Top500
|
|
|
- Margaret McDowell
- 6 years ago
- Views:
Transcription
1 Top500 Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1

2 2
3 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance numbers reflect the largest problem run on a given machine R max the performance in Gflops for the largest problem run on a machine N max the size of the largest problem run on a machine N 1/2 the size where half the R max execution rate is achieved R peak the theoretical peak performance in Glops for the machine 3
4 Linpack benchmark Pros One number: R max Simple to define and and use to rank Allows problem size to change with machine and over time Cons Emphasizes only peak speed and number of CPUs Does not stress the networks Ignores Amdhal s Law (changing problem size when more CPU are exploited) 4
5 5

6 6

7 ASCI: Advanced Simulation and Computing Program Ricerca finanziata dal governo americano per simulare, soprattutto, sistemi d arma 7
8 8
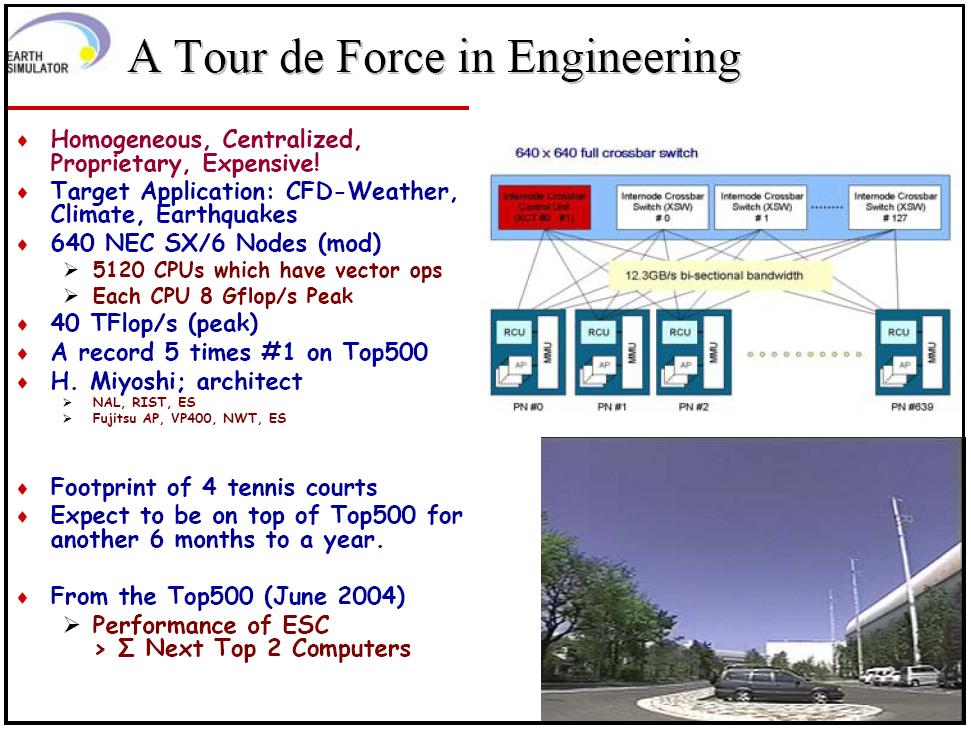

9 9
10 Top 10 remarks (June 2007) A lot of shuffling among the top-ranked systems No. 1: The BlueGene/L (development by IBM and DOE s National Nuclear Security Administration (NNSA) ) reached a Linpack benchmark performance of TFlop/s ( teraflops = ) Two other systems exceeded the level of 100 TFlop/s: the upgraded Cray XT4/XT3 at DOE s Oak Ridge National Laboratory, ranked No. 2 with a benchmark performance of TFlop/s; Sandia National Laboratory s Cray Red Storm system, which ranked third at TFlop/s. Two new IBM BlueGene/L systems entered the Top 10 (New York and Troy: the largest supercomputing installations in an academic setting. The fastest supercomputer in Europe is an IBM JS21 cluster at the Barcelona Supercomputing Center in Spain, which ranked No. 9 at TFlop/s. The highest ranked Japanese system is located at the Tokyo Institute of Technology and ranks No. 14 on the list. This system is a cluster integrated by NEC based on Sun Fire x4600 with Opteron processors, ClearSpeed accelerators and an InfiniBand interconnect. 10
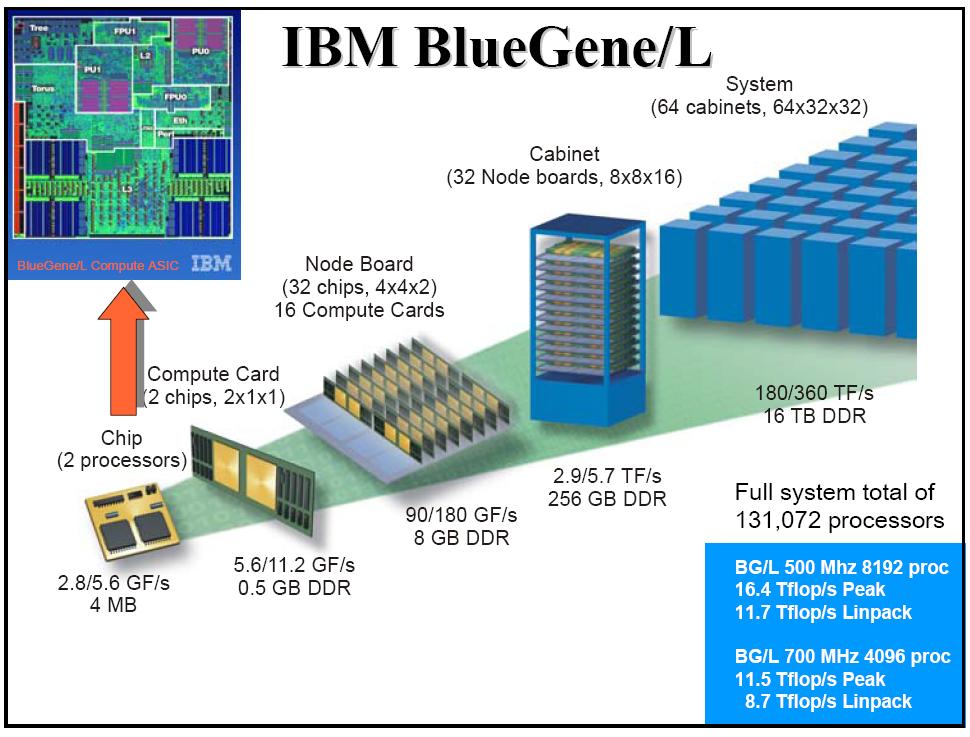
11 11
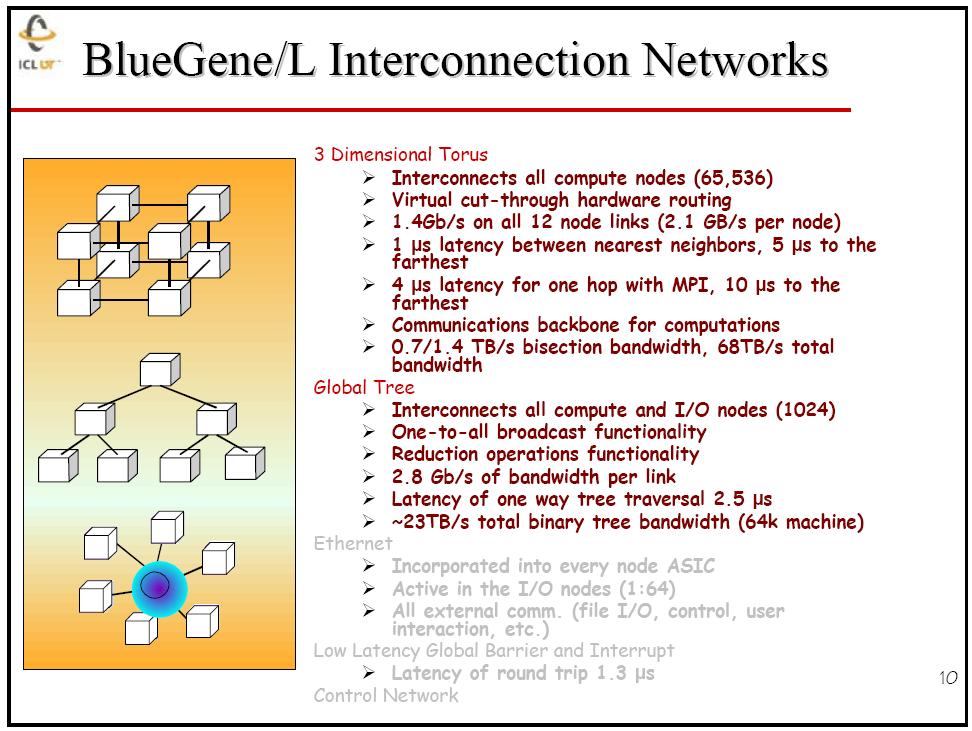
12 12
13 Top 10 of Top 500 (June 2009) Rmax and Rpeak values are in GFlops. Power data in KW for entire system Rank Computer Cores Rmax Rpeak (Gflops) (Gflops) Nmax Power (kw) Processor 1 BladeCenter QS22/LS21 Cluster ,47 PowerXCell 8i 2 Cray XT5 QC 2.3 GHz ,6 AMD x86_64 Opteron Quad Core 3 Blue Gene/P Solution PowerPC SGI Altix ICE 8200EX, Xeon QC 3.0/2.66 GHz Intel EM64T Xeon E54xx (Harpertown) 5 eserver Blue Gene Solution ,6 PowerPC Cray XT5 QC 2.3 GHz AMD x86_64 Opteron Quad Core 7 Blue Gene/P Solution PowerPC SunBlade x6420, Opteron QC 2.3 Ghz, Infiniband AMD x86_64 Opteron Quad Core 9 Blue Gene/P Solution PowerPC 450 Sun Constellation, NovaScale Intel EM64T Xeon 10 R422-E X55xx (Nehalem-EP) 46: CINECA-IT, IBM Power 575, p6 4.7 GHz, Infiniband, Year 2009 Cores=5376 Rmax=78680 RPeak= Nmax= Power=859 13
14 Top 10 remarks (June 2009) HPC entered a new realm 1 petaflop/s: one quadrillion (10 15 ) floating point operations per second) The new No. 1 system, built by IBM for the U.S. Department of Energy s Los Alamos National Laboratory and called Roadrunner, petaflop/s the most energy efficient systems on the TOP500. Roadrunner system is based on the IBM QS22 blades, built with advanced versions of the processor in the Sony PlayStation 3 Blue Gene/P, with a performance of teraflop/s is now ranked No. 3, and is located in Germany All the top-10 positions are in the U.S. but the 2 nd and the 10 th Intel powers an increasing number of Top500 supercomputers: 75% TOP500 now also provides energy efficiency calculations The position 14, 15, 16, and 18 corresponds to machines placed in Saudia Arabia, China, Canada, and India, respectively 14
15 Roadrunner Custom Configuration. Specialized tri-blade combined configuration: Two IBM QS22 blade servers (Cell) One IBM LS21 blade server (AMD Opteron) A total of 3,060 tri-blades built in IBM s Rochester, Minn. plant. Each tri-blade unit can run at 400 billion operations per second (400 Gigaflops). Standard processing (e.g., file system I/O) is handled by the Opteron processors. Mathematically and CPU-intensive elements are directed to the Cell processors. Open-source Linux software from Red Hat IBM is developing new software (targeting commercial applications) to make Cell-powered hybrid computing broadly accessible. Financial services (cause and effect in capital markets in real-time), energy exploration and medical imaging (real-time 3D rendering of tissue and bones) industries among others. 15
16 Roadrunner DOE s (Department of Energy) National Nuclear Security Administration selected Los Alamos National Laboratory as the development site for Roadrunner and IBM as the computer s designer and builder Roadrunner will primarily be used to ensure the safety and reliability of the nation s nuclear weapons stockpile. It will also be used for research into astronomy, energy, human genome science and climate change. Roadrunner is the world s first hybrid supercomputer. In a first-of-a-kind design, the Cell Broadband Engine -- originally designed for video game platforms such as the Sony Playstation 3 -- will work in conjunction with x86 processors from AMD Roadrunner connects 6,562 dual-core AMD Opteron chips 12,240 Cell chips (on IBM Model QS22 blade servers). The Roadrunner has 98 terabytes of memory, and is housed in 278 refrigerator-sized IBM BladeCenter racks occupying 5,200 square feet ( 440 m 2 ). Infiniband and Gigabit Ethernet 55 miles of fiber optic cable. 16

17 Top 10 of Top 500 (June 2010) Rmax and Rpeak values are in TFlops. Power data in KW for entire system 17
18 Top 10 remarks (June 2010) The Chinese System with Intel Xeon X5650 processors (6 cores) and NVidia Tesla C2050 GPUs is now the fastest in theoretical peak performance at 2.98 PFlop/s and No. 2 with a Linpack performance of PFlop/s. This is the highest rank a Chinese system ever achieved. There are now 2 Chinese systems in the TOP10 and 24 in the TOP500 overall. The Jaguar system at Oak Ridge National Laboratory managed to hold the No. 1 spot with 1.75 PFlop/s Linpack performance even as it s peak performance is lower than the Chinese Nebulae system. The most powerful system in Europe is an IBM BlueGene/P system at the German Forschungszentrum Juelich (FZJ) which dropped to No. 5. Intel dominates the high-end processor market 81.6 percent of all systems and over 90 percent of quad-core based systems. The Intel Core i7 (Nehalem-EP) processors increased their presence in the list with 186 systems compared with 95 in the last list. Other notable systems are: The Tianhe-1 system at No. 7, which is a hybrid design with Intel Xeon processors and AMD GPUs. The TH-1 uses AMD GPUs as accelerators. Each node consists of two AMD GPUs attached to two Intel Xeon processors. 18

19 Top 10 of Top 500 (June 2011) Rmax and Rpeak values are in TFlops. Power data in KW for entire system 19
20 Top 10 remarks (June 2011) A Japanese supercomputer capable of performing more than 8 petaflop/ s is the new number one system in the world, putting Japan back in the top spot for the first time since the Earth Simulator was dethroned in November 2004, according to the latest edition of the TOP500 List of the world s top supercomputers. The system, called the K Computer, is at the RIKEN Advanced Institute for Computational Science (AICS) in Kobe. For the first time, all of the top 10 systems achieved petaflop/s performance. The K Computer, built by Fujitsu, currently combines SPARC64 VIIIfx CPUs, each with eight cores, for a total of 548,352 cores almost twice as many as any other system in the TOP500. The K Computer is also more powerful than the next five systems on the list combined. The K Computer s name draws upon the Japanese word "Kei" for 10^16 (ten quadrillions), representing the system's performance goal of 10 petaflops. RIKEN is the Institute for Physical and Chemical Research. Unlike the Chinese system it displaced from the No. 1 slot and other recent very large system, the K Computer does not use graphics processors or other accelerators. The K Computer is also one of the most energy-efficient systems on the list. 20
21 China builds petaflop supercomputer without AMD, Intel or Nvidia Oct COMMUNIST China has built its first supercomputer using chips designed and manufactured in China instead of relying on AMD, Intel or Nvidia. China's new Sunway Bluelight MPP was installed in the country's National Supercomputer Center in Jinan in September, with estimates pegging the cluster somewhere around the petaflop mark. The cluster is made up of 8,700 Shenwei SW1600 processors, which are completely designed and manufactured in China. China's past success in the HPC arena has been down to good old fashioned American technology. The chips might have been baked in China but the design was done by US-based firms. The 8,700 Shenwei SW1600 processors represent the country's first comprehensive design and construction effort to build a large scale HPC cluster. Since the TOP500 list and supercomputers in general are often viewed as objects of national pride, it's no surprise that China wants to produce its own supercomputer. While the Shenwei cluster isn't quite ready to usurp Japan's K-Computer, few will bet against China heading the TOP500 list with its own chips before too long. 21
 Japan K computer, SPARC64 VIIIfx 2.")


 Germany JuQUEEN - BlueGene/Q, Power BQC 16C 1.")

22 Top 10 of Top 500 (June 2012) Rank Site Computer/Year Vendor Cores R max R peak Power 1 DOE/NNSA/LLNL United States Sequoia - BlueGene/Q, Power BQC 16C 1.60 GHz, Custom / 2011 IBM RIKEN Advanced Institute for Computational Science (AICS) Japan K computer, SPARC64 VIIIfx 2.0GHz, Tofu interconnect / 2011 Fujitsu DOE/SC/Argonne National Laboratory United States Mira - BlueGene/Q, Power BQC 16C 1.60GHz, Custom / 2012 IBM Leibniz Rechenzentrum Germany SuperMUC - idataplex DX360M4, Xeon E C 2.70GHz, Infiniband FDR / 2012 IBM National Supercomputing Center in Tianjin China Tianhe-1A - NUDT YH MPP, Xeon X5670 6C 2.93 GHz, NVIDIA 2050 / 2010 NUDT DOE/SC/Oak Ridge National Laboratory United States Jaguar - Cray XK6, Opteron C 2.200GHz, Cray Gemini interconnect, NVIDIA 2090 / 2009 Cray Inc CINECA Italy Fermi - BlueGene/Q, Power BQC 16C 1.60GHz, Custom / 2012 IBM Forschungszentrum Juelich (FZJ) Germany JuQUEEN - BlueGene/Q, Power BQC 16C 1.60GHz, Custom / 2012 IBM CEA/TGCC-GENCI France Curie thin nodes - Bullx B510, Xeon E C 2.700GHz, Infiniband QDR / 2012 Bull National Supercomputing Centre in Shenzhen (NSCS) China Nebulae - Dawning TC3600 Blade System, Xeon X5650 6C 2.66GHz, Infiniband QDR, NVIDIA 2050 / 2010 Dawning
23 Top 10 of Top 500 (June 2012) MANNHEIM, Germany; BERKELEY, Calif.; and KNOXVILLE, Tenn. For the first time since November 2009, a United States supercomputer sits atop the TOP500 list of the world s top supercomputers. Named Sequoia, the IBM BlueGene/Q system installed at the Department of Energy s Lawrence Livermore National Laboratory achieved an impressive petaflop/s on the Linpack benchmark using 1,572,864 cores. Sequoia is also one of the most energy efficient systems on the list, which will be released Monday, June 18, at the 2012 International Supercomputing Conference in Hamburg, Germany. This will mark the 39th edition of the list, which is compiled twice each year. On the latest list, Fujitsu s K Computer installed at the RIKEN Advanced Institute for Computational Science (AICS) in Kobe, Japan, is now the No. 2 system with Pflop/s on the Linpack benchmark using 705,024 SPARC64 processing cores. The K Computer held the No. 1 spot on the previous two lists. Italy makes its debut in the Top 10 with an IBM BlueGene/Q system installed at CINECA. The system is at No. 7 on the list with 1.72 Pflop/s performance. In all, four of the top 10 supercomputers are IBM BlueGene/Q systems. France occupies the No. 9 spot with a homegrown Bull supercomputer. 23
24 Sequoia BlueGen/Q Sequoia BlueGen/Q System Performance by the Numbers: petaflops of sustained performance and a theoretical peak performance of 20.1 petaflops 98,304 computer nodes feature 1.6 million cores with 1GB of RAM per core 1.6 petabytes of RAM total 1.57 million PowerPC cores Parallel design is based on IBM s 18-core PowerPC A2 processor Interconnect speeds clock in at 40Gb/sec with a node to node latency hop of 2.5 microseconds The Sequoia uses 7.89 megawatts of power (in comparison, the #2 supercomputer, Japan s K Computer, uses 20 megawatts of power) 24
")
25 Top 10 of Top 500 (June 2013) 25
26 Top 10 of Top 500 (June 2013) Tianhe-2, a supercomputer developed by China s National University of Defense Technology, is the world s new No. 1 system with a performance of petaflop/s on the Linpack benchmark, according to the 41stedition of the twiceyearlytop500 list of the world s most powerful supercomputers. The list was announced June 17 during the opening session of the 2013 International Supercomputing Conference in Leipzig, Germany. Tianhe-2 has 16,000 nodes, each with two Intel Xeon IvyBridge processors and three Xeon Phi processors for a combined total of 3,120,000 computing cores. Intel Xeon Phi coprocessors provide up to 61 cores, 244 threads, and 1.2 teraflops of performance, and they come in a variety of configurations to address diverse hardware, software, workload, performance, and efficiency requirements. Titan, a Cray XK7 system installed at the U.S. Department of Energy s (DOE) Oak Ridge National Laboratory and previously the No. 1 system, is now ranked No. 2. Titan achieved petaflop/s on the Linpack benchmark using 261,632 of its NVIDIA K20x accelerator cores. Titan is one of the most energy efficient systems on the list, consuming a total of 8.21 MW and delivering 2,143 Mflops/ W. 26
27 Top 10 of Top 500 (June 2015) 27
28 Top 10 of Top 500 (June 2015) For the fifth consecutive time, Tianhe-2, a supercomputer developed by China s National University of Defense Technology, has retained its position as the world s No. 1 system, according to the 45th edition of the twice-yearly TOP500 list of the world s most powerful supercomputers. Tianhe-2, which means Milky Way-2, led the list with a performance of petaflop/s (quadrillions of calculations per second) on the Linpack benchmark. At No. 2 was Titan, a Cray XK7 system installed at the Department of Energy s (DOE) Oak Ridge National Laboratory. Titan, the top system in the United States and one of the most energy-efficient systems on the list, achieved petaflop/ s on the Linpack benchmark. The only new entry in the Top 10 supercomputers on the latest list is at No. 7 Shaheen II is a Cray XC40 system installed at King Abdullah University of Science and Technology (KAUST) in Saudi Arabia. Shaheen II achieved petaflop/s on the Linpack benchmark, making it the highest-ranked Middle East system in the 22-year history of the list and the first to crack the Top
29 Performance Development 10 EF/s 1 EF/s 100 PF/s 10 PF/s Performance 1 PF/s 100 TF/s 10 TF/s 1 TF/s 100 GF/s 10 GF/s 1 GF/s 100 MF/s Lists Sum #1 #500 29
30 Vendors System Share HP IBM Cray Inc. SGI Bull IBM/ Lenovo Fujitsu Dell NUDT MEGWA Others 12% 14.2% 18.2% 35.6% 30

31 THIS WEEK United IN K HPC IBM LOOKS TO EXTEND MOORE S LAW; MICR Korea, S (/BLOG/IBM-LOOKS-TO-EXTEND-MOORES-L Russia AZURE/) Poland Posted 1 week ago Others Country System Share United States Japan China Germany France India 46.6% This Week In HPC IBM Looks High Performance to Computing- Extend S. Orlando 31
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Chapter 1. Introduction
 Chapter 1 Introduction Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand
Chapter 1 Introduction Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
CSE5351: Parallel Procesisng. Part 1B. UTA Copyright (c) Slide No 1
 Slide No 1") Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics
 CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
Emerging Heterogeneous Technologies for High Performance Computing
 MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen
 20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen Hans Meuer Prometeus GmbH & Universität Mannheim hans@meuer.de ZKI Herbsttagung in Leipzig 11. - 12. September 2012 page 1 Outline Mannheim Supercomputer
20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen Hans Meuer Prometeus GmbH & Universität Mannheim hans@meuer.de ZKI Herbsttagung in Leipzig 11. - 12. September 2012 page 1 Outline Mannheim Supercomputer
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
HPC as a Driver for Computing Technology and Education
 HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High-Performance Computing - and why Learn about it?
 High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Roadmapping of HPC interconnects
 Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Report on the Sunway TaihuLight System. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
An Overview of High Performance Computing
 IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek
 www.hpcg-benchmark.org 1 HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek www.hpcg-benchmark.org 2 HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse,
www.hpcg-benchmark.org 1 HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek www.hpcg-benchmark.org 2 HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse,
Overview. High Performance Computing - History of the Supercomputer. Modern Definitions (II)
") Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
China's supercomputer surprises U.S. experts
 China's supercomputer surprises U.S. experts John Markoff Reproduced from THE HINDU, October 31, 2011 Fast forward: A journalist shoots video footage of the data storage system of the Sunway Bluelight
China's supercomputer surprises U.S. experts John Markoff Reproduced from THE HINDU, October 31, 2011 Fast forward: A journalist shoots video footage of the data storage system of the Sunway Bluelight
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory
 Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory 2013 International Workshop on Computational Science and Engineering National University of Taiwan
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory 2013 International Workshop on Computational Science and Engineering National University of Taiwan
HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek
 1 HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse, b known, x computed. An optimized implementation
1 HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse, b known, x computed. An optimized implementation
ECE 574 Cluster Computing Lecture 2
 ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
An approach to provide remote access to GPU computational power
 An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
CINECA and the European HPC Ecosystem
 CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
Jack Dongarra INNOVATIVE COMP ING LABORATORY. University i of Tennessee Oak Ridge National Laboratory
 Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING Top 10 Supercomputers in the World as of November 2013*
 CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014 COMPUTERS : PRESENT, PAST & FUTURE Top 10 Supercomputers in the World as of November 2013* No Site Computer Cores Rmax + (TFLOPS) Rpeak (TFLOPS)
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014 COMPUTERS : PRESENT, PAST & FUTURE Top 10 Supercomputers in the World as of November 2013* No Site Computer Cores Rmax + (TFLOPS) Rpeak (TFLOPS)
Presentation of the 16th List
 Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
The TOP500 list. Hans-Werner Meuer University of Mannheim. SPEC Workshop, University of Wuppertal, Germany September 13, 1999
 The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu
 Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
The TOP500 Project of the Universities Mannheim and Tennessee
 The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
Why we need Exascale and why we won t get there by 2020
 Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory August 27, 2013 Overview Current state of HPC: petaflops firmly established Why we won t get to
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory August 27, 2013 Overview Current state of HPC: petaflops firmly established Why we won t get to
Confessions of an Accidental Benchmarker
 Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
An Overview of High Performance Computing. Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/2005 1
 An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
HPC Technology Update Challenges or Chances?
 HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice
 InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
TOP500 Listen und industrielle/kommerzielle Anwendungen
 TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future
 Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
Chapter 5b: top500. Top 500 Blades Google PC cluster. Computer Architecture Summer b.1
 Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
Jack Dongarra University of Tennessee Oak Ridge National Laboratory
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
HPC IN EUROPE. Organisation of public HPC resources
 HPC IN EUROPE Organisation of public HPC resources Context Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded
HPC IN EUROPE Organisation of public HPC resources Context Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded
Seagate ExaScale HPC Storage
 Seagate ExaScale HPC Storage Miro Lehocky System Engineer, Seagate Systems Group, HPC1 100+ PB Lustre File System 130+ GB/s Lustre File System 140+ GB/s Lustre File System 55 PB Lustre File System 1.6
Seagate ExaScale HPC Storage Miro Lehocky System Engineer, Seagate Systems Group, HPC1 100+ PB Lustre File System 130+ GB/s Lustre File System 140+ GB/s Lustre File System 55 PB Lustre File System 1.6
2014 China TOP100 List of High Performance Computer
 2014 China TOP100 List of High Performance Computer (November, 2014) 1/ 15 2014 China TOP100 List of High Performance Computer The Specialty Association of Mathematical & Scientific Software, CSIA Evaluation
2014 China TOP100 List of High Performance Computer (November, 2014) 1/ 15 2014 China TOP100 List of High Performance Computer The Specialty Association of Mathematical & Scientific Software, CSIA Evaluation
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Building Self-Healing Mass Storage Arrays. for Large Cluster Systems
 Building Self-Healing Mass Storage Arrays for Large Cluster Systems NSC08, Linköping, 14. October 2008 Toine Beckers tbeckers@datadirectnet.com Agenda Company Overview Balanced I/O Systems MTBF and Availability
Building Self-Healing Mass Storage Arrays for Large Cluster Systems NSC08, Linköping, 14. October 2008 Toine Beckers tbeckers@datadirectnet.com Agenda Company Overview Balanced I/O Systems MTBF and Availability
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
HPC Algorithms and Applications
 HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory
 Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title TOP500 Supercomputers for June 2005 Permalink https://escholarship.org/uc/item/4h84j873 Authors Strohmaier, Erich Meuer,
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title TOP500 Supercomputers for June 2005 Permalink https://escholarship.org/uc/item/4h84j873 Authors Strohmaier, Erich Meuer,
IBM HPC DIRECTIONS. Dr Don Grice. ECMWF Workshop November, IBM Corporation
 IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
Supercomputers Prestige Objects or Crucial Tools for Science and Industry?
 Supercomputers Prestige Objects or Crucial Tools for Science and Industry? Hans W. Meuer a 1, Horst Gietl b 2 a University of Mannheim & Prometeus GmbH, 68131 Mannheim, Germany; b Prometeus GmbH, 81245
Supercomputers Prestige Objects or Crucial Tools for Science and Industry? Hans W. Meuer a 1, Horst Gietl b 2 a University of Mannheim & Prometeus GmbH, 68131 Mannheim, Germany; b Prometeus GmbH, 81245
Search for Optimal Network Topologies for Supercomputers 寻找超级计算机优化的网络拓扑结构
 Search for Optimal Network Topologies for Supercomputers 寻找超级计算机优化的网络拓扑结构 GUO, Meng 郭猛 guomeng@sdas.org Shandong Computer Science Center (National Supercomputer Center in Jinan) 山东省计算中心 ( 国家超级计算济南中心 )
Search for Optimal Network Topologies for Supercomputers 寻找超级计算机优化的网络拓扑结构 GUO, Meng 郭猛 guomeng@sdas.org Shandong Computer Science Center (National Supercomputer Center in Jinan) 山东省计算中心 ( 国家超级计算济南中心 )
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
Supercomputing im Jahr eine Analyse mit Hilfe der TOP500 Listen
 Supercomputing im Jahr 2000 - eine Analyse mit Hilfe der TOP500 Listen Hans Werner Meuer Universität Mannheim Feierliche Inbetriebnahme von CLIC TU Chemnitz 11. Oktober 2000 TOP500 CLIC TU Chemnitz View
Supercomputing im Jahr 2000 - eine Analyse mit Hilfe der TOP500 Listen Hans Werner Meuer Universität Mannheim Feierliche Inbetriebnahme von CLIC TU Chemnitz 11. Oktober 2000 TOP500 CLIC TU Chemnitz View
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Trends in HPC Architectures and Parallel
 Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA CINECA, February 11-15, 2013 Agenda Computational
Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA CINECA, February 11-15, 2013 Agenda Computational
A unified Energy Footprint for Simulation Software
 A unified Energy Footprint for Simulation Software Hartwig Anzt, Armen Beglarian, Suren Chilingaryan, Andrew Ferrone, Vincent Heuveline, Andreas Kopmann Hartwig Anzt September 12, 212 ENGINEERING MATHEMATICS
A unified Energy Footprint for Simulation Software Hartwig Anzt, Armen Beglarian, Suren Chilingaryan, Andrew Ferrone, Vincent Heuveline, Andreas Kopmann Hartwig Anzt September 12, 212 ENGINEERING MATHEMATICS
Overview of HPC and Energy Saving on KNL for Some Computations
 Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Prototypes Systems for PRACE. François Robin, GENCI, WP7 leader
 Prototypes Systems for PRACE François Robin, GENCI, WP7 leader Outline Motivation Summary of the selection process Description of the set of prototypes selected by the Management Board Conclusions 2 Outline
Prototypes Systems for PRACE François Robin, GENCI, WP7 leader Outline Motivation Summary of the selection process Description of the set of prototypes selected by the Management Board Conclusions 2 Outline
High Performance Computing
 CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
CCS HPC. Interconnection Network. PC MPP (Massively Parallel Processor) MPP IBM
 MPP IBM") CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
High Performance Linear Algebra
 High Performance Linear Algebra Hatem Ltaief Senior Research Scientist Extreme Computing Research Center King Abdullah University of Science and Technology 4th International Workshop on Real-Time Control
High Performance Linear Algebra Hatem Ltaief Senior Research Scientist Extreme Computing Research Center King Abdullah University of Science and Technology 4th International Workshop on Real-Time Control
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) HPC Services Regionales Rechenzentrum Erlangen (b)
, Dr. G. Hager (a), J. Habich (a) HPC Services Regionales Rechenzentrum Erlangen (b)") Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University Erlangen-Nürnberg
Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University Erlangen-Nürnberg
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Resources & Training
 www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Welcome to the. Jülich Supercomputing Centre. D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich
, Forschungszentrum Jülich") Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 18 13:00-13:30 Welcome
Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 18 13:00-13:30 Welcome
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges