End-to-End Localization and Ranking for Relative Attributes
|
|
|
- Roderick Knight
- 5 years ago
- Views:
Transcription


1 End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee Presented by Minhao Cheng


![Lee, ICCV 2015] Berg et](/docs-images/86/94553651/images/2-2.jpg "al. 2010, Rastegari et")
![al. 2012, ] Visual](/docs-images/86/94553651/images/2-3.jpg "attributes High heel")
2 [Farhadi et al. 2009, Kumar et al. 2009, Lampert et al. 2009, [Slide: Xiao and Lee, ICCV 2015] Berg et al. 2010, Rastegari et al. 2012, ] Visual attributes High heel Smile Cozy Mountainous

![[Slide: Xiao and Lee, ICCV 2015] [Parikh & Grauman 2011,](/docs-images/86/94553651/images/3-1.jpg "Shrivastava et al. 2012, Kovashka et al.")
3 Relative attributes < Is she smiling? Hard to say... Lot easier to say "the right one is more smiling" [Slide: Xiao and Lee, ICCV 2015] [Parikh & Grauman 2011, Shrivastava et al. 2012, Kovashka et al. 2013, Sandeep et al. 2014, ]


![Lee, ICCV 2015]](/docs-images/86/94553651/images/4-2.jpg "Spatial regions")

4 Localization of attributes Cozy Smile Mountainous [Slide: Xiao and Lee, ICCV 2015] Spatial regions that are most relevant to a particular attribute



![2014] Requires strong human](/docs-images/86/94553651/images/5-3.jpg "supervision or binary attribute")


![ICCV 2015] Attribute binary](/docs-images/86/94553651/images/5-6.jpg "attributes: [Berg et al.")
5 Prior work on localizing attributes Attribute localization with pre-trained detectors: [Bourdev et al. 2011, Zhang et al. 2014, Sandeep et al. 2014] Requires strong human supervision or binary attribute annotations Attribute localization with human-in-the-loop: [Duan et al. 2012] [Slide: Xiao and Lee, ICCV 2015] Attribute localization with binary attributes: [Berg et al. 2010, Bourdev et al. 2011, Duan et al. 2012, Zhang et al. 2014]
![Prior work on localizing attributes [Slide: Xiao and Lee, ICCV 2015] Attribute localization in weakly-supervised setting: [Xiao](/docs-images/86/94553651/images/6-0.jpg "and Lee, ICCV 2015] Pipeline where features, localizer, and classifier are trained separately and sequentially; suboptimal and")
6 Prior work on localizing attributes [Slide: Xiao and Lee, ICCV 2015] Attribute localization in weakly-supervised setting: [Xiao and Lee, ICCV 2015] Pipeline where features, localizer, and classifier are trained separately and sequentially; suboptimal and slow
7 End-to-end network for attribute localization and ranking Our idea: jointly learn features, localizer, and ranker end-to-end using deep network [Singh and Lee, ECCV 2016]
8 End-to-end network for attribute localization and ranking Our idea: jointly learn features, localizer, and classifier end-to-end using deep network Attribute: Smile Training Training pairs [Singh and Lee, ECCV 2016]
9 End-to-end network for attribute localization and ranking Our idea: jointly learn features, localizer, and classifier end-to-end using deep network Attribute: Smile Training Training pairs Weak Strong Testing Test images
![[Singh and Lee, ECCV 2016] Overview of our](/docs-images/86/94553651/images/10-1.jpg "end-to-end approach Goal: Given pairs of ordered")

