Raven3: 28nm RISC-V Vector Processor with On-Chip DC/DC Convertors
|
|
|
- Laurence Nicholson
- 5 years ago
- Views:
Transcription



1 Raven3: 28nm RISC-V Vector Processor with On-Chip DC/DC Convertors Brian Zimmer 1, Yunsup Lee 1, Alberto Puggelli 1, Jaehwa Kwak 1, Ruzica Jevtic 1, Ben Keller 1, Stevo Bailey 1, Milovan Blagojevic 1,2, Pi-Feng Chiu 1, Hanh-Phuc Le 1, Po-Hung Chen 1, Nicholas Sutardja 1, Rimas Avizienis 1, Andrew Waterman 1, Brian Richards 1, Philippe Flatresse 2, Elad Alon 1, Krste Asanovic 1, and Borivoje Nikolic 1 1 University of California, Berkeley, USA 2 STMicroelectronics, Crolles, France 6/30/2015, RISC-V Workshop
2 Motivation Dynamic voltage and frequency scaling (DVFS) maximizes energy efficiency Fixed voltage Performance Requirement DVFS voltage Off-chip conversion Slow mode transitions Limited voltage domains Costly -chip components Time On-chip conversion Fast transitions Many domains No -chip components 2
3 Project Goals Energyefficient Fine-grained DVFS High conversion efficiency low-cost Entirely on-chip converter Low area overhead processor Runs Linux Realistic digital load 3
4 Integrated Voltage Regulators Method Linear regulator (eg. Toprak-Deniz ISSCC2014) Buck converter (eg. Kurd ISSCC2014) Efficiency (0.5put) <50%?%-90% Off-chip components Area overhead Interleaved switchedcapacitor (eg. Kim ISSCC2015 1, Clerc ISSCC ) Simultaneous switched-capacitor with adaptive clock (Proposed) 40%-65% 1 65%-82% 2 85% 4
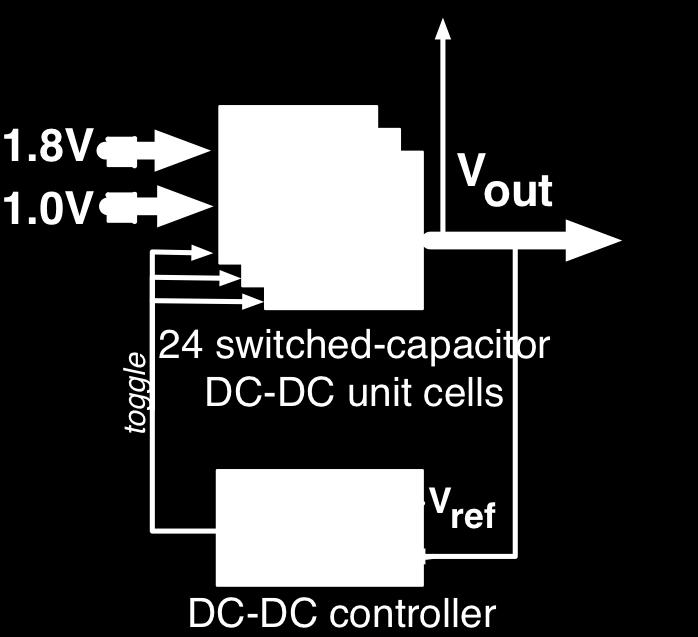
5 V high V ideal V low Proposed Solution Switch all converters simultaneously to avoid charge sharing Traditional Interleaving 1.8V 1.0V Charge sharing losses 2Ghz ref 1.0V To -chip oscilloscope To -chip oscilloscope Simultaneous Switching V high V ideal FSM V low toggle 1.8V 1.0V 1.8V 1.8V V 1.0V switched-capacitor 24 switched-capacitor 24 switched-capacitor 24 switched-capacitor DC-DC unit DC-DC cells unit DC-DC cells Shared unit DC-DC Func. cells Shared Units unit Func. cells Shared int Units int Fu (0.19 mm 2 64-bit Integer Multiplier ) (0.19 mm 2 64-bit Integer Multiplier ) (0.19 mm 2 64-bit Integer ) (0.19 mm 2 ) toggle + toggle V FSM ref out + C RISC-V scalar RISC-V corescalar RISC-V core Vec sc Scalar RF Scalar FPU RF Scalar Vecto FPU RF (16KB Vec int custom 8 C Single-Precision Single-Precision FMA Single-Precisi FMA Double-Precision Double-Precision FMA Double-Precis FMAVector V ref FSM toggle 16KB Scalar 16KB 32KB Scalar 16KB Shared 32K Sca DC-DC controller DC-DC controller DC-DC Inst. controller Cache DC-DC Inst. controller Cache Data Cache Inst. Cac Dat (Custom 8T (Custom (Custom 8T (Custom 8T (C8 SRAM Macros) SRAM Macros) SRAM SRAM Macros) Mac SRA 2Ghz 2Ghz 2Ghz clk Arbiter ref ref clk ref clk clk Async. FIFO/Level Async. shifters FIFO/Level Async. shifters FIFO/Le As 1.0V Adaptive clock 1.0V Adaptive clock 1.0V Adaptive clock Adaptive clock between domains between domains betwee generator generator generator generator int + To -chip oscillosco To -chi V ref FSM No charge sharing! Clock frequency adapts to track the voltage ripple Digital IO pads Digital to wire-bonded IO pads Digital to chip-on wire-bo IO p To/from -chip To/from FPGA -chip FSB To/from FPGA and -chip DRAM FSB To/from FPGA and -chip DRAM FSB FPG and int + V ref 5







6 Chip Architecture CORE (1.19 mm 2 ) 6

7 Floorplan ST 28nm FDSOI Die area: 2.37mm 2 Core area: 1.19mm 2 Converter area: 0.19mm 2 (16%) MOS+MOM (to M3) density: 11fF/µm 2 Core 7
8 Reconfigurable SC Converters Four output voltages, single unit cell Mode 1.8V 1/2 Mode 2/3 Mode 1/2 Mode (~) (~0.9V) (~0.67V) (~0.5V) Simple lower bound control V ref 1.8V 1.8V + FSM 2GHz comparator toggle Simultaneous switching V ref toggle V i V lo 8
 Adaptive system")
9 Self-Adjusting Clock Generator Block Diagram DLL 2Ghz input, 16 phases Tunable Replica Path Controller Select closest edge Replica tracks critical path with voltage ripple Controller quantizes clock edge (Tunable Replica Path) Adaptive system clock 9



10 Test setup Host: Zedboard (ARM+FPGA, network accessible) Motherboard: Programmable supplies Daughterboard: Chip-on-board 10
11 Vout Measurements Fast converter mode transitions enable extremely fine-grain DVFS algorithms 11
12 GFLOPS/W Double-precision matrix-multiplication used as energy-efficiency metric GFLOPS/W inverse of energy/operation 28nm FDSOI ers high energy efficiency and 4 converter modes cover wide operating range 12
13 Conclusion Energy-efficient 28nm processor featuring: 1. Fine-grained and wide-range DVFS 20ns transitions to 0.45V 2. Entirely on-chip voltage conversion Simultaneous switched-capacitor 3. High efficiency 80% across wide voltage range 4. Extreme energy efficiency 26 GFLOPS/W with on-chip conversion 13

14 Acknowledgements Funding: BWRC members, ASPIRE members, DARPA PERFECT Award Number HR , Intel ARO, AMD, GRC, Marie Curie FP7, NSF GRFP, NVIDIA Fellowship Fabrication donation by STMicroelectronics. Tom Burd, James Dunn, Olivier Thomas, and Andrei Vladimirescu 14
Raven: A CHISEL designed 28nm RISC-V Vector Processor with Integrated Switched- Capacitor DC-DC Converters & Adaptive Clocking
 Raven: A CHISEL designed 28nm RISC-V Vector Processor with Integrated Switched- Capacitor DC-DC Converters & Adaptive Clocking Yunsup Lee, Brian Zimmer, Andrew Waterman, Alberto Puggelli, Jaehwa Kwak,
Raven: A CHISEL designed 28nm RISC-V Vector Processor with Integrated Switched- Capacitor DC-DC Converters & Adaptive Clocking Yunsup Lee, Brian Zimmer, Andrew Waterman, Alberto Puggelli, Jaehwa Kwak,
Energy-Efficient RISC-V Processors in 28nm FDSOI
 Energy-Efficient RISC-V Processors in 28nm FDSOI Borivoje Nikolić Department of Electrical Engineering and Computer Sciences University of California, Berkeley bora@eecs.berkeley.edu 26 September 2017
Energy-Efficient RISC-V Processors in 28nm FDSOI Borivoje Nikolić Department of Electrical Engineering and Computer Sciences University of California, Berkeley bora@eecs.berkeley.edu 26 September 2017
Factors which influence in many core processors
 Factors which influence in many core processors ABSTRACT: The applications for multicore and manycore microprocessors as RISC-V are currently useful for the advantages of their friendly nature, compared
Factors which influence in many core processors ABSTRACT: The applications for multicore and manycore microprocessors as RISC-V are currently useful for the advantages of their friendly nature, compared
Simpler, More Efficient Design
 Simpler, More Efficient Design Borivoje Nikolić Electrical Engineering and Computer Sciences, University of California, Berkeley, CA, USA E-mail: bora@eecs.berkeley.edu Abstract Design of custom integrated
Simpler, More Efficient Design Borivoje Nikolić Electrical Engineering and Computer Sciences, University of California, Berkeley, CA, USA E-mail: bora@eecs.berkeley.edu Abstract Design of custom integrated
A 45nm 1.3GHz 16.7 Double-Precision GFLOPS/W RISC-V Processor with Vector Accelerators"
 A 45nm 1.3GHz 16.7 Double-Precision GFLOPS/W ISC-V Processor with Vector Accelerators" Yunsup Lee 1, Andrew Waterman 1, imas Avizienis 1,! Henry Cook 1, Chen Sun 1,2,! Vladimir Stojanovic 1,2, Krste Asanovic
A 45nm 1.3GHz 16.7 Double-Precision GFLOPS/W ISC-V Processor with Vector Accelerators" Yunsup Lee 1, Andrew Waterman 1, imas Avizienis 1,! Henry Cook 1, Chen Sun 1,2,! Vladimir Stojanovic 1,2, Krste Asanovic
A Retrospective on Par Lab Architecture Research
 A Retrospective on Par Lab Architecture Research Par Lab SIGARCH Krste Asanovic, Rimas Avizienis, Jonathan Bachrach, Scott Beamer, Sarah Bird, Alex Bishara, Chris Celio, Henry Cook, Ben Keller, Yunsup
A Retrospective on Par Lab Architecture Research Par Lab SIGARCH Krste Asanovic, Rimas Avizienis, Jonathan Bachrach, Scott Beamer, Sarah Bird, Alex Bishara, Chris Celio, Henry Cook, Ben Keller, Yunsup
Dynamic Voltage and Frequency Scaling Circuits with Two Supply Voltages
 Dynamic Voltage and Frequency Scaling Circuits with Two Supply Voltages ECE Department, University of California, Davis Wayne H. Cheng and Bevan M. Baas Outline Background and Motivation Implementation
Dynamic Voltage and Frequency Scaling Circuits with Two Supply Voltages ECE Department, University of California, Davis Wayne H. Cheng and Bevan M. Baas Outline Background and Motivation Implementation
Lecture 41: Introduction to Reconfigurable Computing
 inst.eecs.berkeley.edu/~cs61c CS61C : Machine Structures Lecture 41: Introduction to Reconfigurable Computing Michael Le, Sp07 Head TA April 30, 2007 Slides Courtesy of Hayden So, Sp06 CS61c Head TA Following
inst.eecs.berkeley.edu/~cs61c CS61C : Machine Structures Lecture 41: Introduction to Reconfigurable Computing Michael Le, Sp07 Head TA April 30, 2007 Slides Courtesy of Hayden So, Sp06 CS61c Head TA Following
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications
 A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
Hwacha V4: Decoupled Data Parallel Custom Extension. Colin Schmidt, Albert Ou, Krste Asanović UC Berkeley
 Hwacha V4: Decoupled Data Parallel Custom Extension Colin Schmidt, Albert Ou, Krste Asanović UC Berkeley Introduction Data-parallel, custom ISA extension to RISC-V with a configurable ASIC-focused implementation
Hwacha V4: Decoupled Data Parallel Custom Extension Colin Schmidt, Albert Ou, Krste Asanović UC Berkeley Introduction Data-parallel, custom ISA extension to RISC-V with a configurable ASIC-focused implementation
Strober: Fast and Accurate Sample-Based Energy Simulation Framework for Arbitrary RTL
 Strober: Fast and Accurate Sample-Based Energy Simulation Framework for Arbitrary RTL Donggyu Kim, Adam Izraelevitz, Christopher Celio, Hokeun Kim, Brian Zimmer, Yunsup Lee, Jonathan Bachrach, Krste Asanović
Strober: Fast and Accurate Sample-Based Energy Simulation Framework for Arbitrary RTL Donggyu Kim, Adam Izraelevitz, Christopher Celio, Hokeun Kim, Brian Zimmer, Yunsup Lee, Jonathan Bachrach, Krste Asanović
How to build a Megacore microprocessor. by Andreas Olofsson (MULTIPROG WORKSHOP 2017)
") How to build a Megacore microprocessor by Andreas Olofsson (MULTIPROG WORKSHOP 2017) 1 Disclaimers 2 This presentation summarizes work done by Adapteva from 2008-2016. Statements and opinions are my own
How to build a Megacore microprocessor by Andreas Olofsson (MULTIPROG WORKSHOP 2017) 1 Disclaimers 2 This presentation summarizes work done by Adapteva from 2008-2016. Statements and opinions are my own
Lecture-14 (Memory Hierarchy) CS422-Spring
 CS422-Spring") Lecture-14 (Memory Hierarchy) CS422-Spring 2018 Biswa@CSE-IITK The Ideal World Instruction Supply Pipeline (Instruction execution) Data Supply - Zero-cycle latency - Infinite capacity - Zero cost - Perfect
Lecture-14 (Memory Hierarchy) CS422-Spring 2018 Biswa@CSE-IITK The Ideal World Instruction Supply Pipeline (Instruction execution) Data Supply - Zero-cycle latency - Infinite capacity - Zero cost - Perfect
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering. Lecture 6 - Memory
 CS 152 Computer Architecture and Engineering Lecture 6 - Memory Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste! http://inst.eecs.berkeley.edu/~cs152!
CS 152 Computer Architecture and Engineering Lecture 6 - Memory Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste! http://inst.eecs.berkeley.edu/~cs152!
A 167-processor 65 nm Computational Platform with Per-Processor Dynamic Supply Voltage and Dynamic Clock Frequency Scaling
 A 167-processor 65 nm Computational Platform with Per-Processor Dynamic Supply Voltage and Dynamic Clock Frequency Scaling Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge,
A 167-processor 65 nm Computational Platform with Per-Processor Dynamic Supply Voltage and Dynamic Clock Frequency Scaling Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge,
KiloCore: A 32 nm 1000-Processor Array
 KiloCore: A 32 nm 1000-Processor Array Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas University of California, Davis VLSI Computation
KiloCore: A 32 nm 1000-Processor Array Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas University of California, Davis VLSI Computation
Asymmetry-Aware Work-Stealing Runtimes
 Asymmetry-Aware Work-Stealing Runtimes Christopher Torng, Moyang Wang, and Christopher atten School of Electrical and Computer Engineering Cornell University 43rd Int l Symp. on Computer Architecture,
Asymmetry-Aware Work-Stealing Runtimes Christopher Torng, Moyang Wang, and Christopher atten School of Electrical and Computer Engineering Cornell University 43rd Int l Symp. on Computer Architecture,
ECE 571 Advanced Microprocessor-Based Design Lecture 24
 ECE 571 Advanced Microprocessor-Based Design Lecture 24 Vince Weaver http://www.eece.maine.edu/ vweaver vincent.weaver@maine.edu 25 April 2013 Project/HW Reminder Project Presentations. 15-20 minutes.
ECE 571 Advanced Microprocessor-Based Design Lecture 24 Vince Weaver http://www.eece.maine.edu/ vweaver vincent.weaver@maine.edu 25 April 2013 Project/HW Reminder Project Presentations. 15-20 minutes.
Evaluation of RISC-V RTL with FPGA-Accelerated Simulation
 Evaluation of RISC-V RTL with FPGA-Accelerated Simulation Donggyu Kim, Christopher Celio, David Biancolin, Jonathan Bachrach, Krste Asanovic CARRV 2017 10/14/2017 Evaluation Methodologies For Computer
Evaluation of RISC-V RTL with FPGA-Accelerated Simulation Donggyu Kim, Christopher Celio, David Biancolin, Jonathan Bachrach, Krste Asanovic CARRV 2017 10/14/2017 Evaluation Methodologies For Computer
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Computer System Components
 Computer System Components CPU Core 1 GHz - 3.2 GHz 4-way Superscaler RISC or RISC-core (x86): Deep Instruction Pipelines Dynamic scheduling Multiple FP, integer FUs Dynamic branch prediction Hardware
Computer System Components CPU Core 1 GHz - 3.2 GHz 4-way Superscaler RISC or RISC-core (x86): Deep Instruction Pipelines Dynamic scheduling Multiple FP, integer FUs Dynamic branch prediction Hardware
Main Memory. EECC551 - Shaaban. Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
EECS Dept., University of California at Berkeley. Berkeley Wireless Research Center Tel: (510)
") A V Heterogeneous Reconfigurable Processor IC for Baseband Wireless Applications Hui Zhang, Vandana Prabhu, Varghese George, Marlene Wan, Martin Benes, Arthur Abnous, and Jan M. Rabaey EECS Dept., University
A V Heterogeneous Reconfigurable Processor IC for Baseband Wireless Applications Hui Zhang, Vandana Prabhu, Varghese George, Marlene Wan, Martin Benes, Arthur Abnous, and Jan M. Rabaey EECS Dept., University
OUTLINE Introduction Power Components Dynamic Power Optimization Conclusions
 OUTLINE Introduction Power Components Dynamic Power Optimization Conclusions 04/15/14 1 Introduction: Low Power Technology Process Hardware Architecture Software Multi VTH Low-power circuits Parallelism
OUTLINE Introduction Power Components Dynamic Power Optimization Conclusions 04/15/14 1 Introduction: Low Power Technology Process Hardware Architecture Software Multi VTH Low-power circuits Parallelism
COL862 - Low Power Computing
 COL862 - Low Power Computing Power Measurements using performance counters and studying the low power computing techniques in IoT development board (PSoC 4 BLE Pioneer Kit) and Arduino Mega 2560 Submitted
COL862 - Low Power Computing Power Measurements using performance counters and studying the low power computing techniques in IoT development board (PSoC 4 BLE Pioneer Kit) and Arduino Mega 2560 Submitted
BERKELEY PAR LAB. RAMP Gold Wrap. Krste Asanovic. RAMP Wrap Stanford, CA August 25, 2010
 RAMP Gold Wrap Krste Asanovic RAMP Wrap Stanford, CA August 25, 2010 RAMP Gold Team Graduate Students Zhangxi Tan Andrew Waterman Rimas Avizienis Yunsup Lee Henry Cook Sarah Bird Faculty Krste Asanovic
RAMP Gold Wrap Krste Asanovic RAMP Wrap Stanford, CA August 25, 2010 RAMP Gold Team Graduate Students Zhangxi Tan Andrew Waterman Rimas Avizienis Yunsup Lee Henry Cook Sarah Bird Faculty Krste Asanovic
Mainstream Computer System Components CPU Core 2 GHz GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation
: Dynamic scheduling, Hardware speculation") Mainstream Computer System Components CPU Core 2 GHz - 3.0 GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation One core or multi-core (2-4) per chip Multiple FP, integer
Mainstream Computer System Components CPU Core 2 GHz - 3.0 GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation One core or multi-core (2-4) per chip Multiple FP, integer
Mainstream Computer System Components
 Mainstream Computer System Components Double Date Rate (DDR) SDRAM One channel = 8 bytes = 64 bits wide Current DDR3 SDRAM Example: PC3-12800 (DDR3-1600) 200 MHz (internal base chip clock) 8-way interleaved
Mainstream Computer System Components Double Date Rate (DDR) SDRAM One channel = 8 bytes = 64 bits wide Current DDR3 SDRAM Example: PC3-12800 (DDR3-1600) 200 MHz (internal base chip clock) 8-way interleaved
A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing
 A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge, Michael Meeuwsen, Christine
A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge, Michael Meeuwsen, Christine
The T0 Vector Microprocessor. Talk Outline
 Slides from presentation at the Hot Chips VII conference, 15 August 1995.. The T0 Vector Microprocessor Krste Asanovic James Beck Bertrand Irissou Brian E. D. Kingsbury Nelson Morgan John Wawrzynek University
Slides from presentation at the Hot Chips VII conference, 15 August 1995.. The T0 Vector Microprocessor Krste Asanovic James Beck Bertrand Irissou Brian E. D. Kingsbury Nelson Morgan John Wawrzynek University
2D/3D Graphics Accelerator for Mobile Multimedia Applications. Ramchan Woo, Sohn, Seong-Jun Song, Young-Don
 RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
L évolution des architectures et des technologies d intégration des circuits intégrés dans les Data centers
 I N S T I T U T D E R E C H E R C H E T E C H N O L O G I Q U E L évolution des architectures et des technologies d intégration des circuits intégrés dans les Data centers 10/04/2017 Les Rendez-vous de
I N S T I T U T D E R E C H E R C H E T E C H N O L O G I Q U E L évolution des architectures et des technologies d intégration des circuits intégrés dans les Data centers 10/04/2017 Les Rendez-vous de
EECS 322 Computer Architecture Superpipline and the Cache
 EECS 322 Computer Architecture Superpipline and the Cache Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses powerpoint animation: please viewshow Summary:
EECS 322 Computer Architecture Superpipline and the Cache Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses powerpoint animation: please viewshow Summary:
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
FABRICATION TECHNOLOGIES
 FABRICATION TECHNOLOGIES DSP Processor Design Approaches Full custom Standard cell** higher performance lower energy (power) lower per-part cost Gate array* FPGA* Programmable DSP Programmable general
FABRICATION TECHNOLOGIES DSP Processor Design Approaches Full custom Standard cell** higher performance lower energy (power) lower per-part cost Gate array* FPGA* Programmable DSP Programmable general
Lecture 6 - Memory. Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
 CS 152 Computer Architecture and Engineering Lecture 6 - Memory Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
CS 152 Computer Architecture and Engineering Lecture 6 - Memory Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
The Memory Hierarchy 1
 The Memory Hierarchy 1 What is a cache? 2 What problem do caches solve? 3 Memory CPU Abstraction: Big array of bytes Memory memory 4 Performance vs 1980 Processor vs Memory Performance Memory is very slow
The Memory Hierarchy 1 What is a cache? 2 What problem do caches solve? 3 Memory CPU Abstraction: Big array of bytes Memory memory 4 Performance vs 1980 Processor vs Memory Performance Memory is very slow
A Non-Volatile Microcontroller with Integrated Floating-Gate Transistors
 A Non-Volatile Microcontroller with Integrated Floating-Gate Transistors Wing-kei Yu, Shantanu Rajwade, Sung-En Wang, Bob Lian, G. Edward Suh, Edwin Kan Cornell University 2 of 32 Self-Powered Devices
A Non-Volatile Microcontroller with Integrated Floating-Gate Transistors Wing-kei Yu, Shantanu Rajwade, Sung-En Wang, Bob Lian, G. Edward Suh, Edwin Kan Cornell University 2 of 32 Self-Powered Devices
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
The Design of the KiloCore Chip
 The Design of the KiloCore Chip Aaron Stillmaker*, Brent Bohnenstiehl, Bevan Baas DAC 2017: Design Challenges of New Processor Architectures University of California, Davis VLSI Computation Laboratory
The Design of the KiloCore Chip Aaron Stillmaker*, Brent Bohnenstiehl, Bevan Baas DAC 2017: Design Challenges of New Processor Architectures University of California, Davis VLSI Computation Laboratory
Physical Implementation of the DSPIN Network-on-Chip in the FAUST Architecture
 1 Physical Implementation of the DSPI etwork-on-chip in the FAUST Architecture Ivan Miro-Panades 1,2,3, Fabien Clermidy 3, Pascal Vivet 3, Alain Greiner 1 1 The University of Pierre et Marie Curie, Paris,
1 Physical Implementation of the DSPI etwork-on-chip in the FAUST Architecture Ivan Miro-Panades 1,2,3, Fabien Clermidy 3, Pascal Vivet 3, Alain Greiner 1 1 The University of Pierre et Marie Curie, Paris,
Memory in Digital Systems
 MEMORIES Memory in Digital Systems Three primary components of digital systems Datapath (does the work) Control (manager) Memory (storage) Single bit ( foround ) Clockless latches e.g., SR latch Clocked
MEMORIES Memory in Digital Systems Three primary components of digital systems Datapath (does the work) Control (manager) Memory (storage) Single bit ( foround ) Clockless latches e.g., SR latch Clocked
edram to the Rescue Why edram 1/3 Area 1/5 Power SER 2-3 Fit/Mbit vs 2k-5k for SRAM Smaller is faster What s Next?
 edram to the Rescue Why edram 1/3 Area 1/5 Power SER 2-3 Fit/Mbit vs 2k-5k for SRAM Smaller is faster What s Next? 1 Integrating DRAM and Logic Integrate with Logic without impacting logic Performance,
edram to the Rescue Why edram 1/3 Area 1/5 Power SER 2-3 Fit/Mbit vs 2k-5k for SRAM Smaller is faster What s Next? 1 Integrating DRAM and Logic Integrate with Logic without impacting logic Performance,
Design Objectives of the 0.35µm Alpha Microprocessor (A 500MHz Quad Issue RISC Microprocessor)
") Design Objectives of the 0.35µm Alpha 21164 Microprocessor (A 500MHz Quad Issue RISC Microprocessor) Gregg Bouchard Digital Semiconductor Digital Equipment Corporation Hudson, MA 1 Outline 0.35µm Alpha
Design Objectives of the 0.35µm Alpha 21164 Microprocessor (A 500MHz Quad Issue RISC Microprocessor) Gregg Bouchard Digital Semiconductor Digital Equipment Corporation Hudson, MA 1 Outline 0.35µm Alpha
Tiered-Latency DRAM: A Low Latency and A Low Cost DRAM Architecture
 Tiered-Latency DRAM: A Low Latency and A Low Cost DRAM Architecture Donghyuk Lee, Yoongu Kim, Vivek Seshadri, Jamie Liu, Lavanya Subramanian, Onur Mutlu Carnegie Mellon University HPCA - 2013 Executive
Tiered-Latency DRAM: A Low Latency and A Low Cost DRAM Architecture Donghyuk Lee, Yoongu Kim, Vivek Seshadri, Jamie Liu, Lavanya Subramanian, Onur Mutlu Carnegie Mellon University HPCA - 2013 Executive
Z-RAM Ultra-Dense Memory for 90nm and Below. Hot Chips David E. Fisch, Anant Singh, Greg Popov Innovative Silicon Inc.
 Z-RAM Ultra-Dense Memory for 90nm and Below Hot Chips 2006 David E. Fisch, Anant Singh, Greg Popov Innovative Silicon Inc. Outline Device Overview Operation Architecture Features Challenges Z-RAM Performance
Z-RAM Ultra-Dense Memory for 90nm and Below Hot Chips 2006 David E. Fisch, Anant Singh, Greg Popov Innovative Silicon Inc. Outline Device Overview Operation Architecture Features Challenges Z-RAM Performance
MemFlow: Memory-Driven Data Scheduling with Datapath Co-design in Accelerators for Largescale. Jade Nie Sharad Malik
 MemFlow: Memory-Driven Data Scheduling with Datapath Co-design in Accelerators for Largescale Applications Jade Nie Sharad Malik This work is sponsored in part by SONIC and C-FAR, funded centers of STARnet,
MemFlow: Memory-Driven Data Scheduling with Datapath Co-design in Accelerators for Largescale Applications Jade Nie Sharad Malik This work is sponsored in part by SONIC and C-FAR, funded centers of STARnet,
MEMORY HIERARCHY DESIGN
 MEMORY HIERARCHY DESIGN Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 3 will be released on Oct. 31 st
MEMORY HIERARCHY DESIGN Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 3 will be released on Oct. 31 st
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
 Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Power and Thermal Models. for RAMP2
 Power and Thermal Models for 2 Jose Renau Department of Computer Engineering, University of California Santa Cruz http://masc.cse.ucsc.edu Motivation Performance not the only first order design parameter
Power and Thermal Models for 2 Jose Renau Department of Computer Engineering, University of California Santa Cruz http://masc.cse.ucsc.edu Motivation Performance not the only first order design parameter
Programmable Logic. Any other approaches?
 Programmable Logic So far, have only talked about PALs (see 22V10 figure next page). What is the next step in the evolution of PLDs? More gates! How do we get more gates? We could put several PALs on one
Programmable Logic So far, have only talked about PALs (see 22V10 figure next page). What is the next step in the evolution of PLDs? More gates! How do we get more gates? We could put several PALs on one
Centip3De: A 64-Core, 3D Stacked, Near-Threshold System
 1 1 1 Centip3De: A 64-Core, 3D Stacked, Near-Threshold System Ronald G. Dreslinski David Fick, Bharan Giridhar, Gyouho Kim, Sangwon Seo, Matthew Fojtik, Sudhir Satpathy, Yoonmyung Lee, Daeyeon Kim, Nurrachman
1 1 1 Centip3De: A 64-Core, 3D Stacked, Near-Threshold System Ronald G. Dreslinski David Fick, Bharan Giridhar, Gyouho Kim, Sangwon Seo, Matthew Fojtik, Sudhir Satpathy, Yoonmyung Lee, Daeyeon Kim, Nurrachman
Neural Networks as Function Primitives
 Neural Networks as Function Primitives Software/Hardware Support with X-FILES/DANA Schuyler Eldridge 1 Tommy Unger 2 Marcia Sahaya Louis 1 Amos Waterland 3 Margo Seltzer 3 Jonathan Appavoo 2 Ajay Joshi
Neural Networks as Function Primitives Software/Hardware Support with X-FILES/DANA Schuyler Eldridge 1 Tommy Unger 2 Marcia Sahaya Louis 1 Amos Waterland 3 Margo Seltzer 3 Jonathan Appavoo 2 Ajay Joshi
ISSCC 2001 / SESSION 9 / INTEGRATED MULTIMEDIA PROCESSORS / 9.2
 ISSCC 2001 / SESSION 9 / INTEGRATED MULTIMEDIA PROCESSORS / 9.2 9.2 A 80/20MHz 160mW Multimedia Processor integrated with Embedded DRAM MPEG-4 Accelerator and 3D Rendering Engine for Mobile Applications
ISSCC 2001 / SESSION 9 / INTEGRATED MULTIMEDIA PROCESSORS / 9.2 9.2 A 80/20MHz 160mW Multimedia Processor integrated with Embedded DRAM MPEG-4 Accelerator and 3D Rendering Engine for Mobile Applications
Memory in Digital Systems
 MEMORIES Memory in Digital Systems Three primary components of digital systems Datapath (does the work) Control (manager) Memory (storage) Single bit ( foround ) Clockless latches e.g., SR latch Clocked
MEMORIES Memory in Digital Systems Three primary components of digital systems Datapath (does the work) Control (manager) Memory (storage) Single bit ( foround ) Clockless latches e.g., SR latch Clocked
A 32nm, 0.9V Supply-Noise Sensitivity Tracking PLL for Improved Clock Data Compensation Featuring a Deep Trench Capacitor Based Loop Filter
 A 32nm, 0.9V Supply-Noise Sensitivity Tracking PLL for Improved Clock Data Compensation Featuring a Deep Trench Capacitor Based Loop Filter Bongjin Kim, Weichao Xu, and Chris H. Kim University of Minnesota,
A 32nm, 0.9V Supply-Noise Sensitivity Tracking PLL for Improved Clock Data Compensation Featuring a Deep Trench Capacitor Based Loop Filter Bongjin Kim, Weichao Xu, and Chris H. Kim University of Minnesota,
High-Speed NAND Flash
 High-Speed NAND Flash Design Considerations to Maximize Performance Presented by: Robert Pierce Sr. Director, NAND Flash Denali Software, Inc. History of NAND Bandwidth Trend MB/s 20 60 80 100 200 The
High-Speed NAND Flash Design Considerations to Maximize Performance Presented by: Robert Pierce Sr. Director, NAND Flash Denali Software, Inc. History of NAND Bandwidth Trend MB/s 20 60 80 100 200 The
An Asynchronous Array of Simple Processors for DSP Applications
 An Asynchronous Array of Simple Processors for DSP Applications Zhiyi Yu, Michael Meeuwsen, Ryan Apperson, Omar Sattari, Michael Lai, Jeremy Webb, Eric Work, Tinoosh Mohsenin, Mandeep Singh, Bevan Baas
An Asynchronous Array of Simple Processors for DSP Applications Zhiyi Yu, Michael Meeuwsen, Ryan Apperson, Omar Sattari, Michael Lai, Jeremy Webb, Eric Work, Tinoosh Mohsenin, Mandeep Singh, Bevan Baas
On GPU Bus Power Reduction with 3D IC Technologies
 On GPU Bus Power Reduction with 3D Technologies Young-Joon Lee and Sung Kyu Lim School of ECE, Georgia Institute of Technology, Atlanta, Georgia, USA yjlee@gatech.edu, limsk@ece.gatech.edu Abstract The
On GPU Bus Power Reduction with 3D Technologies Young-Joon Lee and Sung Kyu Lim School of ECE, Georgia Institute of Technology, Atlanta, Georgia, USA yjlee@gatech.edu, limsk@ece.gatech.edu Abstract The
Memory in Digital Systems
 MEMORIES Memory in Digital Systems Three primary components of digital systems Datapath (does the work) Control (manager) Memory (storage) Single bit ( foround ) Clockless latches e.g., SR latch Clocked
MEMORIES Memory in Digital Systems Three primary components of digital systems Datapath (does the work) Control (manager) Memory (storage) Single bit ( foround ) Clockless latches e.g., SR latch Clocked
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Custom Silicon for all
 Custom Silicon for all Because Moore s Law only ends once Who is SiFive? Best-in-class team with technology depth and breadth Founders & Execs Key Leaders & Team Yunsup Lee CTO Krste Asanovic Chief Architect
Custom Silicon for all Because Moore s Law only ends once Who is SiFive? Best-in-class team with technology depth and breadth Founders & Execs Key Leaders & Team Yunsup Lee CTO Krste Asanovic Chief Architect
CS250 VLSI Systems Design Lecture 9: Memory
 CS250 VLSI Systems esign Lecture 9: Memory John Wawrzynek, Jonathan Bachrach, with Krste Asanovic, John Lazzaro and Rimas Avizienis (TA) UC Berkeley Fall 2012 CMOS Bistable Flip State 1 0 0 1 Cross-coupled
CS250 VLSI Systems esign Lecture 9: Memory John Wawrzynek, Jonathan Bachrach, with Krste Asanovic, John Lazzaro and Rimas Avizienis (TA) UC Berkeley Fall 2012 CMOS Bistable Flip State 1 0 0 1 Cross-coupled
Creating a Scalable Microprocessor:
 Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
Phase Change Memory: Replacement or Transformational
 Phase Change Memory: Replacement or Transformational Hsiang-Lan Lung Macronix International Co., Ltd IBM/Macronix PCM Joint Project LETI 4th Workshop on Inovative Memory Technologies 06/21/2012 PCM is
Phase Change Memory: Replacement or Transformational Hsiang-Lan Lung Macronix International Co., Ltd IBM/Macronix PCM Joint Project LETI 4th Workshop on Inovative Memory Technologies 06/21/2012 PCM is
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568/668
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568/668 Part 11 Memory Hierarchy - I Israel Koren ECE568/Koren Part.11.1 ECE568/Koren Part.11.2 Ideal Memory
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568/668 Part 11 Memory Hierarchy - I Israel Koren ECE568/Koren Part.11.1 ECE568/Koren Part.11.2 Ideal Memory
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 10 -- Cache I 2014-2-20 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152 L10: Cache I UC
CS 152 Computer Architecture and Engineering Lecture 10 -- Cache I 2014-2-20 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: CS 152 L10: Cache I UC
BREAKING THE MEMORY WALL
 BREAKING THE MEMORY WALL CS433 Fall 2015 Dimitrios Skarlatos OUTLINE Introduction Current Trends in Computer Architecture 3D Die Stacking The memory Wall Conclusion INTRODUCTION Ideal Scaling of power
BREAKING THE MEMORY WALL CS433 Fall 2015 Dimitrios Skarlatos OUTLINE Introduction Current Trends in Computer Architecture 3D Die Stacking The memory Wall Conclusion INTRODUCTION Ideal Scaling of power
DRAM with Boosted 3T Gain Cell, PVT-tracking Read Reference Bias
 ASub-0 Sub-0.9V Logic-compatible Embedded DRAM with Boosted 3T Gain Cell, Regulated Bit-line Write Scheme and PVT-tracking Read Reference Bias Ki Chul Chun, Pulkit Jain, Jung Hwa Lee*, Chris H. Kim University
ASub-0 Sub-0.9V Logic-compatible Embedded DRAM with Boosted 3T Gain Cell, Regulated Bit-line Write Scheme and PVT-tracking Read Reference Bias Ki Chul Chun, Pulkit Jain, Jung Hwa Lee*, Chris H. Kim University
A 20 GSa/s 8b ADC with a 1 MB Memory in 0.18 µm CMOS
 A 20 GSa/s 8b ADC with a 1 MB Memory in 0.18 µm CMOS Ken Poulton, Robert Neff, Brian Setterberg, Bernd Wuppermann, Tom Kopley, Robert Jewett, Jorge Pernillo, Charles Tan, Allen Montijo 1 Agilent Laboratories,
A 20 GSa/s 8b ADC with a 1 MB Memory in 0.18 µm CMOS Ken Poulton, Robert Neff, Brian Setterberg, Bernd Wuppermann, Tom Kopley, Robert Jewett, Jorge Pernillo, Charles Tan, Allen Montijo 1 Agilent Laboratories,
POWER consumption has become one of the most important
 704 IEEE JOURNAL OF SOLID-STATE CIRCUITS, VOL. 39, NO. 4, APRIL 2004 Brief Papers High-Throughput Asynchronous Datapath With Software-Controlled Voltage Scaling Yee William Li, Student Member, IEEE, George
704 IEEE JOURNAL OF SOLID-STATE CIRCUITS, VOL. 39, NO. 4, APRIL 2004 Brief Papers High-Throughput Asynchronous Datapath With Software-Controlled Voltage Scaling Yee William Li, Student Member, IEEE, George
THE PATH TO EXASCALE COMPUTING. Bill Dally Chief Scientist and Senior Vice President of Research
 THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
Chisel: Constructing Hardware In a Scala Embedded Language
 Chisel: Constructing Hardware In a Scala Embedded Language Jonathan Bachrach, Huy Vo, Brian Richards, Yunsup Lee, Andrew Waterman, Rimas Avizienis, John Wawrzynek, Krste Asanovic EECS UC Berkeley May 22,
Chisel: Constructing Hardware In a Scala Embedded Language Jonathan Bachrach, Huy Vo, Brian Richards, Yunsup Lee, Andrew Waterman, Rimas Avizienis, John Wawrzynek, Krste Asanovic EECS UC Berkeley May 22,
A Software LDPC Decoder Implemented on a Many-Core Array of Programmable Processors
 A Software LDPC Decoder Implemented on a Many-Core Array of Programmable Processors Brent Bohnenstiehl and Bevan Baas Department of Electrical and Computer Engineering University of California, Davis {bvbohnen,
A Software LDPC Decoder Implemented on a Many-Core Array of Programmable Processors Brent Bohnenstiehl and Bevan Baas Department of Electrical and Computer Engineering University of California, Davis {bvbohnen,
The Processor That Don't Cost a Thing
 The Processor That Don't Cost a Thing Peter Hsu, Ph.D. Peter Hsu Consulting, Inc. http://cs.wisc.edu/~peterhsu DRAM+Processor Commercial demand Heat stiffling industry's growth Heat density limits small
The Processor That Don't Cost a Thing Peter Hsu, Ph.D. Peter Hsu Consulting, Inc. http://cs.wisc.edu/~peterhsu DRAM+Processor Commercial demand Heat stiffling industry's growth Heat density limits small
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
A 256kb 6T Self-Tuning SRAM with Extended 0.38V-1.2V Operating Range using Multiple Read/Write Assists and V MIN Tracking Canary Sensors
 A 256kb 6T Self-Tuning SRAM with Extended 0.38V-1.2V Operating Range using Multiple Read/Write Assists and V MIN Tracking Canary Sensors *Arijit Banerjee, *Ningxi Liu, *Harsh N. Patel, *Benton H. Calhoun
A 256kb 6T Self-Tuning SRAM with Extended 0.38V-1.2V Operating Range using Multiple Read/Write Assists and V MIN Tracking Canary Sensors *Arijit Banerjee, *Ningxi Liu, *Harsh N. Patel, *Benton H. Calhoun
COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design
![COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design](/thumbs/80/81947289.jpg "COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design") COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design Lecture Objectives Background Need for Accelerator Accelerators and different type of parallelizm
COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design Lecture Objectives Background Need for Accelerator Accelerators and different type of parallelizm
Basic Organization Memory Cell Operation. CSCI 4717 Computer Architecture. ROM Uses. Random Access Memory. Semiconductor Memory Types
 CSCI 4717/5717 Computer Architecture Topic: Internal Memory Details Reading: Stallings, Sections 5.1 & 5.3 Basic Organization Memory Cell Operation Represent two stable/semi-stable states representing
CSCI 4717/5717 Computer Architecture Topic: Internal Memory Details Reading: Stallings, Sections 5.1 & 5.3 Basic Organization Memory Cell Operation Represent two stable/semi-stable states representing
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
A 120mW Embedded 3D Graphics Rendering Engine with 6Mb Logically Local Frame-Buffer and 3.2GByte/s Run-time Reconfigurable Bus for PDA-Chip
 A 120mW Embedded 3D Graphics Rendering Engine with 6Mb Logically Local Frame-Buffer and 3.2GByte/s Run-time Reconfigurable Bus for PDA-Chip Ramchan Woo*, Chi-Weon Yoon, Jeonghoon Kook, Se-Joong Lee, Kangmin
A 120mW Embedded 3D Graphics Rendering Engine with 6Mb Logically Local Frame-Buffer and 3.2GByte/s Run-time Reconfigurable Bus for PDA-Chip Ramchan Woo*, Chi-Weon Yoon, Jeonghoon Kook, Se-Joong Lee, Kangmin
Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks
 Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis Stanford University David Patterson U.C. Berkeley http://csl.stanford.edu/~christos Motivation Ideal processor
Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis Stanford University David Patterson U.C. Berkeley http://csl.stanford.edu/~christos Motivation Ideal processor
Views of Memory. Real machines have limited amounts of memory. Programmer doesn t want to be bothered. 640KB? A few GB? (This laptop = 2GB)
") CS6290 Memory Views of Memory Real machines have limited amounts of memory 640KB? A few GB? (This laptop = 2GB) Programmer doesn t want to be bothered Do you think, oh, this computer only has 128MB so
CS6290 Memory Views of Memory Real machines have limited amounts of memory 640KB? A few GB? (This laptop = 2GB) Programmer doesn t want to be bothered Do you think, oh, this computer only has 128MB so
Mark Redekopp, All rights reserved. EE 352 Unit 10. Memory System Overview SRAM vs. DRAM DMA & Endian-ness
 EE 352 Unit 10 Memory System Overview SRAM vs. DRAM DMA & Endian-ness The Memory Wall Problem: The Memory Wall Processor speeds have been increasing much faster than memory access speeds (Memory technology
EE 352 Unit 10 Memory System Overview SRAM vs. DRAM DMA & Endian-ness The Memory Wall Problem: The Memory Wall Processor speeds have been increasing much faster than memory access speeds (Memory technology
IMPROVING energy efficiency is critical for a wide variety
 IEEE JOURNAL OF SOLID-STATE CIRCUITS 1 Reprogrammable Redundancy for SRAM-Based Cache V min Reduction in a 28-nm RISC-V Processor Brian Zimmer, Member, IEEE, Pi-Feng Chiu, Student Member, IEEE, Borivoje
IEEE JOURNAL OF SOLID-STATE CIRCUITS 1 Reprogrammable Redundancy for SRAM-Based Cache V min Reduction in a 28-nm RISC-V Processor Brian Zimmer, Member, IEEE, Pi-Feng Chiu, Student Member, IEEE, Borivoje
FPGA architecture and design technology
 CE 435 Embedded Systems Spring 2017 FPGA architecture and design technology Nikos Bellas Computer and Communications Engineering Department University of Thessaly 1 FPGA fabric A generic island-style FPGA
CE 435 Embedded Systems Spring 2017 FPGA architecture and design technology Nikos Bellas Computer and Communications Engineering Department University of Thessaly 1 FPGA fabric A generic island-style FPGA
Computer Architecture s Changing Definition
 Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Porting Performance across GPUs and FPGAs
 Porting Performance across GPUs and FPGAs Deming Chen, ECE, University of Illinois In collaboration with Alex Papakonstantinou 1, Karthik Gururaj 2, John Stratton 1, Jason Cong 2, Wen-Mei Hwu 1 1: ECE
Porting Performance across GPUs and FPGAs Deming Chen, ECE, University of Illinois In collaboration with Alex Papakonstantinou 1, Karthik Gururaj 2, John Stratton 1, Jason Cong 2, Wen-Mei Hwu 1 1: ECE
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
IBM "Broadway" 512Mb GDDR3 Qimonda
 ffl Wii architecture ffl Wii components ffl Cracking Open" the Wii 20 1 CMPE112 Spring 2008 A. Di Blas 112 Spring 2008 CMPE Wii Nintendo ffl Architecture very similar to that of the ffl Fully backwards
ffl Wii architecture ffl Wii components ffl Cracking Open" the Wii 20 1 CMPE112 Spring 2008 A. Di Blas 112 Spring 2008 CMPE Wii Nintendo ffl Architecture very similar to that of the ffl Fully backwards
Real-Time Dynamic Energy Management on MPSoCs
 Real-Time Dynamic Energy Management on MPSoCs Tohru Ishihara Graduate School of Informatics, Kyoto University 2013/03/27 University of Bristol on Energy-Aware COmputing (EACO) Workshop 1 Background Low
Real-Time Dynamic Energy Management on MPSoCs Tohru Ishihara Graduate School of Informatics, Kyoto University 2013/03/27 University of Bristol on Energy-Aware COmputing (EACO) Workshop 1 Background Low
DRAF: A Low-Power DRAM-based Reconfigurable Acceleration Fabric
 DRAF: A Low-Power DRAM-based Reconfigurable Acceleration Fabric Mingyu Gao, Christina Delimitrou, Dimin Niu, Krishna Malladi, Hongzhong Zheng, Bob Brennan, Christos Kozyrakis ISCA June 22, 2016 FPGA-Based
DRAF: A Low-Power DRAM-based Reconfigurable Acceleration Fabric Mingyu Gao, Christina Delimitrou, Dimin Niu, Krishna Malladi, Hongzhong Zheng, Bob Brennan, Christos Kozyrakis ISCA June 22, 2016 FPGA-Based
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Macro in a Generic Logic Process with No Boosted Supplies
 A 700MHz 2T1C Embedded DRAM Macro in a Generic Logic Process with No Boosted Supplies Ki Chul Chun, Wei Zhang, Pulkit Jain, and Chris H. Kim University of Minnesota, Minneapolis, MN Outline Motivation
A 700MHz 2T1C Embedded DRAM Macro in a Generic Logic Process with No Boosted Supplies Ki Chul Chun, Wei Zhang, Pulkit Jain, and Chris H. Kim University of Minnesota, Minneapolis, MN Outline Motivation
Integrating NVIDIA Deep Learning Accelerator (NVDLA) with RISC-V SoC on FireSim
 with RISC-V SoC on FireSim") Integrating NVIDIA Deep Learning Accelerator (NVDLA) with RISC-V SoC on FireSim Farzad Farshchi, Qijing Huang, Heechul Yun University of Kansas, University of California, Berkeley SiFive Internship Rocket
Integrating NVIDIA Deep Learning Accelerator (NVDLA) with RISC-V SoC on FireSim Farzad Farshchi, Qijing Huang, Heechul Yun University of Kansas, University of California, Berkeley SiFive Internship Rocket