High speed Integrated Circuit Hardware Description Language), RTL (Register transfer level). Abstract:
|
|
|
- Kenneth Terry
- 5 years ago
- Views:
Transcription
1 based implementation of 8-bit ALU of a RISC processor using Booth algorithm written in VHDL language Paresh Kumar Pasayat, Manoranjan Pradhan, Bhupesh Kumar Pasayat Abstract: This paper explains the design and implementation of 8-bit ALU (arithmetic and logic unit of a RISC processor that is implemented in Xilinx (Spartan-II device. The ALU takes two 8-bits s and performs different arithmetic and logic operations like addition, subtraction, multiplication, division, logical AND, OR, NAND, NOR, NOT, XOR, XNOR, INCREMENT, DECREMENT, ROTATE LEFT AND ROTATE RIGHT. The main focus of concern in this ALU is the multiplication operation using booth algorithm and bit-pair recording technique which increases the speed of multiplication operation. There can be s of ALU operations based on the values of the select lines. The top level design consists of arithmetic unit and logic unit which is implemented by using structural model. The different design steps such as VHDL source code, synthesis, simulation and the implementation for 8-bit ALU of the processor are presented in this thesis. The synthesis, simulation and implementation of 8-bit ALU of the processor are performed by using Xilinx software, Xilinx ISE in-bulit simulator and SPARTAN-II device (Xc2s200-6pq208. Index Terms- ALU (arithmetic and logic unit, (Field programmable gate arrays, VHDL (VHSIC HDL or Very High speed Integrated Circuit Hardware Description Language, RTL (Register transfer level. 1. INTRODUCTION The arithmetic and logic unit is very important block of the processor. The VHDL(very high speed integrated circuit hardware description language is used to design ALU of the processor. The ALU is implemented in SPARTAN-II device.the processor requires simple instruction sets, less addressing modes, and supports eight s of arithmetic and logical operations. The algorithm state model approach is used to represent around fifteen s of different states of controller of processor. The processor supports simple addressing modes like register addressing, register indirect addressing, immediate addressing etc. The processor is of register oriented architecture. It involves mainly register data transfer operations. There are less memory accesses to fetch opcodes and data from memory. So the speed and performance are comparatively higher. The paper is organized as follows: In section-2, based design method is discussed. Section-3 describes ALU architecture. The synthesis and simulation results are presented in section-4. Section
2 and Section-6 are the conclusion and references respectively. 2. DESIGN METHOD In classical method of design, a PCB(printed circuit board contains many of chips with other components. Development of these products starts with the definition of the overall structure. After that the required integrated circuit chips are selected followed by the PCBs that house and connect the chips together are designed. Since the complexity of circuits implemented on individual chips and on the circuit boards is usually very high, it is very much essential to make use of Xilinx software. The software performs the following tasks: As the size and complexity of digital systems increases, more and more CAD(computer aided design tools are being introduced in to the hardware design process. Design automation tools can help designer with design entry, hardware generation, and verification and design management. VHDL (very high speed integrated circuit hardware description language is used to describe hardware for the purpose of simulation, modeling testing, design and documentation of processor. (field programmable gate arrays provide the benefit of high integration levels and can be designed and verified quickly. devices are software configured and field programmable. Hence, there is a significant cost savings in design and productions. Design entry of the ALU of the processor is carried out by using VHDL code. Initial synthesis generates an initial circuit, based on data entered during the design entry stage. Functional simulation is done to verify the functionality of the circuit, based on inputs provided by the designer. Logic synthesis and optimization uses optimization techniques to derive optimized circuits. Physical design determines how to implement the optimized circuit in a chip.timing simulation determines the propagation delays that are expected in the implemented circuit. Chip configuration configures the actual chip to realize the designed circuit. 3. ARCHITECTURE The proposed 16-bit ALU of the RISC processor consists of one arithmetic unit and logic unit.using the concept of regularity, the arithmetic unit is divided into different blocks which perform the operations such as: addition, subtraction, multiplication, division. But, the main focus of concern in this arithmetic unit is the multiplier unit which has been implemented using Booth algorithm and bit pair recording techniques. The reason for choosing this technique is to increase the speed of 16-bit ALU. Similarly, the logic unit is also divided into various blocks which perform the operations such as: AND, OR, NAND, NOR, NOT, XOR, XNOR, INCREMENT, DECREMENT, ROTATE LEFT AND ROTATE RIGHT. 1387
3 Multiplier Unit: Architecture of multiplier unit of 16-bit ALU 16 BITS MULTIPLICAND 16 BITS MULTIPLIER RIPPLE CARRY ADDER BOOTH ENCODER * M * M * M Table 1: Truth table for the Booth Encoder Now let us take be the 8-bit multiplier. MULTIPLICATION RESULT Figure 1: Architecture of multiplier unit of 16-bit ALU The architecture for the multiplier unit is shown in Fig. 1.The 16-bit Multiplier unit consists of four components. They are the Booth Encoder, Partial Product Generator and the Adder units. The booth encoder is the first block of the 8- bit multiplier unit. It takes only one input i.e. 8-bit multiplier. This block reduces the of multiplier bits to half (i.e. 8-bit to 4-bit and generates the booth code signals which is used to encode the 16-bit multiplicand into the partial products.the booth encoder takes three bits of 16-bit multiplier at a time and based on certain logic, it generates booth code signals. The logic said above can best be explained with the help of a truth table which is given as follows: Y2 Y1 Y0 Version of the multiplicand(m selected at position i * M * M * M * M * M It is assumes that there is a bit 0 at the right hand side of LSB of the multiplier Partial Product Generator: The partial product generator is the second block of the 8-bit multiplier unit. The outputs of the booth encoder and the 8-bit multiplicand are fed to the inputs of the partial product generator. It consists of two stages: The booth encoder generates the booth code signals for encoding the 8-bit multiplicand into the partial products. Then, the partial product generator reads the booth code signals and encodes the multiplicand into the partial products. The partial product generator takes booth code signals and the 8-bit multiplicand as the inputs to it and performs certain operations to produce the four partial products or summands. The booth encoder generally takes the values which are 0, +1, +2, -1 and -2. Depending upon the values of booth code signals, the different operations are performed on the 8-bit multiplicand so as to produce the partial products. 1388
4 LOGIC 1: If the value of the booth code signal is zero, then the value of the partial product is zero. LOGIC 2: If the values of the booth code signal are +1 and +2, then the values of the partial products are same as the 8-bit multiplicand respectively. LOGIC 3: If the values of the booth code signal are -1 and -2, then the values of the partial products are the 2 s complement of the 8-bit multiplicand respectively. Explanation: Multiplier Multiplicand * pp pp pp pp = (14 16 In the above example, the partial products are generated depending upon the value of the booth code signals. The symbols pp1, pp2, pp3 and pp4 represent the desired partial products or summands. Then the partial products are added to get the multiplication result. If the addition of the partial product consists of any carry bits, then the carry bits are discarded. In the example given above, the carry bits are discarded. The result obtained after discarding the carry bits gives the desired multiplication result. Ripple Carry Adder: The ripple carry adder is the third block of the 8-bit multiplier unit. This unit takes the four partial products as the inputs and performs the addition operation on these partial products and gives the addition result which is the desired multiplication result. In the ripple carry adder, the corresponding bits of the two operands are added and the sum and carry results are obtained. The carry of the current addition of individual bits are added to the addition of next most significant bits of the operands. The sum bits are grouped together to give final sum. Suppose pp1, pp2, pp3 and pp4 are two partial products.let us take, pp1 = and pp2 = The two partial products are added in the following ways as shown below:
5 Similarly, the other two partial products pp3 and pp4 are added and the result is obtained. Finally, the two addition results are added using the ripple carry adder to give the final sum which is the desired multiplication result. Logic operations: The logic operations are most useful and advantageous operations which describes the logical behavior of the logic circuit. The input given to the circuit is in the form of binary format (i.e. 0 or 1 or combination of 0 and 1. The ALU can perform many types of logical operations such as logical and, or, nand, nor, not, xor, xnor, increment, decrement, rotate left and rotate right etc. Assignments in device: Input Bit num_a(0 num_a(1 num_a(2 num_a(3 num_a(4 num_a(5 num_a(6 num_a(7 numbe r P5 P6 P7 P8 P9 P10 P22 P21 Output Bit adder_result(0 adder_result(1 adder_result(2 adder_result(3 adder_result(4 adder_result(5 adder_result(6 adder_result(7 numbe r P46 P48 P57 P59 P61 P63 P68 P70 num_b(0 P20 adder_result(8 P47 Table 2: Numbers Assigned to input and output ports for Addition operation Input Bit numbe r P5 Output Bit numbe r P46 num_a(0 adder_result(0 num_a(1 P6 adder_result(1 P48 num_a(2 P7 adder_result(2 P57 num_a(3 P8 adder_result(3 P59 num_a(4 P9 adder_result(4 P61 num_a(5 P10 adder_result(5 P63 num_a(6 P22 adder_result(6 P68 num_a(7 P21 adder_result(7 P70 num_b(0 P20 adder_result(8 P47 Table 3: Numbers Assigned to input and output ports for Addition operation Input Bit Output Bit num_a(0 P5 Sub_result(0 P46 num_a(1 P6 Sub_result P48 (1 num_a(2 P7 Sub_result P57 (2 num_a(3 P8 Sub_result P59 (3 num_a(4 P9 Sub_result P61 (4 num_a(5 P10 Sub_result (5 P
6 num_a(6 P22 Sub_result P68 (6 num_a(7 P21 Sub_result (7 P70 Table 4: Numbers Assigned to input and output ports for Subtraction operation Input Bit Output Bit num_a(0 P5 product(0 P46 num_a(1 P6 product (1 P48 num_a(2 P7 product (2 P57 num_a(3 P8 product (3 P59 num_a(4 P9 product (4 P61 num_a(5 P10 product (5 P63 num_a(6 P22 product (6 P68 num_a(7 P21 product (7 P70 num_b(0 P20 product(8 P47 num_b(1 P18 product (9 P49 num_b(2 P17 product P58 (10 num_b(3 P16 product P60 (11 num_b(4 P15 product P62 (12 num_b(5 P14 product P67 (13 num_b(6 P23 product P69 (14 num_b(7 P24 product (15 P71 Table 5: Numbers Assigned to input and output ports for Multiplication Operation Input Bit Output Bit num_a(0 P5 quotient(0 P46 num_a(1 P6 quotient (1 P48 num_a(2 P7 quotient (2 P57 num_a(3 P8 quotient (3 P59 num_a(4 P9 quotient (4 P61 num_a(5 P10 quotient ( (5 P63 num_a(6 P22 quotient (6 P68 num_a(7 P21 quotient (7 P70 num_b(0 P20 remainder(0 P47 num_b(1 P18 remainder (1 num_b(2 P17 remainder (2 num_b(3 P16 remainder (3 num_b(4 P15 remainder (4 num_b(5 P14 remainder (5 num_b(6 P23 remainder (6 num_b(7 P24 remainder (7 P49 P58 P60 P62 P67 P69 P71 Table 6: Numbers Assigned to input and output ports for Division operation Input Bit Output Bit num_a(0 P5 log_result(0 P46 num_a(1 P6 log_result(1 P48 num_a(2 P7 log_result(2 P57 num_a(3 P8 log_result(3 P59 num_a(4 P9 log_result(4 P61 num_a(5 P10 log_result(5 P63 num_a(6 P22 log_result(6 P68 num_a(7 P21 log_result(7 P70 Table 7: Numbers Assigned to input and output ports for Logic operation 1391





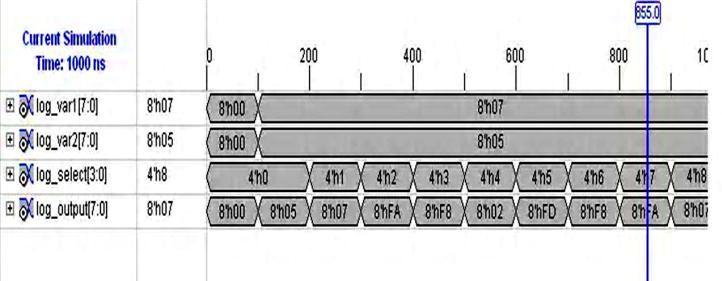

7 4. SIMULATION RESULTS AND COMPARISON: Figure 5: Simulation Result for Restoring Division Figure 2: Simulation Result for Booth Encoder Figure 3: Simulation Result for Partial Product Generator Figure 6: Simulation Result for Arithmetic Unit Figure 7: Simulation Result for Logic Unit Figure 4: Simulation Result for Partial Product Adder Figure 8: Simulation Result for 8-Bit Arithmetic and Logic Unit 1392
8 The maximum combinational path delays of booth multiplier and the normal multiplier are tabulated as follows: Type of multiplier Maximum combinational path delay (in ns Booth multiplier REFERENCES: [1] Mohamed Anane, Hamid Bessalah, Mohamed Issad, Nadjia Anane, and Hassen Salhi, Higher Radix and Redundancy Factor for Floating Point SRT Division IEEE Transactions on VLSI, Vol. 16, No. 6, June Normal multiplier Table 8: Comparison of maximum combinational path delays of booth multiplier and normal multiplier 5. CONCLUSION: This paper presented a new idea to design 8-bit ALU of a processor. This has been implemented in SPARTAN-II device. design offers greater design flexibility. The design is compact and is upgradable without any change in hardware. Here, the synthesis tool optimizes the design architecture of the for the ALU. Hence, additional features can be added to the existing design without any changes in hardware. The ALU is synthesized and simulated. The ALU of a processor is configured using each block designed. The main advantage of the proposed 8- bit ALU design is the achievement of increase in the speed of ALU operation so that the time consumption will be reduced. This is because of the fact that the proposed ALU performs the multiplication operation using booth algorithm and bit-pair recording technique which reduces the of multiplier bits to half (here 8-bit to 4-bit so that the of partial products generated will be reduced by a factor of 2 as compared to normal multiplication using general algorithm. Thus the time required to perform the addition of the partial products will be reduced to half so that the speed of multiplication will be enhanced. Therefore, the overall speed of the 8- bit ALU is increased. [2] M. Mottaghi-Dastjerdi, A. Afzali-Kusha, and M. Pedram, BZ-FAD: A Low-Power Low-Area Multiplier Based on IEEE Transactions on VLSI, 17, No. 2, February [3] Roberr K. Monto ye, University of Illinois, Urbana-Champaign, IL, THAM 11.1: Automatically Generated Area, Power and Delay Optimized ALUs, IEEE international conference on solid state circuits. [4] Mauro Olivieri, Design of Synchronous and Asynchronous Variable-Latency Pipelined Multipliers, IEEE Transaction on VLSI systems, pp , vol. 9, no.2,april, [5] Douglas L. Perry. VHDL Programming by Examples, TMH. [6] Hamacher, Vranesic, and Zaky. Computer Organization, 5th edition, New York: McGraw- Hill Companies. 1393
Prachi Sharma 1, Rama Laxmi 2, Arun Kumar Mishra 3 1 Student, 2,3 Assistant Professor, EC Department, Bhabha College of Engineering
 A Review: Design of 16 bit Arithmetic and Logical unit using Vivado 14.7 and Implementation on Basys 3 FPGA Board Prachi Sharma 1, Rama Laxmi 2, Arun Kumar Mishra 3 1 Student, 2,3 Assistant Professor,
A Review: Design of 16 bit Arithmetic and Logical unit using Vivado 14.7 and Implementation on Basys 3 FPGA Board Prachi Sharma 1, Rama Laxmi 2, Arun Kumar Mishra 3 1 Student, 2,3 Assistant Professor,
Week 7: Assignment Solutions
 Week 7: Assignment Solutions 1. In 6-bit 2 s complement representation, when we subtract the decimal number +6 from +3, the result (in binary) will be: a. 111101 b. 000011 c. 100011 d. 111110 Correct answer
Week 7: Assignment Solutions 1. In 6-bit 2 s complement representation, when we subtract the decimal number +6 from +3, the result (in binary) will be: a. 111101 b. 000011 c. 100011 d. 111110 Correct answer
CS/COE 0447 Example Problems for Exam 2 Spring 2011
 CS/COE 0447 Example Problems for Exam 2 Spring 2011 1) Show the steps to multiply the 4-bit numbers 3 and 5 with the fast shift-add multipler. Use the table below. List the multiplicand (M) and product
CS/COE 0447 Example Problems for Exam 2 Spring 2011 1) Show the steps to multiply the 4-bit numbers 3 and 5 with the fast shift-add multipler. Use the table below. List the multiplicand (M) and product
DC57 COMPUTER ORGANIZATION JUNE 2013
 Q2 (a) How do various factors like Hardware design, Instruction set, Compiler related to the performance of a computer? The most important measure of a computer is how quickly it can execute programs.
Q2 (a) How do various factors like Hardware design, Instruction set, Compiler related to the performance of a computer? The most important measure of a computer is how quickly it can execute programs.
ECE 341 Midterm Exam
 ECE 341 Midterm Exam Time allowed: 75 minutes Total Points: 75 Points Scored: Name: Problem No. 1 (8 points) For each of the following statements, indicate whether the statement is TRUE or FALSE: (a) A
ECE 341 Midterm Exam Time allowed: 75 minutes Total Points: 75 Points Scored: Name: Problem No. 1 (8 points) For each of the following statements, indicate whether the statement is TRUE or FALSE: (a) A
International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
 An Efficient Implementation of Double Precision Floating Point Multiplier Using Booth Algorithm Pallavi Ramteke 1, Dr. N. N. Mhala 2, Prof. P. R. Lakhe M.Tech [IV Sem], Dept. of Comm. Engg., S.D.C.E, [Selukate],
An Efficient Implementation of Double Precision Floating Point Multiplier Using Booth Algorithm Pallavi Ramteke 1, Dr. N. N. Mhala 2, Prof. P. R. Lakhe M.Tech [IV Sem], Dept. of Comm. Engg., S.D.C.E, [Selukate],
Area-Time Efficient Square Architecture
 AMSE JOURNALS 2015-Series: Advances D; Vol. 20; N 1; pp 21-34 Submitted March 2015; Revised Sept. 21, 2015; Accepted Oct. 15, 2015 Area-Time Efficient Square Architecture *Ranjan Kumar Barik, **Manoranjan
AMSE JOURNALS 2015-Series: Advances D; Vol. 20; N 1; pp 21-34 Submitted March 2015; Revised Sept. 21, 2015; Accepted Oct. 15, 2015 Area-Time Efficient Square Architecture *Ranjan Kumar Barik, **Manoranjan
Binary Adders. Ripple-Carry Adder
 Ripple-Carry Adder Binary Adders x n y n x y x y c n FA c n - c 2 FA c FA c s n MSB position Longest delay (Critical-path delay): d c(n) = n d carry = 2n gate delays d s(n-) = (n-) d carry +d sum = 2n
Ripple-Carry Adder Binary Adders x n y n x y x y c n FA c n - c 2 FA c FA c s n MSB position Longest delay (Critical-path delay): d c(n) = n d carry = 2n gate delays d s(n-) = (n-) d carry +d sum = 2n
Keywords: Soft Core Processor, Arithmetic and Logical Unit, Back End Implementation and Front End Implementation.
 ISSN 2319-8885 Vol.03,Issue.32 October-2014, Pages:6436-6440 www.ijsetr.com Design and Modeling of Arithmetic and Logical Unit with the Platform of VLSI N. AMRUTHA BINDU 1, M. SAILAJA 2 1 Dept of ECE,
ISSN 2319-8885 Vol.03,Issue.32 October-2014, Pages:6436-6440 www.ijsetr.com Design and Modeling of Arithmetic and Logical Unit with the Platform of VLSI N. AMRUTHA BINDU 1, M. SAILAJA 2 1 Dept of ECE,
VLSI Based 16 Bit ALU with Interfacing Circuit
 Available online at www.ijiere.com International Journal of Innovative and Emerging Research in Engineering e-issn: 2394-3343 p-issn: 2394-5494 VLSI Based 16 Bit ALU with Interfacing Circuit Chandni N.
Available online at www.ijiere.com International Journal of Innovative and Emerging Research in Engineering e-issn: 2394-3343 p-issn: 2394-5494 VLSI Based 16 Bit ALU with Interfacing Circuit Chandni N.
Computer Organisation CS303
 Computer Organisation CS303 Module Period Assignments 1 Day 1 to Day 6 1. Write a program to evaluate the arithmetic statement: X=(A-B + C * (D * E-F))/G + H*K a. Using a general register computer with
Computer Organisation CS303 Module Period Assignments 1 Day 1 to Day 6 1. Write a program to evaluate the arithmetic statement: X=(A-B + C * (D * E-F))/G + H*K a. Using a general register computer with
University, Patiala, Punjab, India 1 2
 1102 Design and Implementation of Efficient Adder based Floating Point Multiplier LOKESH BHARDWAJ 1, SAKSHI BAJAJ 2 1 Student, M.tech, VLSI, 2 Assistant Professor,Electronics and Communication Engineering
1102 Design and Implementation of Efficient Adder based Floating Point Multiplier LOKESH BHARDWAJ 1, SAKSHI BAJAJ 2 1 Student, M.tech, VLSI, 2 Assistant Professor,Electronics and Communication Engineering
32 bit Arithmetic Logical Unit (ALU) using VHDL
 using VHDL") 32 bit Arithmetic Logical Unit (ALU) using VHDL 1, Richa Singh Rathore 2 1 M. Tech Scholar, Department of ECE, Jayoti Vidyapeeth Women s University, Rajasthan, INDIA, dishamalik26@gmail.com 2 M. Tech Scholar,
32 bit Arithmetic Logical Unit (ALU) using VHDL 1, Richa Singh Rathore 2 1 M. Tech Scholar, Department of ECE, Jayoti Vidyapeeth Women s University, Rajasthan, INDIA, dishamalik26@gmail.com 2 M. Tech Scholar,
COMPUTER ARITHMETIC (Part 1)
") Eastern Mediterranean University School of Computing and Technology ITEC255 Computer Organization & Architecture COMPUTER ARITHMETIC (Part 1) Introduction The two principal concerns for computer arithmetic
Eastern Mediterranean University School of Computing and Technology ITEC255 Computer Organization & Architecture COMPUTER ARITHMETIC (Part 1) Introduction The two principal concerns for computer arithmetic
Chapter 4 Design of Function Specific Arithmetic Circuits
 Chapter 4 Design of Function Specific Arithmetic Circuits Contents Chapter 4... 55 4.1 Introduction:... 55 4.1.1 Incrementer/Decrementer Circuit...56 4.1.2 2 s Complement Circuit...56 4.1.3 Priority Encoder
Chapter 4 Design of Function Specific Arithmetic Circuits Contents Chapter 4... 55 4.1 Introduction:... 55 4.1.1 Incrementer/Decrementer Circuit...56 4.1.2 2 s Complement Circuit...56 4.1.3 Priority Encoder
ABSTRACT I. INTRODUCTION. 905 P a g e
 Design and Implements of Booth and Robertson s multipliers algorithm on FPGA Dr. Ravi Shankar Mishra Prof. Puran Gour Braj Bihari Soni Head of the Department Assistant professor M.Tech. scholar NRI IIST,
Design and Implements of Booth and Robertson s multipliers algorithm on FPGA Dr. Ravi Shankar Mishra Prof. Puran Gour Braj Bihari Soni Head of the Department Assistant professor M.Tech. scholar NRI IIST,
VARUN AGGARWAL
 ECE 645 PROJECT SPECIFICATION -------------- Design A Microprocessor Functional Unit Able To Perform Multiplication & Division Professor: Students: KRIS GAJ LUU PHAM VARUN AGGARWAL GMU Mar. 2002 CONTENTS
ECE 645 PROJECT SPECIFICATION -------------- Design A Microprocessor Functional Unit Able To Perform Multiplication & Division Professor: Students: KRIS GAJ LUU PHAM VARUN AGGARWAL GMU Mar. 2002 CONTENTS
Designing an Improved 64 Bit Arithmetic and Logical Unit for Digital Signaling Processing Purposes
 Available Online at- http://isroj.net/index.php/issue/current-issue ISROJ Index Copernicus Value for 2015: 49.25 Volume 02 Issue 01, 2017 e-issn- 2455 8818 Designing an Improved 64 Bit Arithmetic and Logical
Available Online at- http://isroj.net/index.php/issue/current-issue ISROJ Index Copernicus Value for 2015: 49.25 Volume 02 Issue 01, 2017 e-issn- 2455 8818 Designing an Improved 64 Bit Arithmetic and Logical
Simulation Results Analysis Of Basic And Modified RBSD Adder Circuits 1 Sobina Gujral, 2 Robina Gujral Bagga
 Simulation Results Analysis Of Basic And Modified RBSD Adder Circuits 1 Sobina Gujral, 2 Robina Gujral Bagga 1 Assistant Professor Department of Electronics and Communication, Chandigarh University, India
Simulation Results Analysis Of Basic And Modified RBSD Adder Circuits 1 Sobina Gujral, 2 Robina Gujral Bagga 1 Assistant Professor Department of Electronics and Communication, Chandigarh University, India
ARCHITECTURAL DESIGN OF 8 BIT FLOATING POINT MULTIPLICATION UNIT
 ARCHITECTURAL DESIGN OF 8 BIT FLOATING POINT MULTIPLICATION UNIT Usha S. 1 and Vijaya Kumar V. 2 1 VLSI Design, Sathyabama University, Chennai, India 2 Department of Electronics and Communication Engineering,
ARCHITECTURAL DESIGN OF 8 BIT FLOATING POINT MULTIPLICATION UNIT Usha S. 1 and Vijaya Kumar V. 2 1 VLSI Design, Sathyabama University, Chennai, India 2 Department of Electronics and Communication Engineering,
By, Ajinkya Karande Adarsh Yoga
 By, Ajinkya Karande Adarsh Yoga Introduction Early computer designers believed saving computer time and memory were more important than programmer time. Bug in the divide algorithm used in Intel chips.
By, Ajinkya Karande Adarsh Yoga Introduction Early computer designers believed saving computer time and memory were more important than programmer time. Bug in the divide algorithm used in Intel chips.
Area Efficient, Low Power Array Multiplier for Signed and Unsigned Number. Chapter 3
 Area Efficient, Low Power Array Multiplier for Signed and Unsigned Number Chapter 3 Area Efficient, Low Power Array Multiplier for Signed and Unsigned Number Chapter 3 3.1 Introduction The various sections
Area Efficient, Low Power Array Multiplier for Signed and Unsigned Number Chapter 3 Area Efficient, Low Power Array Multiplier for Signed and Unsigned Number Chapter 3 3.1 Introduction The various sections
An FPGA based Implementation of Floating-point Multiplier
 An FPGA based Implementation of Floating-point Multiplier L. Rajesh, Prashant.V. Joshi and Dr.S.S. Manvi Abstract In this paper we describe the parameterization, implementation and evaluation of floating-point
An FPGA based Implementation of Floating-point Multiplier L. Rajesh, Prashant.V. Joshi and Dr.S.S. Manvi Abstract In this paper we describe the parameterization, implementation and evaluation of floating-point
FPGA based Simulation of Clock Gated ALU Architecture with Multiplexed Logic Enable for Low Power Applications
 IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 04, 2015 ISSN (online): 2321-0613 FPGA based Simulation of Clock Gated ALU Architecture with Multiplexed Logic Enable for
IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 04, 2015 ISSN (online): 2321-0613 FPGA based Simulation of Clock Gated ALU Architecture with Multiplexed Logic Enable for
THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE
 THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE Design and Implementation of Optimized Floating Point Matrix Multiplier Based on FPGA Maruti L. Doddamani IV Semester, M.Tech (Digital Electronics), Department
THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE Design and Implementation of Optimized Floating Point Matrix Multiplier Based on FPGA Maruti L. Doddamani IV Semester, M.Tech (Digital Electronics), Department
Pipelined Quadratic Equation based Novel Multiplication Method for Cryptographic Applications
 , Vol 7(4S), 34 39, April 204 ISSN (Print): 0974-6846 ISSN (Online) : 0974-5645 Pipelined Quadratic Equation based Novel Multiplication Method for Cryptographic Applications B. Vignesh *, K. P. Sridhar
, Vol 7(4S), 34 39, April 204 ISSN (Print): 0974-6846 ISSN (Online) : 0974-5645 Pipelined Quadratic Equation based Novel Multiplication Method for Cryptographic Applications B. Vignesh *, K. P. Sridhar
Chapter 4 Arithmetic Functions
 Logic and Computer Design Fundamentals Chapter 4 Arithmetic Functions Charles Kime & Thomas Kaminski 2008 Pearson Education, Inc. (Hyperlinks are active in View Show mode) Overview Iterative combinational
Logic and Computer Design Fundamentals Chapter 4 Arithmetic Functions Charles Kime & Thomas Kaminski 2008 Pearson Education, Inc. (Hyperlinks are active in View Show mode) Overview Iterative combinational
DESIGN AND SIMULATION OF 1 BIT ARITHMETIC LOGIC UNIT DESIGN USING PASS-TRANSISTOR LOGIC FAMILIES
 Volume 120 No. 6 2018, 4453-4466 ISSN: 1314-3395 (on-line version) url: http://www.acadpubl.eu/hub/ http://www.acadpubl.eu/hub/ DESIGN AND SIMULATION OF 1 BIT ARITHMETIC LOGIC UNIT DESIGN USING PASS-TRANSISTOR
Volume 120 No. 6 2018, 4453-4466 ISSN: 1314-3395 (on-line version) url: http://www.acadpubl.eu/hub/ http://www.acadpubl.eu/hub/ DESIGN AND SIMULATION OF 1 BIT ARITHMETIC LOGIC UNIT DESIGN USING PASS-TRANSISTOR
Implementation of Low Power High Speed 32 bit ALU using FPGA
 Implementation of Low Power High Speed 32 bit ALU using FPGA J.P. Verma Assistant Professor (Department of Electronics & Communication Engineering) Maaz Arif; Brij Bhushan Choudhary& Nitish Kumar Electronics
Implementation of Low Power High Speed 32 bit ALU using FPGA J.P. Verma Assistant Professor (Department of Electronics & Communication Engineering) Maaz Arif; Brij Bhushan Choudhary& Nitish Kumar Electronics
VLSI Design Of a Novel Pre Encoding Multiplier Using DADDA Multiplier. Guntur(Dt),Pin:522017
,Pin:522017") VLSI Design Of a Novel Pre Encoding Multiplier Using DADDA Multiplier 1 Katakam Hemalatha,(M.Tech),Email Id: hema.spark2011@gmail.com 2 Kundurthi Ravi Kumar, M.Tech,Email Id: kundurthi.ravikumar@gmail.com
VLSI Design Of a Novel Pre Encoding Multiplier Using DADDA Multiplier 1 Katakam Hemalatha,(M.Tech),Email Id: hema.spark2011@gmail.com 2 Kundurthi Ravi Kumar, M.Tech,Email Id: kundurthi.ravikumar@gmail.com
Chapter 3: part 3 Binary Subtraction
 Chapter 3: part 3 Binary Subtraction Iterative combinational circuits Binary adders Half and full adders Ripple carry and carry lookahead adders Binary subtraction Binary adder-subtractors Signed binary
Chapter 3: part 3 Binary Subtraction Iterative combinational circuits Binary adders Half and full adders Ripple carry and carry lookahead adders Binary subtraction Binary adder-subtractors Signed binary
An Efficient Implementation of Floating Point Multiplier
 An Efficient Implementation of Floating Point Multiplier Mohamed Al-Ashrafy Mentor Graphics Mohamed_Samy@Mentor.com Ashraf Salem Mentor Graphics Ashraf_Salem@Mentor.com Wagdy Anis Communications and Electronics
An Efficient Implementation of Floating Point Multiplier Mohamed Al-Ashrafy Mentor Graphics Mohamed_Samy@Mentor.com Ashraf Salem Mentor Graphics Ashraf_Salem@Mentor.com Wagdy Anis Communications and Electronics
[Sahu* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116
![[Sahu* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116](/thumbs/86/94398605.jpg "[Sahu* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116") IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY SPAA AWARE ERROR TOLERANT 32 BIT ARITHMETIC AND LOGICAL UNIT FOR GRAPHICS PROCESSOR UNIT Kaushal Kumar Sahu*, Nitin Jain Department
IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY SPAA AWARE ERROR TOLERANT 32 BIT ARITHMETIC AND LOGICAL UNIT FOR GRAPHICS PROCESSOR UNIT Kaushal Kumar Sahu*, Nitin Jain Department
More complicated than addition. Let's look at 3 versions based on grade school algorithm (multiplicand) More time and more area
 More time and more area") Multiplication More complicated than addition accomplished via shifting and addition More time and more area Let's look at 3 versions based on grade school algorithm 01010010 (multiplicand) x01101101 (multiplier)
Multiplication More complicated than addition accomplished via shifting and addition More time and more area Let's look at 3 versions based on grade school algorithm 01010010 (multiplicand) x01101101 (multiplier)
DESIGN AND IMPLEMENTATION OF VLSI SYSTOLIC ARRAY MULTIPLIER FOR DSP APPLICATIONS
 International Journal of Computing Academic Research (IJCAR) ISSN 2305-9184 Volume 2, Number 4 (August 2013), pp. 140-146 MEACSE Publications http://www.meacse.org/ijcar DESIGN AND IMPLEMENTATION OF VLSI
International Journal of Computing Academic Research (IJCAR) ISSN 2305-9184 Volume 2, Number 4 (August 2013), pp. 140-146 MEACSE Publications http://www.meacse.org/ijcar DESIGN AND IMPLEMENTATION OF VLSI
Design, Analysis and Processing of Efficient RISC Processor
 Design, Analysis and Processing of Efficient RISC Processor Ramareddy 1, M.N.Pradeep 2 1M-Tech., VLSI D& Embedded Systems, Dept of E&CE, Dayananda Sagar College of Engineering, Bangalore. Karnataka, India
Design, Analysis and Processing of Efficient RISC Processor Ramareddy 1, M.N.Pradeep 2 1M-Tech., VLSI D& Embedded Systems, Dept of E&CE, Dayananda Sagar College of Engineering, Bangalore. Karnataka, India
Introduction to Digital Logic Missouri S&T University CPE 2210 Multipliers/Dividers
 Introduction to Digital Logic Missouri S&T University CPE 2210 Multipliers/Dividers Egemen K. Çetinkaya Egemen K. Çetinkaya Department of Electrical & Computer Engineering Missouri University of Science
Introduction to Digital Logic Missouri S&T University CPE 2210 Multipliers/Dividers Egemen K. Çetinkaya Egemen K. Çetinkaya Department of Electrical & Computer Engineering Missouri University of Science
Design & Analysis of 16 bit RISC Processor Using low Power Pipelining
 International OPEN ACCESS Journal ISSN: 2249-6645 Of Modern Engineering Research (IJMER) Design & Analysis of 16 bit RISC Processor Using low Power Pipelining Yedla Venkanna 148R1D5710 Branch: VLSI ABSTRACT:-
International OPEN ACCESS Journal ISSN: 2249-6645 Of Modern Engineering Research (IJMER) Design & Analysis of 16 bit RISC Processor Using low Power Pipelining Yedla Venkanna 148R1D5710 Branch: VLSI ABSTRACT:-
FPGA Implementation of MIPS RISC Processor
 FPGA Implementation of MIPS RISC Processor S. Suresh 1 and R. Ganesh 2 1 CVR College of Engineering/PG Student, Hyderabad, India 2 CVR College of Engineering/ECE Department, Hyderabad, India Abstract The
FPGA Implementation of MIPS RISC Processor S. Suresh 1 and R. Ganesh 2 1 CVR College of Engineering/PG Student, Hyderabad, India 2 CVR College of Engineering/ECE Department, Hyderabad, India Abstract The
IJRASET 2015: All Rights are Reserved
 Design High Speed Doubles Precision Floating Point Unit Using Verilog V.Venkaiah 1, K.Subramanyam 2, M.Tech Department of Electronics and communication Engineering Audisankara College of Engineering &
Design High Speed Doubles Precision Floating Point Unit Using Verilog V.Venkaiah 1, K.Subramanyam 2, M.Tech Department of Electronics and communication Engineering Audisankara College of Engineering &
Basic Arithmetic (adding and subtracting)
") Basic Arithmetic (adding and subtracting) Digital logic to show add/subtract Boolean algebra abstraction of physical, analog circuit behavior 1 0 CPU components ALU logic circuits logic gates transistors
Basic Arithmetic (adding and subtracting) Digital logic to show add/subtract Boolean algebra abstraction of physical, analog circuit behavior 1 0 CPU components ALU logic circuits logic gates transistors
COMPUTER ARCHITECTURE AND ORGANIZATION. Operation Add Magnitudes Subtract Magnitudes (+A) + ( B) + (A B) (B A) + (A B)
 + ( B) + (A B) (B A) + (A B)") Computer Arithmetic Data is manipulated by using the arithmetic instructions in digital computers. Data is manipulated to produce results necessary to give solution for the computation problems. The Addition,
Computer Arithmetic Data is manipulated by using the arithmetic instructions in digital computers. Data is manipulated to produce results necessary to give solution for the computation problems. The Addition,
VHDL IMPLEMENTATION OF FLOATING POINT MULTIPLIER USING VEDIC MATHEMATICS
 VHDL IMPLEMENTATION OF FLOATING POINT MULTIPLIER USING VEDIC MATHEMATICS I.V.VAIBHAV 1, K.V.SAICHARAN 1, B.SRAVANTHI 1, D.SRINIVASULU 2 1 Students of Department of ECE,SACET, Chirala, AP, India 2 Associate
VHDL IMPLEMENTATION OF FLOATING POINT MULTIPLIER USING VEDIC MATHEMATICS I.V.VAIBHAV 1, K.V.SAICHARAN 1, B.SRAVANTHI 1, D.SRINIVASULU 2 1 Students of Department of ECE,SACET, Chirala, AP, India 2 Associate
16 BIT IMPLEMENTATION OF ASYNCHRONOUS TWOS COMPLEMENT ARRAY MULTIPLIER USING MODIFIED BAUGH-WOOLEY ALGORITHM AND ARCHITECTURE.
 16 BIT IMPLEMENTATION OF ASYNCHRONOUS TWOS COMPLEMENT ARRAY MULTIPLIER USING MODIFIED BAUGH-WOOLEY ALGORITHM AND ARCHITECTURE. AditiPandey* Electronics & Communication,University Institute of Technology,
16 BIT IMPLEMENTATION OF ASYNCHRONOUS TWOS COMPLEMENT ARRAY MULTIPLIER USING MODIFIED BAUGH-WOOLEY ALGORITHM AND ARCHITECTURE. AditiPandey* Electronics & Communication,University Institute of Technology,
COMPUTER ARCHITECTURE AND ORGANIZATION Register Transfer and Micro-operations 1. Introduction A digital system is an interconnection of digital
 Register Transfer and Micro-operations 1. Introduction A digital system is an interconnection of digital hardware modules that accomplish a specific information-processing task. Digital systems vary in
Register Transfer and Micro-operations 1. Introduction A digital system is an interconnection of digital hardware modules that accomplish a specific information-processing task. Digital systems vary in
Embedded Soc using High Performance Arm Core Processor D.sridhar raja Assistant professor, Dept. of E&I, Bharath university, Chennai
 Embedded Soc using High Performance Arm Core Processor D.sridhar raja Assistant professor, Dept. of E&I, Bharath university, Chennai Abstract: ARM is one of the most licensed and thus widespread processor
Embedded Soc using High Performance Arm Core Processor D.sridhar raja Assistant professor, Dept. of E&I, Bharath university, Chennai Abstract: ARM is one of the most licensed and thus widespread processor
High Speed Special Function Unit for Graphics Processing Unit
 High Speed Special Function Unit for Graphics Processing Unit Abd-Elrahman G. Qoutb 1, Abdullah M. El-Gunidy 1, Mohammed F. Tolba 1, and Magdy A. El-Moursy 2 1 Electrical Engineering Department, Fayoum
High Speed Special Function Unit for Graphics Processing Unit Abd-Elrahman G. Qoutb 1, Abdullah M. El-Gunidy 1, Mohammed F. Tolba 1, and Magdy A. El-Moursy 2 1 Electrical Engineering Department, Fayoum
OPTIMIZATION OF AREA COMPLEXITY AND DELAY USING PRE-ENCODED NR4SD MULTIPLIER.
 OPTIMIZATION OF AREA COMPLEXITY AND DELAY USING PRE-ENCODED NR4SD MULTIPLIER. A.Anusha 1 R.Basavaraju 2 anusha201093@gmail.com 1 basava430@gmail.com 2 1 PG Scholar, VLSI, Bharath Institute of Engineering
OPTIMIZATION OF AREA COMPLEXITY AND DELAY USING PRE-ENCODED NR4SD MULTIPLIER. A.Anusha 1 R.Basavaraju 2 anusha201093@gmail.com 1 basava430@gmail.com 2 1 PG Scholar, VLSI, Bharath Institute of Engineering
VLSI for Multi-Technology Systems (Spring 2003)
") VLSI for Multi-Technology Systems (Spring 2003) Digital Project Due in Lecture Tuesday May 6th Fei Lu Ping Chen Electrical Engineering University of Cincinnati Abstract In this project, we realized the
VLSI for Multi-Technology Systems (Spring 2003) Digital Project Due in Lecture Tuesday May 6th Fei Lu Ping Chen Electrical Engineering University of Cincinnati Abstract In this project, we realized the
Implementation of Efficient Modified Booth Recoder for Fused Sum-Product Operator
 Implementation of Efficient Modified Booth Recoder for Fused Sum-Product Operator A.Sindhu 1, K.PriyaMeenakshi 2 PG Student [VLSI], Dept. of ECE, Muthayammal Engineering College, Rasipuram, Tamil Nadu,
Implementation of Efficient Modified Booth Recoder for Fused Sum-Product Operator A.Sindhu 1, K.PriyaMeenakshi 2 PG Student [VLSI], Dept. of ECE, Muthayammal Engineering College, Rasipuram, Tamil Nadu,
A Review of Various Adders for Fast ALU
 58 JEST-M, Vol 3, Issue 2, July-214 A Review of Various Adders for Fast ALU 1Assistnat Profrssor Department of Electronics and Communication, Chandigarh University 2Assistnat Profrssor Department of Electronics
58 JEST-M, Vol 3, Issue 2, July-214 A Review of Various Adders for Fast ALU 1Assistnat Profrssor Department of Electronics and Communication, Chandigarh University 2Assistnat Profrssor Department of Electronics
Institute of Engineering & Management
 Course:CS493- Computer Architecture Lab PROGRAMME: COMPUTERSCIENCE&ENGINEERING DEGREE:B. TECH COURSE: Computer Architecture Lab SEMESTER: 4 CREDITS: 2 COURSECODE: CS493 COURSE TYPE: Practical COURSE AREA/DOMAIN:
Course:CS493- Computer Architecture Lab PROGRAMME: COMPUTERSCIENCE&ENGINEERING DEGREE:B. TECH COURSE: Computer Architecture Lab SEMESTER: 4 CREDITS: 2 COURSECODE: CS493 COURSE TYPE: Practical COURSE AREA/DOMAIN:
REALIZATION OF AN 8-BIT PROCESSOR USING XILINX
 REALIZATION OF AN 8-BIT PROCESSOR USING XILINX T.Deepa M.E (Applied Electronics) Department of Electronics and Communication Engineering, Sri Venkateswara College of Engineering, Sriperumbudur, Chennai,
REALIZATION OF AN 8-BIT PROCESSOR USING XILINX T.Deepa M.E (Applied Electronics) Department of Electronics and Communication Engineering, Sri Venkateswara College of Engineering, Sriperumbudur, Chennai,
COMPUTER ORGANIZATION AND ARCHITECTURE
 COMPUTER ORGANIZATION AND ARCHITECTURE For COMPUTER SCIENCE COMPUTER ORGANIZATION. SYLLABUS AND ARCHITECTURE Machine instructions and addressing modes, ALU and data-path, CPU control design, Memory interface,
COMPUTER ORGANIZATION AND ARCHITECTURE For COMPUTER SCIENCE COMPUTER ORGANIZATION. SYLLABUS AND ARCHITECTURE Machine instructions and addressing modes, ALU and data-path, CPU control design, Memory interface,
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Arithmetic Unit 10122011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Fixed Point Arithmetic Addition/Subtraction
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Arithmetic Unit 10122011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Fixed Point Arithmetic Addition/Subtraction
Lecture Topics. Announcements. Today: Integer Arithmetic (P&H ) Next: The MIPS ISA (P&H ) Consulting hours. Milestone #1 (due 1/26)
 Next: The MIPS ISA (P&H ) Consulting hours. Milestone #1 (due 1/26)") Lecture Topics Today: Integer Arithmetic (P&H 3.1-3.4) Next: The MIPS ISA (P&H 2.1-2.14) 1 Announcements Consulting hours Milestone #1 (due 1/26) Milestone #2 (due 2/2) 2 1 Review: Integer Operations Internal
Lecture Topics Today: Integer Arithmetic (P&H 3.1-3.4) Next: The MIPS ISA (P&H 2.1-2.14) 1 Announcements Consulting hours Milestone #1 (due 1/26) Milestone #2 (due 2/2) 2 1 Review: Integer Operations Internal
Number Systems and Computer Arithmetic
 Number Systems and Computer Arithmetic Counting to four billion two fingers at a time What do all those bits mean now? bits (011011011100010...01) instruction R-format I-format... integer data number text
Number Systems and Computer Arithmetic Counting to four billion two fingers at a time What do all those bits mean now? bits (011011011100010...01) instruction R-format I-format... integer data number text
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 3. Arithmetic for Computers Implementation
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 3 Arithmetic for Computers Implementation Today Review representations (252/352 recap) Floating point Addition: Ripple
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 3 Arithmetic for Computers Implementation Today Review representations (252/352 recap) Floating point Addition: Ripple
OPTIMIZING THE POWER USING FUSED ADD MULTIPLIER
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
EC2303-COMPUTER ARCHITECTURE AND ORGANIZATION
 EC2303-COMPUTER ARCHITECTURE AND ORGANIZATION QUESTION BANK UNIT-II 1. What are the disadvantages in using a ripple carry adder? (NOV/DEC 2006) The main disadvantage using ripple carry adder is time delay.
EC2303-COMPUTER ARCHITECTURE AND ORGANIZATION QUESTION BANK UNIT-II 1. What are the disadvantages in using a ripple carry adder? (NOV/DEC 2006) The main disadvantage using ripple carry adder is time delay.
Chapter 2 Basic Logic Circuits and VHDL Description
 Chapter 2 Basic Logic Circuits and VHDL Description We cannot solve our problems with the same thinking we used when we created them. ----- Albert Einstein Like a C or C++ programmer don t apply the logic.
Chapter 2 Basic Logic Circuits and VHDL Description We cannot solve our problems with the same thinking we used when we created them. ----- Albert Einstein Like a C or C++ programmer don t apply the logic.
EE260: Logic Design, Spring n Integer multiplication. n Booth s algorithm. n Integer division. n Restoring, non-restoring
 EE 260: Introduction to Digital Design Arithmetic II Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Overview n Integer multiplication n Booth s algorithm n Integer division
EE 260: Introduction to Digital Design Arithmetic II Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Overview n Integer multiplication n Booth s algorithm n Integer division
Implementation and Comparative Analysis between Devices for Double Precision Interval Arithmetic Radix 4 Wallace tree Multiplication
 Implementation and Comparative Analysis between Devices for Double Precision Interval Arithmetic Radix 4 Wallace tree Multiplication Krutika Ranjankumar Bhagwat #1, Dr. Tejas V. Shah * 2, Prof. Deepali
Implementation and Comparative Analysis between Devices for Double Precision Interval Arithmetic Radix 4 Wallace tree Multiplication Krutika Ranjankumar Bhagwat #1, Dr. Tejas V. Shah * 2, Prof. Deepali
UNIT-III COMPUTER ARTHIMETIC
 UNIT-III COMPUTER ARTHIMETIC INTRODUCTION Arithmetic Instructions in digital computers manipulate data to produce results necessary for the of activity solution of computational problems. These instructions
UNIT-III COMPUTER ARTHIMETIC INTRODUCTION Arithmetic Instructions in digital computers manipulate data to produce results necessary for the of activity solution of computational problems. These instructions
VHDL Implementation of Arithmetic Logic Unit
 VHDL Implementation of Arithmetic Logic Unit 1 Saumyakanta Sarangi Associate Professor Electronics & Telecommunication Engg Eastern Academy of Science & Technology Bhubaneswar, India 2 Sangita Swain Associate
VHDL Implementation of Arithmetic Logic Unit 1 Saumyakanta Sarangi Associate Professor Electronics & Telecommunication Engg Eastern Academy of Science & Technology Bhubaneswar, India 2 Sangita Swain Associate
Design and Implementation of VLSI 8 Bit Systolic Array Multiplier
 Design and Implementation of VLSI 8 Bit Systolic Array Multiplier Khumanthem Devjit Singh, K. Jyothi MTech student (VLSI & ES), GIET, Rajahmundry, AP, India Associate Professor, Dept. of ECE, GIET, Rajahmundry,
Design and Implementation of VLSI 8 Bit Systolic Array Multiplier Khumanthem Devjit Singh, K. Jyothi MTech student (VLSI & ES), GIET, Rajahmundry, AP, India Associate Professor, Dept. of ECE, GIET, Rajahmundry,
Optimized Design and Implementation of a 16-bit Iterative Logarithmic Multiplier
 Optimized Design and Implementation a 16-bit Iterative Logarithmic Multiplier Laxmi Kosta 1, Jaspreet Hora 2, Rupa Tomaskar 3 1 Lecturer, Department Electronic & Telecommunication Engineering, RGCER, Nagpur,India,
Optimized Design and Implementation a 16-bit Iterative Logarithmic Multiplier Laxmi Kosta 1, Jaspreet Hora 2, Rupa Tomaskar 3 1 Lecturer, Department Electronic & Telecommunication Engineering, RGCER, Nagpur,India,
An Efficient Fused Add Multiplier With MWT Multiplier And Spanning Tree Adder
 An Efficient Fused Add Multiplier With MWT Multiplier And Spanning Tree Adder 1.M.Megha,M.Tech (VLSI&ES),2. Nataraj, M.Tech (VLSI&ES), Assistant Professor, 1,2. ECE Department,ST.MARY S College of Engineering
An Efficient Fused Add Multiplier With MWT Multiplier And Spanning Tree Adder 1.M.Megha,M.Tech (VLSI&ES),2. Nataraj, M.Tech (VLSI&ES), Assistant Professor, 1,2. ECE Department,ST.MARY S College of Engineering
COMP 303 Computer Architecture Lecture 6
 COMP 303 Computer Architecture Lecture 6 MULTIPLY (unsigned) Paper and pencil example (unsigned): Multiplicand 1000 = 8 Multiplier x 1001 = 9 1000 0000 0000 1000 Product 01001000 = 72 n bits x n bits =
COMP 303 Computer Architecture Lecture 6 MULTIPLY (unsigned) Paper and pencil example (unsigned): Multiplicand 1000 = 8 Multiplier x 1001 = 9 1000 0000 0000 1000 Product 01001000 = 72 n bits x n bits =
Von Neumann Architecture
 Von Neumann Architecture Assist lecturer Donya A. Khalid Lecture 2 2/29/27 Computer Organization Introduction In 945, just after the World War, Jon Von Neumann proposed to build a more flexible computer.
Von Neumann Architecture Assist lecturer Donya A. Khalid Lecture 2 2/29/27 Computer Organization Introduction In 945, just after the World War, Jon Von Neumann proposed to build a more flexible computer.
Chapter 5 : Computer Arithmetic
 Chapter 5 Computer Arithmetic Integer Representation: (Fixedpoint representation): An eight bit word can be represented the numbers from zero to 255 including = 1 = 1 11111111 = 255 In general if an nbit
Chapter 5 Computer Arithmetic Integer Representation: (Fixedpoint representation): An eight bit word can be represented the numbers from zero to 255 including = 1 = 1 11111111 = 255 In general if an nbit
A High Performance Reconfigurable Data Path Architecture For Flexible Accelerator
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 7, Issue 4, Ver. II (Jul. - Aug. 2017), PP 07-18 e-issn: 2319 4200, p-issn No. : 2319 4197 www.iosrjournals.org A High Performance Reconfigurable
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 7, Issue 4, Ver. II (Jul. - Aug. 2017), PP 07-18 e-issn: 2319 4200, p-issn No. : 2319 4197 www.iosrjournals.org A High Performance Reconfigurable
REALIZATION OF MULTIPLE- OPERAND ADDER-SUBTRACTOR BASED ON VEDIC MATHEMATICS
 REALIZATION OF MULTIPLE- OPERAND ADDER-SUBTRACTOR BASED ON VEDIC MATHEMATICS NEETA PANDEY 1, RAJESHWARI PANDEY 2, SAMIKSHA AGARWAL 3, PRINCE KUMAR 4 Department of Electronics and Communication Engineering
REALIZATION OF MULTIPLE- OPERAND ADDER-SUBTRACTOR BASED ON VEDIC MATHEMATICS NEETA PANDEY 1, RAJESHWARI PANDEY 2, SAMIKSHA AGARWAL 3, PRINCE KUMAR 4 Department of Electronics and Communication Engineering
Implementation of IEEE754 Floating Point Multiplier
 Implementation of IEEE754 Floating Point Multiplier A Kumutha 1 Shobha. P 2 1 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67. 2 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67.
Implementation of IEEE754 Floating Point Multiplier A Kumutha 1 Shobha. P 2 1 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67. 2 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67.
Implimentation of A 16-bit RISC Processor for Convolution Application
 Advance in Electronic and Electric Engineering. ISSN 2231-1297, Volume 4, Number 5 (2014), pp. 441-446 Research India Publications http://www.ripublication.com/aeee.htm Implimentation of A 16-bit RISC
Advance in Electronic and Electric Engineering. ISSN 2231-1297, Volume 4, Number 5 (2014), pp. 441-446 Research India Publications http://www.ripublication.com/aeee.htm Implimentation of A 16-bit RISC
Implementation of Floating Point Multiplier Using Dadda Algorithm
 Implementation of Floating Point Multiplier Using Dadda Algorithm Abstract: Floating point multiplication is the most usefull in all the computation application like in Arithematic operation, DSP application.
Implementation of Floating Point Multiplier Using Dadda Algorithm Abstract: Floating point multiplication is the most usefull in all the computation application like in Arithematic operation, DSP application.
ECEN 468 Advanced Logic Design
 ECEN 468 Advanced Logic Design Lecture 26: Verilog Operators ECEN 468 Lecture 26 Operators Operator Number of Operands Result Arithmetic 2 Binary word Bitwise 2 Binary word Reduction 1 Bit Logical 2 Boolean
ECEN 468 Advanced Logic Design Lecture 26: Verilog Operators ECEN 468 Lecture 26 Operators Operator Number of Operands Result Arithmetic 2 Binary word Bitwise 2 Binary word Reduction 1 Bit Logical 2 Boolean
A Review on Optimizing Efficiency of Fixed Point Multiplication using Modified Booth s Algorithm
 A Review on Optimizing Efficiency of Fixed Point Multiplication using Modified Booth s Algorithm Mahendra R. Bhongade, Manas M. Ramteke, Vijay G. Roy Author Details Mahendra R. Bhongade, Department of
A Review on Optimizing Efficiency of Fixed Point Multiplication using Modified Booth s Algorithm Mahendra R. Bhongade, Manas M. Ramteke, Vijay G. Roy Author Details Mahendra R. Bhongade, Department of
Design and Implementation of IEEE-754 Decimal Floating Point Adder, Subtractor and Multiplier
 International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 8958, Volume-4 Issue 1, October 2014 Design and Implementation of IEEE-754 Decimal Floating Point Adder, Subtractor and Multiplier
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 8958, Volume-4 Issue 1, October 2014 Design and Implementation of IEEE-754 Decimal Floating Point Adder, Subtractor and Multiplier
PESIT Bangalore South Campus
 INTERNAL ASSESSMENT TEST III Date : 21/11/2017 Max Marks : 40 Subject & Code : Computer Organization (15CS34) Semester : III (A & B) Name of the faculty: Mrs. Sharmila Banu Time : 11.30 am 1.00 pm Answer
INTERNAL ASSESSMENT TEST III Date : 21/11/2017 Max Marks : 40 Subject & Code : Computer Organization (15CS34) Semester : III (A & B) Name of the faculty: Mrs. Sharmila Banu Time : 11.30 am 1.00 pm Answer
For Example: P: LOAD 5 R0. The command given here is used to load a data 5 to the register R0.
 Register Transfer Language Computers are the electronic devices which have several sets of digital hardware which are inter connected to exchange data. Digital hardware comprises of VLSI Chips which are
Register Transfer Language Computers are the electronic devices which have several sets of digital hardware which are inter connected to exchange data. Digital hardware comprises of VLSI Chips which are
MaanavaN.Com CS1202 COMPUTER ARCHITECHTURE
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK SUB CODE / SUBJECT: CS1202/COMPUTER ARCHITECHTURE YEAR / SEM: II / III UNIT I BASIC STRUCTURE OF COMPUTER 1. What is meant by the stored program
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK SUB CODE / SUBJECT: CS1202/COMPUTER ARCHITECHTURE YEAR / SEM: II / III UNIT I BASIC STRUCTURE OF COMPUTER 1. What is meant by the stored program
VLSI DESIGN (ELECTIVE-I) Question Bank Unit I
 Question Bank Unit I") VLSI DESIGN (ELECTIVE-I) Question Bank Unit I B.E (E&C) NOV-DEC 2008 1) If A & B are two unsigned variables, with A = 1100 and B = 1001, find the values of following expressions. i. (A and B) ii. (A ^
VLSI DESIGN (ELECTIVE-I) Question Bank Unit I B.E (E&C) NOV-DEC 2008 1) If A & B are two unsigned variables, with A = 1100 and B = 1001, find the values of following expressions. i. (A and B) ii. (A ^
EXPERIMENT #8: BINARY ARITHMETIC OPERATIONS
 EE 2 Lab Manual, EE Department, KFUPM EXPERIMENT #8: BINARY ARITHMETIC OPERATIONS OBJECTIVES: Design and implement a circuit that performs basic binary arithmetic operations such as addition, subtraction,
EE 2 Lab Manual, EE Department, KFUPM EXPERIMENT #8: BINARY ARITHMETIC OPERATIONS OBJECTIVES: Design and implement a circuit that performs basic binary arithmetic operations such as addition, subtraction,
Module 2: Computer Arithmetic
 Module 2: Computer Arithmetic 1 B O O K : C O M P U T E R O R G A N I Z A T I O N A N D D E S I G N, 3 E D, D A V I D L. P A T T E R S O N A N D J O H N L. H A N N E S S Y, M O R G A N K A U F M A N N
Module 2: Computer Arithmetic 1 B O O K : C O M P U T E R O R G A N I Z A T I O N A N D D E S I G N, 3 E D, D A V I D L. P A T T E R S O N A N D J O H N L. H A N N E S S Y, M O R G A N K A U F M A N N
Arithmetic Operators There are two types of operators: binary and unary Binary operators:
 Verilog operators operate on several data types to produce an output Not all Verilog operators are synthesible (can produce gates) Some operators are similar to those in the C language Remember, you are
Verilog operators operate on several data types to produce an output Not all Verilog operators are synthesible (can produce gates) Some operators are similar to those in the C language Remember, you are
UPY14602-DIGITAL ELECTRONICS AND MICROPROCESSORS Lesson Plan
 UPY14602-DIGITAL ELECTRONICS AND MICROPROCESSORS Lesson Plan UNIT I - NUMBER SYSTEMS AND LOGIC GATES Introduction to decimal- Binary- Octal- Hexadecimal number systems-inter conversions-bcd code- Excess
UPY14602-DIGITAL ELECTRONICS AND MICROPROCESSORS Lesson Plan UNIT I - NUMBER SYSTEMS AND LOGIC GATES Introduction to decimal- Binary- Octal- Hexadecimal number systems-inter conversions-bcd code- Excess
Lecture 3: Modeling in VHDL. EE 3610 Digital Systems
 EE 3610: Digital Systems 1 Lecture 3: Modeling in VHDL VHDL: Overview 2 VHDL VHSIC Hardware Description Language VHSIC=Very High Speed Integrated Circuit Programming language for modelling of hardware
EE 3610: Digital Systems 1 Lecture 3: Modeling in VHDL VHDL: Overview 2 VHDL VHSIC Hardware Description Language VHSIC=Very High Speed Integrated Circuit Programming language for modelling of hardware
ECE 30 Introduction to Computer Engineering
 ECE 30 Introduction to Computer Engineering Study Problems, Set #6 Spring 2015 1. With x = 1111 1111 1111 1111 1011 0011 0101 0011 2 and y = 0000 0000 0000 0000 0000 0010 1101 0111 2 representing two s
ECE 30 Introduction to Computer Engineering Study Problems, Set #6 Spring 2015 1. With x = 1111 1111 1111 1111 1011 0011 0101 0011 2 and y = 0000 0000 0000 0000 0000 0010 1101 0111 2 representing two s
Tailoring the 32-Bit ALU to MIPS
 Tailoring the 32-Bit ALU to MIPS MIPS ALU extensions Overflow detection: Carry into MSB XOR Carry out of MSB Branch instructions Shift instructions Slt instruction Immediate instructions ALU performance
Tailoring the 32-Bit ALU to MIPS MIPS ALU extensions Overflow detection: Carry into MSB XOR Carry out of MSB Branch instructions Shift instructions Slt instruction Immediate instructions ALU performance
VLSI Implementation of Adders for High Speed ALU
 VLSI Implementation of Adders for High Speed ALU Prashant Gurjar Rashmi Solanki Pooja Kansliwal Mahendra Vucha Asst. Prof., Dept. EC,, ABSTRACT This paper is primarily deals the construction of high speed
VLSI Implementation of Adders for High Speed ALU Prashant Gurjar Rashmi Solanki Pooja Kansliwal Mahendra Vucha Asst. Prof., Dept. EC,, ABSTRACT This paper is primarily deals the construction of high speed
A Novel Design of 32 Bit Unsigned Multiplier Using Modified CSLA
 A Novel Design of 32 Bit Unsigned Multiplier Using Modified CSLA Chandana Pittala 1, Devadas Matta 2 PG Scholar.VLSI System Design 1, Asst. Prof. ECE Dept. 2, Vaagdevi College of Engineering,Warangal,India.
A Novel Design of 32 Bit Unsigned Multiplier Using Modified CSLA Chandana Pittala 1, Devadas Matta 2 PG Scholar.VLSI System Design 1, Asst. Prof. ECE Dept. 2, Vaagdevi College of Engineering,Warangal,India.
VTU NOTES QUESTION PAPERS NEWS RESULTS FORUMS Arithmetic (a) The four possible cases Carry (b) Truth table x y
 The four possible cases Carry (b) Truth table x y") Arithmetic A basic operation in all digital computers is the addition and subtraction of two numbers They are implemented, along with the basic logic functions such as AND,OR, NOT,EX- OR in the ALU subsystem
Arithmetic A basic operation in all digital computers is the addition and subtraction of two numbers They are implemented, along with the basic logic functions such as AND,OR, NOT,EX- OR in the ALU subsystem
Arithmetic Circuits. Design of Digital Circuits 2014 Srdjan Capkun Frank K. Gürkaynak.
 Arithmetic Circuits Design of Digital Circuits 2014 Srdjan Capkun Frank K. Gürkaynak http://www.syssec.ethz.ch/education/digitaltechnik_14 Adapted from Digital Design and Computer Architecture, David Money
Arithmetic Circuits Design of Digital Circuits 2014 Srdjan Capkun Frank K. Gürkaynak http://www.syssec.ethz.ch/education/digitaltechnik_14 Adapted from Digital Design and Computer Architecture, David Money
Introduction to Computer Science. Homework 1
 Introduction to Computer Science Homework. In each circuit below, the rectangles represent the same type of gate. Based on the input and output information given, identify whether the gate involved is
Introduction to Computer Science Homework. In each circuit below, the rectangles represent the same type of gate. Based on the input and output information given, identify whether the gate involved is
JOURNAL OF INTERNATIONAL ACADEMIC RESEARCH FOR MULTIDISCIPLINARY Impact Factor 1.393, ISSN: , Volume 2, Issue 7, August 2014
 DESIGN OF HIGH SPEED BOOTH ENCODED MULTIPLIER PRAVEENA KAKARLA* *Assistant Professor, Dept. of ECONE, Sree Vidyanikethan Engineering College, A.P., India ABSTRACT This paper presents the design and implementation
DESIGN OF HIGH SPEED BOOTH ENCODED MULTIPLIER PRAVEENA KAKARLA* *Assistant Professor, Dept. of ECONE, Sree Vidyanikethan Engineering College, A.P., India ABSTRACT This paper presents the design and implementation
s complement 1-bit Booth s 2-bit Booth s
 ECE/CS 552 : Introduction to Computer Architecture FINAL EXAM May 12th, 2002 NAME: This exam is to be done individually. Total 6 Questions, 100 points Show all your work to receive partial credit for incorrect
ECE/CS 552 : Introduction to Computer Architecture FINAL EXAM May 12th, 2002 NAME: This exam is to be done individually. Total 6 Questions, 100 points Show all your work to receive partial credit for incorrect
Timing for Ripple Carry Adder
 Timing for Ripple Carry Adder 1 2 3 Look Ahead Method 5 6 7 8 9 Look-Ahead, bits wide 10 11 Multiplication Simple Gradeschool Algorithm for 32 Bits (6 Bit Result) Multiplier Multiplicand AND gates 32
Timing for Ripple Carry Adder 1 2 3 Look Ahead Method 5 6 7 8 9 Look-Ahead, bits wide 10 11 Multiplication Simple Gradeschool Algorithm for 32 Bits (6 Bit Result) Multiplier Multiplicand AND gates 32
IMPLEMENTATION OF TWIN PRECISION TECHNIQUE FOR MULTIPLICATION
 IMPLEMENTATION OF TWIN PRECISION TECHNIQUE FOR MULTIPLICATION SUNITH KUMAR BANDI #1, M.VINODH KUMAR *2 # ECE department, M.V.G.R College of Engineering, Vizianagaram, Andhra Pradesh, INDIA. 1 sunithjc@gmail.com
IMPLEMENTATION OF TWIN PRECISION TECHNIQUE FOR MULTIPLICATION SUNITH KUMAR BANDI #1, M.VINODH KUMAR *2 # ECE department, M.V.G.R College of Engineering, Vizianagaram, Andhra Pradesh, INDIA. 1 sunithjc@gmail.com
Lecture #21 March 31, 2004 Introduction to Gates and Circuits
 Lecture #21 March 31, 2004 Introduction to Gates and Circuits To this point we have looked at computers strictly from the perspective of assembly language programming. While it is possible to go a great
Lecture #21 March 31, 2004 Introduction to Gates and Circuits To this point we have looked at computers strictly from the perspective of assembly language programming. While it is possible to go a great