Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
|
|
|
- Gary Robertson
- 5 years ago
- Views:
Transcription
 Carnegie Mellon University Abstract Unlike on images, semantic learning on 3D point clouds using a deep network is challenging")



1 Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling Yiru Shen Chen Feng Yaoqing Yang Dong Tian Clemson University Mitsubishi Electric Research Laboratories (MERL) Carnegie Mellon University Abstract Unlike on images, semantic learning on 3D point clouds using a deep network is challenging due to the naturally unordered data structure. Among existing works, Point- Net has achieved promising results by directly learning on point sets. However, it does not take full advantage of a point s local neighborhood that contains fine-grained structural information which turns out to be helpful towards better semantic learning. In this regard, we present two new operations to improve PointNet with a more efficient exploitation of local structures. The first one focuses on local 3D geometric structures. In analogy to a convolution kernel for images, we define a point-set kernel as a set of learnable 3D points that jointly respond to a set of neighboring data points according to their geometric affinities measured by kernel correlation, adapted from a similar technique for point cloud registration. The second one exploits local high-dimensional feature structures by recursive feature aggregation on a nearest-neighbor-graph computed from 3D positions. Experiments show that our network can efficiently capture local information and robustly achieve better performances on major datasets. Our code is available at license#kcnet 1. Introduction As 3D data become ubiquitous with the rapid development of various 3D sensors, semantic understanding and analysis of such kind of data using deep networks is gaining attentions [3, 20, 29, 32, 41], due to its wide applications in robotics, autonomous driving, reverse engineering, and civil infrastructure monitoring. In particular, as one of the most primitive 3D data format and often the raw 3D sensor output, 3D point clouds cannot be trivially consumed by deep networks in the same way as 2D images by convolutional networks. This is mainly caused by the irregular organization of points, a fundamental challenge inherent in this raw The authors contributed equally. This work is supported by MERL. Figure 1: Visualization of learned kernel correlations. To represent complex local geometric structures around a point p, we propose kernel correlation as an affinity measure between two point sets: p s neighboring points and kernel points. This figure shows kernel point positions and width as sphere centers and radius (top row), and the corresponding filter responses (other rows) of 5 kernels over 4 objects. Colors indicate affinities normalized in each object (red: strongest, white: weakest). Note the various structures (plane, edge, corner, concave and convex surfaces) captured by different kernels. Best viewed in color. data format: compared with a row-column indexed image, a point cloud is a set of point coordinates (possibly with attributes like intensities and surface normals) without obvious orderings between points, except for point clouds computed from depth images. Nevertheless, influenced by the success of convolutional networks for images, many works have focused on 3D voxels, i.e., regular 3D grids converted from point clouds prior to the learning process. Only then do the 3D convolutional networks learn to extract features from voxels [2, 7, 23, 25, 30, 42]. However, to avoid the intractable computation time complexity and memory consumptions, such 4548
2 N 3 N L N (L+3) N 192 N 1024 N (L+3) N 128 N 128 N 512 N 1024 N C Concatenation N 3 N L N (L+3) N 128 N 128 N 512 N 1024 N 128 N 512 Local Geometric Structure K-NN Graph Local Feature Structure Graph Max Pooling K-NN Graph Kernel Correlation (64) Graph Max Pooling (64) (128) Graph Max Pooling (128) (512) (1024) Global Max Pooling Kernel Correlation (64,64) (64,128) (1024) Global Max Pooling (512,256,C) Concatenation Concatenation Replication C (512,256,C) Concatenation (a) Classification network. Shape category (b) Segmentation network. Figure 2: Our KCNet architectures. Local geometric structures are exploited by the front-end kernel correlation layer computing L different affinities between each data point s K nearest neighbor points and L point-set kernels, each kernel containing M learnable 3D points. The resulting responses are concatenated with original 3D coordinates. Local feature structures are later exploited by graph pooling layers, sharing a same graph per 3D object instance constructed offline from each point s 3D Euclidean neighborhood. ReLU is used in each layer without Batchnorm. Dropout layers are used for the last s. Other operations and base network architectures are similar to PointNet [29] for both shape classification and part segmentation. Solid arrows indicate forward operation with backward propagation, while dashed arrows mean no backward propagation. Green boxes are input data, gray are intermediate variables, and blue are network predictions. We name our networks as KCNet for short. Best viewed in color. methods usually work on a small spatial resolution only, which results in quantization artifacts and difficulties to learn fine details of geometric structures, except for a few recent improvements using Octree [32, 41]. Different from convolutional nets, PointNet [29] provides an effective and simple architecture to directly learn on point sets by firstly computing individual point features from per-point Multi-Layer-Perceptron () and then aggregating all features as a global presentation of a point cloud. While achieving state-of-the-art results in different 3D semantic learning tasks, the direct aggregation from perpoint features to a global feature suggests that PointNet does not take full advantage of a point s local structure to capture fine-grained patterns: a per-point output only encodes roughly the existence of a 3D point in a certain nonlinear partition of the 3D space. A more discriminative representation is expected if the can encode not only whether a point exists, but also what type of (e.g., corner vs. planar, convex vs. concave, etc.) a point exists in the nonlinear 3D space partition. Such type information has to be learned from the point s local neighborhood on the 3D object surface, which is the main motivation of this paper. Attempting to address the above issue, PointNet++ [31] propose to segment a point set into smaller clusters, send each through a small PointNet, and repeat such a process iteratively for higher-dimensional feature point sets, which leads to a complicated architecture with reduced speed. Thus, we try to explore from a different direction: is there any efficient learnable local operations with clear geometric interpretations to help directly augment and improve the original PointNet while maintaining its simple architecture? To address this question, we focus on improving Point- Net using two new operations to exploit local geometric and feature structures, as depicted in Figure 2, regarding two classic supervised representation learning tasks on 3D point clouds. Our contributions are summarized as follows: We propose a kernel correlation layer to exploit local geometric structures, with a clear geometric interpretation (see Figure 1 and 3). We propose a graph-based pooling layer to exploit local feature structures to enhance network robustness. Our KCNet efficiently improves point cloud semantic learning performances using these two new operations. 2. Related Works 2.1. Local Geometric Properties We will first discuss some local geometric properties frequently used in 3D data and how they lead us to modify kernel correlation as a tool to enable potentially complex data-driven characterization of local geometric structures. Surface Normal. As a basic surface property, surface normals are heavily used in many areas including 3D shape reconstruction, plane extraction, and point set registration [5, 14, 28, 39, 40]. They usually come directly from CAD models or can be estimated by Principal Component Analysis (PCA) on data covariance matrix of neighboring points as the minimum variance direction [15]. Using perpoint surface normal in PointNet corresponds to modeling a point s local neighborhood as a plane, which is shown in [29, 31] to improve performances comparing with only 3D coordinates. This meets our previous expectation that a point s type along with its positions should enable better representation. Yet, this also leads us to a question: since normals can be estimated from 3D coordinates (not like colors or intensities), then why PointNet with only 3D coor- 4549
3 dinate input cannot learn to achieve the same performance? We believe it is due to the following: 1) the per-point cannot capture neighboring information from just 3D coordinates, and 2) global pooling either cannot or is not efficient enough to achieve that. Covariance Matrix. A second-order description of a local neighborhood is through data covariance matrix, which has also been widely used in cases such as plane extraction, curvature estimation [11,14] along with normals. Following the same line of thought from normals, the information provided by the local data covariance matrix is actually richer than normals as it models the local neighborhood as an ellipsoid, which includes lines and planes in rank-deficient cases. We also observe empirically that it is better than normals for semantic learning. However, both surface normals and covariance matrices can be seen as handcrafted and limited descriptions of local shapes, because point sets of completely different shapes can share a similar data covariance matrix. Naturally, to improve performances of both 3D semantic shape classification of fine-grained categories and 3D semantic segmentation, more detailed analysis of each point s local neighborhood is needed. Although PointNet++ [31] is one direct way to learn more discriminative descriptions, it might not be the most efficient solution. Instead, we would like to find a learnable local description that is efficient, simple, and has a clear geometric interpretation just as the above two handcrafted ones, so it can be directly plugged into the original elegant PointNet architecture. Kernel Correlation. Another widely used description is the similarity. For images, convolution (often implemented as cross-correlation) can quantify the similarity between an input image and a convolution kernel [21]. Yet in face of the aforementioned challenge of defining convolution on point clouds, how can we measure the correlation between two point sets? This question leads us to kernel correlation [17, 38] as such a tool. It has been shown that kernel correlation as a function of pairwise point distance is an efficient way to measure geometric affinity between 2D/3D point sets and has been used in point cloud registration and feature correspondence problems [17, 33, 38]. For registration, in particular, a source point cloud is transformed to best match a reference one by iteratively refining a rigid/non-rigid transformation between the two to maximize their kernel correlation response. Thus, we propose the kernel correlation layer to treat local neighboring points and a learnable point-set kernel as the source and reference respectively, which is further detailed in Section Deep Learning on Point Clouds Recently, deep learning on 3D input data, especially point clouds, attracts increasing research attention. There exist four groups of approaches: volumetric-based, patchbased, graph-based and point-based. Volumetric-based approach partitions the 3D space into regular voxels and apply 3D convolution on the voxels [2,7,23,25,30,42]. However, volumetric representation requires a high memory and computational cost to increase spatial resolution. Octree-based and kd-tree based networks have been introduced recently, but they could still suffer from the memory efficiency problem [20, 32, 41]. Patch-based approach parameterizes 3D surface into local patches and apply convolution over these patches [3, 24]. The advantage of this approach is the invariance to surface deformations. Yet it is non-trivial to generalize from mesh to point clouds [43]. Graph-based approach characterizes point clouds by graphs. Naturally, graph representation is flexible to irregular or even non- Euclidean data such as point clouds, user data on a social network, and gene data [1, 9, 18, 19, 26, 27, 27]. Therefore, a graph e.g. a connectivity graph or a polygon mesh can be used to represent a 3D point cloud, convert to the spectral representation and apply convolution in spectral domain [4, 8, 10, 13, 19, 22]. Another study also investigates convolution over edge attributes in the neighborhood of a vertex from graphs built on point clouds [34]. Pointbased approach such as PointNet directly operates on point clouds, with spatial features learned for each point, and global features obtained by aggregating over point features through max-pooling [29]. PointNet is simple yet efficient for the applications of shape classification and segmentation. However, global aggregation without explicitly considering local structures misses the opportunity to capture fine-grained patterns and suffers from sensitivity to noises. To further extend PointNet to local structures, we use a simple graph-based network: we construct k nearest neighbor graphs (KNNG) to utilize the neighborhood information for kernel correlation and to recursively conduct the max-pooling operations in each nodes neighborhood, with the insight that local points share similar geometric structures. KNNG is usually used to establish local connectivity information, in the applications of point cloud on surface detection, 3D object recognition, 3D object segmentation and compression [12, 35, 37]. 3. Method We now explain the details of learning local structures over point neighborhoods by 1) kernel correlation that measures the geometric affinity of point sets, and 2) a KNNG that propagates local features between neighboring points. Figure 2 illustrates our full network architectures Learning on Local Geometric Structure As mentioned earlier, in our network s front-end, we take inspiration from kernel correlation based point cloud registration and treat a point s local neighborhood as the source, and a set of learnable points, i.e., a kernel, as the 4550
 through backward propagation.")



![Specifically, we adapt ideas of the Leave-one-out Kernel Correlation (LOO-KC) and the multiply-linked registration cost function in [38] to capture local geometric structures of a point cloud.](/docs-images/87/95232917/images/4-7.jpg "Let us define our kernel correlation (KC) between a point-set kernel κ with M learnable points and the current anchor pointx i in a point cloud ofn points as: KC(κ,x i ) = 1 N(i) M m=1n N(i) K σ (κ")
4 reference that characterizes certain types of local geometric structures/shapes. We modify the original kernel correlation computation by allowing the reference to freely adjust its shape (kernel point positions) through backward propagation. Note the change of perspective here compared with point set registration: we want to learn template/reference shapes through a free per-point transformation, instead of using a fixed template to find an optimal transformation between source and reference point sets. In this way, a set of learnable kernel points is analogous to a convolutional kernel, which activates to points only in its joint neighboring regions and captures local geometric structures within this receptive field characterized by the kernel function and its kernel width. Under this setting, the learning process can be viewed as finding a set of reference/template points encoding the most effective and useful local geometric structures that lead to the best learning performance jointly with other parameters in the network. Specifically, we adapt ideas of the Leave-one-out Kernel Correlation (LOO-KC) and the multiply-linked registration cost function in [38] to capture local geometric structures of a point cloud. Let us define our kernel correlation (KC) between a point-set kernel κ with M learnable points and the current anchor pointx i in a point cloud ofn points as: KC(κ,x i ) = 1 N(i) M m=1n N(i) K σ (κ m,x n x i ), (1) where κ m is the m-th learnable point in the kernel, N(i) is the neighborhood index set of the anchor point x i, and x n is one of x i s neighbor point. K σ (, ) : R D R D R is any valid kernel function (D = 2 or 3 for 2D or 3D point clouds). To efficiently store the local neighborhood of points, we pre-compute a KNNG by considering each point as a vertex, with edges connecting only nearby vertices. Following [38], without loss of generality, we choose the Gaussian kernel in this paper: ) K σ (k,δ) = exp ( k δ 2 2σ 2 (2) where is the Euclidean distance between two points and σ is the kernel width that controls the influence of distance between points. One nice property of Gaussian kernel is that it decays exponentially as a function of the distance between the two points, providing a soft-assignment from each kernel point to neighboring points of the anchor point, relaxing from the non-differentiable hard-assignment in ordinary ICP. Our KC encodes pairwise distance between kernel points and neighboring data points and increases as two point sets become similar in shape, hence it can be clearly interpreted as a geometric similarity measure, and is invariant under translation. Note the importance of choosing kernel width here, since either a too large or a too small σ Figure 3: Visualization of handcrafted (linear, planar, and curved) kernels and responses, similar to Figure 1. L KC(κ,x i) will lead to undesired performances (see Table 6), similar to the same issue in kernel density estimation. Fortunately, for 2D or 3D space in our case, this parameter can be empirically chosen as the average neighbor distance in the neighborhood graphs over all training point clouds. To complete the description of the proposed new learnable layer, given 1) L as the network loss function, 2) its derivative w.r.t. each point x i s KC response d i = propagated back from top layers, we provide the backpropagation equation for each kernel pointκ m as: L κ m = N [ α i d i i=1 n N(i) v m,i,n exp( v m,i,n 2 ] 2σ 2 ), (3) where point x i s normalizing constant α i = 1 N(i) σ, and 2 the local difference vectorv m,i,n = κ m +x i x n. Although originates from LOO-KC in [38], our KC operation is different: 1) unlike LOO-KC as a compactness measure between a point set and one of its element point, our KC computes the similarity between a data point s neighborhood and a kernel of learnable points; and 2) unlike the multiply-linked cost function involving a parameter of a transformation for a fixed template, our KC allows all points in the kernel to freely move and adjust (i.e., no weight decay for κ), thus replacing the template and the transformation parameters as a point-set kernel. To better understand how KC captures various local geometric structures, we visualize several handcrafted kernels and corresponding KC responses on different objects in Figure 3. Similarly, we visualize several learned kernels from our segmentation network in Figure 1. Note that we can learn L different kernels in KCNet, where L is a hyperparameter similar to the number of output channels in convolutional nets. 4551
5 3.2. Learning on Local Feature Structure Our KCNet performs KC only in the network front-end to extract local geometric structure, as shown in Figure 2. For computing KC, to efficiently store the local neighborhood of points, we build a KNNG by considering each point as a vertex, with edges connecting only nearby points. This graph is also useful for exploiting local feature structures in deeper layers. Inspired by the ability of convolutional nets to locally aggregate features and gradually increase receptive fields via multiple pooling layers, we use recursive feature propagation and aggregation along edges of the very same 3D neighborhood graph for KC, to exploit local feature structures in the top layers. Our key insight is that neighbor points tend to have similar geometric structures and hence propagating features through neighborhood graph helps to learn more robust local patterns. Note that we specifically avoid changing this neighborhood graph structure in top layers, which is also analogous to convolution on images: each pixel s spatial ordering and neighborhoods remain unchanged even when feature channels of input image expand greatly in top convolutional layers. Specifically, letx R N K represent input to the graph pooling layer, and the KNNG has an adjacency matrixw R N N where W(i,j) = 1 if there exists an edge between vertex i and j, and W(i,j) = 0 otherwise. It is intuitive that neighboring points forming local surface often share similar feature patterns. Therefore, we aggregate features of each point within its neighborhood by a graph pooling operation: Y = PX, (4) which can be implemented as average or max pooling. Graph average pooling averages a point s features over its neighborhood by using P R N N in (4) as a normalized adjacency matrix: P = D 1 W, (5) where D R N N is the degree matrix with (i,j)-th entry d i,j defined as: { deg(i), if i = j d i,j = (6) 0, otherwise where deg(i) is the degree of vertex i counting the number of vertices connected to vertexi. Graph max pooling (GM) takes maximum features over the neighborhood of each vertex, independently operated over each of the K dimensions. This can be simply computed by replacing the + operator in the matrix multiplication in (4) with a max operator. Thus the(i,k)-th entry of outputy is: Y(i,k) = max X(n,k), (7) n N(i) where N(i) indicates the neighbor index set of point X i computed fromw. A point s local signature is then obtained by graph max or average pooling. This signature can represent the aggregated feature information of the local surface. Note the connection of this operation with PointNet++: each point i s local neighborhood is similar to the clusters/segments in PointNet++. This graph operation enables local feature aggregation on the original PointNet architecture. 4. Experiments Now we discuss the proposed architectures for 3D shape classification (Section 4.1), part segmentation (Section 4.2), and perform ablation study (Section 4.3) Shape Classification Datasets. We evaluated our network on both 2D and 3D point clouds. For 2D shape classification, we converted MNIST dataset [21] to 2D point clouds. MNIST contains images of handwritten digits with 60,000 training and 10,000 testing images. We transformed non-zero pixels in each image to 2D points, keeping coordinates as input features and normalize them within [-0.5, 0.5]. For 3D shape classification, we evaluated our KCNet on 10- categories and 40-categories benchmarks ModelNet10 and ModelNet40 [42], consisting of 4899 and CAD models respectively. ModelNet10 is split into 3991 for training and 908 for testing. ModelNet40 is split into 9843 for training and 2468 for testing. As in PointNet, to obtain 3D point clouds, we uniformly sampled points from meshes into 1024 points of each object by Poisson disk sampling using MeshLab [6] and normalized them into a unit ball. Network Configuration. As detailed in Figure 2a, our KCNet has 9 parametric layers in total. The first layer, kernel correlation, takes point coordinates as inputs and outputs local geometric features and concatenated with the point coordinates. Then features are passed into the first 2- layer for per-point feature learning. The graph pooling layer then aggregates the output per-point features into more robust local structure features, which are concatenated with the outputs from the second 2-layer. Other configurations are similar to the original PointNet, except that 1) ReLU is used after each fully connected layer without Batchnorm (we found it not useful in KCNet and PointNet), and 2) Dropout layers are used for the final fully connected layers with drop ratio 0.5. We used 16-NN graph for kernel computation and graph max pooling. L = 32 sets of kernels were used, in which each kernel had M = 16 points uniformly initialized within [-0.2, 0.2] and kernel width σ = We trained the network for 400 epochs on a NVIDIA GTX 1080 GPU using our modified Caffe [16] with ADAM opti- 4552
6 Method Accuracy (%) LeNet5 [21] 99.2 PointNet (vanilla) [29] 98.7 PointNet [29] 99.2 PointNet++ [31] 99.5 KCNet (ours) 99.3 Table 1: MNIST digit classification. Method MN10 MN40 MVCNN [36] VRN Ensemble [2] ECC [34] PointNet (vanilla) [29] PointNet [29] PointNet++ [31] Kd-Net(depth 10) [20] Kd-Net(depth 15) [20] KCNet (ours) Table 2: ModelNet shape classification comparisons of accuracy of proposed network with state-of-the-art. Our KCNet has competitive performance on both ModelNet10 and ModelNet40. Note that MVCNN [36] and VRN Ensemble [2] take image and volume as inputs, while rest of the models take point clouds as inputs. Method #params (M) Fwd. time (ms) PointNet(vanilla) [31] PointNet [31] PointNet++(MSG) [31] Kd-Net (depth 10) KCNet (M = 16) KCNet (M = 3) Table 3: Model size and inference time. M stands for million. Networks were tested on a PC with a single NVIDIA GTX 1080 GPU and an Intel i7-8700@3.2 GHz 12 cores CPU. Other settings are the same as in [31]. mizer, initial learning rate 0.001, batch size 64, momentum 0.9, momentum , and weight decay 1e 5. No data augmentation was performed. Results. Table 1 and Table 2 compares our results with several recent works. In MNIST digit classification, KCNet reaches comparable results obtained with ConvNets. In ModelNet40 shape classification, our method achieves competitive performance with 3.8% and 1.8% higher accuracy than PointNet-vanilla (meaning without T-nets) and Point- Net respectively [29], and is slightly better (0.3%) than PointNet++ [31]. Table 3 summarizes required number of parameters and forward time of different networks. Note KCNet achieves better or comparable accuracy and computes more efficiently than [20, 31] with fewer parameters Part Segmentation Part segmentation is an important task that requires accurate segmentation of complex shapes with delicate structures. We used the network illustrated in Figure 2b to predict the part label of each point in a 3D point cloud object. Datasets. We evaluated KCNet for part segmentation on ShapeNet part dataset [44]. There are 16,881 shapes of 3D point cloud objects from 16 shape categories, with each point in an object corresponds to a part label (50 parts in total, and non-overlapping across shape categories). On average each object consists of less than 6 parts and the highly imbalanced data makes the task quite challenging. We used the same strategy as in Section 4.1 to uniformly sample 2048 points for each CAD object. We used the official train test split following [31]. Network Configuration. Segmentation network has 10 parametric layers. Features of different layers capturing local features are concatenated with the replicated global features and shape information, as in [29]. Details are in Figure 2b. Again, ReLU is used in each layer without Batchnorm. Dropout layers are used for fully connected layers with drop ratio 0.3. We used 18-NN graph for kernel computation and graph max pooling. L = 16 sets of kernels are used, in which each kernel has M = 18 points uniformly initialized within [ 0.2,0.2] and kernel width σ = Other hyper-parameters are the same as in shape classification. No data augmentation was performed. Results. We compared our method with PointNet [29], PointNet++ [31] and Kd-Net [20]. We use intersection over union (IoU) of each category as the evaluation metric following [20]: IoU of each shape instance is the average IoU of each part that occurs in this shape category (the IoUs of the parts belonging to other shape categories are ignored following the protocol of [29]). The mean IoU (miou) of each category is obtained by averaging IoUs of all the shapes in that category. The overall average instance miou (Ins. miou) is calculated by averaging IoUs of all the shape instances. Besides, we also report overall average category miou (Cat. miou) that is directly averaged over 16 categories. Table 4 lists the results. Compared with PointNet++ that uses surface normals as additional inputs, our KCNet only takes raw point clouds as input and achieves better performance with more efficiency regarding computation and parameters in Table 3. Figure 4 displays some examples of predicted results on ShapeNet part test dataset Ablation Study In this section, we further conducted several ablation experiments, investigating various design variations and demonstrating the advantages of KCNet. 4553

















 are reported.")


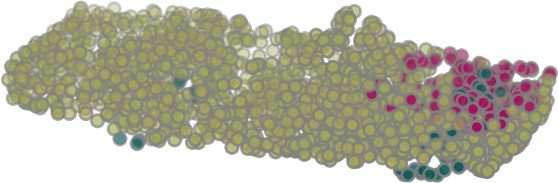
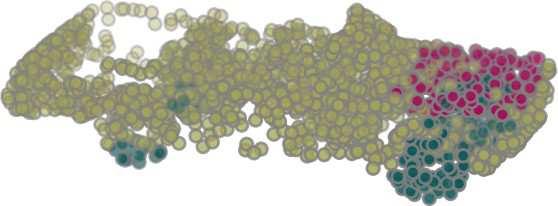
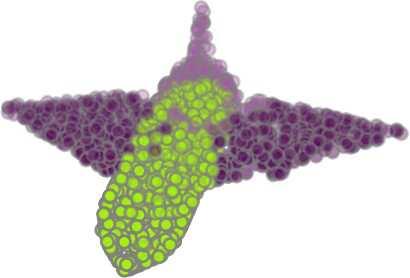

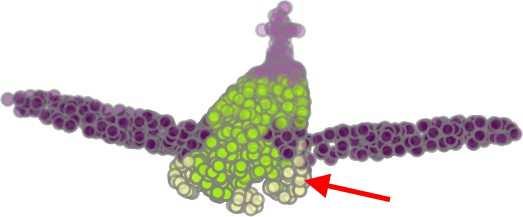


7 Cat. Ins. aero bag cap car chair ear guitar knife lamp laptop motor mug pistol rocket skate table miou miou phone board # shapes PointNet PointNet++ Kd-Net KCNet (ours) Table 4: ShapeNet part segmentation results. Average miou over instances (Ins.) and categories (Cat.) are reported. GT PointNet Ours 42.3% GT PointNet Ours 96.8% 69.6% 68.5% 82.3% 76.5% GT PointNet Ours 83.1% 59.3% 72.1% 70.8% 83.8% 61.4% 79.0% 78.3% 59.5% 66.9% 63.5% 82.8% 48.4% 93.6% 55.8% 90.6% 84.6% 94.9% 88.8% 96.8% 64.0% 67.9% 84.1% 91.5% 48.7% 57.9% 89.9% 92.8% 59.2% 93.4% 58.2% 65.4% 63.2% 68.8% 82.7% 90.4% 68.5% 74.0% 90.8% 93.2% 39.8% 59.1% 77.2% 91.6% 69.4% 94.3% 40.2% 53.9% Figure 4: Examples of part segmentation results on ShapeNet part test dataset. IoU (%) is listed below each result for reference. Red arrows: KCNet improvements. Red circles: some errors in ground truth (GT). Better viewed in color. 4554
8 Effectiveness of Kernel Correlation Accuracy (%) Normal 88.4 Kernel correlation 90.5 Symmetric Functions Accuracy (%) Graph average pooling 88.0 Graph max pooling 88.6 Effectiveness of Local Structures Accuracy (%) Baseline: PointNet (vanilla) 87.2 Kernel correlation (geometric) 90.5 Graph max pooling (feature) 88.6 Both 91.0 Table 5: Ablation study on ModelNet40 test set. L Acc. (%) M Acc. (%) σ Acc. (%) e e e Table 6: Choosing hyper-parameters. Each column only changes the corresponding parameter (base setting in bold). Effectiveness of Kernel Correlation. Table 5 lists the comparison between kernel correlation and normal. In this experiment, we used normals as local geometric features, concatenated them with coordinates and passed them into the proposed architecture in Figure 2a. Normal of each point was computed by applying PCA to the covariance matrix to obtain the direction of minimal variance. Results show that kernel correlation is better than normals. Symmetric Functions. Symmetric function is able to make a network invariant to input permutation [29]. In this experiment, we investigated the performance of graph max pooling and graph average pooling. As shown in Table 5, graph max pooling has a marginal improvement over graph average pooling, and is faster to compute, thus was adopted. Effectiveness of Local Structures. In Table 5 we also demonstrate the effect of our local geometric and feature structures learned by kernel correlation and graph max pooling, respectively. Note that our kernel correlation and graph max pooling layer already respectively achieve comparable or even better performances compared to PointNet. Choosing Hyper-parameters. KCNet have several unique hyper-parameters: L,M, andσ, as explained in Section 3.1. We report their individual influences in Table 6. Robustness Test. We compared our networks with Point- Net on robustness against random noise in the input point cloud. Both networks are trained on the same train and test data with 1024 points per object. The PointNet was trained Accuracy (%) PointNet GM only KC only KC+GM # points replaced with uniform noise Figure 5: KCNet vs. PointNet on random noise. Different numbers of points in each object are replaced with uniform noise between [-1,1]. Metric is overall classification accuracy on the ModelNet40 test set. KCNet is more robust against random noise. GM only: graph max pooling only. KC only: kernel correlation only. KC+GM: both. with the same data augmentation in [29] using the authors code. Our networks were trained without data augmentation. During testing, a certain number of randomly selected input points were replaced with uniformly distributed noise ranging [-1.0, 1.0]. As shown in Figure 5, our networks are more robust against random noise. The accuracy of PointNet drops 58.6% when 10 points were replaced with random noise (from 89.2% to 30.6%), while ours (KC+GM) only drops 23.8% (from 91.0% to 67.2%). Besides, it can be seen that within the groups of experiments, graph max pooling is the most robust under random noise. We speculate that it is caused by the local max pooling - neighbor points sharing max features along each dimension so random noise in the neighborhood could not easily affect the prediction. This could also explain why KC+GM is more robust than KC only. This test shows an advantage of local structures over per-point features - our network learns to exploit local geometric and feature structures within neighboring regions and thus is robust against random noise. 5. Conclusion We proposed kernel correlation and graph pooling to improve PointNet-like methods. Experiments have shown that our method efficiently captures local patterns and robustly improves performances of 3D point cloud semantic learning. We will generalize the kernel correlation to higher dimensions, with learnable kernel widths in the future. Acknowledgment The authors gratefully acknowledge the helpful comments and suggestions from Teng-Yok Lee, Ziming Zhang, Zhiding Yu, Yuichi Taguchi, and Alan Sullivan. 4555
9 References [1] J. Atwood and D. Towsley. Diffusion-convolutional neural networks. In Advances in Neural Information Processing Systems, pages , [2] A. Brock, T. Lim, J. M. Ritchie, and N. Weston. Generative and discriminative voxel modeling with convolutional neural networks. arxiv preprint arxiv: , , 3, 6 [3] M. M. Bronstein, J. Bruna, Y. LeCun, A. Szlam, and P. Vandergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34(4):18 42, , 3 [4] J. Bruna, W. Zaremba, A. Szlam, and Y. LeCun. Spectral networks and locally connected networks on graphs. arxiv preprint arxiv: , [5] Y. Chen and G. Medioni. Object modeling by registration of multiple range images. In IEEE International Conference on Robotics and Automation (ICRA), pages , [6] P. Cignoni, M. Callieri, M. Corsini, M. Dellepiane, F. Ganovelli, and G. Ranzuglia. MeshLab: an Open-Source Mesh Processing Tool. In V. Scarano, R. D. Chiara, and U. Erra, editors, Eurographics Italian Chapter Conference. The Eurographics Association, [7] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), volume 1, , 3 [8] M. Defferrard, X. Bresson, and P. Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems, pages , [9] D. K. Duvenaud, D. Maclaurin, J. Iparraguirre, R. Bombarell, T. Hirzel, A. Aspuru-Guzik, and R. P. Adams. Convolutional networks on graphs for learning molecular fingerprints. In Advances in neural information processing systems, pages , [10] M. Edwards and X. Xie. Graph based convolutional neural network. arxiv preprint arxiv: , [11] C. Feng, Y. Taguchi, and V. R. Kamat. Fast plane extraction in organized point clouds using agglomerative hierarchical clustering. In IEEE International Conference on Robotics and Automation (ICRA), pages , [12] A. Golovinskiy, V. G. Kim, and T. Funkhouser. Shape-based recognition of 3d point clouds in urban environments. In IEEE International Conference on Computer Vision (ICCV), pages , [13] M. Henaff, J. Bruna, and Y. LeCun. Deep convolutional networks on graph-structured data. arxiv preprint arxiv: , [14] D. Holz and S. Behnke. Fast range image segmentation and smoothing using approximate surface reconstruction and region growing. Intelligent autonomous systems 12, pages 61 73, , 3 [15] H. Hoppe, T. DeRose, T. Duchamp, J. McDonald, and W. Stuetzle. Surface reconstruction from unorganized points. SIGGRAPH Comput. Graph., 26(2):71 78, July [16] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, pages , [17] B. Jian and B. C. Vemuri. Robust point set registration using gaussian mixture models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(8): , [18] D. Kempe, J. Kleinberg, and É. Tardos. Maximizing the spread of influence through a social network. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, pages ACM, [19] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arxiv preprint arxiv: , [20] R. Klokov and V. Lempitsky. Escape from cells: Deep kdnetworks for the recognition of 3d point cloud models. International Conference on Computer Vision (ICCV), , 3, 6 [21] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradientbased learning applied to document recognition. Proceedings of the IEEE, 86(11): , , 5, 6 [22] R. Levie, F. Monti, X. Bresson, and M. M. Bronstein. Cayleynets: Graph convolutional neural networks with complex rational spectral filters. arxiv preprint arxiv: , [23] Y. Li, S. Pirk, H. Su, C. R. Qi, and L. J. Guibas. Fpnn: Field probing neural networks for 3d data. In Advances in Neural Information Processing Systems, pages , , 3 [24] J. Masci, D. Boscaini, M. Bronstein, and P. Vandergheynst. Geodesic convolutional neural networks on riemannian manifolds. In Proceedings of the IEEE international conference on computer vision workshops, pages 37 45, [25] D. Maturana and S. Scherer. Voxnet: A 3d convolutional neural network for real-time object recognition. In IEEE International Conference on Intelligent Robots and Systems (IROS), pages IEEE, , 3 [26] F. Monti, D. Boscaini, J. Masci, E. Rodolà, J. Svoboda, and M. M. Bronstein. Geometric deep learning on graphs and manifolds using mixture model cnns. arxiv preprint arxiv: , [27] M. Niepert, M. Ahmed, and K. Kutzkov. Learning convolutional neural networks for graphs. In International conference on machine learning, pages , [28] D. OuYang and H.-Y. Feng. On the normal vector estimation for point cloud data from smooth surfaces. Computer-Aided Design, 37(10): , [29] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), , 2, 3, 6, 8 [30] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. J. Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages , ,
10 [31] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in Neural Information Processing Systems, , 3, 6 [32] G. Riegler, A. O. Ulusoy, and A. Geiger. Octnet: Learning deep 3d representations at high resolutions. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), volume 3, , 2, 3 [33] G. L. Scott and H. C. Longuet-Higgins. An algorithm for associating the features of two images. Proceedings of the Royal Society of London B: Biological Sciences, 244(1309):21 26, [34] M. Simonovsky and N. Komodakis. Dynamic edgeconditioned filters in convolutional neural networks on graphs. Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), , 6 [35] J. Strom, A. Richardson, and E. Olson. Graph-based segmentation for colored 3d laser point clouds. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages , [36] H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller. Multiview convolutional neural networks for 3d shape recognition. In International Conference on Computer Vision (ICCV), pages , [37] D. Thanou, P. A. Chou, and P. Frossard. Graph-based compression of dynamic 3d point cloud sequences. IEEE Transactions on Image Processing, 25(4): , [38] Y. Tsin and T. Kanade. A correlation-based approach to robust point set registration. In European conference on computer vision (ECCV), pages , , 4 [39] G. Vosselman, S. Dijkman, et al. 3d building model reconstruction from point clouds and ground plans. International archives of photogrammetry remote sensing and spatial information sciences, 34(3/W4):37 44, [40] G. Vosselman, B. G. Gorte, G. Sithole, and T. Rabbani. Recognising structure in laser scanner point clouds. International archives of photogrammetry, remote sensing and spatial information sciences, 46(8):33 38, [41] P.-S. Wang, Y. Liu, Y.-X. Guo, C.-Y. Sun, and X. Tong. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Transactions on Graphics (SIG- GRAPH), 36(4), , 2, 3 [42] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages , , 3, 5 [43] Y. Yang, C. Feng, Y. Shen, and D. Tian. Foldingnet: Point cloud auto-encoder via deep grid deformation. Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), [44] L. Yi, V. G. Kim, D. Ceylan, I. Shen, M. Yan, H. Su, A. Lu, Q. Huang, A. Sheffer, L. Guibas, et al. A scalable active framework for region annotation in 3d shape collections. ACM Transactions on Graphics (TOG), 35(6):210,
arxiv: v1 [cs.cv] 28 Nov 2018
![arxiv: v1 [cs.cv] 28 Nov 2018](/thumbs/91/104803963.jpg "arxiv: v1 [cs.cv] 28 Nov 2018") MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
Deep Learning on Point Sets for 3D Classification and Segmentation
 Deep Learning on Point Sets for 3D Classification and Segmentation Charles Ruizhongtai Qi Stanford University rqi@stanford.edu Abstract Point cloud is an important type of geometric data structure. Due
Deep Learning on Point Sets for 3D Classification and Segmentation Charles Ruizhongtai Qi Stanford University rqi@stanford.edu Abstract Point cloud is an important type of geometric data structure. Due
arxiv: v2 [cs.cv] 3 Apr 2018
![arxiv: v2 [cs.cv] 3 Apr 2018](/thumbs/86/93950354.jpg "arxiv: v2 [cs.cv] 3 Apr 2018") FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation Yaoqing Yang yyaoqing@andrew.cmu.edu Chen Feng cfeng@merl.com Yiru Shen yirus@g.clemson.edu Dong Tian tian@merl.com Carnegie Mellon University
FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation Yaoqing Yang yyaoqing@andrew.cmu.edu Chen Feng cfeng@merl.com Yiru Shen yirus@g.clemson.edu Dong Tian tian@merl.com Carnegie Mellon University
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network
 Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
arxiv: v1 [cs.cv] 13 Feb 2018
![arxiv: v1 [cs.cv] 13 Feb 2018](/thumbs/85/92549074.jpg "arxiv: v1 [cs.cv] 13 Feb 2018") Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
SO-Net: Self-Organizing Network for Point Cloud Analysis
 SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore Abstract This paper presents SO-Net, a permutation invariant architecture for
SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore Abstract This paper presents SO-Net, a permutation invariant architecture for
Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network
 Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network Marko Filipović, Petra Ðurović and Robert Cupec Faculty of Electrical Engineering, Computer Science and Information
Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network Marko Filipović, Petra Ðurović and Robert Cupec Faculty of Electrical Engineering, Computer Science and Information
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
arxiv: v4 [cs.cv] 27 Mar 2018
![arxiv: v4 [cs.cv] 27 Mar 2018](/thumbs/96/128983416.jpg "arxiv: v4 [cs.cv] 27 Mar 2018") SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore arxiv:1803.04249v4 [cs.cv] 27 Mar 2018 Abstract This paper presents SO-Net, a
SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore arxiv:1803.04249v4 [cs.cv] 27 Mar 2018 Abstract This paper presents SO-Net, a
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation
 SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong Abstract In this paper, we study the problem
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong Abstract In this paper, we study the problem
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
arxiv: v1 [cs.cv] 2 Dec 2016
![arxiv: v1 [cs.cv] 2 Dec 2016](/thumbs/89/98281292.jpg "arxiv: v1 [cs.cv] 2 Dec 2016") SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong arxiv:1612.00606v1 [cs.cv] 2 Dec 2016 Abstract
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong arxiv:1612.00606v1 [cs.cv] 2 Dec 2016 Abstract
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Deep Learning on Graphs
 Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval
 Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Charles R. Qi Li Yi Hao Su Leonidas J. Guibas Stanford University Abstract Few prior works study deep learning on point sets.
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Charles R. Qi Li Yi Hao Su Leonidas J. Guibas Stanford University Abstract Few prior works study deep learning on point sets.
Robotics Programming Laboratory
 Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
3D Deep Learning
 3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
From processing to learning on graphs
 From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
arxiv: v1 [cs.cv] 27 Nov 2018 Abstract
![arxiv: v1 [cs.cv] 27 Nov 2018 Abstract](/thumbs/91/105025156.jpg "arxiv: v1 [cs.cv] 27 Nov 2018 Abstract") Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
AI Ukraine Point cloud labeling using machine learning
 AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
A Keypoint Descriptor Inspired by Retinal Computation
 A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
arxiv: v4 [cs.cv] 29 Mar 2019
![arxiv: v4 [cs.cv] 29 Mar 2019](/thumbs/96/128038877.jpg "arxiv: v4 [cs.cv] 29 Mar 2019") PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Face Recognition A Deep Learning Approach
 Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
 Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Su et al. Shape Descriptors - III
 Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
arxiv: v1 [cs.cv] 28 Nov 2017
![arxiv: v1 [cs.cv] 28 Nov 2017](/thumbs/81/83356256.jpg "arxiv: v1 [cs.cv] 28 Nov 2017") 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Correspondence. CS 468 Geometry Processing Algorithms. Maks Ovsjanikov
 Shape Matching & Correspondence CS 468 Geometry Processing Algorithms Maks Ovsjanikov Wednesday, October 27 th 2010 Overall Goal Given two shapes, find correspondences between them. Overall Goal Given
Shape Matching & Correspondence CS 468 Geometry Processing Algorithms Maks Ovsjanikov Wednesday, October 27 th 2010 Overall Goal Given two shapes, find correspondences between them. Overall Goal Given
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Multiresolution Tree Networks for 3D Point Cloud Processing
 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY
 MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues
 Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues Ludovico Minto, Pietro Zanuttigh and Giampaolo Pagnutti Department of Information Engineering, University
Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues Ludovico Minto, Pietro Zanuttigh and Giampaolo Pagnutti Department of Information Engineering, University
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Cross-domain Deep Encoding for 3D Voxels and 2D Images
 Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Supplementary Material for Ensemble Diffusion for Retrieval
 Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
arxiv: v1 [cs.cv] 6 Nov 2018 Abstract
![arxiv: v1 [cs.cv] 6 Nov 2018 Abstract](/thumbs/89/101192741.jpg "arxiv: v1 [cs.cv] 6 Nov 2018 Abstract") 3DCapsule: Extending the Capsule Architecture to Classify 3D Point Clouds Ali Cheraghian Australian National University, Data61-CSIRO ali.cheraghian@anu.edu.au Lars Petersson Data61-CSIRO lars.petersson@data61.csiro.au
3DCapsule: Extending the Capsule Architecture to Classify 3D Point Clouds Ali Cheraghian Australian National University, Data61-CSIRO ali.cheraghian@anu.edu.au Lars Petersson Data61-CSIRO lars.petersson@data61.csiro.au
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
3D Object Classification using Shape Distributions and Deep Learning
 3D Object Classification using Shape Distributions and Deep Learning Melvin Low Stanford University mwlow@cs.stanford.edu Abstract This paper shows that the Absolute Angle shape distribution (AAD) feature
3D Object Classification using Shape Distributions and Deep Learning Melvin Low Stanford University mwlow@cs.stanford.edu Abstract This paper shows that the Absolute Angle shape distribution (AAD) feature
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR
 3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Deep Learning on Graphs
 Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 6 April 2017 joint work with Max Welling (University of Amsterdam) The success story of deep
Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 6 April 2017 joint work with Max Welling (University of Amsterdam) The success story of deep
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Robust Attentional Pooling via Feature Selection
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Robust Attentional Pooling via Feature Selection Zhang, J.; Lee, T.-Y.; Feng, C.; Li, X.; Zhang, Z. TR2018-124 August 25, 2018 Abstract In
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Robust Attentional Pooling via Feature Selection Zhang, J.; Lee, T.-Y.; Feng, C.; Li, X.; Zhang, Z. TR2018-124 August 25, 2018 Abstract In
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Selecting Models from Videos for Appearance-Based Face Recognition
 Selecting Models from Videos for Appearance-Based Face Recognition Abdenour Hadid and Matti Pietikäinen Machine Vision Group Infotech Oulu and Department of Electrical and Information Engineering P.O.
Selecting Models from Videos for Appearance-Based Face Recognition Abdenour Hadid and Matti Pietikäinen Machine Vision Group Infotech Oulu and Department of Electrical and Information Engineering P.O.
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
learning stage (Stage 1), CNNH learns approximate hash codes for training images by optimizing the following loss function:
, CNNH learns approximate hash codes for training images by optimizing the following loss function:") 1 Query-adaptive Image Retrieval by Deep Weighted Hashing Jian Zhang and Yuxin Peng arxiv:1612.2541v2 [cs.cv] 9 May 217 Abstract Hashing methods have attracted much attention for large scale image retrieval.
1 Query-adaptive Image Retrieval by Deep Weighted Hashing Jian Zhang and Yuxin Peng arxiv:1612.2541v2 [cs.cv] 9 May 217 Abstract Hashing methods have attracted much attention for large scale image retrieval.
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels
 SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels Matthias Fey, Jan Eric Lenssen, Frank Weichert, Heinrich Mu ller Department of Computer Graphics TU Dortmund University {matthiasfey,janericlenssen}@udoedu
SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels Matthias Fey, Jan Eric Lenssen, Frank Weichert, Heinrich Mu ller Department of Computer Graphics TU Dortmund University {matthiasfey,janericlenssen}@udoedu
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Deep Learning. Deep Learning provided breakthrough results in speech recognition and image classification. Why?
 Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Efficient Algorithms may not be those we think
 Efficient Algorithms may not be those we think Yann LeCun, Computational and Biological Learning Lab The Courant Institute of Mathematical Sciences New York University http://yann.lecun.com http://www.cs.nyu.edu/~yann
Efficient Algorithms may not be those we think Yann LeCun, Computational and Biological Learning Lab The Courant Institute of Mathematical Sciences New York University http://yann.lecun.com http://www.cs.nyu.edu/~yann
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Paper Motivation. Fixed geometric structures of CNN models. CNNs are inherently limited to model geometric transformations
 Paper Motivation Fixed geometric structures of CNN models CNNs are inherently limited to model geometric transformations Higher-level features combine lower-level features at fixed positions as a weighted
Paper Motivation Fixed geometric structures of CNN models CNNs are inherently limited to model geometric transformations Higher-level features combine lower-level features at fixed positions as a weighted
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Depth Estimation from a Single Image Using a Deep Neural Network Milestone Report
 Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document
 Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt