Visual Computing TUM
|
|
|
- Helen Jennings
- 5 years ago
- Views:
Transcription
1

2 Visual Computing TUM


3 Visual Computing TUM

4 BundleFusion Real-time 3D Reconstruction Scalable scene representation Global alignment and re-localization TOG 17 [Dai et al.]: BundleFusion





5 Real-time 3D Reconstruction TOG 17 [Dai et al.]: BundleFusion

6 Understanding the 3D Scans chair? chair? chair? chair? chair? TOG 17 [Dai et al.]: BundleFusion
7 3D Object Classification 3D Convolutional Neural Network operating on Voxel Grid CVPR 16 [Qi et al.]: 3D CNNs




8 3D Object Classification Synthetic Data Real Data CVPR 16 [Qi et al.]: 3D CNNs
9 ScanNet: Annotated 3D Reconstructions CVPR 17 (spotlight) [Dai et al.]: ScanNet
 [Dai et al.")
10 ScanNet Data Annotation CVPR 17 (spotlight) [Dai et al.]: ScanNet
 [Dai et al.")
11 ScanNet CVPR 17 (spotlight) [Dai et al.]: ScanNet
12 ScanNet Statistics CVPR 17 (spotlight) [Dai et al.]: ScanNet

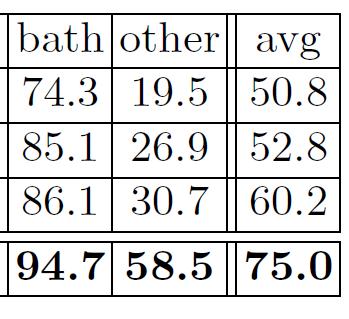
13 CVPR 17 (spotlight) [Dai et al.]: ScanNet ScanNet Tasks: 3D Object Classification Synthetic Prev. Real Ours Lots of real-world data matters!


14 ScanNet Tasks 3D Object Classification 3D Semantic Segmentation 3D Instance Segmentation



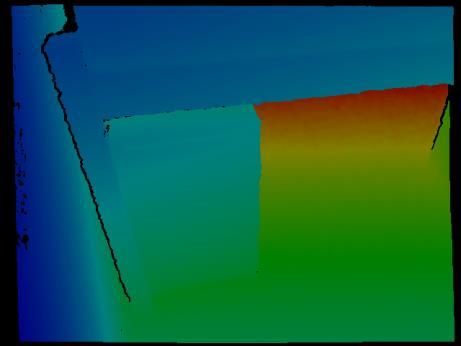


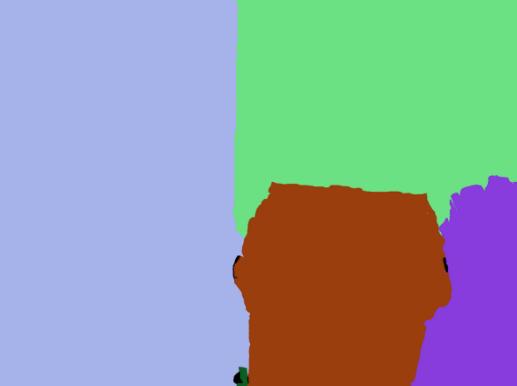



15 ScanNet 2D Projections Color Depth Labels 2.5 mio annotated images for 2D object classification, semantic, and instance segmentation CVPR 17 (spotlight) [Dai et al.]: ScanNet
16 ScanNet v1 Problems Annotations are incomplete Test set is public -> people cheat











17 ScanNet v2: 3D Scene Understanding Benchmark New annotations for all 1513 original scans (by experts)!
!")
18 ScanNet v2: 3D Scene Understanding Benchmark New annotations for all 1513 original scans (by experts)! 90% annotation coverage vs previous 63% annotation coverage
19 ScanNet v2: 3D Scene Understanding Benchmark New annotations for all 1513 original scans (by experts)! 90% annotation coverage vs previous 63% annotation coverage Annotated spurious geometry removed from meshes New room type classifications for all 1513 original scans (24 room types) New hidden test set for benchmarking (100 scans) Benchmark Tasks! Multi-view 2d 3D (+optional multi-view) Check it out


20 ScanNet v2: 3D Semantic Segmentation Task

21 ScanNet v2: 3D Instance Segmentation Task
22 ScanNet v2: Multi-view 2D Semantic Segmentation Task

23 ScanNet v2: Multi-view 2D Instance Segmentation Task

 2d and/or 3d input Apartment")
24 ScanNet v2: Room Type Classification Task Room type classification ( 13 major room types) 2d and/or 3d input Apartment
25 ScanNet v2: Benchmark Evaluation Evaluation in 2D evaluation over image pixels Evaluation in 3D evaluation over mesh vertices Hidden test sets and automated evaluation scripts!

26 ScanNet v2: Benchmark Evaluation Online since CVPR
27 ScanNet v2: Benchmark Evaluation
28 ScanNet v2: Benchmark Evaluation
29 ScanNet v2: Benchmark Evaluation
30 ScanNet v2: Benchmark Evaluation
31 3D Semantic Segmentation
32 3D Semantic Segmentation CVPR 17 (spotlight) [Dai et al.]: ScanNet
33 CVPR 17 (spotlight) [Dai et al.]: ScanNet ScanNet Tasks: 3D Semantic Segmentation Semantic 3D Segmentation
 [Dai et al.")
34 ScanNet Tasks: 3D Semantic Segmentation CVPR 17 (spotlight) [Dai et al.]: ScanNet

35 3DMV: Semantic 3D Segmentation ECCV 18 [Dai and Niessner 18]: 3DMV

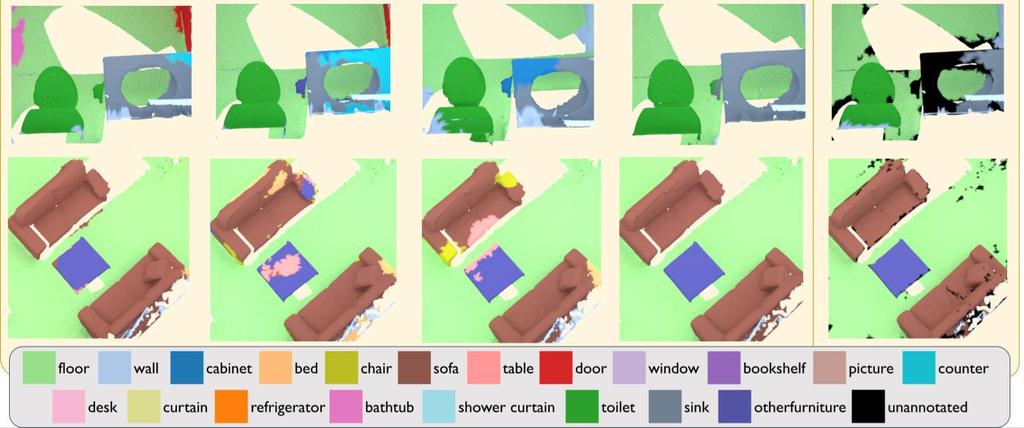


36 3DMV: Semantic 3D Segmentation Under submission [Dai and Niessner 18]: 3DMV
37 3DMV: Semantic 3D Segmentation ECCV 18 [Dai and Niessner 18]: 3DMV
38 3DMV: 2D -> 3D Projections ECCV 18 [Dai and Niessner 18]: 3DMV
39 3DMV: 2D Input -> 3D Convs ECCV 18 [Dai and Niessner 18]: 3DMV
40 3DMV: Geo only vs Voxel Colors ECCV 18 [Dai and Niessner 18]: 3DMV
41 3DMV: Geometry vs Color Features ECCV 18 [Dai and Niessner 18]: 3DMV
42 3DMV: Geometry vs Color Features ECCV 18 [Dai and Niessner 18]: 3DMV


43 3DMV: More Views Helps ECCV 18 [Dai and Niessner 18]: 3DMV

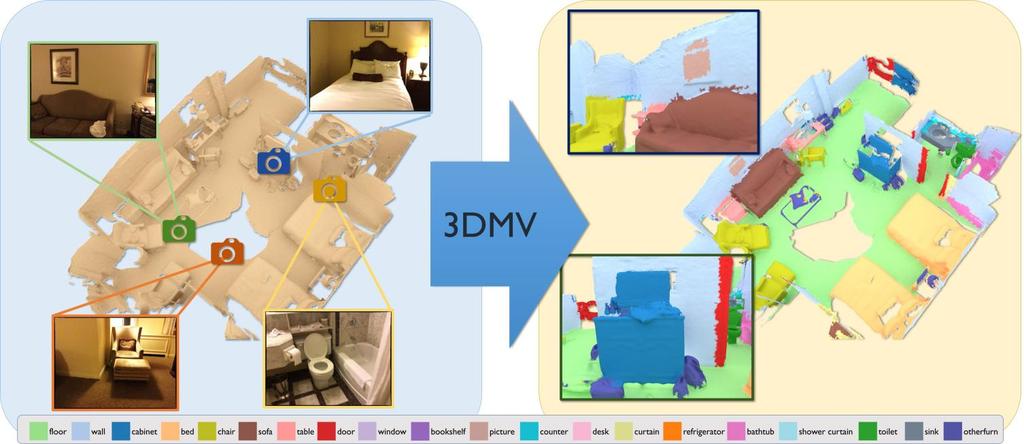
44 3DMV: Semantic 3D Segmentation ECCV 18 [Dai and Niessner 18]: 3DMV
45 3D Scene Understanding + Combination of Multi-view + 3D works extremely well + Great way to combine multiple frames (best perf. so far) - Instances are missing (ongoing work ) - Still interesting question: what is right 3D representation





46 Thank You ScanNet Team Angela Dai Angel Chang Thomas Funkhouser Maciej Halber Manolis Savva
47
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
3D Scene Understanding from RGB-D Images. Thomas Funkhouser
 3D Scene Understanding from RGB-D Images Thomas Funkhouser Recent Ph.D. Student Current Postdocs Current Ph.D. Students Disclaimer: I am talking about the work of these people Shuran Song Yinda Zhang Andy
3D Scene Understanding from RGB-D Images Thomas Funkhouser Recent Ph.D. Student Current Postdocs Current Ph.D. Students Disclaimer: I am talking about the work of these people Shuran Song Yinda Zhang Andy
arxiv: v1 [cs.cv] 28 Mar 2018
![arxiv: v1 [cs.cv] 28 Mar 2018](/thumbs/86/94008018.jpg "arxiv: v1 [cs.cv] 28 Mar 2018") arxiv:1803.10409v1 [cs.cv] 28 Mar 2018 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation Angela Dai 1 Matthias Nießner 2 1 Stanford University 2 Technical University of Munich Fig.
arxiv:1803.10409v1 [cs.cv] 28 Mar 2018 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation Angela Dai 1 Matthias Nießner 2 1 Stanford University 2 Technical University of Munich Fig.
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
arxiv: v2 [cs.cv] 28 Mar 2018
![arxiv: v2 [cs.cv] 28 Mar 2018](/thumbs/80/82275013.jpg "arxiv: v2 [cs.cv] 28 Mar 2018") ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans Angela Dai 1,3,5 Daniel Ritchie 2 Martin Bokeloh 3 Scott Reed 4 Jürgen Sturm 3 Matthias Nießner 5 1 Stanford University
ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans Angela Dai 1,3,5 Daniel Ritchie 2 Martin Bokeloh 3 Scott Reed 4 Jürgen Sturm 3 Matthias Nießner 5 1 Stanford University
CS6501: Deep Learning for Visual Recognition. Object Detection I: RCNN, Fast-RCNN, Faster-RCNN
 CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
Multi-view 3D Models from Single Images with a Convolutional Network
 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
arxiv: v1 [cs.cv] 18 Sep 2017
![arxiv: v1 [cs.cv] 18 Sep 2017](/thumbs/79/79188667.jpg "arxiv: v1 [cs.cv] 18 Sep 2017") Matterport3D: Learning from RGB-D Data in Indoor Environments Angel Chang 1 Angela Dai 2 Thomas Funkhouser 1 Maciej Halber 1 Matthias Nießner 3 Manolis Savva 1 Shuran Song 1 Andy Zeng 1 Yinda Zhang 1 1
Matterport3D: Learning from RGB-D Data in Indoor Environments Angel Chang 1 Angela Dai 2 Thomas Funkhouser 1 Maciej Halber 1 Matthias Nießner 3 Manolis Savva 1 Shuran Song 1 Andy Zeng 1 Yinda Zhang 1 1
ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
 ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans Angela Dai 1,3,5 Daniel Ritchie 2 Martin Bokeloh 3 Scott Reed 4 Jürgen Sturm 3 Matthias Nießner 5 1 Stanford University
ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans Angela Dai 1,3,5 Daniel Ritchie 2 Martin Bokeloh 3 Scott Reed 4 Jürgen Sturm 3 Matthias Nießner 5 1 Stanford University
Deep Learning for Robust Normal Estimation in Unstructured Point Clouds. Alexandre Boulch. Renaud Marlet
 Deep Learning for Robust Normal Estimation in Unstructured Point Clouds Alexandre Boulch Renaud Marlet Normal estimation in point clouds Normal: 3D normalized vector At each point: local orientation of
Deep Learning for Robust Normal Estimation in Unstructured Point Clouds Alexandre Boulch Renaud Marlet Normal estimation in point clouds Normal: 3D normalized vector At each point: local orientation of
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
PIXELS TO VOXELS: MODELING VISUAL REPRESENTATION IN THE HUMAN BRAIN
 PIXELS TO VOXELS: MODELING VISUAL REPRESENTATION IN THE HUMAN BRAIN By Pulkit Agrawal, Dustin Stansbury, Jitendra Malik, Jack L. Gallant University of California Berkeley Presented by Tim Patzelt AGENDA
PIXELS TO VOXELS: MODELING VISUAL REPRESENTATION IN THE HUMAN BRAIN By Pulkit Agrawal, Dustin Stansbury, Jitendra Malik, Jack L. Gallant University of California Berkeley Presented by Tim Patzelt AGENDA
Predicting ground-level scene Layout from Aerial imagery. Muhammad Hasan Maqbool
 Predicting ground-level scene Layout from Aerial imagery Muhammad Hasan Maqbool Objective Given the overhead image predict its ground level semantic segmentation Predicted ground level labeling Overhead/Aerial
Predicting ground-level scene Layout from Aerial imagery Muhammad Hasan Maqbool Objective Given the overhead image predict its ground level semantic segmentation Predicted ground level labeling Overhead/Aerial
Object Detection in 3D Scenes Using CNNs in Multi-view Images
 Object Detection in 3D Scenes Using CNNs in Multi-view Images Ruizhongtai (Charles) Qi Department of Electrical Engineering Stanford University rqi@stanford.edu Abstract Semantic understanding in 3D scenes
Object Detection in 3D Scenes Using CNNs in Multi-view Images Ruizhongtai (Charles) Qi Department of Electrical Engineering Stanford University rqi@stanford.edu Abstract Semantic understanding in 3D scenes
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
 ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes Angela Dai1 Angel X. Chang2 Manolis Savva2 Maciej Halber2 Thomas Funkhouser2 Matthias Nießner1,3 1 Stanford University 2 Princeton University
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes Angela Dai1 Angel X. Chang2 Manolis Savva2 Maciej Halber2 Thomas Funkhouser2 Matthias Nießner1,3 1 Stanford University 2 Princeton University
arxiv: v1 [cs.cv] 27 Nov 2018
![arxiv: v1 [cs.cv] 27 Nov 2018](/thumbs/91/105859139.jpg "arxiv: v1 [cs.cv] 27 Nov 2018") Scan2CAD: Learning CAD Model Alignment in RGB-D Scans Armen Avetisyan 1 Manuel Dahnert 1 Angela Dai 1 Manolis Savva 2 Angel X. Chang 2 Matthias Nießner 1 1 Technical University of Munich 2 Simon Fraser
Scan2CAD: Learning CAD Model Alignment in RGB-D Scans Armen Avetisyan 1 Manuel Dahnert 1 Angela Dai 1 Manolis Savva 2 Angel X. Chang 2 Matthias Nießner 1 1 Technical University of Munich 2 Simon Fraser
Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis
 Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis Angela Dai 1 Charles Ruizhongtai Qi 1 Matthias Nießner 1,2 1 Stanford University 2 Technical University of Munich Our method completes
Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis Angela Dai 1 Charles Ruizhongtai Qi 1 Matthias Nießner 1,2 1 Stanford University 2 Technical University of Munich Our method completes
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
AI Ukraine Point cloud labeling using machine learning
 AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation. Deepak Pathak, Philipp Krähenbühl and Trevor Darrell
 Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
arxiv: v1 [cs.cv] 10 Aug 2018
![arxiv: v1 [cs.cv] 10 Aug 2018](/thumbs/94/118960501.jpg "arxiv: v1 [cs.cv] 10 Aug 2018") Weakly supervised learning of indoor geometry by dual warping Pulak Purkait Ujwal Bonde Christopher Zach Toshiba Research Europe, Cambridge, U.K. {pulak.cv, ujwal.bonde, christopher.m.zach}@gmail.com arxiv:1808.03609v1
Weakly supervised learning of indoor geometry by dual warping Pulak Purkait Ujwal Bonde Christopher Zach Toshiba Research Europe, Cambridge, U.K. {pulak.cv, ujwal.bonde, christopher.m.zach}@gmail.com arxiv:1808.03609v1
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Using Faster-RCNN to Improve Shape Detection in LIDAR
 Using Faster-RCNN to Improve Shape Detection in LIDAR TJ Melanson Stanford University Stanford, CA 94305 melanson@stanford.edu Abstract In this paper, I propose a method for extracting objects from unordered
Using Faster-RCNN to Improve Shape Detection in LIDAR TJ Melanson Stanford University Stanford, CA 94305 melanson@stanford.edu Abstract In this paper, I propose a method for extracting objects from unordered
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Collision Experimental Data
 Hybrid Rendering System for Particle Collision Experimental Data Visualization Ciril Bohak ciril.bohak@fri.uni-lj.si lgm.fri.uni-lj.si Naples March 2018 Content Background; Problem Domains; Possible solutions;
Hybrid Rendering System for Particle Collision Experimental Data Visualization Ciril Bohak ciril.bohak@fri.uni-lj.si lgm.fri.uni-lj.si Naples March 2018 Content Background; Problem Domains; Possible solutions;
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
The Hilbert Problems of Computer Vision. Jitendra Malik UC Berkeley & Google, Inc.
 The Hilbert Problems of Computer Vision Jitendra Malik UC Berkeley & Google, Inc. This talk The computational power of the human brain Research is the art of the soluble Hilbert problems, circa 2004 Hilbert
The Hilbert Problems of Computer Vision Jitendra Malik UC Berkeley & Google, Inc. This talk The computational power of the human brain Research is the art of the soluble Hilbert problems, circa 2004 Hilbert
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Scene Text Recognition for Augmented Reality. Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science
 Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR
 3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
ABC-CNN: Attention Based CNN for Visual Question Answering
 ABC-CNN: Attention Based CNN for Visual Question Answering CIS 601 PRESENTED BY: MAYUR RUMALWALA GUIDED BY: DR. SUNNIE CHUNG AGENDA Ø Introduction Ø Understanding CNN Ø Framework of ABC-CNN Ø Datasets
ABC-CNN: Attention Based CNN for Visual Question Answering CIS 601 PRESENTED BY: MAYUR RUMALWALA GUIDED BY: DR. SUNNIE CHUNG AGENDA Ø Introduction Ø Understanding CNN Ø Framework of ABC-CNN Ø Datasets
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Cross-domain Deep Encoding for 3D Voxels and 2D Images
 Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Overview of 3D Object Representations
 Overview of 3D Object Representations Thomas Funkhouser Princeton University C0S 426, Fall 2000 Course Syllabus I. Image processing II. Rendering III. Modeling IV. Animation Image Processing (Rusty Coleman,
Overview of 3D Object Representations Thomas Funkhouser Princeton University C0S 426, Fall 2000 Course Syllabus I. Image processing II. Rendering III. Modeling IV. Animation Image Processing (Rusty Coleman,
Scanning and Printing Objects in 3D Jürgen Sturm
 Scanning and Printing Objects in 3D Jürgen Sturm Metaio (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects Quadrocopters
Scanning and Printing Objects in 3D Jürgen Sturm Metaio (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects Quadrocopters
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
From 3D descriptors to monocular 6D pose: what have we learned?
 ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
Feature Visualization
 CreativeAI: Deep Learning for Graphics Feature Visualization Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TU Munich UCL Timetable Theory and Basics State of the Art
CreativeAI: Deep Learning for Graphics Feature Visualization Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TU Munich UCL Timetable Theory and Basics State of the Art
arxiv: v1 [cs.cv] 13 Feb 2018
![arxiv: v1 [cs.cv] 13 Feb 2018](/thumbs/85/92549074.jpg "arxiv: v1 [cs.cv] 13 Feb 2018") Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recognizing people. Deva Ramanan
 Recognizing people Deva Ramanan The goal Why focus on people? How many person-pixels are in a video? 35% 34% Movies TV 40% YouTube Let s start our discussion with a loaded question: why is visual recognition
Recognizing people Deva Ramanan The goal Why focus on people? How many person-pixels are in a video? 35% 34% Movies TV 40% YouTube Let s start our discussion with a loaded question: why is visual recognition
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Learning Probabilistic Models from Collections of 3D Meshes
 Learning Probabilistic Models from Collections of 3D Meshes Sid Chaudhuri, Steve Diverdi, Matthew Fisher, Pat Hanrahan, Vladimir Kim, Wilmot Li, Niloy Mitra, Daniel Ritchie, Manolis Savva, and Thomas Funkhouser
Learning Probabilistic Models from Collections of 3D Meshes Sid Chaudhuri, Steve Diverdi, Matthew Fisher, Pat Hanrahan, Vladimir Kim, Wilmot Li, Niloy Mitra, Daniel Ritchie, Manolis Savva, and Thomas Funkhouser
Recurrent Transformer Networks for Semantic Correspondence
 Neural Information Processing Systems (NeurIPS) 2018 Recurrent Transformer Networks for Semantic Correspondence Seungryong Kim 1, Stepthen Lin 2, Sangryul Jeon 1, Dongbo Min 3, Kwanghoon Sohn 1 Dec. 05,
Neural Information Processing Systems (NeurIPS) 2018 Recurrent Transformer Networks for Semantic Correspondence Seungryong Kim 1, Stepthen Lin 2, Sangryul Jeon 1, Dongbo Min 3, Kwanghoon Sohn 1 Dec. 05,
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Multi-view Stereo. Ivo Boyadzhiev CS7670: September 13, 2011
 Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Thanks to Chris Bregler. COS 429: Computer Vision
 Thanks to Chris Bregler COS 429: Computer Vision COS 429: Computer Vision Instructor: Thomas Funkhouser funk@cs.princeton.edu Preceptors: Ohad Fried, Xinyi Fan {ohad,xinyi}@cs.princeton.edu Web page: http://www.cs.princeton.edu/courses/archive/fall13/cos429/
Thanks to Chris Bregler COS 429: Computer Vision COS 429: Computer Vision Instructor: Thomas Funkhouser funk@cs.princeton.edu Preceptors: Ohad Fried, Xinyi Fan {ohad,xinyi}@cs.princeton.edu Web page: http://www.cs.princeton.edu/courses/archive/fall13/cos429/
Collaborative Mapping with Streetlevel Images in the Wild. Yubin Kuang Co-founder and Computer Vision Lead
 Collaborative Mapping with Streetlevel Images in the Wild Yubin Kuang Co-founder and Computer Vision Lead Mapillary Mapillary is a street-level imagery platform, powered by collaboration and computer vision.
Collaborative Mapping with Streetlevel Images in the Wild Yubin Kuang Co-founder and Computer Vision Lead Mapillary Mapillary is a street-level imagery platform, powered by collaboration and computer vision.
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018
 Qixing Huang August 29 th 2018") CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
Learning Semantic Video Captioning using Data Generated with Grand Theft Auto
 A dark car is turning left on an exit Learning Semantic Video Captioning using Data Generated with Grand Theft Auto Alex Polis Polichroniadis Data Scientist, MSc Kolia Sadeghi Applied Mathematician, PhD
A dark car is turning left on an exit Learning Semantic Video Captioning using Data Generated with Grand Theft Auto Alex Polis Polichroniadis Data Scientist, MSc Kolia Sadeghi Applied Mathematician, PhD
arxiv: v1 [cs.cv] 31 Mar 2018
![arxiv: v1 [cs.cv] 31 Mar 2018](/thumbs/90/101585694.jpg "arxiv: v1 [cs.cv] 31 Mar 2018") arxiv:1804.00090v1 [cs.cv] 31 Mar 2018 FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans Chen Liu Jiaye Wu Washington University in St. Louis {chenliu,jiaye.wu}@wustl.edu Yasutaka
arxiv:1804.00090v1 [cs.cv] 31 Mar 2018 FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans Chen Liu Jiaye Wu Washington University in St. Louis {chenliu,jiaye.wu}@wustl.edu Yasutaka
Finding Surface Correspondences With Shape Analysis
 Finding Surface Correspondences With Shape Analysis Sid Chaudhuri, Steve Diverdi, Maciej Halber, Vladimir Kim, Yaron Lipman, Tianqiang Liu, Wilmot Li, Niloy Mitra, Elena Sizikova, Thomas Funkhouser Motivation
Finding Surface Correspondences With Shape Analysis Sid Chaudhuri, Steve Diverdi, Maciej Halber, Vladimir Kim, Yaron Lipman, Tianqiang Liu, Wilmot Li, Niloy Mitra, Elena Sizikova, Thomas Funkhouser Motivation
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material
 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
arxiv: v3 [cs.cv] 31 Oct 2017
![arxiv: v3 [cs.cv] 31 Oct 2017](/thumbs/74/69926053.jpg "arxiv: v3 [cs.cv] 31 Oct 2017") OctNetFusion: Learning Depth Fusion from Data Gernot Riegler 1 Ali Osman Ulusoy 2 Horst Bischof 1 Andreas Geiger 2,3 1 Institute for Computer Graphics and Vision, Graz University of Technology 2 Autonomous
OctNetFusion: Learning Depth Fusion from Data Gernot Riegler 1 Ali Osman Ulusoy 2 Horst Bischof 1 Andreas Geiger 2,3 1 Institute for Computer Graphics and Vision, Graz University of Technology 2 Autonomous
SHREC 18: RGB-D Object-to-CAD Retrieval
 Eurographics Workshop on 3D Object Retrieval (2018), pp. 1 8 A. Telea and T. Theoharis (Editors) SHREC 18: RGB-D Object-to-CAD Retrieval Quang-Hieu Pham 1 Minh-Khoi Tran 1 Wenhui Li 5 Shu Xiang 5 Heyu
Eurographics Workshop on 3D Object Retrieval (2018), pp. 1 8 A. Telea and T. Theoharis (Editors) SHREC 18: RGB-D Object-to-CAD Retrieval Quang-Hieu Pham 1 Minh-Khoi Tran 1 Wenhui Li 5 Shu Xiang 5 Heyu
FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans
 FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans Chen Liu 1, Jiaye Wu 1, and Yasutaka Furukawa 2 1 Washington University in St. Louis, St. Louis, USA {chenliu,jiaye.wu}@wustl.edu
FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans Chen Liu 1, Jiaye Wu 1, and Yasutaka Furukawa 2 1 Washington University in St. Louis, St. Louis, USA {chenliu,jiaye.wu}@wustl.edu
arxiv: v1 [cs.cv] 23 Nov 2017
![arxiv: v1 [cs.cv] 23 Nov 2017](/thumbs/82/86007822.jpg "arxiv: v1 [cs.cv] 23 Nov 2017") SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation arxiv:1711.08588v1 [cs.cv] 23 Nov 2017 Weiyue Wang 1 Ronald Yu 2 Qiangui Huang 1 Ulrich Neumann 1 1 University of Southern
SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation arxiv:1711.08588v1 [cs.cv] 23 Nov 2017 Weiyue Wang 1 Ronald Yu 2 Qiangui Huang 1 Ulrich Neumann 1 1 University of Southern
Is Bigger CNN Better? Samer Hijazi on behalf of IPG CTO Group Embedded Neural Networks Summit (enns2016) San Jose Feb. 9th
 San Jose Feb. 9th") Is Bigger CNN Better? Samer Hijazi on behalf of IPG CTO Group Embedded Neural Networks Summit (enns2016) San Jose Feb. 9th Today s Story Why does CNN matter to the embedded world? How to enable CNN in
Is Bigger CNN Better? Samer Hijazi on behalf of IPG CTO Group Embedded Neural Networks Summit (enns2016) San Jose Feb. 9th Today s Story Why does CNN matter to the embedded world? How to enable CNN in
Linking WordNet to 3D Shapes
 Linking WordNet to 3D Shapes Angel X Chang, Rishi Mago, Pranav Krishna, Manolis Savva, and Christiane Fellbaum Department of Computer Science, Princeton University Princeton, New Jersey, USA angelx@cs.stanford.edu,
Linking WordNet to 3D Shapes Angel X Chang, Rishi Mago, Pranav Krishna, Manolis Savva, and Christiane Fellbaum Department of Computer Science, Princeton University Princeton, New Jersey, USA angelx@cs.stanford.edu,
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Large-Scale Point Cloud Classification Benchmark
 Large-Scale Point Cloud Classification Benchmark www.semantic3d.net IGP & CVG, ETH Zürich www.semantic3d.net, info@semantic3d.net 7/6/2016 1 Timo Hackel Nikolay Savinov Ľubor Ladický Jan Dirk Wegner Konrad
Large-Scale Point Cloud Classification Benchmark www.semantic3d.net IGP & CVG, ETH Zürich www.semantic3d.net, info@semantic3d.net 7/6/2016 1 Timo Hackel Nikolay Savinov Ľubor Ladický Jan Dirk Wegner Konrad
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
Deep 3D Machine Learning for Reconstruction and Repair of 3D Surfaces
 Deep 3D Machine Learning for Reconstruction and Repair of 3D Surfaces TalkID 23152 This session will give the audience a quick overview of recent developments in the field of 3D surface analysis with deep
Deep 3D Machine Learning for Reconstruction and Repair of 3D Surfaces TalkID 23152 This session will give the audience a quick overview of recent developments in the field of 3D surface analysis with deep
COMPARATIVE DEEP LEARNING FOR CONTENT- BASED MEDICAL IMAGE RETRIEVAL
 1 COMPARATIVE DEEP LEARNING FOR CONTENT- BASED MEDICAL IMAGE RETRIEVAL ADITYA SRIRAM DECEMBER 1 st, 2016 Aditya Sriram CS846 Software Engineering for Big Data December 1, 2016 TOPICS 2 Paper Synopsis Content-Based
1 COMPARATIVE DEEP LEARNING FOR CONTENT- BASED MEDICAL IMAGE RETRIEVAL ADITYA SRIRAM DECEMBER 1 st, 2016 Aditya Sriram CS846 Software Engineering for Big Data December 1, 2016 TOPICS 2 Paper Synopsis Content-Based
Video Object Segmentation using Deep Learning
 Video Object Segmentation using Deep Learning Update Presentation, Week 3 Zack While Advised by: Rui Hou, Dr. Chen Chen, and Dr. Mubarak Shah June 2, 2017 Youngstown State University 1 Table of Contents
Video Object Segmentation using Deep Learning Update Presentation, Week 3 Zack While Advised by: Rui Hou, Dr. Chen Chen, and Dr. Mubarak Shah June 2, 2017 Youngstown State University 1 Table of Contents
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION
 LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Object Classification in Domestic Environments
 Object Classification in Domestic Environments Markus Vincze Aitor Aldoma, Markus Bader, Peter Einramhof, David Fischinger, Andreas Huber, Lara Lammer, Thomas Mörwald, Sven Olufs, Ekaterina Potapova, Johann
Object Classification in Domestic Environments Markus Vincze Aitor Aldoma, Markus Bader, Peter Einramhof, David Fischinger, Andreas Huber, Lara Lammer, Thomas Mörwald, Sven Olufs, Ekaterina Potapova, Johann
Action recognition in robot-assisted minimally invasive surgery
 Action recognition in robot-assisted minimally invasive surgery Candidate: Laura Erica Pescatori Co-Tutor: Hirenkumar Chandrakant Nakawala Tutor: Elena De Momi 1 Project Objective da Vinci Robot: Console
Action recognition in robot-assisted minimally invasive surgery Candidate: Laura Erica Pescatori Co-Tutor: Hirenkumar Chandrakant Nakawala Tutor: Elena De Momi 1 Project Objective da Vinci Robot: Console
Multi-view stereo. Many slides adapted from S. Seitz
 Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Lecture 2 Notes. Outline. Neural Networks. The Big Idea. Architecture. Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Todo before next class
 Todo before next class Each project group should submit a short project report (4 pages presentation slides) including 1. Problem definition 2. Related work 3. Preliminary results 4. Future plan Submission:
Todo before next class Each project group should submit a short project report (4 pages presentation slides) including 1. Problem definition 2. Related work 3. Preliminary results 4. Future plan Submission:
Deconvolution Networks
 Deconvolution Networks Johan Brynolfsson Mathematical Statistics Centre for Mathematical Sciences Lund University December 6th 2016 1 / 27 Deconvolution Neural Networks 2 / 27 Image Deconvolution True
Deconvolution Networks Johan Brynolfsson Mathematical Statistics Centre for Mathematical Sciences Lund University December 6th 2016 1 / 27 Deconvolution Neural Networks 2 / 27 Image Deconvolution True
3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions
 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions Andy Zeng 1 Shuran Song 1 Matthias Nießner 2 Matthew Fisher 2,4 Jianxiong Xiao 3 Thomas Funkhouser 1 1 Princeton University 2 Stanford
3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions Andy Zeng 1 Shuran Song 1 Matthias Nießner 2 Matthew Fisher 2,4 Jianxiong Xiao 3 Thomas Funkhouser 1 1 Princeton University 2 Stanford
arxiv: v1 [cs.cv] 25 Oct 2017
![arxiv: v1 [cs.cv] 25 Oct 2017](/thumbs/89/99640500.jpg "arxiv: v1 [cs.cv] 25 Oct 2017") ZOU, LI, HOIEM: COMPLETE 3D SCENE PARSING FROM SINGLE RGBD IMAGE 1 arxiv:1710.09490v1 [cs.cv] 25 Oct 2017 Complete 3D Scene Parsing from Single RGBD Image Chuhang Zou http://web.engr.illinois.edu/~czou4/
ZOU, LI, HOIEM: COMPLETE 3D SCENE PARSING FROM SINGLE RGBD IMAGE 1 arxiv:1710.09490v1 [cs.cv] 25 Oct 2017 Complete 3D Scene Parsing from Single RGBD Image Chuhang Zou http://web.engr.illinois.edu/~czou4/
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction
 GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction Li Jiang 1, Shaoshuai Shi 1, Xiaojuan Qi 1, and Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Tencent YouTu Lab {lijiang,
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction Li Jiang 1, Shaoshuai Shi 1, Xiaojuan Qi 1, and Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Tencent YouTu Lab {lijiang,
VISION FOR AUTOMOTIVE DRIVING
 VISION FOR AUTOMOTIVE DRIVING French Japanese Workshop on Deep Learning & AI, Paris, October 25th, 2017 Quoc Cuong PHAM, PhD Vision and Content Engineering Lab AI & MACHINE LEARNING FOR ADAS AND SELF-DRIVING
VISION FOR AUTOMOTIVE DRIVING French Japanese Workshop on Deep Learning & AI, Paris, October 25th, 2017 Quoc Cuong PHAM, PhD Vision and Content Engineering Lab AI & MACHINE LEARNING FOR ADAS AND SELF-DRIVING
arxiv: v1 [cs.cv] 2 Nov 2018
![arxiv: v1 [cs.cv] 2 Nov 2018](/thumbs/89/100782143.jpg "arxiv: v1 [cs.cv] 2 Nov 2018") 3D Pick & Mix: Object Part Blending in Joint Shape and Image Manifolds Adrian Penate-Sanchez 1,2[0000 0003 2876 3301] Lourdes Agapito 1[0000 0002 6947 1092] arxiv:1811.01068v1 [cs.cv] 2 Nov 2018 1 University
3D Pick & Mix: Object Part Blending in Joint Shape and Image Manifolds Adrian Penate-Sanchez 1,2[0000 0003 2876 3301] Lourdes Agapito 1[0000 0002 6947 1092] arxiv:1811.01068v1 [cs.cv] 2 Nov 2018 1 University
Depth-aware CNN for RGB-D Segmentation
 Depth-aware CNN for RGB-D Segmentation Weiyue Wang [0000 0002 8114 8271] and Ulrich Neumann University of Southern California, Los Angeles, California {weiyuewa,uneumann}@usc.edu Abstract. Convolutional
Depth-aware CNN for RGB-D Segmentation Weiyue Wang [0000 0002 8114 8271] and Ulrich Neumann University of Southern California, Los Angeles, California {weiyuewa,uneumann}@usc.edu Abstract. Convolutional