arxiv: v2 [cs.cv] 3 Apr 2018
|
|
|
- Joel Tucker
- 5 years ago
- Views:
Transcription
 Clemson University arxiv:1712.07262v2 [cs.")
![cv] 3 Apr 2018 Abstract Recent deep networks that directly handle points in a point set, e.g.](/docs-images/86/93950354/images/1-1.jpg ", PointNet, have been state-of-the-art for supervised learning tasks on point clouds such as classification and segmentation.")




 rely on a 2D grid in the image plane with a regular spacing. Point cloud geometry is typically represented by a set of sparse 3D points.")



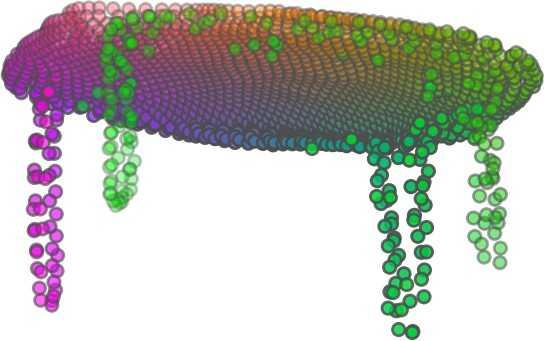
1 FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation Yaoqing Yang Chen Feng Yiru Shen Dong Tian Carnegie Mellon University Mitsubishi Electric Research Laboratories (MERL) Clemson University arxiv: v2 [cs.cv] 3 Apr 2018 Abstract Recent deep networks that directly handle points in a point set, e.g., PointNet, have been state-of-the-art for supervised learning tasks on point clouds such as classification and segmentation. In this work, a novel end-toend deep auto-encoder is proposed to address unsupervised learning challenges on point clouds. On the encoder side, a graph-based enhancement is enforced to promote local structures on top of PointNet. Then, a novel folding-based decoder deforms a canonical 2D grid onto the underlying 3D object surface of a point cloud, achieving low reconstruction errors even for objects with delicate structures. The proposed decoder only uses about 7% parameters of a decoder with fully-connected neural networks, yet leads to a more discriminative representation that achieves higher linear SVM classification accuracy than the benchmark. In addition, the proposed decoder structure is shown, in theory, to be a generic architecture that is able to reconstruct an arbitrary point cloud from a 2D grid. Our code is available at license#foldingnet 1. Introduction 3D point cloud processing and understanding are usually deemed more challenging than 2D images mainly due to a fact that point cloud samples live on an irregular structure while 2D image samples (pixels) rely on a 2D grid in the image plane with a regular spacing. Point cloud geometry is typically represented by a set of sparse 3D points. Such a data format makes it difficult to apply traditional deep learning framework. E.g. for each sample, traditional convolutional neural network (CNN) requires its neighboring samples to appear at some fixed spatial orientations and distances so as to facilitate the convolution. Unfortunately, point cloud samples typically do not follow such constraints. One way to alleviate the problem is to voxelize a point cloud to mimic the image representation and then to operate on voxels. The downside is that voxelization has to either sacrifice the representation accuracy or incurs huge redundancies, that may pose an unnecessary cost in the sub- Input 2D grid 1st folding 2nd folding Table 1. Illustration of the two-step-folding decoding. Column one contains the original point cloud samples from the ShapeNet dataset [57]. Column two illustrates the 2D grid points to be folded during decoding. Column three contains the output after one folding operation. Column four contains the output after two folding operations. This output is also the reconstructed point cloud. We use a color gradient to illustrate the correspondence between the 2D grid in column two and the reconstructed point clouds after folding operations in the last two columns. Best viewed in color. sequent processing, either at a compromised performance or an rapidly increased processing complexity. Related priorarts will be reviewed in Section 1.1. In this work, we focus on the emerging field of unsupervised learning for point clouds. We propose an autoencoder (AE) that is referenced as FoldingNet. The output from the bottleneck layer in the auto-encoder is called a codeword that can be used as a high-dimensional embedding of an input point cloud. We are going to show that a 2D grid structure is not only a sampling structure for imaging, but can indeed be used to construct a point cloud through
 2)graph layers concatenate 3)layer perceptron m 3 Chamfer) Distance output local covariance 3)layer perceptron n 64 n 12 Graph-based Encoder n 3 input replicate m)times m 2")



2 2)layer codeword perceptron n 1024 global max-pooling 3)layer perceptron 1st) folding) m 514 m 3 intermediate) point)cloud m 512 Folding-based Decoder concatenate m 515 n-by-9 2nd) folding) 2)graph layers concatenate 3)layer perceptron m 3 Chamfer) Distance output local covariance 3)layer perceptron n 64 n 12 Graph-based Encoder n 3 input replicate m)times m 2 2D)grid)points)(fixed) Figure 1. FoldingNet Architecture. The graph-layers are the graph-based max-pooling layers mentioned in (2) in Section 2.1. The 1st and the 2nd folding are both implemented by concatenating the codeword to the feature vectors followed by a 3-layer perceptron. Each perceptron independently applies to the feature vector of a single point as in [41], i.e., applies to the rows of the m-by-k matrix. the proposed folding operation. This is based on the observation that the 3D point clouds of our interest are obtained from object surfaces: either discretized from boundary representations in CAD/computer graphics, or sampled from line-of-sight sensors like LIDAR. Intuitively, any 3D object surface could be transformed to a 2D plane through certain operations like cutting, squeezing, and stretching. The inverse procedure is to glue those 2D point samples back onto an object surface via certain folding operations, which are initialized as 2D grid samples. As illustrated in Table 1, to reconstruct a point cloud, successive folding operations are joined to reproduce the surface structure. The points are colorized to show the correspondence between the initial 2D grid samples and the reconstructed 3D point samples. Using the folding-based method, the challenges from the irregular structure of point clouds are well addressed by directly introducing such an implicit 2D grid constraint in the decoder, which avoids the costly 3D voxelization in other works [56]. It will be demonstrated later that the folding operations can build an arbitrary surface provided a proper codeword. Notice that when data are from volumetric format instead of 2D surfaces, a 3D grid may perform better. Despite being strongly expressive in reconstructing point clouds, the folding operation is simple: it is started by augmenting the 2D grid points with the codeword obtained from the encoder, which is then processed through a 3layer perceptron. The proposed decoder is simply a concatenation of two folding operations. This design makes the proposed decoder much smaller in parameter size than the fully-connected decoder proposed recently in [1]. In Section 4.6, we show that the number of parameters of our folding-based decoder is about 7% of the fully connected decoder in [1]. Although the proposed decoder has a sim- ple structure, we theoretically show in Theorem 3.2 that this folding-based structure is universal in that one folding operation that uses only a 2-layer perceptron can already reproduce arbitrary point-cloud structure. Therefore, it is not surprising that our FoldingNet auto-encoder exploiting two consecutive folding operations can produce elaborate structures. To show the efficiency of FoldingNet auto-encoder for unsupervised representation learning, we follow the experimental settings in [1] and test the transfer classification accuracy from ShapeNet dataset [7] to ModelNet dataset [57]. The FoldingNet auto-encoder is trained using ShapeNet dataset, and tested out by extracting codewords from ModelNet dataset. Then, we train a linear SVM classifier to test the discrimination effectiveness of the extracted codewords. The transfer classification accuracy is 88.4% on the ModelNet dataset with 40 shape categories. This classification accuracy is even close to the state-of-the-art supervised training result [41]. To achieve the best classification performance and least reconstruction loss, we use a graphbased encoder structure that is different from [41]. This graph-based encoder is based on the idea of local feature pooling operations and is able to retrieve and propagate local structural information along the graph structure. To intuitively interpret our network design: we want to impose a virtual force to deform/cut/stretch a 2D grid lattice onto a 3D object surface, and such a deformation force should be influenced or regulated by interconnections induced by the lattice neighborhood. Since the intermediate folding steps in the decoder and the training process can be illustrated by reconstructed points, the gradual change of the folding forces can be visualized. Now we summarize our contributions in this work:
3 We train an end-to-end deep auto-encoder that consumes unordered point clouds directly. We propose a new decoding operation called folding and theoretically show it is universal in point cloud reconstruction, while providing orders to reconstructed points as a unique byproduct than other methods. We show by experiments on major datasets that folding can achieve higher classification accuracy than other unsupervised methods Related works Applications of learning on point clouds include shape completion and recognition [57], unmanned autonomous vehicles [36], 3D object detection, recognition and classification [9, 33, 40, 41, 48, 49, 53], contour detection [21], layout inference [18], scene labeling [31], category discovery [60], point classification, dense labeling and segmentation [3, 10, 13, 22, 25, 27, 37, 41, 54, 55, 58], Most deep neural networks designed for 3D point clouds are based on the idea of partitioning the 3D space into regular voxels and extending 2D CNNs to voxels, such as [4, 11, 37], including the the work on 3D generative adversarial network [56]. The main problem of voxel-based networks is the fast growth of neural-network size with the increasing spatial resolution. Some other options include octree-based [44] and kd-tree-based [29] neural networks. Recently, it is shown that neural networks based on purely 3D point representations [1, 41 43] work quite efficiently for point clouds. The point-based neural networks can reduce the overhead of converting point clouds into other data formats (such as octrees and voxels), and in the meantime avoid the information loss due to the conversion. The only work that we are aware of on end-to-end deep auto-encoder that directly handles point clouds is [1]. The AE designed in [1] is for the purpose of extracting features for generative networks. To encode, it sorts the 3D points using the lexicographic order and applies a 1D CNN on the point sequence. To decode, it applies a three-layer fully connected network. This simple structure turns out to outperform all existing unsupervised works on representation extraction of point clouds in terms of the transfer classification accuracy from the ShapeNet dataset to the ModelNet dataset [1]. Our method, which has a graph-based encoder and a folding-based decoder, outperforms this method in transfer classification accuracy on the ModelNet40 dataset [1]. Moreover, compared to [1], our AE design is more interpretable: the encoder learns the local shape information and combines information by max-pooling on a nearestneighbor graph, and the decoder learns a force to fold a two-dimensional grid twice in order to warp the grid into the shape of the point cloud, using the information obtained by the encoder. Another closely related work reconstructs a point set from a 2D image [17]. Although the deconvolution network in [17] requires a 2D image as side information, we find it useful as another implementation of our folding operation. We compare FoldingNet with the deconvolutionbased folding and show that FoldingNet performs slightly better in reconstruction error with fewer parameters (see Supplementary Section 9). It is hard for purely point-based neural networks to extract local neighborhood structure around points, i.e., features of neighboring points instead of individual ones. Some attempts for this are made in [1, 42]. In this work, we exploit local neighborhood features using a graph-based framework. Deep learning on graph-structured data is not a new idea. There are tremendous amount of works on applying deep learning onto irregular data such as graphs and point sets [2,5,6,12,14,15,23,24,28,32,35,38,39,43,47,52, 59]. Although using graphs as a processing framework for deep learning on point clouds is a natural idea, only several seminal works made attempts in this direction [5, 38, 47]. These works try to generalize the convolution operations from 2D images to graphs. However, since it is hard to define convolution operations on graphs, we use a simple graph-based neural network layer that is different from previous works: we construct the K-nearest neighbor graph (K- NNG) and repeatedly conduct the max-pooling operations in each node s neighborhood. It generalizes the global maxpooling operation proposed in [41] in that the max-pooling is only applied to each local neighborhood to generate local data signatures. Compared to the above graph based convolution networks, our design is simpler and computationally efficient as in [41]. K-NNGs are also used in other applications of point clouds without the deep learning framework such as surface detection, 3D object recognition, 3D object segmentation and compression [20, 50, 51]. The folding operation that reconstructs a surface from a 2D grid essentially establishes a mapping from a 2D regular domain to a 3D point cloud. A natural question to ask is whether we can parameterize 3D points with compatible meshes that are not necessarily regular grids, such as cross-parametrization [30]. From Table 2, it seems that FoldingNet can learn to generate cuts on the 2D grid and generate surfaces that are not even topologically equivalent to a 2D grid, and hence make the 2D grid representation universal to some extent. Nonetheless, the reconstructed points may still have genus-wise distortions when the original surface is too complex. For example, in Table 2, see the missing winglets on the reconstructed plane and the missing holes on the back of the reconstructed chair. To recover those finer details might require more input point samples and more complex encoder/decoder networks. Another method to learn the surface embedding is to learn a metric alignment layer as in [16], which may require computationally intensive internal optimization during training.
4 1.2. Preliminaries and Notation We will often denote the point set by S. We use bold lower-case letters to represent vectors, such as x, and use bold upper-case letters to represent matrices, such as A. The codeword is always represented by θ. We call a matrix m-by-n or m n if it has m rows and n columns. 2. FoldingNet Auto-encoder on Point Clouds Now we propose the FoldingNet deep auto-encoder. The structure of the auto-encoder is shown in Figure 1. The input to the encoder is an n-by-3 matrix. Each row of the matrix is composed of the 3D position (x, y, z). The output is an m-by-3 matrix, representing the reconstructed point positions. The number of reconstructed points m is not necessarily the same as n. Suppose the input contains the point set S and the reconstructed point set is the set Ŝ. Then, the reconstruction error for Ŝ is computed using a layer defined as the (extended) Chamfer distance, { d CH (S, Ŝ) = max 1 S x Ŝ x S min x x 2, x Ŝ 1 Ŝ min x x 2 x S. The term min x Ŝ x x 2 enforces that any 3D point x in the original point cloud has a matching 3D point x in the reconstructed point cloud, and the term min x S x x 2 enforces the matching vice versa. The max operation enforces that the distance from S to Ŝ and the distance vice versa have to be small simultaneously. The encoder computes a representation (codeword) of each input point cloud and the decoder reconstructs the point cloud using this codeword. In our experiments, the codeword length is set as 512 in accordance with [1] Graph-based Encoder Architecture The graph-based encoder follows a similar design in [46] which focuses on supervised learning using point cloud neighborhood graphs. The encoder is a concatenation of multi-layer perceptrons (MLP) and graph-based maxpooling layers. The graph is the K-NNG constructed from the 3D positions of the nodes in the input point set. In experiments, we choose K = 16. First, for every single point v, we compute its local covariance matrix of size 3-by-3 and vectorize it to size 1-by-9. The local covariance of v is computed using the 3D positions of the points that are one-hop neighbors of v (including v) in the K-NNG. We concatenate the matrix of point positions with size n-by-3 and the local covariances for all points of size n-by-9 into a matrix of size n-by-12 and input them to a 3-layer perceptron. The perceptron is applied in parallel to each row of the (1) input matrix of size n-by-12. It can be viewed as a per-point function on each 3D point. The output of the perceptron is fed to two consecutive graph layers, where each layer applies max-pooling to the neighborhood of each node. More specifically, suppose the K-NN graph has adjacency matrix A and the input matrix to the graph layer is X. Then, the output matrix is Y = A max (X)K, (2) where K is a feature mapping matrix, and the (i,j)-th entry of the matrix A max (X) is (A max (X)) ij = ReLU( max k N (i) x kj). (3) The local max-pooling operation max k N (i) in (3) essentially computes a local signature based on the graph structure. This signature can represent the (aggregated) topology information of the local neighborhood. Through concatenations of the graph-based max-pooling layers, the network propagates the topology information into larger areas Folding-based Decoder Architecture The proposed decoder uses two consecutive 3-layer perceptrons to warp a fixed 2D grid into the shape of the input point cloud. The input codeword is obtained from the graph-based encoder. Before we feed the codeword into the decoder, we replicate it m times and concatenate the m-by- 512 matrix with an m-by-2 matrix that contains the m grid points on a square centered at the origin. The result of the concatenation is a matrix of size m-by-514. The matrix is processed row-wise by a 3-layer perceptron and the output is a matrix of size m-by-3. After that, we again concatenate the replicated codewords to the m-by-3 output and feed it into a 3-layer perceptron. This output is the reconstructed point cloud. The parameter n is set as per the input point cloud size, e.g. n = 2048 in our experiments, which is the same as [1].We choose m grid points in a square, so m is chosen as 2025 which is the closest square number to Definition 1. We call the concatenation of replicated codewords to low-dimensional grid points, followed by a pointwise MLP a folding operation. The folding operation essentially forms a universal 2Dto-3D mapping. To intuitively see why this folding operation is a universal 2D-to-3D mapping, denote the input 2D grid points by the matrix U. Each row of U is a twodimensional grid point. Denote the i-th row of U by u i and the codeword output from the encoder by θ. Then, after concatenation, the i-th row of the input matrix to the MLP is [u i, θ]. Since the MLP is applied in parallel to each row of the input matrix, the i-th row of the output matrix can be written as f([u i, θ]), where f indicates the function conducted by the MLP. This function can be viewed as a parameterized high-dimensional function with the codeword θ
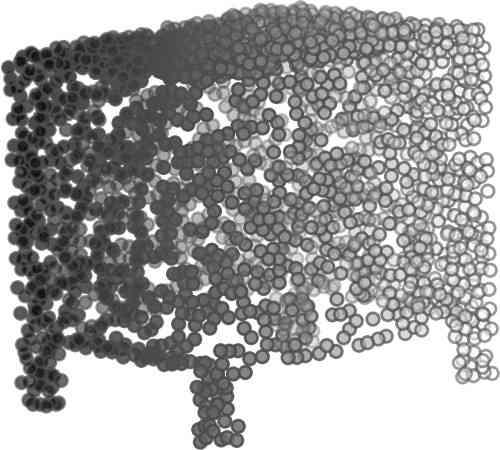
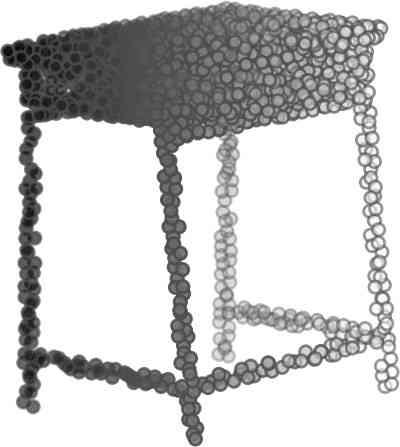
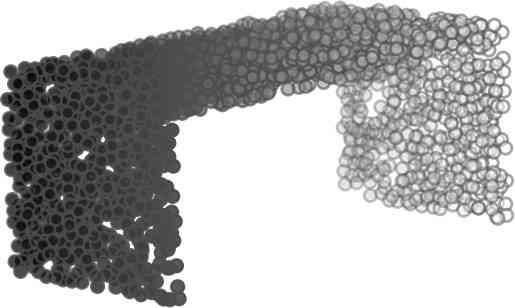
5 being a parameter to guide the structure of the function (the folding operation). Since MLPs are good at approximating non-linear functions, they can perform elaborate folding operations on the 2D grids. The high-dimensional codeword essentially stores the force that is needed to do the folding, which makes the folding operation more diverse. The proposed decoder has two successive folding operations. The first one folds the 2D grid to 3D space, and the second one folds inside the 3D space. We show the outputs after these two folding operations in Table 1. From column C and column D in Table 1, we can see that each folding operation conducts a relatively simple operation, and the composition of the two folding operations can produce quite elaborate surface shapes. Although the first folding seems simpler than the second one, together they lead to substantial changes in the final output. More successive folding operations can be applied if more elaborate surface shapes are required. More variations of the decoder including changes of grid dimensions and the number of folding operations can be found in Supplementary Section Theoretical Analysis Theorem 3.1. The proposed encoder structure is permutation invariant, i.e., if the rows of the input point cloud matrix are permuted, the codeword remains unchanged. Proof. See Supplementary Section 6. Then, we state a theorem about the universality of the proposed folding-based decoder. It shows the existence of a folding-based decoder such that by changing the codeword θ, the output can be an arbitrary point cloud. Theorem 3.2. There exists a 2-layer perceptron that can reconstruct arbitrary point clouds from a 2-dimensional grid using the folding operation. More specifically, suppose the input is a matrix U of size m-by-2 such that each row of U is the 2D position of a point on a 2-dimensional grid of size m. Then, there exists an explicit construction of a 2-layer perceptron (with handcrafted coefficients) such that for any arbitrary 3D point cloud matrix S of size m-by-3 (where each row of S is the (x, y, z) position of a point in the point cloud), there exists a codeword vector θ such that if we concatenate θ to each row of U and apply the 2-layer perceptron in parallel to each row of the matrix after concatenation, we obtain the point cloud matrix S from the output of the perceptron. Proof in sketch. The full proof is in Supplementary Section 7. In the proof, we show the existence by explicitly constructing a 2-layer perceptron that satisfies the stated properties. The main idea is to show that in the worst case, the points in the 2D grid functions as a selective logic gate to map the 2D points in the 2D grid to the corresponding 3D points in the point cloud. Notice that the above proof is just an existence-based one to show that our decoder structure is universal. It does not indicate what happens in reality inside the FoldingNet autoencoder. The theoretically constructed decoder requires 3m hidden units while in reality, the size of the decoder that we use is much smaller. Moreover, the construction in Theorem 3.2 leads to a lossless reconstruction of the point cloud, while the FoldingNet auto-encoder only achieves lossy reconstruction. However, the above theorem can indeed guarantee that the proposed decoding operation (i.e., concatenating the codewords to the 2-dimensional grid points and processing each row using a perceptron) is legitimate because in the worst case there exists a folding-based neural network with hand-crafted edge weights that can reconstruct arbitrary point clouds. In reality, a good parameterization of the proposed decoder with suitable training leads to better performance. 4. Experimental Results 4.1. Visualization of the Training Process It might not be straightforward to see how the decoder folds the 2D grid into the surface of a 3D point cloud. Therefore, we include an illustration of the training process to show how a random 2D manifold obtained by the initial random folding gradually turns into a meaningful point cloud. The auto-encoder is a single FoldingNet trained using the ShapeNet part dataset [58] which contains 16 categories of the ShapeNet dataset. We trained the FoldingNet using ADAM with an initial learning rate , batch size 1, momentum 0.9, momentum , and weight decay 1e 6, for iterations (i.e., 330 epochs). The reconstructed point clouds of several models after different numbers of training iterations are reported in Table 2. From the training process, we see that an initial random 2D manifold can be warped/cut/squeezed/stretched/attached to form the point cloud surface in various ways Point Cloud Interpolation A common method to demonstrate that the codewords have extracted the natural representations of the input is to see if the auto-encoder enables meaningful novel interpolations between two inputs in the dataset. In Table 3, we show both inter-class and intra-class interpolations. Note that we used a single AE for all shape categories for this task Illustration of Point Cloud Clustering We also provide an illustration of clustering 3D point clouds using the codewords obtained from FoldingNet. We used the ShapeNet dataset to train the AE and obtain codewords for the ModelNet10 dataset, which we will explain in details in Section 4.4. Then, we used T-SNE [34] to obtain an embedding of the high-dimensional codewords in




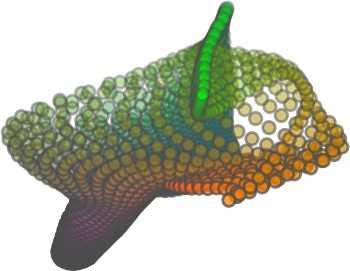


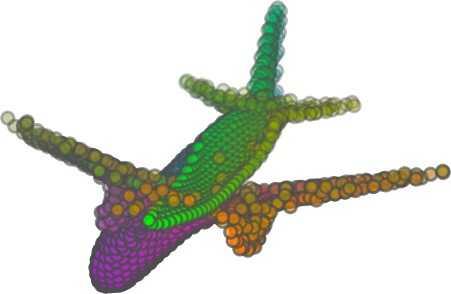

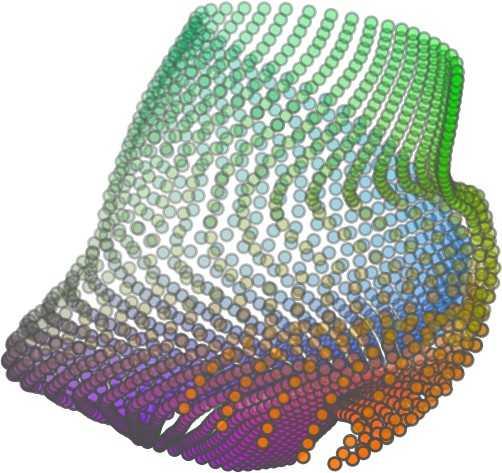
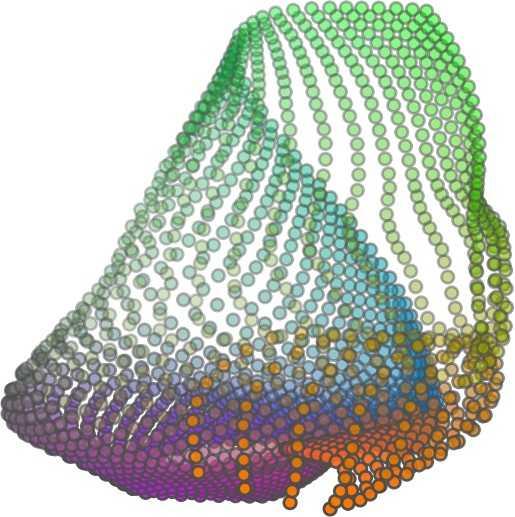
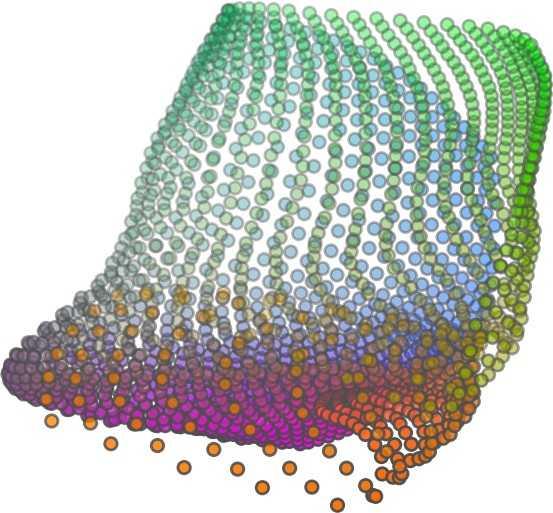

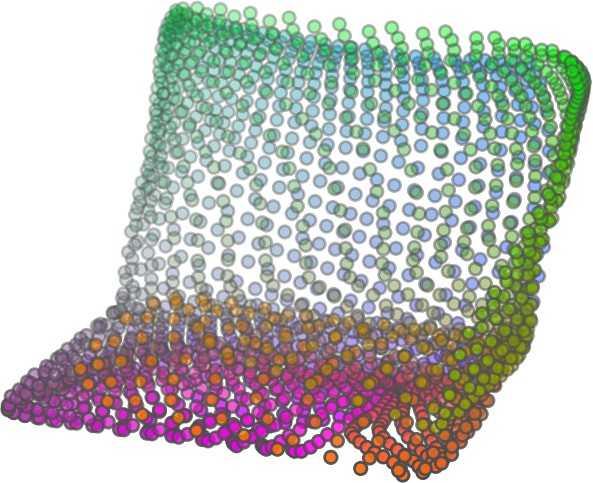
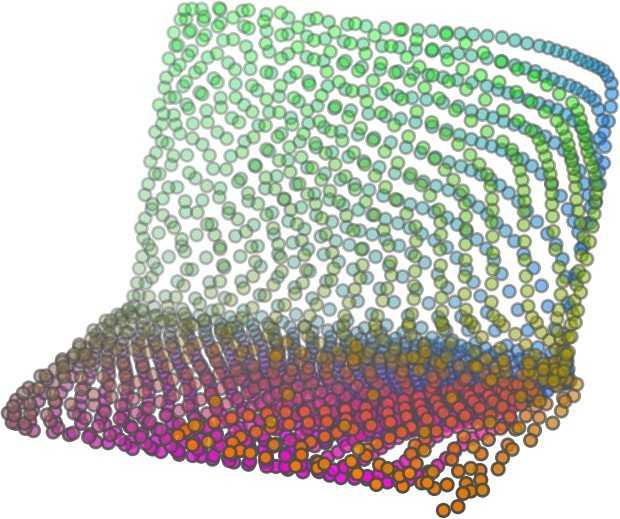
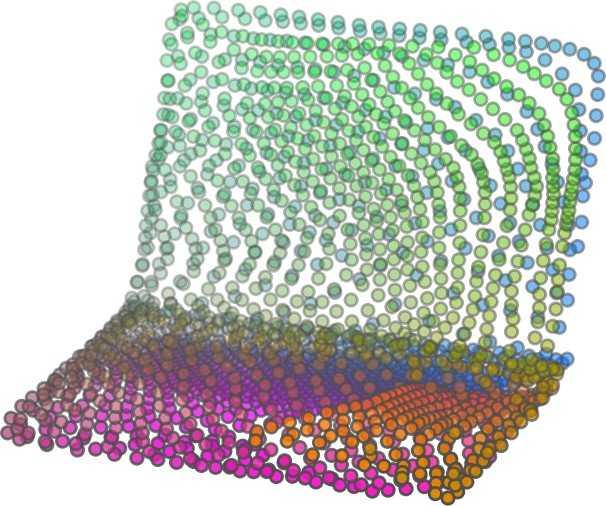
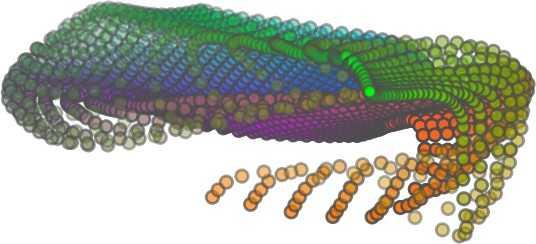
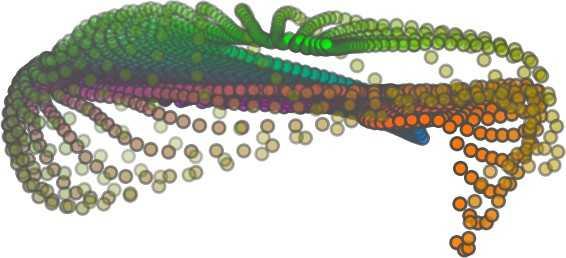



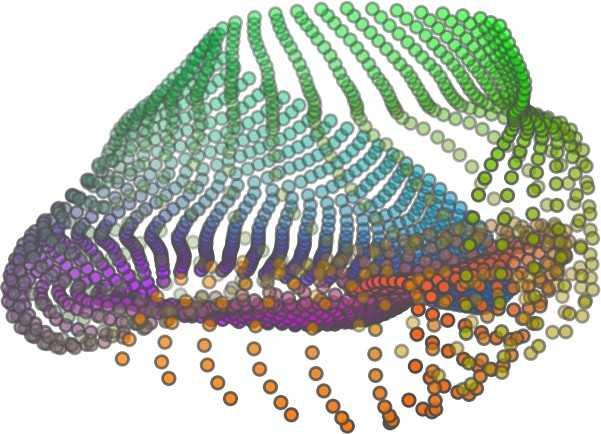
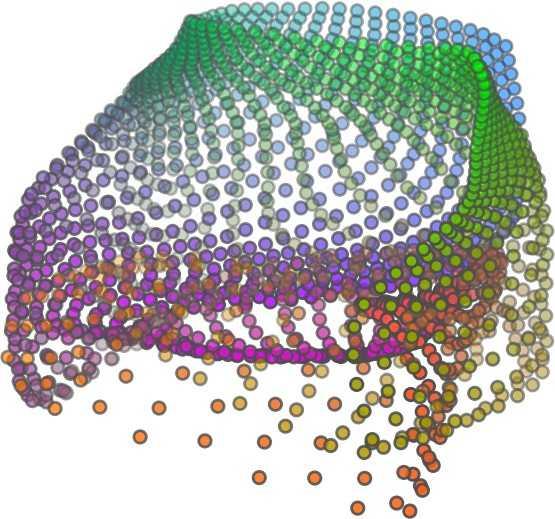
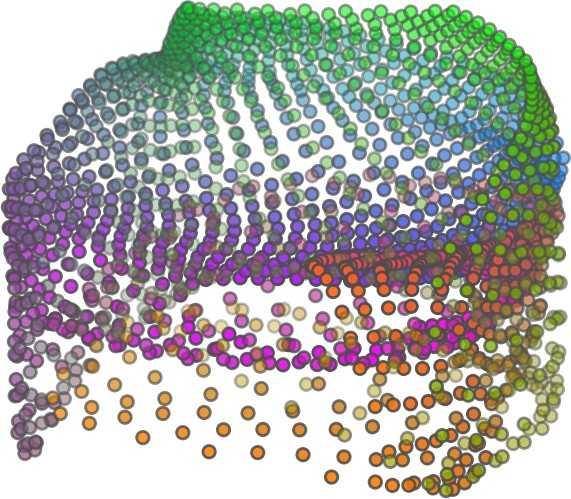

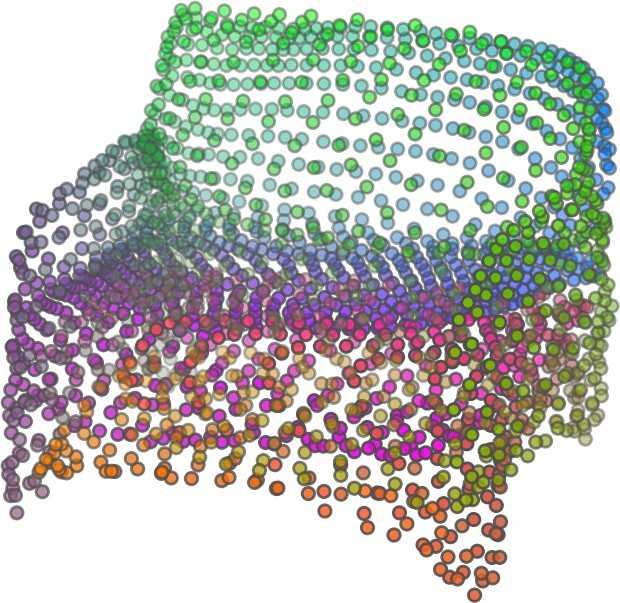
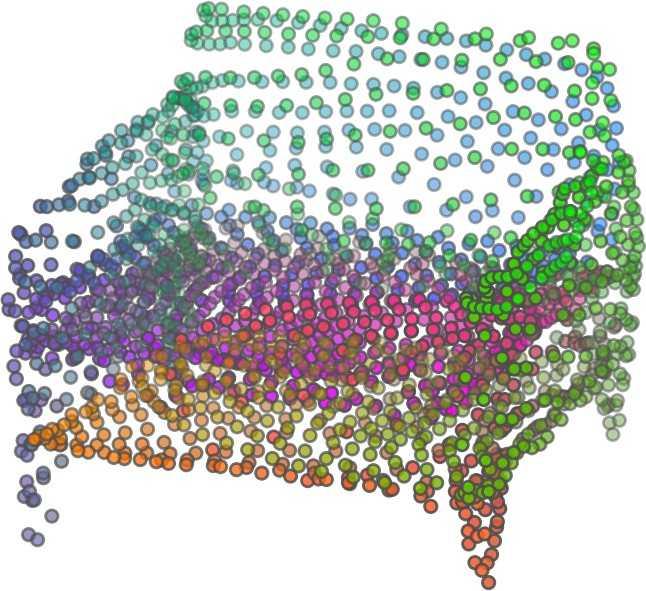
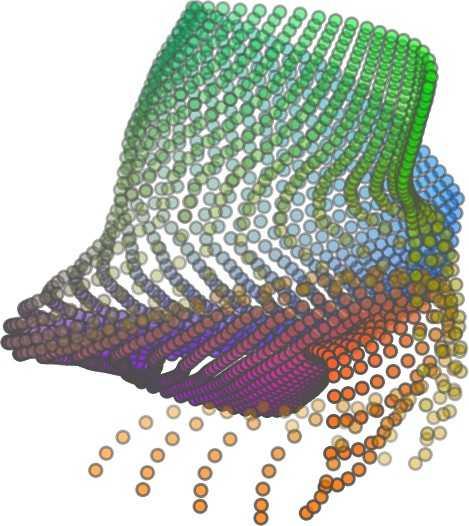

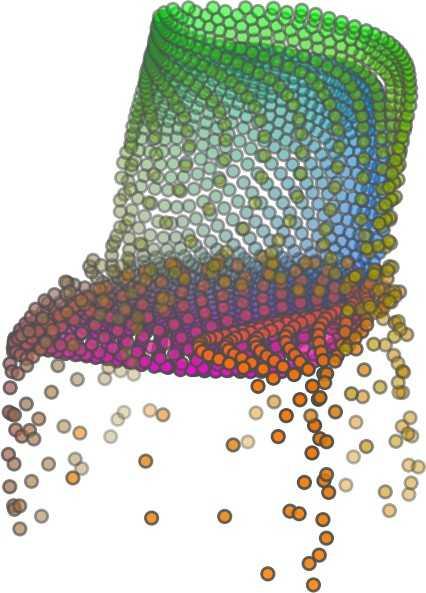
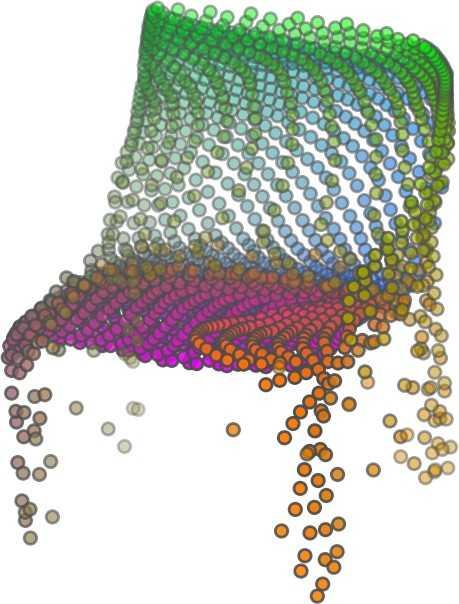
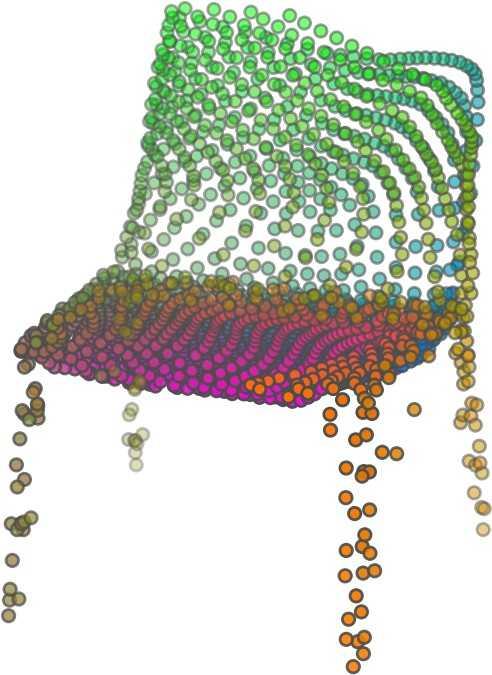
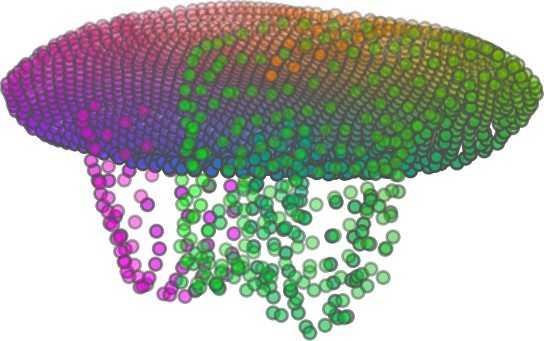
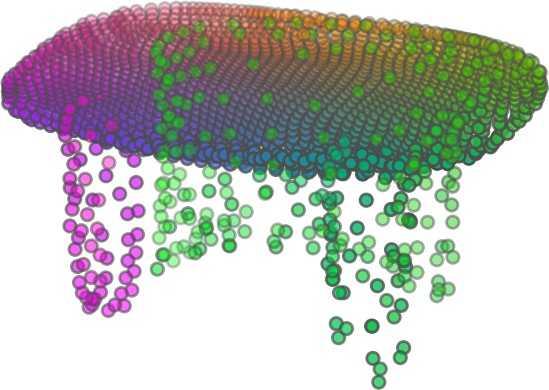

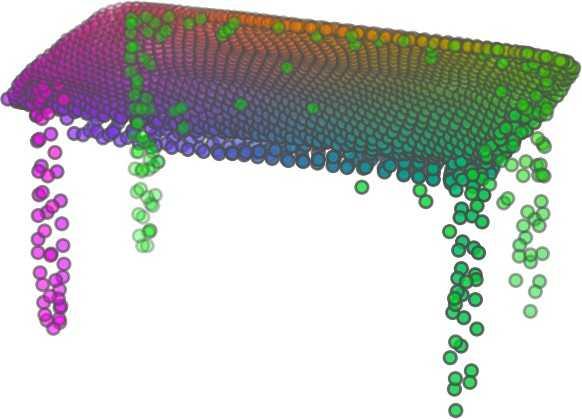


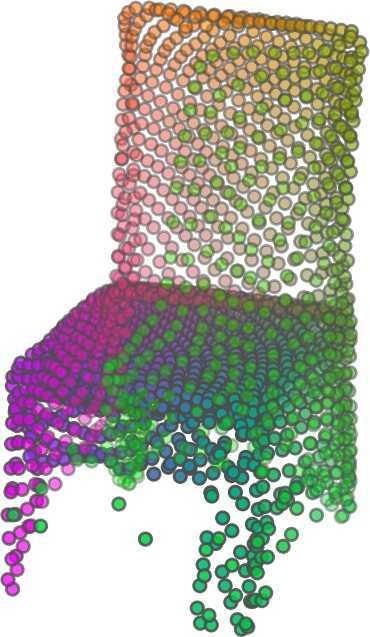
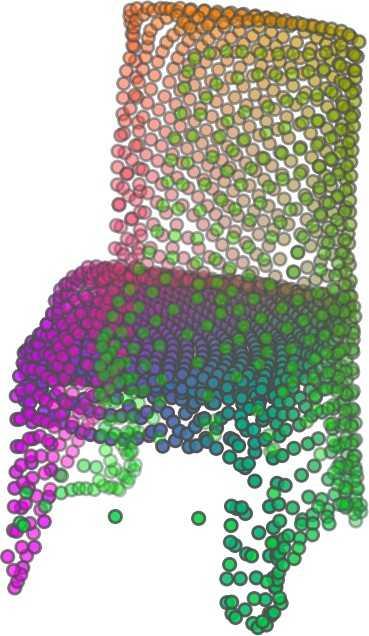

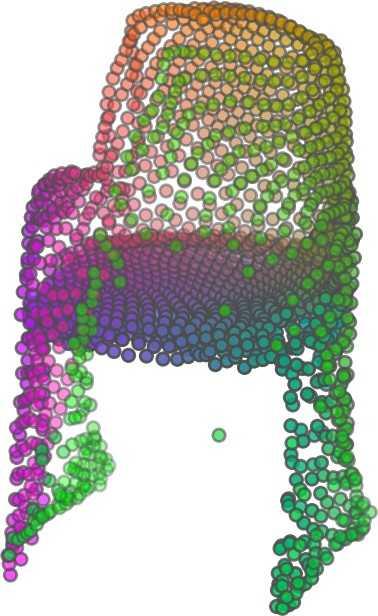




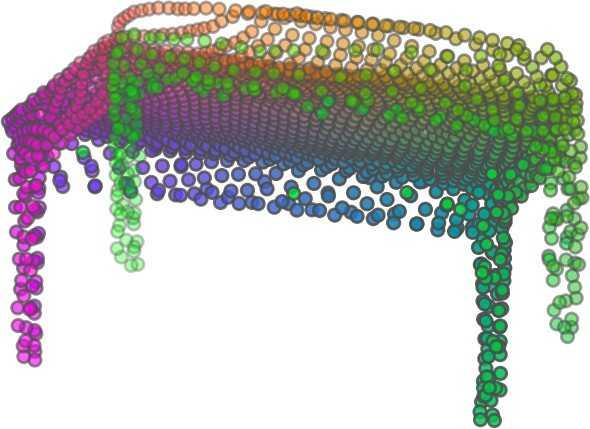
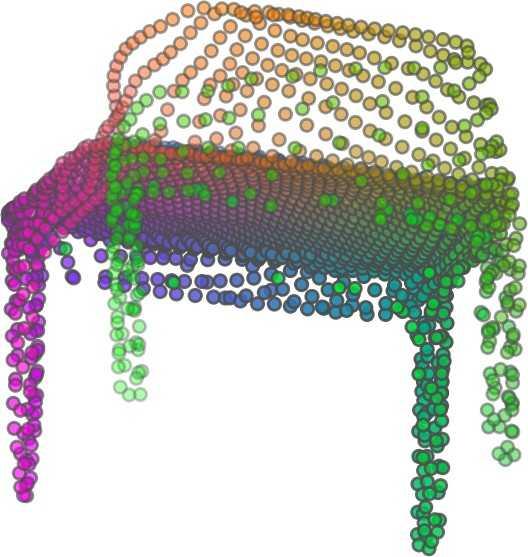
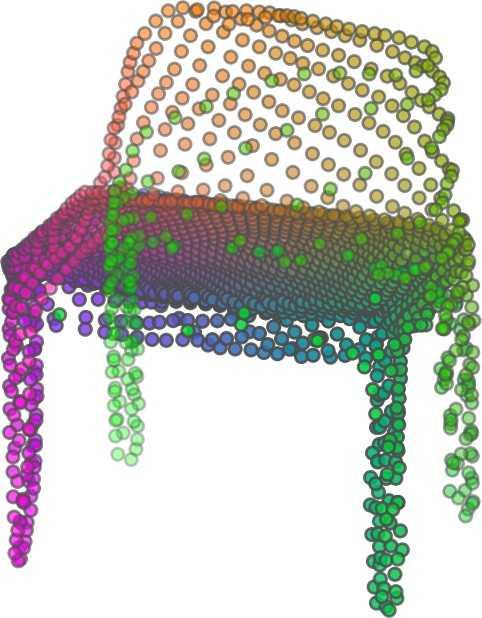
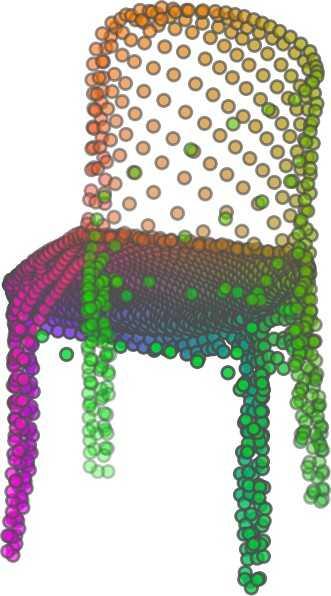


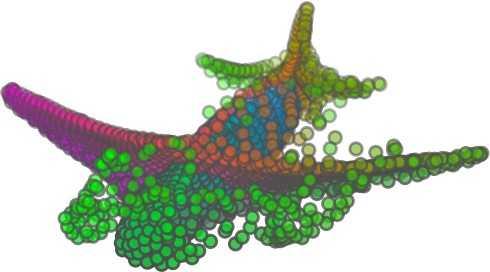
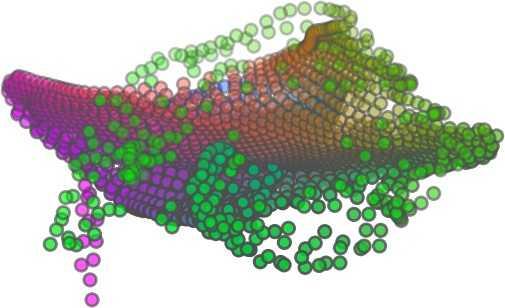




6 Input 5K iters 10K iters 20K iters 40K iters 100K iters 500K iters 4M iters Table 2. Illustration of the training process. Random 2D manifolds gradually transform into the surfaces of point clouds. Source Interpolations Target Table 3. Illustration of point cloud interpolation. The first 3 rows: intra-class interpolations. The last 3 rows: inter-class interpolations. R2. The parameter perplexity in T-SNE was set as 50. We show the embedding result in Figure 2. From the figure, we see that most classes are easily separable except {dresser (violet) v.s. nightstand (pink)} and {desk (red) v.s. table (yellow)}. We have visually checked these two pairs of classes, and found that many pairs cannot be easily distinguished even by a human. In Table 4, we list the most common mistakes made in classifying the ModelNet10 dataset Transfer Classification Accuracy In this section, we show the efficiency of FoldingNet in representation learning and feature extraction from 3D point clouds. In particular, we follow the routine from [1, 56] to train a linear SVM classifier on the ModelNet dataset [57] using the codewords (latent representations) obtained from the auto-encoder, while training the autoencoder from the ShapeNet dataset [7]. The train/test splits

7 Figure 2. The T-SNE clustering visualization of the codewords obtained from FoldingNet auto-encoder. Item 1 Item 2 Number of mistakes dresser night stand 19 table desk 15 bed bath tub 3 night stand table 3 Table 4. The first four types of mistakes made in the classification of ModelNet10 dataset. Their images are shown in the Supplementary Section 11. of the ModelNet dataset in our experiment is the same as in [41,56]. The point-cloud-format of the ShapeNet dataset is obtained by sampling random points on the triangles from the mesh models in the dataset. It contains models from 55 categories of man-made objects. The ModelNet datasets are the same one used in [41], and the MN40/MN10 datasets respectively contain 9843/3991 models for training and 2468/909 models for testing. Each point cloud in the selected datasets contains 2048 points with (x,y,z) positions normalized into a unit sphere as in [41]. The codewords obtained from the FoldingNet autoencoder is of length 512, which is the same as in [1] and smaller than 7168 in [57]. When training the auto-encoder, we used ADAM with an initial learning rate of and batch size of 1. We trained the auto-encoder for iterations (i.e., 278 epochs) on the ShapeNet dataset. Similar to [1, 41], when training the AE, we applied random rotations to each point cloud. Unlike the random rotations in [1, 41], we applied the rotation that is one of the 24 axisaligned rotations in the right-handed system. When training the linear SVM from the codewords obtained by the AE, we did not apply random rotations. We report our results in Table 5. The results of [8,19,26,45] are according to the report in [1, 56]. Since the training of the AE and the training of the SVM are based on different datasets, the experiment shows the transfer robustness of the FoldingNet. We also include a figure (see Figure 3) to show how the reconstruction loss decreases and the linear SVM classification accuracy increases during training. From Table 5, we can see that FoldingNet outperforms all other methods on the MN40 Classification Accuracy Chamfer distance v.s. classification accuracy on ModelNet Training epochs Figure 3. Linear SVM classification accuracy v.s. reconstruction loss on ModelNet40 dataset. The auto-encoder is trained using data from the ShapeNet dataset. Method MN40 MN10 SPH [26] 68.2% 79.8% LFD [8] 75.5% 79.9% T-L Network [19] 74.4% - VConv-DAE [45] 75.5% 80.5% 3D-GAN [56] 83.3% 91.0% Latent-GAN [1] 85.7% 95.3% FoldingNet (ours) 88.4% 94.4% Table 5. The comparison on classification accuracy between FoldingNet and other unsupervised methods. All the methods train a linear SVM on the high-dimensional representations obtained from unsupervised training. dataset. On the MN10 dataset, the auto-encoder proposed in [1] performs slightly better. However, the point-cloud format of the ModelNet10 dataset used in [1] is not public, so the point-cloud sampling protocol of ours may be different from the one in [1]. So it is inconclusive whether [1] is better than ours on MN10 dataset Semi-supervised Learning: What Happens when Labeled Data are Rare One of the main motivations to study unsupervised classification problems is that the number of labeled data is usually much smaller compared to the number of unlabeled data. In Section 4.4, the experiment is very close to this setting: the number of data in the ShapeNet dataset is large, which is more than , while the number of data in the labeled ModelNet dataset is small, which is around Since obtaining human-labeled data is usually hard, we would like to test how the performance of FoldingNet degrades when the number of labeled data is small. We still used the ShapeNet dataset to train the FoldingNet auto-encoder. Then, we trained the linear SVM using only a% of the overall training data in the ModelNet dataset, where a can be 1, 2, 5, 7.5, 10, 15, and 20. The test data for the linear SVM are always all the data in the test data partition of the ModelNet dataset. If the codewords obtained by the auto-encoder are already linearly separable, the re- Reconstruction loss (chamfer distance)
8 Classification Accuracy Classification Accuracy v.s. Number of Labeled Data % 100% 20% 15% 5% 7.5% 10% 0.5 1% Available Labeled Data/Overall Labeled Data Figure 4. Linear SVM classification accuracy v.s. percentage of available labeled training data in ModelNet40 dataset. Classification Accuracy Comparing FC decoder with Folding decoder Folding decoder FC decoder Training epochs Figure 5. Comparison between the fully-connected (FC) decoder in [1] and the folding decoder on ModelNet40. quired number of labeled data to train a linear SVM should be small. To demonstrate this intuitive statement, we report the experiment results in Figure 4. We can see that even if only 1% of the labeled training data are available (98 labeled training data, which is about 1 3 labeled data per class), the test accuracy is still more than 55%. When 20% of the training data are available, the test classification accuracy is already close to 85%, higher than most methods listed in Table Effectiveness of the Folding-Based Decoder In this section, we show that the folding-based decoder performs better in extracting features than the fullyconnected decoder proposed in [1] in terms of classification accuracy and reconstruction loss. We used the ModelNet40 dataset to train two deep auto-encoders. The first autoencoder uses the folding-based decoder that has the same structure as in Section 2.2, and the second auto-encoder uses a fully-connected three-layer perceptron as proposed in [1]. For the fully-connected decoder, the number of inputs and number of outputs in the three layers are respectively {512,1024}, {1024,2048}, {2048,2048 3}, which are the same as in [1]. The output is a 2048-by-3 ma- Reconstruction loss (chamfer distance) trix that contains the three-dimensional points in the output point cloud. The encoders of the two auto-encoders are both the graph-based encoder mentioned in Section 2.1. When training the AE, we used ADAM with an initial learning rate , a batch size 1, for iterations (i.e., 406 epochs) on the ModelNet40 training dataset. After training, we used the encoder to process all data in the ModelNet40 dataset to obtain a codeword for each point cloud. Then, similar to Section 4.4, we trained a linear SVM using these codewords and report the classification accuracy to see if the codewords are already linearly separable after encoding. The results are shown in Figure 5. During the training process, the reconstruction loss (measured in Chamfer distance) keeps decreasing, which means the reconstructed point cloud is more and more similar to the input point cloud. At the same time, the classification accuracy of the linear SVM trained on the codewords is increasing, which means the codeword representation becomes more linearly separable. From the figure, we can see that the folding decoder almost always has a higher accuracy and lower reconstruction loss. Compared to the fully-connected decoder that relies on the unnatural 1D order of the reconstructed 3D points in 3D space, the proposed decoder relies on the folding of an inherently 2D manifold corresponding to the point cloud inside the 3D space. As we mentioned earlier, this folding operation is more natural than the fully-connected decoder. Moreover, the number of parameters in the fully-connected decoder is , while the number of parameters in our folding decoder is , which is about 7% of the fully-connected decoder. One may wonder if uniformly random sampled 2D points on a plane can perform better than the 2D grid points in reconstructing point clouds. From our experiments, 2D grid points indeed provide reduced reconstruction loss than random points (Table 6 in Supplementary Section 8). Notice that our graph-based max-pooling encoder can be viewed as a generalized version of the maxpooling neural network PointNet [41]. The main difference is that the pooling operation in our encoder is done in a local neighborhood instead of globally (see Section 2.1). In Supplementary Section 10, we show that the graph-based encoder architecture is better than an encoder architecture without the graph-pooling layers mentioned in Section 2.1 in terms of robustness towards random disturbance in point positions. 5. Acknowledgment This work is supported by MERL. The authors would like to thank the helpful comments and suggestions from the anonymous reviewers, Teng-Yok Lee, Ziming Zhang, Zhiding Yu, Siheng Chen, Yuichi Taguchi, Mike Jones and Alan Sullivan.
9 References [1] P. Achlioptas, O. Diamanti, I. Mitliagkas, and L. Guibas. Representation learning and adversarial generation of 3d point clouds. arxiv preprint arxiv: , , 3, 4, 6, 7, 8 [2] J. Atwood and D. Towsley. Diffusion-convolutional neural networks. In Advances in Neural Information Processing Systems, pages , [3] A. Boulch, B. L. Saux, and N. Audebert. Unstructured point cloud semantic labeling using deep segmentation networks. In Eurographics Workshop on 3D Object Retrieval, volume 2, [4] A. Brock, T. Lim, J. M. Ritchie, and N. Weston. Generative and discriminative voxel modeling with convolutional neural networks. Advances in Neural Information Processing Systems, Workshop on 3D learning, [5] M. M. Bronstein, J. Bruna, Y. LeCun, A. Szlam, and P. Vandergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34(4):18 42, [6] J. Bruna, W. Zaremba, A. Szlam, and Y. LeCun. Spectral networks and locally connected networks on graphs. International Conference on Learning Representations (ICLR), [7] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, et al. Shapenet: An information-rich 3d model repository. CoRR, , 6 [8] D.-Y. Chen, X.-P. Tian, Y.-T. Shen, and M. Ouhyoung. On visual similarity based 3D model retrieval. Computer Graphics Forum, 22(3): , [9] X. Chen, K. Kundu, Y. Zhu, A. G. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3D object proposals for accurate object class detection. In Advances in Neural Information Processing Systems, pages , [10] S. Christoph Stein, M. Schoeler, J. Papon, and F. Worgotter. Object partitioning using local convexity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [11] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly-annotated 3D reconstructions of indoor scenes. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [12] M. Defferrard, X. Bresson, and P. Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems, pages , [13] D. Dohan, B. Matejek, and T. Funkhouser. Learning hierarchical semantic segmentations of LIDAR data. In International Conference on 3D Vision (3DV), pages IEEE, [14] D. K. Duvenaud, D. Maclaurin, J. Iparraguirre, R. Bombarell, T. Hirzel, A. Aspuru-Guzik, and R. P. Adams. Convolutional networks on graphs for learning molecular fingerprints. In Advances in neural information processing systems, pages , [15] M. Edwards and X. Xie. Graph based convolutional neural network. CoRR, [16] D. Ezuz, J. Solomon, V. G. Kim, and M. Ben-Chen. Gwcnn: A metric alignment layer for deep shape analysis. Computer Graphics Forum, 36(5):49 57, [17] H. Fan, H. Su, and L. Guibas. A point set generation network for 3D object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, , 13 [18] A. Geiger and C. Wang. Joint 3D object and layout inference from a single RGB-D image. In German Conference on Pattern Recognition, pages Springer, [19] R. Girdhar, D. F. Fouhey, M. Rodriguez, and A. Gupta. Learning a predictable and generative vector representation for objects. In European Conference on Computer Vision, pages Springer, [20] A. Golovinskiy, V. G. Kim, and T. Funkhouser. Shape-based recognition of 3d point clouds in urban environments. In 12th International Conference on Computer Vision, pages IEEE, [21] T. Hackel, J. D. Wegner, and K. Schindler. Contour detection in unstructured 3d point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [22] T. Hackel, J. D. Wegner, and K. Schindler. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Annals of Photogrammetry, Remote Sensing & Spatial Information Sciences, 3(3), [23] Y. Hechtlinger, P. Chakravarti, and J. Qin. A generalization of convolutional neural networks to graph-structured data. arxiv preprint arxiv: , [24] M. Henaff, J. Bruna, and Y. LeCun. Deep convolutional networks on graph-structured data. arxiv: , [25] J. Huang and S. You. Point cloud labeling using 3D convolutional neural network. In 23rd International Conference on Pattern Recognition (ICPR), pages IEEE, [26] M. Kazhdan, T. Funkhouser, and S. Rusinkiewicz. Rotation invariant spherical harmonic representation of 3d shape descriptors. In Symposium on geometry processing, volume 6, pages , [27] B.-S. Kim, P. Kohli, and S. Savarese. 3D scene understanding by voxel-crf. In Proceedings of the IEEE International Conference on Computer Vision, pages , [28] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. International Conference on Learning Representations (ICLR), [29] R. Klokov and V. Lempitsky. Escape from cells: Deep Kdnetworks for the recognition of 3D point cloud models. International Conference on Computer Vision (ICCV), [30] V. Kraevoy and A. Sheffer. Cross-parameterization and compatible remeshing of 3D models. ACM Transactions on Graphics (TOG), 23(3): , [31] K. Lai, L. Bo, and D. Fox. Unsupervised feature learning for 3D scene labeling. In IEEE International Conference on Robotics and Automation (ICRA), pages IEEE,
10 [32] R. Levie, F. Monti, X. Bresson, and M. M. Bronstein. Cayleynets: Graph convolutional neural networks with complex rational spectral filters. arxiv: , [33] Y. Li, S. Pirk, H. Su, C. R. Qi, and L. J. Guibas. Fpnn: Field probing neural networks for 3D data. In Advances in Neural Information Processing Systems, pages , [34] L. v. d. Maaten and G. Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(Nov): , [35] J. Masci, D. Boscaini, M. Bronstein, and P. Vandergheynst. Geodesic convolutional neural networks on riemannian manifolds. In Proceedings of the IEEE International conference on computer vision workshops, pages 37 45, [36] D. Maturana and S. Scherer. 3D convolutional neural networks for landing zone detection from LIDAR. In IEEE International Conference on Robotics and Automation (ICRA), pages IEEE, [37] D. Maturana and S. Scherer. Voxnet: A 3D convolutional neural network for real-time object recognition. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages IEEE, [38] F. Monti, D. Boscaini, J. Masci, E. Rodolà, J. Svoboda, and M. M. Bronstein. Geometric deep learning on graphs and manifolds using mixture model CNNs. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [39] M. Niepert, M. Ahmed, and K. Kutzkov. Learning convolutional neural networks for graphs. In International Conference on Machine Learning, pages , [40] G. Pang and U. Neumann. Fast and robust multi-view 3D object recognition in point clouds. In International Conference on 3D Vision (3DV), pages IEEE, [41] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3D classification and segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, , 3, 7, 8, 13 [42] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in Neural Information Processing Systems, [43] S. Ravanbakhsh, J. Schneider, and B. Poczos. Deep learning with sets and point clouds. International Conference on Learning Representations (ICLR), workshop track, [44] G. Riegler, A. O. Ulusoys, and A. Geiger. Octnet: Learning deep 3D representations at high resolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [45] A. Sharma, O. Grau, and M. Fritz. Vconv-DAE: Deep volumetric shape learning without object labels. In Computer Vision-ECCV 2016 Workshops, pages Springer, [46] Y. Shen, C. Feng, Y. Yang, and D. Tian. Mining point cloud local structures by kernel correlation and graph pooling. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [47] M. Simonovsky and N. Komodakis. Dynamic edgeconditioned filters in convolutional neural networks on graphs. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [48] R. Socher, B. Huval, B. Bath, C. D. Manning, and A. Y. Ng. Convolutional-recursive deep learning for 3D object classification. In Advances in Neural Information Processing Systems, pages , [49] S. Song and J. Xiao. Deep sliding shapes for amodal 3D object detection in RGB-D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [50] J. Strom, A. Richardson, and E. Olson. Graph-based segmentation for colored 3d laser point clouds. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages IEEE, [51] D. Thanou, P. A. Chou, and P. Frossard. Graph-based compression of dynamic 3d point cloud sequences. IEEE Transactions on Image Processing, 25(4): , [52] J.-C. Vialatte, V. Gripon, and G. Mercier. Generalizing the convolution operator to extend cnns to irregular domains. arxiv preprint arxiv: , [53] E. Wahl, U. Hillenbrand, and G. Hirzinger. Surflet-pairrelation histograms: a statistical 3D-shape representation for rapid classification. In Fourth International Conference on 3-D Digital Imaging and Modeling, pages IEEE, [54] P. Wang, Y. Gan, P. Shui, F. Yu, Y. Zhang, S. Chen, and Z. Sun. 3d shape segmentation via shape fully convolutional networks. Computers & Graphics, [55] Y. Wang, R. Ji, and S.-F. Chang. Label propagation from ImageNet to 3D point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [56] J. Wu, C. Zhang, T. Xue, B. Freeman, and J. Tenenbaum. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In Advances in Neural Information Processing Systems, pages 82 90, , 3, 6, 7 [57] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3D Shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , , 2, 3, 6, 7 [58] L. Yi, V. G. Kim, D. Ceylan, I. Shen, M. Yan, H. Su, A. Lu, Q. Huang, A. Sheffer, L. Guibas, et al. A scalable active framework for region annotation in 3d shape collections. ACM Transactions on Graphics (TOG), 35(6):210, , 5 [59] M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. Salakhutdinov, and A. Smola. Deep sets. Advances in Neural Information Processing Systems, [60] Q. Zhang, X. Song, X. Shao, H. Zhao, and R. Shibasaki. Unsupervised 3D category discovery and point labeling from a large urban environment. In IEEE International Conference on Robotics and Automation (ICRA), pages IEEE,
11 6. Supplementary: Proof of Theorem 3.1 Denote the input n-by-12 matrix by L. Denote by θ the codeword obtained by the encoder. Now we prove if the input is PL where P is an n-by-n permutation matrix, the codeword obtained from the encoder is still θ. The first part of the encoder is a per-point function, i.e., the 3-layer perceptron is applied to each row of the input matrix L. Denote the function by f 1. Then, it is obvious that f 1 (PL) = Pf 1 (L). The second part computes (2). Now we prove that for (2), PY = A max (PX)K. (4) Since Y = A max (X)K, we only need to prove A max (PX) = PA max (X). (5) Suppose the permutation operation P makes the i-th row of PX equal to x π(i), where π( ) is a permutation function on the set of row indexes {1, 2,..., n}. Then, from (3), the (i,j)-th entry of the matrix A max (PX) is (A max (PX)) ij = ReLU( max k N (π(i)) x kj). (6) In the meantime, the (π(i),j)-th entry of A max (PX) is (A max (X)) π(i)j = ReLU( max k N (π(i)) x kj). (7) Since the right hand side of (6) and (7) are the same, we know that the matrix A max (PX) can be obtained by changing the i-th row of A max (X) to the π(i)-th row, which means A max (PX) = PA max (X). Thus, we have proved that for the second part of the encoder, permuting the input rows is equivalent to permuting the output rows, i.e., (4) holds. Therefore, if we permute the input to the encoder, the output of the graph layers also permute. Then, we apply global max-pooling to the output of the graph layers. It is obvious that the result remains the same if the rows of the input to the global max-pooling layer (or the output of the graph layers) permute. The conclusion of Theorem 3.1 is hence proved. 7. Supplementary: Proof of Theorem 3.2 We prove the existence-based Theorem 3.2 by explicitly constructing a 2-layer perceptron and a codeword vector θ that satisfy the stated properties. The codeword is simply chosen as the vectorized form of the point cloud matrix S. In particular, For a matrix S of size m-by-3, if S = [s jk ], j = 1, 2,... m and k = 1, 2, 3, the codeword vector θ is chosen to be θ = [s 11, s 12, s 13, s 21, s 22, s 23,..., s m1, s m2, s m3 ]. Then, the i-th row after concatenation is v i = [x i, y i, s 11, s 12, s 13, s 21, s 22, s 23,..., s m1, s m2, s m3 ], where [x i, y i ] is the position of the i-th 2D grid point. Suppose the 2D grid points have an interval 2δ, i.e., the distance between any two points in the 2D grid is at least 2δ. Further assume these m grid points can all be written as [x i, y i ] = [(2β i + 1)δ, (2γ i + 1)δ], where β i and γ i are two integers whose absolute values are smaller than a positive constant M. One example of a set of 4-by-4 grid points is {[ 3δ, 3δ], [ 3δ, 1δ], [ 3δ, 1δ], [ 3δ, 3δ], [ 1δ, 3δ], [ 1δ, 1δ], [ 1δ, 1δ], [ 1δ, 3δ], [1δ, 3δ], [1δ, 1δ], [1δ, 1δ], [1δ, 3δ], [3δ, 3δ], [3δ, 1δ], [3δ, 1δ], [3δ, 3δ]}. In this case, the choice of M is 4. Also assume that the output point cloud is bounded inside 3-dimensional box of length 2 centered at the origin, i.e., s ij 1. Now, we construct a 2-layer perceptron f that takes the rows v i as inputs and provides the outputs f(v i ) = [s i1, s i2, s i3 ], for i = 1, 2,..., m. The input layer takes the vector intput v i which has 3m+2 scalars. The hidden layer has 3m neurons. The output layer provides three scalar outputs [s i1, s i2, s i3 ]. The 3m neurons in the hidden layer are partitioned into m groups of 3 neurons. The k-th neuron (k = 1, 2, 3) in the j-th group (j = 1, 2, 3,..., m) is only connected to three inputs x i, y i and [s j,k ], and it computes a linear combination of x i, y i and s j,k with weights and bias α j1 = u 2 x j, α j2 = uy j, α j3 = 1, (8) (9) b = u 2 x 2 j uy 2 j (10) where u is a positive constant to be specified later. Suppose the linear combination output is y j,k. The linear combination is followed by a nonlinear activation function 1 that computes the following { yj,k, if y z j,k = j,k < c, (11) 0, if y j,k c, where c is a constant to be specified later. The outputs of the activation functions are linearly combined to produce the final output. There are three neurons in the output layer. The k-th neuron (k=1,2,3) computes w k = m z j,k. (12) j=1 1 It is not hard to prove that this function can be obtained by concatenating ReLU functions with appropriate bias terms. We specifically avoid using the ReLU function in order not to hinder the main intuition. In all of our experiments, we use ReLU activation functions.
12 We assume the parameters (δ, u, c, M) satisfy u > 0, c > 0, δ > 0, M > 0, (13) uδ 2 > c + 1, (14) u > 8M 2 + 4M + 1, (15) c > 1. (16) Now we prove that for this perceptron, the final output [w 1, w 2, w 3 ] is indeed [s i1, s i2, s i3 ] when the input to the perceptron is v i. For the i-th input v i = [x i, y i, s 11, s 12, s 13, s 21, s 22, s 23,..., s m1, s m2, s m3 ], the k-th neuron in the j-th group in the hidden layer computes the following linear combination y j,k =α j1 x i + α j2 y i + α j3 s j,k + b =u 2 x j x i + uy j y i + s j,k u 2 x 2 j uy 2 j =u 2 x j (x i x j ) + uy j (y i y j ) + s j,k. (17) Notice that we have assumed [x i, y i ] = [(2β i + 1)δ, (2γ i + 1)δ], i. So we have y j,k = u 2 x j (x i x j ) + uy j (y i y j ) + s j,k =2u 2 δ 2 (2β j + 1)(β i β j ) + 2uδ 2 (2γ j + 1)(γ i γ j ) + s j,k =u 2 δ 2 m 1 + uδ 2 m 2 + s j,k, (18) where the two integer constants m 1 = 2(2β j + 1)(β i β j ) and m 2 = 2(2γ j +1)(γ i γ j ), and m 1 = 0 only if x i = x j and m 2 = 0 only if y i = y j. Since the absolute values of β i, β j, γ i and γ j are all smaller than M, we have m 1 2 2β j +1 β i β j < 2(2M+1) 2M = 8M 2 +4M. (19) Similarly, we have m 2 2 2γ j +1 γ i γ j < 2(2M+1) 2M = 8M 2 +4M. (20) Now we consider 3 possible cases: m 1 1: In this case, y j,k = u 2 δ 2 m 1 + uδ 2 m 2 + s j,k >u 2 δ 2 m 1 uδ 2 m 2 s j,k >u 2 δ 2 uδ 2 (8M 2 + 4M) 1 =uδ 2 [u (8M 2 + 4M)] 1 (a) > (c + 1) 1 1 = c, where step (a) follows from the assumption (14). m 1 = 0 but m 2 1: In this case, y j,k = uδ 2 m 2 + s j,k uδ 2 m 2 s j,k uδ 2 (a) c + 1 > c, (21) (22) where step (a) follows from assumption (15). m 1 = m 2 = 0. In this case, y j,k = s j,k 1 (a) < c, (23) where step (a) follows from assumption (16). Notice that the first two cases are equivalent to i j and the last case is equivalent to i = j. Thus, from (11), we have { sj,k, if j = i, z j,k = (24) 0, if j i. Thus, from (12), the final output is w k = m z j,k = s i,k, k = 1, 2, 3, (25) j=1 which means the output is indeed [s i,1, s i,2, s i,3 ] when the input is v i. This concludes the proof. 8. Supplementary: Decoder Variations The current decoder design has two consecutive folding operations that apply on a 2D grid. Therefore, one may wonder if the performance of FoldingNet can be improved if we utilize (1) more folding operations or (2) the same number of folding operations on regular grids of different dimensions. In this section, we report the results for these different settings. The experimental settings are the same with Section 4.6. The experiment results are shown in Table 6. As one can see from line 1 and line 2, increasing the number of folding operations does not significantly increase the performance. Comparing line 1 and line 3, one can see that a 2D grid is better than a 1D grid for both classification and reconstruction. From line 1 and line 4, one can see that a 3D grid only brings a marginal improvement. As we discussed in the introduction, this is because the intrinsic dimensionality of data in the ShapeNet and ModelNet datasets is 2, as they are sampled from object surfaces. If point clouds are intrinsically volumetric, we believe using a 3D grid in the decoder is more suitable. In addition, we also tried to generate the fixed grid by uniformly random Grid Setting #Folds Test Cls. Acc. Test Loss regular 2D % regular 2D % regular 1D % regular 3D % uniform 2D % Table 6. Comparison between different FoldingNet decoders. Uniform : the grid is uniformly random sampled. Regular : the grid is regularly sampled with fixed spacings.
13 sampling in the square. However, it leads to slightly worse results. We believe it is caused by the local density variation introduced by the random sampling. 9. Supplementary: Folding by Deconvolution The folding operation in Definition 1 is essentially a per-point 2D-to-3D function from a 2D grid to a 3D surface. A natural question to ask is whether introducing explicit correlations in the functions imposed on neighboring grid points can help improve the performance. We noted that there is a closely related work on reconstructing 3D point sets using side information from images [17]. The point reconstruction network in [17] uses deconvolution to fuse information on the regular grid structure imposed by the image, which is similar to the idea above. Here, we compare a deconvolution network with FoldingNet on the reconstruction performance. The feature sizes of the deconvolution network (C H W) are with kernel sizes 3, 3, 5, 5. The comparison is shown in Table 7. We conjecture that deconvolution goes beyond point-wise operations, thus imposes a stronger constraint on the smoothness of the reconstructed surface. Thus, its reconstruction is worse (although with comparable classification accuracy). On the other hand, the use of grids with point-wise MLP in FoldingNet only impose an implicit constraint, thus leading to better reconstructions. Cl. Acc. Tst. Loss # Params. FoldingNet 88.41% Deconv 88.86% Table 7. Comparison of two different implementations of the folding operation. 10. Supplementary: Robustness of the graphbased encoder Here, we use one experiment to show that the graphpooling layers are useful in maintaining the good performance of the FoldingNet when the data is subject to random noise. The following experiment compares FoldingNet with a deep auto-encoder that has the same folding-based decoder architecture but a different encoder architecture in which the graph-based max-pooling layers are removed. The setting of the experiment is the same as in Section 4.6 except that 5 percents of the points in each point cloud in the ModelNet40 dataset are randomly shifted to other positions (but still within the bounding box of the original point cloud). We use this noisy data to see how the performances degrade for the graph-based encoder and the encoder without graph-based max-pooling layers. The results are reported in Figure 6. We can see that when the graph-based Classification Accuracy Comparing Encoders with or without Graph Layers Graph-based Encoder Encoder without Graph Layers Training epochs Figure 6. Comparison between the graph-based encoder in Section 2.1 and the encoder from which the graph-based max-pooling layers are removed. The encoder with no graph-based layers is similar to the one proposed in [41] which is for a different goal (supervised learning). max-pooling layers are removed, the performance degrades by approximately 2 percents when noise is injected into the dataset. However, the classification accuracy of FoldingNet does not change much (when compared with Figure 5 in Section 4.6). Thus, it can be seen that the graph-based encoder can make FoldingNet more robust. Reconstruction loss (chamfer distance) 11. Supplementary: More Details on the Linear SVM Experiment on ModelNet10 The classification accuracy obtained in Section 4.4 on MN10 dataset is 94.4%. We stated in Section 4.5 that many pairs which are wrongly classified are actually hard to distinguish even by a human. In the table on the next page, we list all the incorrectly classified models and their point cloud representations. A phrase like table desk means the point cloud has label table but it is wrongly classified as desk by the linear SVM.











































14 toilet bed toilet bathtub toilet chair dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand monitor dresser desk table desk table desk sofa desk night stand desk table desk sofa desk table desk table bathtub bed bathtub table bathtub bed bathtub table bathtub bed table desk table desk table desk table desk table desk table desk table desk table desk table desk table desk table night stand sofa night stand night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand dresser night stand table night stand dresser night stand table chair bed
arxiv: v1 [cs.cv] 28 Nov 2018
![arxiv: v1 [cs.cv] 28 Nov 2018](/thumbs/91/104803963.jpg "arxiv: v1 [cs.cv] 28 Nov 2018") MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
arxiv: v1 [cs.cv] 27 Jan 2019
![arxiv: v1 [cs.cv] 27 Jan 2019](/thumbs/95/122752774.jpg "arxiv: v1 [cs.cv] 27 Jan 2019") : Euclidean Point Cloud Auto-Encoder and Sampler Edoardo Remelli 1 Pierre Baque 1 Pascal Fua 1 Abstract arxiv:1901.09394v1 [cs.cv] 27 Jan 2019 Most algorithms that rely on deep learning-based approaches
: Euclidean Point Cloud Auto-Encoder and Sampler Edoardo Remelli 1 Pierre Baque 1 Pascal Fua 1 Abstract arxiv:1901.09394v1 [cs.cv] 27 Jan 2019 Most algorithms that rely on deep learning-based approaches
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
 Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling Yiru Shen yirus@g.clemson.edu Chen Feng cfeng@merl.com Yaoqing Yang yyaoqing@andrew.cmu.edu Dong Tian tian@merl.com Clemson University
Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling Yiru Shen yirus@g.clemson.edu Chen Feng cfeng@merl.com Yaoqing Yang yyaoqing@andrew.cmu.edu Dong Tian tian@merl.com Clemson University
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
Learning Adversarial 3D Model Generation with 2D Image Enhancer
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network
 Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network Marko Filipović, Petra Ðurović and Robert Cupec Faculty of Electrical Engineering, Computer Science and Information
Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network Marko Filipović, Petra Ðurović and Robert Cupec Faculty of Electrical Engineering, Computer Science and Information
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
Deep Learning on Graphs
 Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
SO-Net: Self-Organizing Network for Point Cloud Analysis
 SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore Abstract This paper presents SO-Net, a permutation invariant architecture for
SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore Abstract This paper presents SO-Net, a permutation invariant architecture for
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY
 MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Convolutional-Recursive Deep Learning for 3D Object Classification
 Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv: v4 [cs.cv] 27 Mar 2018
![arxiv: v4 [cs.cv] 27 Mar 2018](/thumbs/96/128983416.jpg "arxiv: v4 [cs.cv] 27 Mar 2018") SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore arxiv:1803.04249v4 [cs.cv] 27 Mar 2018 Abstract This paper presents SO-Net, a
SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore arxiv:1803.04249v4 [cs.cv] 27 Mar 2018 Abstract This paper presents SO-Net, a
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval
 Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
arxiv: v1 [cs.cv] 13 Feb 2018
![arxiv: v1 [cs.cv] 13 Feb 2018](/thumbs/85/92549074.jpg "arxiv: v1 [cs.cv] 13 Feb 2018") Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Deep Learning on Point Sets for 3D Classification and Segmentation
 Deep Learning on Point Sets for 3D Classification and Segmentation Charles Ruizhongtai Qi Stanford University rqi@stanford.edu Abstract Point cloud is an important type of geometric data structure. Due
Deep Learning on Point Sets for 3D Classification and Segmentation Charles Ruizhongtai Qi Stanford University rqi@stanford.edu Abstract Point cloud is an important type of geometric data structure. Due
Deep Learning on Graphs
 Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 6 April 2017 joint work with Max Welling (University of Amsterdam) The success story of deep
Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 6 April 2017 joint work with Max Welling (University of Amsterdam) The success story of deep
Su et al. Shape Descriptors - III
 Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation
 SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong Abstract In this paper, we study the problem
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong Abstract In this paper, we study the problem
Multiresolution Tree Networks for 3D Point Cloud Processing
 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network
 Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
AI Ukraine Point cloud labeling using machine learning
 AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues
 Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues Ludovico Minto, Pietro Zanuttigh and Giampaolo Pagnutti Department of Information Engineering, University
Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues Ludovico Minto, Pietro Zanuttigh and Giampaolo Pagnutti Department of Information Engineering, University
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Learning to Sample. Shai Avidan Tel-Aviv University. Oren Dovrat Tel-Aviv University. Itai Lang Tel-Aviv University. Abstract. 1.
 Learning to Sample Oren Dovrat Tel-Aviv University Itai Lang Tel-Aviv University Shai Avidan Tel-Aviv University We propose a simplification network, termed S-NET, that is based on the architecture of
Learning to Sample Oren Dovrat Tel-Aviv University Itai Lang Tel-Aviv University Shai Avidan Tel-Aviv University We propose a simplification network, termed S-NET, that is based on the architecture of
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Deep Learning. Deep Learning provided breakthrough results in speech recognition and image classification. Why?
 Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
From processing to learning on graphs
 From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
 Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
arxiv: v1 [cs.cv] 2 Dec 2016
![arxiv: v1 [cs.cv] 2 Dec 2016](/thumbs/89/98281292.jpg "arxiv: v1 [cs.cv] 2 Dec 2016") SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong arxiv:1612.00606v1 [cs.cv] 2 Dec 2016 Abstract
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong arxiv:1612.00606v1 [cs.cv] 2 Dec 2016 Abstract
When Big Datasets are Not Enough: The need for visual virtual worlds.
 When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Charles R. Qi Li Yi Hao Su Leonidas J. Guibas Stanford University Abstract Few prior works study deep learning on point sets.
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Charles R. Qi Li Yi Hao Su Leonidas J. Guibas Stanford University Abstract Few prior works study deep learning on point sets.
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
Supplementary Material for Ensemble Diffusion for Retrieval
 Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
arxiv: v4 [cs.cv] 29 Mar 2019
![arxiv: v4 [cs.cv] 29 Mar 2019](/thumbs/96/128038877.jpg "arxiv: v4 [cs.cv] 29 Mar 2019") PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
Cross-domain Deep Encoding for 3D Voxels and 2D Images
 Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Large-Scale Traffic Sign Recognition based on Local Features and Color Segmentation
 Large-Scale Traffic Sign Recognition based on Local Features and Color Segmentation M. Blauth, E. Kraft, F. Hirschenberger, M. Böhm Fraunhofer Institute for Industrial Mathematics, Fraunhofer-Platz 1,
Large-Scale Traffic Sign Recognition based on Local Features and Color Segmentation M. Blauth, E. Kraft, F. Hirschenberger, M. Böhm Fraunhofer Institute for Industrial Mathematics, Fraunhofer-Platz 1,
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Does the Brain do Inverse Graphics?
 Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto How to learn many layers of features
Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto How to learn many layers of features
3D Deep Learning
 3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material
 Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material Ameesh Makadia Google New York, NY 10011 makadia@google.com Mehmet Ersin Yumer Carnegie Mellon University Pittsburgh, PA 15213
Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material Ameesh Makadia Google New York, NY 10011 makadia@google.com Mehmet Ersin Yumer Carnegie Mellon University Pittsburgh, PA 15213
Visual object classification by sparse convolutional neural networks
 Visual object classification by sparse convolutional neural networks Alexander Gepperth 1 1- Ruhr-Universität Bochum - Institute for Neural Dynamics Universitätsstraße 150, 44801 Bochum - Germany Abstract.
Visual object classification by sparse convolutional neural networks Alexander Gepperth 1 1- Ruhr-Universität Bochum - Institute for Neural Dynamics Universitätsstraße 150, 44801 Bochum - Germany Abstract.
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Learning Descriptor Networks for 3D Shape Synthesis and Analysis
 Learning Descriptor Networks for 3D Shape Synthesis and Analysis Jianwen Xie 1, Zilong Zheng 2, Ruiqi Gao 2, Wenguan Wang 2,3, Song-Chun Zhu 2, Ying Nian Wu 2 1 Hikvision Research Institute 2 University
Learning Descriptor Networks for 3D Shape Synthesis and Analysis Jianwen Xie 1, Zilong Zheng 2, Ruiqi Gao 2, Wenguan Wang 2,3, Song-Chun Zhu 2, Ying Nian Wu 2 1 Hikvision Research Institute 2 University
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Lab meeting (Paper review session) Stacked Generative Adversarial Networks
 Stacked Generative Adversarial Networks") Lab meeting (Paper review session) Stacked Generative Adversarial Networks 2017. 02. 01. Saehoon Kim (Ph. D. candidate) Machine Learning Group Papers to be covered Stacked Generative Adversarial Networks
Lab meeting (Paper review session) Stacked Generative Adversarial Networks 2017. 02. 01. Saehoon Kim (Ph. D. candidate) Machine Learning Group Papers to be covered Stacked Generative Adversarial Networks
ROOFN3D: DEEP LEARNING TRAINING DATA FOR 3D BUILDING RECONSTRUCTION
 ROOFN3D: DEEP LEARNING TRAINING DATA FOR 3D BUILDING RECONSTRUCTION Andreas Wichmann, Amgad Agoub, Martin Kada Institute of Geodesy and Geoinformation Science (IGG), Technische Universität Berlin, Straße
ROOFN3D: DEEP LEARNING TRAINING DATA FOR 3D BUILDING RECONSTRUCTION Andreas Wichmann, Amgad Agoub, Martin Kada Institute of Geodesy and Geoinformation Science (IGG), Technische Universität Berlin, Straße
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
arxiv: v1 [cs.cv] 21 Jun 2017
![arxiv: v1 [cs.cv] 21 Jun 2017](/thumbs/82/85530580.jpg "arxiv: v1 [cs.cv] 21 Jun 2017") Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction arxiv:1706.07036v1 [cs.cv] 21 Jun 2017 Chen-Hsuan Lin, Chen Kong, Simon Lucey The Robotics Institute Carnegie Mellon University
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction arxiv:1706.07036v1 [cs.cv] 21 Jun 2017 Chen-Hsuan Lin, Chen Kong, Simon Lucey The Robotics Institute Carnegie Mellon University
arxiv: v1 [cs.cv] 2 Dec 2018
![arxiv: v1 [cs.cv] 2 Dec 2018](/thumbs/91/106472963.jpg "arxiv: v1 [cs.cv] 2 Dec 2018") PVRNet: Point-View Relation Neural Network for 3D Shape Recognition Haoxuan You 1, Yifan Feng 2, Xibin Zhao 1, hangqing Zou 3, Rongrong Ji 2, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University,
PVRNet: Point-View Relation Neural Network for 3D Shape Recognition Haoxuan You 1, Yifan Feng 2, Xibin Zhao 1, hangqing Zou 3, Rongrong Ji 2, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University,
LEARNING LOCALIZED GENERATIVE MODELS FOR 3D POINT CLOUDS VIA GRAPH CONVOLUTION
 LEARNING LOCALIZED GENERATIVE MODELS FOR 3D POINT CLOUDS VIA GRAPH CONVOLUTION Diego Valsesia Politecnico di Torino Torino, Italy diego.valsesia@polito.it Giulia Fracastoro Politecnico di Torino Torino,
LEARNING LOCALIZED GENERATIVE MODELS FOR 3D POINT CLOUDS VIA GRAPH CONVOLUTION Diego Valsesia Politecnico di Torino Torino, Italy diego.valsesia@polito.it Giulia Fracastoro Politecnico di Torino Torino,
Deep Learning. Deep Learning. Practical Application Automatically Adding Sounds To Silent Movies
 http://blog.csdn.net/zouxy09/article/details/8775360 Automatic Colorization of Black and White Images Automatically Adding Sounds To Silent Movies Traditionally this was done by hand with human effort
http://blog.csdn.net/zouxy09/article/details/8775360 Automatic Colorization of Black and White Images Automatically Adding Sounds To Silent Movies Traditionally this was done by hand with human effort
Flexible Calibration of a Portable Structured Light System through Surface Plane
 Vol. 34, No. 11 ACTA AUTOMATICA SINICA November, 2008 Flexible Calibration of a Portable Structured Light System through Surface Plane GAO Wei 1 WANG Liang 1 HU Zhan-Yi 1 Abstract For a portable structured
Vol. 34, No. 11 ACTA AUTOMATICA SINICA November, 2008 Flexible Calibration of a Portable Structured Light System through Surface Plane GAO Wei 1 WANG Liang 1 HU Zhan-Yi 1 Abstract For a portable structured
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Urban Scene Segmentation, Recognition and Remodeling. Part III. Jinglu Wang 11/24/2016 ACCV 2016 TUTORIAL
 Part III Jinglu Wang Urban Scene Segmentation, Recognition and Remodeling 102 Outline Introduction Related work Approaches Conclusion and future work o o - - ) 11/7/16 103 Introduction Motivation Motivation
Part III Jinglu Wang Urban Scene Segmentation, Recognition and Remodeling 102 Outline Introduction Related work Approaches Conclusion and future work o o - - ) 11/7/16 103 Introduction Motivation Motivation
Does the Brain do Inverse Graphics?
 Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto The representation used by the
Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto The representation used by the
arxiv: v1 [cs.cv] 28 Nov 2017
![arxiv: v1 [cs.cv] 28 Nov 2017](/thumbs/81/83356256.jpg "arxiv: v1 [cs.cv] 28 Nov 2017") 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction
 Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction Chen-Hsuan Lin Chen Kong Simon Lucey The Robotics Institute Carnegie Mellon University chlin@cmu.edu, {chenk,slucey}@cs.cmu.edu
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction Chen-Hsuan Lin Chen Kong Simon Lucey The Robotics Institute Carnegie Mellon University chlin@cmu.edu, {chenk,slucey}@cs.cmu.edu
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Learning to Match. Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li
 Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
arxiv: v1 [cs.cv] 27 Nov 2018 Abstract
![arxiv: v1 [cs.cv] 27 Nov 2018 Abstract](/thumbs/91/105025156.jpg "arxiv: v1 [cs.cv] 27 Nov 2018 Abstract") Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS
 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Large-Scale Point Cloud Classification Benchmark
 Large-Scale Point Cloud Classification Benchmark www.semantic3d.net IGP & CVG, ETH Zürich www.semantic3d.net, info@semantic3d.net 7/6/2016 1 Timo Hackel Nikolay Savinov Ľubor Ladický Jan Dirk Wegner Konrad
Large-Scale Point Cloud Classification Benchmark www.semantic3d.net IGP & CVG, ETH Zürich www.semantic3d.net, info@semantic3d.net 7/6/2016 1 Timo Hackel Nikolay Savinov Ľubor Ladický Jan Dirk Wegner Konrad
arxiv: v1 [cs.cv] 28 Nov 2018
![arxiv: v1 [cs.cv] 28 Nov 2018](/thumbs/92/107776900.jpg "arxiv: v1 [cs.cv] 28 Nov 2018") A GRAPH-CNN FOR 3D POINT CLOUD CLASSIFICATION Yingxue Zhang and Michael Rabbat McGill University Montreal, Canada arxiv:1812.01711v1 [cs.cv] 28 Nov 2018 ABSTRACT Graph convolutional neural networks (Graph-CNNs)
A GRAPH-CNN FOR 3D POINT CLOUD CLASSIFICATION Yingxue Zhang and Michael Rabbat McGill University Montreal, Canada arxiv:1812.01711v1 [cs.cv] 28 Nov 2018 ABSTRACT Graph convolutional neural networks (Graph-CNNs)
Structure-oriented Networks of Shape Collections
 Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
GraphNet: Recommendation system based on language and network structure
 GraphNet: Recommendation system based on language and network structure Rex Ying Stanford University rexying@stanford.edu Yuanfang Li Stanford University yli03@stanford.edu Xin Li Stanford University xinli16@stanford.edu
GraphNet: Recommendation system based on language and network structure Rex Ying Stanford University rexying@stanford.edu Yuanfang Li Stanford University yli03@stanford.edu Xin Li Stanford University xinli16@stanford.edu
Simulation of Zhang Suen Algorithm using Feed- Forward Neural Networks
 Simulation of Zhang Suen Algorithm using Feed- Forward Neural Networks Ritika Luthra Research Scholar Chandigarh University Gulshan Goyal Associate Professor Chandigarh University ABSTRACT Image Skeletonization
Simulation of Zhang Suen Algorithm using Feed- Forward Neural Networks Ritika Luthra Research Scholar Chandigarh University Gulshan Goyal Associate Professor Chandigarh University ABSTRACT Image Skeletonization
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
JOINT INTENT DETECTION AND SLOT FILLING USING CONVOLUTIONAL NEURAL NETWORKS. Puyang Xu, Ruhi Sarikaya. Microsoft Corporation
 JOINT INTENT DETECTION AND SLOT FILLING USING CONVOLUTIONAL NEURAL NETWORKS Puyang Xu, Ruhi Sarikaya Microsoft Corporation ABSTRACT We describe a joint model for intent detection and slot filling based
JOINT INTENT DETECTION AND SLOT FILLING USING CONVOLUTIONAL NEURAL NETWORKS Puyang Xu, Ruhi Sarikaya Microsoft Corporation ABSTRACT We describe a joint model for intent detection and slot filling based
GLOBAL SAMPLING OF IMAGE EDGES. Demetrios P. Gerogiannis, Christophoros Nikou, Aristidis Likas
 GLOBAL SAMPLING OF IMAGE EDGES Demetrios P. Gerogiannis, Christophoros Nikou, Aristidis Likas Department of Computer Science and Engineering, University of Ioannina, 45110 Ioannina, Greece {dgerogia,cnikou,arly}@cs.uoi.gr
GLOBAL SAMPLING OF IMAGE EDGES Demetrios P. Gerogiannis, Christophoros Nikou, Aristidis Likas Department of Computer Science and Engineering, University of Ioannina, 45110 Ioannina, Greece {dgerogia,cnikou,arly}@cs.uoi.gr
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
08 An Introduction to Dense Continuous Robotic Mapping
 NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
Learning to Recognize Faces in Realistic Conditions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Preparation Meeting. Recent Advances in the Analysis of 3D Shapes. Emanuele Rodolà Matthias Vestner Thomas Windheuser Daniel Cremers
 Preparation Meeting Recent Advances in the Analysis of 3D Shapes Emanuele Rodolà Matthias Vestner Thomas Windheuser Daniel Cremers What You Will Learn in the Seminar Get an overview on state of the art
Preparation Meeting Recent Advances in the Analysis of 3D Shapes Emanuele Rodolà Matthias Vestner Thomas Windheuser Daniel Cremers What You Will Learn in the Seminar Get an overview on state of the art
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to