Understanding Dynamic Parallelism
|
|
|
- Erin Green
- 5 years ago
- Views:
Transcription

1 Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management
2 Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic Parallelism Questions & Answers
3 Allinea The Company Parallel development tools company since 2002 Leading in HPC software tools market worldwide Global customer base Making parallel programming accessible to the widest range of scientists and programmers Design an unrivaled productive and easy-to-use development environment To help you reach the highest level of performance and scalability Define a new standard of customer support



4 Allinea Unified environment A modern integrated environment for HPC developers Supporting the lifecycle of application development and improvement Allinea DDT : Productively debug code Allinea MAP : Enhance application performance Designed for productivity Consistent easy to use tools Enables effective HPC development Improve system usage Fewer failed jobs Higher application performance




5 Unified building blocks in production since 2010 Shared Graphical Interface Shared Configuration Files Shared Scalable Architecture Shared Intelligence and Data Consolidation
6 Allinea MAP Increase application performance Parallel profiler designed for: C/C++, Fortran Multiprocess code Interdependent or independent processes Multithreaded code Monitor the main threads for each process Accelerated codes GPUs, Intel Xeon Phi Improve productivity : Helps you detect performance issues quickly and easily Tells you immediately where your time is spent in your source code Helps you to optimize your application efficiently


7 Allinea MAP Find performance issues quickly Look at the entire application on real data sets Visualize the entire run at full scale, not just reduced sets Zoom in to explore iterations, functions and loops Understand the nature of bottlenecks Source code viewer pinpoints bottleneck locations CPU, MPI and memory access metrics identify the cause

8 Allinea DDT Fix software problems - fast Graphical debugger designed for: C/C++, Fortran, UPC, CUDA Multithreaded code Single address space Multiprocess code Interdependent or independent processes Accelerated codes GPUs, Intel Xeon Phi Any mix of the above Slash your time to debug : Reproduces and triggers your bugs instantly Helps you easily understand where issues come from quickly Helps you to fix them as swiftly as possible



9 Allinea DDT Scalable debugging by design Where did it happen? Allinea DDT leaps to source automatically Merges stacks from processes and threads How did it happen? Some faults evident instantly from source Why did it happen? Real-time data comparison and consolidation Unique Smart Highlighting coloring differences and changes Sparklines comparing data across processes

10 New in Allinea DDT 4.1 Debug problems even quicker Debugging logbook Records debugging activity Compare runs side-by-side Extends offline debugging capabilities Benefit : Compare sane runs to buggy runs to quickly narrow down your problem.

11 New in Allinea DDT 4.1 Debug problems even quicker

12 New in Allinea DDT 4.1 Debug problems even quicker Version control integration Highlights where source code has been changed Source code annotated with a change heatmap Support for Mercurial, CVS, SVN, Git Benefit : Quickly identify the cause of regressions by seeing at a glance what has changed
13 New in Allinea DDT 4.1 Debug problems even quicker



14 New in Allinea DDT 4.1 Tighten the link with VisIt Visualization enhancements Pick cells and interact with them in the debugger e.g. set a watchpoint Display of multiple datasets Wizard to guide data layout Benefit: Link visualization to precise memory areas to shorten the debugging process

 Support")

15 Leading the way to Innovation Support for accelerated environments CUDA 5.0 and Kepler 20 Intel Xeon Phi Coprocessor GPU directives (both OpenACC and non-openacc) Support for complex architectures Debug and profile MPI, OpenMP and CUDA combinations Supports low power CPU architectures (Moonshot program) Support for all major compilers, MPI and OpenMP implementations Murex : NVIDIA Carma Dev Kit Quick resolution of our customer issues 90% of support tickets are resolved within 7 days University of Gent
16 Today: Debugging Dynamic Parallelism on K20
17 Debugging Dynamic Parallelism
18 Debugging Dynamic Parallelism

19 Debugging Dynamic Parallelism wait, what?
20
21

22

23
24
25

26 Debugging Dynamic Parallelism
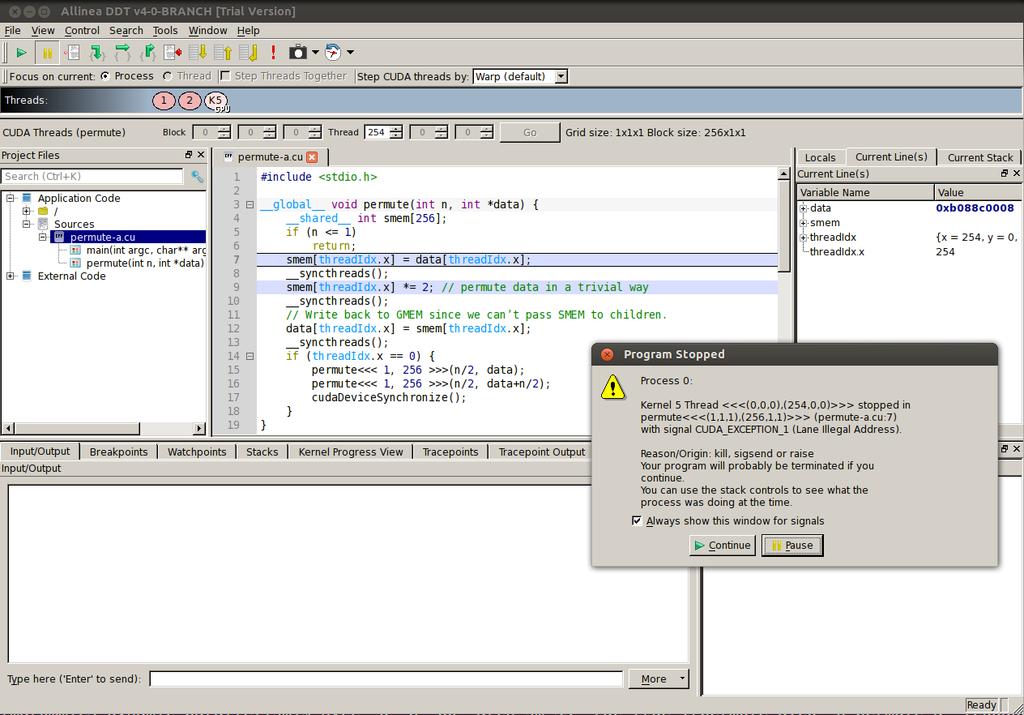
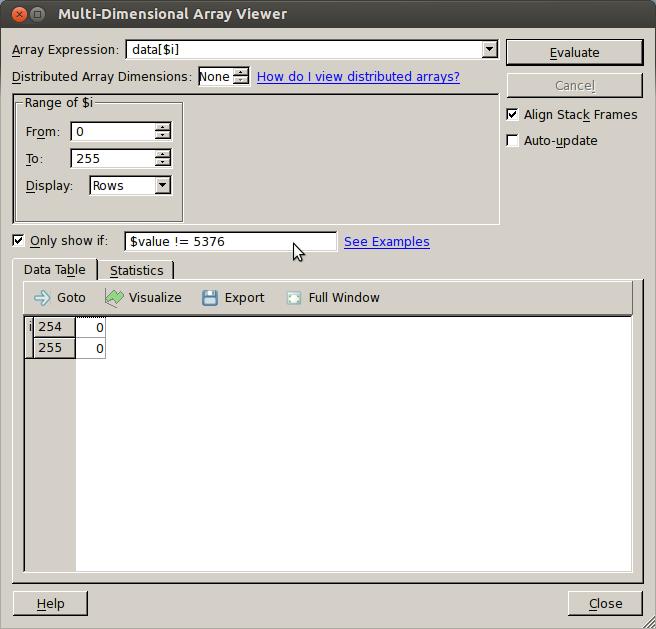
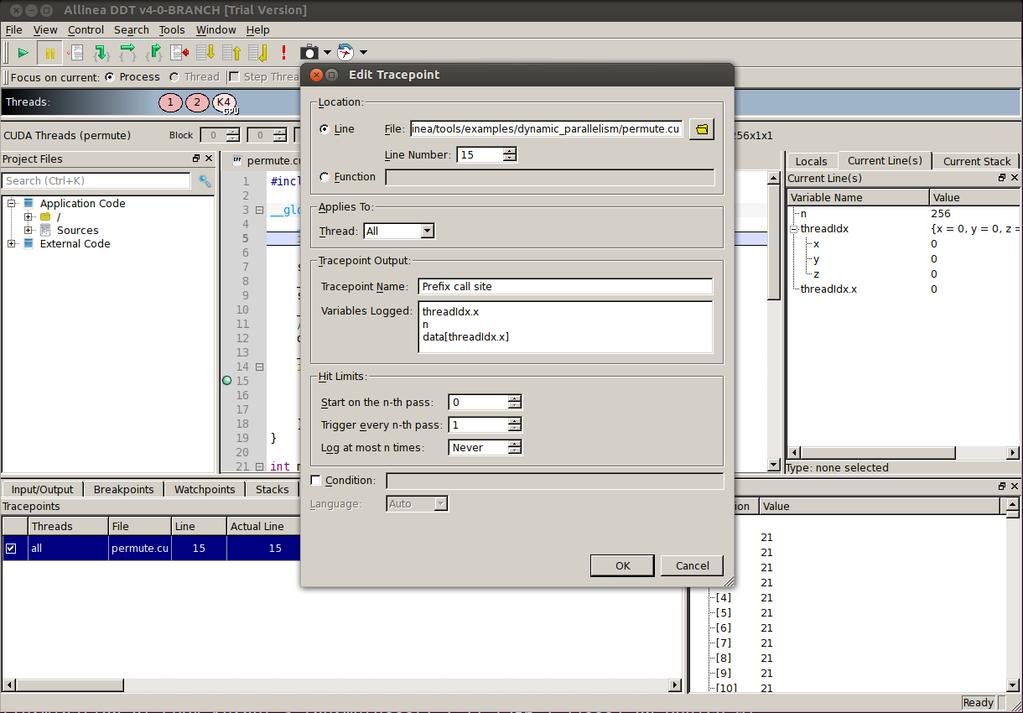
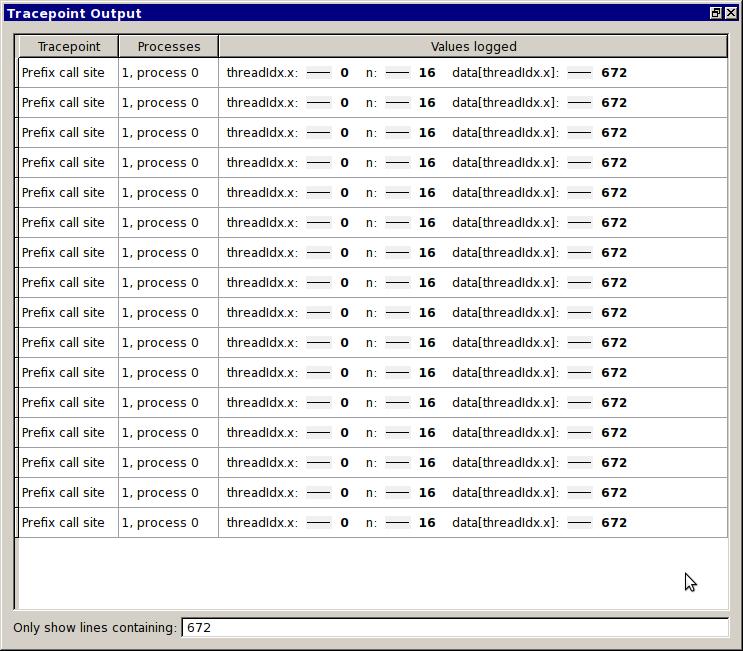
27 Debugging is About Understanding What actually happens here? Which values are put into data and when? What's the relationship between n and data? How many kernels are launched?

28
29
30
31

32
33

34
35

36
37


38 Allinea DDT + MAP An integrated, ready-to-run development suite Get correct results fast using the industry-leading parallel debugger Full support for NVIDIA CUDA 5 See which loops can be offloaded to the GPU most effectively with Allinea MAP
39 Questions and Answers Mark O Connor, VP Product Management Robert Rick, VP Sales, Director of Operations, Americas


40 Upcoming GTC Express Webinars July 10 Introduction to the CUDA Toolkit as an Application Build Tool Adam DeConinck, HPC Systems Engineer, NVIDIA July 11 Uncovering the Elusive HIV Capsid with Kepler GPUs Juan R. Perilla, Postdoctoral Fellow, University of Illinois at Urbana-Champaign Register at
Allinea Unified Environment
 Allinea Unified Environment Allinea s unified tools for debugging and profiling HPC Codes Beau Paisley Allinea Software bpaisley@allinea.com 720.583.0380 Today s Challenge Q: What is the impact of current
Allinea Unified Environment Allinea s unified tools for debugging and profiling HPC Codes Beau Paisley Allinea Software bpaisley@allinea.com 720.583.0380 Today s Challenge Q: What is the impact of current
Tools and Methodology for Ensuring HPC Programs Correctness and Performance. Beau Paisley
 Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge
 Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
GPU Debugging Made Easy. David Lecomber CTO, Allinea Software
 GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
Debugging for the hybrid-multicore age (A HPC Perspective) David Lecomber CTO, Allinea Software
 David Lecomber CTO, Allinea Software") Debugging for the hybrid-multicore age (A HPC Perspective) David Lecomber CTO, Allinea Software david@allinea.com Agenda What is HPC? How is scale affecting HPC? Achieving tool scalability Scale in practice
Debugging for the hybrid-multicore age (A HPC Perspective) David Lecomber CTO, Allinea Software david@allinea.com Agenda What is HPC? How is scale affecting HPC? Achieving tool scalability Scale in practice
Debugging HPC Applications. David Lecomber CTO, Allinea Software
 Debugging HPC Applications David Lecomber CTO, Allinea Software david@allinea.com Agenda Bugs and Debugging Debugging parallel applications Debugging OpenACC and other hybrid codes Debugging for Petascale
Debugging HPC Applications David Lecomber CTO, Allinea Software david@allinea.com Agenda Bugs and Debugging Debugging parallel applications Debugging OpenACC and other hybrid codes Debugging for Petascale
Accelerate HPC Development with Allinea Performance Tools
 Accelerate HPC Development with Allinea Performance Tools 19 April 2016 VI-HPS, LRZ Florent Lebeau / Ryan Hulguin flebeau@allinea.com / rhulguin@allinea.com Agenda 09:00 09:15 Introduction 09:15 09:45
Accelerate HPC Development with Allinea Performance Tools 19 April 2016 VI-HPS, LRZ Florent Lebeau / Ryan Hulguin flebeau@allinea.com / rhulguin@allinea.com Agenda 09:00 09:15 Introduction 09:15 09:45
CUDA Development Using NVIDIA Nsight, Eclipse Edition. David Goodwin
 CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
The Eclipse Parallel Tools Platform
 May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
Debugging at Scale Lindon Locks
 Debugging at Scale Lindon Locks llocks@allinea.com Debugging at Scale At scale debugging - from 100 cores to 250,000 Problems faced by developers on real systems Alternative approaches to debugging and
Debugging at Scale Lindon Locks llocks@allinea.com Debugging at Scale At scale debugging - from 100 cores to 250,000 Problems faced by developers on real systems Alternative approaches to debugging and
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2. (Mouse over to the left to see thumbnails of all of the slides)
") STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
GPU Technology Conference Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile
 GPU Technology Conference 2015 Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile What do
GPU Technology Conference 2015 Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile What do
Development tools to enable Multicore
 Development tools to enable Multicore From the desktop to the extreme A perspective on multicore looking in from HPC David Lecomber CTO, Allinea Software david@allinea.com Introduction The Multicore Challenge
Development tools to enable Multicore From the desktop to the extreme A perspective on multicore looking in from HPC David Lecomber CTO, Allinea Software david@allinea.com Introduction The Multicore Challenge
Welcomes PRACE/LinkSCEEM 2011 Winter School Jacques Philouze Vice President Sales & Marketing
 Welcomes PRACE/LinkSCEEM 2011 Winter School Jacques Philouze jacques@allinea.com Vice President Sales & Marketing Content Company Background Products in more depth Allinea OPT (Optimization and Profiling
Welcomes PRACE/LinkSCEEM 2011 Winter School Jacques Philouze jacques@allinea.com Vice President Sales & Marketing Content Company Background Products in more depth Allinea OPT (Optimization and Profiling
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Accelerator programming with OpenACC
 ..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Development Tools for Parallel Computing. David Lecomber CTO, Allinea Software
 Development Tools for Parallel Computing David Lecomber CTO, Allinea Software david@allinea.com Agenda Introduction What is HPC Bugs and Debugging Debugging parallel applications Challenges for the future
Development Tools for Parallel Computing David Lecomber CTO, Allinea Software david@allinea.com Agenda Introduction What is HPC Bugs and Debugging Debugging parallel applications Challenges for the future
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010
 Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Cuda C Programming Guide Appendix C Table C-
 Cuda C Programming Guide Appendix C Table C-4 Professional CUDA C Programming (1118739329) cover image into the powerful world of parallel GPU programming with this down-to-earth, practical guide Table
Cuda C Programming Guide Appendix C Table C-4 Professional CUDA C Programming (1118739329) cover image into the powerful world of parallel GPU programming with this down-to-earth, practical guide Table
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Guillimin HPC Users Meeting July 14, 2016
 Guillimin HPC Users Meeting July 14, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Guillimin HPC Users Meeting July 14, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Debugging, benchmarking, tuning i.e. software development tools. Martin Čuma Center for High Performance Computing University of Utah
 Debugging, benchmarking, tuning i.e. software development tools Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu SW development tools Development environments Compilers
Debugging, benchmarking, tuning i.e. software development tools Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu SW development tools Development environments Compilers
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
Welcome. HRSK Practical on Debugging, Zellescher Weg 12 Willers-Bau A106 Tel
 Center for Information Services and High Performance Computing (ZIH) Welcome HRSK Practical on Debugging, 03.04.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351-463 - 31945 Matthias Lieber (matthias.lieber@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Welcome HRSK Practical on Debugging, 03.04.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351-463 - 31945 Matthias Lieber (matthias.lieber@tu-dresden.de)
Intel Parallel Studio 2011
 THE ULTIMATE ALL-IN-ONE PERFORMANCE TOOLKIT Studio 2011 Product Brief Studio 2011 Accelerate Development of Reliable, High-Performance Serial and Threaded Applications for Multicore Studio 2011 is a comprehensive
THE ULTIMATE ALL-IN-ONE PERFORMANCE TOOLKIT Studio 2011 Product Brief Studio 2011 Accelerate Development of Reliable, High-Performance Serial and Threaded Applications for Multicore Studio 2011 is a comprehensive
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
ECMWF Workshop on High Performance Computing in Meteorology. 3 rd November Dean Stewart
 ECMWF Workshop on High Performance Computing in Meteorology 3 rd November 2010 Dean Stewart Agenda Company Overview Rogue Wave Product Overview IMSL Fortran TotalView Debugger Acumem ThreadSpotter 1 Copyright
ECMWF Workshop on High Performance Computing in Meteorology 3 rd November 2010 Dean Stewart Agenda Company Overview Rogue Wave Product Overview IMSL Fortran TotalView Debugger Acumem ThreadSpotter 1 Copyright
The Arm Technology Ecosystem: Current Products and Future Outlook
 The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Headline in Arial Bold 30pt. Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008
 Headline in Arial Bold 30pt Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008 Agenda Visualisation Today User Trends Technology Trends Grid Viz Nodes Software Ecosystem
Headline in Arial Bold 30pt Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008 Agenda Visualisation Today User Trends Technology Trends Grid Viz Nodes Software Ecosystem
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
COMP528: Multi-core and Multi-Processor Computing
 COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
HPC on Windows. Visual Studio 2010 and ISV Software
 HPC on Windows Visual Studio 2010 and ISV Software Christian Terboven 19.03.2012 / Aachen, Germany Stand: 16.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda
HPC on Windows Visual Studio 2010 and ISV Software Christian Terboven 19.03.2012 / Aachen, Germany Stand: 16.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda
Large Scale Debugging
 Large Scale Debugging Project Meeting Report - December 2015 Didier Nadeau Under the supervision of Michel Dagenais Distributed Open Reliable Systems Analysis Lab École Polytechnique de Montréal Table
Large Scale Debugging Project Meeting Report - December 2015 Didier Nadeau Under the supervision of Michel Dagenais Distributed Open Reliable Systems Analysis Lab École Polytechnique de Montréal Table
IBM High Performance Computing Toolkit
 IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Introduction to debugging. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to debugging Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu Overview Program errors Simple debugging Graphical debugging DDT and Totalview Intel tools
Introduction to debugging Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu Overview Program errors Simple debugging Graphical debugging DDT and Totalview Intel tools
OpenMP 4.0: A Significant Paradigm Shift in Parallelism
 OpenMP 4.0: A Significant Paradigm Shift in Parallelism Michael Wong OpenMP CEO michaelw@ca.ibm.com http://bit.ly/sc13-eval SC13 OpenMP 4.0 released 2 Agenda The OpenMP ARB History of OpenMP OpenMP 4.0
OpenMP 4.0: A Significant Paradigm Shift in Parallelism Michael Wong OpenMP CEO michaelw@ca.ibm.com http://bit.ly/sc13-eval SC13 OpenMP 4.0 released 2 Agenda The OpenMP ARB History of OpenMP OpenMP 4.0
Programming Environment 4/11/2015
 Programming Environment 4/11/2015 1 Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent interface
Programming Environment 4/11/2015 1 Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent interface
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Parallel Debugging with TotalView BSC-CNS
 Parallel Debugging with TotalView BSC-CNS AGENDA What debugging means? Debugging Tools in the RES Allinea DDT as alternative (RogueWave Software) What is TotalView Compiling Your Program Starting totalview
Parallel Debugging with TotalView BSC-CNS AGENDA What debugging means? Debugging Tools in the RES Allinea DDT as alternative (RogueWave Software) What is TotalView Compiling Your Program Starting totalview
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
OpenStaPLE, an OpenACC Lattice QCD Application
 OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
Debugging on Intel Platforms
 White Paper Robert Mueller-Albrecht Developer Products Division Intel Corporation Debugging on Intel Platforms Introduction...3 Overview...3 Servers and Workstations...4 Support for Linux*, Mac OS X*,
White Paper Robert Mueller-Albrecht Developer Products Division Intel Corporation Debugging on Intel Platforms Introduction...3 Overview...3 Servers and Workstations...4 Support for Linux*, Mac OS X*,
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Oracle Developer Studio 12.6
 Oracle Developer Studio 12.6 Oracle Developer Studio is the #1 development environment for building C, C++, Fortran and Java applications for Oracle Solaris and Linux operating systems running on premises
Oracle Developer Studio 12.6 Oracle Developer Studio is the #1 development environment for building C, C++, Fortran and Java applications for Oracle Solaris and Linux operating systems running on premises
Performance Analysis of Parallel Scientific Applications In Eclipse
 Performance Analysis of Parallel Scientific Applications In Eclipse EclipseCon 2015 Wyatt Spear, University of Oregon wspear@cs.uoregon.edu Supercomputing Big systems solving big problems Performance gains
Performance Analysis of Parallel Scientific Applications In Eclipse EclipseCon 2015 Wyatt Spear, University of Oregon wspear@cs.uoregon.edu Supercomputing Big systems solving big problems Performance gains
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future
 HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future Dr. R. Glenn Brook & Shane Sawyer Joint Institute For Computational Sciences University of Tennessee, Knoxville Dr. Bhanu
HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future Dr. R. Glenn Brook & Shane Sawyer Joint Institute For Computational Sciences University of Tennessee, Knoxville Dr. Bhanu
Eliminate Memory Errors to Improve Program Stability
 Introduction INTEL PARALLEL STUDIO XE EVALUATION GUIDE This guide will illustrate how Intel Parallel Studio XE memory checking capabilities can find crucial memory defects early in the development cycle.
Introduction INTEL PARALLEL STUDIO XE EVALUATION GUIDE This guide will illustrate how Intel Parallel Studio XE memory checking capabilities can find crucial memory defects early in the development cycle.
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT
 7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
Debugging and profiling of MPI programs
 Debugging and profiling of MPI programs The code examples: http://syam.sharcnet.ca/mpi_debugging.tgz Sergey Mashchenko (SHARCNET / Compute Ontario / Compute Canada) Outline Introduction MPI debugging MPI
Debugging and profiling of MPI programs The code examples: http://syam.sharcnet.ca/mpi_debugging.tgz Sergey Mashchenko (SHARCNET / Compute Ontario / Compute Canada) Outline Introduction MPI debugging MPI
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
To hear the audio, please be sure to dial in: ID#
 Introduction to the HPP-Heterogeneous Processing Platform A combination of Multi-core, GPUs, FPGAs and Many-core accelerators To hear the audio, please be sure to dial in: 1-866-440-4486 ID# 4503739 Yassine
Introduction to the HPP-Heterogeneous Processing Platform A combination of Multi-core, GPUs, FPGAs and Many-core accelerators To hear the audio, please be sure to dial in: 1-866-440-4486 ID# 4503739 Yassine
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Oracle Developer Studio Performance Analyzer
 Oracle Developer Studio Performance Analyzer The Oracle Developer Studio Performance Analyzer provides unparalleled insight into the behavior of your application, allowing you to identify bottlenecks and
Oracle Developer Studio Performance Analyzer The Oracle Developer Studio Performance Analyzer provides unparalleled insight into the behavior of your application, allowing you to identify bottlenecks and
Eliminate Threading Errors to Improve Program Stability
 Eliminate Threading Errors to Improve Program Stability This guide will illustrate how the thread checking capabilities in Parallel Studio can be used to find crucial threading defects early in the development
Eliminate Threading Errors to Improve Program Stability This guide will illustrate how the thread checking capabilities in Parallel Studio can be used to find crucial threading defects early in the development
Developing Scientific Applications with the IBM Parallel Environment Developer Edition
 Developing Scientific Applications with the IBM Parallel Environment Developer Edition Greg Watson, IBM grw@us.ibm.com Christoph Pospiech, IBM christoph.pospiech@de.ibm.com ScicomP 13 May 2013 Portions
Developing Scientific Applications with the IBM Parallel Environment Developer Edition Greg Watson, IBM grw@us.ibm.com Christoph Pospiech, IBM christoph.pospiech@de.ibm.com ScicomP 13 May 2013 Portions
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
This guide will show you how to use Intel Inspector XE to identify and fix resource leak errors in your programs before they start causing problems.
 Introduction A resource leak refers to a type of resource consumption in which the program cannot release resources it has acquired. Typically the result of a bug, common resource issues, such as memory
Introduction A resource leak refers to a type of resource consumption in which the program cannot release resources it has acquired. Typically the result of a bug, common resource issues, such as memory
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
ELP. Effektive Laufzeitunterstützung für zukünftige Programmierstandards. Speaker: Tim Cramer, RWTH Aachen University
 ELP Effektive Laufzeitunterstützung für zukünftige Programmierstandards Agenda ELP Project Goals ELP Achievements Remaining Steps ELP Project Goals Goals of ELP: Improve programmer productivity By influencing
ELP Effektive Laufzeitunterstützung für zukünftige Programmierstandards Agenda ELP Project Goals ELP Achievements Remaining Steps ELP Project Goals Goals of ELP: Improve programmer productivity By influencing
SENSEI / SENSEI-Lite / SENEI-LDC Updates
 SENSEI / SENSEI-Lite / SENEI-LDC Updates Chris Roy and Brent Pickering Aerospace and Ocean Engineering Dept. Virginia Tech July 23, 2014 Collaborations with Math Collaboration on the implicit SENSEI-LDC
SENSEI / SENSEI-Lite / SENEI-LDC Updates Chris Roy and Brent Pickering Aerospace and Ocean Engineering Dept. Virginia Tech July 23, 2014 Collaborations with Math Collaboration on the implicit SENSEI-LDC
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
NightStar. NightView Source Level Debugger. Real-Time Linux Debugging and Analysis Tools BROCHURE
 NightStar Real-Time Linux Debugging and Analysis Tools Concurrent s NightStar is a powerful, integrated tool set for debugging and analyzing time-critical Linux applications. NightStar tools run with minimal
NightStar Real-Time Linux Debugging and Analysis Tools Concurrent s NightStar is a powerful, integrated tool set for debugging and analyzing time-critical Linux applications. NightStar tools run with minimal
Programming for the Intel Many Integrated Core Architecture By James Reinders. The Architecture for Discovery. PowerPoint Title
 Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Arm crossplatform. VI-HPS platform October 16, Arm Limited
 Arm crossplatform tools VI-HPS platform October 16, 2018 An introduction to Arm Arm is the world's leading semiconductor intellectual property supplier We license to over 350 partners: present in 95% of
Arm crossplatform tools VI-HPS platform October 16, 2018 An introduction to Arm Arm is the world's leading semiconductor intellectual property supplier We license to over 350 partners: present in 95% of
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation