MIXED PRECISION TRAINING OF NEURAL NETWORKS. Carl Case, Senior Architect, NVIDIA
|
|
|
- Irene Richard
- 5 years ago
- Views:
Transcription
1 MIXED PRECISION TRAINING OF NEURAL NETWORKS Carl Case, Senior Architect, NVIDIA
2 OUTLINE 1. What is mixed precision training with FP16? 2. Considerations and methodology for mixed precision training 3. Mixed precision training in practice 2
3 OUTLINE 1. What is mixed precision training with FP16? 2. Considerations and methodology for mixed precision training 3. Mixed precision training in practice 3
4 BACKGROUND: VOLTA TENSOR CORES Hardware support for accelerated 16-bit FP math Peak throughput of 125 TFLOPS (8x FP32) Used by cudnn and cublas libraries to accelerate matrix multiply and convolution Internal accumulation occurs in FP32 to maintain accuracy* Exposed in CUDA as WMMA. See: FP16 storage/input Full precision product Sum with FP32 accumulator more products *FP16 accumulator is also available for inference 4
5 MIXED PRECISION TRAINING In a nutshell Goal Benefits Keep stored values in FP16: weights and activations, along with their gradients Use Tensor Cores to accelerate math and maintain accuracy Up to 8x math speedup (depends on arithmetic intensity) Half the memory traffic Half the memory storage Can enable larger model or batch sizes 5
6 MIXED PRECISION FOR RESNET-50 Four lines of code => 2.3x training speedup in PyTorch Mixed precision training uses halfprecision floating point (FP16) to accelerate training You can start using mixed precision today with four lines of code This example uses AMP: Automatic Mixed Precision, a PyTorch library No hyperparameters changed + amp_handle = amp.init() #... Define model and optimizer for x, y in dataset: prediction = model(x) loss = criterion(prediction, y) - loss.backward() + with amp_handle.scale_loss(loss, + optimizer) as scaled_loss: + scaled_loss.backward() optimizer.step() 6
7 MIXED PRECISION FOR RESNET-50 Real-world single-gpu runs using default PyTorch ImageNet example NVIDIA PyTorch py3 container AMP for mixed precision Minibatch=256 Single GPU RN-50 speedup for FP32 -> M.P. (with 2x batch size): MxNet: 2.9x TensorFlow: 2.2x TensorFlow + XLA: ~3x Four lines of code => 2.3x training speedup PyTorch: 2.3x Work ongoing to bring to 3x everywhere 7
8 MIXED PRECISION FOR RESNET-50 Speedup at scale Real-world 8GPU runs using MxNet on DGX-1 NVIDIA mxnet py3 container Minibatch=256 per GPU Note: less inter-iteration loss variance since total batch size is 8x larger Total time to run a full 90 epochs of training in mixed precision is well under four hours 8
9 MIXED PRECISION IS GENERAL PURPOSE Models trained to match FP32 results (same hyperparameters) Image Classification AlexNet, VGG-D, GoogLeNet, Inception v{2,3}, ResNet-50, ResNeXt-50 Detection Faster R-CNN, Multibox SSD, NVIDIA-proprietary automotive Translation, other NLP GNMT (RNN-based), FairSeq (convolution-based), Sentiment classification Speech Deep Speech 2 (recognition); Tacotron2 + Wavenet (synthesis) Image Synthesis Progressive GANs, Partial image inpainting 9
10 MIXED PRECISION SPEEDUPS Not limited to image classification Model FP32 -> M.P. Speedup Comments GNMT (Translation) 2.3x Iso-batch size FairSeq Transformer (Translation) 2.9x 4.9x Iso-batch size 2x lr + larger batch ConvSeq2Seq (Translation) Deep Speech 2 (Speech recognition) wav2letter (Speech recognition) Nvidia Sentiment (Language modeling) 2.5x 2x batch size 4.5x Larger batch 3.0x 2x batch size 4.0x Larger batch *In all cases trained to same accuracy as FP32 model **No hyperaparameter changes, except as noted 10
11 MIXED PRECISION IN DL RESEARCH Large Scale Language Modeling: Converging on 40GB of Text in Four Hours [Nvidia] We train our recurrent models with mixed precision FP16/FP32 arithmetic, which speeds up training on a single V100 by 4.2X over training in FP32. Scaling Neural Machine Translation [Facebook] This paper shows that reduced precision and large batch training can speedup training by nearly 5x on a single 8-GPU machine with careful tuning and implementation. 11
12 OUTLINE 1. What is mixed precision training with FP16? 2. Considerations and methodology for mixed precision training 3. Mixed precision training in practice 12
13 MIXED PRECISION METHODOLOGY For training Goal: training with FP16 is general purpose, not only for a limited class of applications In order to train with no architecture or hyperparameter changes, we need to give consideration to the reduced precision inherent in using only 16 bits Note: true for any reduced precision format, though specifics may be different Three parts: 1. Model conversion, with careful handling of non-tensor Core ops 2. Master weight copy 3. Loss scaling 13
14 1. MODEL CONVERSION For Tensor Core ops For most of the model, we make simple type updates to each layer: Use FP16 values for the weights (layer parameters) Ensure the inputs are FP16, so the layer runs on Tensor Cores 14
15 1. MODEL CONVERSION Pointwise and reduction ops Common operations that are not matrix multiply or convolution: Activation functions: ReLU, sigmoid, tanh, softplus Normalization functions: batchnorm, layernorm, sum, mean, softmax Loss functions: cross entropy, L2 loss, weight decay Miscellaneous: exp, log, pointwise-{add, subtract, multiply, divide} We want to maintain the accuracy of these operations, even though they will not run on Tensor Cores 15
16 POINTWISE AND REDUCTION OPS Principles Tensor Cores increase precision in two ways: 1. Each individual multiply is performed in high precision 2. The sum of the products is accumulated in high precision For non-tc operations, we want to adhere to those same principles: 1. Keep intermediate or temporary values in high precision 2. Perform sums (reductions) in high precision 16
 x (or same for grads) Eg: exp, log, pow Pointwise op fusion is a good next step for performance and")
17 POINTWISE AND REDUCTION OPS Intermediate and temporary values in high precision For pointwise operations, generally fine to operate directly on FP16 values. FP32 math and storage recommended for ops where f(x) x (or same for grads) Eg: exp, log, pow Pointwise op fusion is a good next step for performance and precision 17
18 POINTWISE AND REDUCTION OPS Perform sums / reductions in high precision Common to normalize a large set of FP16 values in, e.g., a softmax layer Two choices : Sum all the values directly into an FP16 accumulator, then perform division in FP16 Perform math in high precision (FP32 accumulator, division), then write the final result in FP16 The first introduces the possibility of compounding precision error The second does what Tensor Cores do: limit reduced precision to final output This is the desired behavior 18
19 POINTWISE AND REDUCTION OPS Practical recommendations Nonlinearities: fine for FP16 Except: watch out for exp, log, pow Normalization: input /output in FP16; intermediate results stored in FP32 Ideally: fused into single op. Example: cudnn BatchNorm Loss functions: input / output in FP32 Also: attention modules (softmax) 19
20 2. MASTER WEIGHTS At each iteration of training, perform a weight update of the form w t+1 = w t α t w t s are weights; t s are gradients; α is the learning rate As a rule, gradients are smaller than weights, and learning rate is less than one Consequence: weight update can be a no-op, since you can t get to next representable value Conservative solution: keep a high-precision copy of weights so small updates accumulate across iterations No-op weight update
21 Range representable in FP16: ~40 powers of 2 Gradients are small: 3. LOSS SCALING Weights Activations Some lost to zero While ~15 powers of 2 remain unused Loss scaling: Multiply loss by a constant S All gradients scaled up by S (chain rule) Weight Grads Activation Grads Unscale weight gradient (in FP32) before weight update 21

22 3. LOSS SCALING Automatically choosing a scaling factor S Intuition: 0. Start with a very large scaling factor. 1. If an inf or NaN is present in the gradient, decrease the scale. And skip the update, including optimizer state. 2. If no inf or NaN has occurred for some time, increase the scale. 22
23 3. LOSS SCALING Automatically choosing a scaling factor S Intuition: 0. Start with a very large scaling factor. 1. If an inf or NaN is present in the gradient, decrease the scale. And skip the update, including optimizer state. 2. If no inf or NaN has occurred for some time, increase the scale. Described in detail: Implementations available in major frameworks (see references at the end) 23
24 OUTLINE 1. What is mixed precision training with FP16? 2. Considerations and methodology for mixed precision training 3. Mixed precision training in practice 24
25 Matrix Multiply MAKING USE OF TENSOR CORES Performance Guidelines All three dimensions (M, N, K) should be multiples of 8 Larger K (shared dimension) is more efficient (amortizes write overhead) Convolution Note this makes wider recurrent cells more practical (K is input layer width) Number of channels for input and output should be a multiple of 8 (can be different) If you are designing models: Choose layer widths and batch sizes or channel counts that are multiples of 8 Am I using Tensor Cores? cublas and cudnn are optimized for Tensor Cores, coverage is always increasing Run with nvprof and look for s[some digits] in kernel name Eg: volta_fp16_s884gemm_fp16_128x128_ldg8_f2f_nn 25
26 ENABLING MIXED PRECISION In real-world training pipelines Three ways to switch to mixed precision training: 1. Add all the necessary code yourself 2. Use libraries that enable safe updates; manage model conversion by hand 3. Use a fully-automated tool to perform necessary transformations under-the-hood Recommendation: (3) to get familiar with mixed precision training; (2) for more control (and occasionally better performance) (1) if using a custom setup for which libraries don t exist 26
27 DEBUGGING MIXED PRECISION Notes and what to watch for The unreasonable effectiveness of gradient descent Bugs in code for mixed precision steps often manifest as slightly worse training accuracy Be sure to follow good software engineering practices, especially testing Common mistakes: Gradients not unscaled correctly before weight update (AdaGrad / Adam will try to handle this!) Gradient clipping or regularization improperly using scaled gradients Incorrectly synchronizing master weight updates across multiple GPUs Not running loss function in FP32 27
28 RUNNING EXAMPLE FOR ENABLING MIXED PRECSION Toy Model in PyTorch N, D_in, D_out = 64, 1024, 512 x = torch.randn(n, D_in ).cuda() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda() optimizer = torch.optim.sgd(model.parameters(), lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() 28
29 DIY: MODEL CONVERSION N, D_in, D_out = 64, 1024, 512 x = torch.randn(n, D_in ).cuda().half() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda().half() optimizer = torch.optim.sgd(model.parameters(), lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred.float(), y) optimizer.zero_grad() loss.backward() optimizer.step() 29
30 N, D_in, D_out = 64, 1024, 512 DIY: MASTER WEIGHTS x = torch.randn(n, D_in ).cuda().half() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda().half() master_weights = [x.clone().detach().float() for x in model.parameters()] for p in master_weights: p.requires_grad = True optimizer = torch.optim.sgd(master_weights, lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred.float(), y) optimizer.zero_grad() loss.backward() for mod_w, master_w in zip(model.parameters(), master_weights): master_w.grad.data.copy_(mod_w.grad.data) optimizer.step() for mod_w, master_w in zip(model.parameters(), master_weights): mod_w.data.copy_(master_w.data) 30
31 DIY: LOSS SCALING (FIXED VALUE) N, D_in, D_out = 64, 1024, 512 loss_scale = 256. x = torch.randn(n, D_in ).cuda().half() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda().half() master_weights = [x.clone().detach().float() for x in model.parameters()] for p in master_weights: p.requires_grad = True optimizer = torch.optim.sgd(master_weights, lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred.float(), y) * loss_scale optimizer.zero_grad() loss.backward() for mod_w, master_w in zip(model.parameters(), master_weights): master_w.grad.data.copy_(mod_w.grad.data) master_w.grad.data.mul_(1. / loss_scale) optimizer.step() for mod_w, master_w in zip(model.parameters(), master_weights): mod_w.data.copy_(master_w.data) 31
32 LIBRARIES FOR MIXED PRECISION N, D_in, D_out = 64, 1024, 512 x = torch.randn(n, D_in ).cuda() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda() optimizer = torch.optim.sgd(model.parameters(), lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() 32
33 LIBRARIES FOR MIXED PRECISION from apex.fp16_utils import FP16_Optimizer N, D_in, D_out = 64, 1024, 512 x = torch.randn(n, D_in ).cuda().half() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda().half() optimizer = FP16_Optimizer(torch.optim.SGD(model.parameters(), lr=1e-3), dynamic_loss_scale=true) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred.float(), y) optimizer.zero_grad() loss.backward() optimizer.backward(loss) optimizer.step() 33
34 AUTOMATIC MIXED PRECISION N, D_in, D_out = 64, 1024, 512 x = torch.randn(n, D_in ).cuda() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda() optimizer = torch.optim.sgd(model.parameters(), lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() 34
35 AUTOMATIC MIXED PRECISION from apex import amp amp_handle = amp.init() N, D_in, D_out = 64, 1024, 512 x = torch.randn(n, D_in ).cuda() y = torch.randn(n, D_out).cuda() model = torch.nn.linear(d_in, D_out).cuda() optimizer = torch.optim.sgd(model.parameters(), lr=1e-3) for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) optimizer.zero_grad() loss.backward() with amp_handle.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() optimizer.step() 35
36 RESOURCES (1) Examples New mixed precision model examples: GitHub: DGX/NGC deep learning framework containers: Latest versions of software stack and Tensor Core optimized examples. DGX/NGC Registry 36
37 Mixed Precision Training (ICLR 2018): RESOURCES (2) Reading Mixed Precision Guide: OpenSeq2Seq (describes mixed precision for sequence models): GTC 2018 Sessions: Training Neural Networks with Mixed Precision: Theory and Practice Training Neural Networks with Mixed Precision: Real Examples 37
38 RESOURCES (3) Tools TensorFlow OpenSeq2Seq: Full implementation of mixed precision for sequence-to-sequence models Building blocks of mixed precision for TensorFlow Apex for PyTorch: Tools for master weights and loss scaling amp for PyTorch: Fully automatic mixed precision training 38
39 CONCLUSION Mixed precision training is a general-purpose technique with tremendous benefits: Math and memory speedups Memory savings, enabling larger models (or minibatches) Accuracy matches FP32 training across a wide range of models (all we have tried) Significant speedups are common and getting more common with each new library release Enabling mixed precision depends on a specific methodology: Model conversion with special care for pointwise and reduction ops Safe updates with master weights and loss scaling There are many tools to make it easier to use mixed precision all the way up to fully automatic! 39
40
41 MODEL ACCURACY REFERENCES WITH MIXED PRECISION TRAINING 41
42 ILSVRC12 Classification Networks, Top-1 Accuracy FP32 Baseline Mixed Precision AlexNet 56.8% 56.9% VGG-D 65.4% 65.4% GoogLeNet 69.3% 69.3% Inception v2 70.0% 70.0% Inception v3 73.9% 74.1% Resnet % 76.0% ResNeXt % 77.5% A number of these train fine in mixed precision even without loss-scaling. (C) NVIDIA 42
43 Detection Networks, map FP32 Baseline Mixed Precision Faster R-CNN, VOC 07 data 69.1% 69.7% Multibox SSD, VOC data 76.9% 77.1% NVIDIA s proprietary automotive networks train with mixed-precision matching FP32 baseline accuracy. (C) NVIDIA 43
44 Language Translation GNMT: German -> English (train on WMT, test on newstest2015) 8 layer encoder, 8 layer decoder, 1024x LSTM cells, attention FP32 and Mixed Precision: ~29 BLEU using SGD Both equally lower with Adam, match the paper FairSeq: Convolutional net for translation, English - French FP32 and Mixed Precision: ~40.5 BLEU after 12 epochs (C) NVIDIA 44
45 Speech Courtesy of Baidu 2 2D-conv layers, 3 GRU layers, 1D conv Baidu internal datasets Character Error Rate (lower is better) FP32 Baseline Mixed Precision English Mandarin (C) NVIDIA 45

46 Progressive Growing of GANs Generates 1024x1024 face images No perceptible difference between FP32 and mixed-precision training Loss-scaling: Separate scaling factors for generator and discriminator (you are training 2 networks) Automatic loss scaling greatly simplified training gradient stats shift drastically when image resolution is increased (C) NVIDIA 46
47 Sentiment Analysis Multiplicative LSTM, based on Amazon Reviews training BPC FP32 Mixed Precision Train BPC Val BPC SST acc IMDB acc FP Mixed Precision (C) NVIDIA 47




48 Image Inpainting Fill in arbitrary holes Network Architecture: U-Net with partial convolution VGG16 based Perceptual loss + Style loss Speedup: 3x, at 2x bigger batch size We can increase batch size only in mixed precision Input Inpainted Result (C) NVIDIA 48

")
49 Image Inpainting : result Testing Input Training Loss Curve Mixed Precision Result FP32 Result (C) NVIDIA 49

50 Text to speech synthesis Using Tacotron 2 Shen et al, Natural TTS Synthesis by Conditioning Wavenet on Mel-Spectrogram Predictions,




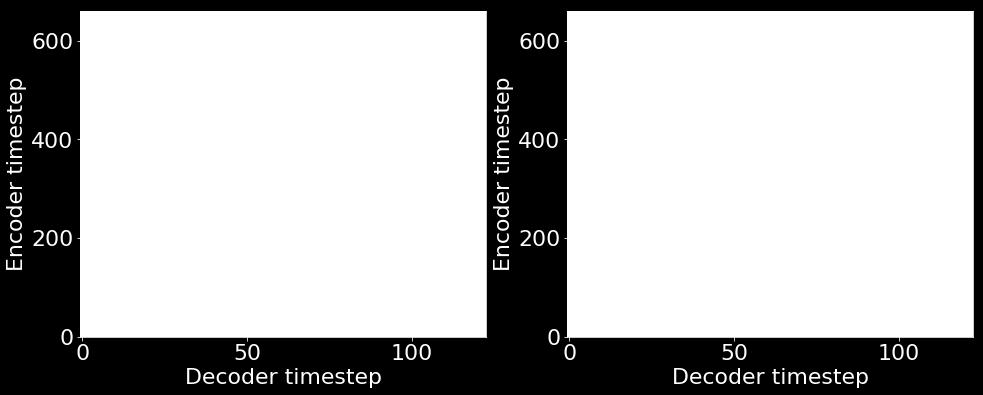
51 Text to speech synthesis : results Mixed Precision: Pink FP32: Green Predicted Mel-Spectrograms Predicted Alignments Mixed Precision FP32
52 Wavenet 12 Layers of dilated convolutions Dilations reset every 6 layers 128 channels for dilated convs. (64 per nonlinearity) 64 channels for residual convs. 256 channels for skip convs. Van den Oord et al. WaveNet: A Generative Model for Raw Audio,
53 Wavenet : results Mixed precision: Pink; FP32: Green Results in FP16 (pink) and FP32 (green)
MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius
 MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius What is Mixed Precision Training? Reduced precision tensor math with FP32 accumulation, FP16 storage Successfully used to train a variety
MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius What is Mixed Precision Training? Reduced precision tensor math with FP32 accumulation, FP16 storage Successfully used to train a variety
Training Neural Networks with Mixed Precision MICHAEL CARILLI CHRISTIAN SAROFEEN MICHAEL RUBERRY BEN BARSDELL
 Training Neural Networks with Mixed Precision MICHAEL CARILLI CHRISTIAN SAROFEEN MICHAEL RUBERRY BEN BARSDELL 1 THIS TALK Using mixed precision and Volta your networks can be: 1. 2-4x faster 2. half the
Training Neural Networks with Mixed Precision MICHAEL CARILLI CHRISTIAN SAROFEEN MICHAEL RUBERRY BEN BARSDELL 1 THIS TALK Using mixed precision and Volta your networks can be: 1. 2-4x faster 2. half the
Inference Optimization Using TensorRT with Use Cases. Jack Han / 한재근 Solutions Architect NVIDIA
 Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS
 TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
Convolutional Sequence to Sequence Learning. Denis Yarats with Jonas Gehring, Michael Auli, David Grangier, Yann Dauphin Facebook AI Research
 Convolutional Sequence to Sequence Learning Denis Yarats with Jonas Gehring, Michael Auli, David Grangier, Yann Dauphin Facebook AI Research Sequence generation Need to model a conditional distribution
Convolutional Sequence to Sequence Learning Denis Yarats with Jonas Gehring, Michael Auli, David Grangier, Yann Dauphin Facebook AI Research Sequence generation Need to model a conditional distribution
Tutorial on Keras CAP ADVANCED COMPUTER VISION SPRING 2018 KISHAN S ATHREY
 Tutorial on Keras CAP 6412 - ADVANCED COMPUTER VISION SPRING 2018 KISHAN S ATHREY Deep learning packages TensorFlow Google PyTorch Facebook AI research Keras Francois Chollet (now at Google) Chainer Company
Tutorial on Keras CAP 6412 - ADVANCED COMPUTER VISION SPRING 2018 KISHAN S ATHREY Deep learning packages TensorFlow Google PyTorch Facebook AI research Keras Francois Chollet (now at Google) Chainer Company
Convolutional Neural Networks
 NPFL114, Lecture 4 Convolutional Neural Networks Milan Straka March 25, 2019 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics unless otherwise
NPFL114, Lecture 4 Convolutional Neural Networks Milan Straka March 25, 2019 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics unless otherwise
EFFICIENT INFERENCE WITH TENSORRT. Han Vanholder
 EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
OPENSEQ2SEQ: A DEEP LEARNING TOOLKIT FOR SPEECH RECOGNITION, SPEECH SYNTHESIS, AND NLP
 OPENSEQ2SEQ: A DEEP LEARNING TOOLKIT FOR SPEECH RECOGNITION, SPEECH SYNTHESIS, AND NLP Boris Ginsburg, Vitaly Lavrukhin, Igor Gitman, Oleksii Kuchaiev, Jason Li, Vahid Noroozi, Ravi Teja Gadde, Chip Nguyen
OPENSEQ2SEQ: A DEEP LEARNING TOOLKIT FOR SPEECH RECOGNITION, SPEECH SYNTHESIS, AND NLP Boris Ginsburg, Vitaly Lavrukhin, Igor Gitman, Oleksii Kuchaiev, Jason Li, Vahid Noroozi, Ravi Teja Gadde, Chip Nguyen
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017
 A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
GPU FOR DEEP LEARNING. 周国峰 Wuhan University 2017/10/13
 GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
Profiling DNN Workloads on a Volta-based DGX-1 System
 Profiling DNN Workloads on a Volta-based DGX-1 System Saiful A. Mojumder 1, Marcia S Louis 1, Yifan Sun 2, Amir Kavyan Ziabari 3, José L. Abellán 4, John Kim 5, David Kaeli 2, Ajay Joshi 1 1 ECE Department,
Profiling DNN Workloads on a Volta-based DGX-1 System Saiful A. Mojumder 1, Marcia S Louis 1, Yifan Sun 2, Amir Kavyan Ziabari 3, José L. Abellán 4, John Kim 5, David Kaeli 2, Ajay Joshi 1 1 ECE Department,
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
Characterization and Benchmarking of Deep Learning. Natalia Vassilieva, PhD Sr. Research Manager
 Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
All You Want To Know About CNNs. Yukun Zhu
 All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
Fei-Fei Li & Justin Johnson & Serena Yeung
 Lecture 9-1 Administrative A2 due Wed May 2 Midterm: In-class Tue May 8. Covers material through Lecture 10 (Thu May 3). Sample midterm released on piazza. Midterm review session: Fri May 4 discussion
Lecture 9-1 Administrative A2 due Wed May 2 Midterm: In-class Tue May 8. Covers material through Lecture 10 (Thu May 3). Sample midterm released on piazza. Midterm review session: Fri May 4 discussion
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
MoonRiver: Deep Neural Network in C++
 MoonRiver: Deep Neural Network in C++ Chung-Yi Weng Computer Science & Engineering University of Washington chungyi@cs.washington.edu Abstract Artificial intelligence resurges with its dramatic improvement
MoonRiver: Deep Neural Network in C++ Chung-Yi Weng Computer Science & Engineering University of Washington chungyi@cs.washington.edu Abstract Artificial intelligence resurges with its dramatic improvement
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 11. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Effectively Scaling Deep Learning Frameworks
 Effectively Scaling Deep Learning Frameworks (To 40 GPUs and Beyond) Welcome everyone! I m excited to be here today and get the opportunity to present some of the work that we ve been doing at SVAIL, the
Effectively Scaling Deep Learning Frameworks (To 40 GPUs and Beyond) Welcome everyone! I m excited to be here today and get the opportunity to present some of the work that we ve been doing at SVAIL, the
NVIDIA FOR DEEP LEARNING. Bill Veenhuis
 NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
Deep learning at Microsoft
 Deep learning at Services Skype Translator Cortana Bing HoloLens Research Services ImageNet: 2015 ResNet 28.2 25.8 ImageNet Classification top-5 error (%) 16.4 11.7 7.3 6.7 3.5 ILSVRC 2010 NEC America
Deep learning at Services Skype Translator Cortana Bing HoloLens Research Services ImageNet: 2015 ResNet 28.2 25.8 ImageNet Classification top-5 error (%) 16.4 11.7 7.3 6.7 3.5 ILSVRC 2010 NEC America
Fuzzy Set Theory in Computer Vision: Example 3
 Fuzzy Set Theory in Computer Vision: Example 3 Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Purpose of these slides are to make you aware of a few of the different CNN architectures
Fuzzy Set Theory in Computer Vision: Example 3 Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Purpose of these slides are to make you aware of a few of the different CNN architectures
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
Deep Learning Explained Module 4: Convolution Neural Networks (CNN or Conv Nets)
") Deep Learning Explained Module 4: Convolution Neural Networks (CNN or Conv Nets) Sayan D. Pathak, Ph.D., Principal ML Scientist, Microsoft Roland Fernandez, Senior Researcher, Microsoft Module Outline
Deep Learning Explained Module 4: Convolution Neural Networks (CNN or Conv Nets) Sayan D. Pathak, Ph.D., Principal ML Scientist, Microsoft Roland Fernandez, Senior Researcher, Microsoft Module Outline
Index. Umberto Michelucci 2018 U. Michelucci, Applied Deep Learning,
 A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
Training Deep Neural Networks (in parallel)
") Lecture 9: Training Deep Neural Networks (in parallel) Visual Computing Systems How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors as
Lecture 9: Training Deep Neural Networks (in parallel) Visual Computing Systems How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors as
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer
 S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer 2 100 倍以上速く 本当に可能ですか? 2 DOUGLAS ADAMS BABEL FISH Neural Machine Translation Unit 3 4 OVER 100X FASTER, IS IT REALLY POSSIBLE?
S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer 2 100 倍以上速く 本当に可能ですか? 2 DOUGLAS ADAMS BABEL FISH Neural Machine Translation Unit 3 4 OVER 100X FASTER, IS IT REALLY POSSIBLE?
Hello Edge: Keyword Spotting on Microcontrollers
 Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
A performance comparison of Deep Learning frameworks on KNL
 A performance comparison of Deep Learning frameworks on KNL R. Zanella, G. Fiameni, M. Rorro Middleware, Data Management - SCAI - CINECA IXPUG Bologna, March 5, 2018 Table of Contents 1. Problem description
A performance comparison of Deep Learning frameworks on KNL R. Zanella, G. Fiameni, M. Rorro Middleware, Data Management - SCAI - CINECA IXPUG Bologna, March 5, 2018 Table of Contents 1. Problem description
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Sayan Pathak Principal ML Scientist. Chris Basoglu Partner Dev Manager
 Sayan Pathak Principal ML Scientist Chris Basoglu Partner Dev Manager With many contributors: A. Agarwal, E. Akchurin, E. Barsoum, C. Basoglu, G. Chen, S. Cyphers, W. Darling, J. Droppo, K. Deng, A. Eversole,
Sayan Pathak Principal ML Scientist Chris Basoglu Partner Dev Manager With many contributors: A. Agarwal, E. Akchurin, E. Barsoum, C. Basoglu, G. Chen, S. Cyphers, W. Darling, J. Droppo, K. Deng, A. Eversole,
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Profiling GPU Code. Jeremy Appleyard, February 2016
 Profiling GPU Code Jeremy Appleyard, February 2016 What is Profiling? Measuring Performance Measuring application performance Usually the aim is to reduce runtime Simple profiling: How long does an operation
Profiling GPU Code Jeremy Appleyard, February 2016 What is Profiling? Measuring Performance Measuring application performance Usually the aim is to reduce runtime Simple profiling: How long does an operation
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Usable while performant: the challenges building. Soumith Chintala
 Usable while performant: the challenges building Soumith Chintala Problem Statement Deep Learning Workloads Problem Statement Deep Learning Workloads for epoch in range(max_epochs): for data, target in
Usable while performant: the challenges building Soumith Chintala Problem Statement Deep Learning Workloads Problem Statement Deep Learning Workloads for epoch in range(max_epochs): for data, target in
Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture
 The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
Convolutional Neural Networks and Supervised Learning
 Convolutional Neural Networks and Supervised Learning Eilif Solberg August 30, 2018 Outline Convolutional Architectures Convolutional neural networks Training Loss Optimization Regularization Hyperparameter
Convolutional Neural Networks and Supervised Learning Eilif Solberg August 30, 2018 Outline Convolutional Architectures Convolutional neural networks Training Loss Optimization Regularization Hyperparameter
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
OPTIMIZING PERFORMANCE OF RECURRENT NEURAL NETWORKS
 April 4-7, 2016 Silicon Valley OPTIMIZING PERFORMANCE OF RECURRENT NEURAL NETWORKS Jeremy Appleyard, 7 April 2016 RECURRENT NEURAL NETWORKS Output is fed into input Perform the same operation repeatedly
April 4-7, 2016 Silicon Valley OPTIMIZING PERFORMANCE OF RECURRENT NEURAL NETWORKS Jeremy Appleyard, 7 April 2016 RECURRENT NEURAL NETWORKS Output is fed into input Perform the same operation repeatedly
C-Brain: A Deep Learning Accelerator
 C-Brain: A Deep Learning Accelerator that Tames the Diversity of CNNs through Adaptive Data-level Parallelization Lili Song, Ying Wang, Yinhe Han, Xin Zhao, Bosheng Liu, Xiaowei Li State Key Laboratory
C-Brain: A Deep Learning Accelerator that Tames the Diversity of CNNs through Adaptive Data-level Parallelization Lili Song, Ying Wang, Yinhe Han, Xin Zhao, Bosheng Liu, Xiaowei Li State Key Laboratory
High-Performance Data Loading and Augmentation for Deep Neural Network Training
 High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
PRACTICAL SCALING TECHNIQUES. Ujval Kapasi Dec 9, 2017
 PRACTICAL SCALING TECHNIQUES Ujval Kapasi Dec 9, 2017 DNN TRAINING ON MULTIPLE GPUS Making DL training times shorter 2 DNN TRAINING ON MULTIPLE GPUS Making DL training times shorter local local local Allreduce
PRACTICAL SCALING TECHNIQUES Ujval Kapasi Dec 9, 2017 DNN TRAINING ON MULTIPLE GPUS Making DL training times shorter 2 DNN TRAINING ON MULTIPLE GPUS Making DL training times shorter local local local Allreduce
Natural Language Processing with Deep Learning CS224N/Ling284. Christopher Manning Lecture 4: Backpropagation and computation graphs
 Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Beyond Data and Model Parallelism for Deep Neural Networks
 Beyond Data and Model Parallelism for Deep Neural Networks In this paper, we present FlexFlow, a deep learning framework that automatically finds fast parallelization strategies over a significantly broader
Beyond Data and Model Parallelism for Deep Neural Networks In this paper, we present FlexFlow, a deep learning framework that automatically finds fast parallelization strategies over a significantly broader
CNNS FROM THE BASICS TO RECENT ADVANCES. Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague
 CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Introduction to Deep Learning in Signal Processing & Communications with MATLAB
 Introduction to Deep Learning in Signal Processing & Communications with MATLAB Dr. Amod Anandkumar Pallavi Kar Application Engineering Group, Mathworks India 2019 The MathWorks, Inc. 1 Different Types
Introduction to Deep Learning in Signal Processing & Communications with MATLAB Dr. Amod Anandkumar Pallavi Kar Application Engineering Group, Mathworks India 2019 The MathWorks, Inc. 1 Different Types
NVIDIA DATA LOADING LIBRARY (DALI)
") NVIDIA DATA LOADING LIBRARY (DALI) RN-09096-001 _v01 September 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. DALI DALI DALI DALI DALI Overview...1 Release
NVIDIA DATA LOADING LIBRARY (DALI) RN-09096-001 _v01 September 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. DALI DALI DALI DALI DALI Overview...1 Release
Nvidia Jetson TX2 and its Software Toolset. João Fernandes 2017/2018
 Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
Recurrent Neural Networks
 Recurrent Neural Networks 11-785 / Fall 2018 / Recitation 7 Raphaël Olivier Recap : RNNs are magic They have infinite memory They handle all kinds of series They re the basis of recent NLP : Translation,
Recurrent Neural Networks 11-785 / Fall 2018 / Recitation 7 Raphaël Olivier Recap : RNNs are magic They have infinite memory They handle all kinds of series They re the basis of recent NLP : Translation,
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA GPUS
 SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
NVIDIA PLATFORM FOR AI
 NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Recurrent Neural Nets II
 Recurrent Neural Nets II Steven Spielberg Pon Kumar, Tingke (Kevin) Shen Machine Learning Reading Group, Fall 2016 9 November, 2016 Outline 1 Introduction 2 Problem Formulations with RNNs 3 LSTM for Optimization
Recurrent Neural Nets II Steven Spielberg Pon Kumar, Tingke (Kevin) Shen Machine Learning Reading Group, Fall 2016 9 November, 2016 Outline 1 Introduction 2 Problem Formulations with RNNs 3 LSTM for Optimization
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs
 A Torch Library for Action Recognition and Detection Using CNNs and LSTMs Gary Thung and Helen Jiang Stanford University {gthung, helennn}@stanford.edu Abstract It is very common now to see deep neural
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs Gary Thung and Helen Jiang Stanford University {gthung, helennn}@stanford.edu Abstract It is very common now to see deep neural
Accelerating Convolutional Neural Nets. Yunming Zhang
 Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
POWERING THE AI REVOLUTION JENSEN HUANG, FOUNDER & CEO GTC 2017
 POWERING THE AI REVOLUTION JENSEN HUANG, FOUNDER & CEO GTC 2017 LIFE AFTER MOORE S LAW 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 Transistors (thousands) 1.1X per year 10 4 10 3 1.5X per year
POWERING THE AI REVOLUTION JENSEN HUANG, FOUNDER & CEO GTC 2017 LIFE AFTER MOORE S LAW 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 Transistors (thousands) 1.1X per year 10 4 10 3 1.5X per year
Inception Network Overview. David White CS793
 Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK
 Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC
 TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
CNN optimization. Rassadin A
 CNN optimization Rassadin A. 01.2017-02.2017 What to optimize? Training stage time consumption (CPU / GPU) Inference stage time consumption (CPU / GPU) Training stage memory consumption Inference stage
CNN optimization Rassadin A. 01.2017-02.2017 What to optimize? Training stage time consumption (CPU / GPU) Inference stage time consumption (CPU / GPU) Training stage memory consumption Inference stage
GPU-Accelerated Deep Learning
 GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
A Quick Guide on Training a neural network using Keras.
 A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Scalable Distributed Training with Parameter Hub: a whirlwind tour
 Scalable Distributed Training with Parameter Hub: a whirlwind tour TVM Stack Optimization High-Level Differentiable IR Tensor Expression IR AutoTVM LLVM, CUDA, Metal VTA AutoVTA Edge FPGA Cloud FPGA ASIC
Scalable Distributed Training with Parameter Hub: a whirlwind tour TVM Stack Optimization High-Level Differentiable IR Tensor Expression IR AutoTVM LLVM, CUDA, Metal VTA AutoVTA Edge FPGA Cloud FPGA ASIC
Deep Learning Applications
 October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 10, 2017
 INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
LSTM for Language Translation and Image Captioning. Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia
 1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
CNN Basics. Chongruo Wu
 CNN Basics Chongruo Wu Overview 1. 2. 3. Forward: compute the output of each layer Back propagation: compute gradient Updating: update the parameters with computed gradient Agenda 1. Forward Conv, Fully
CNN Basics Chongruo Wu Overview 1. 2. 3. Forward: compute the output of each layer Back propagation: compute gradient Updating: update the parameters with computed gradient Agenda 1. Forward Conv, Fully
Evaluating On-Node GPU Interconnects for Deep Learning Workloads
 Evaluating On-Node GPU Interconnects for Deep Learning Workloads NATHAN TALLENT, NITIN GAWANDE, CHARLES SIEGEL ABHINAV VISHNU, ADOLFY HOISIE Pacific Northwest National Lab PMBS 217 (@ SC) November 13,
Evaluating On-Node GPU Interconnects for Deep Learning Workloads NATHAN TALLENT, NITIN GAWANDE, CHARLES SIEGEL ABHINAV VISHNU, ADOLFY HOISIE Pacific Northwest National Lab PMBS 217 (@ SC) November 13,
TENSORRT. RN _v01 January Release Notes
 TENSORRT RN-08624-030_v01 January 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter 1. 2. 3. 4. Overview...1 Release 3.0.2... 2 Release 3.0.1... 4 Release 2.1... 10 RN-08624-030_v01
TENSORRT RN-08624-030_v01 January 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter 1. 2. 3. 4. Overview...1 Release 3.0.2... 2 Release 3.0.1... 4 Release 2.1... 10 RN-08624-030_v01
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI
 MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
Deep Learning. Practical introduction with Keras JORDI TORRES 27/05/2018. Chapter 3 JORDI TORRES
 Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
OPTIMIZED GPU KERNELS FOR DEEP LEARNING. Amir Khosrowshahi
 OPTIMIZED GPU KERNELS FOR DEEP LEARNING Amir Khosrowshahi GTC 17 Mar 2015 Outline About nervana Optimizing deep learning at assembler level Limited precision for deep learning neon benchmarks 2 About nervana
OPTIMIZED GPU KERNELS FOR DEEP LEARNING Amir Khosrowshahi GTC 17 Mar 2015 Outline About nervana Optimizing deep learning at assembler level Limited precision for deep learning neon benchmarks 2 About nervana
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability
 Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Machine Learning With Python. Bin Chen Nov. 7, 2017 Research Computing Center
 Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Parallel Deep Network Training
 Lecture 19: Parallel Deep Network Training Parallel Computer Architecture and Programming How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors
Lecture 19: Parallel Deep Network Training Parallel Computer Architecture and Programming How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors
INTRODUCTION TO DEEP LEARNING
 INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Neural Network Exchange Format
 Copyright Khronos Group 2017 - Page 1 Neural Network Exchange Format Deploying Trained Networks to Inference Engines Viktor Gyenes, specification editor Copyright Khronos Group 2017 - Page 2 Outlook The
Copyright Khronos Group 2017 - Page 1 Neural Network Exchange Format Deploying Trained Networks to Inference Engines Viktor Gyenes, specification editor Copyright Khronos Group 2017 - Page 2 Outlook The
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications
 Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
Learning Deep Representations for Visual Recognition
 Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Convolutional Neural Networks: Applications and a short timeline. 7th Deep Learning Meetup Kornel Kis Vienna,
 Convolutional Neural Networks: Applications and a short timeline 7th Deep Learning Meetup Kornel Kis Vienna, 1.12.2016. Introduction Currently a master student Master thesis at BME SmartLab Started deep
Convolutional Neural Networks: Applications and a short timeline 7th Deep Learning Meetup Kornel Kis Vienna, 1.12.2016. Introduction Currently a master student Master thesis at BME SmartLab Started deep
Scaling Distributed Machine Learning
 Scaling Distributed Machine Learning with System and Algorithm Co-design Mu Li Thesis Defense CSD, CMU Feb 2nd, 2017 nx min w f i (w) Distributed systems i=1 Large scale optimization methods Large-scale
Scaling Distributed Machine Learning with System and Algorithm Co-design Mu Li Thesis Defense CSD, CMU Feb 2nd, 2017 nx min w f i (w) Distributed systems i=1 Large scale optimization methods Large-scale
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters
 Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed