Decomposing a Scene into Geometric and Semantically Consistent Regions
|
|
|
- Rhoda Arnold
- 5 years ago
- Views:
Transcription
1 Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International Conference on Computer Vision September 2009
2 Segmentation and Context What is this pixel?

3 Segmentation and Context What is this pixel?
4 Segmentation and Context What is this pixel?
5 Segmentation and Context Now what is this pixel?

6 Segmentation and Context Now what is this pixel?

7 Segmentation and Context
 coherent geometric placement (orientation and location with respect to the horizon)")
8 Goal of Scene Decomposition Decompose the scene into regions with semantic region labels (e.g., road, sky, building, etc.) coherent geometric placement (orientation and location with respect to the horizon)
9 Region-based Model S r, G r R p regions Variables α p : pixel appearance R p : pixel-to-region correspondence A r : region appearance S r : region semantic class G r : region geometry v hz : location of horizon pixels Energy Function Ε(R, A, S, G, v hz, K I, θ)
10 Energy Function E(R, A, S, G, v hz, K I, θ) = ψ horizon (v hz ) ψ region (S r, G r, A r, v hz ) ψ boundary (A r, A s ) ψ pair (S r,s s,g r,g s ) Horizon Term e.g., vanishing lines Region Term e.g., consistent appearance and location Boundary Term e.g., difference in color/texture between regions Pairwise Term e.g., foreground on road
11 Energy Function E(R, A, S, G, v hz, K I, θ) = ψ horizon (v hz ) ψ region (S r, G r, A r, v hz ) ψ boundary (A r, A s ) ψ pair (S r,s s,g r,g s ) Horizon Term e.g., vanishing lines + Region Term e.g., consistent appearance and location + Exact inference is intractable Boundary Term e.g., difference in color/texture between regions + Pairwise Term e.g., foreground on road
12 Inference image segment database (Ω) initialize scene decomposition proposal move (R p )


13 (Segment) Proposal Moves initial decomposition proposal move final decomposition segment database (Ω)
 accept if lower E(R, A, S, G, v hz, K I, θ) evaluate energy")
14 Inference image segment database (Ω) initialize scene decomposition proposal move (R p ) global inference (S r, G r, v hz ) accept if lower E(R, A, S, G, v hz, K I, θ) evaluate energy function

15 Inference Animation semantic overlay image geometry overlay regions
16 Parameter Learning Positive examples: all coherent regions and segments Negative examples: exponentially many Most of them are ridiculously easy Closed-loop learning Learn simple region and context models Run inference (on training set) sampling errors Re-train with augmented training set training set inference E(R, A, S, G, v hz, K I, θ)




17 Results: 21-class MSRC Validate against state-ofthe-art approaches Region/pixel class only Ground truth labels are approximate No geometry information 21 CLASS Shotton et al. Gould et al. Pixel CRF Region-based Mean hand labeled image pixel CRF region-based

18 High Quality Dataset MSRC dataset is limited poorly labeled boundaries many missing pixels (void) no geometry information Collected images from MSRC, Hoiem et al., Pascal VOC 715 outdoor scenes with high-quality labels region boundaries region class and geometry horizon Used Amazon s Mechanical Turk for labeling Available for download from:
 5-10 minutes per task 24-48 hour turn-around time (for 715 images) Less than 10% of tasks needed rework")
19 Amazon Mechanical Turk (AMT) $0.10 per task (regions, classes, surface types) 5-10 minutes per task hour turn-around time (for 715 images) Less than 10% of tasks needed rework Total cost for labels: under $250 (includes $40 textbook on Adobe Flash) Saving me from having to label image: priceless.













20 AMT: Label Quality Typical quality (hand labeled) You don t always get what you want Comparison with MSRC labels
21 Quantitative Results 0.8 pixelwise region-based accuracy 0.7 accuracy pixelwise region-based fold fold CLASS Mean Std GEOMETRY Mean Std Pixel CRF Pixel CRF Region-based Region-based Region Classes: sky, tree, road, grass, water, building, mountain, fg. object Region Geometry: sky, vertical, horizontal (support) Horizon error: 6.9% (17 pixels)


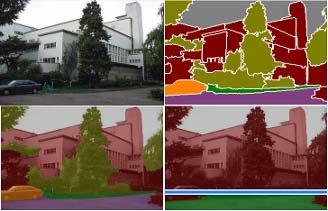

22 Example Results
23 Application: 3d Reconstruction Estimate camera tilt from location of horizon Predict region 3d position using ray projected through camera plane image plane horizon camera h image ground plane

![, PAMI 08], [Hoiem et al.](/docs-images/87/96815627/images/24-2.jpg ", IJCV 07], [Russell and")
24 Example 3d Reconstructions Related work: [Saxena et al., PAMI 08], [Hoiem et al., IJCV 07], [Russell and Torralba, CVPR 09]
25 NIPS 2009 Sneak Peak
![[Gould, Gao, Koller NIPS 09] Hierarchical Scene Model C o O r objects Variables α p : pixel appearance R p : pixel-to-region correspondence A r : region appearance S r : region](/docs-images/87/96815627/images/26-1.jpg "semantic class G r : region geometry O r : region-to-object correspondence C o : object class v hz : location of horizon S r, G r R p regions pixels energy function E(R, A, S, G, O, C,")
26 [Gould, Gao, Koller NIPS 09] Hierarchical Scene Model C o O r objects Variables α p : pixel appearance R p : pixel-to-region correspondence A r : region appearance S r : region semantic class G r : region geometry O r : region-to-object correspondence C o : object class v hz : location of horizon S r, G r R p regions pixels energy function E(R, A, S, G, O, C, v hz, K)
![[Gould, Gao, Koller NIPS 09] Energy Function E(R, A,](/docs-images/87/96815627/images/27-1.jpg "S, G, O, C, v hz, K I, θ) = ψ horizon (v hz ) ψ region")
 ψ context (C o, S r ) + + + + Horizon Term e.")


27 [Gould, Gao, Koller NIPS 09] Energy Function E(R, A, S, G, O, C, v hz, K I, θ) = ψ horizon (v hz ) ψ region (S r, G r, v hz ) ψ boundary (A r, A s ) ψ object (C o,v hz ) ψ context (C o, S r ) Horizon Term e.g., vanishing lines Region Term e.g., consistent appearance and location Boundary Term e.g., difference in color/texture between regions Object Term e.g. wheel-like appearance in bottom corner Context Term e.g., cars on road
28 [Gould, Gao, Koller NIPS 09] Top-down Proposal Moves image segment database detection database initialize scene decomposition proposal move (R p, O r ) global inference (S r, G r, C o, v hz ) accept if lower E(R, A, S, G, O, C, v hz, K I, θ) evaluate energy function



 car (88.3%) car (88.")
 Our joint")
29 [Gould, Gao, Koller NIPS 09] Object Detection Results Sliding-window detector s top two detections per image person (88.1%) person (98.1%) car (88.3%) car (88.9%) cow (98.4%) Our joint region-based segmentation and object detection
30 Summary Our model decomposes a scene into geometric and semantically consistent regions using a unified energy function over pixels and regions By classifying large regions rather than individual pixels we can compute more robust features and reduce inference complexity Multiple over-segmentations allow us to refine region boundaries and make large moves in energy space Context can be easily captured using a pairwise term between adjacent regions Our model provides a base for integrating many other vision tasks (e.g., 3D reconstruction and object detection)
31 Thank You ありがとうございます
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould 1 Tianshi Gao 1 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer Science, Stanford University
Region-based Segmentation and Object Detection Stephen Gould 1 Tianshi Gao 1 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer Science, Stanford University
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Structured Completion Predictors Applied to Image Segmentation
 Structured Completion Predictors Applied to Image Segmentation Dmitriy Brezhnev, Raphael-Joel Lim, Anirudh Venkatesh December 16, 2011 Abstract Multi-image segmentation makes use of global and local features
Structured Completion Predictors Applied to Image Segmentation Dmitriy Brezhnev, Raphael-Joel Lim, Anirudh Venkatesh December 16, 2011 Abstract Multi-image segmentation makes use of global and local features
Multi-Class Segmentation with Relative Location Prior
 Multi-Class Segmentation with Relative Location Prior Stephen Gould, Jim Rodgers, David Cohen, Gal Elidan, Daphne Koller Department of Computer Science, Stanford University International Journal of Computer
Multi-Class Segmentation with Relative Location Prior Stephen Gould, Jim Rodgers, David Cohen, Gal Elidan, Daphne Koller Department of Computer Science, Stanford University International Journal of Computer
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Object recognition (part 2)
") Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Simultaneous Multi-class Pixel Labeling over Coherent Image Sets
 Simultaneous Multi-class Pixel Labeling over Coherent Image Sets Paul Rivera Research School of Computer Science Australian National University Canberra, ACT 0200 Stephen Gould Research School of Computer
Simultaneous Multi-class Pixel Labeling over Coherent Image Sets Paul Rivera Research School of Computer Science Australian National University Canberra, ACT 0200 Stephen Gould Research School of Computer
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Cascaded Classification Models: Combining Models for Holistic Scene Understanding
 Cascaded Classification Models: Combining Models for Holistic Scene Understanding Geremy Heitz Stephen Gould Department of Electrical Engineering Stanford University, Stanford, CA 94305 {gaheitz,sgould}@stanford.edu
Cascaded Classification Models: Combining Models for Holistic Scene Understanding Geremy Heitz Stephen Gould Department of Electrical Engineering Stanford University, Stanford, CA 94305 {gaheitz,sgould}@stanford.edu
CS 229 Final Project: Single Image Depth Estimation From Predicted Semantic Labels
 CS 229 Final Project: Single Image Deth Estimation From Predicted Semantic Labels Beyang Liu beyangl@cs.stanford.edu Stehen Gould sgould@stanford.edu Prof. Dahne Koller koller@cs.stanford.edu December
CS 229 Final Project: Single Image Deth Estimation From Predicted Semantic Labels Beyang Liu beyangl@cs.stanford.edu Stehen Gould sgould@stanford.edu Prof. Dahne Koller koller@cs.stanford.edu December
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Context. CS 554 Computer Vision Pinar Duygulu Bilkent University. (Source:Antonio Torralba, James Hays)
") Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Joint Semantic and Geometric Segmentation of Videos with a Stage Model
 Joint Semantic and Geometric Segmentation of Videos with a Stage Model Buyu Liu ANU and NICTA Canberra, ACT, Australia buyu.liu@anu.edu.au Xuming He NICTA and ANU Canberra, ACT, Australia xuming.he@nicta.com.au
Joint Semantic and Geometric Segmentation of Videos with a Stage Model Buyu Liu ANU and NICTA Canberra, ACT, Australia buyu.liu@anu.edu.au Xuming He NICTA and ANU Canberra, ACT, Australia xuming.he@nicta.com.au
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Automatic Dense Semantic Mapping From Visual Street-level Imagery
 Automatic Dense Semantic Mapping From Visual Street-level Imagery Sunando Sengupta [1], Paul Sturgess [1], Lubor Ladicky [2], Phillip H.S. Torr [1] [1] Oxford Brookes University [2] Visual Geometry Group,
Automatic Dense Semantic Mapping From Visual Street-level Imagery Sunando Sengupta [1], Paul Sturgess [1], Lubor Ladicky [2], Phillip H.S. Torr [1] [1] Oxford Brookes University [2] Visual Geometry Group,
Multi-Class Segmentation with Relative Location Prior
 International Journal of Computer Vision DOI 10.1007/s11263-008-0140-x Multi-Class Segmentation with Relative Location Prior Stephen Gould, Jim Rodgers, David Cohen, Gal Elidan, Daphne Koller Department
International Journal of Computer Vision DOI 10.1007/s11263-008-0140-x Multi-Class Segmentation with Relative Location Prior Stephen Gould, Jim Rodgers, David Cohen, Gal Elidan, Daphne Koller Department
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Texton Clustering for Local Classification using Scene-Context Scale
 Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Learning and Inference to Exploit High Order Poten7als
 Learning and Inference to Exploit High Order Poten7als Richard Zemel CVPR Workshop June 20, 2011 Collaborators Danny Tarlow Inmar Givoni Nikola Karamanov Maks Volkovs Hugo Larochelle Framework for Inference
Learning and Inference to Exploit High Order Poten7als Richard Zemel CVPR Workshop June 20, 2011 Collaborators Danny Tarlow Inmar Givoni Nikola Karamanov Maks Volkovs Hugo Larochelle Framework for Inference
CS 558: Computer Vision 13 th Set of Notes
 CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
arxiv: v1 [cs.cv] 20 Oct 2012
![arxiv: v1 [cs.cv] 20 Oct 2012](/thumbs/75/71957326.jpg "arxiv: v1 [cs.cv] 20 Oct 2012") Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials arxiv:1210.5644v1 [cs.cv] 20 Oct 2012 Philipp Krähenbühl Computer Science Department Stanford University philkr@cs.stanford.edu
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials arxiv:1210.5644v1 [cs.cv] 20 Oct 2012 Philipp Krähenbühl Computer Science Department Stanford University philkr@cs.stanford.edu
Closing the Loop in Scene Interpretation
 Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Big and Tall: Large Margin Learning with High Order Losses
 Big and Tall: Large Margin Learning with High Order Losses Daniel Tarlow University of Toronto dtarlow@cs.toronto.edu Richard Zemel University of Toronto zemel@cs.toronto.edu Abstract Graphical models
Big and Tall: Large Margin Learning with High Order Losses Daniel Tarlow University of Toronto dtarlow@cs.toronto.edu Richard Zemel University of Toronto zemel@cs.toronto.edu Abstract Graphical models
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
LEARNING BOUNDARIES WITH COLOR AND DEPTH. Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen
 LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Learning Deep Structured Models for Semantic Segmentation. Guosheng Lin
 Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues
 2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation
 Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
CS229 Final Project One Click: Object Removal
 CS229 Final Project One Click: Object Removal Ming Jiang Nicolas Meunier December 12, 2008 1 Introduction In this project, our goal is to come up with an algorithm that can automatically detect the contour
CS229 Final Project One Click: Object Removal Ming Jiang Nicolas Meunier December 12, 2008 1 Introduction In this project, our goal is to come up with an algorithm that can automatically detect the contour
Visual Recognition: Examples of Graphical Models
 Visual Recognition: Examples of Graphical Models Raquel Urtasun TTI Chicago March 6, 2012 Raquel Urtasun (TTI-C) Visual Recognition March 6, 2012 1 / 64 Graphical models Applications Representation Inference
Visual Recognition: Examples of Graphical Models Raquel Urtasun TTI Chicago March 6, 2012 Raquel Urtasun (TTI-C) Visual Recognition March 6, 2012 1 / 64 Graphical models Applications Representation Inference
Contextual Classification with Functional Max-Margin Markov Networks
 Contextual Classification with Functional Max-Margin Markov Networks Dan Munoz Nicolas Vandapel Drew Bagnell Martial Hebert Geometry Estimation (Hoiem et al.) Sky Problem 3-D Point Cloud Classification
Contextual Classification with Functional Max-Margin Markov Networks Dan Munoz Nicolas Vandapel Drew Bagnell Martial Hebert Geometry Estimation (Hoiem et al.) Sky Problem 3-D Point Cloud Classification
Supplementary Material: Decision Tree Fields
 Supplementary Material: Decision Tree Fields Note, the supplementary material is not needed to understand the main paper. Sebastian Nowozin Sebastian.Nowozin@microsoft.com Toby Sharp toby.sharp@microsoft.com
Supplementary Material: Decision Tree Fields Note, the supplementary material is not needed to understand the main paper. Sebastian Nowozin Sebastian.Nowozin@microsoft.com Toby Sharp toby.sharp@microsoft.com
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Dynamic visual understanding of the local environment for an indoor navigating robot
 Dynamic visual understanding of the local environment for an indoor navigating robot Grace Tsai and Benjamin Kuipers Abstract We present a method for an embodied agent with vision sensor to create a concise
Dynamic visual understanding of the local environment for an indoor navigating robot Grace Tsai and Benjamin Kuipers Abstract We present a method for an embodied agent with vision sensor to create a concise
Markov Networks in Computer Vision. Sargur Srihari
 Markov Networks in Computer Vision Sargur srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Important application area for MNs 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Markov Networks in Computer Vision Sargur srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Important application area for MNs 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Multi-Class Segmentation with Relative Location Prior
 DOI 10.1007/s11263-008-0140-x Multi-Class Segmentation with Relative Location Prior Stephen Gould Jim Rodgers David Cohen Gal Elidan Daphne Koller Received: 26 September 2007 / Accepted: 17 April 2008
DOI 10.1007/s11263-008-0140-x Multi-Class Segmentation with Relative Location Prior Stephen Gould Jim Rodgers David Cohen Gal Elidan Daphne Koller Received: 26 September 2007 / Accepted: 17 April 2008
Supplemental Material: Discovering Groups of People in Images
 Supplemental Material: Discovering Groups of People in Images Wongun Choi 1, Yu-Wei Chao 2, Caroline Pantofaru 3 and Silvio Savarese 4 1. NEC Laboratories 2. University of Michigan, Ann Arbor 3. Google,
Supplemental Material: Discovering Groups of People in Images Wongun Choi 1, Yu-Wei Chao 2, Caroline Pantofaru 3 and Silvio Savarese 4 1. NEC Laboratories 2. University of Michigan, Ann Arbor 3. Google,
Scene Understanding From a Moving Camera for Object Detection and Free Space Estimation
 Scene Understanding From a Moving Camera for Object Detection and Free Space Estimation Vladimir Haltakov, Heidrun Belzner and Slobodan Ilic Abstract Modern vehicles are equipped with multiple cameras
Scene Understanding From a Moving Camera for Object Detection and Free Space Estimation Vladimir Haltakov, Heidrun Belzner and Slobodan Ilic Abstract Modern vehicles are equipped with multiple cameras
What, Where & How Many? Combining Object Detectors and CRFs
 What, Where & How Many? Combining Object Detectors and CRFs Lubor Ladicky, Paul Sturgess, Karteek Alahari, Chris Russell, and Philip H.S. Torr Oxford Brookes University http://cms.brookes.ac.uk/research/visiongroup
What, Where & How Many? Combining Object Detectors and CRFs Lubor Ladicky, Paul Sturgess, Karteek Alahari, Chris Russell, and Philip H.S. Torr Oxford Brookes University http://cms.brookes.ac.uk/research/visiongroup
Convolutional Networks in Scene Labelling
 Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Unsupervised Patch-based Context from Millions of Images
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Spatially Constrained Location Prior for Scene Parsing
 Spatially Constrained Location Prior for Scene Parsing Ligang Zhang, Brijesh Verma, David Stockwell, Sujan Chowdhury Centre for Intelligent Systems School of Engineering and Technology, Central Queensland
Spatially Constrained Location Prior for Scene Parsing Ligang Zhang, Brijesh Verma, David Stockwell, Sujan Chowdhury Centre for Intelligent Systems School of Engineering and Technology, Central Queensland
Combining Appearance and Structure from Motion Features for Road Scene Understanding
 STURGESS et al.: COMBINING APPEARANCE AND SFM FEATURES 1 Combining Appearance and Structure from Motion Features for Road Scene Understanding Paul Sturgess paul.sturgess@brookes.ac.uk Karteek Alahari karteek.alahari@brookes.ac.uk
STURGESS et al.: COMBINING APPEARANCE AND SFM FEATURES 1 Combining Appearance and Structure from Motion Features for Road Scene Understanding Paul Sturgess paul.sturgess@brookes.ac.uk Karteek Alahari karteek.alahari@brookes.ac.uk
Spatial Pattern Templates for Recognition of Objects with Regular Structure
 Spatial Pattern Templates for Recognition of Objects with Regular Structure Radim Tyleček and Radim Šára Center for Machine Perception Czech Technical University in Prague Abstract. We propose a method
Spatial Pattern Templates for Recognition of Objects with Regular Structure Radim Tyleček and Radim Šára Center for Machine Perception Czech Technical University in Prague Abstract. We propose a method
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
A Segmentation-aware Object Detection Model with Occlusion Handling
 A Segmentation-aware Object Detection Model with Occlusion Handling Tianshi Gao 1 Benjamin Packer 2 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer
A Segmentation-aware Object Detection Model with Occlusion Handling Tianshi Gao 1 Benjamin Packer 2 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer
Sports Field Localization
 Sports Field Localization Namdar Homayounfar February 5, 2017 1 / 1 Motivation Sports Field Localization: Have to figure out where the field and players are in 3d space in order to make measurements and
Sports Field Localization Namdar Homayounfar February 5, 2017 1 / 1 Motivation Sports Field Localization: Have to figure out where the field and players are in 3d space in order to make measurements and
Harmony Potentials for Joint Classification and Segmentation
 Harmony Potentials for Joint Classification and Segmentation Josep M. Gonfaus 1,2, Xavier Boix 1, Joost van de Weijer 1,2 Andrew D. Bagdanov 1 Joan Serrat 1,2 Jordi Gonzàlez 1,2 1 Centre de Visió per Computador
Harmony Potentials for Joint Classification and Segmentation Josep M. Gonfaus 1,2, Xavier Boix 1, Joost van de Weijer 1,2 Andrew D. Bagdanov 1 Joan Serrat 1,2 Jordi Gonzàlez 1,2 1 Centre de Visió per Computador
Self Lane Assignment Using Smart Mobile Camera For Intelligent GPS Navigation and Traffic Interpretation
 For Intelligent GPS Navigation and Traffic Interpretation Tianshi Gao Stanford University tianshig@stanford.edu 1. Introduction Imagine that you are driving on the highway at 70 mph and trying to figure
For Intelligent GPS Navigation and Traffic Interpretation Tianshi Gao Stanford University tianshig@stanford.edu 1. Introduction Imagine that you are driving on the highway at 70 mph and trying to figure
Can Similar Scenes help Surface Layout Estimation?
 Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Learning Spatial Context: Using Stuff to Find Things
 Learning Spatial Context: Using Stuff to Find Things Wei-Cheng Su Motivation 2 Leverage contextual information to enhance detection Some context objects are non-rigid and are more naturally classified
Learning Spatial Context: Using Stuff to Find Things Wei-Cheng Su Motivation 2 Leverage contextual information to enhance detection Some context objects are non-rigid and are more naturally classified
Exploiting Sparsity for Real Time Video Labelling
 2013 IEEE International Conference on Computer Vision Workshops Exploiting Sparsity for Real Time Video Labelling Lachlan Horne, Jose M. Alvarez, and Nick Barnes College of Engineering and Computer Science,
2013 IEEE International Conference on Computer Vision Workshops Exploiting Sparsity for Real Time Video Labelling Lachlan Horne, Jose M. Alvarez, and Nick Barnes College of Engineering and Computer Science,
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Sparse Point Cloud Densification by Using Redundant Semantic Information
 Sparse Point Cloud Densification by Using Redundant Semantic Information Michael Hödlmoser CVL, Vienna University of Technology ken@caa.tuwien.ac.at Branislav Micusik AIT Austrian Institute of Technology
Sparse Point Cloud Densification by Using Redundant Semantic Information Michael Hödlmoser CVL, Vienna University of Technology ken@caa.tuwien.ac.at Branislav Micusik AIT Austrian Institute of Technology
Joint 2D-3D Temporally Consistent Semantic Segmentation of Street Scenes
 Joint 2D-3D Temporally Consistent Semantic Segmentation of Street Scenes Georgios Floros and Bastian Leibe UMIC Research Centre RWTH Aachen University, Germany {floros,leibe}@umic.rwth-aachen.de Abstract
Joint 2D-3D Temporally Consistent Semantic Segmentation of Street Scenes Georgios Floros and Bastian Leibe UMIC Research Centre RWTH Aachen University, Germany {floros,leibe}@umic.rwth-aachen.de Abstract
Markov Networks in Computer Vision
 Markov Networks in Computer Vision Sargur Srihari srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Some applications: 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Markov Networks in Computer Vision Sargur Srihari srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Some applications: 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Single-view 3D Reconstruction
 Single-view 3D Reconstruction 10/12/17 Computational Photography Derek Hoiem, University of Illinois Some slides from Alyosha Efros, Steve Seitz Notes about Project 4 (Image-based Lighting) You can work
Single-view 3D Reconstruction 10/12/17 Computational Photography Derek Hoiem, University of Illinois Some slides from Alyosha Efros, Steve Seitz Notes about Project 4 (Image-based Lighting) You can work
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
Computer Vision: Summary and Discussion
 12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
570 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 20, NO. 2, FEBRUARY 2011
 570 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 20, NO. 2, FEBRUARY 2011 Contextual Object Localization With Multiple Kernel Nearest Neighbor Brian McFee, Student Member, IEEE, Carolina Galleguillos, Student
570 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 20, NO. 2, FEBRUARY 2011 Contextual Object Localization With Multiple Kernel Nearest Neighbor Brian McFee, Student Member, IEEE, Carolina Galleguillos, Student
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Local cues and global constraints in image understanding
 Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
SuperParsing: Scalable Nonparametric Image Parsing with Superpixels
 SuperParsing: Scalable Nonparametric Image Parsing with Superpixels Joseph Tighe and Svetlana Lazebnik Dept. of Computer Science, University of North Carolina at Chapel Hill Chapel Hill, NC 27599-3175
SuperParsing: Scalable Nonparametric Image Parsing with Superpixels Joseph Tighe and Svetlana Lazebnik Dept. of Computer Science, University of North Carolina at Chapel Hill Chapel Hill, NC 27599-3175
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Geometric Context from Videos
 2013 IEEE Conference on Computer Vision and Pattern Recognition Geometric Context from Videos S. Hussain Raza Matthias Grundmann Irfan Essa Georgia Institute of Technology, Atlanta, GA, USA http://www.cc.gatech.edu/cpl/projects/videogeometriccontext
2013 IEEE Conference on Computer Vision and Pattern Recognition Geometric Context from Videos S. Hussain Raza Matthias Grundmann Irfan Essa Georgia Institute of Technology, Atlanta, GA, USA http://www.cc.gatech.edu/cpl/projects/videogeometriccontext
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Learning Semantic Environment Perception for Cognitive Robots
 Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Correcting User Guided Image Segmentation
 Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Multi-Class Image Labeling with Top-Down Segmentation and Generalized Robust P N Potentials
 FLOROS ET AL.: MULTI-CLASS IMAGE LABELING WITH TOP-DOWN SEGMENTATIONS 1 Multi-Class Image Labeling with Top-Down Segmentation and Generalized Robust P N Potentials Georgios Floros 1 floros@umic.rwth-aachen.de
FLOROS ET AL.: MULTI-CLASS IMAGE LABELING WITH TOP-DOWN SEGMENTATIONS 1 Multi-Class Image Labeling with Top-Down Segmentation and Generalized Robust P N Potentials Georgios Floros 1 floros@umic.rwth-aachen.de
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE
 OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
arxiv: v1 [cs.cv] 7 Aug 2017
![arxiv: v1 [cs.cv] 7 Aug 2017](/thumbs/81/83599070.jpg "arxiv: v1 [cs.cv] 7 Aug 2017") LEARNING TO SEGMENT ON TINY DATASETS: A NEW SHAPE MODEL Maxime Tremblay, André Zaccarin Computer Vision and Systems Laboratory, Université Laval Quebec City (QC), Canada arxiv:1708.02165v1 [cs.cv] 7 Aug
LEARNING TO SEGMENT ON TINY DATASETS: A NEW SHAPE MODEL Maxime Tremblay, André Zaccarin Computer Vision and Systems Laboratory, Université Laval Quebec City (QC), Canada arxiv:1708.02165v1 [cs.cv] 7 Aug
Attributes. Computer Vision. James Hays. Many slides from Derek Hoiem
 Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
3D Scene Understanding by Voxel-CRF
 3D Scene Understanding by Voxel-CRF Byung-soo Kim University of Michigan bsookim@umich.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Silvio Savarese Stanford University ssilvio@stanford.edu
3D Scene Understanding by Voxel-CRF Byung-soo Kim University of Michigan bsookim@umich.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Silvio Savarese Stanford University ssilvio@stanford.edu
Part-Based Models for Object Class Recognition Part 3
 High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
Pulling Things out of Perspective
 Pulling Things out of Perspective L ubor Ladický ETH Zürich, Switzerland lubor.ladicky@inf.ethz.ch Jianbo Shi University of Pennsylvania, USA jshi@seas.upenn.edu Marc Pollefeys ETH Zürich, Switzerland
Pulling Things out of Perspective L ubor Ladický ETH Zürich, Switzerland lubor.ladicky@inf.ethz.ch Jianbo Shi University of Pennsylvania, USA jshi@seas.upenn.edu Marc Pollefeys ETH Zürich, Switzerland
Object Detection Using Cascaded Classification Models
 Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Context by Region Ancestry
 Context by Region Ancestry Joseph J. Lim, Pablo Arbeláez, Chunhui Gu, and Jitendra Malik University of California, Berkeley - Berkeley, CA 94720 {lim,arbelaez,chunhui,malik}@eecs.berkeley.edu Abstract
Context by Region Ancestry Joseph J. Lim, Pablo Arbeláez, Chunhui Gu, and Jitendra Malik University of California, Berkeley - Berkeley, CA 94720 {lim,arbelaez,chunhui,malik}@eecs.berkeley.edu Abstract
Learning CRFs for Image Parsing with Adaptive Subgradient Descent
 Learning CRFs for Image Parsing with Adaptive Subgradient Descent Honghui Zhang Jingdong Wang Ping Tan Jinglu Wang Long Quan The Hong Kong University of Science and Technology Microsoft Research National
Learning CRFs for Image Parsing with Adaptive Subgradient Descent Honghui Zhang Jingdong Wang Ping Tan Jinglu Wang Long Quan The Hong Kong University of Science and Technology Microsoft Research National
Scene Segmentation in Adverse Vision Conditions
 Scene Segmentation in Adverse Vision Conditions Evgeny Levinkov Max Planck Institute for Informatics, Saarbrücken, Germany levinkov@mpi-inf.mpg.de Abstract. Semantic road labeling is a key component of
Scene Segmentation in Adverse Vision Conditions Evgeny Levinkov Max Planck Institute for Informatics, Saarbrücken, Germany levinkov@mpi-inf.mpg.de Abstract. Semantic road labeling is a key component of
24 hours of Photo Sharing. installation by Erik Kessels
 24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
Hough Regions for Joining Instance Localization and Segmentation
 Hough Regions for Joining Instance Localization and Segmentation Hayko Riemenschneider 1,2, Sabine Sternig 1, Michael Donoser 1, Peter M. Roth 1, and Horst Bischof 1 1 Institute for Computer Graphics and
Hough Regions for Joining Instance Localization and Segmentation Hayko Riemenschneider 1,2, Sabine Sternig 1, Michael Donoser 1, Peter M. Roth 1, and Horst Bischof 1 1 Institute for Computer Graphics and
Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model
 Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model Ido Ofir Computer Science Department Stanford University December 17, 2011 Abstract This project
Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model Ido Ofir Computer Science Department Stanford University December 17, 2011 Abstract This project
This is an author-deposited version published in : Eprints ID : 15223
 Open Archive TOULOUSE Archive Ouverte (OATAO) OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible. This is an author-deposited
Open Archive TOULOUSE Archive Ouverte (OATAO) OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible. This is an author-deposited
MRFs and Segmentation with Graph Cuts
 02/24/10 MRFs and Segmentation with Graph Cuts Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class Finish up EM MRFs w ij i Segmentation with Graph Cuts j EM Algorithm: Recap
02/24/10 MRFs and Segmentation with Graph Cuts Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class Finish up EM MRFs w ij i Segmentation with Graph Cuts j EM Algorithm: Recap
Learning a Dictionary of Shape Epitomes with Applications to Image Labeling
 Learning a Dictionary of Shape Epitomes with Applications to Image Labeling Liang-Chieh Chen 1, George Papandreou 2, and Alan L. Yuille 1,2 Departments of Computer Science 1 and Statistics 2, UCLA lcchen@cs.ucla.edu,
Learning a Dictionary of Shape Epitomes with Applications to Image Labeling Liang-Chieh Chen 1, George Papandreou 2, and Alan L. Yuille 1,2 Departments of Computer Science 1 and Statistics 2, UCLA lcchen@cs.ucla.edu,
Towards Spatio-Temporally Consistent Semantic Mapping
 Towards Spatio-Temporally Consistent Semantic Mapping Zhe Zhao, Xiaoping Chen University of Science and Technology of China, zhaozhe@mail.ustc.edu.cn,xpchen@ustc.edu.cn Abstract. Intelligent robots require
Towards Spatio-Temporally Consistent Semantic Mapping Zhe Zhao, Xiaoping Chen University of Science and Technology of China, zhaozhe@mail.ustc.edu.cn,xpchen@ustc.edu.cn Abstract. Intelligent robots require
Toward Coherent Object Detection And Scene Layout Understanding
 Toward Coherent Object Detection And Scene Layout Understanding Sid Ying-Ze Bao Min Sun Silvio Savarese Dept. of Electrical and Computer Engineering, University of Michigan at Ann Arbor, USA {yingze,sunmin,silvio}@eecs.umich.edu
Toward Coherent Object Detection And Scene Layout Understanding Sid Ying-Ze Bao Min Sun Silvio Savarese Dept. of Electrical and Computer Engineering, University of Michigan at Ann Arbor, USA {yingze,sunmin,silvio}@eecs.umich.edu
Scalable Cascade Inference for Semantic Image Segmentation
 STURGESS et al.: SCALABLE CASCADE INFERENCE 1 Scalable Cascade Inference for Semantic Image Segmentation Paul Sturgess 1 paul.sturgess@brookes.ac.uk L ubor Ladický 2 lubor@robots.ox.ac.uk Nigel Crook 1
STURGESS et al.: SCALABLE CASCADE INFERENCE 1 Scalable Cascade Inference for Semantic Image Segmentation Paul Sturgess 1 paul.sturgess@brookes.ac.uk L ubor Ladický 2 lubor@robots.ox.ac.uk Nigel Crook 1
A Hierarchical Conditional Random Field Model for Labeling and Segmenting Images of Street Scenes
 A Hierarchical Conditional Random Field Model for Labeling and Segmenting Images of Street Scenes Qixing Huang Stanford University huangqx@stanford.edu Mei Han Google Inc. meihan@google.com Bo Wu Google
A Hierarchical Conditional Random Field Model for Labeling and Segmenting Images of Street Scenes Qixing Huang Stanford University huangqx@stanford.edu Mei Han Google Inc. meihan@google.com Bo Wu Google
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.