A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
|
|
|
- Vincent Stephens
- 5 years ago
- Views:
Transcription



1 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey Martin Berzins Thanks to: TACC Team for early access to Stampede John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens and Steve Parker, Nvidia



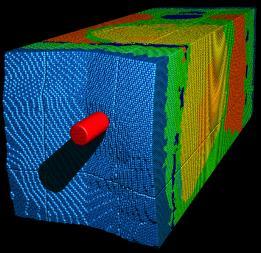



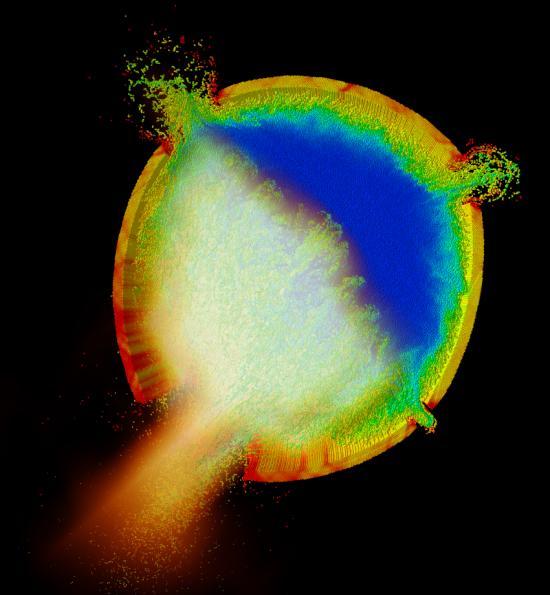
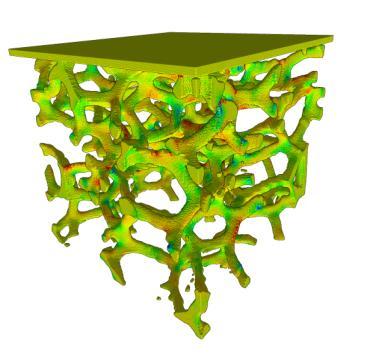


2 Uintah Overview Parallel, adaptive multi-physics framework Fluid-structure interaction problems Patch-based AMR using: particles and mesh-based fluid-solve Plume Fires Sandstone Compaction Explosions Foam Compaction Carbon Capture Clean Coal Boiler Industrial Flares Shaped Charges Virtual Soldier

3 Uintah - Scalability Patch-based domain decomposition Asynchronous task-based paradigm 256K cores Jaguar XK6 Cores 95% weak scaling efficiency & 60% strong scaling efficiency Multi-threaded MPI shared memory model on-node 1 Scalable, efficient, lock-free data structures 2 1. Q. Meng, M. Berzins, and J. Schmidt. Using Hybrid Parallelism to Improve Memory Use in the Uintah Framework. In Proc. of the 2011 TeraGrid Conference (TG11), Salt Lake City, Utah, Q. Meng and M. Berzins. Scalable Large-scale Fluid-structure Interaction Solvers in the Uintah Framework via Hybrid Task-based Parallelism Algorithms. Concurrency and Computation: Practice and Experience 2012, Submitted

4 Uintah Task-Based Approach Task Graph Directed Acyclic Graph Asynchronous, out of order execution of tasks Multi-stage work queue design Task basic unit of work Key idea C++ method with computation Allows Uintah to be generalized to support co-processors and accelerators 4 patch, single level ICE task graph No sweeping code changes





5 Emergence of Heterogeneous Systems Xeon Phi GPU + TACC Stampede 1000s of Xeon Phi Co-processors Multi-core CPU DOE Titan 1000s of Nvidia Kepler GPUs Motivation - Accelerate Uintah Components Utilize all on-node computational resources Uintah s asynchronous task-based approach well suited for Co-processors and Accelerator designs Natural progression: Accelerator & Co-processor Tasks

6 Unified Heterogeneous Scheduler & Runtime GPU support on Keeneland and Titan
7 The Emergence of the Intel Xeon Phi
8 Intel Xeon Phi What is it? Co-processor PCI Express card Light weight Linux OS (busy box) Dense, simplified processor Many power-hungry operations removed Wider vector unit Wider hardware thread count Many Integrated Core architecture, aka MIC Knights Corner (code name) Intel Xeon Phi Co-processor (product name)
9 Intel Xeon Phi What is it? Leverage x86 architecture (CPU with many cores) simpler x86 cores, allow more compute throughput Leverage existing x86 programming models Dedicate much of the silicon to FP ops Cache coherent Increase floating-point throughput Strip expensive features out-of-order execution branch prediction Wide SIMD registers for more throughput Fast (GDDR5) memory on card

10 Intel Xeon Phi George Chrysos, Intel, Hot Chips 24 (2012):

11 4 Hardware threads/core Intel Xeon Phi George Chrysos, Intel, Hot Chips 24 (2012):
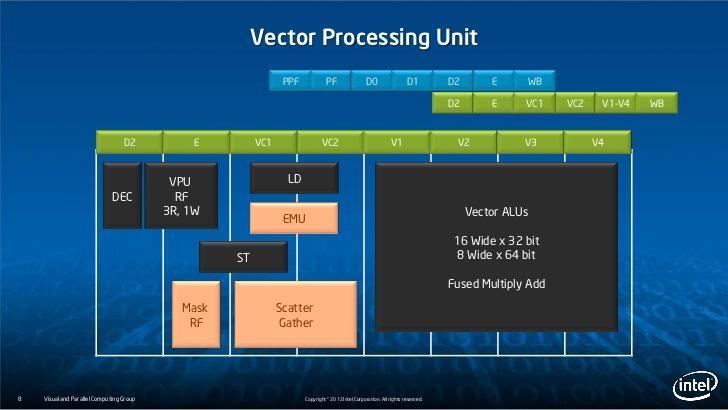
12 Intel Xeon Phi George Chrysos, Intel, Hot Chips 24 (2012):
13 Programming for the Intel Xeon Phi and TACC Stampede System
14 Programming Advantages Intel s MIC is based on x86 technology x86 cores w/ caches and cache coherency SIMD instruction set Programming for MIC is similar to programming for CPUs Familiar languages: C/C++ and Fortran Familiar parallel programming models: OpenMP & MPI MPI on host and on the coprocessor Any code can run on MIC, not just kernels Optimizing for MIC is similar to optimizing for CPUs Optimize once, run anywhere Early MIC porting efforts for codes in the field are frequently doubling performance on Sandy Bridge.
15 Xeon Phi Programming Models Traditional Cluster Pure MPI and MPI+X X: OpenMP, TBB, Cilk+, OpenCL, Native Phi Use Phi and run OpenMP or MPI programs directly MPI tasks on Host and Phi Treat the Phi (mostly) like another host Pure MPI and MPI+X MPI on Host, Offload to Xeon Phi Targeted offload through OpenMP extensions Automatically offload some library routines with MKL

16 Xeon Phi Execution Models
17 Xeon Phi Execution Models Host Only Ignore Xeon Phi cards Native Compile with mmic, MPI/OpenMP/Pthreads Single node only, can t run multi-node jobs Need one MPI rank on a host CPU Offload MPI inter-node, OpenMP on-node Synchronous no overlapping Asynchronous overlapping with signal/wait Symmetric MPI internode, OpenMP / Pthreads on-node Use both host and co-processor simultaneously
18 NSF Stampede System Texas Advanced Computing Center $27.5M acquisition 10 petaflops (PF) peak performance 2+ PF Linux cluster 6400 Dell DCS C8220X nodes 2.7GHz Intel Xeon E5 (Sandy Bridge) 102,400 total cores 56Gb/s FDR Mellanox InfiniBand 7+ PF Intel Xeon Phi Coprocessor (1.0GHz cores) 500,000+ total cores TACC has a special release: Intel Xeon Phi SE10P 14+ PB disk, 150GB/s 16 1TB shared memory nodes 128 NVIDIA Tesla K20 GPUs
19 Stampede Processor Specs Arch. Features Xeon E5 (Sandy Bridge) Xeon Phi SE10P Frequency 2.7GHz+turbo 1.0GHz +turbo Cores 8 61 HW Threads/core 2 4 Vector Size 256 bits, 4 doubles, 8 singles 512 bits, 8 doubles, 16 singles Inst. Pipeline Out of Order In order Registers Caches L1:32KB, L2:256KB, L3:20MB L132KB, L2:512KB Memory 2 GB/core 128 MB/core Sustained Memory BW 75 GB/s 170 GB/s Sustain Peak FLOPS 1 thread/core 2 threads/core Instruction Set x86+ AVX x86+ new vector instructions
20 Stampede Compute Node Comm layer & Virtual IP Service For MIC CPUs and MIC appear as separate HOSTS ( symmetric computing) PCIe X16 Two Xeon E5 8-core CPUs 16 cores 32G RAM Xeon Phi Coprocessor 61 lightweight cores 8G RAM Each core has 4 hardware threads Runs micro Linux OS (BusyBox)
 3000 ft 2 0.")
21 TACC Facilities Footprint (Stampede & Ranger) Stampede: 8000 ft 2 10 PF 6.5 MW Capabilities: 20x Footprint: 2x Ranger: (decomissioned) 3000 ft PF 3 MW InfiniBand (fat-tree) ~75 Miles of InfiniBand Cables Stampede footprint figure courtesy, Bill Barth, TACC
22 Preliminary Experiences with the Uintah Framework on Intel Xeon Phi and Stampede



23 Host-only Model Incompressible turbulent flow Intel MPI issues beyond 2048 cores (seg faults) MVAPICH2 required for larger core counts Using Hypre with a conjugate gradient solver Preconditioned with geometric multi-grid Red Black Gauss Seidel relaxation - each patch
24 TIme Per Timestep Uintah on Xeon Phi Native Model Compile with mmic (cross compiling) 128 AMR MPMICE Need to build all Uintah required 3p libraries libxml2 libz MPI pthread pthread w/ lockfree dw Run Uintah natively on Xeon Phi within 1 day Xeon Phi Threads/Processes Single Xeon Phi Card 2 MPI processes per Phi core, up to 120 processes 2 threads per Phi core, up to 120 threads Lock-free multi-threaded MPI
25 Unified Heterogeneous Scheduler & Runtime Offload Model Completed tasks MIC Kernels Running Device Task Running Device Task PUT GET Device Data Warehouse Running CPU Task Signals H2D copy D2H copy MPI sends MPI recvs CPU Threads Running CPU Task PUT GET Shared Scheduler Objects (host MEM) Task Graph Internal ready tasks Running CPU Task Device ready tasks Device Task Queues Device-enabled tasks ready tasks CPU Task Queues PUT GET MPI Data Ready Data Warehouse (variables) Network
26 Uintah on Xeon Phi Offload Model Use compiler directives (#pragma) Offload target: #pragma offload target(mic:0) OpenMP: #pragma omp parallel Find copy in/out variables Functions called in MIC must be defined with attribute ((target(mic))) Hard for Uintah to use offload mode Rewrite highly templated C++ methods with simple C/C++ so they can be called on the Xeon Phi Have to use OpenMP: Uintah currently use MPI+ Pthreads Less effort than GPU port, but still significant work for complex code such as Uintah
27 Uintah on Xeon Phi Symmetric Model Best fits current Uintah model Xeon Phi directly calls MPI Two MPI processes per node: Use Pthreads on both host CPU and Xeon Phi: 1 MPI process on host 16 threads 1 MPI process on MIC up to 120 threads Currently only Intel MPI supported mpiexec.hydra -n 8./sus nthreads 16 : -n 8./sus.mic nthreads 120 No major Uintah code changes
28 Unified Heterogeneous Scheduler & Runtime (symmetric) Device Threads completed task completed task Running Task Running Task Running Task PUT GET PUT GET Device Data Warehouse receives Device Virtual Network Device Memory Task Graph New tasks Task Queues Ready task (variables directory) PCI-E Host Threads Host Memory Task Graph completed task completed task Runing Task Running Task Running Task Task Queues PUT GET PUT GET Ready task Host Data Warehouse (variables directory) sends receives Network New tasks
29 Symmetric Model Challenges Native debugging with gdb Built gdb for ourselves from source Weren t aware of idb / idbc (need idb server/client setup) Different floating point accuracy on host and co-processor p= c= b=p/c b=162 Host-only Model Symmetric Model b= Rank0: CPU MPI OK Rank0: CPU MPI Size Mismatch MPI message mismatch issue Any control logic based on result of FP calculation may choose different execution routes on Xeon Phi and host Size of MPI send/rcv buffers determined by FP result Caused Uintah MPI message mismatch (MSG_TRUNC) Rank1: CPU b=162 Rank1: MIC b=
30 Exectuion TIme Scaling Results on Xeon Phi Symmetric Model AMR MPMICE (multi Xeon Phi) Xeon Phi Cards 60 threads per MPI process, 2 MPI processes per Xeon Phi card 16 threads per MPI process, 1 MPI processes per host CPU Scaling results limited by development queue allowances for symmetric model
31 Load Balancer Current and Future Work Cannot treat all MPI ranks uniformly Profile CPU and Xeon Phi separately Need separate forecast model for each. Address different cache sizes New regridder to generate large patches for CPU and small patches for Xeon Phi Explicitly use long vector Asynchronous offload model _Offload_signaled(mic_no, &c)

32 Questions?
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System
 Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins, Todd Harman Scientific Computing and Imaging Institute & University of Utah I. Uintah
Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins, Todd Harman Scientific Computing and Imaging Institute & University of Utah I. Uintah
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Alan Humphrey, Qingyu Meng, Brad Peterson, Martin Berzins Scientific Computing and Imaging Institute, University of Utah
 Alan Humphrey, Qingyu Meng, Brad Peterson, Martin Berzins Scientific Computing and Imaging Institute, University of Utah I. Uintah Framework Overview II. Extending Uintah to Leverage GPUs III. Target Application
Alan Humphrey, Qingyu Meng, Brad Peterson, Martin Berzins Scientific Computing and Imaging Institute, University of Utah I. Uintah Framework Overview II. Extending Uintah to Leverage GPUs III. Target Application
Scalability of Uintah Past Present and Future
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps, INCITE, XSEDE Scalability of Uintah Past Present and Future Martin Berzins Qingyu Meng John Schmidt,
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps, INCITE, XSEDE Scalability of Uintah Past Present and Future Martin Berzins Qingyu Meng John Schmidt,
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Cost Estimation Algorithms for Dynamic Load Balancing of AMR Simulations
 Cost Estimation Algorithms for Dynamic Load Balancing of AMR Simulations Justin Luitjens, Qingyu Meng, Martin Berzins, John Schmidt, et al. Thanks to DOE for funding since 1997, NSF since 2008, TACC, NICS
Cost Estimation Algorithms for Dynamic Load Balancing of AMR Simulations Justin Luitjens, Qingyu Meng, Martin Berzins, John Schmidt, et al. Thanks to DOE for funding since 1997, NSF since 2008, TACC, NICS
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Preliminary Experiences with the Uintah Framework on Intel Xeon Phi and Stampede
 1 Preliminary Experiences with the Uintah Framework on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins UUSCI-2013-002 Scientific Computing and Imaging Institute March
1 Preliminary Experiences with the Uintah Framework on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins UUSCI-2013-002 Scientific Computing and Imaging Institute March
Improving Uintah s Scalability Through the Use of Portable
 Improving Uintah s Scalability Through the Use of Portable Kokkos-Based Data Parallel Tasks John Holmen1, Alan Humphrey1, Daniel Sunderland2, Martin Berzins1 University of Utah1 Sandia National Laboratories2
Improving Uintah s Scalability Through the Use of Portable Kokkos-Based Data Parallel Tasks John Holmen1, Alan Humphrey1, Daniel Sunderland2, Martin Berzins1 University of Utah1 Sandia National Laboratories2
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT 84112 USA Email: qymeng@sci.utah.edu
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT 84112 USA Email: qymeng@sci.utah.edu
Native Computing and Optimization. Hang Liu December 4 th, 2013
 Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
Overview of Intel Xeon Phi Coprocessor
 Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
An Applications-Driven path from Terascale to Exascale (?) with the Asynchronous Many Task (AMT) Uintah Framework
 with the Asynchronous Many Task (AMT) Uintah Framework") An Applications-Driven path from Terascale to Exascale (?) with the Asynchronous Many Task (AMT) Uintah Framework Martin Berzins Scientific Imaging and Computing Institute University of Utah 1. Foundations:
An Applications-Driven path from Terascale to Exascale (?) with the Asynchronous Many Task (AMT) Uintah Framework Martin Berzins Scientific Imaging and Computing Institute University of Utah 1. Foundations:
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Solving Petascale Turbulent Combustion Problems with the Uintah Software
 Solving Petascale Turbulent Combustion Problems with the Uintah Software Martin Berzins DOE NNSA PSAAP2 Center Thanks to DOE ASCI (97-10), NSF, DOE NETL+NNSA, NSF, INCITE, XSEDE, ALCC, ORNL, ALCF for funding
Solving Petascale Turbulent Combustion Problems with the Uintah Software Martin Berzins DOE NNSA PSAAP2 Center Thanks to DOE ASCI (97-10), NSF, DOE NETL+NNSA, NSF, INCITE, XSEDE, ALCC, ORNL, ALCF for funding
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Native Computing and Optimization on the Intel Xeon Phi Coprocessor John D. McCalpin mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps Controlling Execution Tuning Vectorization
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Investigation of Intel MIC for implementation of Fast Fourier Transform
 Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
HPC. Accelerating. HPC Advisory Council Lugano, CH March 15 th, Herbert Cornelius Intel
 15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Native Computing and Optimization on the Intel Xeon Phi Coprocessor. Lars Koesterke John D. McCalpin
 Native Computing and Optimization on the Intel Xeon Phi Coprocessor Lars Koesterke John D. McCalpin lars@tacc.utexas.edu mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps
Native Computing and Optimization on the Intel Xeon Phi Coprocessor Lars Koesterke John D. McCalpin lars@tacc.utexas.edu mccalpin@tacc.utexas.edu Intro (very brief) Outline Compiling & Running Native Apps
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Petascale Parallel Computing and Beyond. General trends and lessons. Martin Berzins
 Petascale Parallel Computing and Beyond General trends and lessons Martin Berzins 1. Technology Trends 2. Towards Exascale 3. Trends in programming large scale systems What kind of machine will you use
Petascale Parallel Computing and Beyond General trends and lessons Martin Berzins 1. Technology Trends 2. Towards Exascale 3. Trends in programming large scale systems What kind of machine will you use
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
AACE: Applications. Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn-
 AACE: Applications R. Glenn Brook Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn- brook@tennessee.edu Ryan C. Hulguin Computational Science
AACE: Applications R. Glenn Brook Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn- brook@tennessee.edu Ryan C. Hulguin Computational Science
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Hybrid MPI - A Case Study on the Xeon Phi Platform
 Hybrid MPI - A Case Study on the Xeon Phi Platform Udayanga Wickramasinghe Center for Research on Extreme Scale Technologies (CREST) Indiana University Greg Bronevetsky Lawrence Livermore National Laboratory
Hybrid MPI - A Case Study on the Xeon Phi Platform Udayanga Wickramasinghe Center for Research on Extreme Scale Technologies (CREST) Indiana University Greg Bronevetsky Lawrence Livermore National Laboratory
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
An Extension of XcalableMP PGAS Lanaguage for Multi-node GPU Clusters
 An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
Many-core Processor Programming for beginners. Hongsuk Yi ( 李泓錫 ) KISTI (Korea Institute of Science and Technology Information)
 KISTI (Korea Institute of Science and Technology Information)") Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
How to Boost the Performance of Your MPI and PGAS Applications with MVAPICH2 Libraries
 How to Boost the Performance of Your MPI and PGAS s with MVAPICH2 Libraries A Tutorial at the MVAPICH User Group (MUG) Meeting 18 by The MVAPICH Team The Ohio State University E-mail: panda@cse.ohio-state.edu
How to Boost the Performance of Your MPI and PGAS s with MVAPICH2 Libraries A Tutorial at the MVAPICH User Group (MUG) Meeting 18 by The MVAPICH Team The Ohio State University E-mail: panda@cse.ohio-state.edu
Intro to Parallel Computing
 Outline Intro to Parallel Computing Remi Lehe Lawrence Berkeley National Laboratory Modern parallel architectures Parallelization between nodes: MPI Parallelization within one node: OpenMP Why use parallel
Outline Intro to Parallel Computing Remi Lehe Lawrence Berkeley National Laboratory Modern parallel architectures Parallelization between nodes: MPI Parallelization within one node: OpenMP Why use parallel
Does the Intel Xeon Phi processor fit HEP workloads?
 Does the Intel Xeon Phi processor fit HEP workloads? October 17th, CHEP 2013, Amsterdam Andrzej Nowak, CERN openlab CTO office On behalf of Georgios Bitzes, Havard Bjerke, Andrea Dotti, Alfio Lazzaro,
Does the Intel Xeon Phi processor fit HEP workloads? October 17th, CHEP 2013, Amsterdam Andrzej Nowak, CERN openlab CTO office On behalf of Georgios Bitzes, Havard Bjerke, Andrea Dotti, Alfio Lazzaro,
A4. Intro to Parallel Computing
 Self-Consistent Simulations of Beam and Plasma Systems Steven M. Lund, Jean-Luc Vay, Rémi Lehe and Daniel Winklehner Colorado State U., Ft. Collins, CO, 13-17 June, 2016 A4. Intro to Parallel Computing
Self-Consistent Simulations of Beam and Plasma Systems Steven M. Lund, Jean-Luc Vay, Rémi Lehe and Daniel Winklehner Colorado State U., Ft. Collins, CO, 13-17 June, 2016 A4. Intro to Parallel Computing
Intel Software Development Products for High Performance Computing and Parallel Programming
 Intel Software Development Products for High Performance Computing and Parallel Programming Multicore development tools with extensions to many-core Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN
Intel Software Development Products for High Performance Computing and Parallel Programming Multicore development tools with extensions to many-core Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming