Trends in HPC Architectures and Parallel
|
|
|
- Damian Blankenship
- 6 years ago
- Views:
Transcription


1 Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA
2 Agenda - Computational Sciences - Trends in Parallel Architectures - Trends in Parallel Programming - PRACE 1
, is the third pillar of scientific inquiry,")


3 Computational Sciences Computational science (with theory and experimentation), is the third pillar of scientific inquiry, enabling researchers to build and test models of complex phenomena Quick evolution of innovation: Instantaneous communication Geographically distributed work Increased productivity More data everywhere Increasing problem complexity Innovation happens worldwide 2


4 Technology Evolution More data everywhere: Radar, satellites, CAT scans, weather models, the human genome. The size and resolution of the problems scientists address today are limited only by the size of the data they can reasonably work with. There is a constantly increasing demand for faster processing on bigger data. Increasing problem complexity: Partly driven by the ability to handle bigger data, but also by the requirements and opportunities brought by new technologies. For example, new kinds of medical scans create new computational challenges. HPC Evolution As technology allows scientists to handle bigger datasets and faster computations, they push to solve harder problems. In turn, the new class of problems drives the next cycle of technology innovation. 3


5 Computational Sciences today Multidisciplinary problems Coupled applicatitions - Full simulation of engineering systems - Full simulation of biological systems - Astrophysics - Materials science - Bio-informatics, proteomics, pharmaco-genetics - Scientifically accurate 3D functional models of the human body - Biodiversity and biocomplexity - Climate and Atmospheric Research - Energy - Digital libraries for science and engineering Large amount of data Complex mathematical models 4
6 HPC Architectures Performance Comes from: Device Technology Logic switching speed and device density Memory capacity and access time Communications bandwidth and latency Computer Architecture Instruction issue rate Execution pipelining Reservation stations Branch prediction Cache management Parallelism Number of operations per cycle per processor Instruction level parallelism (ILP) Vector processing Number of processors per node Number of nodes in a system CPU 1 CPU 2 CPU 3 Network memory memory memory CPU 1 CPU 2 CPU 3 memory memory memory Network memory memory memory CPU 1 CPU 2 CPU 3 Network Shared Memory Systems Distributed Shared Memory Distributed Memory Systems 5
7 HPC Architectures: Parameters affecting Performance Peak floating point performance Main memory capacity Bi-section bandwidth I/O bandwidth Secondary storage capacity Organization Class of system # nodes # processors per node Accelerators Network topology Control strategy MIMD Vector, PVP SIMD SPMD 6
 Cray XMP, YMP, C90 NEC Earth Simulator, SX-6 Massively Parallel Processors")
 SGI Origin HP Superdome Hybrid HPC Systems Roadrunner Chinese Tianhe-1A system")
8 HPC systems evolution Vector Processors Cray-1 SIMD, Array Processors Goodyear MPP, MasPar 1 & 2, TMC CM-2 Parallel Vector Processors (PVP) Cray XMP, YMP, C90 NEC Earth Simulator, SX-6 Massively Parallel Processors (MPP) Cray T3D, T3E, TMC CM-5, Blue Gene/L Commodity Clusters Beowulf-class PC/Linux clusters Constellations Distributed Shared Memory (DSM) SGI Origin HP Superdome Hybrid HPC Systems Roadrunner Chinese Tianhe-1A system GPGPU systems 7
9 HPC systems evolution in CINECA 1969: CDC st system for scientific computing 1975: CDC st supercomputer 1985: Cray X-MP / st vector supercomputer 1989: Cray Y-MP / : Cray C-90 / : Cray T3D 64 1 st parallel supercomputer 1995: Cray T3D : Cray T3E st MPP supercomputer 2002: IBM SP Teraflops 2005: IBM SP : IBM BCX 10 Teraflops 2009: IBM SP6 100 Teraflops 2012: IBM BG/Q 2 Petaflops 8

10 BG/Q in CINECA 10 BGQ Frame nodes 1 PowerA2 processor per node 16 core per processor cores 1GByte / core 2PByte of scratch space 2PFlop/s peak performance 1MWatt liquid cooled -16 core 1.6 GHz - a crossbar switch links the cores and L2 cache memory together. - 5D torus interconnect The Power A2 core has a 64-bit instruction set (unlike the prior 32-bit PowerPC chips used in BG/L and BG/P The A2 core have four threads and has inorder dispatch, execution, and completion instead of out-of-order execution common in many RISC processor designs. The A2 core has 16KB of L1 data cache and another 16KB of L1 instruction cache. Each core also includes a quad-pumped double-precision floating point unit: Each FPU on each core has four pipelines, which can be used to execute scalar floating point instructions, four-wide SIMD instructions, or two-wide complex arithmetic SIMD instructions. 9
11 Top 500: some facts 1976 Cray 1 installed at Los Alamos: peak performance 160 MegaFlop/s (10 6 flop/s) 1993 (1 Edition Top 500) N GFlop/s (10 12 flop/s) 1997 Teraflop/s barrier (10 12 flop/s) 2008 Petaflop/s (10 15 flop/s): Roadrunner (LANL) Rmax 1026 Gflop/s, Rpeak 1375 Gflop/s hybrid system: 6562 processors dual-core AMD Opteron accelerated with IBM Cell processors (98 TByte di RAM) Petaflop/s : K computer (SPARC64 VIIIfx 2.0GHz, Tofu interconnect) RIKEN Japan - 62% of the systems on the top500 use processors with six or more cores - 39 systems use GPUs as accelerators (35 NVIDIA, 2 Cell, 2 ATI Radeon) 10
12 HPC Evolution Moore s law is holding, in the number of transistors Transistors on an ASIC still doubling every 18 months at constant cost 15 years of exponential clock rate growth has ended Moore s Law reinterpreted Performance improvements are now coming from the increase in the number of cores on a processor (ASIC) #cores per chip doubles every 18 months instead of clock threads per node will become visible soon - Million-way parallelism From Herb Sutter<hsutter@microsoft.com> Heterogeneity: Accelerators -GPGPU - MIC 11

 projected to grow slowly Requires mechanisms for efficient inter-processor coordination Synchronization Mutual exclusion Context")
13 Multi-core Motivation for Multi-Core Exploits improved feature-size and density Increases functional units per chip (spatial efficiency) Limits energy consumption per operation Constrains growth in processor complexity Challenges resulting from multi-core Relies on effective exploitation of multiple-thread parallelism Need for parallel computing model and parallel programming model Aggravates memory wall Memory bandwidth Way to get data out of memory banks Way to get data into multi-core processor array Memory latency Fragments (shared) L3 cache Pins become strangle point Rate of pin growth projected to slow and flatten Rate of bandwidth per pin (pair) projected to grow slowly Requires mechanisms for efficient inter-processor coordination Synchronization Mutual exclusion Context switching 12
14 Heterogeneous Multicore Architecture Combines different types of processors Each optimized for a different operational modality Performance > Nx better than other N processor types Synthesis favors superior performance For complex computation exhibiting distinct modalities Conventional co-processors Graphical processing units (GPU) Network controllers (NIC) Efforts underway to apply existing special purpose components to general applications Purpose-designed accelerators Integrated to significantly speedup some critical aspect of one or more important classes of computation IBM Cell architecture ClearSpeed SIMD attached array processor 13
15 Real HPC Crisis is with Software A supercomputer application and software are usually much more long-lived than a hardware - Hardware life typically four-five years at most. - Fortran and C are still the main programming models Programming is stuck - Arguably hasn t changed so much since the 70 s Software is a major cost component of modern technologies. - The tradition in HPC system procurement is to assume that the software is free. It s time for a change - Complexity is rising dramatically - Challenges for the applications on Petaflop systems - Improvement of existing codes will become complex and partly impossible - The use of O(100K) cores implies dramatic optimization effort - New paradigm as the support of a hundred threads in one node implies new parallelization strategies - Implementation of new parallel programming methods in existing large applications has not always a promising perspective There is the need for new community codes 14

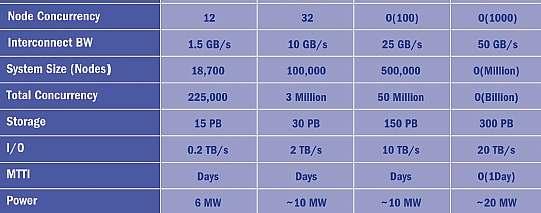
16 Roadmap to Exascale(architectural trends) 15
17 What about parallel App? In a massively parallel context, an upper limit for the scalability of parallel applications is determined by the fraction of the overall execution time spent in non-scalable operations (Amdahl's law). maximum speedup tends to 1 / ( 1 P ) P= parallel fraction core P = serial fraction=
18 Programming Models Message Passing (MPI) Shared Memory (OpenMP) Partitioned Global Address Space Programming (PGAS) Languages UPC, Coarray Fortran, Titanium Next Generation Programming Languages and Models Chapel, X10, Fortress Languages and Paradigm for Hardware Accelerators CUDA, OpenCL Hybrid: MPI + OpenMP + CUDA/OpenCL 17
19 Trends Scalar Application Vector MPP System, Message Passing: MPI Distributed memory Shared Memory Multi core nodes: OpenMP Hybrid codes Accelerator (GPGPU, FPGA): Cuda, OpenCL 18
20 Message Passing domain decomposition node memory node memory node memory CPU CPU CPU Internal High Performance Network node memory node memory node memory CPU CPU CPU 19
21 Ghost Cells - Data exchange sub-domain boundaries Processor 1 i,j+1 i-1,j i,j i+1,j Processor 1 i,j+1 i-1,j i,j i+1,j i,j+1 i-1,j i,j i+1,j i,j-1 Ghost Cells Ghost Cells exchanged between processors at every update i,j+1 i-1,j i,j i+1,j i,j-1 Processor 2 i,j+1 i-1,j i,j i+1,j i,j-1 Processor 2 20
22 Message Passing: MPI Main Characteristic Library Coarse grain Inter node parallelization (few real alternative) Domain partition Distributed Memory Almost all HPC parallel App Open Issue Latency OS jitter Scalability
23 Shared memory node Thread 0 CPU y Thread 1 Thread 2 Thread 3 CPU CPU CPU memory x 22
24 Shared Memory: OpenMP Main Characteristic Compiler directives Medium grain Intra node parallelization (pthreads) Loop or iteration partition Shared memory Many HPC App Open Issue Thread creation overhead Memory/core affinity Interface with MPI 23
25 OpenMP!$omp parallel do do i = 1, nsl call 1DFFT along z ( f [ offset( threadid ) ] ) end do!$omp end parallel do call fw_scatter (... )!$omp parallel do i = 1, nzl!$omp parallel do do j = 1, Nx call 1DFFT along y ( f [ offset( threadid ) ] ) end do!$omp parallel do do j = 1, Ny call 1DFFT along x ( f [ offset( threadid ) ] ) end do end do!$omp end parallel 24
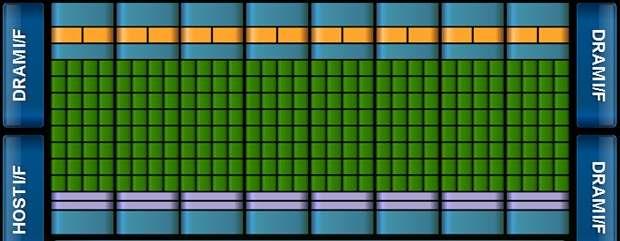
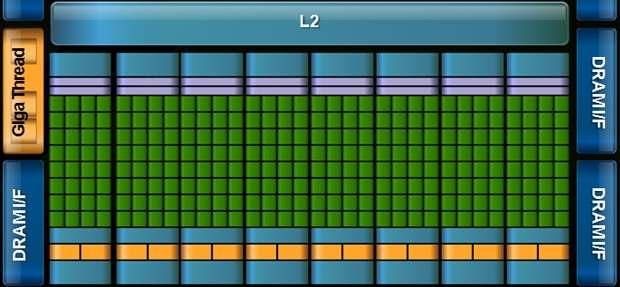
26 Accelerator/GPGPU + Sum of 1D array 25

27 CUDA - OpenCL Main Characteristic Ad-hoc compiler Fine grain offload parallelization (GPU) Single iteration parallelization Ad-hoc memory Few HPC App Open Issue Memory copy Standard Tools Integration with other languages 26
28 Hybrid (MPI+OpenMP+CUDA+ Take the positive off all models Exploit memory hierarchy Many HPC applications are adopting this model Mainly due to developer inertia Hard to rewrite million of source lines +python) 27

29 Hybrid parallel programming Python: Ensemble simulations MPI: Domain partition OpenMP: External loop partition CUDA: assign inner loops Iteration to GPU threads Quantum ESPRESSO 28


30 PRACE Partnership for Advanced Computing in Europe PRACE is part of the ESFRI roadmap and has the aim of creating a European Research Infrastructure providing world class systems and services and coordinating their use throughout Europe. It covers both hardware at the multi petaflop/s level and also very demanding software (parallel applications) to exploit these systems. 29


31 PRACE Tier 0 Systems - JUGENE - CURIE - HERMIT - SuperMUC - FERMI - Marenostrum 30
32 PRACE: Objectives Creation and manage a persistent, sustainable pan-european HPC service Deployment of three to five Pflop/s systems at different European sites: Hosting Sites: Germany, France, Italy, Spain First Pflop/s system installed at Juelich in Germany Establish a legal and organisational structure involving HPC centres, national funding agencies, and scientific user communities Develop funding and usage models and establish a peer review process Provide training for European scientists and create a permanent education programme Late 2009: 1PF in the top : 3 more systems in the top : the exaflop in the top 5 Call for access to PRACE HPC resources OPEN till August

33 HPC-Europa 2: Providing access to HPC resources HPC-Europa is a consortium of seven leading HPC infrastructures and five centres of excellence aiming at the integrated provision of advanced computational services to the European research community working at the forefront of science. The services will be delivered at a large spectrum both in terms of access to HPC systems and provision of a suitable computational environment to allow the European researchers to remain competitive with teams elsewhere in the world. Moreover, Joint Research and Networking actions will contribute to foster a culture of cooperation to generate critical mass for computational. HP-Europa 2: (FP7-INFRASTRUCTURES ) 32

34 HPC-Europa 2: Access Provision of transnational access to some of the most powerful HPC facilities in Europe Opportunities to collaborate with scientists working in related fields at a relevant local research institute HPC consultancy from experienced staff Provision of a suitable computational environment Travel costs, subsistence expenses and accommodation 33
Trends in HPC Architectures and Parallel
 Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA CINECA, February 11-15, 2013 Agenda Computational
Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA CINECA, February 11-15, 2013 Agenda Computational
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
HPC Architectures past,present and emerging trends
 HPC Architectures past,present and emerging trends Author: Andrew Emerson, Cineca a.emerson@cineca.it Speaker: Alessandro Marani, Cineca a.marani@cineca.it Agenda Computational Science Trends in HPC technology
HPC Architectures past,present and emerging trends Author: Andrew Emerson, Cineca a.emerson@cineca.it Speaker: Alessandro Marani, Cineca a.marani@cineca.it Agenda Computational Science Trends in HPC technology
CINECA and the European HPC Ecosystem
 CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
HPC Architectures past,present and emerging trends
 HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Introduction to High Performance Computing
 Introduction to High Performance Computing Giovanni Erbacci - g.erbacci@cineca.it Supercomputing Applications & Innovation Department - CINECA Outline Computational Sciences High Performance Computing
Introduction to High Performance Computing Giovanni Erbacci - g.erbacci@cineca.it Supercomputing Applications & Innovation Department - CINECA Outline Computational Sciences High Performance Computing
HPC IN EUROPE. Organisation of public HPC resources
 HPC IN EUROPE Organisation of public HPC resources Context Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded
HPC IN EUROPE Organisation of public HPC resources Context Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded
Supercomputer Architecture
 Prof. Thomas Sterling Pervasive Technology Institute School of Informatics & Computing Indiana University Dr. Steven R. Brandt Center for Computation & Technology Louisiana State University Basics of Supercomputing
Prof. Thomas Sterling Pervasive Technology Institute School of Informatics & Computing Indiana University Dr. Steven R. Brandt Center for Computation & Technology Louisiana State University Basics of Supercomputing
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to High Performance Computing. Giovanni Erbacci - Supercomputing Applications & Innovation Department - CINECA
 Introduction to High Performance Computing Giovanni Erbacci - g.erbacci@cineca.it Supercomputing Applications & Innovation Department - CINECA Outline Computational Sciences High Performance Computing
Introduction to High Performance Computing Giovanni Erbacci - g.erbacci@cineca.it Supercomputing Applications & Innovation Department - CINECA Outline Computational Sciences High Performance Computing
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I. Thomas Schulthess
 High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High Performance Computing from an EU perspective
 High Performance Computing from an EU perspective DEISA PRACE Symposium 2010 Barcelona, 10 May 2010 Kostas Glinos European Commission - DG INFSO Head of Unit GÉANT & e-infrastructures 1 "The views expressed
High Performance Computing from an EU perspective DEISA PRACE Symposium 2010 Barcelona, 10 May 2010 Kostas Glinos European Commission - DG INFSO Head of Unit GÉANT & e-infrastructures 1 "The views expressed
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
IBM HPC DIRECTIONS. Dr Don Grice. ECMWF Workshop November, IBM Corporation
 IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
HPC Resources & Training
 www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Parallel Computing Why & How?
 Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Parallel Programming Concepts. Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04. Parallel Background. Why Bother?
 Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
High Performance Computing
 CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
CSC630/CSC730: Parallel & Distributed Computing Trends in HPC 1 High Performance Computing High-performance computing (HPC) is the use of supercomputers and parallel processing techniques for solving complex
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
FUSION PROCESSORS AND HPC
 FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
The way toward peta-flops
 The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
The IBM Blue Gene/Q: Application performance, scalability and optimisation
 The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
European energy efficient supercomputer project
 http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
CS4961 Parallel Programming. Lecture 1: Introduction 08/25/2009. Course Details. Mary Hall August 25, Today s Lecture.
 Parallel Programming Lecture 1: Introduction Mary Hall August 25, 2009 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
Parallel Programming Lecture 1: Introduction Mary Hall August 25, 2009 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Parallel Computing Basics, Semantics
 1 / 15 Parallel Computing Basics, Semantics Landau s 1st Rule of Education Rubin H Landau Sally Haerer, Producer-Director Based on A Survey of Computational Physics by Landau, Páez, & Bordeianu with Support
1 / 15 Parallel Computing Basics, Semantics Landau s 1st Rule of Education Rubin H Landau Sally Haerer, Producer-Director Based on A Survey of Computational Physics by Landau, Páez, & Bordeianu with Support
Advanced Topics in Computer Architecture
 Advanced Topics in Computer Architecture Lecture 7 Data Level Parallelism: Vector Processors Marenglen Biba Department of Computer Science University of New York Tirana Cray I m certainly not inventing
Advanced Topics in Computer Architecture Lecture 7 Data Level Parallelism: Vector Processors Marenglen Biba Department of Computer Science University of New York Tirana Cray I m certainly not inventing
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu
 Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
BİL 542 Parallel Computing
 BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
Los Alamos National Laboratory Modeling & Simulation
 Los Alamos National Laboratory Modeling & Simulation Lawrence J. Cox, Ph.D. Deputy Division Leader Computer, Computational and Statistical Sciences February 2, 2009 LA-UR 09-00573 Modeling and Simulation
Los Alamos National Laboratory Modeling & Simulation Lawrence J. Cox, Ph.D. Deputy Division Leader Computer, Computational and Statistical Sciences February 2, 2009 LA-UR 09-00573 Modeling and Simulation
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
HPC-CINECA infrastructure: The New Marconi System. HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati,
 HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Accelerating CFD with Graphics Hardware
 Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
OpenMP for next generation heterogeneous clusters
 OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Current Status of the Next- Generation Supercomputer in Japan. YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN
 Current Status of the Next- Generation Supercomputer in Japan YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN International Workshop on Peta-Scale Computing Programming Environment, Languages
Current Status of the Next- Generation Supercomputer in Japan YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN International Workshop on Peta-Scale Computing Programming Environment, Languages