Programming NVM Systems
|
|
|
- Alexandra Edwards
- 5 years ago
- Views:
Transcription




1 Programming NVM Systems Random Access Talk Jeffrey S. Vetter Seyong Lee, Joel Denny, Jungwon Kim, et al. Presented to Salishan Conference on High Speed Computing Gleneden Beach, Oregon 27 Apr 2016 ORNL is managed by UT-Battelle for the US Department of Energy
2 Executive Summary Architectures are growing more complex This will get worse; not better Programming systems must provide performance portability (in addition to functional portability)!! Programming NVM systems is the next major challenge 2
3 Exascale architecture targets circa Exascale Challenges Workshop in San Diego Attendees envisioned two possible architectural swim lanes: 1. Homogeneous many-core thin-node system 2. Heterogeneous (accelerator + CPU) fat-node system System attributes 2009 Pre-Exascale Exascale System peak 2 PF PF/s 1 Exaflop/s Power 6 MW 15 MW 20 MW System memory 0.3 PB 5 PB PB Storage 15 PB 150 PB 500 PB Node performance 125 GF 0.5 TF 7 TF 1 TF 10 TF Node memory BW 25 GB/s 0.1 TB/s 1 TB/s 0.4 TB/s 4 TB/s Node concurrency 12 O(100) O(1,000) O(1,000) O(10,000) System size (nodes) 18, ,000 50,000 1,000, ,000 Node interconnect BW 1.5 GB/s 150 GB/s 1 TB/s 250 GB/s 2 TB/s IO Bandwidth 0.2 TB/s 10 TB/s TB/s MTTI day O(1 day) O(0.1 day) 3
 2.6 27 10 > 30 150 >8.5 180 Peak Power (MW) 2 9 4.8 < 3.7 10 1.7 13 Total system memory 357 TB 710TB 768TB ~1 PB DDR4 + High Bandwidth Memory (HBM)+1.")
4 Current ASCR Computing At a Glance System attributes NERSC Now OLCF Now ALCF Now Planned Installation Edison TITAN MIRA NERSC Upgrade OLCF Upgrade ALCF Upgrades Cori 2016 Summit Theta 2016 Aurora System peak (PF) > > Peak Power (MW) < Total system memory 357 TB 710TB 768TB ~1 PB DDR4 + High Bandwidth Memory (HBM)+1.5PB persistent memory > 1.74 PB DDR4 + HBM PB persistent memory >480 TB DDR4 + High Bandwidth Memory (HBM) > 7 PB High Bandwidth On-Package Memory Local Memory and Persistent Memory Node performance (TF) > 3 > 40 > 3 > 17 times Mira Node processors Intel Ivy Bridge AMD Opteron Nvidia Kepler 64-bit PowerPC A2 Intel Knights Landing many core CPUs Intel Haswell CPU in data partition Multiple IBM Power9 CPUs & multiple Nvidia Voltas GPUS Intel Knights Landing Xeon Phi many core CPUs Knights Hill Xeon Phi many core CPUs System size (nodes) 5,600 nodes 18,688 nodes 49,152 9,300 nodes 1,900 nodes in data partition ~3,500 nodes >2,500 nodes >50,000 nodes System Interconnect Aries Gemini 5D Torus Aries Dual Rail EDR-IB Aries 2 nd Generation Intel Omni-Path Architecture File System 7.6 PB 168 GB/s, Lustre 32 PB 1 TB/s, Lustre 26 PB 300 GB/s GPFS 28 PB 744 GB/s Lustre 120 PB 1 TB/s GPFS 10PB, 210 GB/s Lustre initial 150 PB 1 TB/s Lustre 4 Complexity α T
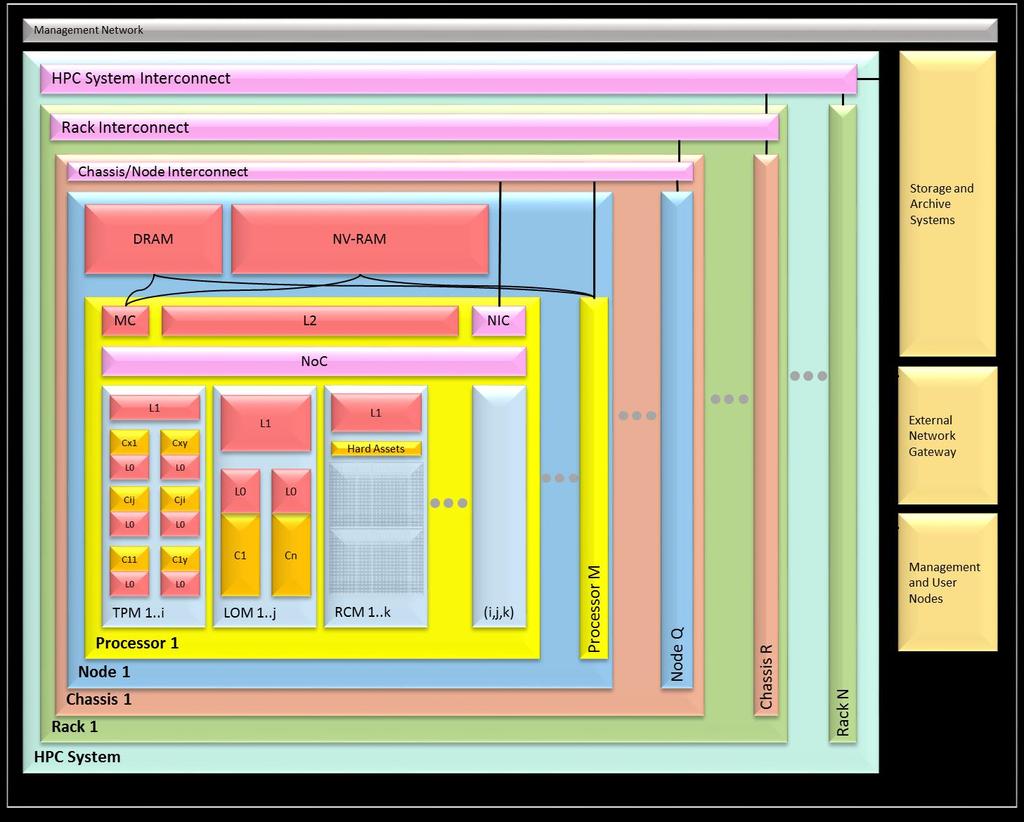
5 5




:73-82, 2015. 6 H.S.P. Wong, H.Y.")
6 Memory Systems are Diversifying HMC, HBM/2/3, LPDDR4, GDDR5X, WIDEIO2, etc 2.5D, 3D Stacking New devices (ReRAM, PCRAM, STT- MRAM, Xpoint) Configuration diversity Fused, shared memory Scratchpads Write through, write back, etc Consistency and coherence protocols Virtual v. Physical, paging strategies J.S. Vetter and S. Mittal, Opportunities for Nonvolatile Memory Systems in Extreme-Scale High Performance Computing, CiSE, 17(2):73-82, H.S.P. Wong, H.Y. Lee, S. Yu et al., Metal-oxide RRAM, Proceedings of the IEEE, 100(6): ,







7 NVRAM Technology Continues to Improve Driven by Market Forces 7
8 Jeffrey Vetter, ORNL Comparison of Emerging Memory Robert Schreiber, HP Labs Trevor Mudge, University of Michigan Yuan Xie, Penn State University Technologies SRAM DRAM edram 2D NAND Flash 3D NAND Flash PCRAM STTRAM 2D ReRAM Data Retention N N N Y Y Y Y Y Y Cell Size (F 2 ) < <1 Minimum F demonstrated (nm) 3D ReRAM Read Time (ns) < Write Time (ns) < Number of Rewrites Read Power Low Low Low High High Low Medium Medium Medium Write Power Low Low Low High High High Medium Medium Medium Power (other than R/W) Leakage Refresh Refresh None None None None Sneak Sneak Maturity Intel/Micron Xpoint? 8


9 As NVM improves, it is working its way toward the processor core Caches Main Memory I/O Device HDD Newer technologies improve density, power usage, durability r/w performance In scalable systems, a variety of architectures exist NVM in the SAN NVM nodes in system NVM in each node 9

:73-82, 2015, 10.")
10 Opportunities for NVM in Emerging Systems Burst Buffers, C/R [Liu, et al., MSST 2012] In situ visualization In-mem tables 10 J.S. Vetter and S. Mittal, Opportunities for Nonvolatile Memory Systems in Extreme-Scale High- Performance Computing, Computing in Science & Engineering, 17(2):73-82, 2015, /MCSE
11 Programming NVM Systems

12 Design Goals for NVM Programming Systems Active area of research See survey Architectures will vary dramatically How should we design the node? Portable across various NVM architectures Performance for HPC scenarios Allow user or compiler/runtime/os to exploit NVM Asymmetric R/W Remote/Local Security Assume lower power costs under normal usage MPI and OpenMP do not solve this problem. Correctness and durability Enhanced ECC for NVM devices A crash or erroneous program could corrupt the NVM data structures Programming system needs to provide support for this model ACID Atomicity: A transaction is all or nothing Consistency: Takes data from one consistent state to another Isolation: Concurrent transactions appears to be one after another Durability: Changes to data will remain across system boots 12
13 Ideally, NVM would hold data indefinitely Large grids, tables, KV stores, etc would remain in the NVM (similar to a filesystem) A crash or erroneous program could corrupt the NVM data structures Programming system needs to provide support for this model ACID Atomicity: A transaction is all or nothing Consistency: Takes data from one consistent state to another Isolation: Concurrent transactions appears to be one after another Durability: Changes to data will remain across system boots 13










14 OpenARC Compiler OpenARC Runtime OpenACC OpenMP 4 NVL-C Input C Programs OpenARC Front-End C Parser Directive Parser OpenARC Back-End Kernels & Host Program Generator Device Specific Optimizer Feedback Output Codes Kernels for Target Devices Host Program Run CUDA, OpenCL Libraries HeteroIR Common Runtime with Tuning Engine LLVM Back-End Extended LLVM IR Generator NVL Passes Standard LLVM Passes Preprocessor General Optimizer OpenARC IR Tuning Configuration Generator Search Space Pruner OpenARC Auto-Tuner CUDA GPU NVM Run AMD GPU NVM Executable Xeon Phi NVM NVL Runtime Altera FPGA NVM pmem.io NVM Library Vetter, 27 Apr 2016
15 NVL-C: Portable Programming for NVMM Minimal, familiar, programming interface: Minimal C language extensions. App can still use DRAM. Pointer safety: Persistence creates new categories of pointer bugs. Best to enforce pointer safety constraints at compile time rather than run time. Transactions: Prevent corruption of persistent memory in case of application or system failure. Language extensions enable: Compile-time safety constraints. NVM-related compiler analyses and optimizations. LLVM-based: Core of compiler can be reused for other front ends and languages. Can take advantage of LLVM ecosystem. #include <nvl.h> struct list { int value; nvl struct list *next; }; void remove(int k) { nvl_heap_t *heap = nvl_open("foo.nvl"); nvl struct list *a = nvl_get_root(heap, struct list); #pragma nvl atomic while (a->next!= NULL) { if (a->next->value == k) a->next = a->next->next; else a = a->next; } nvl_close(heap); } 15 J. Denny, S. Lee, and J.S. Vetter, NVL-C: Static Analysis Techniques for Efficient, Correct Programming of Non-Volatile Main Memory Systems, in ACM High Performance Distributed Computing (HPDC). Kyoto: ACM, 2016



16 Preliminary Results Applications extended with NVL-C Compiled with NVL-C Executed on Fusion ioscale Compared to DRAM Various levels of optimization LULESH XSBENCH 16


17 PMES SC16 Position papers due June 17 17
18 Summary 18 Recent trends in extreme-scale HPC paint an ambiguous future Contemporary systems provide evidence that power constraints are driving architectures to change rapidly Multiple architectural dimensions are being (dramatically) redesigned: Processors, node design, memory systems, I/O Complexity is our main challenge Applications and software systems are all reaching a state of crisis Applications will not be functionally or performance portable across architectures Programming and operating systems need major redesign to address these architectural changes Procurements, acceptance testing, and operations of today s new platforms depend on performance prediction and benchmarking. We need performance portable programming models now more than ever! Programming systems must provide performance portability (in addition to functional portability)!! New memory hierarchies with NVM everywhere Heterogeneous systems


19 Acknowledgements Contributors and Sponsors Future Technologies Group: US Department of Energy Office of Science DOE Vancouver Project: DOE Blackcomb Project: DOE ExMatEx Codesign Center: DOE Cesar Codesign Center: DOE Exascale Efforts: mputer-science/ Scalable Heterogeneous Computing Benchmark team: US National Science Foundation Keeneland Project: US DARPA NVIDIA CUDA Center of Excellence 19
20 Bonus Material
Exploring Emerging Technologies in the Extreme Scale HPC Co- Design Space with Aspen
 Exploring Emerging Technologies in the Extreme Scale HPC Co- Design Space with Aspen Jeffrey S. Vetter SPPEXA Symposium Munich 26 Jan 2016 ORNL is managed by UT-Battelle for the US Department of Energy
Exploring Emerging Technologies in the Extreme Scale HPC Co- Design Space with Aspen Jeffrey S. Vetter SPPEXA Symposium Munich 26 Jan 2016 ORNL is managed by UT-Battelle for the US Department of Energy
Quantifying Resiliency in the Extreme Scale HPC Co-Design Space
 Quantifying Resiliency in the Extreme Scale HPC Co-Design Space Jeffrey S. Vetter Jeremy Meredith Dagstuhl Seminar #15281 Algorithms and Scheduling Techniques to Manage Resilience and Power Consumption
Quantifying Resiliency in the Extreme Scale HPC Co-Design Space Jeffrey S. Vetter Jeremy Meredith Dagstuhl Seminar #15281 Algorithms and Scheduling Techniques to Manage Resilience and Power Consumption
Architecture trends, performance prediction and co-design tools
 Architecture trends, performance prediction and co-design tools Jeffrey S. Vetter US-Japan Joint Institute for Fusion Theory Workshop on Innovations and Codesigns of Fusion Simulations towards Extreme
Architecture trends, performance prediction and co-design tools Jeffrey S. Vetter US-Japan Joint Institute for Fusion Theory Workshop on Innovations and Codesigns of Fusion Simulations towards Extreme
Preparing for Supercomputing s Sixth Wave
 Preparing for Supercomputing s Sixth Wave Jeffrey S. Vetter Presented to ACM Symposium on High-Performance Parallel and Distributed Computing 2 June 2016 Kyoto ORNL is managed by UT-Battelle for the US
Preparing for Supercomputing s Sixth Wave Jeffrey S. Vetter Presented to ACM Symposium on High-Performance Parallel and Distributed Computing 2 June 2016 Kyoto ORNL is managed by UT-Battelle for the US
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Exploring Emerging Memory Technologies in Extreme Scale High Performance Computing
 Exploring Emerging Memory Technologies in Extreme Scale High Performance Computing Jeffrey S. Vetter Presented to ISC Third International Workshop on Communication Architectures for HPC, Big Data, Deep
Exploring Emerging Memory Technologies in Extreme Scale High Performance Computing Jeffrey S. Vetter Presented to ISC Third International Workshop on Communication Architectures for HPC, Big Data, Deep
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
LLVM for the future of Supercomputing
 LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
Present and Future Leadership Computers at OLCF
 Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
Preparing Scientific Software for Exascale
 Preparing Scientific Software for Exascale Jack Wells Director of Science Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory Mini-Symposium on Scientific Software Engineering Monday,
Preparing Scientific Software for Exascale Jack Wells Director of Science Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory Mini-Symposium on Scientific Software Engineering Monday,
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
The Effect of Emerging Architectures on Data Science (and other thoughts)
") The Effect of Emerging Architectures on Data Science (and other thoughts) Philip C. Roth With contributions from Jeffrey S. Vetter and Jeremy S. Meredith (ORNL) and Allen Malony (U. Oregon) Future Technologies
The Effect of Emerging Architectures on Data Science (and other thoughts) Philip C. Roth With contributions from Jeffrey S. Vetter and Jeremy S. Meredith (ORNL) and Allen Malony (U. Oregon) Future Technologies
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Cori (2016) and Beyond Ensuring NERSC Users Stay Productive
 and Beyond Ensuring NERSC Users Stay Productive") Cori (2016) and Beyond Ensuring NERSC Users Stay Productive Nicholas J. Wright! Advanced Technologies Group Lead! Heterogeneous Mul-- Core 4 Workshop 17 September 2014-1 - NERSC Systems Today Edison: 2.39PF,
Cori (2016) and Beyond Ensuring NERSC Users Stay Productive Nicholas J. Wright! Advanced Technologies Group Lead! Heterogeneous Mul-- Core 4 Workshop 17 September 2014-1 - NERSC Systems Today Edison: 2.39PF,
Center for Accelerated Application Readiness. Summit. Tjerk Straatsma. Getting Applications Ready for. OLCF Scientific Computing Group
 Center for Accelerated Application Readiness Getting Applications Ready for Summit Tjerk Straatsma OLCF Scientific Computing Group ORNL is managed by UT-Battelle for the US Department of Energy OLCF on
Center for Accelerated Application Readiness Getting Applications Ready for Summit Tjerk Straatsma OLCF Scientific Computing Group ORNL is managed by UT-Battelle for the US Department of Energy OLCF on
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies
 Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Overview. Idea: Reduce CPU clock frequency This idea is well suited specifically for visualization
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Using MPI+OpenMP for current and future architectures
 Using MPI+OpenMP for current and future architectures September 24th, 2018 OpenMPCon 2018 Oscar Hernandez Yun (Helen) He Barbara Chapman DOE s Office of Science Computation User Facilities DOE is leader
Using MPI+OpenMP for current and future architectures September 24th, 2018 OpenMPCon 2018 Oscar Hernandez Yun (Helen) He Barbara Chapman DOE s Office of Science Computation User Facilities DOE is leader
Oak Ridge Leadership Computing Facility: Summit and Beyond
 Oak Ridge Leadership Computing Facility: Summit and Beyond Justin L. Whitt OLCF-4 Deputy Project Director, Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory March 2017 ORNL is managed
Oak Ridge Leadership Computing Facility: Summit and Beyond Justin L. Whitt OLCF-4 Deputy Project Director, Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory March 2017 ORNL is managed
What s P. Thierry
 What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy
 Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
A Breakthrough in Non-Volatile Memory Technology FUJITSU LIMITED
 A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
Interconnect Related Research at Oak Ridge National Laboratory
 Interconnect Related Research at Oak Ridge National Laboratory Barney Maccabe Director, Computer Science and Mathematics Division July 16, 2015 Frankfurt, Germany ORNL is managed by UT-Battelle for the
Interconnect Related Research at Oak Ridge National Laboratory Barney Maccabe Director, Computer Science and Mathematics Division July 16, 2015 Frankfurt, Germany ORNL is managed by UT-Battelle for the
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete
 Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
AMD ACCELERATING TECHNOLOGIES FOR EXASCALE COMPUTING FELLOW 3 OCTOBER 2016
 AMD ACCELERATING TECHNOLOGIES FOR EXASCALE COMPUTING BILL.BRANTLEY@AMD.COM, FELLOW 3 OCTOBER 2016 AMD S VISION FOR EXASCALE COMPUTING EMBRACING HETEROGENEITY CHAMPIONING OPEN SOLUTIONS ENABLING LEADERSHIP
AMD ACCELERATING TECHNOLOGIES FOR EXASCALE COMPUTING BILL.BRANTLEY@AMD.COM, FELLOW 3 OCTOBER 2016 AMD S VISION FOR EXASCALE COMPUTING EMBRACING HETEROGENEITY CHAMPIONING OPEN SOLUTIONS ENABLING LEADERSHIP
Big Data Systems on Future Hardware. Bingsheng He NUS Computing
 Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Emerging NV Storage and Memory Technologies --Development, Manufacturing and
 Emerging NV Storage and Memory Technologies --Development, Manufacturing and Applications-- Tom Coughlin, Coughlin Associates Ed Grochowski, Computer Storage Consultant 2014 Coughlin Associates 1 Outline
Emerging NV Storage and Memory Technologies --Development, Manufacturing and Applications-- Tom Coughlin, Coughlin Associates Ed Grochowski, Computer Storage Consultant 2014 Coughlin Associates 1 Outline
ECE 574 Cluster Computing Lecture 23
 ECE 574 Cluster Computing Lecture 23 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 December 2015 Announcements Project presentations next week There is a final. time. Maybe
ECE 574 Cluster Computing Lecture 23 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 December 2015 Announcements Project presentations next week There is a final. time. Maybe
Toward a Memory-centric Architecture
 Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Adrian Proctor Vice President, Marketing Viking Technology
 Storage PRESENTATION in the TITLE DIMM GOES HERE Socket Adrian Proctor Vice President, Marketing Viking Technology SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
Storage PRESENTATION in the TITLE DIMM GOES HERE Socket Adrian Proctor Vice President, Marketing Viking Technology SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Execution Models for the Exascale Era
 Execution Models for the Exascale Era Nicholas J. Wright Advanced Technology Group, NERSC/LBNL njwright@lbl.gov Programming weather, climate, and earth- system models on heterogeneous muli- core plajorms
Execution Models for the Exascale Era Nicholas J. Wright Advanced Technology Group, NERSC/LBNL njwright@lbl.gov Programming weather, climate, and earth- system models on heterogeneous muli- core plajorms
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
ReRAM Status and Forecast 2017
 ReRAM Status and Forecast 2017 Mark Webb The Latency Spectrum and Gaps More Like Memory More Like Storage CPU/ SRAM DRAM Storage Class Memory GAP NAND SLC to TLC HDD TAPE 1ns 10ns 100ns 1us 10us 100us
ReRAM Status and Forecast 2017 Mark Webb The Latency Spectrum and Gaps More Like Memory More Like Storage CPU/ SRAM DRAM Storage Class Memory GAP NAND SLC to TLC HDD TAPE 1ns 10ns 100ns 1us 10us 100us
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Mohsen Imani. University of California San Diego. System Energy Efficiency Lab seelab.ucsd.edu
 Mohsen Imani University of California San Diego Winter 2016 Technology Trend for IoT http://www.flashmemorysummit.com/english/collaterals/proceedi ngs/2014/20140807_304c_hill.pdf 2 Motivation IoT significantly
Mohsen Imani University of California San Diego Winter 2016 Technology Trend for IoT http://www.flashmemorysummit.com/english/collaterals/proceedi ngs/2014/20140807_304c_hill.pdf 2 Motivation IoT significantly
IHK/McKernel: A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing
 : A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing Balazs Gerofi Exascale System Software Team, RIKEN Center for Computational Science 218/Nov/15 SC 18 Intel Extreme Computing
: A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing Balazs Gerofi Exascale System Software Team, RIKEN Center for Computational Science 218/Nov/15 SC 18 Intel Extreme Computing
IBM HPC Technology & Strategy
 IBM HPC Technology & Strategy Hyperion HPC User Forum Stuttgart, October 1st, 2018 The World s Smartest Supercomputers Klaus Gottschalk gottschalk@de.ibm.com HPC Strategy Deliver End to End Solutions for
IBM HPC Technology & Strategy Hyperion HPC User Forum Stuttgart, October 1st, 2018 The World s Smartest Supercomputers Klaus Gottschalk gottschalk@de.ibm.com HPC Strategy Deliver End to End Solutions for
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
GPFS Experiences from the Argonne Leadership Computing Facility (ALCF) William (Bill) E. Allcock ALCF Director of Operations
 William (Bill) E. Allcock ALCF Director of Operations") GPFS Experiences from the Argonne Leadership Computing Facility (ALCF) William (Bill) E. Allcock ALCF Director of Operations Argonne National Laboratory Argonne National Laboratory is located on 1,500
GPFS Experiences from the Argonne Leadership Computing Facility (ALCF) William (Bill) E. Allcock ALCF Director of Operations Argonne National Laboratory Argonne National Laboratory is located on 1,500
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Efficient Parallel Programming on Xeon Phi for Exascale
 Efficient Parallel Programming on Xeon Phi for Exascale Eric Petit, Intel IPAG, Seminar at MDLS, Saclay, 29th November 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration
Efficient Parallel Programming on Xeon Phi for Exascale Eric Petit, Intel IPAG, Seminar at MDLS, Saclay, 29th November 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration
March 10 11, 2015 San Jose
 March 10 11, 2015 San Jose Neo and Neo64 A new processor and open source ISA for HPC Thomas Sohmers REX Computing CEO Current processors are built for an old paradigm 30#years#ago,#moving#data#was#cheap#(energy#wise)#and#computa9on#was#expensive.#This#has#now#
March 10 11, 2015 San Jose Neo and Neo64 A new processor and open source ISA for HPC Thomas Sohmers REX Computing CEO Current processors are built for an old paradigm 30#years#ago,#moving#data#was#cheap#(energy#wise)#and#computa9on#was#expensive.#This#has#now#
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Hybrid Memory Platform
 Hybrid Memory Platform Kenneth Wright, Sr. Driector Rambus / Emerging Solutions Division Join the Conversation #OpenPOWERSummit 1 Outline The problem / The opportunity Project goals Roadmap - Sub-projects/Tracks
Hybrid Memory Platform Kenneth Wright, Sr. Driector Rambus / Emerging Solutions Division Join the Conversation #OpenPOWERSummit 1 Outline The problem / The opportunity Project goals Roadmap - Sub-projects/Tracks
HPC Storage Use Cases & Future Trends
 Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Evaluation of Parallel I/O Performance and Energy with Frequency Scaling on Cray XC30 Suren Byna and Brian Austin
 Evaluation of Parallel I/O Performance and Energy with Frequency Scaling on Cray XC30 Suren Byna and Brian Austin Lawrence Berkeley National Laboratory Energy efficiency at Exascale A design goal for future
Evaluation of Parallel I/O Performance and Energy with Frequency Scaling on Cray XC30 Suren Byna and Brian Austin Lawrence Berkeley National Laboratory Energy efficiency at Exascale A design goal for future
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Memory: Past, Present and Future Trends Paolo Faraboschi
 Memory: Past, Present and Future Trends Paolo Faraboschi Fellow, Hewlett Packard Labs Systems Research Lab Quiz ( Excerpt from Intel Developer Forum Keynote 2000 ) ANDREW GROVE: is there a role for more
Memory: Past, Present and Future Trends Paolo Faraboschi Fellow, Hewlett Packard Labs Systems Research Lab Quiz ( Excerpt from Intel Developer Forum Keynote 2000 ) ANDREW GROVE: is there a role for more
Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories
 Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories Adrian M. Caulfield Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, Steven Swanson Non-Volatile Systems
Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories Adrian M. Caulfield Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, Steven Swanson Non-Volatile Systems
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MARCH 17 TH, MIC Workshop PAGE 1. MIC workshop Guillaume Colin de Verdière
 EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation
 Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation Dr. Li Li Distinguished Engineer June 28, 2016 Outline Evolution of Internet The Promise of Internet
Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation Dr. Li Li Distinguished Engineer June 28, 2016 Outline Evolution of Internet The Promise of Internet
Gen-Z Memory-Driven Computing
 Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
Exploring Use-cases for Non-Volatile Memories in support of HPC Resilience
 Exploring Use-cases for Non-Volatile Memories in support of HPC Resilience Onkar Patil 1, Saurabh Hukerikar 2, Frank Mueller 1, Christian Engelmann 2 1 Dept. of Computer Science, North Carolina State University
Exploring Use-cases for Non-Volatile Memories in support of HPC Resilience Onkar Patil 1, Saurabh Hukerikar 2, Frank Mueller 1, Christian Engelmann 2 1 Dept. of Computer Science, North Carolina State University
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
SOLVING THE DRAM SCALING CHALLENGE: RETHINKING THE INTERFACE BETWEEN CIRCUITS, ARCHITECTURE, AND SYSTEMS
 SOLVING THE DRAM SCALING CHALLENGE: RETHINKING THE INTERFACE BETWEEN CIRCUITS, ARCHITECTURE, AND SYSTEMS Samira Khan MEMORY IN TODAY S SYSTEM Processor DRAM Memory Storage DRAM is critical for performance
SOLVING THE DRAM SCALING CHALLENGE: RETHINKING THE INTERFACE BETWEEN CIRCUITS, ARCHITECTURE, AND SYSTEMS Samira Khan MEMORY IN TODAY S SYSTEM Processor DRAM Memory Storage DRAM is critical for performance
A case study of performance portability with OpenMP 4.5
 A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
The Long-Term Future of Solid State Storage Jim Handy Objective Analysis
 The Long-Term Future of Solid State Storage Jim Handy Objective Analysis Agenda How did we get here? Why it s suboptimal How we move ahead Why now? DRAM speed scaling Changing role of NVM in computing
The Long-Term Future of Solid State Storage Jim Handy Objective Analysis Agenda How did we get here? Why it s suboptimal How we move ahead Why now? DRAM speed scaling Changing role of NVM in computing
Intel s s Memory Strategy for the Wireless Phone
 Intel s s Memory Strategy for the Wireless Phone Stefan Lai VP and Co-Director, CTM Intel Corporation Nikkei Microdevices Memory Symposium January 26 th, 2005 Agenda Evolution of Memory Requirements Evolution
Intel s s Memory Strategy for the Wireless Phone Stefan Lai VP and Co-Director, CTM Intel Corporation Nikkei Microdevices Memory Symposium January 26 th, 2005 Agenda Evolution of Memory Requirements Evolution
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
Efficiency and Programmability: Enablers for ExaScale. Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford
, EE&CS, Stanford") Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
Emerging NVM Memory Technologies
 Emerging NVM Memory Technologies Yuan Xie Associate Professor The Pennsylvania State University Department of Computer Science & Engineering www.cse.psu.edu/~yuanxie yuanxie@cse.psu.edu Position Statement
Emerging NVM Memory Technologies Yuan Xie Associate Professor The Pennsylvania State University Department of Computer Science & Engineering www.cse.psu.edu/~yuanxie yuanxie@cse.psu.edu Position Statement
SIMULATOR AMD RESEARCH JUNE 14, 2015
 AMD'S gem5apu SIMULATOR AMD RESEARCH JUNE 14, 2015 OVERVIEW Introducing AMD s gem5 APU Simulator Extends gem5 with a GPU timing model Supports Heterogeneous System Architecture in SE mode Includes several
AMD'S gem5apu SIMULATOR AMD RESEARCH JUNE 14, 2015 OVERVIEW Introducing AMD s gem5 APU Simulator Extends gem5 with a GPU timing model Supports Heterogeneous System Architecture in SE mode Includes several
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
It's the end of the world as we know it
 It's the end of the world as we know it Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Background Graduated as Valedictorian in Computer Science from Cardiff University
It's the end of the world as we know it Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Background Graduated as Valedictorian in Computer Science from Cardiff University
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Flash Memory Summit Persistent Memory - NVDIMMs
 Flash Memory Summit 2018 Persistent Memory - NVDIMMs Contents Persistent Memory Overview NVDIMM Conclusions 2 Persistent Memory Memory & Storage Convergence Today Volatile and non-volatile technologies
Flash Memory Summit 2018 Persistent Memory - NVDIMMs Contents Persistent Memory Overview NVDIMM Conclusions 2 Persistent Memory Memory & Storage Convergence Today Volatile and non-volatile technologies
Computation for Beyond Standard Model Physics
 Computation for Beyond Standard Model Physics Xiao-Yong Jin Argonne National Laboratory Lattice for BSM Physics 2018 Boulder, Colorado April 6, 2018 2 My PhD years at Columbia Lattice gauge theory Large
Computation for Beyond Standard Model Physics Xiao-Yong Jin Argonne National Laboratory Lattice for BSM Physics 2018 Boulder, Colorado April 6, 2018 2 My PhD years at Columbia Lattice gauge theory Large
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE
 Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Emerging NVM Enabled Storage Architecture:
 Emerging NVM Enabled Storage Architecture: From Evolution to Revolution. Yiran Chen Electrical and Computer Engineering University of Pittsburgh Sponsors: NSF, DARPA, AFRL, and HP Labs 1 Outline Introduction
Emerging NVM Enabled Storage Architecture: From Evolution to Revolution. Yiran Chen Electrical and Computer Engineering University of Pittsburgh Sponsors: NSF, DARPA, AFRL, and HP Labs 1 Outline Introduction