Introduction to the Intel Xeon Phi on Stampede
|
|
|
- Bennett Russell
- 6 years ago
- Views:
Transcription


1 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center
 6,400 nodes 56 Gb/s Mellanox FDR InfiniBand interconnect More than")

2 Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors Dell dual-socket nodes w/32gb RAM (2GB/core) 6,400 nodes 56 Gb/s Mellanox FDR InfiniBand interconnect More than 100,000 cores, 2.2 PF peak performance Co-Processors: Intel Xeon Phi MIC Many Integrated Core processors Special release of Knight s Corner (61 cores) 7+ PF peak performance Max Total Concurrency: exceeds 500,000 cores 1.8M threads
3 Additional Integrated Subsystems Stampede includes 16 1TB Sandy Bridge shared memory nodes with dual GPUs 128 of the compute nodes are also equipped with NVIDIA Kepler K20 GPUs (and MICS for performance bake-offs) 16 login, data mover and management servers (batch, subnet manager, provisioning, etc) Software included for high throughput computing, remote visualization Storage subsystem driven by Dell storage nodes: Aggregate Bandwidth greater than 150GB/s More than 14PB of capacity Similar partitioning of disk space into multiple Lustre filesystems as previous TACC systems ($HOME, $WORK and $SCRATCH)
4 Power/Physical Stampede spans U cabinets. Power density (after upgrade in 2015) will exceed 40kW per rack. Estimated 2015 peak power is 6.2MW.

5 Stampede Footprint Ranger Stampede 8000 ft 2 ~10PF 6.5 MW 3000 ft2 0.6 PF 3 MW Machine Room Expansion Added 6.5MW of additional power




6 Actually, way more utility space than machine space Turns out the utilities for the datacenter costs more, takes more time and more space than the computing systems
7 Innovative Component One of the goals of the NSF solicitation was to introduce a major new innovative capability component to science and engineering research communities We proposed the Intel Xeon Phi coprocessor (many integrated core or MIC) one first generation Phi installed per host during initial deployment confirmed injection of 1600 future generation MICs in 2015 (5+ PF)
8 An Inflection point (or two) in High Performance Computing Relatively boring, but rapidly improving architectures for the last 16 years. Performance rising much faster than Moore s Law But power rising faster And concurrency rising faster than that, with serial performance decreasing. Something had to give
9 Accelerated Computing for Exascale Exascale systems, predicted for 2018, would have required 500MW on the old curves. Something new was clearly needed. The accelerated computing movement was reborn (this happens periodically, starting with 387 math coprocessors).
10 Key aspects of acceleration We have lots of transistors Moore s law is holding; this isn t necessarily the problem. We don t really need lower power per transistor, we need lower power per *operation*. How to do this? nvidia GPU -AMD Fusion FPGA -ARM Cores
11 Intel s MIC approach Since the days of RISC vs. CISC, Intel has mastered the art of figuring out what is important about a new processing technology, and saying why can t we do this in x86? The Intel Many Integrated Core (MIC) architecture is about large die, simpler circuit, much more parallelism, in the x86 line.
12 Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co-processor PCI Express card Stripped down Linux operating system But still a full host you can log in to the Phi directly and run stuff! Lots of names Many Integrated Core architecture, aka MIC Knights Corner (code name) Intel Xeon Phi Co-processor SE10P (product name of the version for Stampede) I should have many more trademark symbols in my slides if you ask Intel!

13 Intel Xeon Phi Chip 22 nm process Based on what Intel learned from Larrabee SCC TeraFlops Research Chip

14 MIC Architecture Many cores on the die L1 and L2 cache Bidirectional ring network for L2 Memory and PCIe connection
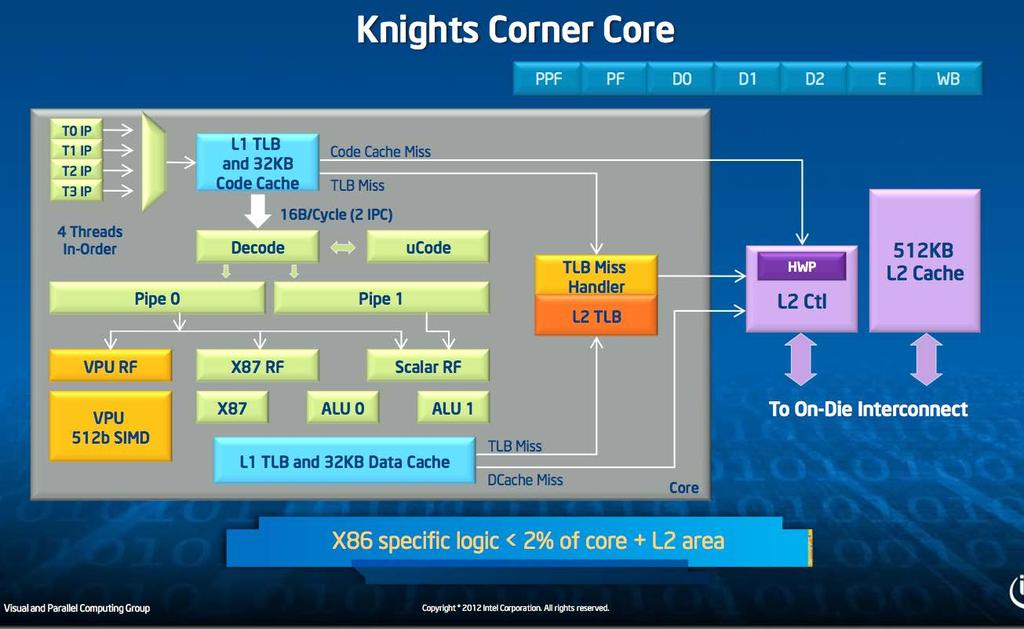
15 George Chrysos, Intel, Hot Chips 24 (2012):
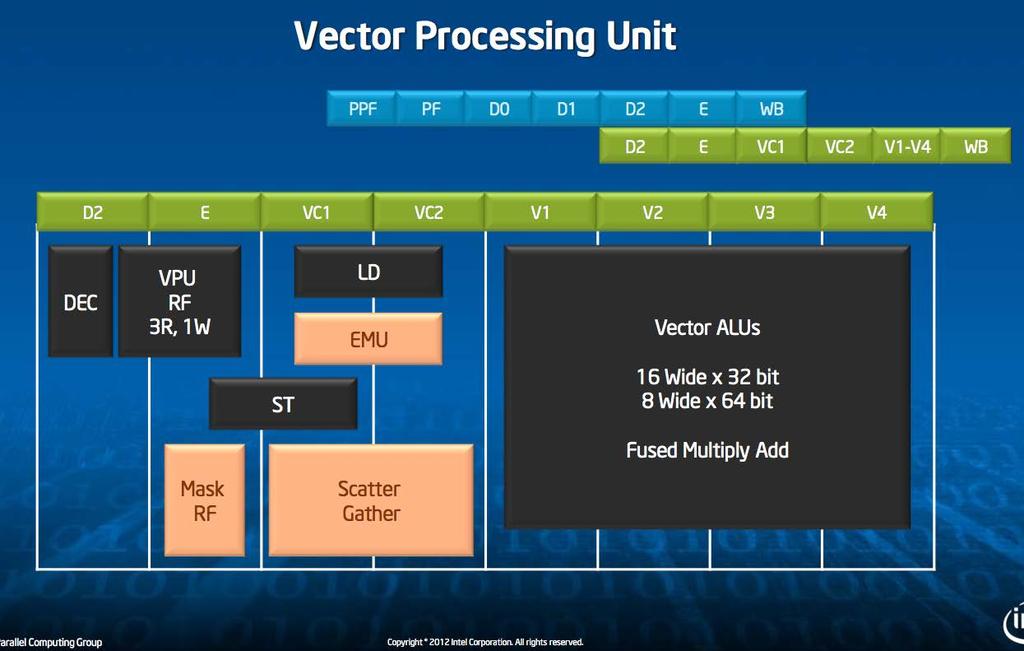
16 George Chrysos, Intel, Hot Chips 24 (2012):
17 Speeds and Feeds Stampede SE10P version (Your mileage may vary) Processor ~1.1 GHz 61 cores 512-bit wide vector unit TF peak DP Data Cache L1 32KB/core L2 512KB/core, 30.5 MB/chip Memory 8GB GDDR5 DRAM 5.5 GT/s, 512-bit* PCIe 5.0 GT/s, 16-bit
18 What we at TACC like about MIC Intel s MIC is based on x86 technology x86 cores w/ caches and cache coherency SIMD instruction set Programming for MIC is similar to programming for CPUs Familiar languages: C/C++ and Fortran Familiar parallel programming models: OpenMP & MPI MPI on host and on the coprocessor Any code can run on MIC, not just kernels Optimizing for MIC is similar to optimizing for CPUs Optimize once, run anywhere Optimizing can be hard; but everything you do to your code should *also* improve performance on current and future regular Intel chips, AMD CPUs, etc.
19 Programming the Xeon Phi Some universal truths of Xeon Phi coding: You need lots of threads. Really. Lots. At least 2 per core to have a chance 3 or 4 per core are often optimal. This is not like old school hyperthreading, if you don t have 2 threads per core, half your cycles will be wasted. You need to vectorize. This helps on regular processors too, but the effect is much more pronounced on the MIC chips. You can no longer ignore the vectorization report from the compiler If you can do these 2 things, good things will happen, in most any language.
20 MIC Programming Experiences at TACC Codes port easily Minutes to days depending mostly on library dependencies Performance requires real work While the silicon continues to evolve Getting codes to run *at all* is almost too easy; really need to put in the effort to get what you expect Scalability is pretty good Multiple threads per core *really important* Getting your code to vectorize *really important*
21 Typical Stampede Node ( = blade ) CPU (Host) Sandy Bridge Coprocessor (MIC) Knights Corner x16 PCIe 16 cores 32G RAM Two Xeon E5 8-core processors 61 lightweight cores 8G RAM Xeon Phi Coprocessor Each core has 4 hardware threads MIC runs lightweight Linux-like OS (BusyBox)
22 Stampede Programming Models Traditional Cluster, or Host Only Pure MPI and MPI+X (OpenMP, TBB, Cilk+, OpenCL ) Ignore the MIC Native Phi Use one Phi and run OpenMP or MPI programs directly Offload MPI on Host, Offload to Xeon Phi Targeted offload through OpenMP extensions Automatically offload some library routines with MKL Symmetric - MPI tasks on Host and Phi Treat the Phi (mostly) like another host
23 What is a native application? It is an application built to run exclusively on the MIC coprocessor. MIC is not binary compatible with the host processor Instruction set is similar to Pentium, but not all 64 bit scalar extensions are included. MIC has 512 bit vector extensions, but does NOT have MMX, SSE, or AVX extensions. Native applications can t be used on the host CPU, and viceversa.
24 Why run a native application? It is possible to login and run applications on the MIC without any host intervention Easy way to get acquainted with the properties of the MIC Performance studies Single card scaling tests (OMP/MPI) No issues with data exchange with host The native code probably performs quite well on the host CPU once you build a host version Good path for symmetric runs
25 Will My Code Run on Xeon Phi? Yes but that s the wrong question Will your code run *best* on Phi?, or Will you get great Phi performance without additional work?
26 Building a native application Cross-compile on the host (login or compute nodes) No compilers installed on coprocessors MIC is fully supported by the Intel C/C++ and Fortran compilers (v13+): icc -openmp -mmic mysource.c -o myapp.mic ifort -openmp -mmic mysource.f90 -o myapp.mic The -mmic flag causes the compiler to generate a native mic executable It is convenient to use a.mic extension to differentiate MIC executables
27 Native Execution Quirks The mic runs a lightweight version of Linux, based on BusyBox Some tools are missing: w,numactl Some tools have reduced functionality: ps Relatively few libraries have been ported to the coprocessor environment These issues make the implicit or explicit launcher approach even more convenient

28 What is Offloading Send block of code to be executed on coprocessor (MIC). Must have a binary of the code (code block or function). Compiler makes the binary and stores it in the executable (a.out). During execution on the CPU, the runtime is contacted to begin executing the MIC binary at an offload point. When the coprocessor is finished, the CPU resumes executing the CPU part of the code. Linux OS HCA PCIe Linux micro OS MIC CPU execution is directed to run a MIC binary section of code on the MIC.
29 MPI with Offload to Phi Existing codes using accelerators have already identified regions where offload works well Porting these to OpenMP offload should be straightforward Automatic offload where MKL kernel routines can be used xgemm, etc.
30 Directives Directives can be inserted before code blocks and functions to run the code on the Xeon Phi Coprocessor (the MIC ). No recoding required. (Optimization may require some changes.) Directives are simple, but more details (specifiers) may be needed for optimal performance. Data must be moved to the MIC For large amounts of data: Amortized when doing large amounts of work. Keep data resident ( persistent ). Move data asynchronously.
31 Simple OMP Example #define N int main(){ float a[n]; int i; #pragma offload target(mic) #pragma omp parallel for for(i=0,i<n;i++) a[i]=(float) i; OMP Parallel Regions Can Be Offloaded Directly program main integer, parameter :: N=10000 real :: a(n)!dir$ offload target(mic)!$omp parallel do do i=1,n a(i)=i; end do } printf( %f \n,a[10]); print*, a(10) end program OpenMP regions can be offloaded directly. OpenMP parallel regions can exist in offloaded code blocks or functions.
32 Automatic Offload Offloads some MKL routines automatically No coding change No recompiling Makes sense with BLAS-3 type routines Minimal Data O(n 2 ), Maximal Compute O(n 3 ) Supported Routines (more to come) Type Level-3 BLAS LAPACK 3 amigos Routine xgemm, xtrsm, STRMM LU, QR, Cholesky
33 Symmetric Computing Run MPI tasks on both MIC and host and across nodes Also called heterogeneous computing Two executables are required: CPU MIC Currently only works with Intel MPI MVAPICH2 support coming

34 Typical Stampede Node ( = blade ) CPU (Host) Sandy Bridge Coprocessor (MIC) Knights Corner x16 PCIe 16 cores 32G RAM Two Xeon E5 8-core processors 61 lightweight cores 8G RAM Xeon Phi Coprocessor Each core has 4 hardware threads MIC runs lightweight Linux-like OS (BusyBox)
35 Balance How to balance the code? Sandy Bridge Xeon Phi Memory 32 GB 8 GB Cores Clock Speed 2.7 GHz 1.1 GHz Memory 51.2 GB/s(x2) 352 GB/s Bandwidth Vector Length 4 DP words 8 DP words
36 Balance Example: Memory balance Balance memory use and performance by using a different # of tasks/threads on host and MIC Host 16 tasks/1 thread/task 2GB/task Xeon PHI 4 tasks/60 threads/task 2GB/task
37 Balance Example: Performance balance Balance performance by tuning the # of tasks and threads on host and MIC Host 16 tasks/1 thread/task 2GB/task Xeon PHI? tasks/? threads/task 2GB/task
38 LBM Example Lattice Boltzmann Method CFD code Carlos Rosales, TACC OpenMP code Finding all the right routines to parallelize is critical
39 Other options At TACC, we ve focused mainly on C/C++ and Fortran, with threading through OpenMP Other options are out there, notably: Intel s cilk extensions for C/C++ TBB (Threading Building Blocks) for C++ OpenCL support is available, but we have little experience so far. It s Linux, you can run whatever you want (ie., I have run a pthreads code on Phi).
40 Summary MIC experiences Early scaling looks good; application porting is fairly straight forward since it can run native C/C++, and Fortran code Optimization work is still required to get at all the available raw performance for a wide variety of applications vectorization on these large many-core devices is key affinitization can have a strong impact (positive/negative) on performance algorithmic threading performance is also key; if the kernel of interest does not have high scaling efficiency on a standard x86_64 processor (8-16 cores), it will not scale on many-core MIC optimization efforts also yield fruit on normal Xeon
41 MIC Information Stampede User Guide: TACC Advanced Offloading: Search and click on Advanced Offloading document in the Stampede User Guide. Intel Programming & Compiler for MIC Intel Compiler Manuals: C/C++ Fortran Example code: /opt/apps/intel/13/composer_xe_ /samples/en_us/

42 Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI Stampede Award, Enabling, Enhancing, and Extending Petascale Computing for Science and Engineering NSF Grant #OCI Topology-Aware MPI Collectives and Scheduling Many, many Dell, Intel, and Mellanox engineers All my colleagues at TACC
43
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Native Computing and Optimization. Hang Liu December 4 th, 2013
 Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Overview of Intel Xeon Phi Coprocessor
 Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Offloading. Kent Milfeld Stampede Training, January 11, 2013
 Kent Milfeld milfeld@tacc.utexas.edu Stampede Training, January 11, 2013 1 MIC Information Stampede User Guide: http://www.tacc.utexas.edu/user-services/user-guides/stampede-user-guide TACC Advanced Offloading:
Kent Milfeld milfeld@tacc.utexas.edu Stampede Training, January 11, 2013 1 MIC Information Stampede User Guide: http://www.tacc.utexas.edu/user-services/user-guides/stampede-user-guide TACC Advanced Offloading:
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
HPC. Accelerating. HPC Advisory Council Lugano, CH March 15 th, Herbert Cornelius Intel
 15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Native Computing and Optimization on Intel Xeon Phi
 Native Computing and Optimization on Intel Xeon Phi ISC 2015 Carlos Rosales carlos@tacc.utexas.edu Overview Why run native? What is a native application? Building a native application Running a native
Native Computing and Optimization on Intel Xeon Phi ISC 2015 Carlos Rosales carlos@tacc.utexas.edu Overview Why run native? What is a native application? Building a native application Running a native
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Many-core Processor Programming for beginners. Hongsuk Yi ( 李泓錫 ) KISTI (Korea Institute of Science and Technology Information)
 KISTI (Korea Institute of Science and Technology Information)") Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Offloading. Kent Milfeld June,
 Kent Milfeld milfeld@tacc.utexas.edu June, 16 2013 MIC Information Stampede User Guide: http://www.tacc.utexas.edu/user-services/user-guides/stampede-user-guide TACC Advanced Offloading: Search and click
Kent Milfeld milfeld@tacc.utexas.edu June, 16 2013 MIC Information Stampede User Guide: http://www.tacc.utexas.edu/user-services/user-guides/stampede-user-guide TACC Advanced Offloading: Search and click
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Outline Overview What is a native application? Why run native? Getting Started: Building a
Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Outline Overview What is a native application? Why run native? Getting Started: Building a
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. Lars Koesterke John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor Lars Koesterke John D. McCalpin lars@tacc.utexas.edu mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps
Native Computing and Optimization on the Intel Xeon Phi Coprocessor Lars Koesterke John D. McCalpin lars@tacc.utexas.edu mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Symmetric Computing. ISC 2015 July John Cazes Texas Advanced Computing Center
 Symmetric Computing ISC 2015 July 2015 John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required:
Symmetric Computing ISC 2015 July 2015 John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required:
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Symmetric Computing. Jerome Vienne Texas Advanced Computing Center
 Symmetric Computing Jerome Vienne Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Symmetric Computing Jerome Vienne Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Symmetric Computing. John Cazes Texas Advanced Computing Center
 Symmetric Computing John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host and across nodes Also called heterogeneous computing Two executables are required:
Symmetric Computing John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host and across nodes Also called heterogeneous computing Two executables are required:
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Knights Corner: Your Path to Knights Landing
 Knights Corner: Your Path to Knights Landing James Reinders, Intel Wednesday, September 17, 2014; 9-10am PDT Photo (c) 2014, James Reinders; used with permission; Yosemite Half Dome rising through forest
Knights Corner: Your Path to Knights Landing James Reinders, Intel Wednesday, September 17, 2014; 9-10am PDT Photo (c) 2014, James Reinders; used with permission; Yosemite Half Dome rising through forest
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Does the Intel Xeon Phi processor fit HEP workloads?
 Does the Intel Xeon Phi processor fit HEP workloads? October 17th, CHEP 2013, Amsterdam Andrzej Nowak, CERN openlab CTO office On behalf of Georgios Bitzes, Havard Bjerke, Andrea Dotti, Alfio Lazzaro,
Does the Intel Xeon Phi processor fit HEP workloads? October 17th, CHEP 2013, Amsterdam Andrzej Nowak, CERN openlab CTO office On behalf of Georgios Bitzes, Havard Bjerke, Andrea Dotti, Alfio Lazzaro,
Investigation of Intel MIC for implementation of Fast Fourier Transform
 Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2
 Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Intel Software Development Products for High Performance Computing and Parallel Programming
 Intel Software Development Products for High Performance Computing and Parallel Programming Multicore development tools with extensions to many-core Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN
Intel Software Development Products for High Performance Computing and Parallel Programming Multicore development tools with extensions to many-core Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Benchmark results on Knight Landing (KNL) architecture
 architecture") Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Offload Computing on Stampede
 Offload Computing on Stampede Kent Milfeld milfeld@tacc.utexas.edu July, 22 2013 1 MIC Information mic-developer (programming & training tabs): http://software.intel.com/mic-developer Intel Programming
Offload Computing on Stampede Kent Milfeld milfeld@tacc.utexas.edu July, 22 2013 1 MIC Information mic-developer (programming & training tabs): http://software.intel.com/mic-developer Intel Programming
Comet Virtualization Code & Design Sprint
 Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
The Heterogeneous Programming Jungle. Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest
 The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
rabbit.engr.oregonstate.edu What is rabbit?
 1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
1 rabbit.engr.oregonstate.edu Mike Bailey mjb@cs.oregonstate.edu rabbit.pptx What is rabbit? 2 NVIDIA Titan Black PCIe Bus 15 SMs 2880 CUDA cores 6 GB of memory OpenGL support OpenCL support Xeon system
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
OpenMP 4.0 (and now 5.0)
") OpenMP 4.0 (and now 5.0) John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Classic OpenMP OpenMP was designed to replace low-level and tedious solutions like POSIX
OpenMP 4.0 (and now 5.0) John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Classic OpenMP OpenMP was designed to replace low-level and tedious solutions like POSIX
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation
 Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation Jianting Zhang 1,2 Simin You 2, Le Gruenwald 3 1 Depart of Computer Science, CUNY City College (CCNY) 2 Department of Computer
Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation Jianting Zhang 1,2 Simin You 2, Le Gruenwald 3 1 Depart of Computer Science, CUNY City College (CCNY) 2 Department of Computer
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Intel Performance Libraries
 Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture
 Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
6/14/2017. The Intel Xeon Phi. Setup. Xeon Phi Internals. Fused Multiply-Add. Getting to rabbit and setting up your account. Xeon Phi Peak Performance
 The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
The Intel Xeon Phi 1 Setup 2 Xeon system Mike Bailey mjb@cs.oregonstate.edu rabbit.engr.oregonstate.edu 2 E5-2630 Xeon Processors 8 Cores 64 GB of memory 2 TB of disk NVIDIA Titan Black 15 SMs 2880 CUDA
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Path to Exascale? Intel in Research and HPC 2012
 Path to Exascale? Intel in Research and HPC 2012 Intel s Investment in Manufacturing New Capacity for 14nm and Beyond D1X Oregon Development Fab Fab 42 Arizona High Volume Fab 22nm Fab Upgrades D1D Oregon
Path to Exascale? Intel in Research and HPC 2012 Intel s Investment in Manufacturing New Capacity for 14nm and Beyond D1X Oregon Development Fab Fab 42 Arizona High Volume Fab 22nm Fab Upgrades D1D Oregon