 Loss Function I 2 Localization")
10 [Singh and Lee, ECCV 2016] Overview of our end-to-end approach Goal: Given pairs of ordered training images, simultaneously localize attribute in each image and learn a ranker Attribute: Smile I 1 Localization Ranker V 1 Siamese (S 1 ) Loss Function I 2 Localization Ranker V 2 Siamese (S 2 )
11 Our end-to-end approach 96 θ Grid generator V Localization I Ranker [Singh and Lee, ECCV 2016]
12 Our end-to-end approach 96 θ Grid generator Localization I Localization network discovers the region-of-interest for the attribute Learn transformation parameters mapping input to output Spatial Transformer s [Jaderberg et al. 2014] [Singh and Lee, ECCV 2016]
13 Our end-to-end approach 96 θ Grid generator Localization 8192 V 1 I Ranker Ranker network takes the localized region to produce a ranking score Combine the global image for global context [Singh and Lee, ECCV 2016]
14 [Singh and Lee, ECCV 2016] Training Attribute: Smile I 1 Localization Ranker V 1 Siamese (S 1 ) Loss Function I 2 Localization Ranker V 2 Siamese (S 2 ) Cross entropy:
15 [Singh and Lee, ECCV 2016] Training Attribute: Smile I 1 Localization Ranker V 1 Siamese (S 1 ) Loss Function I 2 Localization Ranker V 2 Siamese (S 2 ) Localized region can fall outside image bounds making learning difficult
16 [Singh and Lee, ECCV 2016] Training Attribute: Smile I 1 Localization Ranker V 1 Siamese (S 1 ) Loss Function I 2 Localization Ranker V 2 Siamese (S 2 ) Optimized using backpropagation, mini-batch Stochastic Gradient Descent

![2016]](/docs-images/86/94553651/images/17-1.jpg "Progression")







17 [Singh and Lee, ECCV 2016] Progression of localized region over training epochs Attribute: Dark hair Attribute: Smile Training epochs Heatmap: distribution of localized region across entire training dataset




18 Testing Localization Ranker V test Siamese (S 1 ) Test image Localize the relevant attribute region Produce a ranking score for the test image [Singh and Lee, ECCV 2016]












19 Experiments: Relative attribute datasets LFW-10 (2k images) [Sandeep et al., CVPR 2014] UTZappos50k (50k images) [Yu & Grauman, CVPR 2014] Visible teeth, Eyes open, Dark hair, Smile, Good looking... [Singh and Lee, ECCV 2016] Pointy, Open, Sporty, Comfort








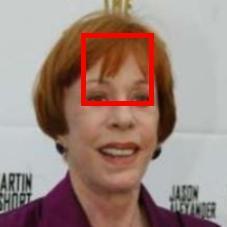















20 Results: Discovered regions and ranking on LFW-10 Faces Weak Strong Smile Bald Dark hair Eyes open Our network discovers relevant attribute regions Leads to accurate rankings














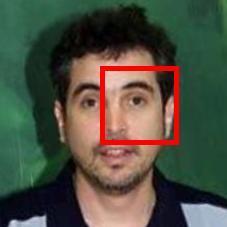
21 Results: Discovered regions and ranking on LFW-10 Faces Weak Strong Good looking Masculine Young [Singh and Lee, ECCV 2016] Global attributes are harder to interpret Focus more on larger areas



















22 [Singh and Lee, ECCV 2016] Results: Discovered regions and ranking UT-Zap50K Shoes Weak Strong Comfort Open Pointy Sporty
23 Results: Image pair ranking accuracy % of test image pairs whose predicted relative attribute ranking is correct State-of-the-art results on LFW-10, UT-Zap50K, OSR, Shoe-with-Attribute Combing global image context w/ localized fine-grained information performs best [Singh and Lee, ECCV 2016]
24 Conclusions Novel end-to-end network for ranking and localizing attributes. State-of-the-art performance on the attribute ranking performance on benchmark face, shoe, and outdoor scene datasets. Our Our approach is 100 times faster than [Xiao & Lee].
25 Question What if we can use multiple localization network instead of one to help to get a better performance? (like we can use the eye s feature to help ranking the smile attribute as well)
End-to-End Localization and Ranking for Relative Attributes
 End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee University of California, Davis Abstract. We propose an end-to-end deep convolutional network to simultaneously
End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee University of California, Davis Abstract. We propose an end-to-end deep convolutional network to simultaneously
arxiv: v1 [cs.cv] 9 Aug 2016
![arxiv: v1 [cs.cv] 9 Aug 2016](/thumbs/87/96312199.jpg "arxiv: v1 [cs.cv] 9 Aug 2016") arxiv:1608.02676v1 [cs.cv] 9 Aug 2016 End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee University of California, Davis Abstract. We propose an end-to-end
arxiv:1608.02676v1 [cs.cv] 9 Aug 2016 End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee University of California, Davis Abstract. We propose an end-to-end
Localizing and Visualizing Relative Attributes
 Localizing and Visualizing Relative Attributes Fanyi Xiao and Yong Jae Lee Abstract In this chapter, we present a weakly-supervised approach that discovers the spatial extent of relative attributes, given
Localizing and Visualizing Relative Attributes Fanyi Xiao and Yong Jae Lee Abstract In this chapter, we present a weakly-supervised approach that discovers the spatial extent of relative attributes, given
Interactive Image Search with Attributes
 Interactive Image Search with Attributes Adriana Kovashka Department of Computer Science January 13, 2015 Joint work with Kristen Grauman and Devi Parikh We Need Search to Access Visual Data 144,000 hours
Interactive Image Search with Attributes Adriana Kovashka Department of Computer Science January 13, 2015 Joint work with Kristen Grauman and Devi Parikh We Need Search to Access Visual Data 144,000 hours
CS 1674: Intro to Computer Vision. Attributes. Prof. Adriana Kovashka University of Pittsburgh November 2, 2016
 CS 1674: Intro to Computer Vision Attributes Prof. Adriana Kovashka University of Pittsburgh November 2, 2016 Plan for today What are attributes and why are they useful? (paper 1) Attributes for zero-shot
CS 1674: Intro to Computer Vision Attributes Prof. Adriana Kovashka University of Pittsburgh November 2, 2016 Plan for today What are attributes and why are they useful? (paper 1) Attributes for zero-shot
Discovering the Spatial Extent of Relative Attributes
 Discovering the Spatial Extent of Relative Attributes Fanyi Xiao and Yong Jae Lee University of California, Davis {fanyix,yjlee}@cs.ucdavis.edu Abstract We present a weakly-supervised approach that discovers
Discovering the Spatial Extent of Relative Attributes Fanyi Xiao and Yong Jae Lee University of California, Davis {fanyix,yjlee}@cs.ucdavis.edu Abstract We present a weakly-supervised approach that discovers
arxiv: v2 [cs.cv] 13 Apr 2018
![arxiv: v2 [cs.cv] 13 Apr 2018](/thumbs/94/118449118.jpg "arxiv: v2 [cs.cv] 13 Apr 2018") Compare and Contrast: Learning Prominent Visual Differences Steven Chen Kristen Grauman The University of Texas at Austin Abstract arxiv:1804.00112v2 [cs.cv] 13 Apr 2018 Relative attribute models can compare
Compare and Contrast: Learning Prominent Visual Differences Steven Chen Kristen Grauman The University of Texas at Austin Abstract arxiv:1804.00112v2 [cs.cv] 13 Apr 2018 Relative attribute models can compare
Class 5: Attributes and Semantic Features
 Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Shifting from Naming to Describing: Semantic Attribute Models. Rogerio Feris, June 2014
 Shifting from Naming to Describing: Semantic Attribute Models Rogerio Feris, June 2014 Recap Large-Scale Semantic Modeling Feature Coding and Pooling Low-Level Feature Extraction Training Data Slide credit:
Shifting from Naming to Describing: Semantic Attribute Models Rogerio Feris, June 2014 Recap Large-Scale Semantic Modeling Feature Coding and Pooling Low-Level Feature Extraction Training Data Slide credit:
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Compare and Contrast: Learning Prominent Differences in Relative Attributes. Steven Ziqiu Chen
 Compare and Contrast: Learning Prominent Differences in Relative Attributes by Steven Ziqiu Chen stevenchen@utexas.edu Supervised by: Dr. Kristen Grauman Department of Computer Science Abstract Relative
Compare and Contrast: Learning Prominent Differences in Relative Attributes by Steven Ziqiu Chen stevenchen@utexas.edu Supervised by: Dr. Kristen Grauman Department of Computer Science Abstract Relative
Deep neural networks II
 Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
arxiv: v2 [cs.cv] 23 May 2016
![arxiv: v2 [cs.cv] 23 May 2016](/thumbs/88/115196824.jpg "arxiv: v2 [cs.cv] 23 May 2016") Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Describable Visual Attributes for Face Verification and Image Search
 Advanced Topics in Multimedia Analysis and Indexing, Spring 2011, NTU. 1 Describable Visual Attributes for Face Verification and Image Search Kumar, Berg, Belhumeur, Nayar. PAMI, 2011. Ryan Lei 2011/05/05
Advanced Topics in Multimedia Analysis and Indexing, Spring 2011, NTU. 1 Describable Visual Attributes for Face Verification and Image Search Kumar, Berg, Belhumeur, Nayar. PAMI, 2011. Ryan Lei 2011/05/05
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation. Deepak Pathak, Philipp Krähenbühl and Trevor Darrell
 Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Experiments of Image Retrieval Using Weak Attributes
 Columbia University Computer Science Department Technical Report # CUCS 005-12 (2012) Experiments of Image Retrieval Using Weak Attributes Felix X. Yu, Rongrong Ji, Ming-Hen Tsai, Guangnan Ye, Shih-Fu
Columbia University Computer Science Department Technical Report # CUCS 005-12 (2012) Experiments of Image Retrieval Using Weak Attributes Felix X. Yu, Rongrong Ji, Ming-Hen Tsai, Guangnan Ye, Shih-Fu
Semantic Jitter: Dense Supervision for Visual Comparisons via Synthetic Images
 In Proceedings of the International Conference on Computer Vision (ICCV), 2017 Semantic Jitter: Dense Supervision for Visual Comparisons via Synthetic Images Aron Yu University of Texas at Austin aron.yu@utexas.edu
In Proceedings of the International Conference on Computer Vision (ICCV), 2017 Semantic Jitter: Dense Supervision for Visual Comparisons via Synthetic Images Aron Yu University of Texas at Austin aron.yu@utexas.edu
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
DeepFace: Closing the Gap to Human-Level Performance in Face Verification
 DeepFace: Closing the Gap to Human-Level Performance in Face Verification Report on the paper Artem Komarichev February 7, 2016 Outline New alignment technique New DNN architecture New large dataset with
DeepFace: Closing the Gap to Human-Level Performance in Face Verification Report on the paper Artem Komarichev February 7, 2016 Outline New alignment technique New DNN architecture New large dataset with
Attributes and More Crowdsourcing
 Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015)
") AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY
 MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
Dimensionality Reduction using Relative Attributes
 Dimensionality Reduction using Relative Attributes Mohammadreza Babaee 1, Stefanos Tsoukalas 1, Maryam Babaee Gerhard Rigoll 1, and Mihai Datcu 1 Institute for Human-Machine Communication, Technische Universität
Dimensionality Reduction using Relative Attributes Mohammadreza Babaee 1, Stefanos Tsoukalas 1, Maryam Babaee Gerhard Rigoll 1, and Mihai Datcu 1 Institute for Human-Machine Communication, Technische Universität
ECS 289H: Visual Recognition Fall Yong Jae Lee Department of Computer Science
 ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science Plan for today Questions? Research overview Standard supervised visual learning building Category models Annotators tree
ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science Plan for today Questions? Research overview Standard supervised visual learning building Category models Annotators tree
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Self-Supervised Learning & Visual Discovery
 CS 2770: Computer Vision Self-Supervised Learning & Visual Discovery Prof. Adriana Kovashka University of Pittsburgh April 10, 2017 Motivation So far we ve assumed access to plentiful labeled data How
CS 2770: Computer Vision Self-Supervised Learning & Visual Discovery Prof. Adriana Kovashka University of Pittsburgh April 10, 2017 Motivation So far we ve assumed access to plentiful labeled data How
PATCH BASED LATENT FINGERPRINT MATCHING USING DEEP LEARNING. Jude Ezeobiejesi and Bir Bhanu
 PATCH BASED LATENT FINGERPRINT MATCHING USING DEEP LEARNING Jude Ezeobiejesi and Bir Bhanu Center for Research in Intelligent Systems University of California at Riverside, Riverside, CA 92521, USA e-mail:
PATCH BASED LATENT FINGERPRINT MATCHING USING DEEP LEARNING Jude Ezeobiejesi and Bir Bhanu Center for Research in Intelligent Systems University of California at Riverside, Riverside, CA 92521, USA e-mail:
Modern Object Detection. Most slides from Ali Farhadi
 Modern Object Detection Most slides from Ali Farhadi Comparison of Classifiers assuming x in {0 1} Learning Objective Training Inference Naïve Bayes maximize j i logp + logp ( x y ; θ ) ( y ; θ ) i ij
Modern Object Detection Most slides from Ali Farhadi Comparison of Classifiers assuming x in {0 1} Learning Objective Training Inference Naïve Bayes maximize j i logp + logp ( x y ; θ ) ( y ; θ ) i ij
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Attributes as Operators (Supplementary Material)
") In Proceedings of the European Conference on Computer Vision (ECCV), 2018 Attributes as Operators (Supplementary Material) This document consists of supplementary material to support the main paper text.
In Proceedings of the European Conference on Computer Vision (ECCV), 2018 Attributes as Operators (Supplementary Material) This document consists of supplementary material to support the main paper text.
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Adversarial Localization Network
 Adversarial Localization Network Lijie Fan Tsinghua University flj14@mails.tsinghua.edu.cn Shengjia Zhao Stanford University sjzhao@stanford.edu Stefano Ermon Stanford University ermon@stanford.edu Abstract
Adversarial Localization Network Lijie Fan Tsinghua University flj14@mails.tsinghua.edu.cn Shengjia Zhao Stanford University sjzhao@stanford.edu Stefano Ermon Stanford University ermon@stanford.edu Abstract
Predicting ground-level scene Layout from Aerial imagery. Muhammad Hasan Maqbool
 Predicting ground-level scene Layout from Aerial imagery Muhammad Hasan Maqbool Objective Given the overhead image predict its ground level semantic segmentation Predicted ground level labeling Overhead/Aerial
Predicting ground-level scene Layout from Aerial imagery Muhammad Hasan Maqbool Objective Given the overhead image predict its ground level semantic segmentation Predicted ground level labeling Overhead/Aerial
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
24 hours of Photo Sharing. installation by Erik Kessels
 24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE. Chubu University 1200, Matsumoto-cho, Kasugai, AICHI
 FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
Improving Face Recognition by Exploring Local Features with Visual Attention
 Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University Difficulties of Face Recognition Large variations in unconstrained face
Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University Difficulties of Face Recognition Large variations in unconstrained face
VISION & LANGUAGE From Captions to Visual Concepts and Back
 VISION & LANGUAGE From Captions to Visual Concepts and Back Brady Fowler & Kerry Jones Tuesday, February 28th 2017 CS 6501-004 VICENTE Agenda Problem Domain Object Detection Language Generation Sentence
VISION & LANGUAGE From Captions to Visual Concepts and Back Brady Fowler & Kerry Jones Tuesday, February 28th 2017 CS 6501-004 VICENTE Agenda Problem Domain Object Detection Language Generation Sentence
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Weakly Supervised Facial Attribute Manipulation via Deep Adversarial Network
 2018 IEEE Winter Conference on Applications of Computer Vision Weakly Supervised Facial Attribute Manipulation via Deep Adversarial Network Yilin Wang 1 Suhang Wang 1 Guojun Qi 2 Jiliang Tang 3 Baoxin
2018 IEEE Winter Conference on Applications of Computer Vision Weakly Supervised Facial Attribute Manipulation via Deep Adversarial Network Yilin Wang 1 Suhang Wang 1 Guojun Qi 2 Jiliang Tang 3 Baoxin
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Fully-Convolutional Siamese Networks for Object Tracking
 Fully-Convolutional Siamese Networks for Object Tracking Luca Bertinetto*, Jack Valmadre*, João Henriques, Andrea Vedaldi and Philip Torr www.robots.ox.ac.uk/~luca luca.bertinetto@eng.ox.ac.uk Tracking
Fully-Convolutional Siamese Networks for Object Tracking Luca Bertinetto*, Jack Valmadre*, João Henriques, Andrea Vedaldi and Philip Torr www.robots.ox.ac.uk/~luca luca.bertinetto@eng.ox.ac.uk Tracking
DEEP LEARNING IN PYTHON. The need for optimization
 DEEP LEARNING IN PYTHON The need for optimization A baseline neural network Input 2 Hidden Layer 5 2 Output - 9-3 Actual Value of Target: 3 Error: Actual - Predicted = 4 A baseline neural network Input
DEEP LEARNING IN PYTHON The need for optimization A baseline neural network Input 2 Hidden Layer 5 2 Output - 9-3 Actual Value of Target: 3 Error: Actual - Predicted = 4 A baseline neural network Input
Attributes. Computer Vision. James Hays. Many slides from Derek Hoiem
 Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CNN for Low Level Image Processing. Huanjing Yue
 CNN for Low Level Image Processing Huanjing Yue 2017.11 1 Deep Learning for Image Restoration General formulation: min Θ L( x, x) s. t. x = F(y; Θ) Loss function Parameters to be learned Key issues The
CNN for Low Level Image Processing Huanjing Yue 2017.11 1 Deep Learning for Image Restoration General formulation: min Θ L( x, x) s. t. x = F(y; Θ) Loss function Parameters to be learned Key issues The
Fully-Convolutional Siamese Networks for Object Tracking
 Fully-Convolutional Siamese Networks for Object Tracking Luca Bertinetto*, Jack Valmadre*, João Henriques, Andrea Vedaldi and Philip Torr www.robots.ox.ac.uk/~luca luca.bertinetto@eng.ox.ac.uk Tracking
Fully-Convolutional Siamese Networks for Object Tracking Luca Bertinetto*, Jack Valmadre*, João Henriques, Andrea Vedaldi and Philip Torr www.robots.ox.ac.uk/~luca luca.bertinetto@eng.ox.ac.uk Tracking
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Learning image representations equivariant to ego-motion (Supplementary material)
") Learning image representations equivariant to ego-motion (Supplementary material) Dinesh Jayaraman UT Austin dineshj@cs.utexas.edu Kristen Grauman UT Austin grauman@cs.utexas.edu max-pool (3x3, stride2)
Learning image representations equivariant to ego-motion (Supplementary material) Dinesh Jayaraman UT Austin dineshj@cs.utexas.edu Kristen Grauman UT Austin grauman@cs.utexas.edu max-pool (3x3, stride2)
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Development in Object Detection. Junyuan Lin May 4th
 Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Input. Output. Problem Definition. Rectified stereo image pair All correspondences lie in same scan lines
 Problem Definition 3 Input Rectified stereo image pair All correspondences lie in same scan lines Output Disparity map of the reference view Foreground: large disparity Background: small disparity Matching
Problem Definition 3 Input Rectified stereo image pair All correspondences lie in same scan lines Output Disparity map of the reference view Foreground: large disparity Background: small disparity Matching
Asking Friendly Strangers: Non-Semantic Attribute Transfer
 Asking Friendly Strangers: Non-Semantic Attribute Transfer Nils Murrugarra-Llerena and Adriana Kovashka Department of Computer Science University of Pittsburgh {nineil, kovashka}@cs.pitt.edu Abstract Attributes
Asking Friendly Strangers: Non-Semantic Attribute Transfer Nils Murrugarra-Llerena and Adriana Kovashka Department of Computer Science University of Pittsburgh {nineil, kovashka}@cs.pitt.edu Abstract Attributes
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
 Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature Extraction SUPPLEMENTAL MATERIAL
 Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature Extraction SUPPLEMENTAL MATERIAL Edgar Simo-Serra Waseda University esimo@aoni.waseda.jp Hiroshi Ishikawa Waseda
Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature Extraction SUPPLEMENTAL MATERIAL Edgar Simo-Serra Waseda University esimo@aoni.waseda.jp Hiroshi Ishikawa Waseda
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Spoken Attributes: Mixing Binary and Relative Attributes to Say the Right Thing
 Spoken ttributes: Mixing inary and Relative ttributes to Say the Right Thing mir Sadovnik Cornell University as2373@cornell.edu ndrew Gallagher Cornell University acg226@cornell.edu Devi Parikh Virginia
Spoken ttributes: Mixing inary and Relative ttributes to Say the Right Thing mir Sadovnik Cornell University as2373@cornell.edu ndrew Gallagher Cornell University acg226@cornell.edu Devi Parikh Virginia
POOF: Part-Based One-vs-One Features for Fine-Grained Categorization, Face Verification, and Attribute Estimation
 2013 IEEE Conference on Computer Vision and Pattern Recognition POOF: Part-Based One-vs-One Features for Fine-Grained Categorization, Face Verification, and Attribute Estimation Thomas Berg Columbia University
2013 IEEE Conference on Computer Vision and Pattern Recognition POOF: Part-Based One-vs-One Features for Fine-Grained Categorization, Face Verification, and Attribute Estimation Thomas Berg Columbia University
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Attribute Pivots for Guiding Relevance Feedback in Image Search
 In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2013. Attribute Pivots for Guiding Relevance Feedback in Image Search Adriana Kovashka Kristen Grauman The University of Texas
In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2013. Attribute Pivots for Guiding Relevance Feedback in Image Search Adriana Kovashka Kristen Grauman The University of Texas
Towards Weakly- and Semi- Supervised Object Localization and Semantic Segmentation
 Towards Weakly- and Semi- Supervised Object Localization and Semantic Segmentation Lecturer: Yunchao Wei Image Formation and Processing (IFP) Group University of Illinois at Urbanahttps://weiyc.githu Champaign
Towards Weakly- and Semi- Supervised Object Localization and Semantic Segmentation Lecturer: Yunchao Wei Image Formation and Processing (IFP) Group University of Illinois at Urbanahttps://weiyc.githu Champaign
Multi-resolution-Tract CNN with Hybrid Pretrained and Skin-Lesion Trained Layers
 Multi-resolution-Tract CNN with Hybrid Pretrained and Skin-Lesion Trained Layers Jeremy Kawahara, and Ghassan Hamarneh Medical Image Analysis Lab, Simon Fraser University, Burnaby, Canada {jkawahar,hamarneh}@sfu.ca
Multi-resolution-Tract CNN with Hybrid Pretrained and Skin-Lesion Trained Layers Jeremy Kawahara, and Ghassan Hamarneh Medical Image Analysis Lab, Simon Fraser University, Burnaby, Canada {jkawahar,hamarneh}@sfu.ca
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Scene Text Recognition for Augmented Reality. Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science
 Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK
 FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
YOLO 9000 TAEWAN KIM
 YOLO 9000 TAEWAN KIM DNN-based Object Detection R-CNN MultiBox SPP-Net DeepID-Net NoC Fast R-CNN DeepBox MR-CNN 2013.11 Faster R-CNN YOLO AttentionNet DenseBox SSD Inside-OutsideNet(ION) G-CNN NIPS 15
YOLO 9000 TAEWAN KIM DNN-based Object Detection R-CNN MultiBox SPP-Net DeepID-Net NoC Fast R-CNN DeepBox MR-CNN 2013.11 Faster R-CNN YOLO AttentionNet DenseBox SSD Inside-OutsideNet(ION) G-CNN NIPS 15
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Interactively Guiding Semi-Supervised Clustering via Attribute-based Explanations
 Interactively Guiding Semi-Supervised Clustering via Attribute-based Explanations Shrenik Lad and Devi Parikh Virginia Tech Abstract. Unsupervised image clustering is a challenging and often illposed problem.
Interactively Guiding Semi-Supervised Clustering via Attribute-based Explanations Shrenik Lad and Devi Parikh Virginia Tech Abstract. Unsupervised image clustering is a challenging and often illposed problem.
Deep Learning for Visual Manipulation and Synthesis
 Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
Xiaowei Hu* Lei Zhu* Chi-Wing Fu Jing Qin Pheng-Ann Heng
 Direction-aware Spatial Context Features for Shadow Detection Xiaowei Hu* Lei Zhu* Chi-Wing Fu Jing Qin Pheng-Ann Heng The Chinese University of Hong Kong The Hong Kong Polytechnic University Shenzhen
Direction-aware Spatial Context Features for Shadow Detection Xiaowei Hu* Lei Zhu* Chi-Wing Fu Jing Qin Pheng-Ann Heng The Chinese University of Hong Kong The Hong Kong Polytechnic University Shenzhen
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
FACE ATTRIBUTE CLASSIFICATION USING ATTRIBUTE-AWARE CORRELATION MAP AND GATED CONVOLUTIONAL NEURAL NETWORKS
 FACE ATTRIBUTE CLASSIFICATION USING ATTRIBUTE-AWARE CORRELATION MAP AND GATED CONVOLUTIONAL NEURAL NETWORKS Sunghun Kang, Donghoon Lee, and Chang D. Yoo Korea Advanced institute of Science and Technology
FACE ATTRIBUTE CLASSIFICATION USING ATTRIBUTE-AWARE CORRELATION MAP AND GATED CONVOLUTIONAL NEURAL NETWORKS Sunghun Kang, Donghoon Lee, and Chang D. Yoo Korea Advanced institute of Science and Technology
Temporal HeartNet: Towards Human-Level Automatic Analysis of Fetal Cardiac Screening Video
 Temporal HeartNet: Towards Human-Level Automatic Analysis of Fetal Cardiac Screening Video Weilin Huang, Christopher P. Bridge, J. Alison Noble, and Andrew Zisserman Department of Engineering Science,
Temporal HeartNet: Towards Human-Level Automatic Analysis of Fetal Cardiac Screening Video Weilin Huang, Christopher P. Bridge, J. Alison Noble, and Andrew Zisserman Department of Engineering Science,
Computer Vision: Summary and Discussion
 12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
ImageNet Classification with Deep Convolutional Neural Networks
 ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset
 LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015
 on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015 Vector visual representation Fixed-size image representation High-dim (100 100,000) Generic, unsupervised: BoW,
on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015 Vector visual representation Fixed-size image representation High-dim (100 100,000) Generic, unsupervised: BoW,
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition Xiao Liu, Jiang Wang,
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition Xiao Liu, Jiang Wang,
Unsupervised Learning of Spatiotemporally Coherent Metrics
 Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Speaker: Ming-Ming Cheng Nankai University 15-Sep-17 Towards Weakly Supervised Image Understanding
 Towards Weakly Supervised Image Understanding (WSIU) Speaker: Ming-Ming Cheng Nankai University http://mmcheng.net/ 1/50 Understanding Visual Information Image by kirkh.deviantart.com 2/50 Dataset Annotation
Towards Weakly Supervised Image Understanding (WSIU) Speaker: Ming-Ming Cheng Nankai University http://mmcheng.net/ 1/50 Understanding Visual Information Image by kirkh.deviantart.com 2/50 Dataset Annotation
FAce detection is an important and long-standing problem in
 1 Faceness-Net: Face Detection through Deep Facial Part Responses Shuo Yang, Ping Luo, Chen Change Loy, Senior Member, IEEE and Xiaoou Tang, Fellow, IEEE arxiv:11.08393v3 [cs.cv] 25 Aug 2017 Abstract We
1 Faceness-Net: Face Detection through Deep Facial Part Responses Shuo Yang, Ping Luo, Chen Change Loy, Senior Member, IEEE and Xiaoou Tang, Fellow, IEEE arxiv:11.08393v3 [cs.cv] 25 Aug 2017 Abstract We
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution