Chapter 1. Introduction
|
|
|
- Winifred Weaver
- 6 years ago
- Views:
Transcription

1 Chapter 1 Introduction
2 Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand nuclear physics because it is too fast. It is hard to understand the greenhouse effect because it is too slow. Supercomputers break these barriers to understanding. They, in effect, shrink oceans, zoom in on molecules, slow down physics, and fastforward climates. Clearly a scientist who can see natural phenomena at the right size and the right speed learns more than one who is faced with a blur. Al Gore,
3 Why High Performance Computing? Grand Challenges (Basic Research) Decoding of human genome Kosmogenesis Global Climate Changes Biological Macro molecules Product development Fluid mechanics Crash tests Material minimization Drug design Chip design IT Infrastructure Search engines Data Mining Virtual Reality Rendering Vision 1-3

4 Examples for HPC-Applications: Finite Element Method: Crash-Analysis Asymmetric frontal impact of a car to a rigid obstacle 1-4

5 Examples for HPC-Applications: Aerodynamics 1-5
 with a")

6 Examples for HPC-Applications: Molecular dynamics Simulation of a noble gas (Argon) with a partitioning for 8 processors: 2048 molecules in a cube of16 nm edge length simulated in time steps of 2x10-14 sec. 1-6

7 Examples for HPC-Applications: Nuclear Energy 1946 Baker Test Tons TNT Lots of nukes produced during the cold war Status today: Largely unknown Source: Wikipedia 1-7
 Rendering")

8 Examples for HPC-Applications: Visualization Rendering (Interior architecture) Rendering (Movie: Titanic) Photo realistic presentation using sophisticated illumination modules 1-8
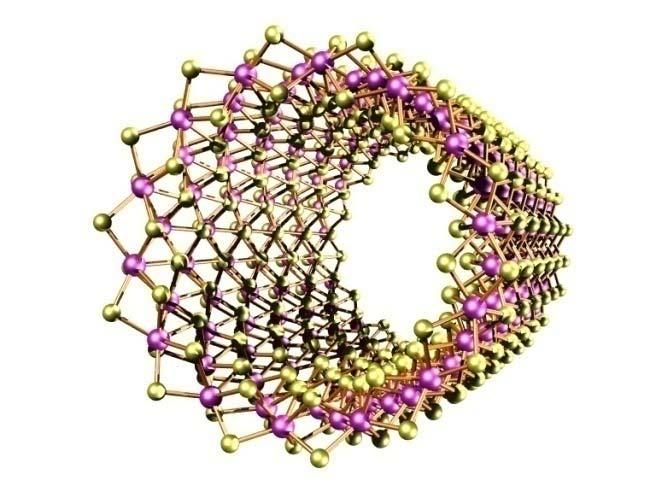
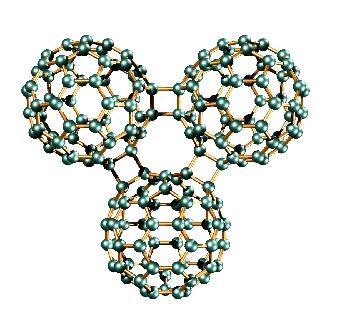

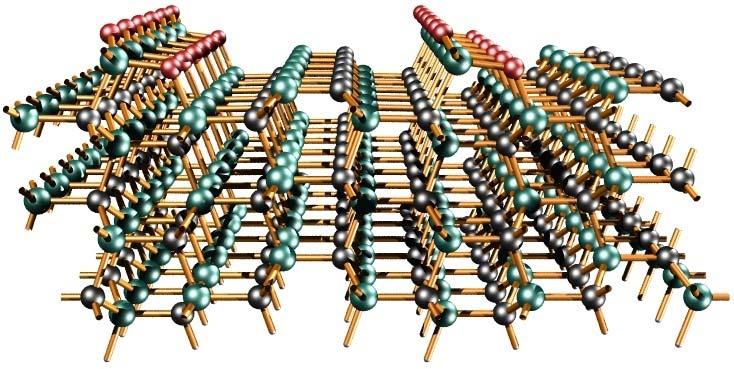
9 Examples for HPC-Applications: Analysis of complex materials C 60 -trimer Si 1600 MoS 2 4H-SiC Source: Th. Frauenheim, Paderborn 1-9
10 Grosch's Law Performance Price The performance of a computer increases (roughly) quadratically with the prize" Consequence: It is better to buy a computer which is twice as fast than to buy two slower computers. (The law was valid in the sixties and seventies over a wide range of universal computers.) 1-10
11 Eighties Availability of powerful Microprocessors High Integration density (VLSI) Single-Chip-Processors Automated production process Automated development process High volume production Consequence: Grosch's Law no longer valid: 1000 cheap microprocessors render (theoretically) more performance in (MFLOPS) than expensive Supercomputer (e.g. Cray) Idea: To achieve high performance at low cost use many microprocessors together Parallel Processing 1-11
12 Eighties Wide spread use of workstations and PCs Terminals being replaced by PCs Workstations achieve (computational) performance of mainframes at a fraction of the price. Availability of local area networks (LAN) (Ethernet) Possibility to connect a larger number of autonomous computers using a low cost medium. Access to data of other computers. Usage of programs and other resources of remote computers. Network of Workstations as Parallel Computer Possibility to exploit unused computational capacity of other computers for computational-intensive calculations (idle time computing). 1-12
13 Nineties Parallel computers are built of a large number of microprocessors (Massively Parallel Processors, MPP), e. g. Transputer systems, Connection Machine CM-5, Intel Paragon, Cray T3E Alternative Architectures are built (Connection Machine CM-2, MasPar). Trend to use cost efficient standard components ( commercial-offthe-shelf, COTS ) leads to coupling of standard PCs to a Cluster (Beowulf, 1995) Exploitation of unused compute power for HPC ( idle time computing ) Program libraries like Parallel Virtual Machine(PVM) and the Message Passing Interface (MPI) allow for development of portable parallel programs Linux as operating system for HPC becomes prevailing 1-13

")

14 Top 10 of TOP500 List (06/2001) 1-14
")
15 Top 10 of TOP500 List (06/2002) 1-15
")
16 Earth Simulator (Rank 1, ) 1-16

17 Earth Simulator 640 Nodes 8 vector processors (each 8 GFLOPS) and 16 GB per node 5120 CPUs 10 TB main memory 40 TFLOPS peak performance 65m x 50m physical dimension Source: H.Simon, NERSC 1-17
18 TOP 10 / Nov Rank Site Country/Year 1 IBM/DOE United States/ NASA/Ames Research Center/NAS United States/ The Earth Simulator Center Japan/ Barcelona Supercomputer Center Spain/ Lawrence Livermore National Laboratory United States/ Los Alamos National Laboratory United States/ Virginia Tech United States/ IBM - Rochester United States/ Naval Oceanographic Office United States/ NCSA United States/2003 Computer / Processors Manufacturer BlueGene/L beta-system BlueGene/L DD2 beta-system (0.7 GHz PowerPC 440) / IBM Columbia SGI Altix 1.5 GHz, Voltaire Infiniband / SGI Earth-Simulator / 5120 NEC MareNostrum eserver BladeCenter JS20 (PowerPC GHz), Myrinet / 3564 IBM Thunder Intel Itanium2 Tiger4 1.4GHz - Quadrics / 4096 California Digital Corporation ASCI Q ASCI Q - AlphaServer SC45, 1.25 GHz / 8192 HP System X 1100 Dual 2.3 GHz Apple XServe/Mellanox Infiniband 4X/Cisco GigE / 2200 Self-made BlueGene/L DD1 Prototype (0.5GHz PowerPC 440 w/custom) / 8192 IBM/ LLNL eserver pseries 655 (1.7 GHz Power4+) / 2944 IBM Tungsten PowerEdge 1750, P4 Xeon 3.06 GHz, Myrinet / 2500 Dell R max R peak
19 Rank Site Computer Processors Year R max 1 DOE/NNSA/LLNL United States BlueGene/L - eserver Blue Gene Solution IBM IBM Thomas J. Watson Research Center United States BGW - eserver Blue Gene Solution IBM DOE/NNSA/LLNL United States ASC Purple - eserver pseries p GHz IBM TOP 10 / Nov NASA/Ames Research Center/NAS United States Sandia National Laboratories United States Sandia National Laboratories United States The Earth Simulator Center Japan Barcelona Supercomputer Center Spain Columbia - SGI Altix 1.5 GHz, Voltaire Infiniband SGI Thunderbird - PowerEdge 1850, 3.6 GHz, Infiniband Dell Red Storm Cray XT3, 2.0 GHz Cray Inc. Earth-Simulator NEC MareNostrum - JS20 Cluster, PPC 970, 2.2 GHz, Myrinet IBM ASTRON/University Groningen Netherlands Stella - eserver Blue Gene Solution IBM Oak Ridge National Laboratory United States Jaguar - Cray XT3, 2.4 GHz Cray Inc



20 IBM Blue Gene 1-20





21 IBM Blue Gene 1-21


22 TOP 10 / Nov
23 Top 500 Nov 2008 Rank Computer Country Year Cores RMax Processor Family System Family Interconnect 1 BladeCenter QS22/LS21 Cluster, PowerXCell 8i 3.2 IBM Ghz / Opteron DC 1.8 GHz, Voltaire Infiniband United States Power Cluster Infiniband 2 Cray XT5 QC 2.3 GHz United States AMD x86_64 Cray XT Proprietary 3 SGI Altix ICE 8200EX, Xeon QC 3.0/2.66 GHz United States Intel EM64T SGI Altix Infiniband IBM 4 eserver Blue Gene Solution United States Power BlueGene Proprietary 5 Blue Gene/P Solution United States Power IBM BlueGene Proprietary Sun Blade 6 SunBlade x6420, Opteron QC 2.3 Ghz, Infiniband United States AMD x86_64 System Infiniband 7 Cray XT4 QuadCore 2.3 GHz United States AMD x86_64 Cray XT Proprietary 8 Cray XT4 QuadCore 2.1 GHz United States AMD x86_64 Cray XT Proprietary 9 Sandia/ Cray Red Storm, XT3/4, 2.4/2.2 GHz Cray Interconnect dual/quad core United States AMD x86_64 Cray XT Dawning 5000A, QC Opteron 1.9 Ghz, Infiniband, Dawning 10 Windows HPC 2008 China AMD x86_64cluster Infiniband 1-23
24 Top 500 Nov 2008 Rank Computer Country Year Cores RMax Processor Family System Family Interconnect 11 Blue Gene/P Solution Germany Power IBM BlueGene Proprietary Intel 12 SGI Altix ICE 8200, Xeon quad core 3.0 GHz United States EM64T SGI Altix Infiniband 13 Cluster Platform 3000 BL460c, Xeon 53xx 3GHz, Infiniband India SGI Altix ICE 8200EX, Xeon quad core 3.0 GHz France Cray XT4 QuadCore 2.3 GHz United States HP Cluster Intel EM64T Platform 3000BL Infiniband Intel EM64T SGI Altix Infiniband AMD x86_64 Cray XT Proprietary 16 Blue Gene/P Solution France Power IBM BlueGene Proprietary Intel 17 SGI Altix ICE 8200EX, Xeon quad core 3.0 GHz France EM64T SGI Altix Infiniband Cluster Platform 3000 BL460c, Xeon 53xx 2.66GHz, Infiniband Sweden Intel EM64T DeepComp 7000, HS21/x3950 Cluster, Xeon QC HT Intel 3 GHz/2.93 GHz, Infiniband China EM64T HP Cluster Platform 3000BL Lenovo Cluster Infiniband Infiniband 1-24
25 Top 500 Nov 2009 Rank Site Computer/Year Vendor Cores R max R peak Power Oak Ridge National Laboratory United States DOE/NNSA/LANL United States National Institute for Computational Sciences/University of Tennessee United States Forschungszentrum Juelich (FZJ) Germany National SuperComputer Center in Tianjin/NUDT / China NASA/Ames Research Center/NAS United States Jaguar - Cray XT5-HE Opteron Six Core 2.6 GHz / 2009 Cray Inc. Roadrunner - BladeCenter QS22/LS21 Cluster, PowerXCell 8i 3.2 Ghz / Opteron DC 1.8 GHz, Voltaire Infiniband / 2009 IBM Kraken XT5 - Cray XT5-HE Opteron Six Core 2.6 GHz / 2009 / Cray Inc JUGENE - Blue Gene/P Solution / 2009 / IBM Tianhe-1 - NUDT TH-1 Cluster, Xeon E5540/E5450, ATI Radeon HD , Infiniband / 2009 / NUDT Pleiades - SGI Altix ICE 8200EX, Xeon QC 3.0 GHz/Nehalem EP 2.93 Ghz / 2009 / SGI DOE/NNSA/LLNL / United States BlueGene/L - eserver Blue Gene Solution / 2007 / IBM Argonne National Laboratory United States Texas Advanced Computing Center/Univ. of Texas / United States Blue Gene/P Solution / 2007 / IBM Ranger - SunBlade x6420, Opteron QC 2.3 Ghz, Infiniband / 2008 / Sun Microsystems Sandia National Laboratories / National Renewable Energy Laboratory / United States Red Sky - Sun Blade x6275, Xeon X55xx 2.93 Ghz, Infiniband / 2009 / Sun Microsystems
26 Top 500 Nov 2011 Rank Computer Site Country Total Cores Rmax Rpeak K computer, SPARC64 VIIIfx 2.0GHz, Tofu RIKEN Advanced Institute for 1 interconnect Computational Science (AICS) Japan NUDT YH MPP, Xeon X5670 6C 2.93 GHz, National Supercomputing Center in 2 NVIDIA 2050 Tianjin China Cray XT5-HE Opteron 6-core 2.6 GHz Dawning TC3600 Blade System, Xeon X5650 6C 2.66GHz, Infiniband QDR, 4 NVIDIA 2050 HP ProLiant SL390s G7 Xeon 6C X5670, 5 Nvidia GPU, Linux/Windows Cray XE6, Opteron C 2.40GHz, 6 Custom SGI Altix ICE 8200EX/8400EX, Xeon HT QC 3.0/Xeon 5570/ Ghz, 7 Infiniband Cray XE6, Opteron C 2.10GHz, 8 Custom 9 Bull bullx super-node S6010/S6030 BladeCenter QS22/LS21 Cluster, PowerXCell 8i 3.2 Ghz / Opteron DC GHz, Voltaire Infiniband DOE/SC/Oak Ridge National Laboratory United States National Supercomputing Centre in Shenzhen (NSCS) China GSIC Center, Tokyo Institute of Technology Japan United DOE/NNSA/LANL/SNL States NASA/Ames Research Center/NAS United States United DOE/SC/LBNL/NERSC States Commissariat a l'energie Atomique (CEA) France DOE/NNSA/LANL United States



27 K-computer (AICS), Rank racks with 88,128 SPARC64 CPUs / 705,024 cores 200,000 cables with total length over 1,000km third floor (50m x 60m) free of structural pillars. New problem: floor load capacity of 1t/m 2 (avg.) Each rack has up to 1.5t High-tech construction required first floor with global file system has just three pillars Own power station (300m 2 ) 1-27

28 The K-Computer 2013: Human Brain Simulation (Coop: Forschungszentrum Jülich) Simulating 1 second of the activity of 1% of a Brain took 40 Minutes. Simulation of a whole Brain possible with Exascale Computers? 1-28

29 Jugene (Forschungszentrum Jülich), Rank
30 Top 500 Nov 2012 Rank Name Computer Site Country Total Cores Rmax Rpeak Cray XK7, Opteron C DOE/SC/Oak Ridge National 1 Titan 2.200GHz, Cray Gemini United States Laboratory interconnect, NVIDIA K20x BlueGene/Q, Power BQC 16C Sequoia DOE/NNSA/LLNL United States ,2 GHz, Custom K computer, SPARC64 VIIIfx RIKEN Advanced Institute for 3 K computer Japan Mira 5 JUQUEEN 6 SuperMUC 7 Stampede 8 Tianhe-1A 9 Fermi 10 DARPA Trial Subset 2.0GHz, Tofu interconnect BlueGene/Q, Power BQC 16C 1.60GHz, Custom BlueGene/Q, Power BQC 16C 1.600GHz, Custom Interconnect idataplex DX360M4, Xeon E C 2.70GHz, Infiniband FDR PowerEdge C8220, Xeon E C 2.700GHz, Infiniband FDR, Intel Xeon Phi NUDT YH MPP, Xeon X5670 6C 2.93 GHz, NVIDIA 2050 BlueGene/Q, Power BQC 16C 1.60GHz, Custom Power 775, POWER7 8C 3.836GHz, Custom Interconnect Computational Science (AICS) DOE/SC/Argonne National Laboratory Forschungszentrum Juelich (FZJ) United States Germany Leibniz Rechenzentrum Germany Texas Advanced Computing Center/Univ. of Texas National Supercomputing Center in Tianjin United States China CINECA Italy IBM Development Engineering United States ,
31 Top 500 Nov 2013 Rank Name Computer Site Country Total Cores Rmax Rpeak 1 TH-IVB-FEP Cluster, Intel Xeon E5- Tianhe C 2.200GHz, TH Express-2, (MilkyWay-2) Intel Xeon Phi 31S1P 2 Titan 3 Sequoia Cray XK7, Opteron C 2.200GHz, Cray Gemini interconnect, NVIDIA K20x BlueGene/Q, Power BQC 16C 1.60 GHz, Custom National Super Computer Center in Guangzhou DOE/SC/Oak Ridge National Laboratory China United States DOE/NNSA/LLNL United States ,2 4 Kcomputer K computer, SPARC64 VIIIfx 2.0GHz, Tofu interconnect RIKEN Advanced Institute for Computational Science (AICS) Japan Mira BlueGene/Q, Power BQC 16C 1.60GHz, Custom DOE/SC/Argonne National Laboratory United States Piz Daint Cray XC30, Xeon E C Swiss National Supercomputing 2.600GHz, Aries interconnect, NVIDIA Centre (CSCS) K20x Switzerland ,8 7 Stampede PowerEdge C8220, Xeon E C 2.700GHz, Infiniband FDR, Intel Xeon Phi SE10P Texas Advanced Computing Center/Univ. of Texas United States ,6 8 JUQUEEN 9 Vulcan BlueGene/Q, Power BQC 16C 1.600GHz, Custom Interconnect BlueGene/Q, Power BQC 16C 1.600GHz, Custom Interconnect Forschungszentrum Juelich (FZJ) Germany ,6 DOE/NNSA/LLNL United States SuperMUC idataplex DX360M4, Xeon E C Leibniz Rechenzentrum Germany GHz, Infiniband FDR 1-31
 48000 Xeon Phi 31S1P (57 Cores, 1.")
32 Tianhe-2 (MilkyWay-2), National Super Computer Center in Guangzhou, Rank 1 Intel Xeon systems with Xeon Phi accelerators Xeon E (12 Core, 2.2 Ghz) Xeon Phi 31S1P (57 Cores, 1.1 GHz) Organization: Nodes, each 2 Xeon E Xeon Phi 31S1P 1408 TB Memory 1024 TB CPUs (64 GB per node) 384 TB Xeon Phi (3x8 GB per node) Power 17.6 MW (24 MW with cooling) 1-32
 AMD Opteron 6274 16-core CPU Nvidia Tesla K20X GPU Memory: 32GB (CPU) + 6 GB (GPU) Cray Linux Environment Power 8.2 MW 1-33")
33 Titan (Oak Ridge National Laboratory), Rank 2 (2012: R1) Cray XK7 18,688 nodes with 299,008 cores, 710 TB (598 TB CPU and 112 TB GPU) AMD Opteron core CPU Nvidia Tesla K20X GPU Memory: 32GB (CPU) + 6 GB (GPU) Cray Linux Environment Power 8.2 MW 1-33
 Network: 5D Torus 40 GBps; 2.5 μsec latency (worst case) Overall peak performance: 5.9 Petaflops Linpack: > 4.")
34 JUQUEEN (Forschungszentrum Jülich), Rank 8 (2012: Rank 5) 28 racks (7 rows à 4 racks) 28,672 nodes (458,752 cores) Rack: 2 midplanes à 16 nodeboards (16,384 cores) Nodeboard: 32 compute nodes Node: 16 cores IBM PowerPC A2, 1.6 GHz Main memory: 448 TB (16 GB per node) Network: 5D Torus 40 GBps; 2.5 μsec latency (worst case) Overall peak performance: 5.9 Petaflops Linpack: > Petaflops 1-34

35 HERMIT (HLRS Stuttgart), Rank 39 (2012: Rank 27) Cray XE Nodes Cores 126TB RAM 1-35
36 Top 500 Nov 2014 R Site System Cores 1 China Tianhe-2 (MilkyWay-2) 3,120,0 00 Rmax (TF/s) Rpeak (TF/s) Power (kw) 33, , ,808 2 United States Titan 560,640 17, , ,209 3 United States Sequoia 1,572, , , ,890 4 Japan K computer 705,024 10, , ,660 5 United States Mira 786,432 8, , ,945 6 Switzerland Piz Daint 115,984 6, , ,325 7 United States Stampede 462,462 5, , ,510 8 Germany JUQUEEN 458,752 5, , ,301 9 United States Vulcan 393,216 4, , , United States Cray CS-Storm 72,800 3, , ,

37 Green 500 Top entries Nov
38 Top 500 vs. Green 500 Top System Tianhe-2 (MilkyWay- 2) Rmax (TF/s) Rpeak (TF/s) Power (kw) Green , , , Titan 17, , , Sequoia 17, , , K computer 10, , , Mira 8, , , Piz Daint 6, , , Stampede 5, , , JUQUEEN 5, , , Vulcan 4, , , Cray CS- Storm 3, , ,
, Rank 120 +")
39 HLRN (Hannover + Berlin), Rank





40 Volunteer Computing 1-40


41 Slide 41
42 Cloud Computing (XaaS) Usage of remote physical and logical resources Software as a service Platform as a service Infrastructure as a service 1-42
43 Supercomputer in the Cloud: Rank 64 Amazon EC2 C3 Instance Intel Xeon E5-2680v2 10C 2.800GHz 10G Ethernet Cores (according to TOP500 list) Rmax: GFLOPS Rpeak: ,4 GFLOPS 1-43
44 Support for parallel programs Parallel Application Program libraries (e.g. communication, synchronization,..) Middleware (e.g. administration, scheduling,..) lok.bs lok.bs Distributed lok.bs operating lok.bs system lok.bs lok.bs node 1 node 2 node 3 node 4 node 5 node n Connection network 1-44
45 Tasks User s point of view (programming comfort, short response times) Efficient Interaction (Information exchange) Message passing Shared memory Synchronization Automatic distribution and allocation of code and data Load balancing Debugging support Security Machine independence Operator s point of view (High utilization, high throughput) Multiprogramming / Partitioning Time sharing Space sharing Load distribution / Load balancing Stability Security 1-45
Top500
 Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Chapter 5b: top500. Top 500 Blades Google PC cluster. Computer Architecture Summer b.1
 Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics
 CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek
 1 HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse, b known, x computed. An optimized implementation
1 HPCG UPDATE: SC 15 Jack Dongarra Michael Heroux Piotr Luszczek HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse, b known, x computed. An optimized implementation
20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen
 20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen Hans Meuer Prometeus GmbH & Universität Mannheim hans@meuer.de ZKI Herbsttagung in Leipzig 11. - 12. September 2012 page 1 Outline Mannheim Supercomputer
20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen Hans Meuer Prometeus GmbH & Universität Mannheim hans@meuer.de ZKI Herbsttagung in Leipzig 11. - 12. September 2012 page 1 Outline Mannheim Supercomputer
High-Performance Computing - and why Learn about it?
 High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future
 Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
CSE5351: Parallel Procesisng. Part 1B. UTA Copyright (c) Slide No 1
 Slide No 1") Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
An Overview of High Performance Computing
 IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
HPC as a Driver for Computing Technology and Education
 HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING Top 10 Supercomputers in the World as of November 2013*
 CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014 COMPUTERS : PRESENT, PAST & FUTURE Top 10 Supercomputers in the World as of November 2013* No Site Computer Cores Rmax + (TFLOPS) Rpeak (TFLOPS)
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014 COMPUTERS : PRESENT, PAST & FUTURE Top 10 Supercomputers in the World as of November 2013* No Site Computer Cores Rmax + (TFLOPS) Rpeak (TFLOPS)
Emerging Heterogeneous Technologies for High Performance Computing
 MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
HPC Technology Update Challenges or Chances?
 HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
An approach to provide remote access to GPU computational power
 An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory
 Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory 2013 International Workshop on Computational Science and Engineering National University of Taiwan
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory 2013 International Workshop on Computational Science and Engineering National University of Taiwan
HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek
 www.hpcg-benchmark.org 1 HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek www.hpcg-benchmark.org 2 HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse,
www.hpcg-benchmark.org 1 HPCG UPDATE: ISC 15 Jack Dongarra Michael Heroux Piotr Luszczek www.hpcg-benchmark.org 2 HPCG Snapshot High Performance Conjugate Gradient (HPCG). Solves Ax=b, A large, sparse,
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
Seagate ExaScale HPC Storage
 Seagate ExaScale HPC Storage Miro Lehocky System Engineer, Seagate Systems Group, HPC1 100+ PB Lustre File System 130+ GB/s Lustre File System 140+ GB/s Lustre File System 55 PB Lustre File System 1.6
Seagate ExaScale HPC Storage Miro Lehocky System Engineer, Seagate Systems Group, HPC1 100+ PB Lustre File System 130+ GB/s Lustre File System 140+ GB/s Lustre File System 55 PB Lustre File System 1.6
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
CINECA and the European HPC Ecosystem
 CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory
 Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title TOP500 Supercomputers for June 2005 Permalink https://escholarship.org/uc/item/4h84j873 Authors Strohmaier, Erich Meuer,
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title TOP500 Supercomputers for June 2005 Permalink https://escholarship.org/uc/item/4h84j873 Authors Strohmaier, Erich Meuer,
Parallel Computing & Accelerators. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
Parallel Computing Accelerators John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Purpose of this talk This is the 50,000 ft. view of the parallel computing landscape. We want
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Why we need Exascale and why we won t get there by 2020
 Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory August 27, 2013 Overview Current state of HPC: petaflops firmly established Why we won t get to
Why we need Exascale and why we won t get there by 2020 Horst Simon Lawrence Berkeley National Laboratory August 27, 2013 Overview Current state of HPC: petaflops firmly established Why we won t get to
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
ECE 574 Cluster Computing Lecture 2
 ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
An Overview of High Performance Computing. Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/2005 1
 An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
HPC Algorithms and Applications
 HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
Report on the Sunway TaihuLight System. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Outline. Execution Environments for Parallel Applications. Supercomputers. Supercomputers
 Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Overview. High Performance Computing - History of the Supercomputer. Modern Definitions (II)
") Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Roadmapping of HPC interconnects
 Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
The TOP500 list. Hans-Werner Meuer University of Mannheim. SPEC Workshop, University of Wuppertal, Germany September 13, 1999
 The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
Presentation of the 16th List
 Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Jack Dongarra INNOVATIVE COMP ING LABORATORY. University i of Tennessee Oak Ridge National Laboratory
 Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Jack Dongarra University of Tennessee Oak Ridge National Laboratory
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
LQCD Computing at BNL
 LQCD Computing at BNL 2012 USQCD All-Hands Meeting Fermilab May 4, 2012 Robert Mawhinney Columbia University Some BNL Computers 8k QCDSP nodes 400 GFlops at CU 1997-2005 (Chulwoo, Pavlos, George, among
LQCD Computing at BNL 2012 USQCD All-Hands Meeting Fermilab May 4, 2012 Robert Mawhinney Columbia University Some BNL Computers 8k QCDSP nodes 400 GFlops at CU 1997-2005 (Chulwoo, Pavlos, George, among
HPC IN EUROPE. Organisation of public HPC resources
 HPC IN EUROPE Organisation of public HPC resources Context Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded
HPC IN EUROPE Organisation of public HPC resources Context Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu
 Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
Výpočetní zdroje IT4Innovations a PRACE pro využití ve vědě a výzkumu Filip Staněk Seminář gridového počítání 2011, MetaCentrum, Brno, 7. 11. 2011 Introduction I Project objectives: to establish a centre
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
TOP500 Listen und industrielle/kommerzielle Anwendungen
 TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
PCS - Part 1: Introduction to Parallel Computing
 PCS - Part 1: Introduction to Parallel Computing Institute of Computer Engineering University of Lübeck, Germany Baltic Summer School, Tartu 2009 Part 1 - Overview Reasons for parallel computing Goals
PCS - Part 1: Introduction to Parallel Computing Institute of Computer Engineering University of Lübeck, Germany Baltic Summer School, Tartu 2009 Part 1 - Overview Reasons for parallel computing Goals
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
The TOP500 Project of the Universities Mannheim and Tennessee
 The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
Building Self-Healing Mass Storage Arrays. for Large Cluster Systems
 Building Self-Healing Mass Storage Arrays for Large Cluster Systems NSC08, Linköping, 14. October 2008 Toine Beckers tbeckers@datadirectnet.com Agenda Company Overview Balanced I/O Systems MTBF and Availability
Building Self-Healing Mass Storage Arrays for Large Cluster Systems NSC08, Linköping, 14. October 2008 Toine Beckers tbeckers@datadirectnet.com Agenda Company Overview Balanced I/O Systems MTBF and Availability
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice
 InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Overview of HPC and Energy Saving on KNL for Some Computations
 Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
Overview of HPC and Energy Saving on KNL for Some Computations Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 1/2/217 1 Outline Overview of High Performance
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
EE 4683/5683: COMPUTER ARCHITECTURE
 3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
HPC Resources & Training
 www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
www.bsc.es HPC Resources & Training in the BSC, the RES and PRACE Montse González Ferreiro RES technical and training coordinator + Facilities + Capacity How fit together the BSC, the RES and PRACE? TIER
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
The Center for Computational Research
 The Center for Computational Research Russ Miller Director, Center for Computational Research UB Distinguished Professor, Computer Science & Engineering Senior Research Scientist, Hauptman-Woodward Medical
The Center for Computational Research Russ Miller Director, Center for Computational Research UB Distinguished Professor, Computer Science & Engineering Senior Research Scientist, Hauptman-Woodward Medical
Prototypes Systems for PRACE. François Robin, GENCI, WP7 leader
 Prototypes Systems for PRACE François Robin, GENCI, WP7 leader Outline Motivation Summary of the selection process Description of the set of prototypes selected by the Management Board Conclusions 2 Outline
Prototypes Systems for PRACE François Robin, GENCI, WP7 leader Outline Motivation Summary of the selection process Description of the set of prototypes selected by the Management Board Conclusions 2 Outline
Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle
 Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron 140TFLOPS, 31.3TB
Supercomputers in ITC/U.Tokyo 2 big systems, 6 yr. cycle FY 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 Hitachi SR11K/J2 IBM Power 5+ 18.8TFLOPS, 16.4TB Hitachi HA8000 (T2K) AMD Opteron 140TFLOPS, 31.3TB
CCS HPC. Interconnection Network. PC MPP (Massively Parallel Processor) MPP IBM
 MPP IBM") CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
Search for Optimal Network Topologies for Supercomputers 寻找超级计算机优化的网络拓扑结构
 Search for Optimal Network Topologies for Supercomputers 寻找超级计算机优化的网络拓扑结构 GUO, Meng 郭猛 guomeng@sdas.org Shandong Computer Science Center (National Supercomputer Center in Jinan) 山东省计算中心 ( 国家超级计算济南中心 )
Search for Optimal Network Topologies for Supercomputers 寻找超级计算机优化的网络拓扑结构 GUO, Meng 郭猛 guomeng@sdas.org Shandong Computer Science Center (National Supercomputer Center in Jinan) 山东省计算中心 ( 国家超级计算济南中心 )
Trends in HPC Architectures and Parallel
 Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA CINECA, February 11-15, 2013 Agenda Computational
Trends in HPC Architectures and Parallel Programmming Giovanni Erbacci - g.erbacci@cineca.it Supercomputing, Applications & Innovation Department - CINECA CINECA, February 11-15, 2013 Agenda Computational
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Self Adapting Numerical Software. Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms
 Effort and Fault Tolerance in Linear Algebra Algorithms") Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 9/19/2005 1 Overview Quick look at
Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 9/19/2005 1 Overview Quick look at
Supercomputing im Jahr eine Analyse mit Hilfe der TOP500 Listen
 Supercomputing im Jahr 2000 - eine Analyse mit Hilfe der TOP500 Listen Hans Werner Meuer Universität Mannheim Feierliche Inbetriebnahme von CLIC TU Chemnitz 11. Oktober 2000 TOP500 CLIC TU Chemnitz View
Supercomputing im Jahr 2000 - eine Analyse mit Hilfe der TOP500 Listen Hans Werner Meuer Universität Mannheim Feierliche Inbetriebnahme von CLIC TU Chemnitz 11. Oktober 2000 TOP500 CLIC TU Chemnitz View
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Das TOP500-Projekt der Universitäten Mannheim und Tennessee zur Evaluierung des Supercomputer Marktes
 Das TOP500-Projekt der Universitäten Mannheim und Tennessee zur Evaluierung des Supercomputer Marktes Hans-Werner Meuer Universität Mannheim RUM - Kolloquium 11. Januar 1999, 11:00 Uhr Outline TOP500 Approach
Das TOP500-Projekt der Universitäten Mannheim und Tennessee zur Evaluierung des Supercomputer Marktes Hans-Werner Meuer Universität Mannheim RUM - Kolloquium 11. Januar 1999, 11:00 Uhr Outline TOP500 Approach
The Center for Computational Research & Grid Computing
 The Center for Computational Research & Grid Computing Russ Miller Center for Computational Research Computer Science & Engineering SUNY-Buffalo Hauptman-Woodward Medical Inst NSF, NIH, DOE NIMA, NYS,
The Center for Computational Research & Grid Computing Russ Miller Center for Computational Research Computer Science & Engineering SUNY-Buffalo Hauptman-Woodward Medical Inst NSF, NIH, DOE NIMA, NYS,
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Welcome to the. Jülich Supercomputing Centre. D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich
, Forschungszentrum Jülich") Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 18 13:00-13:30 Welcome
Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 18 13:00-13:30 Welcome
Multi-scale Thermal Management Challenges in Data Abundant Systems
 Multi-scale Thermal Management Challenges in Data Abundant Systems Yogendra Joshi G.W. Woodruff School of Mechanical Engineering Georgia Institute of Technology Atlanta, GA 30332 Collaborators: M. Bakir,
Multi-scale Thermal Management Challenges in Data Abundant Systems Yogendra Joshi G.W. Woodruff School of Mechanical Engineering Georgia Institute of Technology Atlanta, GA 30332 Collaborators: M. Bakir,
Architetture di calcolo e di gestione dati a alte prestazioni in HEP IFAE 2006, Pavia
 Architetture di calcolo e di gestione dati a alte prestazioni in HEP IFAE 2006, Pavia Marco Briscolini Deep Computing Sales Marco_briscolini@it.ibm.com IBM Pathways to Deep Computing Single Integrated
Architetture di calcolo e di gestione dati a alte prestazioni in HEP IFAE 2006, Pavia Marco Briscolini Deep Computing Sales Marco_briscolini@it.ibm.com IBM Pathways to Deep Computing Single Integrated
Supercomputers Prestige Objects or Crucial Tools for Science and Industry?
 Supercomputers Prestige Objects or Crucial Tools for Science and Industry? Hans W. Meuer a 1, Horst Gietl b 2 a University of Mannheim & Prometeus GmbH, 68131 Mannheim, Germany; b Prometeus GmbH, 81245
Supercomputers Prestige Objects or Crucial Tools for Science and Industry? Hans W. Meuer a 1, Horst Gietl b 2 a University of Mannheim & Prometeus GmbH, 68131 Mannheim, Germany; b Prometeus GmbH, 81245
Blue Gene: A Next Generation Supercomputer (BlueGene/P)
") Blue Gene: A Next Generation Supercomputer (BlueGene/P) Presented by Alan Gara (chief architect) representing the Blue Gene team. 2007 IBM Corporation Outline of Talk A brief sampling of applications on
Blue Gene: A Next Generation Supercomputer (BlueGene/P) Presented by Alan Gara (chief architect) representing the Blue Gene team. 2007 IBM Corporation Outline of Talk A brief sampling of applications on
for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) HPC Services Regionales Rechenzentrum Erlangen (b)
, Dr. G. Hager (a), J. Habich (a) HPC Services Regionales Rechenzentrum Erlangen (b)") Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University Erlangen-Nürnberg
Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University Erlangen-Nürnberg