ADVANCED COMPUTER ARCHITECTURES
|
|
|
- Dennis Hardy
- 5 years ago
- Views:
Transcription
1 ADVANCED COMPUTER ARCHITECTURES AA 2016/2017 Website: Prof. Cristina Silvano Dipartimento di Elettronica, Informazione e Bioingegneria (DEIB) Politecnico di Milano
2 Goals of the ACA course Provide an overview of the most recent and advanced computer architectures Introduce the basic micro-architectural mechanisms found in modern microprocessor architectures Provide the reasoning behind the adoption of advanced computer architectures Cristina Silvano Politecnico di Milano - 2 -
3 ADVANCED COMPUTER ARCHITECTURES: AN OVERVIEW Cristina Silvano Politecnico di Milano - 3 -
4 Advanced Computer Architectures: Supercomputers First supercomputer reaching the Petascale peak performance (10 15 Flops) was IBM Roadrunner installed in 2008 at Los Alamos National Lab (New Mexico) Research on supercomputing is pushing towards the Exascale (10 18 Flops) billions of billions to be reached in Cristina Silvano Politecnico di Milano - 4 -

5 How to measure performance: FLOPS, Floating Point Operations per Second Name FLOPS zettaflops exaflops petaflops teraflops gigaflops 10 9 megaflops 10 6 kiloflops 10 3 FLOPS 1 Cristina Silvano Politecnico di Milano - 5 -
 No. 2 Tianhe-2 (Milky-Way-2) reaches 33.")
 27.11 PetaFlops (peak performance) with 8.2MW power dissipation.")
6 Top500 ranking of the world s most powerful supercomputers (Nov. 2016) No. 1 Sunway TaihuLight reaches PetaFlops (Linpack performance) PetaFlops peak performance with MW power dissipation. Site: National Supercomputing Center in Wuxi (China) No. 2 Tianhe-2 (Milky-Way-2) reaches PetaFlops (Linpack performance) 54.9 PetaFlops peak performance with 17.8 MW power dissipation. Site: National Super Computer Center in Guangzhou (China) No. 3 Titan: PetaFlops (Linpack performance) PetaFlops (peak performance) with 8.2MW power dissipation. Site: Oak Ridge National Laboratory (USA) Cristina Silvano Politecnico di Milano - 6 -
 with with 241,808 cores.")
7 Top500 ranking: the Italian most powerful supercomputer (Nov. 2016) No. 12 in Top500 and No. 3 in Europe: Marconi Intel Xeon Phi: 6.22 PetaFlops (Linpack performance) PetaFlops (peak performance) with with 241,808 cores. Site: Casalecchio di Reno, Bologna (Italy) Marconi is the Cineca's Tier-0 system, codesigned by Cineca and Lenovo based on the Lenovo NeXtScale platform and Intel Xeon Phi product family alongside with Intel Xeon processor E v4 product family. In July 2017, this system is planned to reach a total computational power of about 20Pflop/s utilizing future generation Intel Xeon processors (Sky Lakes). Cristina Silvano Politecnico di Milano - 7 -


8 No. 2 TITAN Cray XK7, Opteron 2.2GHz, NVIDIA K20X Cristina Silvano Politecnico di Milano -8-
9 Exascale Supercomputers To reach 20 MW Exascale supercomputers projected to 2023, current supercomputers must achieve energy efficiency pushing towards a goal of 50 GigaFlops/W No.1 Sunway delivers 6 GigaFlops/W resulting only 4th in the Green500 list ranking supercomputers by their energy efficiency. Today most green supercomputer in Green500 achieves 9.4 GigaFlops/W: NVIDIA DGX-1, Xeon E5-2698v4 and NVIDIA Tesla P100 The top positions of Green500 are currently occupied by heterogeneous computing systems This dominance will become a trend for the next coming years to reach the target of 20 MW Exascale supercomputer Cristina Silvano Politecnico di Milano - 9 -


10 US Dept. of Energy Announced Summit and Sierra Supercomputers Cristina Silvano Politecnico di Milano



11 Applications driving the demand for more computing performance Astrophysics Climate Biology Business Analytics Cristina Silvano Politecnico di Milano

12 Advanced Computer Architectures: Intel Core i7-3770t Processor # of Cores 4 # of Threads 8 Clock Speed Max Turbo Frequency Intel Smart Cache Instruction Set Instruction Set Extensions Embedded Options Available 2.5 GHz 3.7 GHz 8 MB 64-bit SSE4.1/4.2, AVX No 160mm² 22nm 1.40 billion transistors Next generations: Broadwell, Skylake, Kaby Lake at 14nm (2014); Cannonlake at 10nm (2H 2017); Ice Lake 10nm (2018) Cristina Silvano Politecnico di Milano Lithography 22 nm Max TDP 45 W Recomm. Customer Price TRAY: $ Max Memory Size 32 GB Memory Types DDR3-1333/1600 # of Memory Channels 2 Max Memory Bandwidth 25.6 GB/s



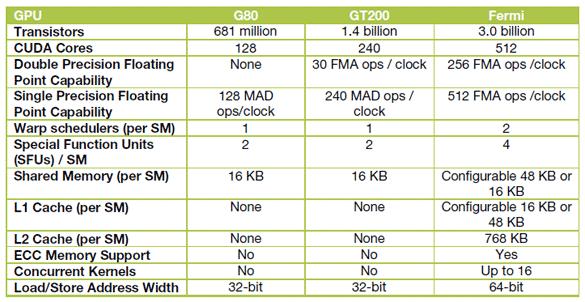
13 NVIDIA Fermi GPU Cristina Silvano Politecnico di Milano

 >1TFLOP FP64 1.")

14 NVIDIA Kepler GPU Kepler GK110 Architecture 7.1B Transistors 15 SMX units (2880 cores) >1TFLOP FP64 1.5MB L2 Cache 384-bit GDDR5 PCI Express Gen3 Cristina Silvano Politecnico di Milano

15 NVIDIA Tesla P100 with Pascal GP100 GPU Cristina Silvano Politecnico di Milano


16 NVIDIA Tesla P100 compared to prior generations -16-




17 Advanced Computer Architectures: Smart Phones 4.7-inch 12MP camera 5MP videocamera Retina HD display with 3D touch A9 chip 64-bit M9 coprocessor ios 10 32GB 128GB 12MP camera 5MP videocamera Retina HD display with 3D touch A9 chip 64-bit M9 coprocessor ios 10 32GB 128GB -17- iphone inch New 12MP camera 7MP videocamera Retina HD display with 3D touch Waterproof Audio stereo A10 Fusion chip 64-bit M10 co-proecessor ios 10 32GB 128GB 256GB iphone 7 Plus 5.5-inch display New 12MP camera ++ 7MP videocamera Retina HD display with 3D touch Waterproof Audio stereo A10 Fusion chip 64-bit M10 coprocessor ios 10 32GB 128GB 256GB

18 Apple A8 System-on-Chip Apple A8 is a 64-bit ARM-based SoC was introduced on Sept for the iphone 6 and iphone 6 Plus Apple states that it has 25% more CPU performance and 50% more graphics performance with 50% of the power compared to its predecessor A7. The A8 features the second generation of the Apple-designed 64-bit 1.4 GHz ARMv8-A dual-core CPU, called Cyclone Gen 2, and an integrated PowerVR Series 6XT GX6450 quad-core GPU. The A8 is manufactured on a 20 nm process by TSMC which replaced Samsung as manufacturer of Apple's mobile device processors. It contains 2 billion transistors. It has 1 GB of LPDDR3 RAM included in the package. On October 16, 2014, Apple introduced a variant of the A8, the A8X, in the ipad Air 2 with improved graphics and CPU performance due to one extra core and higher frequency Cristina Silvano Politecnico di Milano


19 Apple A9 System-on-Chip Apple A8 is a 64-bit ARM-based SoC was introduced on Sept for the iphone 6S and iphone 6S Plus Apple states that it has 70% more CPU performance and 90% more graphics performance compared to its predecessor A8. This is one of the most powerful mobile chip on the market toady along with the Samsung Exynos 8890 and Qualcomm Snapdragon 820. The A9 features the Apple-designed 64-bit 1.85 GHz ARMv8-A dual-core CPU, called Twister, and an integrated PowerVR Series 7XT GT7600 six-core GPU. The A9 is manufactured by two companies: 14nm FinFET process by Samsung and 16 nm FinFET process by TSMC. A9 has 2 GB of LPDDR4 RAM included in the package. Apple introduced a variant of the A9, the A9X, in the ipad Pro with the M9 motion coprocessor embedded in it Cristina Silvano Politecnico di Milano

20 Apple A10 Fusion Apple A10 Fusion is a 64-bit ARM-based SoC designed by Apple and introduced on Sept for the iphone 7 and iphone 7 Plus Apple states that it has 40% more CPU performance and 50% more graphics performance compared to its predecessor A9. The A10 with a die area of 125 mm 2 and 3.3 billion transistors (including GPU and cache) features two Apple-designed 64-bit 2.34 GHz ARMv8-A cores called Hurricane and two energy-efficient 64-bit cores codenamed Zephyr (like the ARM big.little technology). A10 integrates new designed PowerVR Series 7XT GT7600 six-core GPU. The A10 is manufactured 16 nm FinFET process by TSMC. Cristina Silvano Politecnico di Milano




 and target")


21 Energy efficiency underlies all markets Energy efficiency is of paramount importance for all application markets (automotive, consumer, mobile, healthcare and beyond) and target systems spanning from sensors, cyberphysical systems, embedded systems up to servers and HPC systems.
22 Squeezing of computing cores nm 1.4 mm 2 Source: ARM9 STMicroelectronics nm nm nm nm

23 entering the multi/many core era nm 1.4 mm 2 Source: ARM9 STmicroelectronics nm nm nm nm

24 What are the barriers of further scaling? Transistor density increases ~2x every 2 years Frequency wall Power wall Utilisation wall the end of the Dennard scaling entering the dark silicon era


25 The dark silicon problem The power wall and the utilisation wall represent the main barriers for the efficient scaling in the multi/manycore era Dark silicon: Fraction of the die not usable due to the power budget
26 ACA COURSE INFORMATION Cristina Silvano Politecnico di Milano
27 Contact Information Office hours for students: Tuesday at Polo di Como, Via Anzani 42, 2nd floor (please send an to get an appointment). Main Contact: The students can contact prof. Cristina Silvano by by indicating: Subject: ACA COMO, Your_Surname, Your_Name, Your_POLIMI_ID_NUMBER Cristina Silvano Politecnico di Milano
28 ACA Teaching Assistant Ing. Ahmet Erdem: Cristina Silvano Politecnico di Milano
29 ACA Course Info Teaching Activity: The course consists of 5 CFU and it is organized in 30 hours of lectures and 20 hours of written/tool-based exercises to prove the concepts presented during the lectures. Pre-requirements: Basic concepts on logic design and computer architectures. Cristina Silvano Politecnico di Milano
30 ACA Final Exam FINAL EXAM: The final examination consists of a WRITTEN EXAM and an OPTIONAL part consisting of an oral presentation OR discussion of a project topic prepared during the course (the topic for presentation and project will be assigned by the professor and it will cover specific techniques and methodologies) that will be presented by the student at the end of the course. For each written exam, a max. score of 33 points will be assigned: 15 max. points will be assigned for the solution of the exercise part and 18 points will be assigned for answering to the theory part. The OPTIONAL part can provide EXTRA points (from 1 to 2 extra points for the oral presentation and 1 to 4 extra points for the project). The additional points given by the project will be added to the score of the written exam only if the final score of the written exam will be sufficient (>=18). The project/presentation will be assigned at the midterm of the course semester and it must be concluded and presented by: June, 2017 (firm deadline). Cristina Silvano Politecnico di Milano
31 ACA Teaching Material Additional information in slides and papers available through the course webpage: If you're using MOZILLA FIREFOX AS WEB BROWSER, for a correct visualisation and printing of the PDF SLIDES, please use the SAVE AS option and save the PDF FILE on your laptop for correct visualisation and printing. Reference Book: "Computer Architecture, A Quantitative Approach", John Hennessy, David Patterson, Morgan Kaufmann, Fifth Edition. Cristina Silvano Politecnico di Milano
32 Support for the international students ACA course is offered in English Teaching materials (slides/papers/textbook) available in English Final exam can be done in English Teaching support available in English Cristina Silvano Politecnico di Milano -44- March 2013
ADVANCED COMPUTER ARCHITECTURES
 088949 ADVANCED COMPUTER ARCHITECTURES AA 2014/2015 Second Semester http://home.deib.polimi.it/silvano/aca-milano.htm Prof. Cristina Silvano email: cristina.silvano@polimi.it Dipartimento di Elettronica,
088949 ADVANCED COMPUTER ARCHITECTURES AA 2014/2015 Second Semester http://home.deib.polimi.it/silvano/aca-milano.htm Prof. Cristina Silvano email: cristina.silvano@polimi.it Dipartimento di Elettronica,
Introduction to ASIC Design
 Introduction to ASIC Design Victor P. Nelson ELEC 5250/6250 CAD of Digital ICs Design & implementation of ASICs Oops Not these! Application-Specific Integrated Circuit (ASIC) Developed for a specific application
Introduction to ASIC Design Victor P. Nelson ELEC 5250/6250 CAD of Digital ICs Design & implementation of ASICs Oops Not these! Application-Specific Integrated Circuit (ASIC) Developed for a specific application
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Design Space Exploration and Application Autotuning for Runtime Adaptivity in Multicore Architectures
 Design Space Exploration and Application Autotuning for Runtime Adaptivity in Multicore Architectures Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Outline Research challenges in multicore
Design Space Exploration and Application Autotuning for Runtime Adaptivity in Multicore Architectures Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Outline Research challenges in multicore
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
Computer Architecture. Introduction. Lynn Choi Korea University
 Computer Architecture Introduction Lynn Choi Korea University Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, 공학관 411, lchoi@korea.ac.kr, TA: 윤창현 / 신동욱, 3290-3896,
Computer Architecture Introduction Lynn Choi Korea University Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, 공학관 411, lchoi@korea.ac.kr, TA: 윤창현 / 신동욱, 3290-3896,
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
HPC Cineca Infrastructure: State of the art and towards the exascale
 HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
Presented by : Sadegh Riyahi Majid Shokrolahi
 Politecnico di Milano Polo Regionale di Como Architectures for multimedia systems Professor : Cristina Silvano Presented by : Sadegh Riyahi Majid Shokrolahi 29th June 2010 Outline Introduction What is
Politecnico di Milano Polo Regionale di Como Architectures for multimedia systems Professor : Cristina Silvano Presented by : Sadegh Riyahi Majid Shokrolahi 29th June 2010 Outline Introduction What is
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
The Future of High- Performance Computing
 Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
HW Trends and Architectures
 Pavel Tvrdík, Jiří Kašpar (ČVUT FIT) HW Trends and Architectures MI-POA, 2011, Lecture 1 1/29 HW Trends and Architectures prof. Ing. Pavel Tvrdík CSc. Ing. Jiří Kašpar Department of Computer Systems Faculty
Pavel Tvrdík, Jiří Kašpar (ČVUT FIT) HW Trends and Architectures MI-POA, 2011, Lecture 1 1/29 HW Trends and Architectures prof. Ing. Pavel Tvrdík CSc. Ing. Jiří Kašpar Department of Computer Systems Faculty
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
Overview. High Performance Computing - History of the Supercomputer. Modern Definitions (II)
") Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
CS5222 Advanced Computer Architecture. Lecture 1 Introduction
 CS5222 Advanced Computer Architecture Lecture 1 Introduction Overview Teaching Staff Introduction to Computer Architecture History Future / Trends Significance The course Content Workload Administrative
CS5222 Advanced Computer Architecture Lecture 1 Introduction Overview Teaching Staff Introduction to Computer Architecture History Future / Trends Significance The course Content Workload Administrative
Samsung System LSI Business
 Samsung System LSI Business NS (Stephen) Woo, Ph.D. President & GM of System LSI Samsung Electronics 0/32 Disclaimer The materials in this report include forward-looking statements which can generally
Samsung System LSI Business NS (Stephen) Woo, Ph.D. President & GM of System LSI Samsung Electronics 0/32 Disclaimer The materials in this report include forward-looking statements which can generally
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2009 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, SEC 202 Wednesday, 1.00pm 2.30pm, SEC 202 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2009 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, SEC 202 Wednesday, 1.00pm 2.30pm, SEC 202 Evaluation 25% homework
High Performance Computing
 CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
Vectorisation and Portable Programming using OpenCL
 Vectorisation and Portable Programming using OpenCL Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre (JSC) Andreas Beckmann, Ilya Zhukov, Willi Homberg, JSC Wolfram Schenck, FH Bielefeld
Vectorisation and Portable Programming using OpenCL Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre (JSC) Andreas Beckmann, Ilya Zhukov, Willi Homberg, JSC Wolfram Schenck, FH Bielefeld
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2008 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2008 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
MANY-CORE COMPUTING. 7-Oct Ana Lucia Varbanescu, UvA. Original slides: Rob van Nieuwpoort, escience Center
 MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics (10-10-2013)
MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics (10-10-2013)
Chapter 0 Introduction
 Chapter 0 Introduction Jin-Fu Li Laboratory Department of Electrical Engineering National Central University Jhongli, Taiwan Applications of ICs Consumer Electronics Automotive Electronics Green Power
Chapter 0 Introduction Jin-Fu Li Laboratory Department of Electrical Engineering National Central University Jhongli, Taiwan Applications of ICs Consumer Electronics Automotive Electronics Green Power
European energy efficient supercomputer project
 http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Exclusive pricing for UW students, faculty, staff and UWAA members!
 Exclusive pricing for UW students, faculty, staff and UWAA members! MacBook Pro with Retina Display (mid 2017) 720p FaceTime HD Camera; stereo speakers & dual microphones; backlit keyboard with ambient
Exclusive pricing for UW students, faculty, staff and UWAA members! MacBook Pro with Retina Display (mid 2017) 720p FaceTime HD Camera; stereo speakers & dual microphones; backlit keyboard with ambient
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
High-Performance Computing - and why Learn about it?
 High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
HIGH-PERFORMANCE COMPUTING
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
Introduction to ASIC Design. Victor P. Nelson
 Introduction to ASIC Design Victor P. Nelson Design & implementation of ASICs Oops Not these! Application-Specific Integrated Circuit (ASIC) Developed for a specific application Not general purpose Progress
Introduction to ASIC Design Victor P. Nelson Design & implementation of ASICs Oops Not these! Application-Specific Integrated Circuit (ASIC) Developed for a specific application Not general purpose Progress
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Moore s Law. CS 6534: Tech Trends / Intro. Good Ol Days: Frequency Scaling. The Power Wall. Charles Reiss. 24 August 2016
 Moore s Law CS 6534: Tech Trends / Intro Microprocessor Transistor Counts 1971-211 & Moore's Law 2,6,, 1,,, Six-Core Core i7 Six-Core Xeon 74 Dual-Core Itanium 2 AMD K1 Itanium 2 with 9MB cache POWER6
Moore s Law CS 6534: Tech Trends / Intro Microprocessor Transistor Counts 1971-211 & Moore's Law 2,6,, 1,,, Six-Core Core i7 Six-Core Xeon 74 Dual-Core Itanium 2 AMD K1 Itanium 2 with 9MB cache POWER6
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
CS 6534: Tech Trends / Intro
 1 CS 6534: Tech Trends / Intro Charles Reiss 24 August 2016 Moore s Law Microprocessor Transistor Counts 1971-2011 & Moore's Law 16-Core SPARC T3 2,600,000,000 1,000,000,000 Six-Core Core i7 Six-Core Xeon
1 CS 6534: Tech Trends / Intro Charles Reiss 24 August 2016 Moore s Law Microprocessor Transistor Counts 1971-2011 & Moore's Law 16-Core SPARC T3 2,600,000,000 1,000,000,000 Six-Core Core i7 Six-Core Xeon
Introduction to System-on-Chip
 Introduction to System-on-Chip COE838: Systems-on-Chip Design http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer Engineering Ryerson University
Introduction to System-on-Chip COE838: Systems-on-Chip Design http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer Engineering Ryerson University
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
The Macbook Air's Cpu Is Based On Which Instruction Set Architecture (isa) >>>CLICK HERE<<<
 >>>CLICK HERE<<<") The Macbook Air's Cpu Is Based On Which Instruction Set Architecture (isa) There is nothing in the instruction set that is more or less energy efficient than any The gaps between ARM and Atom are driven
The Macbook Air's Cpu Is Based On Which Instruction Set Architecture (isa) There is nothing in the instruction set that is more or less energy efficient than any The gaps between ARM and Atom are driven
HPC-CINECA infrastructure: The New Marconi System. HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati,
 HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
The Mont-Blanc Project
 http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
GPU Programming and Architecture: Course Overview
 Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Monday and Wednesday 9-10:30am Moore 212 Lectures will be recorded Image from http://pinoytutorial.com/techtorial/geforce-gtx-580-vs-amd-radeon-hd-6870-review-and-comparison-conclusion/
Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Monday and Wednesday 9-10:30am Moore 212 Lectures will be recorded Image from http://pinoytutorial.com/techtorial/geforce-gtx-580-vs-amd-radeon-hd-6870-review-and-comparison-conclusion/
Computer Architecture
 Informatics 3 Computer Architecture Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh (thanks to Prof. Nigel Topham) General Information Instructor
Informatics 3 Computer Architecture Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh (thanks to Prof. Nigel Topham) General Information Instructor
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Heterogeneous Parallelism and Hardware Specialization
 Lecture 22: Heterogeneous Parallelism and Hardware Specialization Parallel Computer Architecture and Programming You need to buy a computer system Core Core Core Core Core Core Core Core Core Core Core
Lecture 22: Heterogeneous Parallelism and Hardware Specialization Parallel Computer Architecture and Programming You need to buy a computer system Core Core Core Core Core Core Core Core Core Core Core
Fundamentals of Computers Design
 Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
HPC and the AppleTV-Cluster
 HPC and the AppleTV-Cluster Dieter Kranzlmüller, Karl Fürlinger, Christof Klausecker Munich Network Management Team Ludwig-Maximilians-Universität München (LMU) & Leibniz Supercomputing Centre (LRZ) Outline
HPC and the AppleTV-Cluster Dieter Kranzlmüller, Karl Fürlinger, Christof Klausecker Munich Network Management Team Ludwig-Maximilians-Universität München (LMU) & Leibniz Supercomputing Centre (LRZ) Outline
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Top500
 Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Introducing the Intel Xeon Phi Coprocessor Architecture for Discovery
 Introducing the Intel Xeon Phi Coprocessor Architecture for Discovery Imagine The Possibilities Many industries are poised to benefit dramatically from the highly-parallel performance of the Intel Xeon
Introducing the Intel Xeon Phi Coprocessor Architecture for Discovery Imagine The Possibilities Many industries are poised to benefit dramatically from the highly-parallel performance of the Intel Xeon
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
Building supercomputers from commodity embedded chips
 http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Computer Architecture
 Informatics 3 Computer Architecture Dr. Boris Grot and Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh General Information Instructors: Boris
Informatics 3 Computer Architecture Dr. Boris Grot and Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh General Information Instructors: Boris
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors:!
Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors:!
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen
 Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
COMP 322: Fundamentals of Parallel Programming
 COMP 322: Fundamentals of Parallel Programming! Lecture 1: The What and Why of Parallel Programming; Task Creation & Termination (async, finish) Vivek Sarkar Department of Computer Science, Rice University
COMP 322: Fundamentals of Parallel Programming! Lecture 1: The What and Why of Parallel Programming; Task Creation & Termination (async, finish) Vivek Sarkar Department of Computer Science, Rice University
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
CS/EE 6810: Computer Architecture
 CS/EE 6810: Computer Architecture Class format: Most lectures on YouTube *BEFORE* class Use class time for discussions, clarifications, problem-solving, assignments 1 Introduction Background: CS 3810 or
CS/EE 6810: Computer Architecture Class format: Most lectures on YouTube *BEFORE* class Use class time for discussions, clarifications, problem-solving, assignments 1 Introduction Background: CS 3810 or
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf