Innovative Power Control for. Performance System LSIs. (Univ. of Electro-Communications) (Tokyo Univ. of Agriculture and Tech.)
|
|
|
- Verity Charles
- 5 years ago
- Views:
Transcription
1 Innovative Power Control for Ultra Low-Power and High- Performance System LSIs Hiroshi Nakamura Hideharu Amano Masaaki Kondo Mitaro Namiki Kimiyoshi Usami (Univ. of Tokyo) (Keio Univ.) (Univ. of Electro-Communications) (Tokyo Univ. of Agriculture and Tech.) (Shibaura Inst. of Tech.) 1






2 Objective and Strategy Objective: drastic power reduction of high-performance system LSIs Strategy: innovative power control through tight Co-Optimization / Co-Design of system software, architecture, and circuit design. Principle: Performance: limited by a bottleneck Power: summation of whole system Low power and slow operation for unhurried / idle parts System Software Compiler Architecture Circuit Technology Co-Opt timizat ion/co o-desig gn 2
3 Role of Design Hierarchy for Low Power OS Architecture When? Where? Circuit How? throttle lever of power/performance Device Clock Gating, Dual Vth, DVFS, Power Gating, Back-bias,.. Circuit Level : Provide levers to throttle performance / power Architecture, OS Level : Find a chance to set levers, when and where?? architecture: Intra-task/process optimization OS: Inter-task/process optimization 3
4 Preferable Throttle Lever Effectiveness of Processor Reconfig int fp System Power Reduction Low Overhead in Area, Performance, Power Controlling the throttle lever itself takes time and consumes power Fine Control Granularity in both Space and Time Locations of busy / idle parts are small and change frequently cache Processor int fp cache Cache Memory Network System LSI busy idle time 4
5 Example of Throttle Levers for dynamic power: Clock Gating, DVFS both effective, DVFS particular (Power Vdd 2 ) Clock Gating: very fine-grained control with little overhead easily utilized within circuit level design DVFS: tens of μs to change Vdd through regulator moderate granularity for leakage power: Power Gating, Body Biasing both effective, but large overhead in power and performance Body biasing: spatial granularity statically defined regions not easy for fine-grained i control sleep signal Circuit Block sleep Tr. Vdd VGND GND Power Gating 5
6 Role of Design Hierarchy for Low Power: The Ideal System OS Architecture Circuit Device When? When? Where? Where? How? How? Spatial and Temporal Granularity is important Co-Design of Circuit, Architecture and OS for Power Co-Optimization of Throttle Lever Control: especially, Co-Optimization of Spatial and Temporal Granularity ex. activity localization to make full use of throttle levers characteristics by architecture/os 6
7 Team Formation of our Research Project Co-Optim mization of System Software and Arch hitecture e Archite Circuit t Design Architecture/ Compiler Co-Optim mization cture an of nd n System Software Network Processor int fp cache Circuit it Design Reconfig System Memory VddH VddL Sub-theme (leader) Co-operative System Software with Arch. (Prof. Namiki) Ultra Low-Power Reconf. Architecture (Prof. Amano) Data Resident Architecture (Prof. Nakamura) Data Resident Compiler (Prof. Kondo) Ultra Low-Power Circuit logic block Design (Prof. Usami) 7
8 (Project 1) Geyser: Low Power Processor through Fine-grained Runtime Power Gating Target: Leakage Power Background: Leakage reduction techniques so far, Standby time: power-gating (Coarse Grain) Runtime: Cache-decay, Drowsy-cache, (Coarse Grain in temporal) Leakage for logic parts (ALU, multiplier, etc.) gets serious Fast but Leaky transistors are used Active ratio of those parts are not necessarily high, but active parts change frequently, that is, cycle by cycle Objective : Reduce runtime leakage power of logic parts Challenge: how to optimize the granularity of power gating 8
9 Instruction Pipeline with Power-Gating Geyser: MIPS compatible processor with 5-stage pipeline, Straightforward PG (power-gating) Turn EX-units into active mode only if necessary Ex-unit gets active when an affecting instruction enters the IF stage The activated EX-unit returns to sleep mode after execution IF ID EX MEM WB Inst SHIFT Instruction ALU Shift Mult Div Operation Detects which unit will be used Sends wake-up signal MIPS R3000 pipeline 9
10 Challenges for Run-Time Power-Gating: Energy Overhead Power Break-Even Time (BET) : Energy overhead Normal Leakage = 2 : part of leakage saving 2 Break-Even Time(BET) Time 4 : Net Energy saving Sleep Wake- Up Sleep period should be longer than BET Otherwise, total energy consumption increases BET tells the smallest granularity for Power Gating 10









11 Break Even Time of Each Functional Unit 11 Cycl 00MHz 90 nm technology ALU Shift Mult Div CP0 BET is shortened when the chip temperature climbs up Leakage current depends on temperature heavily We need Novel PG strategies taking BET into account 11
12 Power Gating Strategies Requirement: Power off Ex-units longer than BET static strategy straightforward:ex-units always in sleep after execution ideal compiler (ideal compiler-directed): exact average idle time of Ex-units after each instruction is known (for reference only) dynamic strategy L1 miss: Ex-units fall asleep only if encountering L1 cache misses L1 miss penalty = 15 cycles L2 miss: Ex-units fall asleep only if encountering L2 cache misses L2 miss penalty = 200 cycles both static and dynamic strategies es ideal compiler + L2 cache miss ideal (God) : ideal dynamic strategy exact idle time of Ex-units are known at anytime, upper limit of PG (for reference only) 12






13 Result for Frequently Used Execution Unit FPADD for MGRID straightforward: ard BET is longer than sleep time waste of energy Relative Energy compared to non-pg ideal compiler: less chance for longer BET L1: resulting sleep time is about 15 ideal for BET<15, but waste of energy for longer BETstraightforward L2: resulting sleep time is 200 ideal for longer BET for shorter BET, compiler is effective ideal compiler L1 L2 ideal comp. + L2 ideal (God) BET(cycle) 13
14 Collaboration with Compiler / OS Suggested Power Gating Strategy Co-optimization on Control Granularity of the PG lever compiler direction by assuming short BET, because compiler-directed PG is effective for shorter BET for shorter BET (high temperature), compiler direction is put into use, and take (compiler + L2-miss) strategy for longer BET (low temperature), take L2-miss strategy, but ignore compiler direction OS is expected to switch between strategies by observing changes on BET Power Gating Collaborated with Compiler / OS 14
![Leakage Monitor [Koyama et. al. ITC-CSCC 08] [Usami et. al. ISLPED2011 (poster 15)] BET depends on the dynamic environment, such as temperature and the process variation.](/docs-images/89/98264030/images/15-2.jpg "on-chip leakage monitoring circuit More leakage results in faster charging of VGND Estimate leakage by measuring rise-time of VGND to VREF OS can select the best PG strategy by observing this monitor")
15 Leakage Monitor [Koyama et. al. ITC-CSCC 08] [Usami et. al. ISLPED2011 (poster 15)] BET depends on the dynamic environment, such as temperature and the process variation. on-chip leakage monitoring circuit More leakage results in faster charging of VGND Estimate leakage by measuring rise-time of VGND to VREF OS can select the best PG strategy by observing this monitor OFF ON '1' '0' VGND VGN ND Volta age (V) More leakage Less leakage Reference(V REF ) Rise Rise Sleep time (s) 15
16 Co-Optimization of Throttle Lever Control in Fine-grained ga edruntime Power Gating PG Strategy best granularity changes dynamically (e.g. temperature) PG Control through Activity Localization PG Lever controlled in 10~100cycles OS Architecture Circuit Who should be responsible for PG Control depends on granularity of Control PG control granularity (BET) : 10 ~ 100 cycles best granularity of control changes every msec 16





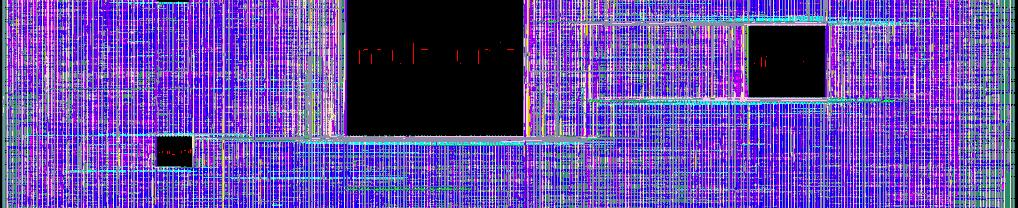




17 Prototype CPU : Geyser-1 [Ikebuchi et. al. ASSCC 09] MIPS R3000 Fujitsu e-shuttle 65nm Vdd=1.2V successfully in operation the first successful cycle by cycle power gating 2.1 mm 4.2 mm Shifter MULT DIV ALU leakage monitor 17







18 Prototype CPU : Geyser-2 Geyser-2: 2 nd Prototype with caches and TLBs on-chip max working frequency : 210MHz (wakeup latency is less than 5ns) ISLPED2011 booth 4 Leakag ge Power [mw] Temperature [C] 18
19 (Project 2) Cool Mega Array Reconfigurable Accelerator: not for performance but power-efficiency PE array consists of only a combinatorial logic Power consumption of registers and clock distribution is reduced Low-voltage and Low-power PE array operation balanced with data bandwidth of memory localization of operations Operation / Reg. access Performance / Power combinational circuit DVS region PE SE DME DME DME DME DMEM DMEM DMEM DMEM M M M M Architecture of CMA 19
20 Prototype : CMA-1 Fujitsu 65nm 8x8 PE array 12KB data memory control part : 1.2V Maximum power efficiency [MOPS/mW] Power Efficiency [MOPS/mW] ISLPED2011 booth 4 PE Array Voltage [V] 20

![NOCS 2010] [Matsutani et. al. IEEE Trans.](/docs-images/89/98264030/images/21-1.jpg "on CAD, 4/2011] Linux-based Evaluation Platform Demonstration @ISLPED2011 booth 4 Towards Integrated System LSIs")
21 Summary and Future Direction Geyser : Run-time Power Gating Processor first cycle-by-cycle l power gating processor Cool Mega Array : Power Efficiency i Accelerator CMA CMA CMA Other Projects Fine Grain Power Gating NoCs [Matsutani et. al. NOCS 2010] [Matsutani et. al. IEEE Trans. on CAD, 4/2011] Linux-based Evaluation Platform booth 4 Towards Integrated System LSIs Evaluation through real integration via 3D wireless NoCs Geyser CPU Main Memory L2 Cache 21
22 Selected Publications 1. N. Seki, et.al., A Fine Grain Dynamic Sleep Control Scheme in MIPS R3000, Proc. of ICCD-2008, pp , K.Usami, et.al., Design and Implementation of Fine-grain Power Gating with Ground Bounce Suppression, Proc. of VLSI Design 2009, pp , N.Takagi, et.al., Cooperative Shared Resource Access Control for Low Power Chip Multiprocessors, ISLPED-2009, pp , SS S.Saito, et.al., "MuCCRA-Cube:A C 3D Dynamically Reconfigurable Processor with Inductive Coupling link," Proc. of FPL09, pp.6-11, D.Ikebuchi, et.al., Geyser-1: A MIPS R3000 CPU core with fine grain runtime power gating, Proc. of IEEE ASSCC-2009, pp , H. Matsutani, et.al., "Ultra Fine-Grained Run-Time Power Gating of On- Chip Routers for CMPs", Proc. of NOCS'10, pp.61-68, H. Matsutani, et.al., "Performance, Area, and Power Evaluations of Ultrafine-Grained Run-Time Power-Gating Routers for CMPs", IEEE Trans. on CAD (TCAD), Vol.30, No.4, pp Apr K.Usami, et.al., On-chip Detection Methodology for Break-Even Time of Power Gated Function Units, Proc. of ISLPED-2011, (to appear) 22
A Study of Leakage Power Reduction Mechanisms on Functional Units and TLBs for Embedded Processors
 A Study of Leakage Power Reduction Mechanisms on Functional Units and TLBs for Embedded Processors Zhao LEI A dissertation submitted in partial fulfillment of the requirements for the degree of DOCTOR
A Study of Leakage Power Reduction Mechanisms on Functional Units and TLBs for Embedded Processors Zhao LEI A dissertation submitted in partial fulfillment of the requirements for the degree of DOCTOR
A Building Block 3D System with Inductive-Coupling Through Chip Interfaces Hiroki Matsutani Keio University, Japan
 A Building Block 3D System with Inductive-Coupling Through Chip Interfaces Hiroki Matsutani Keio University, Japan 1 Outline: 3D Wireless NoC Designs This part also explores 3D NoC architecture with inductive-coupling
A Building Block 3D System with Inductive-Coupling Through Chip Interfaces Hiroki Matsutani Keio University, Japan 1 Outline: 3D Wireless NoC Designs This part also explores 3D NoC architecture with inductive-coupling
A Multi-Vdd Dynamic Variable-Pipeline On-Chip Router for CMPs
 A Multi-Vdd Dynamic Variable-Pipeline On-Chip Router for CMPs Hiroki Matsutani 1, Yuto Hirata 1, Michihiro Koibuchi 2, Kimiyoshi Usami 3, Hiroshi Nakamura 4, and Hideharu Amano 1 1 Keio University 2 National
A Multi-Vdd Dynamic Variable-Pipeline On-Chip Router for CMPs Hiroki Matsutani 1, Yuto Hirata 1, Michihiro Koibuchi 2, Kimiyoshi Usami 3, Hiroshi Nakamura 4, and Hideharu Amano 1 1 Keio University 2 National
A HARDWARE COMPLETE DETECTION MECHANISM FOR AN ENERGY EFFICIENT RECONFIGURABLE ACCELERATOR CMA
 A HARDWARE COMPLETE DETECTION MECHANISM FOR AN ENERGY EFFICIENT RECONFIGURABLE ACCELERATOR CMA Akihito Tsusaka Mai Izawa Rie Uno Nobuyuki Ozaki Hideharu Amano Keio University, Yokohama, 223-8522, Japan
A HARDWARE COMPLETE DETECTION MECHANISM FOR AN ENERGY EFFICIENT RECONFIGURABLE ACCELERATOR CMA Akihito Tsusaka Mai Izawa Rie Uno Nobuyuki Ozaki Hideharu Amano Keio University, Yokohama, 223-8522, Japan
SH-Mobile3: Application Processor for 3G Cellular Phones on a Low-Power SoC Design Platform
 SH-Mobile3: Application Processor for 3G Cellular Phones on a Low-Power SoC Design Platform H. Mizuno, N. Irie, K. Uchiyama, Y. Yanagisawa 1, S. Yoshioka 1, I. Kawasaki 1, and T. Hattori 2 Hitachi Ltd.,
SH-Mobile3: Application Processor for 3G Cellular Phones on a Low-Power SoC Design Platform H. Mizuno, N. Irie, K. Uchiyama, Y. Yanagisawa 1, S. Yoshioka 1, I. Kawasaki 1, and T. Hattori 2 Hitachi Ltd.,
Efficient Systems. Micrel lab, DEIS, University of Bologna. Advisor
 Row-based Design Methodologies To Compensate Variability For Energy- Efficient Systems Micrel lab, DEIS, University of Bologna Mohammad Reza Kakoee PhD Student m.kakoee@unibo.it it Luca Benini Advisor
Row-based Design Methodologies To Compensate Variability For Energy- Efficient Systems Micrel lab, DEIS, University of Bologna Mohammad Reza Kakoee PhD Student m.kakoee@unibo.it it Luca Benini Advisor
Low-Power Technology for Image-Processing LSIs
 Low- Technology for Image-Processing LSIs Yoshimi Asada The conventional LSI design assumed power would be supplied uniformly to all parts of an LSI. For a design with multiple supply voltages and a power
Low- Technology for Image-Processing LSIs Yoshimi Asada The conventional LSI design assumed power would be supplied uniformly to all parts of an LSI. For a design with multiple supply voltages and a power
A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing
 A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge, Michael Meeuwsen, Christine
A 167-processor Computational Array for Highly-Efficient DSP and Embedded Application Processing Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge, Michael Meeuwsen, Christine
A 297MOPS/0.4mW Ultra Low Power Coarse-grained Reconfigurable Accelerator CMA-SOTB-2
 A 297MOPS/.4mW Ultra Low Power Coarse-grained Reconfigurable Accelerator CMA-SOTB-2 Koichiro Masuyama, Yu Fujita, Hayate Okuhara, Hideharu Amano Dept. of ICS, Keio University, Yokohama Japan Email: {wasmii,
A 297MOPS/.4mW Ultra Low Power Coarse-grained Reconfigurable Accelerator CMA-SOTB-2 Koichiro Masuyama, Yu Fujita, Hayate Okuhara, Hideharu Amano Dept. of ICS, Keio University, Yokohama Japan Email: {wasmii,
Delay Modeling and Static Timing Analysis for MTCMOS Circuits
 Delay Modeling and Static Timing Analysis for MTCMOS Circuits Naoaki Ohkubo Kimiyoshi Usami Graduate School of Engineering, Shibaura Institute of Technology 307 Fukasaku, Munuma-ku, Saitama, 337-8570 Japan
Delay Modeling and Static Timing Analysis for MTCMOS Circuits Naoaki Ohkubo Kimiyoshi Usami Graduate School of Engineering, Shibaura Institute of Technology 307 Fukasaku, Munuma-ku, Saitama, 337-8570 Japan
Novel Nonvolatile Memory Hierarchies to Realize "Normally-Off Mobile Processors" ASP-DAC 2014
 Novel Nonvolatile Memory Hierarchies to Realize "Normally-Off Mobile Processors" ASP-DAC 2014 Shinobu Fujita, Kumiko Nomura, Hiroki Noguchi, Susumu Takeda, Keiko Abe Toshiba Corporation, R&D Center Advanced
Novel Nonvolatile Memory Hierarchies to Realize "Normally-Off Mobile Processors" ASP-DAC 2014 Shinobu Fujita, Kumiko Nomura, Hiroki Noguchi, Susumu Takeda, Keiko Abe Toshiba Corporation, R&D Center Advanced
Part IV: 3D WiNoC Architectures
 Wireless NoC as Interconnection Backbone for Multicore Chips: Promises, Challenges, and Recent Developments Part IV: 3D WiNoC Architectures Hiroki Matsutani Keio University, Japan 1 Outline: 3D WiNoC Architectures
Wireless NoC as Interconnection Backbone for Multicore Chips: Promises, Challenges, and Recent Developments Part IV: 3D WiNoC Architectures Hiroki Matsutani Keio University, Japan 1 Outline: 3D WiNoC Architectures
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
An FPGA Architecture Supporting Dynamically-Controlled Power Gating
 An FPGA Architecture Supporting Dynamically-Controlled Power Gating Altera Corporation March 16 th, 2012 Assem Bsoul and Steve Wilton {absoul, stevew}@ece.ubc.ca System-on-Chip Research Group Department
An FPGA Architecture Supporting Dynamically-Controlled Power Gating Altera Corporation March 16 th, 2012 Assem Bsoul and Steve Wilton {absoul, stevew}@ece.ubc.ca System-on-Chip Research Group Department
3D WiNoC Architectures
 Interconnect Enhances Architecture: Evolution of Wireless NoC from Planar to 3D 3D WiNoC Architectures Hiroki Matsutani Keio University, Japan Sep 18th, 2014 Hiroki Matsutani, "3D WiNoC Architectures",
Interconnect Enhances Architecture: Evolution of Wireless NoC from Planar to 3D 3D WiNoC Architectures Hiroki Matsutani Keio University, Japan Sep 18th, 2014 Hiroki Matsutani, "3D WiNoC Architectures",
OUTLINE Introduction Power Components Dynamic Power Optimization Conclusions
 OUTLINE Introduction Power Components Dynamic Power Optimization Conclusions 04/15/14 1 Introduction: Low Power Technology Process Hardware Architecture Software Multi VTH Low-power circuits Parallelism
OUTLINE Introduction Power Components Dynamic Power Optimization Conclusions 04/15/14 1 Introduction: Low Power Technology Process Hardware Architecture Software Multi VTH Low-power circuits Parallelism
SRAMs to Memory. Memory Hierarchy. Locality. Low Power VLSI System Design Lecture 10: Low Power Memory Design
 SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
ECE 571 Advanced Microprocessor-Based Design Lecture 24
 ECE 571 Advanced Microprocessor-Based Design Lecture 24 Vince Weaver http://www.eece.maine.edu/ vweaver vincent.weaver@maine.edu 25 April 2013 Project/HW Reminder Project Presentations. 15-20 minutes.
ECE 571 Advanced Microprocessor-Based Design Lecture 24 Vince Weaver http://www.eece.maine.edu/ vweaver vincent.weaver@maine.edu 25 April 2013 Project/HW Reminder Project Presentations. 15-20 minutes.
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Efficient Evaluation and Management of Temperature and Reliability for Multiprocessor Systems
 Efficient Evaluation and Management of Temperature and Reliability for Multiprocessor Systems Ayse K. Coskun Electrical and Computer Engineering Department Boston University http://people.bu.edu/acoskun
Efficient Evaluation and Management of Temperature and Reliability for Multiprocessor Systems Ayse K. Coskun Electrical and Computer Engineering Department Boston University http://people.bu.edu/acoskun
An Energy-Efficient Near/Sub-Threshold FPGA Interconnect Architecture Using Dynamic Voltage Scaling and Power-Gating
 An Energy-Efficient Near/Sub-Threshold FPGA Interconnect Architecture Using Dynamic Voltage Scaling and Power-Gating He Qi, Oluseyi Ayorinde, and Benton H. Calhoun Charles L. Brown Department of Electrical
An Energy-Efficient Near/Sub-Threshold FPGA Interconnect Architecture Using Dynamic Voltage Scaling and Power-Gating He Qi, Oluseyi Ayorinde, and Benton H. Calhoun Charles L. Brown Department of Electrical
EECS 322 Computer Architecture Superpipline and the Cache
 EECS 322 Computer Architecture Superpipline and the Cache Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses powerpoint animation: please viewshow Summary:
EECS 322 Computer Architecture Superpipline and the Cache Instructor: Francis G. Wolff wolff@eecs.cwru.edu Case Western Reserve University This presentation uses powerpoint animation: please viewshow Summary:
A 167-processor 65 nm Computational Platform with Per-Processor Dynamic Supply Voltage and Dynamic Clock Frequency Scaling
 A 167-processor 65 nm Computational Platform with Per-Processor Dynamic Supply Voltage and Dynamic Clock Frequency Scaling Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge,
A 167-processor 65 nm Computational Platform with Per-Processor Dynamic Supply Voltage and Dynamic Clock Frequency Scaling Dean Truong, Wayne Cheng, Tinoosh Mohsenin, Zhiyi Yu, Toney Jacobson, Gouri Landge,
High performance, power-efficient DSPs based on the TI C64x
 High performance, power-efficient DSPs based on the TI C64x Sridhar Rajagopal, Joseph R. Cavallaro, Scott Rixner Rice University {sridhar,cavallar,rixner}@rice.edu RICE UNIVERSITY Recent (2003) Research
High performance, power-efficient DSPs based on the TI C64x Sridhar Rajagopal, Joseph R. Cavallaro, Scott Rixner Rice University {sridhar,cavallar,rixner}@rice.edu RICE UNIVERSITY Recent (2003) Research
Leakage Mitigation Techniques in Smartphone SoCs
 Leakage Mitigation Techniques in Smartphone SoCs 1 John Redmond 1 Broadcom International Symposium on Low Power Electronics and Design Smartphone Use Cases Power Device Convergence Diverse Use Cases Camera
Leakage Mitigation Techniques in Smartphone SoCs 1 John Redmond 1 Broadcom International Symposium on Low Power Electronics and Design Smartphone Use Cases Power Device Convergence Diverse Use Cases Camera
Power Analysis for CMOS based Dual Mode Logic Gates using Power Gating Techniques
 Power Analysis for CMOS based Dual Mode Logic Gates using Power Gating Techniques S. Nand Singh Dr. R. Madhu M. Tech (VLSI Design) Assistant Professor UCEK, JNTUK. UCEK, JNTUK Abstract: Low power technology
Power Analysis for CMOS based Dual Mode Logic Gates using Power Gating Techniques S. Nand Singh Dr. R. Madhu M. Tech (VLSI Design) Assistant Professor UCEK, JNTUK. UCEK, JNTUK Abstract: Low power technology
Low Power System-on-Chip Design Chapters 3-4
 1 Low Power System-on-Chip Design Chapters 3-4 Tomasz Patyk 2 Chapter 3: Multi-Voltage Design Challenges in Multi-Voltage Designs Voltage Scaling Interfaces Timing Issues in Multi-Voltage Designs Power
1 Low Power System-on-Chip Design Chapters 3-4 Tomasz Patyk 2 Chapter 3: Multi-Voltage Design Challenges in Multi-Voltage Designs Voltage Scaling Interfaces Timing Issues in Multi-Voltage Designs Power
Data Retention in MLC NAND Flash Memory: Characterization, Optimization, and Recovery
 Data Retention in MLC NAND Flash Memory: Characterization, Optimization, and Recovery Yu Cai, Yixin Luo, Erich F. Haratsch*, Ken Mai, Onur Mutlu Carnegie Mellon University, *LSI Corporation 1 Many use
Data Retention in MLC NAND Flash Memory: Characterization, Optimization, and Recovery Yu Cai, Yixin Luo, Erich F. Haratsch*, Ken Mai, Onur Mutlu Carnegie Mellon University, *LSI Corporation 1 Many use
LECTURE 11. Memory Hierarchy
 LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
A Low Power Asynchronous FPGA with Autonomous Fine Grain Power Gating and LEDR Encoding
 A Low Power Asynchronous FPGA with Autonomous Fine Grain Power Gating and LEDR Encoding N.Rajagopala krishnan, k.sivasuparamanyan, G.Ramadoss Abstract Field Programmable Gate Arrays (FPGAs) are widely
A Low Power Asynchronous FPGA with Autonomous Fine Grain Power Gating and LEDR Encoding N.Rajagopala krishnan, k.sivasuparamanyan, G.Ramadoss Abstract Field Programmable Gate Arrays (FPGAs) are widely
Lecture 18: Multithreading and Multicores
 S 09 L18-1 18-447 Lecture 18: Multithreading and Multicores James C. Hoe Dept of ECE, CMU April 1, 2009 Announcements: Handouts: Handout #13 Project 4 (On Blackboard) Design Challenges of Technology Scaling,
S 09 L18-1 18-447 Lecture 18: Multithreading and Multicores James C. Hoe Dept of ECE, CMU April 1, 2009 Announcements: Handouts: Handout #13 Project 4 (On Blackboard) Design Challenges of Technology Scaling,
Power Reduction Techniques in the Memory System. Typical Memory Hierarchy
 Power Reduction Techniques in the Memory System Low Power Design for SoCs ASIC Tutorial Memories.1 Typical Memory Hierarchy On-Chip Components Control edram Datapath RegFile ITLB DTLB Instr Data Cache
Power Reduction Techniques in the Memory System Low Power Design for SoCs ASIC Tutorial Memories.1 Typical Memory Hierarchy On-Chip Components Control edram Datapath RegFile ITLB DTLB Instr Data Cache
INTERNATIONAL JOURNAL OF PROFESSIONAL ENGINEERING STUDIES Volume 9 /Issue 3 / OCT 2017
 Design of Low Power Adder in ALU Using Flexible Charge Recycling Dynamic Circuit Pallavi Mamidala 1 K. Anil kumar 2 mamidalapallavi@gmail.com 1 anilkumar10436@gmail.com 2 1 Assistant Professor, Dept of
Design of Low Power Adder in ALU Using Flexible Charge Recycling Dynamic Circuit Pallavi Mamidala 1 K. Anil kumar 2 mamidalapallavi@gmail.com 1 anilkumar10436@gmail.com 2 1 Assistant Professor, Dept of
DYNAMIC CIRCUIT TECHNIQUE FOR LOW- POWER MICROPROCESSORS Kuruva Hanumantha Rao 1 (M.tech)
") DYNAMIC CIRCUIT TECHNIQUE FOR LOW- POWER MICROPROCESSORS Kuruva Hanumantha Rao 1 (M.tech) K.Prasad Babu 2 M.tech (Ph.d) hanumanthurao19@gmail.com 1 kprasadbabuece433@gmail.com 2 1 PG scholar, VLSI, St.JOHNS
DYNAMIC CIRCUIT TECHNIQUE FOR LOW- POWER MICROPROCESSORS Kuruva Hanumantha Rao 1 (M.tech) K.Prasad Babu 2 M.tech (Ph.d) hanumanthurao19@gmail.com 1 kprasadbabuece433@gmail.com 2 1 PG scholar, VLSI, St.JOHNS
Normally-Off MCU Architecture for Low-power Sensor Node
 Normally-Off MCU Architecture for Low-power Sensor Node ASP-DAC 2014, Session 1S-3 Jan. 21, 2014 Masanori Hayashikoshi (Speaker), Yohei Sato, Hiroshi Ueki, Hiroyuki Kawai, Toru Shimizu, Renesas Electronics
Normally-Off MCU Architecture for Low-power Sensor Node ASP-DAC 2014, Session 1S-3 Jan. 21, 2014 Masanori Hayashikoshi (Speaker), Yohei Sato, Hiroshi Ueki, Hiroyuki Kawai, Toru Shimizu, Renesas Electronics
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor. David Johnson Systems Technology Division Hewlett-Packard Company
 Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Real-Time Dynamic Energy Management on MPSoCs
 Real-Time Dynamic Energy Management on MPSoCs Tohru Ishihara Graduate School of Informatics, Kyoto University 2013/03/27 University of Bristol on Energy-Aware COmputing (EACO) Workshop 1 Background Low
Real-Time Dynamic Energy Management on MPSoCs Tohru Ishihara Graduate School of Informatics, Kyoto University 2013/03/27 University of Bristol on Energy-Aware COmputing (EACO) Workshop 1 Background Low
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
LOW POWER SRAM CELL WITH IMPROVED RESPONSE
 LOW POWER SRAM CELL WITH IMPROVED RESPONSE Anant Anand Singh 1, A. Choubey 2, Raj Kumar Maddheshiya 3 1 M.tech Scholar, Electronics and Communication Engineering Department, National Institute of Technology,
LOW POWER SRAM CELL WITH IMPROVED RESPONSE Anant Anand Singh 1, A. Choubey 2, Raj Kumar Maddheshiya 3 1 M.tech Scholar, Electronics and Communication Engineering Department, National Institute of Technology,
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
A Write-Back-Free 2T1D Embedded. a Dual-Row-Access Low Power Mode.
 A Write-Back-Free 2T1D Embedded DRAM with Local Voltage Sensing and a Dual-Row-Access Low Power Mode Wei Zhang, Ki Chul Chun, Chris H. Kim University of Minnesota, Minneapolis, MN zhang758@umn.edu Outline
A Write-Back-Free 2T1D Embedded DRAM with Local Voltage Sensing and a Dual-Row-Access Low Power Mode Wei Zhang, Ki Chul Chun, Chris H. Kim University of Minnesota, Minneapolis, MN zhang758@umn.edu Outline
6T- SRAM for Low Power Consumption. Professor, Dept. of ExTC, PRMIT &R, Badnera, Amravati, Maharashtra, India 1
 6T- SRAM for Low Power Consumption Mrs. J.N.Ingole 1, Ms.P.A.Mirge 2 Professor, Dept. of ExTC, PRMIT &R, Badnera, Amravati, Maharashtra, India 1 PG Student [Digital Electronics], Dept. of ExTC, PRMIT&R,
6T- SRAM for Low Power Consumption Mrs. J.N.Ingole 1, Ms.P.A.Mirge 2 Professor, Dept. of ExTC, PRMIT &R, Badnera, Amravati, Maharashtra, India 1 PG Student [Digital Electronics], Dept. of ExTC, PRMIT&R,
Low Power System Design
 Low Power System Design Module 18-1 (1.5 hours): Case study: System-Level Power Estimation and Reduction Jan. 2007 Naehyuck Chang EECS/CSE Seoul National University Contents In-house tools for low-power
Low Power System Design Module 18-1 (1.5 hours): Case study: System-Level Power Estimation and Reduction Jan. 2007 Naehyuck Chang EECS/CSE Seoul National University Contents In-house tools for low-power
Ultra Low Power (ULP) Challenge in System Architecture Level
 Challenge in System Architecture Level") Ultra Low Power (ULP) Challenge in System Architecture Level - New architectures for 45-nm, 32-nm era ASP-DAC 2007 Designers' Forum 9D: Panel Discussion: Top 10 Design Issues Toshinori Sato (Kyushu U)
Ultra Low Power (ULP) Challenge in System Architecture Level - New architectures for 45-nm, 32-nm era ASP-DAC 2007 Designers' Forum 9D: Panel Discussion: Top 10 Design Issues Toshinori Sato (Kyushu U)
Extreme Scale Computer Architecture: Energy Efficiency from the Ground Up
 Extreme Scale Computer Architecture: Energy Efficiency from the Ground Up Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Design, Automation
Extreme Scale Computer Architecture: Energy Efficiency from the Ground Up Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu Design, Automation
Advanced Computer Architecture (CS620)
") Advanced Computer Architecture (CS620) Background: Good understanding of computer organization (eg.cs220), basic computer architecture (eg.cs221) and knowledge of probability, statistics and modeling (eg.cs433).
Advanced Computer Architecture (CS620) Background: Good understanding of computer organization (eg.cs220), basic computer architecture (eg.cs221) and knowledge of probability, statistics and modeling (eg.cs433).
Embedded SRAM Technology for High-End Processors
 Embedded SRAM Technology for High-End Processors Hiroshi Nakadai Gaku Ito Toshiyuki Uetake Fujitsu is the only company in Japan that develops its own processors for use in server products that support
Embedded SRAM Technology for High-End Processors Hiroshi Nakadai Gaku Ito Toshiyuki Uetake Fujitsu is the only company in Japan that develops its own processors for use in server products that support
Vdd Programmable and Variation Tolerant FPGA Circuits and Architectures
 Vdd Programmable and Variation Tolerant FPGA Circuits and Architectures Prof. Lei He EE Department, UCLA LHE@ee.ucla.edu Partially supported by NSF. Pathway to Power Efficiency and Variation Tolerance
Vdd Programmable and Variation Tolerant FPGA Circuits and Architectures Prof. Lei He EE Department, UCLA LHE@ee.ucla.edu Partially supported by NSF. Pathway to Power Efficiency and Variation Tolerance
Real-Time Dynamic Voltage Hopping on MPSoCs
 Real-Time Dynamic Voltage Hopping on MPSoCs Tohru Ishihara System LSI Research Center, Kyushu University 2009/08/05 The 9 th International Forum on MPSoC and Multicore 1 Background Low Power / Low Energy
Real-Time Dynamic Voltage Hopping on MPSoCs Tohru Ishihara System LSI Research Center, Kyushu University 2009/08/05 The 9 th International Forum on MPSoC and Multicore 1 Background Low Power / Low Energy
2D/3D Graphics Accelerator for Mobile Multimedia Applications. Ramchan Woo, Sohn, Seong-Jun Song, Young-Don
 RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
RAMP-IV: A Low-Power and High-Performance 2D/3D Graphics Accelerator for Mobile Multimedia Applications Woo, Sungdae Choi, Ju-Ho Sohn, Seong-Jun Song, Young-Don Bae,, and Hoi-Jun Yoo oratory Dept. of EECS,
HPC VT Machine-dependent Optimization
 HPC VT 2013 Machine-dependent Optimization Last time Choose good data structures Reduce number of operations Use cheap operations strength reduction Avoid too many small function calls inlining Use compiler
HPC VT 2013 Machine-dependent Optimization Last time Choose good data structures Reduce number of operations Use cheap operations strength reduction Avoid too many small function calls inlining Use compiler
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection
 An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Blackfin Optimizations for Performance and Power Consumption
 The World Leader in High Performance Signal Processing Solutions Blackfin Optimizations for Performance and Power Consumption Presented by: Merril Weiner Senior DSP Engineer About This Module This module
The World Leader in High Performance Signal Processing Solutions Blackfin Optimizations for Performance and Power Consumption Presented by: Merril Weiner Senior DSP Engineer About This Module This module
Lecture 29 Review" CPU time: the best metric" Be sure you understand CC, clock period" Common (and good) performance metrics"
 performance metrics") Be sure you understand CC, clock period Lecture 29 Review Suggested reading: Everything Q1: D[8] = D[8] + RF[1] + RF[4] I[15]: Add R2, R1, R4 RF[1] = 4 I[16]: MOV R3, 8 RF[4] = 5 I[17]: Add R2, R2, R3
Be sure you understand CC, clock period Lecture 29 Review Suggested reading: Everything Q1: D[8] = D[8] + RF[1] + RF[4] I[15]: Add R2, R1, R4 RF[1] = 4 I[16]: MOV R3, 8 RF[4] = 5 I[17]: Add R2, R2, R3
Prediction Router: Yet another low-latency on-chip router architecture
 Prediction Router: Yet another low-latency on-chip router architecture Hiroki Matsutani Michihiro Koibuchi Hideharu Amano Tsutomu Yoshinaga (Keio Univ., Japan) (NII, Japan) (Keio Univ., Japan) (UEC, Japan)
Prediction Router: Yet another low-latency on-chip router architecture Hiroki Matsutani Michihiro Koibuchi Hideharu Amano Tsutomu Yoshinaga (Keio Univ., Japan) (NII, Japan) (Keio Univ., Japan) (UEC, Japan)
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications
 A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
Massively Parallel Computing on Silicon: SIMD Implementations. V.M.. Brea Univ. of Santiago de Compostela Spain
 Massively Parallel Computing on Silicon: SIMD Implementations V.M.. Brea Univ. of Santiago de Compostela Spain GOAL Give an overview on the state-of of-the- art of Digital on-chip CMOS SIMD Solutions,
Massively Parallel Computing on Silicon: SIMD Implementations V.M.. Brea Univ. of Santiago de Compostela Spain GOAL Give an overview on the state-of of-the- art of Digital on-chip CMOS SIMD Solutions,
Process and Design Solutions for Exploiting FD SOI Technology Towards Energy Efficient SOCs
 Process and Design Solutions for Exploiting FD SOI Technology Towards Energy Efficient SOCs Philippe FLATRESSE Technology R&D Central CAD & Design Solutions STMicroelectronics International Symposium on
Process and Design Solutions for Exploiting FD SOI Technology Towards Energy Efficient SOCs Philippe FLATRESSE Technology R&D Central CAD & Design Solutions STMicroelectronics International Symposium on
An Overview of Standard Cell Based Digital VLSI Design
 An Overview of Standard Cell Based Digital VLSI Design With examples taken from the implementation of the 36-core AsAP1 chip and the 1000-core KiloCore chip Zhiyi Yu, Tinoosh Mohsenin, Aaron Stillmaker,
An Overview of Standard Cell Based Digital VLSI Design With examples taken from the implementation of the 36-core AsAP1 chip and the 1000-core KiloCore chip Zhiyi Yu, Tinoosh Mohsenin, Aaron Stillmaker,
Jae Wook Lee. SIC R&D Lab. LG Electronics
 Jae Wook Lee SIC R&D Lab. LG Electronics Contents Introduction Why power validation on mobile application processor? Then, what to validate? Who is in charge of validation? Power Validation Components
Jae Wook Lee SIC R&D Lab. LG Electronics Contents Introduction Why power validation on mobile application processor? Then, what to validate? Who is in charge of validation? Power Validation Components
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Low-power Architecture. By: Jonathan Herbst Scott Duntley
 Low-power Architecture By: Jonathan Herbst Scott Duntley Why low power? Has become necessary with new-age demands: o Increasing design complexity o Demands of and for portable equipment Communication Media
Low-power Architecture By: Jonathan Herbst Scott Duntley Why low power? Has become necessary with new-age demands: o Increasing design complexity o Demands of and for portable equipment Communication Media
A Memory System Design Framework: Creating Smart Memories
 A Memory System Design Framework: Creating Smart Memories Amin Firoozshahian, Alex Solomatnikov Hicamp Systems Inc. Ofer Shacham, Zain Asgar, http://www.c2s2.org Stephen Richardson, Christos Kozyrakis,
A Memory System Design Framework: Creating Smart Memories Amin Firoozshahian, Alex Solomatnikov Hicamp Systems Inc. Ofer Shacham, Zain Asgar, http://www.c2s2.org Stephen Richardson, Christos Kozyrakis,
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Ultra Low-Cost Defect Protection for Microprocessor Pipelines
 Ultra Low-Cost Defect Protection for Microprocessor Pipelines Smitha Shyam Kypros Constantinides Sujay Phadke Valeria Bertacco Todd Austin Advanced Computer Architecture Lab University of Michigan Key
Ultra Low-Cost Defect Protection for Microprocessor Pipelines Smitha Shyam Kypros Constantinides Sujay Phadke Valeria Bertacco Todd Austin Advanced Computer Architecture Lab University of Michigan Key
Reconfigurable Computing. Introduction
 Reconfigurable Computing Tony Givargis and Nikil Dutt Introduction! Reconfigurable computing, a new paradigm for system design Post fabrication software personalization for hardware computation Traditionally
Reconfigurable Computing Tony Givargis and Nikil Dutt Introduction! Reconfigurable computing, a new paradigm for system design Post fabrication software personalization for hardware computation Traditionally
A Non-Volatile Microcontroller with Integrated Floating-Gate Transistors
 A Non-Volatile Microcontroller with Integrated Floating-Gate Transistors Wing-kei Yu, Shantanu Rajwade, Sung-En Wang, Bob Lian, G. Edward Suh, Edwin Kan Cornell University 2 of 32 Self-Powered Devices
A Non-Volatile Microcontroller with Integrated Floating-Gate Transistors Wing-kei Yu, Shantanu Rajwade, Sung-En Wang, Bob Lian, G. Edward Suh, Edwin Kan Cornell University 2 of 32 Self-Powered Devices
CALCULATION OF POWER CONSUMPTION IN 7 TRANSISTOR SRAM CELL USING CADENCE TOOL
 CALCULATION OF POWER CONSUMPTION IN 7 TRANSISTOR SRAM CELL USING CADENCE TOOL Shyam Akashe 1, Ankit Srivastava 2, Sanjay Sharma 3 1 Research Scholar, Deptt. of Electronics & Comm. Engg., Thapar Univ.,
CALCULATION OF POWER CONSUMPTION IN 7 TRANSISTOR SRAM CELL USING CADENCE TOOL Shyam Akashe 1, Ankit Srivastava 2, Sanjay Sharma 3 1 Research Scholar, Deptt. of Electronics & Comm. Engg., Thapar Univ.,
ReNoC: A Network-on-Chip Architecture with Reconfigurable Topology
 1 ReNoC: A Network-on-Chip Architecture with Reconfigurable Topology Mikkel B. Stensgaard and Jens Sparsø Technical University of Denmark Technical University of Denmark Outline 2 Motivation ReNoC Basic
1 ReNoC: A Network-on-Chip Architecture with Reconfigurable Topology Mikkel B. Stensgaard and Jens Sparsø Technical University of Denmark Technical University of Denmark Outline 2 Motivation ReNoC Basic
EECS Dept., University of California at Berkeley. Berkeley Wireless Research Center Tel: (510)
") A V Heterogeneous Reconfigurable Processor IC for Baseband Wireless Applications Hui Zhang, Vandana Prabhu, Varghese George, Marlene Wan, Martin Benes, Arthur Abnous, and Jan M. Rabaey EECS Dept., University
A V Heterogeneous Reconfigurable Processor IC for Baseband Wireless Applications Hui Zhang, Vandana Prabhu, Varghese George, Marlene Wan, Martin Benes, Arthur Abnous, and Jan M. Rabaey EECS Dept., University
COSC4201. Chapter 5. Memory Hierarchy Design. Prof. Mokhtar Aboelaze York University
 COSC4201 Chapter 5 Memory Hierarchy Design Prof. Mokhtar Aboelaze York University 1 Memory Hierarchy The gap between CPU performance and main memory has been widening with higher performance CPUs creating
COSC4201 Chapter 5 Memory Hierarchy Design Prof. Mokhtar Aboelaze York University 1 Memory Hierarchy The gap between CPU performance and main memory has been widening with higher performance CPUs creating
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
SH-X3 Flexible SuperH Multi-core for High-performance and Low-power Embedded Systems
 SH-X3 Flexible SuperH Multi-core for High-performance and Low-power Embedded Systems Shinichi Shibahara 1, Masashi Takada 2, Tatsuya Kamei 1, Kiyoshi Hayase 1, Yutaka Yoshida 1, Osamu Nishii 1, Toshihiro
SH-X3 Flexible SuperH Multi-core for High-performance and Low-power Embedded Systems Shinichi Shibahara 1, Masashi Takada 2, Tatsuya Kamei 1, Kiyoshi Hayase 1, Yutaka Yoshida 1, Osamu Nishii 1, Toshihiro
Adaptive Voltage Scaling (AVS) Alex Vainberg October 13, 2010
 Alex Vainberg October 13, 2010") Adaptive Voltage Scaling (AVS) Alex Vainberg Email: alex.vainberg@nsc.com October 13, 2010 Agenda AVS Introduction, Technology and Architecture Design Implementation Hardware Performance Monitors Overview
Adaptive Voltage Scaling (AVS) Alex Vainberg Email: alex.vainberg@nsc.com October 13, 2010 Agenda AVS Introduction, Technology and Architecture Design Implementation Hardware Performance Monitors Overview
Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1)
") Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
An Ultra High Performance Scalable DSP Family for Multimedia. Hot Chips 17 August 2005 Stanford, CA Erik Machnicki
 An Ultra High Performance Scalable DSP Family for Multimedia Hot Chips 17 August 2005 Stanford, CA Erik Machnicki Media Processing Challenges Increasing performance requirements Need for flexibility &
An Ultra High Performance Scalable DSP Family for Multimedia Hot Chips 17 August 2005 Stanford, CA Erik Machnicki Media Processing Challenges Increasing performance requirements Need for flexibility &
Simulation and Analysis of SRAM Cell Structures at 90nm Technology
 Vol.1, Issue.2, pp-327-331 ISSN: 2249-6645 Simulation and Analysis of SRAM Cell Structures at 90nm Technology Sapna Singh 1, Neha Arora 2, Prof. B.P. Singh 3 (Faculty of Engineering and Technology, Mody
Vol.1, Issue.2, pp-327-331 ISSN: 2249-6645 Simulation and Analysis of SRAM Cell Structures at 90nm Technology Sapna Singh 1, Neha Arora 2, Prof. B.P. Singh 3 (Faculty of Engineering and Technology, Mody
A Tightly Coupled General Purpose Reconfigurable Accelerator LAPP and Its Power States for HotSpot-Based Energy Reduction
 3092 PAPER Special Section on Parallel and Distributed Computing and Networking A Tightly Coupled General Purpose Reconfigurable Accelerator LAPP and Its Power States for HotSpot-Based Energy Reduction
3092 PAPER Special Section on Parallel and Distributed Computing and Networking A Tightly Coupled General Purpose Reconfigurable Accelerator LAPP and Its Power States for HotSpot-Based Energy Reduction
Performance/Cost trade-off evaluation for the DCT implementation on the Dynamically Reconfigurable Processor
 Performance/Cost trade-off evaluation for the DCT implementation on the Dynamically Reconfigurable Processor Vu Manh Tuan, Yohei Hasegawa, Naohiro Katsura and Hideharu Amano Graduate School of Science
Performance/Cost trade-off evaluation for the DCT implementation on the Dynamically Reconfigurable Processor Vu Manh Tuan, Yohei Hasegawa, Naohiro Katsura and Hideharu Amano Graduate School of Science
Computer Architecture s Changing Definition
 Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
Memory technology and optimizations ( 2.3) Main Memory
 Main Memory") Memory technology and optimizations ( 2.3) 47 Main Memory Performance of Main Memory: Latency: affects Cache Miss Penalty» Access Time: time between request and word arrival» Cycle Time: minimum time between
Memory technology and optimizations ( 2.3) 47 Main Memory Performance of Main Memory: Latency: affects Cache Miss Penalty» Access Time: time between request and word arrival» Cycle Time: minimum time between
Memory Hierarchies. Instructor: Dmitri A. Gusev. Fall Lecture 10, October 8, CS 502: Computers and Communications Technology
 Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Near-Threshold Computing: Reclaiming Moore s Law
 1 Near-Threshold Computing: Reclaiming Moore s Law Dr. Ronald G. Dreslinski Research Fellow Ann Arbor 1 1 Motivation 1000000 Transistors (100,000's) 100000 10000 Power (W) Performance (GOPS) Efficiency (GOPS/W)
1 Near-Threshold Computing: Reclaiming Moore s Law Dr. Ronald G. Dreslinski Research Fellow Ann Arbor 1 1 Motivation 1000000 Transistors (100,000's) 100000 10000 Power (W) Performance (GOPS) Efficiency (GOPS/W)
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Gigascale Integration Design Challenges & Opportunities. Shekhar Borkar Circuit Research, Intel Labs October 24, 2004
 Gigascale Integration Design Challenges & Opportunities Shekhar Borkar Circuit Research, Intel Labs October 24, 2004 Outline CMOS technology challenges Technology, circuit and μarchitecture solutions Integration
Gigascale Integration Design Challenges & Opportunities Shekhar Borkar Circuit Research, Intel Labs October 24, 2004 Outline CMOS technology challenges Technology, circuit and μarchitecture solutions Integration
Marching Memory マーチングメモリ. UCAS-6 6 > Stanford > Imperial > Verify 中村維男 Based on Patent Application by Tadao Nakamura and Michael J.
 UCAS-6 6 > Stanford > Imperial > Verify 2011 Marching Memory マーチングメモリ Tadao Nakamura 中村維男 Based on Patent Application by Tadao Nakamura and Michael J. Flynn 1 Copyright 2010 Tadao Nakamura C-M-C Computer
UCAS-6 6 > Stanford > Imperial > Verify 2011 Marching Memory マーチングメモリ Tadao Nakamura 中村維男 Based on Patent Application by Tadao Nakamura and Michael J. Flynn 1 Copyright 2010 Tadao Nakamura C-M-C Computer
Integrating MRPSOC with multigrain parallelism for improvement of performance
 Integrating MRPSOC with multigrain parallelism for improvement of performance 1 Swathi S T, 2 Kavitha V 1 PG Student [VLSI], Dept. of ECE, CMRIT, Bangalore, Karnataka, India 2 Ph.D Scholar, Jain University,
Integrating MRPSOC with multigrain parallelism for improvement of performance 1 Swathi S T, 2 Kavitha V 1 PG Student [VLSI], Dept. of ECE, CMRIT, Bangalore, Karnataka, India 2 Ph.D Scholar, Jain University,
FPGA Power and Timing Optimization: Architecture, Process, and CAD
 FPGA Power and Timing Optimization: Architecture, Process, and CAD Chun Zhang 1, Lerong Cheng 2, Lingli Wang 1* and Jiarong Tong 1 1 State-Key-Lab of ASIC & System, Fudan University llwang@fudan.edu.cn
FPGA Power and Timing Optimization: Architecture, Process, and CAD Chun Zhang 1, Lerong Cheng 2, Lingli Wang 1* and Jiarong Tong 1 1 State-Key-Lab of ASIC & System, Fudan University llwang@fudan.edu.cn
A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps
 A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps Nandita Vijaykumar Gennady Pekhimenko, Adwait Jog, Abhishek Bhowmick, Rachata Ausavarangnirun,
A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps Nandita Vijaykumar Gennady Pekhimenko, Adwait Jog, Abhishek Bhowmick, Rachata Ausavarangnirun,
KiloCore: A 32 nm 1000-Processor Array
 KiloCore: A 32 nm 1000-Processor Array Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas University of California, Davis VLSI Computation
KiloCore: A 32 nm 1000-Processor Array Brent Bohnenstiehl, Aaron Stillmaker, Jon Pimentel, Timothy Andreas, Bin Liu, Anh Tran, Emmanuel Adeagbo, Bevan Baas University of California, Davis VLSI Computation
Memory Hierarchy. Reading. Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 (2) Lecture notes from MKP, H. H. Lee and S.
, 5.9 (2) Lecture notes from MKP, H. H. Lee and S.") Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
ECE 571 Advanced Microprocessor-Based Design Lecture 22
 ECE 571 Advanced Microprocessor-Based Design Lecture 22 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 19 April 2018 HW#11 will be posted Announcements 1 Reading 1 Exploring DynamIQ
ECE 571 Advanced Microprocessor-Based Design Lecture 22 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 19 April 2018 HW#11 will be posted Announcements 1 Reading 1 Exploring DynamIQ
University of California, Berkeley. Midterm II. You are allowed to use a calculator and one 8.5" x 1" double-sided page of notes.
 University of California, Berkeley College of Engineering Computer Science Division EECS Fall 1997 D.A. Patterson Midterm II October 19, 1997 CS152 Computer Architecture and Engineering You are allowed
University of California, Berkeley College of Engineering Computer Science Division EECS Fall 1997 D.A. Patterson Midterm II October 19, 1997 CS152 Computer Architecture and Engineering You are allowed
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Lecture 18: Core Design, Parallel Algos
 Lecture 18: Core Design, Parallel Algos Today: Innovations for ILP, TLP, power and parallel algos Sign up for class presentations 1 SMT Pipeline Structure Front End Front End Front End Front End Private/
Lecture 18: Core Design, Parallel Algos Today: Innovations for ILP, TLP, power and parallel algos Sign up for class presentations 1 SMT Pipeline Structure Front End Front End Front End Front End Private/