS 275: Machine Learning Bias-Variance Trade-off (cont d) + Image Representations Prof. Adriana Kovashka University of Pittsburgh January 2, 26 Announcement Homework now due Feb. Generalization Training
Leveraging flickr images for object detection
 Leveraging flickr images for object detection Elisavet Chatzilari Spiros Nikolopoulos Yiannis Kompatsiaris Outline Introduction to object detection Our proposal Experiments Current research 2 Introduction
Leveraging flickr images for object detection Elisavet Chatzilari Spiros Nikolopoulos Yiannis Kompatsiaris Outline Introduction to object detection Our proposal Experiments Current research 2 Introduction
The Kinect Sensor. Luís Carriço FCUL 2014/15
 Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Part-Based Models for Object Class Recognition Part 3
 High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
Object Recognition. Lecture 11, April 21 st, Lexing Xie. EE4830 Digital Image Processing
 Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Interactive Image Search with Attributes
 Interactive Image Search with Attributes Adriana Kovashka Department of Computer Science January 13, 2015 Joint work with Kristen Grauman and Devi Parikh We Need Search to Access Visual Data 144,000 hours
Interactive Image Search with Attributes Adriana Kovashka Department of Computer Science January 13, 2015 Joint work with Kristen Grauman and Devi Parikh We Need Search to Access Visual Data 144,000 hours
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
CS6670: Computer Vision
 CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Visual words. Map high-dimensional descriptors to tokens/words by quantizing the feature space.
 Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Learning Transferable Features with Deep Adaptation Networks
 Learning Transferable Features with Deep Adaptation Networks Mingsheng Long, Yue Cao, Jianmin Wang, Michael I. Jordan Presented by Changyou Chen October 30, 2015 1 Changyou Chen Learning Transferable Features
Learning Transferable Features with Deep Adaptation Networks Mingsheng Long, Yue Cao, Jianmin Wang, Michael I. Jordan Presented by Changyou Chen October 30, 2015 1 Changyou Chen Learning Transferable Features
arxiv: v3 [cs.cv] 16 Jan 2016
![arxiv: v3 [cs.cv] 16 Jan 2016](/thumbs/76/73535134.jpg "arxiv: v3 [cs.cv] 16 Jan 2016") Unsupervised Visual Representation Learning by Context Prediction Carl Doersch 1,2 Abhinav Gupta 1 Alexei A. Efros 2 1 School of Computer Science 2 Dept. of Electrical Engineering and Computer Science
Unsupervised Visual Representation Learning by Context Prediction Carl Doersch 1,2 Abhinav Gupta 1 Alexei A. Efros 2 1 School of Computer Science 2 Dept. of Electrical Engineering and Computer Science
Towards Large-Scale Semantic Representations for Actionable Exploitation. Prof. Trevor Darrell UC Berkeley
 Towards Large-Scale Semantic Representations for Actionable Exploitation Prof. Trevor Darrell UC Berkeley traditional surveillance sensor emerging crowd sensor Desired capabilities: spatio-temporal reconstruction
Towards Large-Scale Semantic Representations for Actionable Exploitation Prof. Trevor Darrell UC Berkeley traditional surveillance sensor emerging crowd sensor Desired capabilities: spatio-temporal reconstruction
arxiv: v2 [cs.cv] 21 Nov 2016
![arxiv: v2 [cs.cv] 21 Nov 2016](/thumbs/76/73850250.jpg "arxiv: v2 [cs.cv] 21 Nov 2016") Context Encoders: Feature Learning by Inpainting Deepak Pathak Philipp Krähenbühl Jeff Donahue Trevor Darrell Alexei A. Efros University of California, Berkeley {pathak,philkr,jdonahue,trevor,efros}@cs.berkeley.edu
Context Encoders: Feature Learning by Inpainting Deepak Pathak Philipp Krähenbühl Jeff Donahue Trevor Darrell Alexei A. Efros University of California, Berkeley {pathak,philkr,jdonahue,trevor,efros}@cs.berkeley.edu
List of Accepted Papers for ICVGIP 2018
 List of Accepted Papers for ICVGIP 2018 Paper ID ACM Article Title 3 1 PredGAN - A deep multi-scale video prediction framework for anomaly detection in videos 7 2 Handwritten Essay Grading on Mobiles using
List of Accepted Papers for ICVGIP 2018 Paper ID ACM Article Title 3 1 PredGAN - A deep multi-scale video prediction framework for anomaly detection in videos 7 2 Handwritten Essay Grading on Mobiles using
Geodesic Flow Kernel for Unsupervised Domain Adaptation
 Geodesic Flow Kernel for Unsupervised Domain Adaptation Boqing Gong University of Southern California Joint work with Yuan Shi, Fei Sha, and Kristen Grauman 1 Motivation TRAIN TEST Mismatch between different
Geodesic Flow Kernel for Unsupervised Domain Adaptation Boqing Gong University of Southern California Joint work with Yuan Shi, Fei Sha, and Kristen Grauman 1 Motivation TRAIN TEST Mismatch between different
Bilinear Models for Fine-Grained Visual Recognition
 Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Attributes. Computer Vision. James Hays. Many slides from Derek Hoiem
 Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Lecture 12 Recognition. Davide Scaramuzza
 Lecture 12 Recognition Davide Scaramuzza Oral exam dates UZH January 19-20 ETH 30.01 to 9.02 2017 (schedule handled by ETH) Exam location Davide Scaramuzza s office: Andreasstrasse 15, 2.10, 8050 Zurich
Lecture 12 Recognition Davide Scaramuzza Oral exam dates UZH January 19-20 ETH 30.01 to 9.02 2017 (schedule handled by ETH) Exam location Davide Scaramuzza s office: Andreasstrasse 15, 2.10, 8050 Zurich
arxiv: v2 [cs.cv] 28 Sep 2015
![arxiv: v2 [cs.cv] 28 Sep 2015](/thumbs/74/70012825.jpg "arxiv: v2 [cs.cv] 28 Sep 2015") Unsupervised Visual Representation Learning by Context Prediction Carl Doersch 1,2 Abhinav Gupta 1 Alexei A. Efros 2 1 School of Computer Science 2 Dept. of Electrical Engineering and Computer Science
Unsupervised Visual Representation Learning by Context Prediction Carl Doersch 1,2 Abhinav Gupta 1 Alexei A. Efros 2 1 School of Computer Science 2 Dept. of Electrical Engineering and Computer Science
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Class 5: Attributes and Semantic Features
 Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Large-Scale Live Active Learning: Training Object Detectors with Crawled Data and Crowds
 Large-Scale Live Active Learning: Training Object Detectors with Crawled Data and Crowds Sudheendra Vijayanarasimhan Kristen Grauman Department of Computer Science University of Texas at Austin Austin,
Large-Scale Live Active Learning: Training Object Detectors with Crawled Data and Crowds Sudheendra Vijayanarasimhan Kristen Grauman Department of Computer Science University of Texas at Austin Austin,
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Copyright by Yong Jae Lee 2012
 Copyright by Yong Jae Lee 2012 The Dissertation Committee for Yong Jae Lee certifies that this is the approved version of the following dissertation: Visual Object Category Discovery in Images and Videos
Copyright by Yong Jae Lee 2012 The Dissertation Committee for Yong Jae Lee certifies that this is the approved version of the following dissertation: Visual Object Category Discovery in Images and Videos
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
R-FCN: Object Detection with Really - Friggin Convolutional Networks
 R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
Painting-to-3D Model Alignment Via Discriminative Visual Elements. Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA)
 Bryan Russell (Intel) Josef Sivic (INRIA)") Painting-to-3D Model Alignment Via Discriminative Visual Elements Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA) This work Browsing across time 1699 1740 1750 1800 1800 1699 1740 1750
Painting-to-3D Model Alignment Via Discriminative Visual Elements Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA) This work Browsing across time 1699 1740 1750 1800 1800 1699 1740 1750
Storyline Reconstruction for Unordered Images
 Introduction: Storyline Reconstruction for Unordered Images Final Paper Sameedha Bairagi, Arpit Khandelwal, Venkatesh Raizaday Storyline reconstruction is a relatively new topic and has not been researched
Introduction: Storyline Reconstruction for Unordered Images Final Paper Sameedha Bairagi, Arpit Khandelwal, Venkatesh Raizaday Storyline reconstruction is a relatively new topic and has not been researched
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance
 Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Single Image Super-resolution. Slides from Libin Geoffrey Sun and James Hays
 Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Single Image Super-resolution Slides from Libin Geoffrey Sun and James Hays Cs129 Computational Photography James Hays, Brown, fall 2012 Types of Super-resolution Multi-image (sub-pixel registration) Single-image
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
ACM MM Dong Liu, Shuicheng Yan, Yong Rui and Hong-Jiang Zhang
 ACM MM 2010 Dong Liu, Shuicheng Yan, Yong Rui and Hong-Jiang Zhang Harbin Institute of Technology National University of Singapore Microsoft Corporation Proliferation of images and videos on the Internet
ACM MM 2010 Dong Liu, Shuicheng Yan, Yong Rui and Hong-Jiang Zhang Harbin Institute of Technology National University of Singapore Microsoft Corporation Proliferation of images and videos on the Internet
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014
 Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
A Deep Learning Approach to Vehicle Speed Estimation
 A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation