Arquitectura de Computadores
|
|
|
- Kristopher Harrell
- 6 years ago
- Views:
Transcription
1 Arquitectura de Computadores Capítulo 2. Procesadores segmetados Based o the origial material of the book: D.A. Patterso y J.L. Heessy Computer Orgaizatio ad Desig: The Hardware/Software Iterface 4 th editio. Escuela Politécica Superior Uiversidad Autóoma de Madrid Profesores: G130 y G131: Ivá Gozález Martíez G136: Fracisco Javier Gómez Arribas
2 Ageda The Processor: A Basic MIPS Implemetatio Buildig a Datapath Desigig the Cotrol Uit (sigle cycle) A Overview of Pipeliig Pipelie performace MIPS five stages pipelie Hazards: Structure, Data ad Cotrol MIPS Pipelied Datapath ad Cotrol Data Hazards: Forwardig vs Stallig Cotrol Hazards: Brach predictio 2
3 Itroductio CPU performace factors Istructio cout Determied by ISA ad compiler CPI ad Cycle time Determied by CPU hardware We will examie two MIPS implemetatios A simplified versio A more realistic pipelied versio Simple subset, shows most aspects Memory referece: lw, sw Arithmetic/logical: add, sub, ad, or, slt Cotrol trasfer: beq, j 4.1 Itroductio The Processor 3
4 Itroductio (2) We will study simple RISC processor called MIPS (Microprocessor without Iterlocked Pipelie Stages) 32 bits processor (data, memory) 32 geeral purpose registers Separated data ad code memory (Harvard architecture) The Processor 4


5 CPU Overview Istructio Executio PC istructio memory, fetch istructio Register umbers register file, read registers Depedig o istructio class Use ALU to calculate Arithmetic result Memory address for load/store Brach target address Access data memory for load/store PC target address or PC + 4 The Processor 5
6 Datapath & cotrol desig Datapath: Elemets that process data ad addresses i the CPU Registers, ALUs, mux s, memories, We will build a MIPS datapath icremetally 4.3 Buildig a Datapath Cotrol Uit: Iformatio comes from the 32 bits of the istructio ad the cotrol lies select: Registers to be read (always read two). The operatio to be performed by ALU If data memory is to be read or writte What is writte ad where i the register file What goes i PC Combiatioal Sigle Cycle implemetatio The Processor 6


7 Full Datapath The Processor 7
8 The Mai Cotrol Uit Cotrol sigals derived from istructio R-type Load/ Store Brach 0 rs rt rd shamt fuct 31:26 25:21 20:16 15:11 10:6 5:0 35 or 43 rs rt address 31:26 25:21 20:16 15:0 4 rs rt address 31:26 25:21 20:16 15:0 opcode always read read, except for load write for R-type ad load sig-exted ad add The Processor 8
9 ALU Cotrol ALU used for Load/Store: F = add Brach: F = subtract R-type: F depeds o fuct field ALU cotrol Fuctio 0000 AND 4.4 A Simple Implemetatio Scheme 0001 OR 0010 add 0110 subtract 0111 set-o-less-tha 1100 NOR The Processor 9
10 ALU Cotrol Assume 2-bit ALUOp derived from opcode Combiatioal logic derives ALU cotrol opcode ALUOp Operatio fuct ALU fuctio ALU cotrol lw 00 load word XXXXXX add 0010 sw 00 store word XXXXXX add 0010 beq 01 brach equal XXXXXX subtract 0110 R-type 10 add add 0010 subtract subtract 0110 AND AND 0000 OR OR 0001 set-o-less-tha set-o-less-tha 0111 The Processor 10


11 Datapath With Cotrol The Processor 11

12 R-Type Istructio The Processor 12
13 Load Istructio The Processor 13

14 Brach-o-Equal Istructio The Processor 14
15 Implemetig Jumps Jump 2 address Jump uses word address Update PC with cocateatio of Top 4 bits of old PC 26-bit jump address 00 31:26 25:0 Need a extra cotrol sigal decoded from opcode The Processor 15


16 Datapath With Jumps Added The Processor 16
17 Performace Issues Logest delay determies clock period Critical path: load istructio Istructio memory register file ALU data memory register file Not feasible to vary period for differet istructios Violates desig priciple Makig the commo case fast We will improve performace by pipeliig The Processor 17
18 Ageda A Basic MIPS Implemetatio Buildig a Datapath Desigig the Cotrol Uit (sigle cycle) A Overview of Pipeliig Pipelie performace MIPS five stages pipelie Hazards: Structure, Data ad Cotrol MIPS Pipelied Datapath ad Cotrol Data Hazards: Forwardig vs Stallig Cotrol Hazards: Brach predictio 18


19 Pipeliig Aalogy Pipelied laudry: overlappig executio Parallelism improves performace Four loads: Speedup = 8/3.5 = 2.3 No-stop: 4.5 A Overview of Pipeliig Speedup = 2/ = umber of stages The Processor 19
20 MIPS Pipelie Five stages, oe step per stage 1. IF: Istructio fetch from memory 2. ID: Istructio decode & register read 3. EX: Execute operatio or calculate address 4. MEM: Access memory operad 5. WB: Write result back to register The Processor 20
21 Pipelie Performace Assume time for stages is 100ps for register read or write 200ps for other stages Compare pipelied datapath with sigle-cycle datapath Istr Istr fetch Register read ALU op Memory access Register write Total time lw 200ps 100 ps 200ps 200ps 100 ps 800ps sw 200ps 100 ps 200ps 200ps 700ps R-format 200ps 100 ps 200ps 100 ps 600ps beq 200ps 100 ps 200ps 500ps The Processor 21
 Pipelied (T c = 200ps) The")
22 Pipelie Performace Sigle-cycle (T c = 800ps) Pipelied (T c = 200ps) The Processor 22
23 Pipelie Speedup If all stages are balaced i.e., all take the same time Time betwee istructios pipelied = Time betwee istructios opipelied Number of stages If ot balaced, speedup is less Speedup due to icreased throughput Latecy (time for each istructio) does ot decrease The Processor 23
24 Pipeliig ad ISA Desig MIPS ISA desiged for pipeliig All istructios are 32-bits Easier to fetch ad decode i oe cycle c.f. x86: 1- to 17-byte istructios Few ad regular istructio formats Ca decode ad read registers i oe step Load/store addressig Ca calculate address i 3 rd stage, access memory i 4 th stage Aligmet of memory operads Memory access takes oly oe cycle The Processor 24
25 Hazards Situatios that prevet startig the ext istructio i the ext cycle Structure hazards A required resource is busy Data hazard Need to wait for previous istructio to complete its data read/write Cotrol hazard Decidig o cotrol actio depeds o previous istructio The Processor 25
26 Structure Hazards Coflict for use of a resource I MIPS pipelie with a sigle memory Load/store requires data access Istructio fetch would have to stall for that cycle Would cause a pipelie bubble Hece, pipelied datapaths require separate istructio/data memories Or separate istructio/data caches The Processor 26


27 Data Hazards A istructio depeds o completio of data access by a previous istructio add $s0, $t0, $t1 sub $t2, $s0, $t3 The Processor 27


28 Forwardig (aka Bypassig) Use result whe it is computed Do t wait for it to be stored i a register Requires extra coectios i the datapath The Processor 28


29 Load-Use Data Hazard Ca t always avoid stalls by forwardig If value ot computed whe eeded Ca t forward backward i time! The Processor 29
30 Code Schedulig to Avoid Stalls Reorder code to avoid use of load result i the ext istructio C code for A = B + E; C = B + F; stall stall lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 13 cycles lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t2 sw $t3, 12($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 11 cycles The Processor 30
31 Cotrol Hazards Brach determies flow of cotrol Fetchig ext istructio depeds o brach outcome Pipelie ca t always fetch correct istructio Still workig o ID stage of brach I MIPS pipelie Need to compare registers ad compute target early i the pipelie Add hardware to do it i ID stage The Processor 31


32 Stall o Brach Wait util brach outcome determied before fetchig ext istructio The Processor 32
33 Brach Predictio Loger pipelies ca t readily determie brach outcome early Stall pealty becomes uacceptable Predict outcome of brach Oly stall if predictio is wrog I MIPS pipelie Ca predict braches ot take Fetch istructio after brach, with o delay The Processor 33

34 MIPS with Predict Not Take Predictio correct Predictio icorrect The Processor 34
35 More-Realistic Brach Predictio Static brach predictio Based o typical brach behavior Example: loop ad if-statemet braches Predict backward braches take Predict forward braches ot take Dyamic brach predictio Hardware measures actual brach behavior e.g., record recet history of each brach Assume future behavior will cotiue the tred Whe wrog, stall while re-fetchig, ad update history The Processor 35
36 Pipelie Summary The BIG Picture Pipeliig improves performace by icreasig istructio throughput Executes multiple istructios i parallel Each istructio has the same latecy Subject to hazards Structure, data, cotrol Istructio set desig affects complexity of pipelie implemetatio The Processor 36
37 Ageda A Basic MIPS Implemetatio Buildig a Datapath Desigig the Cotrol Uit (sigle cycle) A Overview of Pipeliig Pipelie performace MIPS five stages pipelie Hazards: Structure, Data ad Cotrol MIPS Pipelied Datapath ad Cotrol Data Hazards: Forwardig vs Stallig Cotrol Hazards: Brach predictio


38 MIPS Pipelied Datapath 4.6 Pipelied Datapath ad Cotrol MEM Right-to-left flow leads to hazards WB The Processor 38

39 Pipelie registers Need registers betwee stages To hold iformatio produced i previous cycle The Processor 39
40 Pipelie Operatio Cycle-by-cycle flow of istructios through the pipelied datapath Sigle-clock-cycle pipelie diagram Shows pipelie usage i a sigle cycle Highlight resources used c.f. multi-clock-cycle diagram Graph of operatio over time We ll look at sigle-clock-cycle diagrams for load & store The Processor 40

41 IF for Load, Store, The Processor 41

42 ID for Load, Store, The Processor 42

43 EX for Load The Processor 43
44 MEM for Load The Processor 44

45 WB for Load Wrog register umber The Processor 45

46 Corrected Datapath for Load The Processor 46
47 EX for Store The Processor 47

48 MEM for Store The Processor 48

49 WB for Store The Processor 49
50 Multi-Cycle Pipelie Diagram Form showig resource usage The Processor 50

51 Multi-Cycle Pipelie Diagram Traditioal form The Processor 51

52 Sigle-Cycle Pipelie Diagram State of pipelie i a give cycle The Processor 52

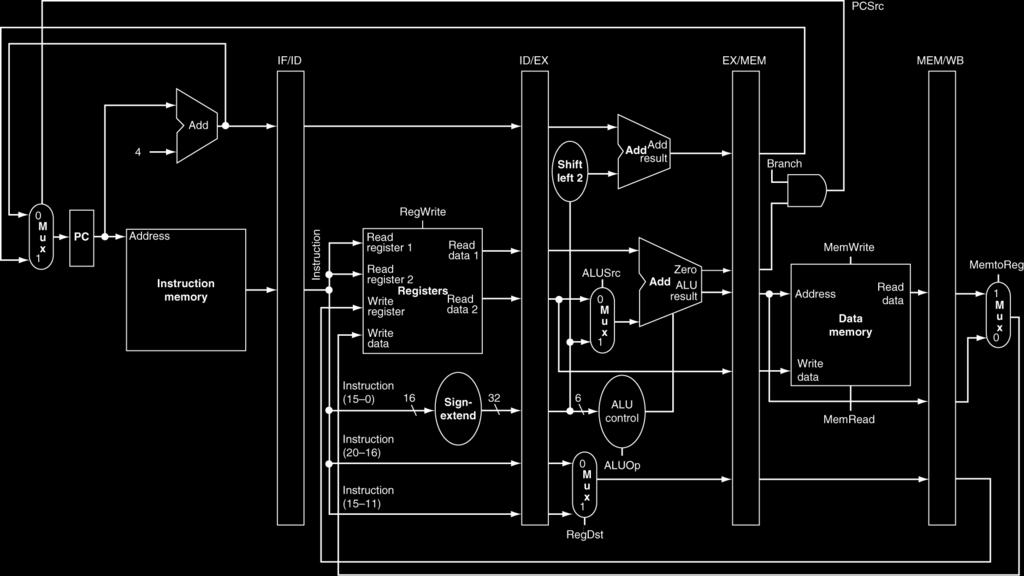
53 Pipelied Cotrol (Simplified) The Processor 53


54 Pipelied Cotrol Cotrol sigals derived from istructio As i sigle-cycle implemetatio The Processor 54


55 Pipelied Cotrol The Processor 55
56 Data Hazards i ALU Istructios Cosider this sequece: sub $2, $1,$3 ad $12,$2,$5 or $13,$6,$2 add $14,$2,$2 sw $15,100($2) We ca resolve hazards with forwardig How do we detect whe to forward? 4.7 Data Hazards: Forwardig vs. Stallig The Processor 56


57 Depedecies & Forwardig The Processor 57
58 Detectig the Need to Forward Pass register umbers alog pipelie e.g., ID/EX.RegisterRs = register umber for Rs sittig i ID/EX pipelie register ALU operad register umbers i EX stage are give by ID/EX.RegisterRs, ID/EX.RegisterRt Data hazards whe 1a. EX/MEM.RegisterRd = ID/EX.RegisterRs 1b. EX/MEM.RegisterRd = ID/EX.RegisterRt 2a. MEM/WB.RegisterRd = ID/EX.RegisterRs 2b. MEM/WB.RegisterRd = ID/EX.RegisterRt Fwd from EX/MEM pipelie reg Fwd from MEM/WB pipelie reg The Processor 58
59 Detectig the Need to Forward But oly if forwardig istructio will write to a register! EX/MEM.RegWrite, MEM/WB.RegWrite Ad oly if Rd for that istructio is ot $zero EX/MEM.RegisterRd 0, MEM/WB.RegisterRd 0 The Processor 59
) ForwardA = 10 * if (EX/MEM.RegWrite ad (EX/MEM.RegisterRd 0) ad (EX/MEM.RegisterRd = ID/EX.")
) ForwardA = 01 * if (MEM/WB.RegWrite ad (MEM/WB.RegisterRd 0) ad (MEM/WB.RegisterRd = ID/EX.")
60 Forwardig Paths & Coditios EX hazard * if (EX/MEM.RegWrite ad (EX/MEM.RegisterRd 0) ad (EX/MEM.RegisterRd = ID/EX.RegisterRs)) ForwardA = 10 * if (EX/MEM.RegWrite ad (EX/MEM.RegisterRd 0) ad (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 10 MEM hazard * if (MEM/WB.RegWrite ad (MEM/WB.RegisterRd 0) ad (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01 * if (MEM/WB.RegWrite ad (MEM/WB.RegisterRd 0) ad (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01 The Processor 60
61 Double Data Hazard Cosider the sequece: add $1,$1,$2 add $1,$1,$3 add $1,$1,$4 Both hazards occur Wat to use the most recet Revise MEM hazard coditio Oly fwd if EX hazard coditio is t true The Processor 61
62 Revised Forwardig Coditio MEM hazard if (MEM/WB.RegWrite ad (MEM/WB.RegisterRd 0) ad ot (EX/MEM.RegWrite ad (EX/MEM.RegisterRd 0) ad (EX/MEM.RegisterRd = ID/EX.RegisterRs)) ad (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01 if (MEM/WB.RegWrite ad (MEM/WB.RegisterRd 0) ad ot (EX/MEM.RegWrite ad (EX/MEM.RegisterRd 0) ad (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ad (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01 The Processor 62


63 Datapath with Forwardig The Processor 63

64 Load-Use Data Hazard Need to stall for oe cycle The Processor 64
65 Load-Use Hazard Detectio Check whe usig istructio is decoded i ID stage ALU operad register umbers i ID stage are give by IF/ID.RegisterRs, IF/ID.RegisterRt Load-use hazard whe ID/EX.MemRead ad ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) If detected, stall ad isert bubble The Processor 65
66 How to Stall the Pipelie Force cotrol values i ID/EX register to 0 EX, MEM ad WB do op (o-operatio) Prevet update of PC ad IF/ID register Usig istructio is decoded agai Followig istructio is fetched agai 1-cycle stall allows MEM to read data for lw Ca subsequetly forward to EX stage The Processor 66

67 Stall/Bubble i the Pipelie Stall iserted here The Processor 67

68 Stall/Bubble i the Pipelie Or, more accurately The Processor 68


69 Datapath with Hazard Detectio The Processor 69
70 Stalls ad Performace The BIG Picture Stalls reduce performace But are required to get correct results Compiler ca arrage code to avoid hazards ad stalls Requires kowledge of the pipelie structure The Processor 70
")
71 Brach Hazards If brach outcome determied i MEM 4.8 Cotrol Hazards Flush these istructios (Set cotrol values to 0) PC The Processor 71
72 Reducig Brach Delay Move hardware to determie outcome to ID stage Target address adder Register comparator Example: brach take 36: sub $10, $4, $8 40: beq $1, $3, 7 44: ad $12, $2, $5 48: or $13, $2, $6 52: add $14, $4, $2 56: slt $15, $6, $ : lw $4, 50($7) The Processor 72


73 Example: Brach Take The Processor 73


74 Example: Brach Take The Processor 74
75 Data Hazards for Braches If a compariso register is a destiatio of 2 d or 3 rd precedig ALU istructio add $1, $2, $3 IF ID EX MEM WB add $4, $5, $6 IF ID EX MEM WB IF ID EX MEM WB beq $1, $4, target IF ID EX MEM WB Ca resolve usig forwardig The Processor 75
76 Data Hazards for Braches If a compariso register is a destiatio of precedig ALU istructio or 2 d precedig load istructio Need 1 stall cycle lw $1, addr IF ID EX MEM WB add $4, $5, $6 IF ID EX MEM WB beq stalled IF ID beq $1, $4, target ID EX MEM WB The Processor 76
77 Data Hazards for Braches If a compariso register is a destiatio of immediately precedig load istructio Need 2 stall cycles lw $1, addr IF ID EX MEM WB beq stalled IF ID beq stalled ID beq $1, $0, target ID EX MEM WB The Processor 77
78 Brach Hazard ad Predictio Static predictio: always predict the same: Speculative ruig util coditio is solved. If error, remove speculative results: Effective Predictio (E): brach occurs. No Effective predictio (NE): brach does NOT occur. Predictio NE if the brach is forward ad E if it is back. Dyamic Predictio: chage the predictio accordig the brach history. Use a small memory for each brach address (BHT, Brach History Table) PC Brach Istructio Address BHT T 1 BIT PREDICTION 2 BITS PREDICTION E F F NE T T Ef F F T F Ed F NEd T NEf T
79 Dyamic Brach Predictio I deeper ad superscalar pipelies, brach pealty is more sigificat Use dyamic predictio Brach predictio buffer (aka brach history table) Idexed by recet brach istructio addresses Stores outcome (take/ot take) To execute a brach Check table, expect the same outcome Start fetchig from fall-through or target If wrog, flush pipelie ad flip predictio The Processor 79
80 Calculatig the Brach Target Eve with predictor, still eed to calculate the target address 1-cycle pealty for a take brach Brach target buffer Cache of target addresses Idexed by PC whe istructio fetched If hit ad istructio is brach predicted take, ca fetch target immediately The Processor 80

81 Brach Target Buffer (BTB) Istructio Address Target Address History bits Brach Target Buffer (BTB) look-up table Fully associative Load target address Program Couter Target address foud Address Istructio Fetch Decod. Istructio Pipelie
82 Fallacies Pipeliig is easy (!) The basic idea is easy The devil is i the details e.g., detectig data hazards Pipeliig is idepedet of techology 4.13 Fallacies ad Pitfalls So why have t we always doe pipeliig? More trasistors make more advaced techiques feasible Pipelie-related ISA desig eeds to take accout of techology treds e.g., predicated istructios The Processor 82
83 Pitfalls Poor ISA desig ca make pipeliig harder e.g., complex istructio sets (VAX, IA-32) Sigificat overhead to make pipeliig work IA-32 micro-op approach e.g., complex addressig modes Register update side effects, memory idirectio e.g., delayed braches Advaced pipelies have log delay slots The Processor 83
84 Cocludig Remarks ISA iflueces desig of datapath ad cotrol Datapath ad cotrol ifluece desig of ISA Pipeliig improves istructio throughput usig parallelism More istructios completed per secod Latecy for each istructio ot reduced Hazards: structural, data, cotrol 4.14 Cocludig Remarks The Processor 84
85 Iformació Adicioal Iformació adicioal para los problemas del capítulo 2 85
86 Tipos de riesgos por depedecia de datos q Depedecias que se preseta para 2 istruccioes i y j, co i ejecutádose ates que j. q RAW (Read After Write): la istrucció posterior j iteta leer ua fuete ates de que la istrucció aterior i la haya modificado. q WAR (Write After Read): la istrucció j iteta modificar u destio ates de que la istrucció i lo haya leído como fuete. q WAW (Write After Write): la istrucció j iteta modificar u destio ates de que la istrucció i lo haya hecho (se modifica el orde ormal de escritura). ü Ejemplos: RAW WAR WAW ADD r1, r2, r3 ADD r1, r2, r3 DIV r1, r2, r3 SUB r5, r1, r6 OR r3,r4, r5 AND r1,r4, r5 AND r6, r5, r1 ADD r4, r1, r3 SW r10, 100(r1) E procesadores segmetados co ejecució e orde SÓLO hay que gestioar los RAW
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Review Istructio Set Architecture Istructio Set The repertoire of istructios of a computer Differet computers have differet istructio
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Review Istructio Set Architecture Istructio Set The repertoire of istructios of a computer Differet computers have differet istructio
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Chapter 4. The Processor. Part A Datapath Design
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter The Processor Part A path Desig Itroductio CPU performace factors Istructio cout Determied by ISA ad compiler. CPI ad
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter The Processor Part A path Desig Itroductio CPU performace factors Istructio cout Determied by ISA ad compiler. CPI ad
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Chapter 4. The Processor. Determined by ISA and compiler. Determined by CPU hardware
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface ARM Editio Chapter 4 The Processor Itroductio CPU performace factors Istructio cout Determied by ISA ad compiler CPI ad Cycle time Determied
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface ARM Editio Chapter 4 The Processor Itroductio CPU performace factors Istructio cout Determied by ISA ad compiler CPI ad Cycle time Determied
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Chapter 4. The Processor. Single-Cycle Disadvantages & Advantages
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter 4 The Processor Pipeliig Sigle-Cycle Disadvatages & Advatages Clk Uses the clock cycle iefficietly the clock cycle must
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter 4 The Processor Pipeliig Sigle-Cycle Disadvatages & Advatages Clk Uses the clock cycle iefficietly the clock cycle must
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Chapter 4. The Processor Advanced Issues
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter 4 The Processor Advaced Issues Review: Pipelie Hazards Structural hazards Desig pipelie to elimiate structural hazards.
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter 4 The Processor Advaced Issues Review: Pipelie Hazards Structural hazards Desig pipelie to elimiate structural hazards.
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
ECE260: Fundamentals of Computer Engineering
 Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture.
 zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
ECE473 Computer Architecture and Organization. Pipeline: Data Hazards
 Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Data Hazards Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 14.1 Pipelining Outline Introduction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
CMSC Computer Architecture Lecture 5: Pipelining. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 5: Pipeliig Prof. Yajig Li Uiversity of Chicago Admiistrative Stuff Lab1 Due toight Lab2: out later today; due 2 weeks from ow Review sessio this Friday Turig award
CMSC 22200 Computer Architecture Lecture 5: Pipeliig Prof. Yajig Li Uiversity of Chicago Admiistrative Stuff Lab1 Due toight Lab2: out later today; due 2 weeks from ow Review sessio this Friday Turig award
Pipelined datapath Staging data. CS2504, Spring'2007 Dimitris Nikolopoulos
 Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Pipelined datapath Staging data b 55 Life of a load in the MIPS pipeline Note: both the instruction and the incremented PC value need to be forwarded in the next stage (in case the instruction is a beq)
Appendix D. Controller Implementation
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Appedix D Cotroller Implemetatio Cotroller Implemetatios Combiatioal logic (sigle-cycle); Fiite state machie (multi-cycle, pipelied);
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Appedix D Cotroller Implemetatio Cotroller Implemetatios Combiatioal logic (sigle-cycle); Fiite state machie (multi-cycle, pipelied);
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
CSC 220: Computer Organization Unit 11 Basic Computer Organization and Design
 College of Computer ad Iformatio Scieces Departmet of Computer Sciece CSC 220: Computer Orgaizatio Uit 11 Basic Computer Orgaizatio ad Desig 1 For the rest of the semester, we ll focus o computer architecture:
College of Computer ad Iformatio Scieces Departmet of Computer Sciece CSC 220: Computer Orgaizatio Uit 11 Basic Computer Orgaizatio ad Desig 1 For the rest of the semester, we ll focus o computer architecture:
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
14:332:331 Pipelined Datapath
 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
LECTURE 9. Pipeline Hazards
 LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
Morgan Kaufmann Publishers 26 February, COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Chapter 5
 Morga Kaufma Publishers 26 February, 28 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter 5 Set-Associative Cache Architecture Performace Summary Whe CPU performace icreases:
Morga Kaufma Publishers 26 February, 28 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Iterface 5 th Editio Chapter 5 Set-Associative Cache Architecture Performace Summary Whe CPU performace icreases:
Master Informatics Eng. 2017/18. A.J.Proença. Memory Hierarchy. (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2017/18 1
 AJProença, Advanced Architectures, MiEI, UMinho, 2017/18 1") Advaced Architectures Master Iformatics Eg. 2017/18 A.J.Proeça Memory Hierarchy (most slides are borrowed) AJProeça, Advaced Architectures, MiEI, UMiho, 2017/18 1 Itroductio Programmers wat ulimited amouts
Advaced Architectures Master Iformatics Eg. 2017/18 A.J.Proeça Memory Hierarchy (most slides are borrowed) AJProeça, Advaced Architectures, MiEI, UMiho, 2017/18 1 Itroductio Programmers wat ulimited amouts
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
Chapter 4 The Datapath
 The Ageda Chapter 4 The Datapath Based o slides McGraw-Hill Additioal material 24/25/26 Lewis/Marti Additioal material 28 Roth Additioal material 2 Taylor Additioal material 2 Farmer Tae the elemets that
The Ageda Chapter 4 The Datapath Based o slides McGraw-Hill Additioal material 24/25/26 Lewis/Marti Additioal material 28 Roth Additioal material 2 Taylor Additioal material 2 Farmer Tae the elemets that
Course Site: Copyright 2012, Elsevier Inc. All rights reserved.
 Course Site: http://cc.sjtu.edu.c/g2s/site/aca.html 1 Computer Architecture A Quatitative Approach, Fifth Editio Chapter 2 Memory Hierarchy Desig 2 Outlie Memory Hierarchy Cache Desig Basic Cache Optimizatios
Course Site: http://cc.sjtu.edu.c/g2s/site/aca.html 1 Computer Architecture A Quatitative Approach, Fifth Editio Chapter 2 Memory Hierarchy Desig 2 Outlie Memory Hierarchy Cache Desig Basic Cache Optimizatios
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
CMSC Computer Architecture Lecture 12: Virtual Memory. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Virtual Memory Prof. Yajig Li Uiversity of Chicago A System with Physical Memory Oly Examples: most Cray machies early PCs Memory early all embedded systems
CMSC 22200 Computer Architecture Lecture 12: Virtual Memory Prof. Yajig Li Uiversity of Chicago A System with Physical Memory Oly Examples: most Cray machies early PCs Memory early all embedded systems
The Processor: Datapath and Control. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 The Processor: Datapath and Control Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Introduction CPU performance factors Instruction count Determined
The Processor: Datapath and Control Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Introduction CPU performance factors Instruction count Determined
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: A Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
Processor (I) - datapath & control. Hwansoo Han
 - datapath & control. Hwansoo Han") Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
EE557--FALL 1999 MIDTERM 1. Closed books, closed notes
 NAME: SOLUTIONS STUDENT NUMBER: EE557--FALL 1999 MIDTERM 1 Closed books, closed notes GRADING POLICY: The front page of your exam shows your total numerical score out of 75. The highest numerical score
NAME: SOLUTIONS STUDENT NUMBER: EE557--FALL 1999 MIDTERM 1 Closed books, closed notes GRADING POLICY: The front page of your exam shows your total numerical score out of 75. The highest numerical score
ECS 154B Computer Architecture II Spring 2009
 ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12 (2) Lecture notes from MKP, H. H. Lee and S.
 Lecture notes from MKP, H. H. Lee and S.") Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12
 Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online
CS252 Spring 2017 Graduate Computer Architecture. Lecture 6: Out-of-Order Processors
 CS252 Sprig 2017 Graduate Computer Architecture Lecture 6: Out-of-Order Processors Lisa Wu, Krste Asaovic http://ist.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 2 WU UCB CS252 SP17 Last Time i Lecture
CS252 Sprig 2017 Graduate Computer Architecture Lecture 6: Out-of-Order Processors Lisa Wu, Krste Asaovic http://ist.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 2 WU UCB CS252 SP17 Last Time i Lecture
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
Multi-Threading. Hyper-, Multi-, and Simultaneous Thread Execution
 Multi-Threadig Hyper-, Multi-, ad Simultaeous Thread Executio 1 Performace To Date Icreasig processor performace Pipeliig. Brach predictio. Super-scalar executio. Out-of-order executio. Caches. Hyper-Threadig
Multi-Threadig Hyper-, Multi-, ad Simultaeous Thread Executio 1 Performace To Date Icreasig processor performace Pipeliig. Brach predictio. Super-scalar executio. Out-of-order executio. Caches. Hyper-Threadig
Lecture 1: Introduction and Fundamental Concepts 1
 Uderstadig Performace Lecture : Fudametal Cocepts ad Performace Aalysis CENG 332 Algorithm Determies umber of operatios executed Programmig laguage, compiler, architecture Determie umber of machie istructios
Uderstadig Performace Lecture : Fudametal Cocepts ad Performace Aalysis CENG 332 Algorithm Determies umber of operatios executed Programmig laguage, compiler, architecture Determie umber of machie istructios
Chapter 4. The Processor Designing the datapath
 Chapter 4 The Processor Designing the datapath Introduction CPU performance determined by Instruction Count Clock Cycles per Instruction (CPI) and Cycle time Determined by Instruction Set Architecure (ISA)
Chapter 4 The Processor Designing the datapath Introduction CPU performance determined by Instruction Count Clock Cycles per Instruction (CPI) and Cycle time Determined by Instruction Set Architecure (ISA)
(Basic) Processor Pipeline
 Processor Pipeline") (Basic) Processor Pipeline Nima Honarmand Generic Instruction Life Cycle Logical steps in processing an instruction: Instruction Fetch (IF_STEP) Instruction Decode (ID_STEP) Operand Fetch (OF_STEP) Might
(Basic) Processor Pipeline Nima Honarmand Generic Instruction Life Cycle Logical steps in processing an instruction: Instruction Fetch (IF_STEP) Instruction Decode (ID_STEP) Operand Fetch (OF_STEP) Might
Pipelining. Ideal speedup is number of stages in the pipeline. Do we achieve this? 2. Improve performance by increasing instruction throughput ...
 CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
COSC121: Computer Systems. ISA and Performance
 COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
COSC121: Computer Systems. ISA and Performance Jeremy Bolton, PhD Assistant Teaching Professor Constructed using materials: - Patt and Patel Introduction to Computing Systems (2nd) - Patterson and Hennessy
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Chapter 4. The Processor. Instruction count Determined by ISA and compiler. We will examine two MIPS implementations
 Chapter 4 The Processor Part I Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations
Chapter 4 The Processor Part I Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
The Processor (1) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (1) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (1) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CS/CoE 1541 Exam 1 (Spring 2019).
.") CS/CoE 1541 Exam 1 (Spring 2019). Name: Question 1 (8+2+2+3=15 points): In this problem, consider the execution of the following code segment on a 5-stage pipeline with forwarding/stalling hardware and
CS/CoE 1541 Exam 1 (Spring 2019). Name: Question 1 (8+2+2+3=15 points): In this problem, consider the execution of the following code segment on a 5-stage pipeline with forwarding/stalling hardware and
Elementary Educational Computer
 Chapter 5 Elemetary Educatioal Computer. Geeral structure of the Elemetary Educatioal Computer (EEC) The EEC coforms to the 5 uits structure defied by vo Neuma's model (.) All uits are preseted i a simplified
Chapter 5 Elemetary Educatioal Computer. Geeral structure of the Elemetary Educatioal Computer (EEC) The EEC coforms to the 5 uits structure defied by vo Neuma's model (.) All uits are preseted i a simplified
End Semester Examination CSE, III Yr. (I Sem), 30002: Computer Organization
, 30002: Computer Organization") Ed Semester Examiatio 2013-14 CSE, III Yr. (I Sem), 30002: Computer Orgaizatio Istructios: GROUP -A 1. Write the questio paper group (A, B, C, D), o frot page top of aswer book, as per what is metioed
Ed Semester Examiatio 2013-14 CSE, III Yr. (I Sem), 30002: Computer Orgaizatio Istructios: GROUP -A 1. Write the questio paper group (A, B, C, D), o frot page top of aswer book, as per what is metioed
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
CS 251, Winter 2018, Assignment % of course mark
 CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Chapter 4 (Part II) Sequential Laundry
 Sequential Laundry") Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Lecture Topics. Announcements. Today: Single-Cycle Processors (P&H ) Next: continued. Milestone #3 (due 2/9) Milestone #4 (due 2/23)
 Next: continued. Milestone #3 (due 2/9) Milestone #4 (due 2/23)") Lecture Topics Today: Single-Cycle Processors (P&H 4.1-4.4) Next: continued 1 Announcements Milestone #3 (due 2/9) Milestone #4 (due 2/23) Exam #1 (Wednesday, 2/15) 2 1 Exam #1 Wednesday, 2/15 (3:00-4:20
Lecture Topics Today: Single-Cycle Processors (P&H 4.1-4.4) Next: continued 1 Announcements Milestone #3 (due 2/9) Milestone #4 (due 2/23) Exam #1 (Wednesday, 2/15) 2 1 Exam #1 Wednesday, 2/15 (3:00-4:20
CMSC Computer Architecture Lecture 3: ISA and Introduction to Microarchitecture. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 3: ISA ad Itroductio to Microarchitecture Prof. Yajig Li Uiversity of Chicago Lecture Outlie ISA uarch (hardware implemetatio of a ISA) Logic desig basics Sigle-cycle
CMSC 22200 Computer Architecture Lecture 3: ISA ad Itroductio to Microarchitecture Prof. Yajig Li Uiversity of Chicago Lecture Outlie ISA uarch (hardware implemetatio of a ISA) Logic desig basics Sigle-cycle
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and